Qu'est-ce qui fait que la recherche dans l'app semble lente ou inutile
On dit que la recherche doit sembler instantanée, mais rarement on entend zéro milliseconde. Les utilisateurs veulent une réponse claire assez vite pour ne jamais se demander si l'app les a entendus. Si quelque chose de visible se produit en environ une seconde (mise à jour des résultats, indice de chargement, ou état "recherche" stable), la plupart restent confiants et continuent de taper.
La recherche paraît lente quand l'UI vous fait attendre en silence, ou quand elle réagit de façon désordonnée. Un backend rapide n'aide pas si la saisie saccade, la liste saute, ou les résultats se réinitialisent pendant que quelqu'un tape.
Les symptômes de recherche mauvais les plus fréquents
Quelques schémas reviennent souvent :
- Lagg de frappe : le curseur saccade parce que l'app fait trop de travail à chaque frappe.
- Scintillement : la liste se vide et se remplit en boucle, l'utilisateur perd sa place.
- Résultats obsolètes : l'UI affiche des résultats pour une requête plus ancienne parce que les réponses arrivent hors ordre.
- Correspondances erronées : le premier résultat semble aléatoire, les utilisateurs perdent confiance.
- Impasses : Pas de résultats et aucune aide, l'utilisateur ne sait pas quoi essayer ensuite.
Cela compte même avec de petits jeux de données. Avec seulement quelques centaines d'éléments, les gens utilisent toujours la recherche comme un raccourci, pas en dernier recours. Si elle semble peu fiable, ils passent au défilement, aux filtres, ou abandonnent. Les petits jeux de données vivent souvent sur mobile et appareils peu puissants, où le travail inutile à chaque frappe se remarque davantage.
Beaucoup de choses se corrigent avant d'ajouter un moteur de recherche dédié. La plupart de la rapidité et de l'utilité viennent de l'UX et du contrôle des requêtes, pas d'un indexage sophistiqué.
Rendez l'interface d'abord prévisible : gardez l'entrée réactive, évitez de vider les résultats trop tôt, et affichez un état de chargement calme seulement quand c'est nécessaire. Réduisez ensuite le travail inutile avec du debounce et de l'annulation pour ne pas lancer une recherche à chaque caractère. Ajoutez un petit cache pour que les requêtes répétées semblent immédiates (par exemple quand l'utilisateur efface un caractère). Enfin, appliquez des règles de classement simples (exact > commence par > contient) pour que les premiers résultats aient du sens.
Fixez des objectifs et des limites simples pour la version 1
Les corrections de vitesse n'aident pas si votre recherche tente de tout faire. La version 1 marche mieux quand la portée, le niveau de qualité et les limites sont explicites.
Choisissez une portée adaptée au besoin
Décidez à quoi sert la recherche. Est-ce un sélecteur rapide pour trouver un élément connu, ou un outil d'exploration de beaucoup de contenu ?
Pour la plupart des apps, rechercher quelques champs attendus suffit : titres, noms et identifiants clés. Dans un CRM, cela peut être le nom du contact, la société et l'email. La recherche full-text dans les notes peut attendre que vous voyiez la nécessité.
Définissez une pertinence "suffisante"
Vous n'avez pas besoin d'un classement parfait pour livrer. Il faut des résultats qui paraissent justes.
Utilisez des règles que vous pouvez expliquer si quelqu'un demande pourquoi un élément est apparu :
- Correspondance exacte en premier ("Alex Kim" bat "Alexandra")
- Commence par ensuite ("pro" correspond à "Project")
- Contient après ("jet" correspond à "Budget")
- Les éléments récemment utilisés ou épinglés ont un léger bonus
- En cas d'égalité, départagez par ordre alphabétique ou récence
Cette base évite les surprises et réduit le sentiment d'aléatoire.
Fixez des limites dès le départ (et montrez-les dans l'UI)
Les bornes protègent les performances et empêchent les cas limites de casser l'expérience.
Décidez tôt de choses comme un nombre maximal de résultats (souvent 20–50), une longueur maximale de requête (par exemple 50–100 caractères), et une longueur minimale avant de lancer la recherche (souvent 2). Si vous limitez à 25 résultats, dites-le (par exemple, "Top 25 résultats") au lieu de laisser croire que vous avez tout cherché.
Préparez l'utilisation hors ligne et les connexions mauvaises
Si l'app peut être utilisée dans des trains, ascenseurs ou sur du Wi‑Fi faible, définissez ce qui fonctionne encore. Une option pratique pour la version 1 : les éléments récents et une petite liste mise en cache sont consultables hors ligne, tandis que le reste nécessite une connexion.
Quand la connexion est mauvaise, évitez de vider l'écran. Gardez les derniers bons résultats visibles et montrez un message clair indiquant que les résultats peuvent être obsolètes. Cela semble plus calme qu'un état vide qui ressemble à une erreur.
Debounce et contrôle des requêtes sans latence
La façon la plus rapide de rendre la recherche dans l'app lente est d'envoyer une requête réseau à chaque frappe. Les gens tapent par rafales, et l'UI commence à scintiller entre des résultats partiels. Le debounce règle ça en attendant un court moment après la dernière frappe avant de lancer la recherche.
Un bon délai de départ est 150–300 ms. Plus court peut encore spammer les requêtes, plus long donne l'impression que l'app ignore l'utilisateur. Si vos données sont surtout locales (en mémoire), vous pouvez réduire. Si chaque requête va au serveur, restez plutôt autour de 250–300 ms.
Le debounce marche mieux avec une longueur minimale de requête. Pour beaucoup d'apps, 2 caractères suffisent pour éviter des recherches inutiles comme "a" qui retournent tout. Si les utilisateurs cherchent souvent des codes courts (comme "HR" ou "ID"), autorisez 1–2 caractères, mais seulement après une pause.
Le contrôle des requêtes est aussi important que le debounce. Sans cela, des réponses lentes arrivent hors ordre et écrasent des résultats plus récents. Si un utilisateur tape "car" puis ajoute vite "d" pour obtenir "card", la réponse pour "car" peut arriver en dernier et faire reculer l'UI.
Utilisez l'un de ces schémas :
- Annuler les requêtes en cours quand une nouvelle commence.
- Suivre un ID de requête et n'afficher que les résultats de la dernière requête.
- Conserver la dernière chaîne recherchée et ignorer les réponses qui ne correspondent pas.
Pendant l'attente, donnez un retour instantané pour que l'app semble réactive avant l'arrivée des résultats. Ne bloquez pas la saisie. Affichez un petit spinner inline dans la zone de résultats ou un court message comme "Recherche...". Si vous gardez les résultats précédents à l'écran, étiquetez‑les subtilement (par exemple, "Résultats précédents") pour éviter la confusion.
Exemple pratique : dans la recherche de contacts d'un CRM, gardez la liste visible, debounce à 200 ms, ne lancez la recherche qu'après 2 caractères, et annulez l'ancienne requête quand l'utilisateur continue de taper. L'UI reste calme, les résultats ne scintillent pas, et les utilisateurs se sentent en contrôle.
Principes de cache qui accélèrent en toute sécurité
Le cache est une des façons les plus simples de faire paraître la recherche instantanée, car beaucoup de recherches se répètent. Les gens tapent, effacent, retentent la même requête, ou passent entre quelques filtres.
Mettez en cache avec une clé qui reflète ce que l'utilisateur a réellement demandé. Un bug courant est de mettre en cache seulement par texte de requête, puis d'afficher des résultats incorrects quand les filtres changent.
Une clé de cache pratique inclut normalement la requête normalisée plus les filtres actifs et l'ordre de tri. Si vous paginez, incluez la page ou le curseur. Si les permissions diffèrent par utilisateur ou espace de travail, incluez-les aussi.
Gardez le cache petit et éphémère. Stockez seulement les 20–50 dernières recherches et expirez les entrées après 30–120 secondes. C'est suffisant pour couvrir les allers-retours de frappe, mais assez court pour que des modifications n'entraînent pas une UI manifestement fausse trop longtemps.
Vous pouvez aussi préchauffer le cache en le préremplissant avec ce que l'utilisateur vient de voir : éléments récents, dernier projet ouvert, ou le résultat par défaut pour une requête vide (souvent "tous les éléments" triés par récence). Dans un petit CRM, mettre en cache la première page de Clients rend l'interaction initiale immédiate.
Ne mettez pas les échecs en cache comme les succès. Un 500 temporaire ou un timeout ne doit pas empoisonner le cache. Si vous stockez des erreurs, gardez‑les séparées avec un TTL beaucoup plus court.
Enfin, décidez comment invalider les entrées du cache quand les données changent. Au minimum, effacez les entrées pertinentes quand l'utilisateur courant crée, édite ou supprime quelque chose qui pourrait apparaître dans les résultats, quand les permissions changent, ou quand l'utilisateur change d'espace de travail/compte.
Bases de pertinence avec des règles simples et explicables
Si les résultats semblent aléatoires, les gens cessent de faire confiance à la recherche. Vous pouvez obtenir une pertinence solide sans moteur dédié en appliquant quelques règles explicables.
Une recette simple de scoring
Commencez par la priorité de correspondance :
- Correspondance exacte (le champ entier correspond à la requête)
- Correspondance préfixe (commence par la requête)
- Correspondance contenant (la requête apparaît n'importe où)
- Correspondance par token (un mot de la requête correspond à un mot du champ)
Puis renforcez les champs importants. Les titres comptent généralement plus que les descriptions. Les IDs ou tags importent souvent le plus quand quelqu'un les colle. Gardez les poids faibles et cohérents pour pouvoir raisonner dessus.
À ce stade, la gestion légère des fautes de frappe consiste surtout en normalisation, pas un fuzzy matching lourd. Normalisez à la fois la requête et le texte recherché : minuscule, trim, collapse d'espaces multiples, et suppression des accents si votre audience les utilise. Cela règle déjà beaucoup de plaintes du type «pourquoi ça ne trouve pas».
Décidez tôt comment traiter les symboles et les chiffres, car cela change les attentes. Une politique simple : conservez les hashtags comme partie du token, traitez les tirets et underscores comme des espaces, conservez les nombres, et retirez la plupart de la ponctuation (mais conservez @ et . si vous recherchez des emails ou pseudonymes).
Rendez le classement explicable. Une astuce simple : stockez une courte raison de debug par résultat dans les logs, par exemple "préfixe dans le titre" bat "contient dans la description".
Recherche locale vs serveur : une séparation pratique
Une expérience de recherche rapide tient souvent à un choix : quoi filtrer sur l'appareil, et quoi demander au serveur.
Le filtrage local marche mieux quand les données sont petites, déjà affichées, ou récemment utilisées : les 50 dernières discussions, projets récents, contacts sauvegardés, ou éléments déjà récupérés pour une vue liste. Si l'utilisateur vient de le voir, il s'attend à ce que la recherche le trouve immédiatement.
La recherche serveur sert pour des jeux de données énormes, des données qui changent souvent, ou tout ce que vous ne voulez pas télécharger. Elle est aussi nécessaire quand les résultats dépendent des permissions et des espaces de travail partagés.
Un schéma pratique et stable :
- Affichez d'abord les correspondances locales à partir de ce que vous avez déjà.
- Lancez une requête serveur en arrière-plan pour une couverture plus large.
- Fusionnez les résultats à l'arrivée (dédoublonnez par ID).
- Gardez la hauteur du conteneur de résultats stable pour éviter les sauts de page.
- Gardez le focus dans le champ de recherche.
Exemple : un CRM peut filtrer instantanément les clients vus récemment lorsque quelqu'un tape "ann", puis charger silencieusement les résultats serveur complets pour "Ann" à travers la base.
Pour éviter les changements de layout, réservez de l'espace pour les résultats et mettez à jour les lignes en place. Si vous passez des résultats locaux aux résultats serveur, un discret message "Résultats mis à jour" suffit souvent. Le comportement clavier doit rester cohérent : flèches pour naviguer, Entrée pour sélectionner, Échap pour effacer ou fermer.
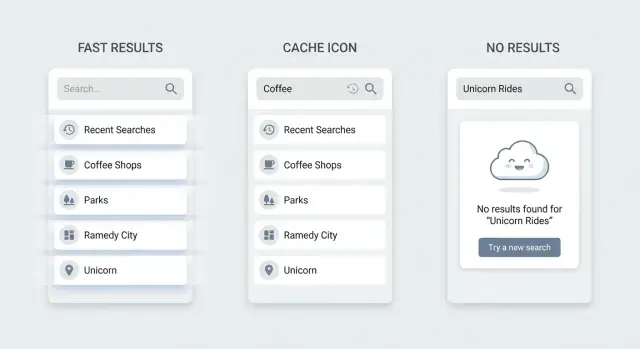
États vide, chargement et pas de résultats que les gens peuvent utiliser
La plupart des frustrations de recherche ne viennent pas du classement. Elles viennent de ce que l'écran fait quand l'utilisateur est entre deux actions : avant de taper, pendant la mise à jour des résultats, et quand rien ne correspond.
Quand la zone est vide : donnez un point de départ
Une page de recherche vide force l'utilisateur à deviner ce qui marche. De meilleures valeurs par défaut sont les recherches récentes (pour répéter une tâche) et un petit ensemble d'éléments populaires ou de catégories courantes (pour naviguer sans taper). Gardez‑les petites, scannables, et accessibles en un tap.
Pendant le chargement : gardez le contexte, évitez le scintillement
Les gens interprètent le scintillement comme de la lenteur. Vider la liste à chaque frappe donne l'impression d'une UI instable, même si le backend est rapide.
Gardez les résultats précédents à l'écran et affichez un petit indice de chargement près de l'entrée (ou un spinner subtil dedans). Si vous attendez plus longtemps, ajoutez quelques lignes squelette en bas tout en préservant la liste existante.
Si une requête échoue, affichez un message inline et gardez les anciens résultats visibles.
Une page blanche disant "Pas de résultats" est une impasse. Suggérez quoi essayer ensuite selon ce que votre UI supporte. Si des filtres sont actifs, proposez un Clear filters en un tap. Si vous supportez des requêtes multi-mots, suggérez d'utiliser moins de mots. Si vous avez des synonymes connus, proposez un terme alternatif.
Donnez aussi une vue de secours pour que l'utilisateur puisse continuer (éléments récents, top items ou catégories), et ajoutez une action Créer si votre produit le permet.
Scénario concret : quelqu'un cherche "invoice" dans un CRM et n'obtient rien parce que les éléments sont étiquetés "billing". Un état utile peut suggérer "Essayez : billing" et afficher la catégorie Billing.
Loggez les requêtes sans résultat (avec filtres actifs) pour ajouter des synonymes, améliorer les libellés ou créer le contenu manquant.
Étape par étape : construire une recherche qui semble instantanée en une semaine
La sensation d'instantanéité vient d'une petite version 1 claire. La plupart des équipes se coincent en voulant supporter tous les champs, tous les filtres et un classement parfait dès le jour 1.
Commencez par un cas d'usage. Exemple : dans un petit CRM, on cherche surtout des clients par nom, email et société, puis on filtre par statut (Active, Trial, Churned). Écrivez ces champs et filtres pour que tout le monde construise la même chose.
Un plan pratique d'une semaine :
- Jour 1 : Verrouiller la portée. Choisissez 3–5 champs recherchables, 0–2 filtres, et une règle de tri (par exemple exact d'abord, puis préfixe).
- Jour 2 : Rendre la saisie sûre. Ajoutez du debounce (souvent 150–250 ms) et annulez les anciennes requêtes pour que les réponses tardives n'écrasent pas les plus récentes.
- Jour 3 : Ajouter un classement simple et du surlignage. Utilisez des règles explicables (exact > commence par > contient). Surlignez les correspondances pour que l'utilisateur voie pourquoi un résultat apparaît.
- Jour 4 : Ajouter un petit cache. Mettez en cache les requêtes récentes et leurs résultats pour un court laps (30–120 s) et réutilisez‑les quand l'utilisateur efface ou répète une requête.
- Jour 5 : Terminer les états UI. Ajoutez un état de chargement léger et un état pas de résultats avec une action suivante.
Gardez l'invalidation simple. Effacez le cache à la déconnexion, au changement d'espace de travail, et après toute action qui modifie la liste sous-jacente (création, suppression, changement de statut). Si vous ne pouvez pas détecter les changements de façon fiable, utilisez un TTL court et traitez le cache comme un indice de vitesse, pas une source de vérité.
Utilisez le dernier jour pour mesurer. Suivez le temps jusqu'au premier résultat, le taux de pas-de-résultats, et le taux d'erreur. Si le temps jusqu'au premier résultat est bon mais que le pas-de-résultats est élevé, vos champs, filtres ou libellés demandent des ajustements.
Erreurs fréquentes qui rendent la recherche frustrante
La plupart des plaintes sur la lenteur sont en réalité des problèmes de retour et de justesse. Les gens peuvent attendre une seconde si l'UI paraît vivante et que les résultats ont du sens. Ils abandonnent quand la zone semble bloquée, les résultats bougent partout, ou l'app laisse entendre qu'ils ont fait une erreur.
Un piège courant est de mettre un debounce trop élevé. Si vous attendez 500–800 ms avant d'agir, la saisie semble non réactive, surtout sur de courtes requêtes comme "hr" ou "tax". Gardez le délai bas et montrez un retour immédiat pour que la frappe ne paraisse jamais ignorée.
Autre frustration : laisser gagner les anciennes requêtes. Si un utilisateur tape "app" puis ajoute rapidement "l", la réponse pour "app" peut arriver en dernier et écraser les résultats pour "appl". Annulez la requête précédente quand vous commencez une nouvelle, ou ignorez toute réponse qui ne correspond pas à la requête la plus récente.
Le cache peut se retourner contre vous si les clés sont trop vagues. Si votre clé n'est que le texte de la requête alors que vous avez aussi des filtres (statut, plage de dates, catégorie), vous afficherez des résultats incorrects et les utilisateurs perdront confiance. Traitez requête + filtres + tri comme une seule identité.
Les erreurs de classement sont subtiles mais pénibles. Les gens s'attendent à voir les correspondances exactes en premier. Un ensemble de règles simple et cohérent vaut souvent mieux qu'un système compliqué :
- Correspondance exacte sur le nom ou l'ID en premier
- Correspondance préfixe ensuite
- Puis correspondance partielle n'importe où
- Fuzzy uniquement si rien d'autre ne correspond
- Les éléments récents ou fréquents départagent, sans outrepasser une correspondance exacte
Les écrans pas de résultats font souvent rien. Affichez ce qui a été cherché, proposez d'effacer les filtres, suggérez une requête plus large, et montrez quelques éléments populaires ou récents.
Exemple : un fondateur cherche des clients dans un CRM, tape "Ana", a le filtre Active activé, et obtient rien. Un état utile dirait "Aucun client actif pour 'Ana'" et proposerait une action Afficher tous les statuts en un tap.
Checklist rapide et prochaines étapes
Avant d'ajouter un moteur de recherche dédié, assurez-vous que les bases semblent calmes : la saisie reste fluide, les résultats ne sautent pas, et l'UI dit toujours aux gens ce qui se passe.
Une checklist rapide pour la version 1 :
- La saisie ne saccade jamais. Débouncer le travail après l'entrée, pas l'entrée elle‑même.
- Les résultats se mettent à jour dans l'ordre. Annulez ou ignorez les anciennes requêtes pour ne jamais montrer de résultats obsolètes.
- Le chargement est clair mais doux. Gardez la liste actuelle visible et montrez un petit indice de mise à jour.
- Le pas de résultats aide l'utilisateur à se relever. Proposez une action suivante comme effacer les filtres ou essayer une requête plus courte.
- Les règles de classement sont écrites et cohérentes.
Confirmez ensuite que votre cache fait plus de bien que de mal. Gardez‑le petit (seulement recherches récentes), mettez en cache la liste finale de résultats, et invalidez‑le quand les données changent. Si vous ne pouvez pas détecter les changements de façon fiable, raccourcissez la durée de vie.
Prochaines étapes
Avancez par petites étapes mesurables :
- Ajoutez un petit plan de test : 5 requêtes courantes, 2 cas limites, et 1 cas pas de résultats.
- Loggez seulement ce dont vous avez besoin : longueur de requête, temps jusqu'au premier résultat, et taux d'annulation (évitez de stocker le texte personnel si possible).
- Choisissez une amélioration par semaine : meilleur classement, meilleur état vide, ou meilleur cache.
- Ajoutez un vrai backend de recherche seulement après avoir expliqué ce qui manque aujourd'hui.
Si vous construisez une app sur Koder.ai (koder.ai), il vaut la peine de traiter la recherche comme une fonctionnalité de première classe dans vos prompts et vos critères d'acceptation : définissez les règles, testez les états, et faites en sorte que l'UI se comporte calmement dès le premier jour.