21 अग॰ 2025·8 मिनट
6 SQL JOINs जिन्हें आपको जानना चाहिए (सरल, स्पष्ट उदाहरणों के साथ)
INNER, LEFT, RIGHT, FULL OUTER, CROSS और SELF सहित 6 जरूरी SQL JOINs को सरल उदाहरणों और सामान्य गलतियों के साथ जानें।
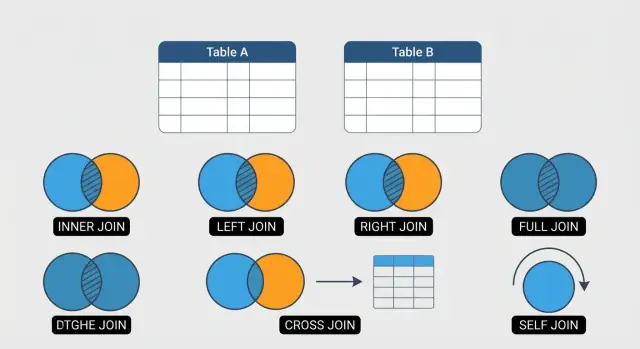
INNER, LEFT, RIGHT, FULL OUTER, CROSS और SELF सहित 6 जरूरी SQL JOINs को सरल उदाहरणों और सामान्य गलतियों के साथ जानें।
एक SQL JOIN आपको दो (या अधिक) तालिकाओं की पंक्तियों को संबंधित कॉलम—अक्सर कोई ID—के आधार पर एक परिणाम में मिलाने देता है।
अधिकांश रियल‑वर्ल्ड डेटाबेस जानबूझकर अलग तालिकाओं में विभाजित होते हैं ताकि वही जानकारी बार‑बार न दोहरानी पड़े। उदाहरण के लिए, ग्राहक का नाम customers तालिका में रहता है, जबकि उनके खरीद orders तालिका में रहते हैं। जब आपको जवाब चाहिए होता है, तो JOINs उन्हीं टुकड़ों को फिर से जोड़ने का तरीका हैं।
इसीलिए JOINs रिपोर्टिंग और एनालिसिस में हर जगह दिखते हैं:
बिना JOINs के आप अलग सवालों के लिए अलग‑अलग क्वेरी चलाकर मैन्युअल रूप से परिणाम जोड़ने पड़ेंगे—धीमा, त्रुटिपूर्ण और मुश्किल से दोहराने योग्य।
यदि आप रिलेशनल डेटाबेस पर उत्पाद बना रहे हैं (डैशबोर्ड, एडमिन पैनल, अंतरिक टूल, कस्टमर पोर्टल), तो JOINs ही “रॉ टेबल्स” को यूजर‑फेस वाला दृश्य बनाते हैं। प्लेटफ़ॉर्म जैसे Koder.ai (जो React + Go + PostgreSQL ऐप चैट से बनाता है) तब भी JOIN बेसिक्स पर निर्भर करते हैं जब आपको सटीक लिस्ट पेज, रिपोर्ट और reconciliation स्क्रीन चाहिए—क्यूंकि डेटाबेस लॉजिक कहीं नहीं जाता, भले ही डेवलपमेंट तेज़ हो।
यह गाइड उन छह JOINs पर केंद्रित है जो रोज़मर्रा के SQL काम का अधिकांश भाग कवर करते हैं:
JOIN सिंटैक्स अधिकांश SQL डेटाबेस (PostgreSQL, MySQL, SQL Server, SQLite) में बहुत समान है। कुछ अंतर होते हैं—विशेषकर FULL OUTER JOIN सपोर्ट और कुछ किनारे‑केस व्यवहार के आस‑पास—पर कांसेप्ट और कोर पैटर्न आसानी से ट्रांसफर हो जाते हैं।
JOIN उदाहरणों को सरल रखने के लिए, हम तीन छोटी तालिकाओं का उपयोग करेंगे जो सामान्य रियल‑वर्ल्ड सेटअप को दर्शाती हैं: ग्राहक ऑर्डर करते हैं, और ऑर्डर के साथ‑साथ पेमेंट हो भी सकते हैं या नहीं भी।
एक छोटी बात पहले: नीचे दिए गए सैंपल तालिकाएँ केवल कुछ कॉलम दिखाती हैं, पर बाद की कुछ क्वेरीज़ अतिरिक्त फ़ील्ड्स (order_date, created_at, status, या paid_at) का संदर्भ देती हैं ताकि सामान्य पैटर्न दिख सकें। उन कॉलम्स को "टिपिकल" फ़ील्ड्स समझें जो प्रोडक्शन स्कीमाओं में अक्सर होते हैं।
Primary key: customer_id
| customer_id | name |
|---|---|
| 1 | Ava |
| 2 | Ben |
| 3 | Chen |
| 4 | Dia |
Primary key: order_id
Foreign key: customer_id → customers.customer_id
| order_id | customer_id | order_total |
|---|---|---|
| 101 | 1 | 50 |
| 102 | 1 | 120 |
| 103 | 2 | 35 |
| 104 | 5 | 70 |
ध्यान दें कि order_id = 104 customer_id = 5 को संदर्भित करता है, जो customers में मौजूद नहीं है। यह "मिसिंग मैच" यह दिखाने में उपयोगी है कि LEFT JOIN, RIGHT JOIN, और FULL OUTER JOIN कैसे व्यवहार करते हैं।
Primary key: payment_id
Foreign key: order_id → orders.order_id
| payment_id | order_id | amount |
|---|---|---|
| 9001 | 101 | 50 |
| 9002 | 102 | 60 |
| 9003 | 102 | 60 |
| 9004 | 999 | 25 |
दो महत्वपूर्ण शिक्षण‑डिटेल्स:
order_id = 102 के पास दो payment पंक्तियाँ हैं (split payment)। जब आप orders को payments से जोड़ेंगे, वह ऑर्डर दो बार दिखेगा—यही वह जगह है जहाँ डुप्लीकेट अक्सर लोगों को चौंकाते हैं।payment_id = 9004 order_id = 999 को संदर्भित करता है, जो orders में मौजूद नहीं है। यह एक और "अनमैच्ड" केस बनाता है।orders को payments से जोड़ने पर ऑर्डर 102 दो बार दिखाई देगा क्योंकि उसके दो संबंधित पेमेंट हैं।INNER JOIN केवल उन पंक्तियों को लौटाता है जहाँ दोनों तालिकाओं में मैच हो। अगर किसी ग्राहक के पास ऑर्डर नहीं है तो वे परिणाम में नहीं दिखेंगे। यदि कोई ऑर्डर किसी मौजूद ग्राहक को रेफ़र नहीं करता (बुरा डेटा), तो वह ऑर्डर भी नहीं दिखाई देगा।
आप एक "बाईं" तालिका चुनते हैं, एक "दाहिनी" तालिका जोड़ते हैं, और उन्हें ON क्लॉज़ में कंडीशन से कनेक्ट करते हैं।
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id;
मुख्य विचार वह ON o.customer_id = c.customer_id लाइन है: यह SQL को बताती है कि पंक्तियाँ कैसे संबंधित हैं।
यदि आप केवल उन ग्राहकों की सूची चाहते हैं जिन्होंने कम से कम एक ऑर्डर दिया है (और ऑर्डर विवरण), तो INNER JOIN स्वाभाविक विकल्प है:
SELECT
c.name,
o.order_id,
o.total_amount
FROM customers c
INNER JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY o.order_id;
यह उपयोगी है जैसे “ऑर्डर फॉलो‑अप ईमेल भेजना” या “हर ग्राहक के लिए राजस्व निकालना” (जब आप केवल खरीद करने वाले ग्राहकों पर ध्यान दे रहे हों)।
यदि आप join लिखते हैं लेकिन ON कंडीशन भूल जाते हैं (या गलत कॉलम पर जोइन करते हैं), तो आप आकस्मिक रूप से कार्टेशियन प्रोडक्ट (हर ग्राहक का हर ऑर्डर के साथ संयोजन) बना सकते हैं या सूक्ष्म रूप से गलत मैच दे सकते हैं।
गलत (यह न करें):
SELECT c.name, o.order_id
FROM customers c
JOIN orders o;
हमेशा सुनिश्चित करें कि आपके पास ON (या जहाँ लागू हो USING) में एक स्पष्ट join कंडीशन हो।
LEFT JOIN बाईं तालिका की सभी पंक्तियाँ लौटाता है, और दाहिनी तालिका से मिलान होने पर संबंधित डेटा जोड़ता है। यदि कोई मैच नहीं मिलता तो दाहिनी‑साइड के कॉलम NULL होंगे।
जब आप अपनी प्राथमिक तालिका की पूरी सूची चाहते हैं और संबंधित वैकल्पिक डेटा भी चाहते हैं, तब LEFT JOIN प्रयोग करें।
उदाहरण: “मुझे सभी ग्राहक दिखाइए, और यदि उनके पास ऑर्डर हैं तो उन्हें शामिल करें।”
SELECT
c.customer_id,
c.name,
o.order_id,
o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
ORDER BY c.customer_id;
o.order_id (और अन्य orders कॉलम) NULL होंगे।एक बहुत ही सामान्य कारण LEFT JOIN का उपयोग करने का यह है कि आप उन आइटम्स को खोज रहे हैं जिनके संबंधित रिकॉर्ड नहीं हैं।
उदाहरण: “कौन से ग्राहक कभी भी ऑर्डर नहीं किए हैं?”
SELECT
c.customer_id,
c.name
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.order_id IS NULL;
यह WHERE ... IS NULL शर्त केवल उन बाईं‑तालिका की पंक्तियों को रखती है जहाँ मैच नहीं मिला।
जब दाईं‑साइड पर कई मिलान होते हैं तो LEFT JOIN बाईं‑तालिका की पंक्तियों को “डुप्लिकेट” कर सकता है।
यदि किसी एक ग्राहक के 3 ऑर्डर हैं, तो वह ग्राहक 3 बार दिखाई देगा—प्रति ऑर्डर एक बार। यह अपेक्षित व्यवहार है, पर यदि आप ग्राहकों की गिनती कर रहे हैं तो यह चौंकाने वाला हो सकता है।
उदाहरण के लिए, यह ऑर्डर्स को गिनता है (ग्राहकों को नहीं):
SELECT COUNT(*)
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id;
यदि आपका लक्ष्य ग्राहकों की गिनती है, तो आमतौर पर आप ग्राहक‑कुंजी की तरह गिनेंगे (अक्सर COUNT(DISTINCT c.customer_id)), यह निर्भर करता है कि आप क्या माप रहे हैं।
RIGHT JOIN दाहिनी तालिका की सभी पंक्तियाँ रखता है, और केवल बाईं तालिका से मिलान वाली पंक्तियाँ जोड़ता है। यदि कोई मैच नहीं है तो बाईं तालिका के कॉलम NULL दिखेंगे। यह मूलतः LEFT JOIN का मिरर है।
हमारी उदाहरण तालिकाओं का उपयोग करते हुए, मानिए आप हर payment को सूचीबद्ध करना चाहते हैं, भले ही वह किसी ऑर्डर से जुड़ा न हो (शायद ऑर्डर हटा दिया गया था, या पेमेंट डेटा गड़बड़ा गया हो)।
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM orders o
RIGHT JOIN payments p
ON o.order_id = p.order_id;
आपको क्या मिलता है:
payments दाहिने पर है)।o.order_id और o.customer_id NULL होंगे।अधिकांश मामलों में आप RIGHT JOIN को LEFT JOIN के रूप में फिर लिख सकते हैं बस तालिकाओं के क्रम को बदलकर:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount,
p.paid_at
FROM payments p
LEFT JOIN orders o
ON o.order_id = p.order_id;
यह वही परिणाम देता है, पर कई लोग इसे पढ़ने में आसान पाते हैं: आप पहले मुख्य तालिका (यहाँ payments) से शुरू करते हैं और फिर वैकल्पिक संबंधित डेटा खींचते हैं।
कई SQL स्टाइल‑गाइड्स RIGHT JOIN को नकारात्मक मानते हैं क्योंकि यह रीडर को सामान्य पैटर्न को उल्टा समझने पर मजबूर करता है:
जब वैकल्पिक संबंध लगातार LEFT JOIN के रूप में लिखे जाते हैं तो क्वेरीज़ स्कैन करने में आसान हो जाती हैं।
जब आप किसी मौजूदा क्वेरी को एडिट कर रहे हों और आपको अचानक महसूस हो कि "जरूरी‑रहने वाली" तालिका वर्तमान में दाहिने पर है, तो पूरे क्वेरी को फिर से लिखने की बजाय सिर्फ एक JOIN को RIGHT JOIN में बदलना एक त्वरित, कम‑जोखिम भरा परिवर्तन हो सकता है।
FULL OUTER JOIN दोनों तालिकाओं की सभी पंक्तियाँ लौटाता है।
INNER JOIN में होता है)।NULL होंगे।NULL होंगे।एक क्लासिक बिज़नेस केस है orders vs. payments का reconciliation:
उदाहरण:
SELECT
o.order_id,
o.customer_id,
p.payment_id,
p.amount
FROM orders o
FULL OUTER JOIN payments p
ON p.order_id = o.order_id;
FULL OUTER JOIN PostgreSQL, SQL Server, और Oracle में समर्थित है।
यह MySQL और SQLite में उपलब्ध नहीं है (आपको वर्कअराउंड चाहिए होगा)।
यदि आपका डेटाबेस FULL OUTER JOIN सपोर्ट नहीं करता, तो आप इसे इस तरह नकल कर सकते हैं कि:
orders की सभी पंक्तियाँ (जब उपलब्ध हों तो matching payments के साथ), औरएक आम पैटर्न:
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
LEFT JOIN payments p
ON p.order_id = o.order_id
UNION
SELECT o.order_id, o.customer_id, p.payment_id, p.amount
FROM orders o
RIGHT JOIN payments p
ON p.order_id = o.order_id;
टिप: जब आप एक साइड पर NULLs देखें, तो इसका संकेत है कि वह पंक्ति दूसरी तालिका में "मिसिंग" थी — ऑडिट और reconciliation के लिए यही आप ढूँढ रहे हैं।
CROSS JOIN दो तालिकाओं से हर संभव जोड़ी लौटाता है। यदि तालिका A में 3 पंक्तियाँ हैं और तालिका B में 4 पंक्तियाँ हैं, तो परिणाम में 3 × 4 = 12 पंक्तियाँ होंगी। इसे कार्टेशियन प्रोडक्ट भी कहा जाता है।
यह डरावना लगता है—और कभी‑कभी होता भी है—पर यह वास्तविक में उपयोगी होता है जब आप संयोजन ही बनाना चाहते हैं।
मानिए आप उत्पाद विकल्प अलग तालिकाओं में रखते हैं:
sizes: S, M, Lcolors: Red, Blueएक CROSS JOIN सभी संभावित वेरिएंट बना सकता है (SKU बनाना, कैटलॉग प्रीबिल्ड करना, या टेस्टिंग के लिए उपयोगी):
SELECT
s.size,
c.color
FROM sizes AS s
CROSS JOIN colors AS c;
परिणाम (3 × 2 = 6 पंक्तियाँ):
क्योंकि पंक्तियों की संख्या गुणा होती है, CROSS JOIN जल्दी से बहुत बड़ा परिणाम पैदा कर सकता है:
यह क्वेरीज़ को धीमा कर सकता है, मेमोरी पर दबाव डाल सकता है, और ऐसा आउटपुट बना सकता है जिसका उपयोग कोई न कर सके। यदि आपको संयोजन चाहिए तो इनपुट तालिकाओं को छोटा रखें और सीमाएँ/फ़िल्टर नियंत्रित तरीके से लागू करें।
एक SELF JOIN बिल्कुल वही है जितना इसका नाम बताता है: आप किसी तालिका को खुद से जोड़ते हैं। यह तब उपयोगी होता है जब तालिका की एक पंक्ति किसी दूसरी पंक्ति से संबंधित हो—सबसे सामान्य रूप में parent/child संबंध जैसे employees और उनके managers।
क्योंकि आप एक ही तालिका का दो बार उपयोग कर रहे हैं, आपको हर "कॉपी" को अलग alias देना होगा। aliases क्वेरी को पठनीय बनाते हैं और SQL को बताते हैं कि आप किस साइड का संदर्भ दे रहे हैं।
एक सामान्य पैटर्न है:
e कर्मचारी के लिएm प्रबंधक के लिएमानिए employees तालिका में ये कॉलम हैं:
idnamemanager_id (किसी दूसरे employee के id की ओर इशारा)प्रत्येक कर्मचारी के साथ उनके मैनेजर का नाम सूचीबद्ध करने के लिए:
SELECT
e.id,
e.name AS employee_name,
m.name AS manager_name
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id;
ध्यान दें कि क्वेरी LEFT JOIN का उपयोग करती है, न कि INNER JOIN। यह महत्वपूर्ण है क्योंकि कुछ कर्मचारियों का कोई मैनेजर नहीं हो सकता (उदा. CEO)। ऐसे मामलों में manager_id अक्सर NULL होता है, और LEFT JOIN कर्मचारी पंक्ति को बनाए रखता है जबकि manager_name NULL दिखेगा।
यदि आप INNER JOIN का उपयोग करते तो वे शीर्ष‑स्तरीय कर्मचारी परिणाम से गायब हो जाएंगे क्योंकि उनके लिए कोई मेल खाती मैनेजर पंक्ति नहीं है।
एक JOIN "स्वतः" नहीं जानता कि दो तालिकाएँ कैसे संबंधित हैं—आपको उसे बताना होगा। वह संबंध join कंडीशन में परिभाषित होता है, और यह JOIN के ठीक पास होना चाहिए क्योंकि यह बताता है कि तालिकाएँ कैसे मिलती हैं, न कि आप अंतिम परिणाम में क्या फ़िल्टर करना चाहते हैं।
ON: सबसे लचीला (और सबसे सामान्य)जब आपको मैचिंग लॉजिक पर पूरा नियंत्रण चाहिए—जैसे अलग‑नाम कॉलम, एक से अधिक कंडीशन, या अतिरिक्त नियम—तो ON का उपयोग करें।
SELECT
c.customer_id,
c.name,
o.order_id,
o.created_at
FROM customers AS c
INNER JOIN orders AS o
ON o.customer_id = c.customer_id;
ON वही जगह है जहाँ आप जटिल मैच (उदा. दो कॉलम पर मैच) भी परिभाषित कर सकते हैं बिना क्वेरी को कठिन बनाए।
USING: छोटा, पर केवल same‑name कॉलम के लिएकुछ डेटाबेस (जैसे PostgreSQL और MySQL) USING को सपोर्ट करते हैं। यह तब सुविधाजनक शॉर्टहैंड है जब दोनों तालिकाओं में एक ही नाम का कॉलम हो और आप उसी कॉलम पर जोड़ना चाहते हों।
SELECT
customer_id,
name,
order_id
FROM customers
JOIN orders
USING (customer_id);
एक अच्छा फायदा: USING आमतौर पर आउटपुट में केवल एक customer_id कॉलम लौटाता है (दो कॉपियों की जगह)।
एक बार जब आप तालिकाएँ जोड़ते हैं, तो कॉलम नाम अक्सर ओवरलैप हो जाते हैं (id, created_at, status)। यदि आप SELECT id लिखते हैं तो डेटाबेस “ambiguous column” त्रुटि फेंक सकता है—या बदतर, आप गलती से गलत id पढ़ सकते हैं।
स्पष्टता के लिए table prefixes (या aliases) को प्राथमिकता दें:
SELECT c.customer_id, o.order_id
FROM customers AS c
JOIN orders AS o
ON o.customer_id = c.customer_id;
SELECT * से बचेंSELECT * जॉइन के साथ तेजी से गड़बड़ा जाता है: आप अनावश्यक कॉलम खींचते हैं, नामों के डुप्लीकेट जोखिम लेते हैं, और यह समझना मुश्किल हो जाता है कि क्वेरी का मकसद क्या है।
इसके बजाय जिस‑जिस कॉलम की ज़रूरत हो उन्हें ही चुनें। आपका परिणाम साफ़, बनाए रखने में आसान और अक्सर अधिक कुशल होगा—खासकर तब जब तालिकाएँ चौड़ी हों।
जब आप तालिकाएँ जोड़ते हैं, तो WHERE और ON दोनों “फ़िल्टर” करते हैं, पर वे अलग‑अलग क्षणों पर करते हैं।
यह समय‑भेद अक्सर लोगों को गलती से LEFT JOIN को INNER JOIN बना देता है।
मान लीजिए आप सभी ग्राहक चाहते हैं, भले ही उनके पास हाल‑फिलहाल का कोई भुगतान किया हुआ ऑर्डर न हो।
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
WHERE o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
समस्या: जिन ग्राहकों के पास कोई मिलान ऑर्डर नहीं है, वहाँ o.status और o.order_date NULL होंगे। WHERE क्लॉज़ उन पंक्तियों को अस्वीकार कर देता है, इसलिए अनमैच्ड ग्राहक गायब हो जाते हैं—आपका LEFT JOIN INNER JOIN जैसा व्यवहार करने लगता है।
SELECT c.customer_id, c.name, o.order_id, o.status, o.order_date
FROM customers c
LEFT JOIN orders o
ON o.customer_id = c.customer_id
AND o.status = 'PAID'
AND o.order_date >= DATE '2025-01-01';
अब उन ग्राहकों के साथ‑साथ जिनके पास पात्र ऑर्डर नहीं हैं वे भी दिखेंगे (ऑर्डर कॉलम NULL होंगे), जो आम तौर पर LEFT JOIN का उद्देश्य होता है।
WHERE o.order_id IS NOT NULL) उपयोग करें।JOINs केवल कॉलम नहीं जोड़ते—वे पंक्तियाँ भी गुणा कर सकते हैं। यह आमतौर पर सही व्यवहार है, पर जब टोटल्स अचानक दोगुना होते हैं तो यह अक्सर लोगों को आश्चर्यचकित कर देता है।
जॉइन हर मैचिंग जोड़ी के लिए एक आउटपुट पंक्ति लौटाता है।
customers को orders से जोड़ते हैं, तो हर ऑर्डर के लिए ग्राहक कई बार दिखाई देगा।orders को payments से जोड़ते हैं और हर ऑर्डर के कई payments हो सकते हैं, और फिर आप किसी और "many" तालिका (जैसे order_items) भी जोड़ते हैं, तो आप multiplication प्रभाव देख सकते हैं: payments × items प्रति ऑर्डर।यदि आपका लक्ष्य "प्रति‑ग्राहक एक पंक्ति" या "प्रति‑ऑर्डर एक पंक्ति" है, तो पहले "many" साइड को सारांशित करें (summarize), फिर join करें।
-- One row per order from payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
यह जॉइन के "आकार" को पूर्वानुमेय बनाए रखता है: एक ऑर्डर‑पंक्ति एक ही रहेगी।
SELECT DISTINCT डुप्लीकेट्स को हटाकर समस्या को दिखा सकता है, पर यह रियल इश्यू छिपा सकता है:
जब आप सुनिश्चित हों कि डुप्लीकेट वास्तविक गलती नहीं हैं और आप कारण जानते हों तभी उपयोग करें।
परिणामों पर भरोसा करने से पहले पंक्ति‑गणनाएँ तुलना करें:
JOINs को अक्सर "धीमी क्वेरीज़" का दोषी माना जाता है, पर असली कारण अक्सर यह होता है कि आपने डेटाबेस से कितना डेटा जोड़ने के लिए कहा और वह कितनी आसानी से मैच करने वाली पंक्तियाँ ढूँढ सकता है।
इंडेक्स को किताब की तालिका‑वर्णन (table of contents) की तरह सोचें। इसके बिना डेटाबेस को मैच खोजने के लिए कई पंक्तियाँ स्कैन करनी पड़ सकती हैं। यदि join key पर इंडेक्स है (उदाहरण: customers.customer_id और orders.customer_id), तो डेटाबेस तेज़ी से संबंधित पंक्तियों पर जा सकता है।
आपको अंदरूनी तंत्र जानने की ज़रूरत नहीं—यदि कोई कॉलम अक्सर मैच के लिए उपयोग होता है (ON a.id = b.a_id), तो वह इंडेक्स के लिए अच्छा उम्मीदवार है।
जहाँ संभव हो, स्थिर, यूनिक identifiers पर जोड़ें:
customers.customer_id = orders.customer_idcustomers.email = orders.email या customers.name = orders.nameनाम बदल सकते हैं और दोहराए जा सकते हैं। ईमेल बदल सकते हैं, गायब हो सकते हैं, या केस/फॉर्मैट में भिन्न हो सकते हैं। IDs निरंतर मिलान के लिए डिज़ाइन किए गए होते हैं और आमतौर पर indexed भी होते हैं।
दो आदतें JOINs को काफी तेज़ बना देती हैं:
SELECT * से बचें—अतिरिक्त कॉलम मेमोरी और नेटवर्क उपयोग बढ़ाते हैं।उदाहरण: पहले ऑर्डर्स को सीमित करें, फिर जोइन करें:
SELECT c.customer_id, c.name, o.order_id, o.created_at
FROM customers c
JOIN (
SELECT order_id, customer_id, created_at
FROM orders
WHERE created_at >= DATE '2025-01-01'
) o
ON o.customer_id = c.customer_id;
यदि आप इन क्वेरीज़ को किसी ऐप‑बिल्ड के भीतर रिपीट कर रहे हैं (जैसे रिपोर्टिंग पेज PostgreSQL पर), तो टूल्स जैसे Koder.ai स्कैफोल्डिंग तेज़ कर सकते हैं—स्कीमा, एंडपॉइंट, UI—जबकि आप JOIN लॉजिक की सटीकता नियंत्रित करते रहें।
NULL)NULL जब मिसिंग)NULL दिखते हैंएक SQL JOIN दो (या अधिक) तालिकाओं की पंक्तियों को संबंधित कॉलमों के आधार पर एक परिणाम सेट में जोड़ता है—अक्सर यह एक primary key को foreign key से मिलाकर होता है (उदाहरण के लिए, customers.customer_id = orders.customer_id)। यह वही तरीका है जिससे आप सामान्यीकृत (normalized) तालिकाओं को रिपोर्ट, ऑडिट या विश्लेषण के लिए फिर से “कनेक्ट” करते हैं।
INNER JOIN तब इस्तेमाल करें जब आप केवल उन पंक्तियों को चाहते हैं जहाँ दोनों तालिकाओं में संबंध मौजूद हो।
यह “पुष्ट संबंध” दिखाने के लिए उपयुक्त है, जैसे केवल उन ग्राहकों की सूची जो वाकई ने ऑर्डर दिया है।
जब आप अपनी मुख्य (left) तालिका की सभी पंक्तियाँ चाहते हैं और दूसरी तालिका से वैकल्पिक संबंधित डेटा शामिल करना चाहते हैं तो LEFT JOIN का उपयोग करें।
“मिलान न होने वाली” पंक्तियाँ खोजने के लिए, जुड़कर दाईं साइड को NULL पर फ़िल्टर करें:
c.customer_id, c.name
customers c
orders o o.customer_id c.customer_id
o.order_id ;
RIGHT JOIN दाईं तालिका की हर पंक्ति को रखता है और यदि मिलान नहीं होता तो बाईं तालिका के कॉलम NULL दिखाता है। कई टीमें इसे पढ़ने में उल्टा समझने के कारण टालती हैं।
अधिकतर मामलों में आप इसे LEFT JOIN से बदल सकते हैं बस तालिकाओं के क्रम को उलटकर:
FROM payments p
LEFT orders o o.order_id p.order_id
FULL OUTER JOIN का उपयोग reconciliation के लिए सबसे उपयुक्त है: आप मैच, बाएं-उनके-लिए (left-only) और दाहिने-उनके-लिए (right-only) सभी रिकॉर्ड एक ही आउटपुट में देखना चाहते हैं।
यह “ऑर्डर जिनके भुगतान नहीं हैं” और “ऐसे भुगतान जिनका कोई ऑर्डर नहीं है” जैसी ऑडिटिंग के लिए बहुत अच्छा है क्योंकि मिसिंग साइड के कॉलम NULL के रूप में दिखते हैं।
कुछ डेटाबेस (विशेष रूप से MySQL और SQLite) सीधे FULL OUTER JOIN को सपोर्ट नहीं करते। सामान्य वर्कअराउंड यह है कि आप दो क्वेरीज़ को मिलाकर (उदाहरण के लिए orders LEFT JOIN payments और दाईं साइड के केवल उन रिकॉर्ड्स को शामिल करना) UNION का उपयोग करके समान परिणाम बनाते हैं।
इसमें मित्रवत सावधानी रखें कि आप डुप्लीकेट या मिसिंग रिकार्ड्स को ठीक से हैंडल करें — कभी-कभी UNION ALL और अतिरिक्त फ़िल्टरिंग की ज़रूरत पड़ती है।
CROSS JOIN दो तालिकाओं के बीच हर संभव संयोजन (कार्टेशियन प्रोडक्ट) लौटाता है। यह उपयोगी है पर केवल जब आप सचमुच सभी संयोजन चाहते हों—जैसे sizes × colors से SKU बनाना या टेस्ट डेटा जनरेट करना।
ध्यान रखें: पंक्तियों की संख्या जल्दी बढ़ जाती है, इसलिए इनपुट छोटा और नियंत्रित रखें।
SELF JOIN तब लागू होता है जब आप एक तालिका को स्वयं से जोड़ना चाहते हैं ताकि तालिका के भीतर पंक्तियों के बीच संबंध दिखे—आमतौर पर हायार्की (जैसे employee → manager)।
आपको अलग-अलग alias चाहिए ताकि SQL समझ सके आप तालिका की किस “कॉपी” का संदर्भ दे रहे हैं:
FROM employees e
LEFT JOIN employees m
ON e.manager_id = m.id
ON यह निर्धारित करता है कि जॉइन के दौरान कौन‑सी पंक्तियाँ मिलेंगी; WHERE अंतिम परिणाम को फ़िल्टर करता है। LEFT JOIN के साथ अगर आप दायीं तालिका के कॉलमों पर WHERE लगाते हैं तो वे NULL होने पर उस पंक्ति को हटा देंगे और आपका LEFT JOIN अप्रत्याशित रूप से एक INNER JOIN जैसा व्यवहार कर सकता है।
जॉइन तब डुप्लिकेट पंक्तियाँ बना सकते हैं जब संबंध one‑to‑many या many‑to‑many हो। उदाहरण: एक ऑर्डर के दो भुगतान हों तो orders और payments को जोड़ने पर वह ऑर्डर दो बार दिखेगा।
इसे रोकने के लिए अक्सर “many” पक्ष को पहले aggregate कर लें, फिर जोइन करें:
यदि आप बाएं तालिका की सभी पंक्तियाँ रखना चाहते हैं पर दायीं तालिका को सीमित करना चाहते हैं, तो दायीं तालिका से संबंधित शर्तें ON में रखें।
-- One row per order from payments
WITH payment_totals AS (
SELECT
order_id,
SUM(amount) AS total_paid,
COUNT(*) AS payment_count
FROM payments
GROUP BY order_id
)
SELECT
o.order_id,
o.customer_id,
COALESCE(pt.total_paid, 0) AS total_paid,
COALESCE(pt.payment_count, 0) AS payment_count
FROM orders o
LEFT JOIN payment_totals pt
ON pt.order_id = o.order_id;
DISTINCT को आखिरी उपाय समझें—यह समस्या छुपा सकता है और totals/काउंट्स को गलत कर सकता है।