Ce que signifie une seule base de code générée par l'IA
« Une seule base de code » ne veut pas dire une seule interface qui tourne partout. En pratique, cela signifie plutôt un seul dépôt et un ensemble de règles partagées — avec des surfaces de livraison séparées (application web, application mobile, API) qui dépendent toutes des mêmes décisions métier sous-jacentes.
Logique partagée vs UI partagée
Un modèle mental utile est de partager les parties qui ne doivent jamais diverger :
- Règles du domaine : calculs, contrôles d'éligibilité, tarification, workflows, invariants.
- Cas d'utilisation : « créer une commande », « annuler un abonnement », « émettre un remboursement », etc.
- Contrats de données : formes des requêtes/réponses, règles de validation, codes d'erreur.
Pendant ce temps, vous ne partagez généralement pas la couche UI en bloc. Le web et le mobile ont des patterns de navigation, des attentes d'accessibilité, des contraintes de performance et des capacités de plateforme différentes. Partager l'UI peut être un avantage dans certains cas, mais ce n'est pas la définition d'« une seule base de code ».
Ce que l'IA change (et ce qu'elle ne change pas)
Le code généré par l'IA peut accélérer énormément :
- la création de l'ossature du projet (répertoires, scripts de build, composants basiques)
- la génération d'endpoints CRUD et de clients
- la création de tests et de fixtures à partir d'exemples
Mais l'IA ne produit pas automatiquement une architecture cohérente. Sans frontières claires, elle a tendance à dupliquer la logique entre applications, mélanger les responsabilités (UI appelant directement le code de la base de données) et créer des validations « presque identiques » à plusieurs endroits. Le levier vient de la définition de la structure d'abord — puis d'utiliser l'IA pour remplir les parties répétitives.
Résultats visés
Une base de code assistée par l'IA est réussie quand elle apporte :
- Cohérence : le web, le mobile et l'API appliquent les mêmes règles.
- Vitesse : les nouvelles fonctionnalités sont implémentées une fois, puis exposées partout.
- Maintenabilité : les changements sont localisés, relus, testés et publiés de manière prévisible.
Objectifs et contraintes pour la livraison web, mobile et API
Une seule base de code fonctionne uniquement si vous savez clairement ce qu'elle doit accomplir — et ce qu'elle ne doit pas standardiser. Le web, le mobile et les API servent des audiences et des usages différents, même s'ils partagent les mêmes règles métier.
La plupart des produits ont au moins trois « portes d'entrée » :
- Utilisateurs web (clients, admins, équipes support) qui attendent une navigation rapide, de l'accessibilité et des mises à jour faciles.
- Utilisateurs mobiles qui attendent des interactions natives, une tolérance à la connectivité intermittente et une utilisation efficace de la batterie/réseau.
- Intégrations tierces (partenaires, systèmes internes, outils d'automatisation) qui comptent sur des APIs stables, des contrats clairs et une gestion d'erreur prédictible.
L'objectif est la cohérence du comportement (règles, permissions, calculs) — pas des expériences identiques.
Non-objectifs : ne forcez pas une UX identique
Un échec courant consiste à traiter « base de code unique » comme « UI unique ». Cela produit souvent une app mobile à l'allure web ou une app web à l'allure mobile — les deux frustrantes.
Visez plutôt :
- une logique domaine et une validation partagées
- des modèles de données et des contrats d'API partagés
- une conception de présentation et d'interaction spécifique à chaque plateforme
Contraintes clés à concevoir tôt
Mode hors-ligne : le mobile a souvent besoin d'accès en lecture (et parfois en écriture) sans réseau. Cela implique un stockage local, des stratégies de synchronisation, la gestion des conflits et des règles claires sur la « source de vérité ».
Performance : le web se soucie de la taille des bundles et du time-to-interactive ; le mobile du temps de démarrage et de l'efficacité réseau ; les APIs de la latence et du débit. Partager du code ne doit pas signifier livrer des modules inutiles à chaque client.
Sécurité et conformité : authentification, autorisation, journaux d'audit, chiffrement et rétention des données doivent être cohérents sur toutes les surfaces. Si vous opérez dans des secteurs régulés, intégrez dès le départ des exigences comme la journalisation, le consentement et le principe du moindre privilège — pas des rustines.
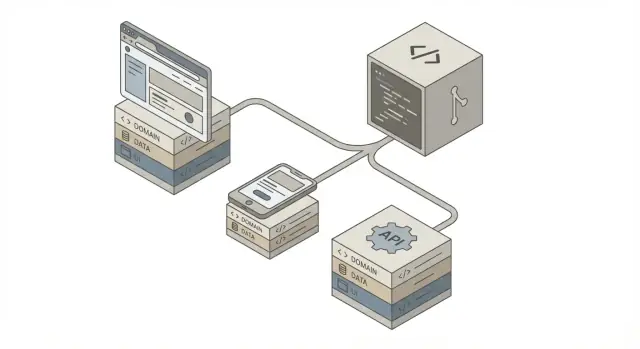
Architecture de référence : couches et responsabilités
Une seule base de code fonctionne mieux lorsqu'elle est organisée en couches claires avec des responsabilités strictes. Cette structure rend aussi le code généré par l'IA plus facile à relire, tester et remplacer sans casser des parties non liées.
Flux haut niveau
Voici la forme basique sur laquelle la plupart des équipes convergent :
Clients (Web / Mobile / Partners)
↓
API Layer
↓
Domain Layer
↓
Data Sources (DB / Cache / External APIs)
L'idée principale : les interfaces utilisateur et les détails de transport se situent aux bords, tandis que les règles métier restent au centre.
Ce qui est partagé
Le « noyau partageable » regroupe tout ce qui doit se comporter de la même façon partout :
- Domaine (logique métier) : règles de tarification, contrôles d'éligibilité, transitions d'état de commande, etc.
- Validation : règles d'entrée et messages d'erreur mappés à des codes d'erreur cohérents.
- Réseau + schémas : types de requête/réponse, sérialisation et tests de contrat.
Quand l'IA génère de nouvelles fonctionnalités, le meilleur résultat est : elle met à jour les règles du domaine une seule fois, et tous les clients en bénéficient automatiquement.
Ce qui doit rester différent
Certain code est coûteux (ou risqué) à forcer dans une abstraction partagée :
- Composants UI : design systems web vs contrôles natifs.
- Navigation et flux utilisateur : routage navigateur vs stacks mobiles.
- Capacités device : notifications push, biométrie, appareil photo, stockage hors-ligne.
Règle pratique : si l'utilisateur peut voir quelque chose ou si le système d'exploitation peut casser un comportement, gardez-le spécifique à l'application. Si c'est une décision métier, laissez-la dans le domaine.
Responsabilités par couche
- Couche API : authentification, limites de débit, mappage HTTP/GraphQL vers commandes domaine.
- Couche domaine : règles pures et cas d'utilisation, dépendances minimales.
- Sources de données : bases et services tiers derrière des interfaces pour pouvoir changer d'implémentation sans réécrire la logique métier.
Couche domaine partagée (logique métier)
La couche domaine partagée est la partie qui devrait sembler « ennuyeuse » au meilleur sens : prédictible, testable et réutilisable partout. Si l'IA aide à générer votre système, cette couche est l'ancre du projet — pour que les écrans web, les flux mobiles et les endpoints API reflètent les mêmes règles.
Commencez par les noms et verbes
Définissez les concepts centraux de votre produit comme des entités (choses avec une identité dans le temps, comme Account, Order, Subscription) et des value objects (choses définies par leur valeur, comme Money, EmailAddress, DateRange). Ensuite capturez le comportement comme des cas d'utilisation (parfois appelés services d'application) : « Create order », « Cancel subscription », « Change email ».
Cette structure rend le domaine compréhensible pour des non-spécialistes : les noms décrivent ce qui existe, les verbes décrivent ce que le système fait.
Garder les règles métier agnostiques à l'UI
La logique métier ne doit pas savoir si elle est déclenchée par un tap, un submit de formulaire web ou une requête API. Concrètement, cela signifie :
- Pas d'imports de frameworks (pas de contrôleurs web, de vues mobile ou d'annotations ORM dans le code domaine)
- Pas de chaînes UI (les codes d'erreur ou clés sont préférables aux messages en dur)
- Pas d'hypothèses réseau (le domaine ne doit pas « appeler l'API » ; il doit exprimer des règles)
Quand l'IA génère du code, cette séparation est facile à perdre — les modèles intègrent des préoccupations UI. Traitez cela comme un déclencheur de refactor, pas comme une préférence.
Un seul ensemble de règles de validation partout
La validation est souvent le point de dérive : le web permet quelque chose que l'API rejette, ou le mobile valide différemment. Placez la validation cohérente dans la couche domaine (ou un module de validation partagé) afin que toutes les surfaces appliquent les mêmes règles.
Exemples :
EmailAddress valide le format une fois, réutilisé sur web/mobile/APIMoney empêche les totaux négatifs, peu importe l'origine de la valeur- Les cas d'utilisation appliquent les règles multi-champs (ex. « la date de fin doit être après la date de début »)
Si vous réussissez cela, la couche API devient un traducteur et le web/mobile deviennent des présentateurs — tandis que la couche domaine reste la source unique de vérité.
Couche API : des contrats qui pilotent tout le reste
La couche API est le « visage public » de votre système — et dans une base de code unique assistée par l'IA, elle doit ancrer tout le reste. Si le contrat est clair, l'app web, l'app mobile et même les services internes peuvent être générés et validés à partir de la même source de vérité.
Commencez par un contrat API-first
Définissez le contrat avant de générer des handlers ou du wiring UI :
- Endpoints et ressources : noms cohérents (ex.
/users, /orders/{id}), filtrage et tri prévisibles.
- Erreurs : forme d'erreur stable (code, message, details), avec usage documenté des statuts HTTP.
- Pagination : choisissez une approche (la pagination par curseur est souvent la plus évolutive) et standardisez les champs de réponse.
- Versioning : choisissez tôt (chemin
/v1/... ou header) et documentez les règles de dépréciation.
Générez types et clients depuis un seul schéma
Utilisez OpenAPI (ou un outil schema-first comme GraphQL SDL) comme artefact canonique. À partir de là, générez :
- stubs serveur (routes, scaffolding de validation)
- clients typés pour le web et le mobile
- modèles requête/réponse partagés qui réduisent la dérive
Ceci est important pour le code généré par l'IA : le modèle peut produire beaucoup de code rapidement, mais le schéma le maintient aligné.
Règles de cohérence qui évitent des régressions subtiles
Fixez quelques non-négociables :
- Nommage :
snake_case ou camelCase, pas les deux ; concordance entre JSON et types générés.
- Codes de statut : 200/201/204 pour le succès, 400 pour validation, 401/403 pour auth, 409 pour conflits.
- Idempotence : exiger une
Idempotency-Key pour les opérations risquées (paiements, création de commande) et définir le comportement de retry.
Traitez le contrat d'API comme un produit. Quand il est stable, tout le reste devient plus facile à générer, tester et livrer.
Application web : intégrer la logique partagée sans couplage
Livrez plus vite après génération
Passez du code généré à une application en fonctionnement avec déploiement, hébergement et domaines personnalisés.
Une app web tire grand profit de la logique métier partagée — et souffre quand cette logique est emmêlée avec les préoccupations UI. L'idée clé est de considérer la couche domaine partagée comme un moteur « headless » : il connaît les règles, validations et workflows, mais rien sur les composants, routes ou APIs du navigateur.
Choix de rendu : SSR vs CSR (et pourquoi cela compte)
Si vous utilisez SSR (server-side rendering), le code partagé doit être sûr à exécuter côté serveur : pas d'accès direct à window, document ou au stockage navigateur. C'est une bonne contrainte : garder les comportements dépendants du navigateur dans une couche adaptatrice web mince.
Avec CSR (client-side rendering), vous avez plus de liberté, mais la même discipline est payante. Les projets CSR-only importent souvent par accident du code UI dans des modules domaine parce que tout s'exécute dans le navigateur — jusqu'au jour où vous ajoutez du SSR, du rendu edge ou des tests qui tournent en Node.
Règle pratique : les modules partagés doivent être déterministes et agnostiques à l'environnement ; tout ce qui touche cookies, localStorage ou l'URL appartient à la couche web.
Frontières d'état : état domaine vs état UI
La logique partagée peut exposer état domaine (par ex. totaux de commande, éligibilité, flags dérivés) via des objets purs et fonctions pures. L'app web doit posséder l'état UI : spinners de chargement, focus de formulaire, animations optimistes, visibilité des modaux.
Cela rend la gestion d'état (React/Vue) flexible : vous pouvez changer de librairie sans réécrire les règles métier.
Préoccupations web à isoler
La couche web doit gérer :
- Accessibilité (balises sémantiques, navigation clavier, ARIA)
- Routage (structure d'URL, deep links, redirections serveur)
- Stockage navigateur (cookies/session,
localStorage, cache)
Considérez l'app web comme un adaptateur qui traduit les interactions utilisateur en commandes domaine — et traduit les résultats domaine en écrans accessibles.
Application mobile : logique partagée avec capacités natives
Une app mobile profite surtout d'une couche domaine partagée : les règles de tarification, d'éligibilité, de validation et les workflows doivent se comporter comme sur le web et l'API. L'UI mobile devient alors une « coquille » autour de cette logique partagée — optimisée pour le tactile, la connectivité intermittente et les fonctionnalités device.
Même avec une logique partagée, le mobile a des patterns rarement transposables 1:1 depuis le web :
- Navigation : modélisez l'état de navigation dans la couche app (écrans, onglets, modaux), tout en gardant les décisions domaine (ex. « l'utilisateur doit vérifier son e‑mail avant le paiement") dans le code partagé.
- Tâches en arrière-plan : traitez le sync, les uploads et les rafraîchissements comme des jobs explicites avec limites de temps et reprise.
- Notifications push : parsez le payload dans la couche app, puis déléguez à la logique partagée la décision de l'action suivante.
- Deep links : routez les liens dans la couche app, mais utilisez le code partagé pour valider permissions et récupérer les données nécessaires.
Offline-first : cache, sync et stratégie de conflit
Si vous attendez un usage mobile réel, supposez le hors-ligne :
- mettez en cache les modèles de lecture localement (key-value ou SQLite) avec une politique claire de staleness.
- mettez les écritures en file comme intentions/événements (ex. « créer un brouillon de commande »), puis synchronisez à la connexion.
- définissez les règles de conflit dès le départ (last-write-wins, fusion côté serveur ou résolution par l'utilisateur).
- implémentez des retries avec backoff et des clés d'idempotence pour que l'API accepte les doublons en toute sécurité.
Préoccupations mobiles spécifiques
- Taille de l'app : gardez la couche partagée modulaire pour n'expédier que ce dont l'app a besoin.
- Batterie/données : batcher les appels réseau et éviter un polling agressif.
- Permissions : demandez-les uniquement quand nécessaire (caméra, localisation, contacts), et gardez les vérifications de permission hors du code domaine pour que les politiques puissent varier par plateforme.
Modèles de données, auth et permissions sur toutes les surfaces
Mettez en place une base de code unifiée
Lancez une configuration type monorepo avec des modules de domaine partagés et des shells web et mobile séparés.
Une « base de code unique » se casse rapidement si votre web, mobile et API inventent chacun leurs propres formes de données et règles de sécurité. La solution est de traiter modèles, authentification et autorisation comme des décisions produit partagées, puis de les encoder une fois.
Une source de vérité pour les modèles de données
Choisissez un endroit unique où vivent les modèles, et faites dériver tout le reste de là. Options courantes :
- Schema-first : définir entités et règles de validation dans des fichiers de schéma (OpenAPI/JSON Schema), puis générer des types pour l'API, le web et le mobile.
- Modules partagés : garder les types de modèle et validateurs dans un paquet partagé (souvent le paquet « domaine ») que toutes les apps importent.
- Hybride : fichiers de schéma pour les contrats externes, modules partagés pour les règles interne du domaine.
L'important n'est pas l'outil mais la cohérence. Si OrderStatus a cinq valeurs dans un client et six dans un autre, le code généré par l'IA compilera et livrera quand même des bugs.
Authentification : sessions, tokens et stockage sécurisé
L'authentification doit être conceptuellement identique pour l'utilisateur, mais la mécanique diffère selon la surface :
- Web : souvent sessions via cookies (bonnes protections CSRF, stockage simple côté navigateur).
- Mobile et clients tiers : authentification par tokens (access token + refresh token).
Concevez un flux unique : login → accès courte durée → refresh si besoin → logout qui invalide l'état côté serveur. Sur mobile, stockez les secrets dans un stockage sécurisé (Keychain/Keystore), pas dans des préférences simples. Sur le web, privilégiez les cookies httpOnly pour que les tokens ne soient pas exposés au JavaScript.
Autorisation : règles centrales, appliquées à l'API
Les permissions doivent être définies une fois — idéalement proches des règles métier — puis appliquées partout :
- Centralisez les vérifications dans la couche domaine (ex.
canApproveInvoice(user, invoice)).
- Faites-les respecter dans l'API pour la sécurité réelle.
- Miroitez-les dans l'UI uniquement pour masquer/désactiver des actions, pas pour protéger les données.
Cela évite le glissement « marche sur mobile mais pas sur le web » et donne à la génération IA un contrat clair et testable sur qui peut faire quoi.
Stratégie de build, release et déploiement
Une base de code unifiée reste unie uniquement si les builds et les releases sont prévisibles. L'objectif est de permettre aux équipes de publier l'API, le web et le mobile indépendamment — sans forcer des forks de logique ni des cas spécifiques d'environnement.
Monorepo vs multi-repo
Un monorepo (un seul repo, plusieurs paquets/apps) fonctionne souvent mieux pour une base de code unique parce que la logique domaine partagée, les contrats d'API et les clients UI évoluent ensemble. Vous obtenez des changements atomiques (une PR met à jour un contrat et tous les consommateurs) et des refactors plus simples.
Un multi-repo peut aussi être uni, mais vous paierez le prix de la coordination : versioning des paquets partagés, publication d'artéfacts et synchronisation des changements cassants. Choisissez le multi-repo uniquement si les frontières organisationnelles, les règles de sécurité ou l'échelle rendent le monorepo impraticable.
Cibles de build et artéfacts
Traitez chaque surface comme une cible de build séparée qui consomme des paquets partagés :
- Artefact service API : image conteneur ou bundle serverless issu du package API.
- Bundle web : assets statiques + runtime serveur (si SSR) issu du package web.
- Builds mobile : Android (AAB/APK) et iOS (IPA) produits par des pipelines natifs, mais important la logique partagée en dépendance.
Gardez les sorties de build explicites et reproductibles (lockfiles, toolchains figés, builds déterministes).
Pipeline CI/CD et séparation des environnements
Un pipeline typique : lint → typecheck → tests unitaires → tests de contrat → build → scan sécurité → déploiement.
Séparez la config du code : variables d'environnement et secrets résident dans votre CI/CD et gestionnaire de secrets, pas dans le repo. Utilisez des overlays par environnement (dev/stage/prod) pour que le même artefact puisse être promu entre environnements sans rebuild — particulièrement pour l'API et le runtime web.
Tests et portes qualité pour le code partagé
Quand le web, le mobile et l'API proviennent du même repo, les tests cessent d'être « une case de plus » et deviennent le mécanisme qui empêche un petit changement de casser trois produits à la fois. L'objectif est simple : détecter les problèmes là où ils coûtent le moins, et bloquer les changements risqués avant qu'ils n'atteignent les utilisateurs.
Une pyramide de tests pratique pour une base de code partagée
Commencez par le domaine partagé (votre logique métier) car c'est la partie la plus réutilisée et la plus facile à tester sans infra lente.
- Tests unitaires (couche domaine) : valider les règles comme tarification, éligibilité, décisions d'autorisation, transitions d'état et cas limites. Ils doivent être rapides et constituer la majorité de la suite.
- Tests d'intégration (couche API) : prouver que l'API fonctionne bout à bout avec sérialisation réelle, validation, authentification et accès aux données. Concentrez-les sur les flux critiques plutôt que sur tous les cas.
- Tests UI (par client) : un petit nombre de vérifications à haute valeur pour le web et le mobile confirmant les parcours clés (connexion, checkout, soumission de formulaire) dans l'UI réelle. Ils sont lents, considérez-les comme des « alarmes » plutôt que des preuves exhaustives.
Cette structure place la confiance principalement dans la logique partagée, tout en attrapant les problèmes d'assemblage entre couches.
Tests de contrat pour garder clients et API alignés
Même en monorepo, l'API peut changer d'une manière qui compile mais casse l'expérience utilisateur. Les tests de contrat préviennent la dérive silencieuse.
- Contrats API-client : verrouillez les formes requête/réponse, les formats d'erreur et les codes de statut. Si l'API renvoie un champ requis nouveau ou change une valeur d'enum, les tests de contrat échouent avant la merge.
- Schéma comme porte : si vous publiez des schémas OpenAPI/GraphQL, traitez les changements de schéma comme des artefacts révisables. Les changements cassants doivent nécessiter une approbation explicite et un plan de migration.
Portes qualité qui protègent les releases
Les bons tests sont importants, mais aussi les règles autour d'eux :
- Gates de PR : exiger tests unitaires + d'intégration passés, lint/formatage et couverture minimale sur la couche domaine.
- Feature flags : livrer du code en toute sécurité en cachant le comportement inachevé derrière des flags activables par environnement ou groupe d'utilisateurs.
- Déploiements progressifs : publier d'abord aux utilisateurs internes, puis à un petit pourcentage du trafic production, puis à tout le monde.
- Plan de rollback : faites du rollback un résultat de première classe — releases versionnées, migrations de BD réversibles (ou pouvant être roll-forward), et critères clairs « arrêter la ligne ».
Avec ces garde-fous, les changements assistés par l'IA peuvent être fréquents sans être fragiles.
Obtenez du code source exportable
Gardez le contrôle total avec du vrai code source que vous pouvez relire, tester et déplacer où vous voulez.
L'IA peut accélérer une base de code unique, mais uniquement si on la traite comme un junior rapide : excellente pour produire des drafts, dangereuse à fusionner sans revue. L'objectif est d'utiliser l'IA pour la vitesse tout en laissant aux humains la responsabilité de l'architecture, des contrats et de la cohérence long terme.
Où l'IA aide le plus (et reste peu risquée)
Servez-vous de l'IA pour générer des « premières versions » que vous écririez autrement mécaniquement :
- squelettes de projet (répertoires, modules boilerplate, ossatures de features)
- docs API et exemples basés sur des contrats existants
- suites de tests (unitaires autour des règles du domaine, tests de contrat pour les endpoints)
- migrations et scripts de seed
- refactors répétitifs (renommer des champs, scinder des modules), après définition du plan
Règle : laissez l'IA produire du code facile à vérifier en lecture ou par tests, pas du code qui modifie en silence la signification métier.
Garde-fous qui protègent l'architecture
La sortie IA doit être contrainte par des règles explicites, pas par des impressions. Placez ces règles là où est le code :
- Standards de code : linters/formatters, règles de nommage et contraintes comme « pas d'accès DB direct depuis l'UI ».
- Règles d'architecture : frontières de dépendance (par ex. la couche domaine ne doit pas importer API/web/mobile), appliquées via des outils ou des vérifications de build simples.
- Checklist PR : « Contrat changé ? Mettre à jour OpenAPI + types clients + tests. » « Nouvelle règle métier ? Ajouter des tests domaine. »
Si l'IA propose un raccourci qui viole les frontières, la réponse est « non », même si ça compile.
Gouvernance : rendre l'IA traçable
Le risque n'est pas seulement du mauvais code — ce sont des décisions non tracées. Conservez une piste d'audit :
- enregistrez prompts et réponses importants avec les tickets (IDs, liens PR)
- documentez les décisions architecturales (ADRs) pour les changements de contrat, modèles d'auth, ou nouveaux concepts de domaine
- exigez que les changements d'API soient explicites : versionnés, documentés et couverts par des tests de contrat
L'IA est la plus utile lorsqu'elle est reproductible : l'équipe voit pourquoi quelque chose a été généré, peut le vérifier et le régénérer en toute sécurité si les exigences évoluent.
Note outil : l'IA qui respecte les frontières
Si vous adoptez le développement assisté par l'IA à l'échelle système (web + API + mobile), la caractéristique la plus importante n'est pas la vitesse brute mais la capacité à maintenir l'alignement avec vos contrats et vos couches.
Par exemple, Koder.ai est une plateforme de « vibe-coding » qui aide les équipes à construire des applications web, serveur et mobile via une interface de chat — tout en produisant du code source réel et exportable. En pratique, c'est utile pour le workflow décrit ici : définir un contrat d'API et des règles de domaine, puis itérer rapidement sur des surfaces React, des backends Go + PostgreSQL et des apps Flutter sans perdre la possibilité de relire, tester et faire respecter les frontières architecturales. Des fonctionnalités comme le mode planification, les snapshots et le rollback s'intègrent bien au cycle « générer → vérifier → promouvoir » dans une base de code unifiée.
Quand ne pas utiliser une base de code unique (et quoi faire à la place)
Une base de code unique peut réduire la duplication, mais ce n'est pas un « meilleur choix » par défaut. Dès que le code partagé commence à forcer des UX maladroites, ralentir les releases ou masquer les différences de plateforme, vous passerez plus de temps à négocier l'architecture qu'à livrer de la valeur.
Cas où des bases séparées sont préférables
Des bases séparées (ou au moins des couches UI séparées) sont souvent justifiées lorsque :
- Les UI très personnalisées sont le produit. Si votre web et votre mobile nécessitent des modèles d'interaction fondamentalement différents (gestes, écrans hors-ligne complets, flux centrés caméra, animations complexes), l'UI partagée devient un compromis.
- Contraintes strictes de plateforme existent. Revue App Store, permissions hardware, limites d'exécution background et exigences d'accessibilité peuvent demander des implémentations spécifiques.
- Cadences de release différentes. Le mobile peut sortir mensuellement tandis que le web sort quotidiennement. Un monorepo trop couplé transforme chaque changement en événement de coordination.
Modes d'échec courants à surveiller
- Sur-partage de l'UI : « une UI pour tous » conduit à des expériences au dénominateur commun.
- Abstractions qui fuient : un module « partagé » expose encore des détails web/mobile (routage, stockage, tokens), rendant chaque consommateur fragile.
- Dérive de version : des équipes copient-collent du code partagé pour aller vite, puis les correctifs n'atterrissent que dans un seul endroit.
Checklist de décision (et alternatives)
Posez-vous ces questions avant de vous engager sur une base de code unique :
- La logique métier peut-elle être partagée proprement tout en gardant l'UI native ?
- Les équipes plateformes ont-elles besoin d'autonomie sur les outils, le calendrier de release et l'expérimentation ?
- Les APIs sont-elles suffisamment stables pour que les clients évoluent indépendamment ?
Si vous voyez des signaux d'alerte, une alternative pratique est domaine partagé + contrats API, avec web et mobile séparés. Gardez le code partagé centré sur les règles métier et la validation, et laissez chaque client gérer l'UX et les intégrations plateforme.
Si vous souhaitez de l'aide pour choisir une voie, comparez les options sur /pricing ou parcourez des patterns d'architecture apparentés sur /blog.