Définir les objectifs et le périmètre du suivi de la fiabilité
Avant de choisir des métriques ou de construire des tableaux de bord, décidez de ce dont votre application de fiabilité est responsable — et de ce qu'elle n'est pas. Un périmètre clair empêche l'outil de devenir un « portail ops » fourre‑tout que personne ne regarde.
Définir ce que vous suivez
Commencez par lister les outils internes que l'application couvrira (par ex. gestion de tickets, paie, intégrations CRM, pipelines de données) et les équipes qui les possèdent ou en dépendent. Soyez explicite sur les frontières : « site client » peut être hors périmètre, tandis que « console d'admin interne » est dedans.
S'accorder sur la définition de « fiabilité »
Les organisations n'emploient pas toujours ce mot de la même façon. Rédigez votre définition opérationnelle en langage clair — généralement un mélange de :
- Disponibilité : les utilisateurs peuvent‑ils y accéder quand il le faut ?
- Latence : est‑ce assez rapide pour être utilisable ?
- Erreurs : y a‑t‑il des échecs perceptibles par les utilisateurs (timeouts, jobs échoués, réponses incorrectes) ?
Si les équipes ne sont pas alignées, l'app finira par comparer des pommes et des oranges.
Décider des résultats attendus
Choisissez 1 à 3 résultats principaux, par exemple :
- Détection plus rapide des problèmes (temps moyen pour remarquer réduit)
- Rapports plus clairs pour managers et parties prenantes
- Moins d'incidents répétés via un meilleur suivi des actions
Ces résultats guideront ensuite ce que vous mesurez et comment vous le présentez.
Identifier les utilisateurs et les rôles
Listez qui utilisera l'app et quelles décisions ils prennent : ingénieurs investiguant les incidents, support escaladant, managers regardant les tendances, et parties prenantes demandant des statuts. Cela façonnera la terminologie, les permissions et le niveau de détail pour chaque vue.
Choisir les métriques de fiabilité pertinentes (SLIs/SLOs)
Le suivi de fiabilité ne fonctionne que si tout le monde s'accorde sur ce que signifie « bon ». Commencez par séparer trois termes proches.
SLIs vs SLOs vs SLAs (en clair)
Un SLI (Service Level Indicator) est une mesure : « quel pourcentage de requêtes a réussi ? » ou « combien de temps les pages mettent‑elles à charger ? »
Un SLO (Service Level Objective) est l'objectif pour cette mesure : « 99,9 % de succès sur 30 jours. »
Un SLA (Service Level Agreement) est une promesse avec conséquences, généralement orientée externe (crédits, pénalités). Pour les outils internes, vous définirez souvent des SLOs sans SLAs formels — suffisants pour aligner les attentes sans transformer la fiabilité en contrat.
Choisir un petit ensemble d'SLIs cohérents par outil
Gardez‑les comparables entre outils et faciles à expliquer. Une base pratique :
- Uptime/disponibilité : le service était‑il joignable ?
- Temps de réponse : à quelle vitesse les pages ou endpoints clés répondent‑ils ?
- Taux d'erreur : quelle part des vérifications ou requêtes a échoué (5xx, timeouts, états d'échec connus) ?
Évitez d'en ajouter tant que vous ne pouvez pas répondre : « Quelle décision cette métrique déclenchera ? »
Choisir des fenêtres temporelles qui font sens
Utilisez des fenêtres glissantes pour que les scorecards se mettent à jour en continu :
- 7 jours : capte rapidement les régressions
- 30 jours : reporting et tendance mensuels
- 90 jours : stabilité sur le trimestre
Définir les incidents avec des niveaux de sévérité clairs
Votre app doit transformer les métriques en actions. Définissez des niveaux de sévérité (par ex. Sev1–Sev3) et des déclencheurs explicites comme :
- Sev1 : outil indisponible ou workflow critique bloqué pendant X minutes
- Sev2 : dégradation majeure (p. ex. taux d'erreur au‑dessus de Y % pendant Z minutes)
- Sev3 : problèmes mineurs ou intermittents
Ces définitions rendent l'alerte, les timelines d'incident et le suivi du budget d'erreur cohérents entre équipes.
Planifier les sources de données et l'approche d'ingestion
Une application de suivi de fiabilité n'est crédible que si les données le sont. Avant de construire des pipelines d'ingestion, cartographiez chaque signal que vous traiterez comme « vérité » et notez la question à laquelle il répond (disponibilité, latence, erreurs, impact de déploiement, réponse à incident).
Cartographier les sources de données existantes
La plupart des équipes peuvent couvrir le socle avec un mélange de :
- Checks de statut / probes synthétiques (uptime et temps de réponse basique)
- Métriques (percentiles de latence, taux d'erreur, saturation)
- Logs (comptes d'erreurs, endpoints les plus défaillants)
- Traces (où la latence se consomme entre dépendances)
- Outils de ticketing/incidents (début/fin d'incident, sévérité, propriétaire, liens de postmortem)
Soyez explicite sur les systèmes faisant foi. Par exemple, votre « SLI d'uptime » peut provenir uniquement des probes synthétiques, pas des logs serveurs.
Choisir push vs pull (et à quelle fréquence)
- Pull fonctionne bien pour des APIs (Prometheus, monitoring cloud, ticketing) : votre app interroge selon un planning.
- Push est préférable pour les événements à fort volume (déploiements, incidents, alertes) : les systèmes envoient webhooks/événements à votre app.
Définissez la fréquence selon le cas d'usage : les tableaux peuvent se rafraîchir toutes les 1–5 minutes, tandis que les scorecards peuvent être calculées chaque heure ou quotidiennement.
Normaliser les identifiants et la propriété
Créez des IDs cohérents pour outils/services, environnements (prod/stage) et propriétaires. Accordez‑vous sur des règles de nommage tôt pour que « Payments-API », « payments_api » et « payments » ne deviennent pas trois entités distinctes.
Rétention et confidentialité
Planifiez ce que vous conservez et combien de temps (par ex. événements bruts 30–90 jours, agrégats quotidiens 12–24 mois). Évitez d'ingérer des payloads sensibles ; stockez seulement les métadonnées nécessaires à l'analyse de fiabilité (horodatage, codes d'état, buckets de latence, tags d'incident).
Concevoir le modèle de données et le schéma de la base
Votre schéma doit faciliter deux choses : répondre aux questions courantes (« cet outil est‑il sain ? ») et reconstruire ce qui s'est passé pendant un incident (« quand les symptômes ont‑ils commencé, qui a changé quoi, quelles alertes sont tombées ? »). Commencez par un petit ensemble d'entités cœur et explicitez les relations.
Entités cœur (démarrez minimal)
- Tool/Service : l'outil interne suivi (nom, description, environnement, criticité).
- Check : une vérification d'uptime ou synthétique liée à un outil (type, URL cible, planning, activée).
- Metric : datapoints de séries temporelles (latence, taux de succès, compte d'erreurs) associés à un outil ou check.
- SLO : l'objectif et la fenêtre d'évaluation (p. ex. 99,9 % sur 30 jours) plus les paramètres de budget d'erreur.
- Incident : un événement impactant la fiabilité (sévérité, statut, début/fin, résumé).
- Event : un enregistrement de timeline pour les incidents (changements d'état, notes, alerte reçue, mitigation appliquée).
- Owner : équipe ou individu responsable de l'outil.
Relations qui simplifient les requêtes
Un socle pratique :
- Tool a plusieurs Checks (et peut avoir plusieurs SLOs).
- Check a plusieurs Metrics (ou flux de métriques).
- Incident appartient à Tool, et Incident a plusieurs Events pour la timeline.
- Tool appartient à Owner (ou many‑to‑many si la propriété partagée est fréquente).
Cette structure prend en charge les tableaux de bord (« outil → statut courant → incidents récents ») et le drill‑down (« incident → events → checks et métriques associés »).
Champs d'audit et tagging
Ajoutez des champs d'audit partout où vous avez besoin de responsabilité et d'historique :
created_by, created_at, updated_atstatus plus suivi des changements de statut (soit dans la table Event, soit dans une table d'historique dédiée)
Enfin, incluez des tags flexibles pour filtrer et reporter (par ex. équipe, criticité, système, conformité). Une table de jointure tool_tags (tool_id, key, value) garde le tagging cohérent et facilite les scorecards et rollups plus tard.
Choisir une stack technique et un modèle de déploiement
Votre tracker de fiabilité doit être « ennuyeux » dans le meilleur sens : facile à exécuter, à modifier et à maintenir. La stack « correcte » est souvent celle que votre équipe peut supporter sans exploits héroïques.
Commencez par ce que votre équipe connaît déjà
Choisissez un framework web mainstream que l'équipe maîtrise — Node/Express, Django ou Rails sont de bons choix. Priorisez :
- Conventions claires (pour que les nouveaux contributeurs ne se perdent pas)
- Bonnes bibliothèques pour l'auth, les jobs en arrière‑plan et les graphiques
- Chemins de mise à jour prévisibles
Si vous intégrez des systèmes internes (SSO, ticketing, chat), choisissez l'écosystème où ces intégrations sont les plus simples.
Si vous voulez accélérer la première itération, une plateforme de vibe‑coding comme Koder.ai peut être un point de départ pratique : vous décrivez vos entités (tools, checks, SLOs, incidents), workflows (alerte → incident → postmortem) et tableaux, puis générez rapidement un scaffold d'app web. Koder.ai cible souvent React côté frontend et Go + PostgreSQL côté backend, ce qui correspond bien à la stack par défaut « ennuyeuse et maintenable » que beaucoup d'équipes préfèrent — et vous pouvez exporter le code source si vous migrez ensuite vers un pipeline entièrement manuel.
Base de données d'abord, puis composants annexes
Pour la plupart des applications internes, PostgreSQL est le bon défaut : il gère bien le reporting relationnel, les requêtes temporelles et l'audit.
Ajoutez des composants supplémentaires seulement s'ils résolvent un vrai problème :
- Cache (ex. Redis) si les tableaux sont lents ou si vous êtes limité par des APIs upstream
- Queue / jobs en arrière‑plan (Redis + worker, Sidekiq, Celery, BullMQ) pour le polling d'uptime, l'envoi de notifications et la génération de rapports
Hébergement et modèle de déploiement
Décidez entre :
- Cloud interne / Kubernetes quand vous avez besoin d'un accès réseau plus serré aux services internes
- PaaS quand vous voulez des opérations plus simples et une itération rapide
Quelle que soit l'option, standardisez dev/staging/prod et automatisez les déploiements (CI/CD), pour que des changements ne modifient pas silencieusement les chiffres de fiabilité. Si vous utilisez une plateforme (y compris Koder.ai), recherchez des fonctionnalités comme séparation d'environnements, déploiement/hébergement et rollback rapide (snapshots) pour itérer en sécurité sans casser le tracker lui‑même.
Gestion de configuration fiable
Documentez la configuration en un seul endroit : variables d'environnement, secrets et feature flags. Gardez un guide « comment lancer en local » et un runbook minimal (quoi faire si l'ingestion s'arrête, si la queue s'accumule ou si la DB atteint ses limites). Une page courte dans /docs suffit souvent.
Concevoir l'UX : tableaux de bord, drill‑downs et workflows
Itérez avec des rollbacks sécurisés
Utilisez des instantanés et des rollbacks pour itérer sur l'ingestion et les alertes sans perdre une version stable.
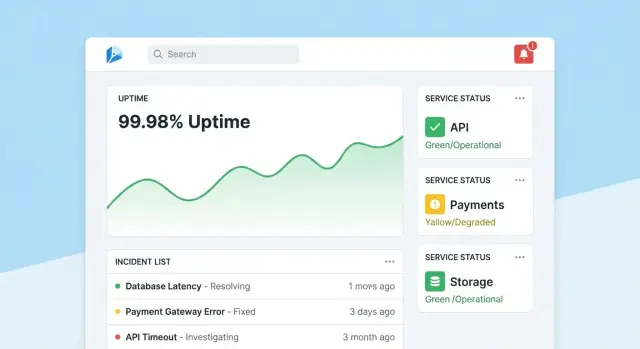
Une application de suivi de fiabilité réussit quand les gens peuvent répondre en quelques secondes à deux questions : « Sommes‑nous OK ? » et « Que dois‑je faire ensuite ? » Concevez les écrans autour de ces décisions, avec une navigation claire Aperçu → Outil spécifique → Incident spécifique.
Page d'accueil : lecture rapide de santé
Faites de la page d'accueil un centre de commande compact. Mettez en avant un résumé de santé global (p. ex. nombre d'outils respectant les SLOs, incidents actifs, plus gros risques actuels), puis affichez incidents et alertes récentes avec badges de statut.
Gardez la vue par défaut calme : n'affichez que ce qui requiert de l'attention. Donnez à chaque tuile un drill‑down direct vers l'outil ou l'incident affecté.
Page d'outil : du statut à l'action
Chaque page d'outil doit répondre à « Cet outil est‑il suffisamment fiable ? » et « Pourquoi / pourquoi pas ? » Incluez :
- Statut SLO courant avec pass/fail simple et budget d'erreur restant
- Graphiques d'uptime, latence ou taux d'erreur sur des plages temporelles sélectionnables
- Changements récents (déploiements, éditions de config, mises à jour de checks) pour faire ressortir des patterns
- Runbooks et owners : une section « Que faire » bien visible avec liens et contacts
Concevez les graphiques pour des non‑experts : étiquetez les unités, marquez les seuils SLO et ajoutez de petites explications (tooltips) plutôt que des contrôles techniques denses.
Page d'incident : contexte partagé et timeline
Une page d'incident est un document vivant. Incluez une timeline (événements capturés automatiquement comme alerte déclenchée, acquittée, atténuée), les mises à jour humaines, les utilisateurs impactés et les actions prises.
Simplifiez la publication des mises à jour : une zone de texte unique, statuts prédéfinis (Investigating/Identified/Monitoring/Resolved) et notes internes optionnelles. À la clôture, une action « Démarrer postmortem » devrait préremplir les faits depuis la timeline.
Pages d'administration : propriété et cohérence
Les admins ont besoin d'écrans simples pour gérer outils, checks, cibles SLO et owners. Optimisez pour la justesse : valeurs par défaut sensées, validations et avertissements quand une modification impacte le reporting. Ajoutez une trace visible « dernière modification » pour que les gens fassent confiance aux chiffres.
Implémenter authentification, permissions et traces d'audit
Les données de fiabilité restent utiles tant que les gens y font confiance. Cela implique d'associer chaque changement à une identité, de limiter qui peut faire des modifications à fort impact et de garder un historique clair pour les revues.
Authentification : utilisez ce que votre entreprise a déjà
Pour un outil interne, par défaut utilisez SSO (SAML) ou OAuth/OIDC via votre fournisseur d'identité (Okta, Azure AD, Google Workspace). Cela réduit la gestion des mots de passe et automatise onboarding/offboarding.
Détails pratiques :
- Imposer MFA via l'IdP (ne le ré‑implémentez pas)
- Mapper les groupes IdP aux rôles applicatifs à la connexion
- Définir des durées de session courtes et supporter la déconnexion manuelle
Permissions : contrôle par rôles avec « actions protégées »
Commencez par des rôles simples et ajoutez des règles plus fines seulement si nécessaire :
- Viewer : tableaux et scorecards en lecture seule
- Editor : création/mise à jour des checks, incidents et notes
- Admin : gestion des définitions SLO, des seuils, des intégrations et des mappings utilisateurs/rôles
Protégez les actions modifiant les résultats de fiabilité ou le récit du reporting :
- Seuls les Admins peuvent changer les cibles SLO, les seuils d'alerte ou les mappings de source de données.
- Restreignez qui peut clore un incident ou le marquer « résolu », et exigez un résumé de résolution.
Traces d'audit : historique immuable des modifications
Loggez chaque édition d'SLOs, checks et champs d'incident avec :
- qui l'a fait (utilisateur + rôle)
- quand (timestamp)
- ce qui a changé (valeurs avant/après)
- d'où ça vient (UI, API, automation)
Rendez ces logs consultables et visibles depuis les pages détaillées (p. ex. la page d'incident affiche toute son histoire de changements). Cela rend les revues factuelles et réduit les débats pendant les postmortems.
Construire des checks de monitoring et la collecte d'uptime
Le monitoring est la « couche capteur » de votre app : il transforme le comportement réel en données fiables. Pour les outils internes, les checks synthétiques sont souvent la voie la plus rapide car vous contrôlez la définition de « healthy ».
Définir des checks synthétiques par outil
Commencez par un petit ensemble de types de checks couvrant la plupart des apps internes :
- HTTP ping : vérifier que le service répond (code d'état, TLS, en‑têtes basiques).
- Validation d'endpoint : frapper une URL connue et valider quelque chose de signifiant (forme JSON attendue, présence d'une chaîne dans le HTML, payload d'health endpoint).
- Chemin « smoke » sans login : si possible, tester un flux en lecture seule reflétant l'expérience utilisateur (p. ex. charger la page du dashboard et vérifier le rendu).
Gardez les validations déterministes. Si une validation peut échouer à cause d'un contenu changeant, vous génèrerez du bruit et perdrez la confiance.
Collecter uptime et latence (et les stocker intelligemment)
Pour chaque exécution de check, capturez :
- Timestamp (début et fin)
- Résultat : up/down/unknown
- Latence : durée totale (et optionnellement DNS/connect/TTFB si mesuré)
- Raison : code d'erreur, timeout, échec de validation ou message d'exception
Stockez soit comme événements séries temporelles (une ligne par exécution de check), soit comme rollups agrégés (ex. rollups par minute avec comptes et p95 de latence). Les données événementielles aident au débogage ; les rollups accélèrent les tableaux de bord. Beaucoup d'équipes font les deux : garder les événements bruts 7–30 jours et les rollups pour le reporting à long terme.
Traiter explicitement les pannes vs les données manquantes
Un résultat de check manquant ne devrait pas signifier automatiquement « down ». Ajoutez un état unknown pour les cas comme :
- le worker de check est arrêté
- partition réseau entre le checker et la cible
- configuration retirée en cours d'exécution
Cela évite de gonfler le temps d'arrêt et rend les « lacunes de monitoring » visibles comme leur propre problème opérationnel.
Exécuter les checks avec des jobs en arrière‑plan
Utilisez des workers (planning type cron, queues) pour exécuter les checks à intervalles fixes (p. ex. toutes les 30–60 secondes pour les outils critiques). Intégrez timeouts, retries avec backoff et limites de concurrence pour que vos checkers ne saturent pas les services internes. Persistez chaque résultat d'exécution — mêmes les échecs — pour que le dashboard d'uptime montre l'historique fiable et l'état courant.
Créer des flux d'alerte et de notification
Exportez le code source à tout moment
Gardez le contrôle total en exportant le code quand vous souhaitez passer à votre propre pipeline.
Les alertes sont le point où le suivi de fiabilité devient action. L'objectif est simple : notifier les bonnes personnes, avec le bon contexte, au bon moment — sans les inonder.
Relier les alertes aux SLOs (pas seulement aux seuils)
Définissez des règles d'alerte liées directement à vos SLIs/SLOs. Deux motifs pratiques :
- Alertes burn‑rate : alerter quand le budget d'erreur est consommé trop rapidement et que l'on risque de manquer l'SLO.
- Brèches de seuil : prévenir quand une métrique franchit une borne claire (ex. disponibilité < 99,5 % sur 15 minutes).
Pour chaque règle, stockez le « pourquoi » avec le « quoi » : quel SLO est impacté, la fenêtre d'évaluation et la sévérité prévue.
Rendre les notifications actionnables
Envoyez les notifications via les canaux où les équipes vivent déjà (email, Slack, Microsoft Teams). Chaque message doit contenir :
- Un résumé en une ligne (service + symptôme + sévérité)
- Un lien direct vers la vue de dashboard pertinente (ex.
/services/payments?window=1h)
- Un lien vers la page d'incident si elle est créée (ex.
/incidents/123)
Évitez de balancer des métriques brutes. Fournissez une courte « prochaine étape » comme « Vérifier les déploiements récents » ou « Ouvrir les logs ».
Réduire le bruit avec déduplication, groupement et heures calmes
Implémentez :
- Déduplication (même empreinte d'alerte → mettre à jour le fil existant)
- Groupement (un incident peut agréger plusieurs alertes liées)
- Heures calmes et règles de routage pour que les alertes de faible sévérité n'éveillent pas l'on‑call
Supporter l'escalade et le routage on‑call
Même en interne, les gens ont besoin de contrôle. Ajoutez une escalade manuelle (bouton sur la page d'alerte/incident) et intégrez‑vous à l'outil on‑call si disponible (PagerDuty/Opsgenie ou équivalents), ou au minimum une rotation configurable stockée dans votre app.
Ajouter la gestion d'incidents et les fonctionnalités de postmortem
La gestion d'incidents transforme « on a reçu une alerte » en réponse partagée et traçable. Intégrez‑la dans l'app pour que les équipes passent du signal à la coordination sans sauter entre outils.
Création d'incident en un clic
Permettez de créer un incident directement depuis une alerte, une page de service ou un graphique d'uptime. Préremplissez les champs clés (service, environnement, source de l'alerte, première apparition) et assignez un ID d'incident unique.
Un jeu de champs par défaut léger garde l'action simple : sévérité, impact client (équipes internes affectées), propriétaire courant et liens vers l'alerte déclenchante.
Cycle de vie et collaboration
Utilisez un cycle simple correspondant au travail réel :
- Open → Investigating → Mitigated → Resolved
Chaque changement de statut doit capturer qui l'a fait et quand. Ajoutez des mises à jour timeline (notes courtes horodatées), et supportez pièces jointes et liens vers runbooks et tickets (ex. /runbooks/payments-retries ou /tickets/INC-1234). Cela devient le fil unique « ce qui s'est passé et ce que nous avons fait ».
Postmortems avec éléments d'action
Les postmortems doivent être rapides à démarrer et cohérents à revoir. Fournissez des modèles avec :
- Résumé, impact, détection et cause racine
- Facteurs contributifs (y compris gaps de process)
- Ce qui a fonctionné / ce qui n'a pas fonctionné
- Suivis avec propriétaires et dates d'échéance
Reliez les actions au ticket d'incident, suivez leur achèvement et affichez les éléments en retard sur les tableaux d'équipe. Si vous supportez des « learning reviews », proposez un mode non‑blâmant axé sur le système et les processus plutôt que sur les erreurs individuelles.
Reporting et scorecards de fiabilité
Transformez les SLOs en tableaux de bord
Créez des vues React pour tableaux de score et analyses détaillées avec Go et PostgreSQL générés pour vous.
Le reporting transforme le suivi en prise de décision. Les tableaux aident les opérateurs ; les scorecards aident les dirigeants à voir si les outils internes s'améliorent, quelles zones nécessitent des investissements et ce que signifie « bon ».
Contenu d'une scorecard
Construisez une vue cohérente par outil (et éventuellement par équipe) qui répond rapidement :
- Conformité SLO dans le temps : période courante (semaine/mois/trimestre) et courbe de tendance contre l'objectif.
- Outils les moins fiables : classement par SLO manqué, minutes d'indisponibilité ou burn d'erreur le plus élevé.
- MTTR : médiane et p90 du temps de restauration, pour qu'un incident long n'occulte pas une tendance.
- Nombre d'incidents : total et répartition par sévérité (Sev1–Sev3), avec comparaison à la période précédente.
Ajoutez, lorsque possible, un contexte léger : « SLO manqué dû à 2 déploiements » ou « plupart des indisponibilités causées par la dépendance X », sans transformer le rapport en revue d'incident complète.
Filtres rendant le reporting utile pour la direction
Les dirigeants veulent rarement « tout ». Ajoutez des filtres par équipe, criticité de l'outil (ex. Tier 0–3) et fenêtre temporelle. Assurez‑vous qu'un même outil peut apparaître dans plusieurs rollups (équipe plateforme le possède, finance y dépend).
Résumés et exports
Fournissez des résumés hebdomadaires et mensuels partageables :
- Export CSV en un clic pour les tableurs
- Export PDF propre pour les revues de statut
Gardez la narration cohérente (« Qu'est‑ce qui a changé depuis la période précédente ? » « Où sommes‑nous en dépassement de budget ? »). Si nécessaire, liez un guide court comme /blog/sli-slo-basics pour les parties prenantes.
Sécurité, qualité des données et durcissement opérationnel
Le tracker devient rapidement une source de vérité. Traitez‑le comme un système de production : sécurisé par défaut, résistant aux mauvaises données et facile à restaurer quand quelque chose casse.
Protéger la surface de l'app
Verrouillez chaque endpoint — même ceux « internes » :
- Validez les entrées à la frontière (types, plages, enums autorisés, tailles maximales) et rejetez les champs inconnus.
- Ajoutez du rate limiting par utilisateur/token pour éviter que des clients bruyants saturent l'ingestion ou les dashboards.
- Utilisez des requêtes paramétrées et des patterns ORM sûrs pour éviter les injections.
Secrets et contrôle d'accès
Gardez les credentials hors du code et des logs.
Stockez les secrets dans un gestionnaire de secrets et faites‑les tourner. Donnez à l'app un accès DB au moindre privilège : rôles lecture/écriture séparés, restreindre l'accès aux seules tables nécessaires et utiliser des credentials short‑lived si possible. Chiffrez les données en transit (TLS) entre navigateur↔app et app↔base.
Garde‑fous qualité des données
Les métriques de fiabilité ne sont utiles que si les événements sous‑jacents sont fiables.
Ajoutez des vérifications serveur sur les timestamps (décalage/clock skew), champs requis et clés d'idempotence pour dédupliquer les retries. Suivez les erreurs d'ingestion dans une dead‑letter queue ou une table de « quarantaine » pour que les événements corrompus n'empoisonnent pas les dashboards.
Bases opérationnelles (à ne pas sauter)
Automatisez les migrations DB et testez les rollbacks. Planifiez des backups, restaurez‑les régulièrement en test, et documentez un plan de reprise minimal (qui, quoi, combien de temps).
Enfin, rendez l'application elle‑même fiable : ajoutez des health checks, du monitoring de lag de queue et de latence DB, et alertez quand l'ingestion tombe silencieusement à zéro.
Plan de déploiement et feuille de route d'itération
Une application de suivi de fiabilité réussit quand les gens lui font confiance et l'utilisent réellement. Traitez la première release comme une boucle d'apprentissage, pas comme un lancement « big bang ».
Commencer par un pilote ciblé
Choisissez 2–3 outils internes largement utilisés et avec des propriétaires clairs. Implémentez un petit ensemble de checks (par ex. : disponibilité de la page d'accueil, succès de login, endpoint API clé) et publiez un tableau répondant : « Est‑ce que c'est up ? Si non, qu'est‑ce qui a changé et qui en est responsable ? »
Gardez le pilote visible mais contenu : une équipe ou un petit groupe d'utilisateurs avancés suffit pour valider le flux.
Recueillir le feedback là où ça fait mal
Pendant les 1–2 premières semaines, collectez activement du feedback sur :
- Ce qui est confus (noms de métriques, graphiques, filtres, définitions)
- Ce qui est bruyant (alertes sans impact utilisateur)
- Ce qui manque (propriété, runbooks, liens vers incidents)
Transformez le feedback en éléments concrets de backlog. Un simple bouton « Signaler un problème sur cette métrique » sur chaque graphique fait souvent remonter les insights les plus rapides.
Itérer avec intégrations et automatisation
Ajoutez de la valeur par couches : connectez votre outil de chat pour les notifications, puis votre outil d'incident pour la création automatique de tickets, puis le CI/CD pour les marqueurs de déploiement. Chaque intégration doit réduire le travail manuel ou raccourcir le temps de diagnostic — sinon ce n'est que de la complexité.
Si vous prototypez rapidement, envisagez le mode planning de Koder.ai pour cartographier le périmètre initial (entités, rôles, workflows) avant de générer la première build. C'est un moyen simple de garder le MVP serré — et comme vous pouvez snapshotter et rollback, vous pouvez itérer sur les tableaux et l'ingestion en sécurité au fur et à mesure que les équipes affinent les définitions.
Définir les métriques de succès et étendre
Avant d'étendre à d'autres équipes, définissez des métriques de succès comme utilisateurs hebdomadaires sur le dashboard, réduction du temps de détection, moins d'alertes en double ou revues SLO régulières. Publiez une feuille de route légère dans /blog/reliability-tracking-roadmap et étendez outil par outil avec des propriétaires clairs et des sessions de formation.