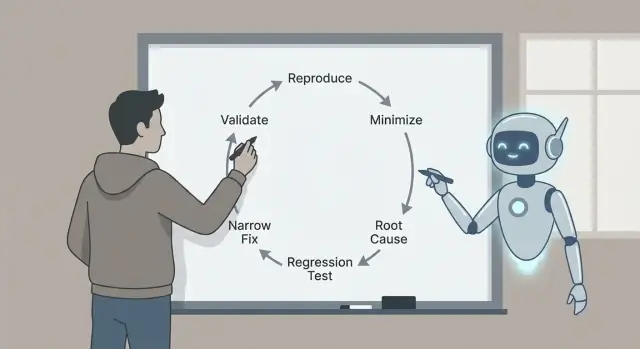
Ce qu’est le tri de bugs et pourquoi la boucle compte
Les bugs paraissent aléatoires quand chaque rapport devient une énigme unique. Vous fouillez dans le code, essayez quelques idées, et espérez que le problème disparaisse. Parfois ça marche, mais on n’apprend pas grand‑chose, et le même souci réapparaît sous une autre forme.
Le tri de bugs est l’inverse. C’est un moyen rapide de réduire l’incertitude. L’objectif n’est pas de tout corriger sur le champ. L’objectif est de transformer une plainte vague en une affirmation claire et testable, puis de faire le plus petit changement qui prouve que l’affirmation est fausse.
C’est pour ça que la boucle importe : reproduire, minimiser, identifier des causes probables avec des preuves, ajouter un test de régression, implémenter une correction ciblée et valider. Chaque étape enlève un type précis d’hypothèse. Sauter des étapes vous coûte souvent plus tard, avec des correctifs plus larges, des effets de bord, ou des « corrections » qui n’étaient pas vraiment des corrections.
Voici un exemple réaliste. Un utilisateur dit : « Le bouton Enregistrer ne fait parfois rien. » Sans boucle, vous pourriez fouiller le code UI et changer des timings, l’état ou des appels réseau. Avec la boucle, vous commencez par transformer « parfois » en « à chaque fois, dans ces conditions exactes », par exemple : « Après avoir modifié un titre, puis changé d’onglet rapidement, Enregistrer reste désactivé. » Cette phrase seule est déjà un progrès.
Claude Code peut accélérer la partie réflexion : transformer les rapports en hypothèses précises, suggérer où regarder, et proposer un test minimal qui devrait échouer. Il est particulièrement utile pour scanner le code, les logs et les diffs récents afin de générer rapidement des explications plausibles.
Vous devez néanmoins vérifier ce qui importe. Confirmez que le bug est réel dans votre environnement. Privilégiez les preuves (logs, traces, tests qui échouent) plutôt qu’une histoire convaincante. Gardez la correction aussi petite que possible, prouvez‑la avec un test de régression, et validez avec des contrôles clairs pour ne pas échanger un bug contre un autre.
Le gain est une correction petite et sûre que vous pouvez expliquer, défendre et empêcher de régresser.
Préparez l’espace de tri (avant de toucher au code)
Les bonnes corrections commencent avec un espace propre et une seule problématique claire. Avant de demander quoi que ce soit à Claude, choisissez un rapport et réécrivez‑le ainsi :
« Quand je fais X, j’attends Y, mais j’obtiens Z. »
Si vous ne pouvez pas écrire cette phrase, ce n’est pas encore un bug. C’est un mystère.
Rassemblez les informations de base dès le départ pour ne pas tourner en rond. Ces détails rendent les suggestions testables plutôt que vagues : version de l’app ou commit (et si c’est local, staging ou production), détails d’environnement (OS, navigateur/appareil, flags de fonctionnalité, région), entrées exactes (champs de formulaire, payload API, actions utilisateur), qui voit le problème (tout le monde, un rôle, un compte/tenant unique), et ce que « attendu » signifie (texte, état UI, code de statut, règle métier).
Puis conservez les preuves tant qu’elles sont fraîches. Un simple horodatage peut vous faire gagner des heures. Capturez les logs autour de l’événement (client et serveur si possible), une capture d’écran ou un court enregistrement, les IDs de requête ou de trace, les horodatages exacts (avec fuseau), et le plus petit extrait de données qui déclenche le souci.
Exemple : une app React générée par Koder.ai affiche « Payment succeeded » mais la commande reste « Pending ». Notez le rôle de l’utilisateur, l’ID de commande exact, le corps de la réponse API et les lignes de log serveur pour cet ID de requête. Vous pouvez alors demander à Claude de se concentrer sur un seul flux au lieu de gesticuler.
Enfin, définissez une règle d’arrêt. Décidez ce qui comptera comme corrigé avant de commencer à coder : un test précis qui passe, un état UI qui change, une erreur qui n’apparaît plus dans les logs, plus une courte checklist de validation que vous exécuterez à chaque fois. Cela évite de « corriger » le symptôme et d’expédier un nouveau bug.
Un rapport brouillon mélange souvent faits, suppositions et frustration. Avant de demander de l’aide, convertissez‑le en une question nette que Claude peut répondre avec des preuves.
Commencez par un résumé en une phrase qui nomme la fonctionnalité et la défaillance. Bon : « La sauvegarde d’un brouillon supprime parfois le titre sur mobile. » Pas bon : « Les brouillons sont cassés. » Cette phrase devient l’ancre du fil de tri.
Séparez ensuite ce que vous avez vu de ce que vous attendiez. Restez terne et concret : le bouton exact que vous avez cliqué, le message affiché, la ligne de log, l’horodatage, l’appareil, le navigateur, la branche, le commit. Si vous n’avez pas ces éléments, dites‑le.
Une structure simple à coller :
- Résumé (une phrase)
- Comportement observé (ce qui s’est passé, y compris les erreurs)
- Comportement attendu (ce qui devrait se produire)
- Étapes de repro (numérotées, le plus petit jeu d’actions connu)
- Environnement (version/appareil/OS/navigateur/flags)
Si des détails manquent, demandez‑les sous forme de questions oui/non pour que les gens répondent vite : Ça se produit sur un compte neuf ? Seulement sur mobile ? Seulement après un rafraîchissement ? Ça a commencé après la dernière release ? Reproduit en navigation privée ?
Claude est aussi utile comme « nettoyeur de rapports ». Collez le rapport original (y compris le texte copié depuis des captures d’écran, logs et discussions), puis demandez :
« Réécris ceci comme une checklist structurée. Signale les contradictions. Liste les 5 faits manquants en questions oui/non. Ne suppose pas de causes. »
Si un collègue dit « Ça échoue aléatoirement », poussez‑le vers quelque chose de testable : « Échoue 2/10 fois sur iPhone 14, iOS 17.2, quand on tape Enregistrer deux fois rapidement. » Vous pouvez alors le reproduire volontairement.
Étape 1 - Reproduire le bug de façon fiable
Si vous ne pouvez pas déclencher le bug à la demande, chaque étape suivante est de la supposition.
Commencez par le reproduire dans l’environnement le plus petit qui montre encore le problème : build local, branche minimale, petit jeu de données, et le moins de services activés possible.
Notez les étapes exactes pour que quelqu’un d’autre puisse les suivre sans poser de questions. Rendez‑les collables : commandes, IDs, payloads d’exemple doivent être inclus tels quels.
Un modèle simple de capture :
- Setup : branche/commit, flags de config, état de la base (vide, seedé, copie prod)
- Étapes : actions numérotées avec inputs exacts
- Attendu vs réel : ce que vous pensiez qui se passerait et ce qui s’est passé
- Preuves : texte d’erreur, captures, horodatages, IDs de requête
- Fréquence : toujours, parfois, seulement au premier essai, seulement après un rafraîchissement
La fréquence change votre stratégie. Les bugs « toujours » sont parfaits pour itérer vite. Les bugs « parfois » pointent souvent vers la temporisation, le caching, des conditions de course ou un état caché.
Quand vous avez des notes de repro, demandez à Claude des sondes rapides qui réduisent l’incertitude sans réécrire l’app. De bonnes sondes sont petites : une ligne de log ciblée autour de la frontière qui échoue (inputs, outputs, état clé), un flag de débogage pour un composant, un moyen de forcer un comportement déterministe (seed fixe, temps fixé, worker unique), un petit dataset qui déclenche le problème, ou une seule paire requête/réponse à rejouer.
Exemple : le flux d’inscription échoue « parfois ». Claude pourrait suggérer de logger l’ID utilisateur généré, le résultat de la normalisation d’email, et les détails d’erreur de contrainte d’unicité, puis de relancer la même payload 10 fois. Si l’échec n’a lieu qu’au premier essai après un déploiement, c’est un indice fort pour vérifier les migrations, le warmup du cache ou des données manquantes.
Étape 2 - Minimiser vers un petit cas de test répétable
Déboguez en toute sécurité avec des snapshots
Expérimentez librement, puis revenez en arrière rapidement si une correction dérape.
Une bonne reproduction est utile. Une reproduction minimale est puissante. Elle rend le bug plus rapide à comprendre, plus facile à déboguer et moins susceptible d’être « corrigé » par accident.
Éliminez tout ce qui n’est pas nécessaire. Si le bug survient après un long flux UI, trouvez le chemin le plus court qui le déclenche. Retirez les écrans optionnels, les flags de fonctionnalité et les intégrations non liées jusqu’à ce que le bug disparaisse (vous avez enlevé quelque chose d’essentiel) ou reste (vous avez trouvé le bruit).
Puis réduisez les données. Si le bug nécessite un payload large, testez le plus petit payload qui casse encore. Si la faille nécessite une liste de 500 éléments, voyez si 5 échouent, puis 2, puis 1. Retirez les champs un par un. L’objectif est le moins de pièces mobiles possible qui reproduisent encore le bug.
Une méthode pratique est « retirer la moitié et retester » :
- Coupez les étapes en deux et vérifiez si le bug survient encore.
- Si oui, gardez la moitié restante et recoupez.
- Si non, restaurez la moitié de ce que vous avez retiré et re‑coupez.
- Répétez jusqu’à ne plus pouvoir enlever quoi que ce soit sans perdre le bug.
Exemple : une page de checkout plante « parfois » lors de l’application d’un coupon. Vous découvrez que ça n’échoue que lorsque le panier contient au moins un article soldé, que le coupon comporte des lettres minuscules, et que la livraison est sur « retrait ». Voilà votre cas minimal : un article soldé, un coupon en minuscules, une option retrait.
Quand le cas minimal est clair, demandez à Claude de le transformer en un petit scaffold de reproduction : un test minimal qui appelle la fonction en faute avec les inputs les plus petits, un script court qui frappe un endpoint avec un payload réduit, ou un petit test UI qui visite une route et effectue une seule action.
Étape 3 - Identifier les causes probables (avec preuves)
Quand vous pouvez reproduire le problème et que vous avez un petit cas de test, arrêtez de deviner. L’objectif est d’aboutir à une courte liste de causes plausibles, puis de prouver ou réfuter chacune.
Une règle utile est de limiter à trois hypothèses. Si vous en avez plus, votre cas est probablement encore trop grand ou vos observations trop vagues.
Cartographier les symptômes vers les composants
Traduisiez ce que vous voyez en où cela peut se produire. Un symptôme UI n’est pas toujours un bug UI.
Exemple : une page React affiche un toast « Saved », mais l’enregistrement est manquant ensuite. Ça peut pointer vers (1) l’état UI, (2) le comportement API, ou (3) le chemin d’écriture en base.
Construire des preuves pour chaque hypothèse
Demandez à Claude d’expliquer les modes d’échec probables en langage simple, puis demandez quelle preuve confirmerait chacun. L’objectif est de transformer « peut‑être » en « vérifiez ceci précisément ».
Trois hypothèses courantes et les preuves à collecter :
- Décalage UI/état : le client met à jour l’état local avant que le serveur confirme. Preuve : capture d’un snapshot d’état avant et après l’action, comparé à la réponse API réelle.
- Cas limite API : le handler retourne 200 mais ignore silencieusement une opération (validation, parsing d’ID, flag de fonctionnalité). Preuve : logs requête/réponse avec IDs de corrélation, et vérification que le handler atteint l’appel d’écriture avec les inputs attendus.
- Problème de base/timing : une transaction est rollbackée, une erreur de conflit survient, ou un « read after write » provient d’un cache/réplica. Preuve : inspecter la requête DB, les lignes affectées et les codes d’erreur ; logger les frontières de transaction et le comportement de retry.
Gardez vos notes serrées : symptôme, hypothèse, preuve, verdict. Quand une hypothèse colle aux faits, vous êtes prêt à verrouiller un test de régression et à corriger seulement ce qui est nécessaire.
Étape 4 - Ajouter un test de régression qui échoue pour la bonne raison
Un bon test de régression est votre ceinture de sécurité. Il prouve que le bug existe et qu’il vous alertera si la régression revient.
Commencez par choisir le plus petit test qui reflète la défaillance réelle. Si le bug n’apparaît que quand plusieurs parties interagissent, un test unitaire peut le manquer.
Choisir le niveau de test adapté
Utilisez un test unitaire quand une fonction renvoie la mauvaise valeur. Utilisez un test d’intégration quand la frontière entre parties est en cause (handler API + base, UI + état). Utilisez end‑to‑end seulement si le bug dépend du flux complet.
Avant de demander à Claude d’écrire quoi que ce soit, reformulez le cas minimisé en un comportement strict attendu. Exemple : « Quand l’utilisateur sauvegarde un titre vide, l’API doit retourner 400 avec le message ‘title required’. » Le test a alors une cible claire.
Demandez ensuite à Claude de rédiger un test qui échoue d’abord. Gardez la configuration minimale et ne copiez que les données qui déclenchent le bug. Nommez le test d’après l’expérience utilisateur, pas la fonction interne.
Vérifier l’ébauche (ne lui faites pas aveuglément confiance)
Faites une passe rapide :
- Confirmez qu’il échoue sur le code actuel pour la raison prévue (et pas pour un fixture manquant ou un import erroné).
- Vérifiez que les assertions sont spécifiques (code de statut exact, message, texte rendu).
- Assurez‑vous que le test couvre un seul bug, pas un paquet de comportements.
- Gardez un nom centré utilisateur, par exemple « rejette un titre vide à l’enregistrement » plutôt que « gère la validation ».
Quand le test échoue pour la bonne raison, vous pouvez implémenter une correction ciblée en confiance.
Étape 5 - Implémenter une correction ciblée
Créez une app prête pour la reproduction
Générez une app React et itérez sur des scénarios échouants sans lourde configuration.
Avec un petit repro et un test de régression qui échoue, résistez à l’envie de « tout nettoyer ». L’objectif est d’arrêter le bug avec le plus petit changement possible qui rend le test vert pour la bonne raison.
Une bonne correction ciblée modifie la surface la plus petite possible. Si la défaillance est dans une fonction, corrigez cette fonction, pas tout le module. Si une vérification de frontière manque, ajoutez‑la à la frontière, pas sur toute la chaîne d’appels.
Si vous utilisez Claude pour aider, demandez deux options de correction, puis comparez‑les en termes d’étendue et de risque. Exemple : si un formulaire React plante quand un champ est vide, vous pourriez avoir :
- Option A : Ajouter une garde dans le handler de soumission qui bloque l’entrée vide et affiche une erreur.
- Option B : Refactoriser la gestion d’état pour que le champ ne puisse jamais être vide.
L’option A est généralement le choix de triage : plus petite, plus simple à relire et moins susceptible de casser autre chose.
Pour garder la correction étroite, touchez le moins de fichiers possible, privilégiez des corrections locales plutôt que des refactors, ajoutez des gardes et validations là où la mauvaise valeur entre, et gardez le changement de comportement explicite avec un avant/après clair. Laissez des commentaires seulement quand la raison n’est pas évidente.
Exemple concret : un endpoint Go panique quand un paramètre de query optionnel est manquant. La correction ciblée est de gérer la chaîne vide à la frontière du handler (parser avec une valeur par défaut, ou retourner 400 avec un message clair). Évitez de changer des utilitaires partagés à moins que le test de régression montre que le bug se trouve dans ce code partagé.
Après le changement, relancez le test qui échouait et un ou deux tests proches. Si votre correction oblige à mettre à jour beaucoup de tests non liés, c’est un signe que le changement est trop large.
Étape 6 - Valider la correction avec des contrôles clairs
La validation permet de choper les petits problèmes faciles à manquer : une correction qui passe un test mais casse un chemin voisin, change un message d’erreur, ou ajoute une requête lente.
D’abord, relancez le test de régression que vous avez ajouté. S’il passe, exécutez les voisins les plus proches : tests dans le même fichier, le même module, et tout ce qui couvre les mêmes inputs. Les bugs se cachent souvent dans des helpers partagés, du parsing, des vérifications de frontière ou du caching, donc les échecs pertinents apparaissent généralement à proximité.
Ensuite, faites une vérification manuelle rapide en utilisant les étapes du rapport original. Restez court et précis : même environnement, mêmes données, même séquence de clics ou d’appels API. Si le rapport était vague, testez le scénario exact que vous avez utilisé pour le reproduire.
Une checklist simple de validation
- Le test de régression passe, plus les tests voisins dans la même zone.
- Les étapes manuelles de repro ne déclenchent plus le bug.
- Le traitement des erreurs reste cohérent (messages, codes, retries).
- Les cas limites se comportent toujours (entrée vide, tailles max, caractères étranges).
- Pas d’impact de performance évident (boucles supplémentaires, appels en plus, requêtes lentes).
Si vous voulez rester concentré, demandez à Claude un plan de validation court basé sur votre changement et le scénario qui échouait. Indiquez le fichier modifié, le comportement attendu, et ce qui pourrait être affecté. Les meilleurs plans sont courts et exécutables : 5 à 8 contrôles que vous pouvez finir en quelques minutes, chacun avec un résultat clair pass/échoué.
Enfin, consignez ce que vous avez validé dans la PR ou les notes : quels tests vous avez lancés, quelles étapes manuelles vous avez essayées, et les limites (par exemple « mobile non testé »). Cela rend la correction plus digne de confiance et plus simple à revoir plus tard.
Testez les corrections côté serveur
Prototypez des flux Go + PostgreSQL et reproduisez des cas limites d'API avec moins de friction.
La façon la plus rapide de perdre du temps est d’accepter une « correction » avant de pouvoir reproduire le problème à la demande. Si vous ne pouvez pas le faire échouer de façon fiable, vous ne saurez pas ce qui s’est réellement amélioré.
Une règle pratique : ne demandez pas de corrections tant que vous ne pouvez pas décrire un setup reproductible (étapes exactes, inputs, environnement et ce qui est « faux »). Si le rapport est vague, passez vos premières minutes à le transformer en une checklist exécutable deux fois avec le même résultat.
Pièges qui vous ralentissent
Corriger sans cas reproductible. Exigez un script minimal qui « échoue à chaque fois » ou un ensemble d’étapes. Si c’est « parfois », capturez le timing, la taille des données, les flags, et les logs jusqu’à ce que ce ne soit plus aléatoire.
Minimiser trop tôt. Si vous réduisez le cas avant d’avoir confirmé l’échec original, vous pouvez perdre le signal. Verrouillez d’abord la reproduction de base, puis réduisez‑la une modification à la fois.
Laisser Claude deviner. Claude peut proposer des causes probables, mais il vous faut toujours des preuves. Demandez 2 à 3 hypothèses et les observations exactes qui confirment ou infirment chacune (une ligne de log, un breakpoint, un résultat de requête).
Tests de régression qui passent pour la mauvaise raison. Un test peut « passer » parce qu’il n’atteint jamais le chemin défaillant. Assurez‑vous qu’il échoue avant la correction, et qu’il échoue avec le message ou l’assertion attendue.
Traiter les symptômes plutôt que le déclencheur. Si vous ajoutez une vérification null mais que le vrai problème est « cette valeur ne devrait jamais être nulle », vous risquez de masquer un bug plus profond. Préférez corriger la condition qui crée l’état invalide.
Un petit contrôle de sanity avant de déclarer le bug clos
Exécutez le nouveau test de régression et les étapes de repro originales avant et après votre changement. Si un bug de checkout n’apparaît que quand un code promo est appliqué après avoir changé l’expédition, gardez cette séquence complète comme votre « vérité », même si votre cas minimisé est plus petit.
Si votre validation dépend d’un « ça a l’air bon maintenant », ajoutez une vérification concrète (un log, une métrique ou une sortie spécifique) pour que la prochaine personne puisse vérifier rapidement.
Une checklist rapide, des modèles de prompt et les suites possibles
Quand vous êtes pressé, une petite boucle répétable bat le débogage héroïque.
Checklist de tri sur une page
- Reproduire : obtenir un repro fiable et noter inputs, environnement, attendu vs réel.
- Minimiser : réduire aux étapes ou au test le plus petit qui échoue encore.
- Expliquer : lister 2 à 3 causes probables et les preuves attendues pour chacune.
- Verrouiller : ajouter un test de régression qui échoue pour la bonne raison.
- Corriger + valider : faire le changement le plus étroit, puis exécuter une courte checklist de validation.
Écrivez la décision finale en quelques lignes pour que la prochaine personne (souvent le vous du futur) puisse s’y fier. Un format utile : « Cause racine : X. Déclencheur : Y. Correction : Z. Pourquoi sûr : W. Ce que nous n’avons pas modifié : Q. »
Modèles de prompt à coller
- « Given this bug report and logs, ask me only the missing questions needed to reproduce it reliably. »
- « Help me minimize: propose a smaller test case and tell me what to remove first, one change at a time. »
- « Rank likely root causes and cite the exact files, functions, or conditions that support each claim. »
- « Write a regression test that fails only because of this bug. Explain why it fails for the right reason. »
- « Suggest the narrowest fix, plus a validation checklist (unit, integration, and manual checks) that proves we didn’t break nearby behavior. »
Étapes suivantes : automatisez ce que vous pouvez (un script de repro sauvegardé, une commande de test standard, un template pour les notes de root cause).
Si vous construisez des apps avec Koder.ai (koder.ai), Planning Mode peut vous aider à esquisser la modification avant de toucher au code, et les snapshots/rollback facilitent l’expérimentation en toute sécurité pendant que vous travaillez sur un repro difficile. Une fois la correction validée, vous pouvez exporter le code source ou déployer et héberger l’app mise à jour, y compris via un domaine personnalisé si nécessaire.