Quel problème l’application résout (et qui l’utilise)
Une hypothèse commerciale est une croyance sur laquelle votre équipe agit avant qu’elle ne soit pleinement prouvée. Elle peut porter sur :
- Marché : « Ce segment croît suffisamment vite pour soutenir notre produit. »
- Client : « Les utilisateurs passeront des tableurs si l’installation prend moins de 10 minutes. »
- Tarification : « Les équipes paieront 49 $/mois pour cet ensemble de fonctionnalités. »
- Opérations : « Le support peut gérer l’onboarding avec une seule personne. »
- Risques : « Cette approche n’entraînera pas de problèmes de conformité. »
Ces hypothèses apparaissent partout — pitch decks, discussions de feuille de route, appels commerciaux, conversations informelles — puis disparaissent souvent sans trace.
Pourquoi les équipes perdent les hypothèses
La plupart du temps, les équipes ne perdent pas les hypothèses parce qu’elles s’en fichent. Elles les perdent parce que la documentation diverge, les gens changent de rôle et le savoir devient tribal. La « vérité la plus récente » finit dispersée entre un doc, un fil Slack, quelques tickets et la mémoire de quelqu’un.
Quand cela arrive, les équipes répètent les mêmes débats, relancent les mêmes expérimentations ou prennent des décisions sans réaliser ce qui reste non prouvé.
Résultats visés
Une application simple de suivi des hypothèses vous apporte :
- Clarté : ce que vous croyez, ce qui est prouvé et ce qui reste en attente
- Responsabilité : qui est propriétaire de chaque hypothèse et quand elle a été revue pour la dernière fois
- Apprentissage accéléré : boucles plus courtes entre hypothèses, expériences et preuves
- Moins de ré-litiges : un enregistrement partagé qui réduit les conversations circulaires
Qui l’utilise (et quelle taille doit-elle avoir)
Chefs de produit, fondateurs, équipes growth, chercheurs et responsables commerciaux en bénéficient — en fait, toute personne qui prend des paris. Commencez par un « journal d’hypothèses » léger, facile à tenir à jour, puis étendez les fonctionnalités seulement si l’usage l’exige.
Définir le modèle de données principal
Avant de concevoir les écrans ou de choisir une stack technique, décidez quelles « choses » votre appli va stocker. Un modèle de données clair maintient la cohérence du produit et permet d’ajouter des rapports plus tard.
Objets principaux (restez concis)
Commencez par cinq objets qui correspondent à la manière dont les équipes valident des idées :
- Hypothèse : l’affirmation que vous croyez vraie (jusqu’à preuve du contraire)
- Preuve : liens, notes, fichiers ou métriques qui soutiennent ou affaiblissent une hypothèse
- Expérience : un test structuré (entretien, sondage, A/B test, prototype) qui génère des preuves
- Revue : un point de contrôle périodique où quelqu’un confirme le statut/confiance actuel
- Commentaire : discussion légère liée à une hypothèse (et optionnellement à une preuve/expérience)
Champs recommandés pour une Hypothèse
Un enregistrement Hypothèse doit être rapide à créer, mais suffisamment riche pour être actionnable :
- Énoncé (obligatoire) : une phrase testable et unique
- Catégorie (obligatoire) : ex. client, problème, tarification, canal, faisabilité
- Responsable (obligatoire) : qui va la faire avancer
- Confiance (obligatoire) : faible/moyenne/élevée (ou 1–5)
- Statut (obligatoire) : brouillon, actif, validé, invalidé, archivé
Ajoutez des horodatages pour que l’app puisse piloter les workflows de revue :
- Créé le, Dernière mise à jour (générés par le système)
- Dernière revue, Prochaine date de revue (éditables ou dérivés)
Relations
Modélisez le flux de validation :
- Une Hypothèse → plusieurs Preuves
- Une Hypothèse → plusieurs Expériences
- Une Hypothèse → plusieurs Revues et Commentaires
Obligatoire vs optionnel (réduire la friction)
Ne rendez obligatoires que l’essentiel : énoncé, catégorie, responsable, confiance, statut. Laissez des détails comme les tags, l’impact et les liens en option pour que les gens puissent journaliser rapidement les hypothèses — et les enrichir ensuite au fil des preuves.
Définir statut, confiance et règles de revue
Si votre journal d’hypothèses doit rester utile, chaque entrée doit avoir une signification claire d’un coup d’œil : où elle en est dans son cycle de vie, à quel point vous y croyez, et quand elle doit être vérifiée. Ces règles empêchent aussi les équipes de traiter discrètement des suppositions comme des faits.
Un cycle de vie simple et cohérent
Utilisez un flux de statut unique pour chaque hypothèse :
Brouillon → Actif → Validé / Invalidé → Archivé
- Brouillon : capturée, mais pas encore acceptée comme digne de suivi.
- Actif : l’équipe s’appuie dessus (ou pourrait s’appuyer) et a l’intention de la tester ou de la surveiller.
- Validé : les preuves atteignent votre critère minimal (défini ci‑dessous).
- Invalidé : les preuves la contredisent clairement ; conservez-la pour apprendre.
- Archivé : plus pertinente (le produit a changé, le marché a évolué, la stratégie a bougé).
Score de confiance (1–5)
Choisissez une échelle 1–5 et définissez-la en langage clair :
- Spéculation (aucune preuve)
- Signal faible (une donnée)
- Un certain soutien (plusieurs signaux, des lacunes persistent)
- Soutien fort (preuves cohérentes, faible doute)
- Très fort (résultats reproductibles, stabilité dans le temps)
Faites en sorte que la « confiance » porte sur la solidité des preuves — pas sur le désir que ce soit vrai.
Impact décisionnel : quoi valider en priorité
Ajoutez Impact de la décision : Faible / Moyen / Élevé. Les hypothèses à fort impact doivent être testées en priorité car elles influencent la tarification, le positionnement, le go‑to‑market ou de grosses décisions de développement.
Définir ce que « validé » signifie
Rédigez des critères explicites par hypothèse : quel résultat comptera, et quelle preuve minimale est requise (par ex. 30+ réponses d’enquête, 10+ appels commerciaux avec un motif cohérent, A/B test avec un indicateur de succès prédéfini, 3 semaines de données de rétention).
Règles de révision et de réexamen
Fixez des déclencheurs automatiques de revue :
- Revoir les hypothèses à fort impact toutes les 2–4 semaines
- Revoir lorsqu’un indicateur clé change (conversion, churn, CAC)
- Revoir après des changements majeurs de produit ou de marché
Ainsi, « validé » n’évolue pas en « vrai pour toujours ».
Concevoir l’expérience utilisateur et les écrans clés
Une appli de suivi d’hypothèses réussit lorsqu’elle est plus rapide qu’un tableur. Concevez autour des actions répétées chaque semaine : ajouter une hypothèse, mettre à jour ce que vous croyez, joindre ce que vous avez appris et programmer la prochaine date de revue.
Flux principaux (en un clic)
Visez une boucle serrée :
- Créer une hypothèse : partir d’un modèle (Problème, Client, Tarification, Canal) avec des valeurs par défaut sensées.
- Mettre à jour le statut : passer rapidement entre Brouillon → Actif → Validé/Invalidé, avec une note optionnelle.
- Joindre une preuve : glisser‑déposer un fichier ou coller un lien, puis l’étiqueter pour une ou plusieurs hypothèses.
- Programmer une revue : définir la « prochaine revue » juste après tout changement, pour éviter que rien ne devienne périmé.
Écrans principaux réellement nécessaires
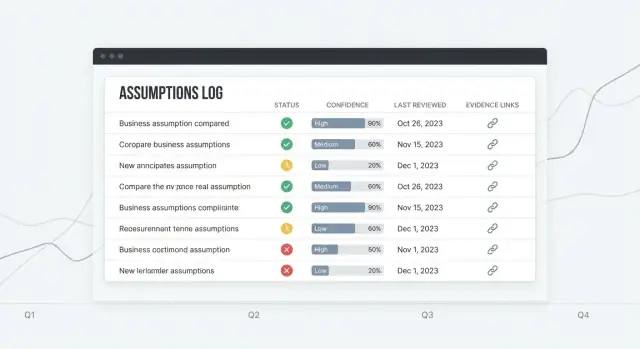
Liste d’hypothèses doit être la page d’accueil : un tableau lisible avec des colonnes claires (Statut, Confiance, Responsable, Dernière revue, Prochaine revue). Ajoutez une ligne « ajout rapide » bien visible pour que les nouveaux éléments n’exigent pas un formulaire long.
Détail d’hypothèse est l’endroit où les décisions se prennent : un court résumé en haut, puis une timeline des mises à jour (changements de statut, de confiance, commentaires) et un panneau Preuves dédié.
Bibliothèque de preuves aide à réutiliser l’apprentissage : rechercher par tag, source et date, puis lier une preuve à plusieurs hypothèses.
Tableau de bord doit répondre à : « Qu’est‑ce qui nécessite de l’attention ? » Montrez les revues à venir, les hypothèses récemment modifiées et les items à fort impact avec faible confiance.
Filtrage, recherche et contrôle du bruit
Rendez les filtres persistants et rapides : catégorie, responsable, statut, confiance, date de dernière revue. Réduisez le bruit via des modèles, des valeurs par défaut et la divulgation progressive (les champs avancés sont cachés tant qu’on n’en a pas besoin).
Principes d’accessibilité de base
Utilisez un texte à fort contraste, des labels clairs et des contrôles utilisables au clavier. Les tableaux doivent supporter la focalisation sur une ligne, des en‑têtes triables et des espacements lisibles — surtout pour les badges de statut et de confiance.
Choisir une stack technique pragmatique
Une application de suivi d’hypothèses est majoritairement composée de formulaires, filtres, recherche et d’un journal d’audit. Bonne nouvelle : vous pouvez livrer de la valeur avec une stack simple et consacrer votre énergie au workflow (règles de revue, preuves, décisions) plutôt qu’à l’infrastructure.
Une stack simple qui marche
Une configuration courante et pratique :
- Frontend : React, souvent via Next.js (UI rapide, routage, rendu côté serveur quand utile)
- Backend : Node.js (Express/Nest) ou Python (FastAPI/Django)
- Base de données : Postgres
Si votre équipe maîtrise déjà l’un de ces outils, choisissez‑le — la cohérence vaut mieux que la nouveauté.
Si vous voulez prototyper rapidement sans tout câbler à la main, une plateforme de type « vibe‑coding » comme Koder.ai peut vous mener à un outil interne fonctionnel vite : décrivez votre modèle de données et vos écrans en chat, itérez en Planning Mode, et générez une UI React avec un backend prêt pour la production (Go + PostgreSQL) que vous pouvez exporter en code source plus tard si vous décidez de le maintenir vous‑même.
Pourquoi Postgres est un bon choix
Postgres gère bien la nature « connectée » de la gestion d’hypothèses : les hypothèses appartiennent à des workspaces, ont des responsables, se lient à des preuves et se rapportent à des expériences. Une base relationnelle maintient ces liens fiables.
Elle est aussi facile à indexer pour les requêtes fréquentes (par statut, confiance, à relire, tag, responsable) et ami de l’audit quand vous ajoutez un historique de versions et des journaux de modification. Vous pouvez stocker les événements de changement dans une table séparée et les interroger pour les rapports.
Garder l’hébergement et l’ops légers
Visez des services managés :
- Postgres managé (sauvegardes automatiques, mises à jour, réplicas en lecture plus tard)
- Hébergement d’app pour Next.js et votre API (ou une application Next.js full‑stack)
Cela réduit le risque que « maintenir en marche » vous prenne la semaine.
Si vous ne voulez pas gérer l’infra au début, Koder.ai peut aussi s’occuper du déploiement et de l’hébergement, avec des commodités comme domaines personnalisés et snapshots/rollback pendant que vous peaufinez les workflows avec de vrais utilisateurs.
Approche API : REST d’abord
Commencez par des endpoints REST pour le CRUD, la recherche et les flux d’activité. C’est simple à déboguer et documenter. Envisagez GraphQL seulement si vous avez vraiment besoin de requêtes client complexes sur de nombreux objets liés.
Environnements clairs
Prévoyez trois environnements dès le départ :
- Local (machines de développement)
- Staging (lieu sûr pour tester imports, notifications et permissions)
- Production (données réelles, accès stricts, monitoring)
Cette configuration soutient le suivi des hypothèses sans sur‑architecturer votre application.
Implémenter l’authentification, les rôles et les workspaces
Prototypez les écrans clés
Prototypez les écrans principaux — liste, détail, bibliothèque de preuves, tableau de bord — en un seul endroit.
Si votre journal est partagé, le contrôle d’accès doit être fiable et sans surprise. Les gens doivent savoir exactement qui peut voir, éditer ou approuver des changements — sans freiner l’équipe.
Authentification : simple au départ, SSO plus tard
Pour la plupart des équipes, email + mot de passe suffit pour livrer et apprendre. Ajoutez SSO Google ou Microsoft lorsque vous ciblez des organisations plus grandes, des politiques IT strictes ou des intégrations fréquentes. Si vous supportez les deux, laissez les admins choisir par workspace.
Gardez la surface de connexion minimale : inscription, connexion, réinitialisation de mot de passe et (optionnel) MFA forcé plus tard.
Rôles et permissions (Admin / Éditeur / Lecteur)
Définissez les rôles une fois et appliquez‑les uniformément :
- Admin : gère les paramètres du workspace, les membres, les rôles et les intégrations ; peut supprimer des enregistrements (ou demander suppression).
- Éditeur : crée et modifie des hypothèses, joint des preuves, enregistre des expérimentations et change statut/confiance.
- Lecteur : accès en lecture seule aux hypothèses, preuves, résultats d’expériences et tableaux de bord.
Faites les vérifications de permission côté serveur (pas seulement dans l’UI). Si vous ajoutez un jour un flux d’« approbation », traitez‑le comme une permission plutôt que comme un nouveau rôle.
Workspaces : séparer équipes, produits et clients
Un workspace est la frontière pour les données et les membres. Chaque hypothèse, preuve et expérience appartient à exactement un workspace, de sorte que les agences, les entreprises multi‑produits ou les startups avec plusieurs initiatives restent organisées et évitent le partage accidentel.
Invitations, offboarding et audit minimal
Utilisez des invitations par e‑mail avec une fenêtre d’expiration. Lors d’un offboarding, retirez l’accès mais conservez l’historique : les modifications passées doivent toujours afficher l’acteur d’origine.
Au minimum, stockez une piste d’audit : qui a changé quoi et quand (ID utilisateur, horodatage, objet et action). Cela renforce la confiance, la responsabilité et facilite le debug quand des décisions sont remises en question.
Construire le CRUD avec historique de versions et journaux de modifications
Le CRUD est l’endroit où votre application cesse d’être un document et devient un système. L’objectif n’est pas seulement de créer et modifier des hypothèses — c’est rendre chaque changement compréhensible et réversible.
Endpoints CRUD et actions UI
Au minimum, supportez ces actions pour hypothèses et preuves :
- Créer, voir, éditer, archiver (soft‑delete) et restaurer des hypothèses
- Joindre des preuves (liens, fichiers, notes) et éditer leurs métadonnées
- Changer de statut (par ex. Brouillon → Actif → Validé/Invalidé)
Dans l’UI, gardez ces actions proches de la page de détail : un bouton clair « Éditer », un « Changer le statut » dédié et une action « Archiver » volontairement plus difficile à cliquer.
Versioning : révisions vs journal append‑only
Deux stratégies pratiques :
-
Stocker des révisions complètes (un snapshot par sauvegarde). Restaurer une version précédente est simple.
-
Journal append‑only (flux d’événements). Chaque édition écrit un événement comme « énoncé modifié », « confiance changée », « preuve attachée ». C’est excellent pour l’audit mais demande plus de travail pour reconstruire d’anciens états.
Beaucoup d’équipes adoptent un hybride : snapshots pour les modifications majeures + événements pour les petites actions.
Rendre l’historique lisible (pas seulement stocké)
Fournissez une timeline sur chaque hypothèse :
- Qui a changé quoi, quand
- Une vue diff pour les champs textuels (énoncé, critère de succès)
- Un bouton Restaurer la version précédente sur les versions antérieures (avec confirmation)
Exigez une courte note « pourquoi » sur les modifications significatives (changement de statut/confiance, archivage). Considérez‑la comme un journal de décision léger : ce qui a changé, quelle preuve a déclenché le changement et ce que vous ferez ensuite.
Prévenir les modifications accidentelles
Ajoutez des confirmations pour les actions destructrices :
- Changements de statut qui clôturent une hypothèse
- Archivage
- Restauration d’une ancienne version (prévenir que cela crée une nouvelle révision)
Cela préserve la fiabilité de l’historique même quand les gens vont vite.
Joindre des preuves et suivre les expérimentations
Les hypothèses deviennent dangereuses lorsqu’elles semblent « vraies » sans preuves auxquelles pointer. Votre appli doit permettre de joindre des preuves et d’exécuter des expériences légères pour que chaque assertion ait une trace.
Preuves : quoi stocker (sans tout casser)
Supportez les types de preuves courants : notes d’entretien, résultats d’enquête, métriques produit ou revenu, documents (PDF, slides) et liens simples (dashboards analytiques, tickets support).
Quand quelqu’un joint une preuve, capturez un petit ensemble de métadonnées pour qu’elle reste exploitable des mois plus tard :
- Source (nom du client, dataset, outil ou propriétaire du document)
- Date de collecte (et optionnellement date d’upload)
- Méthode (entretien, test d’utilisabilité, A/B test, recherche documentaire, etc.)
- Note / force de la preuve (voir ci‑dessous)
Pour éviter les doublons, modélisez la preuve comme une entité séparée et reliez‑la aux hypothèses en many‑to‑many : une note d’entretien peut soutenir trois hypothèses, et une hypothèse peut avoir dix preuves. Stockez le fichier une fois (ou uniquement le lien), puis rattachez‑le où nécessaire.
Ajoutez un objet Expérience facile à remplir :
- Hypothèse (ce que vous attendez et pourquoi)
- Méthode (ce que vous ferez)
- Métrique clé (le nombre que vous surveillerez)
- Résultat (ce qui est arrivé)
- Conclusion (conserver, modifier ou abandonner l’hypothèse)
Liez les expériences aux hypothèses qu’elles testent et, si possible, joignez automatiquement les preuves générées (graphiques, notes, captures de métriques).
Force de la preuve : guide pour éviter la fausse certitude
Utilisez un simple rubriquage (par ex. Faible / Modérée / Forte) avec des infobulles :
- Faible : opinions, anecdote unique, lien non vérifié
- Modérée : plusieurs entretiens, signal cohérent d’un sondage, tendance métrique précoce
- Forte : résultats répétables selon les segments, impact métrique clair, expérience contrôlée
Le but n’est pas la perfection, mais rendre la confiance explicite pour qu’on ne prenne pas de décisions sur des impressions.
Ajouter des rappels et des workflows de revue
Remplacez le processus basé sur un tableur
Transformez vos modèles et filtres en une application utilisable qui surpasse un tableur pour les mises à jour hebdomadaires.
Les hypothèses se périment silencieusement. Un workflow de revue simple maintient l’utilité du journal en transformant « on devrait revoir ça » en habitude prévisible.
Cadence de revue adaptée au risque
Reliez la fréquence de revue à l’impact et à la confiance pour ne pas traiter chaque hypothèse de la même manière :
- Hebdomadaire : fort impact + faible confiance (ex. tarif principal, canal d’acquisition majeur)
- Mensuel : fort impact + confiance moyenne, ou impact moyen + faible confiance
- Trimestriel (optionnel) : faible impact + confiance élevée
Stockez la prochaine date de revue sur l’hypothèse et recalculer automatiquement quand impact/confiance changent.
Rappels sans spam
Supportez email et notifications in‑app. Gardez des valeurs par défaut conservatrices : un rappel à l’échéance, puis un relance légère.
Rendez les notifications configurables par utilisateur et par workspace :
- préférences de canal (email/in‑app)
- fréquence des rappels (quotidien/hebdomadaire)
- heures calmes / fuseau horaire
- désactivation pour les items à faible impact
Vues digest qui poussent à l’action
Plutôt que d’envoyer une longue liste, créez des digests ciblés :
- À réviser (en retard ou proche de la date)
- Fort impact + faible confiance (risques prioritaires)
- Modifications récentes (hypothèses éditées, confiance en baisse, preuves supprimées)
Ces filtres doivent être des filtres de première classe dans l’UI pour que la même logique alimente le tableau de bord et les notifications.
Règles d’escalade simples
L’escalade doit être prévisible et légère :
- Notifier le responsable quand c’est en retard.
- Si toujours en retard après X jours, notifier le chef d’équipe (ou l’admin du workspace).
Consignez chaque rappel et escalade dans l’historique d’activité de l’hypothèse pour voir ce qui s’est passé et quand.
Créer des tableaux de bord et des rapports
Les tableaux de bord transforment votre journal d’hypothèses en quelque chose que les équipes consultent réellement. L’objectif n’est pas des analyses sophistiquées, mais une visibilité rapide sur ce qui est risqué, périmé ou en mutation.
Indicateurs clés qui répondent à « Sommes‑nous en sécurité ? »
Commencez par un petit ensemble de tuiles qui se mettent à jour automatiquement :
- Hypothèses par statut (Brouillon, Actif, Validé, Invalidé, Archivé)
- Distribution de la confiance (combien sont 1–5, ou Faible/Moyenne/Élevée)
- Revues en retard (nombre + lien direct vers la liste des retardataires)
Associez chaque KPI à une vue cliquable pour que les gens puissent agir, pas seulement observer.
Graphiques de tendance (utiles, mais honnêtes)
Un simple graphique linéaire montrant validations vs invalidations dans le temps aide à voir si l’apprentissage s’accélère ou stagne. Restez prudent :
- Traitez les tendances comme des signaux, pas comme des preuves définitives.
- Affichez la taille de l’échantillon (ex. « 8 résultats ce mois ») pour qu’une seule semaine ne ressemble pas à une percée.
Vues enregistrées pour parties prenantes différentes
Les rôles posent des questions différentes. Fournissez des filtres enregistrés comme :
- Produit : hypothèses liées à la découverte active, regroupées par domaine produit
- Sales/CS : hypothèses sur la tarification, les objections, les segments cibles
- Direction : items à plus fort impact, principaux risques, santé des revues
Les vues enregistrées doivent être partageables via une URL stable (ex. /assumptions?view=leadership-risk).
Mettre en évidence le risque : fort impact + preuves faibles
Créez un tableau « Radar de risque » qui affiche les items où Impact = Élevé mais Force de la preuve = Faible (ou confiance faible). Cela devient votre ordre du jour pour la planification et les pré‑mortems.
Résumés exportables pour les réunions
Rendez les rapports portables :
- Export en PDF/CSV d’une vue en un clic
- Un « Résumé hebdomadaire d’hypothèses » listant : changements majeurs, nouvelles invalidations et revues en retard
Cela maintient l’application présente dans la planification sans forcer chacun à se connecter pendant la réunion.
Supporter les imports, exports et intégrations
Déployez et itérez en toute sécurité
Déployez un outil interne avec hébergement, domaines personnalisés et retours en arrière simples pendant vos itérations.
Une appli de suivi ne marche que si elle s’intègre aux habitudes des équipes. Les imports/exports facilitent un démarrage rapide et la possession des données, tandis que des intégrations légères réduisent les copiages manuels — sans transformer votre MVP en plateforme d’intégration.
Exports utiles
Commencez par un export CSV pour trois tables : hypothèses, preuves/expériences, et journaux de modifications. Gardez des colonnes prévisibles (IDs, énoncé, statut, confiance, tags, responsable, dernière revue, horodatages).
Ajoutez des commodités UX :
- Exporter la vue actuelle (filtres appliqués) et l’espace de travail complet
- Permettre d’inclure ou non les éléments archivés
- Inclure un ID Hypothèse stable pour fusionner des feuilles de calcul plus tard
Importer depuis des tableurs (sans douleur)
La plupart des équipes commencent avec un Google Sheet désordonné. Fournissez un flux d’import qui supporte :
- Upload CSV
- Mappage des colonnes (ex. « Hypothesis » → Énoncé, « Risk » → Impact)
- Validation avec erreurs claires (champs obligatoires manquants, statuts inconnus, dates invalides)
- Un aperçu montrant combien d’hypothèses seront créées vs mises à jour
Considérez l’import comme une fonctionnalité de première classe : c’est souvent le moyen le plus rapide d’obtenir l’adoption. Documentez le format attendu et les règles dans /help/assumptions.
Intégrations optionnelles : simples, pas infinies
Gardez les intégrations optionnelles pour que le cœur reste simple. Deux patterns pratiques :
- Webhooks : émettre des événements comme
assumption.created, status.changed, review.overdue.
- Liens externes : stocker des URL pour tickets Jira, docs Notion ou dossiers de recherche comme « Liens associés » sur une hypothèse.
Pour une valeur immédiate, proposez une intégration Slack basique (via webhook) qui poste quand une hypothèse à fort impact change de statut ou quand des revues sont en retard. Cela donne de la visibilité sans forcer le changement d’outil.
Couvrir la sécurité, la confidentialité et les bases de protection des données
La sécurité et la confidentialité sont des fonctionnalités produit pour un journal d’hypothèses. Les gens y collent des liens, des notes d’appels et des décisions internes — concevez donc pour être « sûr par défaut », même en version initiale.
Principes basiques de protection des données
Utilisez TLS partout (HTTPS uniquement). Redirigez HTTP vers HTTPS et configurez des cookies sécurisés (HttpOnly, Secure, SameSite).
Stockez les mots de passe avec un algorithme moderne comme Argon2id (préféré) ou bcrypt avec un facteur de coût élevé. Ne stockez jamais de mots de passe en clair et ne loggez pas les tokens d’authentification.
Appliquez le principe du moindre privilège :
- Rôles séparés (admin, éditeur, lecteur) et vérifications sur chaque action en écriture
- Clés API limitées pour les intégrations et possibilité de révocation
- Credentials DB restreints pour que l’app ne puisse accéder qu’aux tables nécessaires
Règles d’accès au niveau des lignes (workspaces)
La plupart des fuites dans les apps multi‑tenant proviennent de bugs d’autorisation. Faites de l’isolation des workspaces une règle de base :
- Chaque enregistrement (hypothèse, preuve, expérience, commentaire) doit inclure
workspace_id.
- Faites respecter l’accès au niveau base (row‑level security) ou des politiques équivalentes, pas seulement dans le code applicatif.
- Dans les tests, créez deux workspaces et vérifiez qu’un utilisateur du workspace A ne peut pas lire, chercher, exporter ou deviner des IDs du workspace B.
Sauvegardes et rétention (ce que vous mettrez en place)
Définissez un plan simple exécutable :
- Sauvegardes journalières automatisées stockées ailleurs
- Politique de rétention (ex. : conserver 30 jours de sauvegardes journalières et 12 mois de sauvegardes mensuelles)
- Exercice de restauration trimestriel : restaurer en staging et valider les flux clés
Logs et gestion des données sensibles
Soyez délibéré sur ce qui est stocké. Évitez de placer des secrets dans les notes de preuve (API keys, mots de passe, liens privés). Si les utilisateurs peuvent les coller, ajoutez des avertissements et envisagez une redaction automatique de motifs courants.
Limitez les logs : ne loggez pas le corps complet des requêtes pour les endpoints acceptant des notes ou des pièces jointes. Si vous avez besoin de diagnostics, loggez des métadonnées (workspace ID, record ID, codes d’erreur) à la place.
Confidentialité pour les notes d’entretien
Les notes d’entretien peuvent contenir des données personnelles. Fournissez un moyen de :
- Marquer des champs comme « contient des données personnelles » et restreindre qui peut les voir
- Supprimer ou anonymiser les notes sur demande
- Documenter ce que vous stockez et pourquoi via une courte note de confidentialité (lien depuis
/settings ou /help)
Lancer, surveiller et planifier l’itération suivante
Livrer une application d’hypothèses, c’est moins « terminé » que « mise en production dans des workflows réels en sécurité », puis apprendre de l’usage.
Checklist de déploiement pratique
Avant d’ouvrir l’accès aux utilisateurs, exécutez une checklist répétable :
- Appliquer les migrations DB (et vérifier qu’elles sont réversibles)
- Charger des données seed (statuts, niveaux de confiance, cadences de revue)
- Créer le premier compte admin et un workspace par défaut
- Confirmer les paramètres d’email/notifications pour les rappels de revue
- Activer les sauvegardes basiques et vérifier une restauration
Si vous avez un environnement staging, pratiquez la release d’abord là — surtout pour tout ce qui touche à l’historique de versions et aux journaux.
Commencez simplement : visibilité sans semaines de configuration.
Utilisez un tracker d’erreurs (ex. Sentry/Rollbar) pour capturer crashes, appels API échoués et erreurs de jobs en arrière‑plan. Ajoutez un monitoring de performance basique (APM ou métriques serveur) pour repérer les pages lentes comme le tableau de bord et les rapports.
Tests qui protègent les règles centrales
Concentrez les tests là où les erreurs coûtent cher :
- Tests unitaires pour les transitions de statut, les règles de confiance et la planification des revues
- Tests d’intégration pour les flux principaux : créer une hypothèse → joindre une preuve → enregistrer une expérience → changer de statut → voir la piste d’audit
Onboarding qui fait « cliquer » l’app
Fournissez des modèles et des hypothèses d’exemple pour que les nouveaux utilisateurs n’aient pas un écran vide. Un court tour guidé (3–5 étapes) doit mettre en évidence : où ajouter des preuves, comment fonctionnent les revues et comment lire le journal de décision.
Planifier l’itération suivante
Après le lancement, priorisez les améliorations selon le comportement réel :
- Modèles de scoring (impact × incertitude, ou formules de confiance personnalisées)
- Flux d’approbation pour les changements à haut risque
- Résumés assistés par IA des preuves et des résultats d’expériences
Si vous itérez rapidement, pensez à des outils qui réduisent le délai entre « on devrait ajouter ce workflow » et « c’est en production ». Par exemple, des équipes utilisent Koder.ai pour esquisser de nouveaux écrans et changements backend depuis un brief en chat, puis s’appuient sur snapshots et rollback pour déployer des expérimentations en sécurité — et exporter le code quand la direction produit est claire.