03 अप्रैल 2025·8 मिनट
AI ऐप्स में फ्रंटेंड और बैकएंड में स्टेट प्रबंधन
UI, सत्र और डेटा स्टेट फ्रंटेंड और बैकएंड के बीच AI ऐप्स में कैसे चलते हैं — सिंकिंग, परज़िस्टेंस, कैशिंग और सुरक्षा के व्यावहारिक पैटर्न के साथ जानें।
AI-निर्मित एप्लिकेशन में “स्टेट” का क्या अर्थ है
"स्टेट" वह सब कुछ है जिसे आपका ऐप सही तरीके से व्यवहार करने के लिए याद रखता है, एक पल से अगले पल तक।
यदि कोई उपयोगकर्ता चैट UI में Send क्लिक करता है, तो ऐप को यह नहीं भूलना चाहिए कि उसने क्या टाइप किया, असिस्टेंट ने पहले क्या जवाब दिया, कोई अनुरोध चल रहा है या नहीं, या कौन-से सेटिंग्स (टोन, मॉडल, टूल) सक्षम हैं। ये सब स्टेट है।
साधारण शब्दों में स्टेट
स्टेट को उपयोगी ढंग से सोचने का तरीका है: ऐप की वर्तमान सच्चाई—ऐसे मान जो उपयोगकर्ता को दिखने वाली चीज़ों और सिस्टम के अगले कदम को प्रभावित करते हैं। इसमें सहज चीज़ें शामिल हैं जैसे फ़ॉर्म इनपुट, लेकिन साथ ही "अदृश्य" तथ्य भी, जैसे:
- उपयोगकर्ता किस बातचीत में है
- क्या पिछला उत्तर स्ट्रीमिंग में है या पूरा हुआ है
- संदेशों की सूची और उनका क्रम
- टूल कॉल और टूल परिणाम (सर्च परिणाम, डेटाबेस लुकअप, फ़ाइल एक्सट्रैक्ट)
- एरर, रीट्राई, और रेट-लिमिट बैकऑफ़
क्यों AI ऐप्स में ज्यादा घटक चलते हैं
पारंपरिक ऐप्स अक्सर डेटा पढ़ते हैं, दिखाते हैं और अपडेट सेव करते हैं। AI ऐप्स अतिरिक्त चरण और मध्यवर्ती आउटपुट जोड़ते हैं:
- एक अकेला यूज़र एक्शन कई बैकएंड ऑपरेशंस ट्रिगर कर सकता है (LLM कॉल, टूल कॉल, फिर से LLM कॉल)।
- प्रतिक्रियाएँ क्रमिक रूप से आ सकती हैं (स्ट्रीमिंग टोकन), इसलिए UI को आंशिक स्टेट संभालना होगा।
- संदर्भ मायने रखता है: सिस्टम को संवाद मेमोरी, टूल आउटपुट और मॉडल सेटिंग्स अनुरोधों के बीच संगत रखने की ज़रूरत हो सकती है।
यही अतिरिक्त गतिशीलता AI एप्लिकेशन्स में स्टेट मैनेजमेंट को अक्सर छिपी हुई जटिलता बनाती है।
इस गाइड में क्या मिलेगा
आगे के सेक्शनों में हम स्टेट को व्यवहारिक श्रेणियों (UI स्टेट, सत्र स्टेट, परज़istí डेटा, और मॉडल/रनटाइम स्टेट) में बाँटेंगे, और दिखाएंगे कि हर एक कहाँ रहना चाहिए (फ्रंटेंड बनाम बैकएंड)। साथ ही सिंकिंग, कैशिंग, लंबी-चलने वाली जॉब्स, स्ट्रीमिंग अपडेट्स, और सुरक्षा को भी कवर करेंगे—क्योंकि स्टेट तभी उपयोगी है जब वह सही और सुरक्षित हो।
एक त्वरित उदाहरण परिदृश्य
कल्पना करें एक चैट ऐप जहाँ उपयोगकर्ता पूछता है: “पिछले महीने के इनवॉइस का सारांश दो और कोई असामान्य चीज़ फ्लैग करो।” बैकएंड ऐसा कर सकता है: (1) इनवॉइस लाना, (2) एक विश्लेषण टूल चलाना, (3) सारांश UI को स्ट्रीम करना, और (4) अंतिम रिपोर्ट सेव करना।
इसके सहज अनुभव के लिए, ऐप को संदेशों, टूल परिणामों, प्रगति, और सेव किए गए आउटपुट को ट्रैक करना होगा—बिना बातचीतों को मिलाए या उपयोगकर्ताओं के बीच डेटा लीक किए।
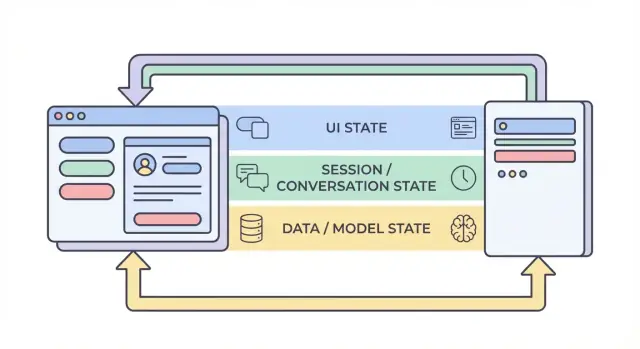
चार स्तर जहाँ स्टेट रहता है: UI, सत्र, डेटा, और मॉडल
जब लोग किसी AI ऐप में "स्टेट" कहते हैं, तो अक्सर वे बहुत अलग चीज़ों को मिला देते हैं। स्टेट को चार परतों में बाँटना—UI, सत्र, डेटा, और मॉडल/रuntime—निर्णय को आसान बनाता है कि किसी चीज़ को कहाँ रखना चाहिए, कौन उसे बदल सकता है, और कैसे उसे स्टोर करना चाहिए।
1) UI स्टेट (जो उपयोगकर्ता अभी कर रहा है)
UI स्टेट ब्राउज़र या मोबाइल ऐप में लाइव, पल-दर-पल की स्थिति है: टेक्स्ट इनपुट, टॉगल्स, चयनित आइटम, कौन-सा टैब खुला है, और क्या कोई बटन डिसेबल है।
AI ऐप्स कुछ UI-विशेष विवरण जोड़ते हैं:
- लोडिंग संकेतक और “सोचना” की स्थिति
- स्ट्रीम किए गए टोकन (उत्पन्न होते ही आ रहा आंशिक टेक्स्ट)
- लोकल ड्राफ्ट मैसेज (जब तक वे भेजे नहीं जाते)
UI स्टेट को रीसेट करना आसान होना चाहिए और खो जाना सुरक्षित होना चाहिए। अगर उपयोगकर्ता पेज रीफ़्रेश कर दे, तो आप यह खो सकते हैं—और अक्सर यह ठीक होता है।
2) सत्र / संवाद स्टेट (उपयोगकर्ता के फ्लो के लिए साझा संदर्भ)
सत्र स्टेट उपयोगकर्ता को एक चल रही बातचीत से जोड़ता है: उपयोगकर्ता पहचान, एक conversation ID, और संदेश इतिहास का एक संगत दृश्य।
AI ऐप्स में यह अक्सर शामिल होता है:
- संदेश इतिहास (या उसके संदर्भ)
- टूल ट्रेस (कौन-से फ़ंक्शन/टूल कॉल हुए और क्या परिणाम मिला)
- "वर्किंग सेट" विकल्प जैसे वर्तमान प्रोजेक्ट/दस्तावेज़, चयनित मॉडल, या वर्कस्पेस
यह परत अक्सर फ्रंटेंड और बैकएंड दोनों में फैली होती है: फ्रंटेंड हल्के आइडेंटिफ़ायर्स रखता है, जबकि बैकएंड सत्र निरंतरता और एक्सेस कंट्रोल के लिए प्राधिकरण होता है।
3) डेटा स्टेट (स्टोरेज में टिकाऊ रिकॉर्ड)
डेटा स्टेट वह है जिसे आप जानबूझकर डेटाबेस में स्टोर करते हैं: प्रोजेक्ट, दस्तावेज़, एम्बेडिंग, प्रेफ़रेंसेज़, ऑडिट लॉग, बिलिंग इवेंट्स, और सेव किए गए वार्तालाप ट्रांसक्रिप्ट।
UI और सत्र स्टेट के विपरीत, डेटा स्टेट होना चाहिए:
- टिकाऊ (रिस्टार्ट से बचता है)
- क्वेरी करने योग्य (आप उसे खोज/फिल्टर कर सकें)
- ऑडिटेबल (बाद में आप समझ सकें क्या हुआ)
4) मॉडल / रंटाइम स्टेट (AI अभी कैसे कॉन्फ़िगर है)
मॉडल/रनटाइम स्टेट वह ऑपरेशनल सेटअप है जिसका उपयोग उत्तर उत्पन्न करने के लिए किया जाता है: सिस्टम प्रॉम्प्ट, सक्षम टूल, temperature/max tokens, सुरक्षा सेटिंग्स, रेट लिमिट्स, और अस्थायी कैश।
इनमें से कुछ कॉन्फ़िगरेशन हैं (स्थिर डिफ़ॉल्ट); कुछ अल्पजीवी हैं (शॉर्ट-लाइव्ड कैश या पर-रिक्वेस्ट टोकन बजट)। इनका अधिकतर बैकएंड पर होना चाहिए ताकि इन्हें लगातार नियंत्रित किया जा सके और अनावश्यक रूप से एक्सपोज़ न किया जाए।
अलगाव क्यों बग घटाता है
जब ये परतें मिल जाती हैं, तो आपको क्लासिक फ़ेलियर्स मिलते हैं: UI वह दिखाता है जो सेव नहीं हुआ, बैकएंड अलग प्रॉम्प्ट सेटिंग्स इस्तेमाल करता है, या संवाद मेमोरी उपयोगकर्ताओं के बीच लीक हो जाती है। स्पष्ट सीमाएँ स्रोत-of-truth को क्लियर बनाती हैं—और यह स्पष्ट करती हैं कि क्या पीर्सिस्ट करना है, क्या फिर से गणना किया जा सकता है, और क्या सुरक्षित रखना है।
फ्रंटेंड बनाम बैकएंड: क्या कहाँ रहता है (और क्यों)
हर स्टेट-पीस के लिए एक विश्वसनीय नियम यह तय करना है कि वह ब्राउज़र (फ्रंटेंड), सर्वर (बैकएंड), या दोनों में कहाँ रहेगा। यह निर्णय विश्वसनीयता, सुरक्षा, और वापिस-रिफ्रेश/नई टैब/नेटवर्क लॉस के दौरान ऐप का व्यवहार प्रभावित करता है।
फ्रंटेंड स्टेट: तेज़, अस्थायी, और उपयोगकर्ता-चालित
फ्रंटेंड स्टेट उन चीज़ों के लिए सबसे उपयुक्त है जो तेजी से बदलती हैं और जिन्हें रीफ़्रेश के बाद बचाए रखना जरूरी नहीं है। इसे लोकल रखने से UI प्रतिक्रियाशील रहता है और अनावश्यक API कॉल्स से बचता है।
सामान्य फ्रंटेंड-ओनली उदाहरण:
- उपयोगकर्ता टाइप कर रहा ड्राफ्ट संदेश टेक्स्ट
- लोकल फ़िल्टर और टेबल में सॉर्ट ऑर्डर
- मॉडल ओपन/क्लोज़ स्टेट, चयनित टैब, होवर स्टेट्स
अगर आप यह स्टेट रीफ़्रेश पर खो देते हैं, तो आमतौर पर यह स्वीकार्य है।
बैकएंड स्टेट: अधिकारिक, संवेदनशील, और साझा
बैकएंड स्टेट वह रखना चाहिए जिसे भरोसा किया जाना चाहिए, ऑडिट किया जाना चाहिए, या जो लगातार लागू होना चाहिए। इसमें वह स्टेट आता है जिसे अन्य डिवाइस/टैब्स को देखना चाहिए, या जो तब भी सही रहना चाहिए जब क्लाइंट मॉडिफ़ाय किया गया हो।
सामान्य बैकएंड-ओनली उदाहरण:
- परमीशन और रोल्स (उपयोगकर्ता क्या कर सकता है)
- बिलिंग/सदस्यता स्थिति और उपयोग सीमाएँ
- लंबी-चलने वाली जॉब्स (दस्तावेज़ इंडेक्सिंग, बड़े एक्सपोर्ट, फाइन-ट्यून रन) और उनका स्टेट
एक अच्छा माइंडसेट: अगर गलत स्टेट से पैसे का नुकसान, डेटा लीक, या एक्सेस कंट्रोल टूट सकता है, तो वह बैकएंड में ही होना चाहिए।
साझा स्टेट: समन्वित, पर एक स्रोत-ऑफ-ट्रुथ के साथ
कुछ स्टेट नेचुरल रूप से साझा होते हैं:
- बातचीत का शीर्षक
- किसी चैट के लिए चुने गए नॉलेज सोर्सेज
- उपयोगकर्ता प्रोफ़ाइल फ़ील्ड जो कई डिवाइस पर काम आते हैं
साझा होने पर भी एक "स्रोत-ऑफ-ट्रुथ" चुनें। सामान्यतः बैकएंड अधिकारिक होता है और फ्रंटेंड स्पीड के लिए उसकी कॉपी कैश करता है।
नियम की अंगुली (और एक सामान्य एंटी-पैटर्न)
स्टेट को जहाँ सबसे ज़रूरी हो वहाँ रखें, लेकिन जो चीज़ रीफ़्रेश, डिवाइस परिवर्तन, या व्यवधानों से बचनी चाहिए उसे परज़िस्त करें।
सेंसिटिव या अधिकारिक स्टेट को केवल ब्राउज़र में स्टोर करने के एंटी-पैटर्न से बचें (उदा., क्लाइंट-साइड isAdmin फ्लैग, प्लान टीयर, या जॉब कम्पलीशन स्टेट को सच मान लेना)। UI इन्हें दिखा सकता है, पर बैकएंड को उन्हें सत्यापित करना चाहिए।
एक सामान्य AI अनुरोध लाइफसाइकल: क्लिक से पूरा होने तक
एक AI फीचर "एक क्रिया" जैसा लगता है, पर वास्तव में यह ब्राउज़र और सर्वर के बीच स्टेट परिवर्तन की एक श्रृंखला है। लाइफसाइकल को समझने से मिस्टमैच्ड UI, गायब संदर्भ, और डुप्लिकेट चार्जेज से बचा जा सकता है।
1) उपयोगकर्ता क्रिया → फ्रंटेंड इरादा तैयार करता है
उपयोगकर्ता Send क्लिक करता है। UI तुरंत लोकल स्टेट अपडेट करता है: यह एक "पेंडिंग" संदेश बबल जोड़ सकता है, सेंड बटन डिसेबल कर सकता है, और वर्तमान इनपुट्स (टेक्स्ट, अटैचमेंट, चुने गए टूल) कैप्चर कर सकता है।
इस बिंदु पर फ्रंटेंड को सह-संबंध पहचानकर्ता जेनरेट या अटैच करने चाहिए:
- conversation_id: किस थ्रेड से यह संबंधित है
- message_id: नए उपयोगकर्ता संदेश के लिए क्लाइंट का ID
- request_id: हर कोशिश के लिए यूनिक (रीट्राई के लिए उपयोगी)
ये IDs दोनों पक्षों को एक ही इवेंट के बारे में बात करने देते हैं, भले ही प्रतिक्रियाएँ लेट आएं या दोहराई जाएं।
2) API कॉल → सर्वर वैलिडेट और परज़िस्त करता है
फ्रंटेंड एक API रिक्वेस्ट भेजता है उपयोगकर्ता संदेश और IDs के साथ। सर्वर परमिशन्स, रेट लिमिट्स, और पेलोड शेप को वैलिडेट करता है, फिर उपयोगकर्ता संदेश को परज़िस्त करता है (या कम से कम एक अपरिवर्तनीय लॉग रेकॉर्ड) जिसे conversation_id और message_id से की- किया गया हो।
यह परज़िस्टेंस स्टेप "फैंटम इतिहास" को रोकता है जब उपयोगकर्ता बीच-रिक्वेस्ट पेज रीफ़्रेश कर दे।
3) सर्वर सन्दर्भ पुनर्निर्मित करता है
मॉडल को कॉल करने के लिए, सर्वर अपने स्रोत-ऑफ-ट्रुथ से संदर्भ फिर से बनाता है:
conversation_idके लिए हाल के संदेश लाना- संबंधित रिकॉर्ड खींचना (दस्तावेज़, प्रेफ़रेंसेज़, टूल आउटपुट)
- बातचीत की नीतियाँ लागू करना (सिस्टम प्रॉम्प्ट, मेमोरी नियम, ट्रंकैशन)
मुख्य विचार: क्लाइंट पर पूरा इतिहास निर्भर न करें। क्लाइंट स्टेल हो सकता है।
4) मॉडल/टूल निष्पादन → मध्यवर्ती स्टेट
सर्वर टूल्स (सर्च, डेटाबेस क्वेरी) कॉल कर सकता है मॉडल जनरेशन से पहले या दौरान। हर टूल कॉल एक मध्यवर्ती स्टेट उत्पन्न करती है जिसे request_id के खिलाफ ट्रैक किया जाना चाहिए ताकि उसे ऑडिट और सुरक्षित रीट्राई किया जा सके।
5) प्रतिक्रिया (स्ट्रीमिंग या नहीं) → UI पूर्णता
स्ट्रीमिंग के साथ, सर्वर आंशिक टोकन/इवेंट भेजता है। UI पेंडिंग असिस्टेंट संदेश को धीरे-धीरे अपडेट करता है, पर इसे “इन प्रोग्रेस” तब तक मानता है जब तक कोई फाइनल इवेंट पूरा होने का संकेत न दे।
6) विफलताओं की योजना बनाएं
रीट्राईज़, डबल-सबमिट्स, और आउट-ऑफ-ऑर्डर प्रतिक्रियाएँ होती हैं। सर्वर पर डीडुप करने के लिए request_id का उपयोग करें, और UI में सुलह करने के लिए message_id का उपयोग करें (एक्टिव रिक्वेस्ट से मेल न खाने वाले लेट चंक्स को इग्नोर करें)। हमेशा एक स्पष्ट “failed” स्थिति दिखाएँ और एक सुरक्षित रीट्राइ दें जो डुप्लिकेट संदेश उत्पन्न न करे।
सत्र और संवाद मेमोरी: संदर्भ रखना बिना अराजकता के
बनाते समय क्रेडिट कमाएँ
Koder.ai पर जो आप शिप करते हैं शेयर करें या teammates को रेफर करें और अतिरिक्त क्रेडिट पाएं.
एक सत्र वह "थ्रेड" है जो उपयोगकर्ता की कार्रवाईयों को जोड़ता है: वे किस वर्कस्पेस में हैं, उन्होंने आख़िरी क्या खोजा, वे किस ड्राफ्ट को एडिट कर रहे थे, और किस बातचीत को AI रिप्लाई जारी रखना चाहिए। अच्छा सत्र स्टेट पेजों के बीच ऐप को सतत महसूस कराता है—और आदर्श रूप में डिवाइसों के बीच भी—बशर्ते आपका बैकएंड हर चीज़ का अपशिष्ट-भंडार न बन जाए।
सत्र स्टेट के लक्ष्य
इन लक्ष्यों का पालन करें: (1) निरंतरता (उपयोगकर्ता छोड़ सके और वापस आ सके), (2) सठीकता (AI सही संदर्भ उपयोग करे), और (3) पृथक्करण (एक सत्र दूसरे में लीक न हो)। यदि आप मल्टीपल डिवाइसेस सपोर्ट करते हैं, तो सत्र को उपयोगकर्ता-स्तर + डिवाइस-स्तर मानें: "वही अकाउंट" हमेशा "वही खुला काम" नहीं होता।
कुकीज़ बनाम टोकन बनाम सर्वर सत्र
सत्र की पहचान के लिए आप आमतौर पर इनमें से एक चुनते हैं:
- Cookies: वेब ऐप्स के लिए सबसे सरल क्योंकि ब्राउज़र उन्हें ऑटोमैटिक भेज देता है। ट्रेडिशनल सत्रों के लिए बढ़िया, पर
HttpOnly,Secure,SameSiteजैसे सिक्योर फ्लैग्स सेट करें और CSRF का ध्यान रखें। - Tokens (उदा., JWT): APIs और मोबाइल ऐप्स के लिए अच्छे क्योंकि क्लाइंट उन्हें स्पष्ट रूप से जोड़ सकता है। ये स्केल करते हैं, पर रिवोकेशन और रोटेशन के लिए अतिरिक्त डिज़ाइन चाहिए (और संवेदनशील स्टेट को टोकन में न भरें)।
- Server sessions: सर्वर सत्र डेटा स्टोर करता है (अक्सर Redis), और क्लाइंट केवल एक अस्पष्ट सत्र ID रखता है। रिवोक और अपडेट करना आसान है, पर आपको सत्र स्टोर चलाना और स्केल करना होगा।
संवाद मेमोरी रणनीतियाँ
"मेमोरी" बस वह स्टेट है जिसे आप मॉडल में वापस भेजने का चुनाव करते हैं।
- पूर्ण इतिहास: सबसे सटीक, पर महँगा और पुराना संवेदनशील कंटेंट सतह पर ला सकता है।
- सारांशित इतिहास: एक चल रहा सारांश रखें और कुछ हाल के टर्न; सस्ता और अक्सर काफी होता है।
- विंडोड संदर्भ: केवल आख़िरी N संदेश; सबसे सरल, पर ज़रूरी पिछली जानकारियाँ खो सकती हैं।
एक व्यवहारिक पैटर्न है सारांश + विंडो: यह अनुमान्य है और अप्रत्याशित मॉडल व्यवहार से बचाता है।
टूल कॉल्स: पुनरावृत्ति योग्य और ऑडिटेबल
यदि AI टूल्स (सर्च, DB क्वेरी, फ़ाइल रीड्स) का उपयोग करता है, तो हर टूल कॉल स्टोर करें: इनपुट्स, टाइमस्टैम्प, टूल वर्ज़न, और लौटाया गया आउटपुट (या उसका रेफरेंस)। इससे आप समझा सकेंगे "AI ने ऐसा क्यों कहा", डिबग के लिए रन को फिर से चला पाएंगे, और पता कर पाएंगे जब परिणाम किसी टूल या डेटासेट बदलने की वजह से बदले हों।
प्राइवेसी गार्डरिल्स
डिफ़ॉल्ट रूप से लंबी-आयु वाली मेमोरी न रखें। केवल वही रखें जो निरंतरता के लिए ज़रूरी हो (conversation IDs, सारांश, और टूल लॉग्स), रिटेंशन लिमिट सेट करें, और कच्चे उपयोगकर्ता टेक्स्ट को तभी परज़िस्त करें जब उत्पाद कारण और उपयोगकर्ता की सहमति स्पष्ट हो।
स्टेट को सुरक्षित तरीके से सिंक करना: स्रोत-ऑफ-ट्रुथ और संघर्ष हैंडलिंग
जब वही "चीज़" कई जगह संपादित हो सकती है—आपका UI, दूसरी टैब, या बैकग्राउंड जॉब—तो स्टेट रिस्की हो जाता है। समाधान चालाक कोड से कम और स्पष्ट मालिकाना निर्धारित करने से ज्यादा जुड़ा है।
स्रोत-ऑफ-ट्रुथ परिभाषित करें
निर्णय लें कि किस सिस्टम के पास प्रत्येक स्टेट का अधिकार है। अधिकांश AI एप्लिकेशन्स में, बैकएंड को किसी भी ऐसी चीज़ का कैनोनिकल रिकॉर्ड रखना चाहिए जो सही होनी चाहिए: बातचीत सेटिंग्स, टूल अनुमतियाँ, संदेश इतिहास, बिलिंग सीमाएँ, और जॉब स्टेट। फ्रंटेंड स्पीड के लिए कैश और व्युत्पन्न स्टेट रख सकता है (चुनिंदा टैब, ड्राफ्ट प्रॉम्प्ट टेक्स्ट, "is typing" संकेतक), पर असंगति होने पर फ्रंटेंड को मान लेना चाहिए कि बैकएंड सही है।
एक व्यवहारिक नियम: अगर आप इसे रीफ़्रेश पर खो देने से दुखी होंगे, तो शायद वह बैकएंड में होना चाहिए।
आशावादी UI अपडेट्स (सावधानी से प्रयोग करें)
Optimistic updates ऐप को त्वरित बनाते हैं: कोई सेटिंग टॉगल करें, UI तुरंत अपडेट हो जाए, फिर सर्वर से पुष्टि हो। यह कम-जोखिम, उलटने योग्य क्रियाओं के लिए अच्छा है (उदा., किसी बातचीत को स्टार करना)।
यह भ्रम पैदा करता है जब सर्वर अस्वीकार कर सकता है या बदलाव को बदल सकता है (पैमिशन चेक, क्वोटा लिमिट, वैलिडेशन, या सर्वर-साइड डिफ़ॉल्ट)। ऐसे मामलों में, "saving..." स्टेट दिखाएँ और केवल पुष्टि के बाद UI अपडेट करें।
संघर्षों को हैंडल करना (दो टैब, एक बातचीत)
संघर्ष तब होते हैं जब दो क्लाइंट उसी रिकॉर्ड को अलग-अलग प्रारंभिक वर्ज़न के आधार पर अपडेट करते हैं। आम उदाहरण: टैब A और टैब B दोनों मॉडल टेम्परेचर बदलते हैं।
बैकएंड को स्टेल राइट्स का पता लगाने के लिए हल्का वर्ज़निंग इस्तेमाल करें:
updated_atटाइमस्टैम्प (सरल, मानव-डिबग योग्य)- ETags /
If-Matchहेडर (HTTP-नैटिव) - बढ़ती हुई संशोधन संख्याएँ (स्पष्ट संघर्ष-डिटेक्शन)
अगर वर्ज़न मेल नहीं खाती, तो एक कॉन्फ्लिक्ट रिस्पॉन्स लौटाएँ (अक्सर HTTP 409) और नवीनतम सर्वर ऑब्जेक्ट वापस भेजें।
API डिज़ाइन से मिस्टमैच घटाएँ
किसी भी लिखने के बाद, API को सेव किए गए ऑब्जेक्ट को वापस करें (सर्वर-जनित डिफ़ॉल्ट्स, नॉर्मलाइज़्ड फ़ील्ड्स, और नया वर्ज़न सहित)। इससे फ्रंटेंड अपनी कैश कॉपी तुरंत बदल सके—एक बार में स्रोत-ऑफ-ट्रुथ अपडेट, बजाय इसके कि वह अनुमान लगाए कि क्या बदला।
कैशिंग और प्रदर्शन: तेज़ी बिना स्टेल स्टेट के
कैशिंग AI ऐप को तुरंत महसूस कराने का एक तेज़ तरीका है, पर यह भी स्टेट की एक दूसरी कॉपी बनाता है। गलत चीज़ कैश करना—या गलत जगह कैश करना—ऐसा UI देगा जो तेज़ पर कन्फ्यूज़िंग लगेगा।
क्लाइंट पर क्या कैश करें
क्लाइंट-साइड कैशेज़ अनुभव पर केंद्रित होने चाहिए, न कि अधिकार पर। अच्छे उम्मीदवार:
- हाल की बातचीत प्रीव्यू (शीर्षक, आख़िरी संदेश स्निपेट)
- UI प्रेफ़रेंसेज़ (थीम, चुना हुआ मॉडल, साइडबार स्टेट)
- ऑप्टिमिस्टिक UI स्टेट ("sending" वाले संदेश)
क्लाइंट कैश छोटा और डिस्पोज़ेबल रखें: अगर यह साफ़ हो जाए तो भी ऐप सर्वर से रीफ़ेच करके काम करना चाहिए।
सर्वर पर क्या कैश करें
सर्वर कैश उन महँगे या बार-बार दोहराए जाने वाले कामों पर केंद्रित होना चाहिए:
- ऐसे टूल परिणाम जो पुन:उपयोग के लिए सुरक्षित हैं (उदा., किसी शहर के लिए मौसम लुकअप 5 मिनट के भीतर)
- एम्बेडिंग लुकअप और वेक्टर सर्च परिणाम बार-बार पूछे जाने वाले क्वेरीज के लिए (अक्सर छोटे TTL के साथ)
- रेट-लिमिट स्टेट और थ्रॉटलिंग काउंटर (API व लागत की सुरक्षा के लिए)
यहां आप व्युत्पन्न स्टेट भी कैश कर सकते हैं जैसे टोकन काउंट्स, मॉडरेशन फैसले, या दस्तावेज़ पार्सिंग आउटपुट—कुछ भी निर्धारक और महँगा।
कैश इनवैलिडेशन बेसिक्स (ज्यादा जटिल न बनें)
तीन व्यवहारिक नियम:
- स्पष्ट कैश कीज़ इस्तेमाल करें जो इनपुट्स एन्कोड करें (
user_id, model, टूल पैरामीटर्स, दस्तावेज़ वर्ज़न)। - underlying डेटा कितनी जल्दी बदलता है उसके आधार पर TTL सेट करें। छोटा TTL समझदारी है।
- जब सठीकता स्पीड से ज़्यादा मायने रखती हो तो कैश बाईपास करें: उपयोगकर्ता ने दस्तावेज़ अपडेट किया, अनुमतियाँ बदली, या रिफ्रेश माँगा।
अगर आप समझा नहीं पा रहे कि कब कोई कैश एंट्री गलत हो जाएगी, तो उसे कैश मत करें।
साझा कैश में सीक्रेट्स या पर्सनल डेटा न रखें
शेयर्ड लेयर्स जैसे CDN में API कीज़, ऑथ टोकन, कच्चे प्रॉम्प्ट जिनमें संवेदनशील टेक्स्ट हो, या उपयोगकर्ता-विशिष्ट कंटेंट कैश न करें। यदि उपयोगकर्ता डेटा कैश करना ही आवश्यक है, तो उपयोगकर्ता के अनुसार अलग रखें और एट-रेस्ट एन्क्रिप्ट करें—या उसे प्राथमिक डेटाबेस में रखें।
प्रभाव नापें: स्पीड बनाम स्टेल UI
कैशिंग मानकर न करें—इसे साबित करें। p95 लेटेंसी, कैश हिट रेट, और उपयोगकर्ता-दिखने वाली त्रुटियाँ ट्रैक करें जैसे "रेंडरिंग के बाद संदेश अपडेट हुआ"। बाद में विरोधाभासी UI के साथ तेज़ रिस्पॉन्स अक्सर धीमा पर संगत होना से बदतर होता है।
परज़िस्टेंस और लंबी-चलने वाली वर्क: जॉब्स, कतारें, और स्टेट ऑफ़ स्टेटस
Rollback सुरक्षा के साथ शिप करें
Snapshots और rollback के साथ Koder.ai में स्टेट बदलाव आत्मविश्वास के साथ लागू करें.
कुछ AI फीचर सेकंड में पूरा हो जाते हैं। अन्य मिनट लेते हैं: PDF अपलोड और पार्सिंग, नॉलेज बेस का एम्बेडिंग और इंडेक्सिंग, या बहु-चरण टूल वर्कफ़्लो। इन मामलों में, "स्टेट" सिर्फ स्क्रीन पर नहीं है—यह वह चीज़ है जो रीफ़्रेश, रीट्राईज़ और समय के पार बचती है।
क्या परज़िस्ट करें (और क्यों)
केवल वही परज़िस्ट करें जो असल उत्पाद मान देता है।
संवाद इतिहास स्पष्ट है: संदेश, टाइमस्टैम्प, उपयोगकर्ता पहचान, और (अक्सर) कौन-सा मॉडल/टूल इस्तेमाल हुआ। यह "बाद में.resume" करने, ऑडिट ट्रेल, और बेहतर सपोर्ट के लिए ज़रूरी है।
उपयोगकर्ता और वर्कस्पेस सेटिंग्स डेटाबेस में होनी चाहिए: पसंदीदा मॉडल, temperature डिफ़ॉल्ट, फ़ीचर टॉगल्स, सिस्टम प्रॉम्प्ट, और UI प्रेफ़रेंसेज़ जो उपयोगकर्ता के साथ डिवाइसेज़ पर फॉलो करें।
फ़ाइलें और आर्टिफैक्ट्स (अपलोड, एक्स्ट्रैक्ट किया गया टेक्स्ट, जेनरेटेड रिपोर्ट) आमतौर पर ऑब्जेक्ट स्टोरेज में रखे जाते हैं और डेटाबेस रिकॉर्ड उनसे पॉइंट करते हैं। डेटाबेस मेटाडेटा रखता है (ओनर, साइज, कंटेंट टाइप, प्रोसेसिंग स्टेट), जबकि ब्लॉब स्टोर बाइट्स रखता है।
लंबी टास्क के लिए बैकग्राउंड जॉब्स
यदि कोई अनुरोध सामान्य HTTP टाइमआउट के भीतर भरोसेमंद तरीके से पूरा नहीं हो सकता, तो काम को कतार में डालें।
एक आम पैटर्न:
- फ्रंटेंड
POST /jobsजैसे API को इनपुट्स के साथ कॉल करता है (file id, conversation id, parameters)। - बैकएंड एक जॉब एनक्यू करता है (एक्स्ट्रैक्शन, इंडेक्सिंग, बैच टूल रन) और तुरंत
job_idलौटाता है। - वर्कर्स असिंक्रोनस रूप से जॉब प्रोसेस करते हैं और परिणाम को परज़िस्टेंट स्टोरेज में लिखते हैं।
यह UI को प्रतिक्रियाशील रखता है और रीट्राईज़ को सुरक्षित बनाता है।
UI भरोसा कर सकने योग्य स्टेटस
जॉब स्टेट स्पष्ट और क्वेरीयोग्य रखें: queued → running → succeeded/failed (वैकल्पिक रूप से canceled)। इन ट्रांज़िशंस को सर्वर-साइड पर टाइमस्टैम्प और एरर डिटेल्स के साथ स्टोर करें।
फ्रंटेंड पर स्टेट स्पष्ट रूप से दिखाएँ:
- Queued/running: स्पिनर दिखाएँ और डुप्लिकेट क्रियाओं को डिसेबल करें।
- Failed: संक्षेप एरर दिखाएँ, और एक Retry बटन दें।
- Succeeded: परिणामों को लोड करें या बातचीत अपडेट करें।
GET /jobs/{id} (पोलिंग) या SSE/WebSocket जैसे स्ट्रीम अपडेट एक्सपोज़ करें ताकि UI को अनुमान न लगाना पड़े।
Idempotency keys: रीट्राई बिना डुप्लिकेट लिखावट
नेटवर्क टाइमआउट होते हैं। यदि फ्रंटेंड POST /jobs को रीट्राई करता है, तो आप दो समान जॉब नहीं चाहते (और दो बिल)।
प्रत्येक तार्किक क्रिया के लिए एक Idempotency-Key आवश्यक करें। बैकएंड की-को job_id/रिस्पॉन्स के साथ स्टोर करे और दोहराव पर वही परिणाम लौटाए।
क्लीनअप और एक्सपिरेशन नीतियाँ
लंबी-चलने वाले AI ऐप तेज़ी से डेटा जमा कर लेते हैं। जल्दी रिटेंशन नियम निर्धारित करें:
- पुरानी बातचीत N दिनों के बाद एक्सपायर करें (या उपयोगकर्ता को कन्फ़िगर करने दें)।
- स्रोत हटाए जाने पर व्युत्पन्न आर्टिफैक्ट्स हटाएँ।
- समय-समय पर फेल हुए जॉब्स और मध्यवर्ती फ़ाइलें पर्ज़ करें।
क्लीनअप को स्टेट मैनेजमेंट का हिस्सा मानें: यह जोखिम, लागत, और भ्रम कम करता है।
स्ट्रीमिंग प्रतिक्रियाएँ और रियल-टाइम अपडेट: आंशिक स्टेट संभालना
स्ट्रीमिंग स्टेट को और जटिल बनाती है क्योंकि "उत्तर" अब एक सिंगल ब्लॉब नहीं रहा। आप आंशिक टोकन (टेक्स्ट शब्द-दर-शब्द आना) और कभी-कभी आंशिक टूल वर्क (सर्च शुरू होता है, फिर बाद में खत्म होता है) से निपट रहे होते हैं। इसका अर्थ यह है कि आपका UI और बैकएंड यह सहमत हों कि अस्थायी बनाम अंतिम स्टेट क्या है।
बैकएंड: सिर्फ टेक्स्ट नहीं, टाइप्ड इवेंट्स स्ट्रीम करें
एक साफ़ पैटर्न है कि आप छोटे-छोटे इवेंट्स की सीक्वेंस स्ट्रीम करें, हर एक का एक प्रकार और पेलोड हो। उदाहरण के लिए:
token: क्रमिक टेक्स्ट (या छोटा चंक)tool_start: किसी टूल कॉल की शुरुआत (उदा., “Searching…”, id के साथ)tool_result: टूल आउटपुट तैयार है (उसी id के साथ)done: असिस्टेंट संदेश पूरा हैerror: कुछ फेल हुआ (एक उपयोगकर्ता-सुरक्षित संदेश और एक डिबग id शामिल करें)
यह इवेंट स्ट्रीम कच्चे टेक्स्ट स्ट्रीमिंग से अधिक वर्ज़नेबल और डिबग करने में आसान है, क्योंकि फ्रंटेंड प्रोग्रेस को सही तरीके से रेंडर कर सकता है (और टूल स्टेट दिखा सकता है) बिना अटकने के।
फ्रंटेंड: अपेंड-ओनली अपडेट्स, फिर फाइनल कमिट
क्लाइंट पर, स्ट्रीमिंग को अपेंड-ओनली मानें: एक "ड्राफ्ट" असिस्टेंट संदेश बनाएं और जैसे-जैसे token इवेंट्स आएँ उसे बढ़ाते जाएँ। जब आप done प्राप्त करें, तब कमिट करें: संदेश को फाइनल मार्क करें, अगर आप लोकली स्टोर करते हैं तो परज़िस्ट करें, और कॉपी/रेट/रिजेनरेट जैसे एक्शन अनलॉक करें।
यह इतिहास को स्ट्रीम के बीच फिर से लिखने से रोकता है और UI को अनुमान्य रखता है।
व्यवधानों का हैंडलिंग (कैंसिल, ड्रॉप्स, टाइमआउट)
स्ट्रीमिंग अध-पूर्ण काम की संभावना बढ़ाती है:
- उपयोगकर्ता कैंसिल करता है: कैंसिल सिग्नल भेजें; टोकन्स रेंडर करना बंद करें; ड्राफ्ट को स्पष्ट रूप से कैंसिल दिखाएँ।
- नेटवर्क ड्रॉप्स: स्ट्रीम रुक जाए; "reconnecting..." दिखाएँ और पूरा मानकर न लें।
- सर्वर टाइमआउट/एरर्स: ड्राफ्ट को फेल के रूप में फाइनलाइज़ करें, और एक रीट्राइ दें जो नई रिक्वेस्ट शुरू करे (स्ट्रीम्स को चुपचाप जोड़ने की कोशिश न करें)।
रीहाइड्रेशन: रीलोड पर स्थिर स्टेट पुनर्निर्माण
अगर पेज मिड-स्ट्रीम रीलोड हो जाए, तो नवीनतम स्थिर स्टेट से पुनर्निर्माण करें: आख़िरी कमिटेड संदेश और किसी भी स्टोर किए गए ड्राफ्ट मेटाडेटा (message id, अब तक जमा टेक्स्ट, टूल स्टेट)। यदि आप स्ट्रीम को फिर से शुरू नहीं कर सकते, तो ड्राफ्ट को इंटरप्टेड दिखाएँ और उपयोगकर्ता को रीट्राइ करने दें, बजाय इसके कि आप उसे पूरा दिखाएं।
सुरक्षा और गोपनीयता: स्टेट का एंड-टू-एंड संरक्षण
एक streaming बैकएंड बनाएं
सिंपल चैट ब्रीफ़ से टाइप्ड SSE इवेंट्स, जॉब स्टेटस और idempotent APIs बनाएं.
स्टेट केवल "डेटा जो आप स्टोर करते हैं" नहीं है—यह उपयोगकर्ता के प्रॉम्प्ट्स, अपलोड्स, प्रेफ़रेंसेज़, जनरेटेड आउटपुट, और उन मेटाडेटा का समूह है जो सब कुछ जोड़ता है। AI ऐप्स में वह स्टेट असाधारण रूप से संवेदनशील हो सकता है (निजी जानकारी, स्वामित्व-प्रलेख, आंतरिक निर्णय), अतः सुरक्षा हर परत में डिज़ाइन करनी चाहिए।
सीक्रेट्स सर्वर पर रखें
जो भी चीज़ क्लाइंट को आपकी ऐप की नकल करने दे सकती है, उसे बैकएंड-ओनली रखें: API कीज़, प्राइवेट कनेक्टर्स (Slack/Drive/DB क्रेडेंशियल्स), और आंतरिक सिस्टम प्रॉम्प्ट या राउटिंग लॉजिक। फ्रंटेंड एक क्रिया माँग सकता है ("इस फ़ाइल का सारांश बनाओ"), पर बैकएंड तय करे कि यह कैसे और किस क्रेडेंशियल के साथ किया जाएगा।
हर राइट को ऑथराइज़ करें (और अधिकतर रीड्स)
हर स्टेट म्यूटेशन को एक संवेदनशील ऑपरेशन मानें। जब क्लाइंट कोई संदेश बनाए, बातचीत का नाम बदले, या फ़ाइल अटैच करे, तो बैकएंड यह सत्यापित करे:
- उपयोगकर्ता प्रमाणीकृत है।
- उपयोगकर्ता संसाधन का मालिक है (conversation, workspace, project)।
- उपयोगकर्ता वह क्रिया करने के लिए अनुमत है (रोल, प्लान लिमिट, संगठन नीति)।
यह "ID guessing" हमलों से बचाता है जहाँ कोई conversation_id बदलकर किसी और का इतिहास एक्सेस कर ले।
ब्राउज़र पर कभी भरोसा न करें: वैलिडेट और सैनिटाइज़ करें
किसी भी क्लाइंट-प्रोवाइडेड स्टेट को अनट्रस्टेड इनपुट मानकर चलें। स्कीमा और कंस्ट्रेंट्स (टाइप्स, लंबाई, अनुमत एनम्स) को वैलिडेट करें, और गंतव्य के अनुसार सैनिटाइज़ करें (SQL/NoSQL, लॉग्स, HTML रेंडरिंग)। यदि आप "स्टेट अपडेट्स" स्वीकार करते हैं (उदा., सेटिंग्स, टूल पैरामीटर्स), तो व्हाइटलिस्टेड फ़ील्ड ही स्वीकार करें बजाय इसके कि आप मनमाना JSON मर्ज करें।
महत्वपूर्ण क्रियाओं के लिए ऑडिट ट्रेल्स
वे क्रियाएँ जो परज़िस्टेंट स्टेट बदलती हैं—शेयरिंग, एक्सपोर्ट, डिलीट, कनेक्टर एक्सेस—उनके लिए रिकॉर्ड रखें कि किसने क्या और कब किया। हल्का ऑडिट लॉग incident response, कस्टमर सपोर्ट, और अनुपालन में मदद करता है।
डेटा मिनिमाइज़ेशन और एन्क्रिप्शन
वह ही स्टोर करें जो फीचर देने के लिए ज़रूरी है। अगर आपको हमेशा के लिए पूर्ण प्रॉम्प्ट्स की जरूरत नहीं है, तो रिटेंशन विंडोज़ या रेडैक्शन पर विचार करें। संवेदनशील स्टेट को आवश्यकतानुसार एट-रेस्ट एन्क्रिप्ट करें (टोकन, कनेक्टर क्रेड्स, अपलोड किए दस्तावेज़) और ट्रानज़िट में TLS का उपयोग करें। ऑपरेशनल मेटाडेटा को कंटेंट से अलग रखें ताकि आप अधिक कड़ा एक्सेस नियंत्रण लागू कर सकें।
व्यवहारिक संदर्भ आर्किटेक्चर और बिल्ड चेकलिस्ट
AI ऐप्स के लिए एक उपयोगी डिफ़ॉल्ट सरल है: बैकएंड स्रोत-ऑफ-ट्रुथ हो, और फ्रंटेंड तेज़, आशावादी कैश हो। UI इंस्टेंट लगे, पर कोई भी चीज़ जिसे आप खोने पर दुखी होंगे (संदेश, जॉब स्टेट, टूल आउटपुट, बिलिंग-संबंधी इवेंट) उसे सर्वर-साइड पर कन्फ़र्म और स्टोर किया जाना चाहिए।
यदि आप "vibe-coding" वर्कफ़्लो के साथ बना रहे हैं—जहाँ बहुत उत्पाद सतह तेजी से जनरेट होती है—तो स्टेट मॉडल और भी ज़्यादा महत्वपूर्ण हो जाता है। Koder.ai जैसे प्लेटफ़ॉर्म टीमों को चैट से पूरा वेब, बैकएंड, और मोबाइल ऐप तेज़ी से शिप करने में मदद करते हैं, पर वही नियम लागू होते हैं: तेज़ इटरेशन सुरक्षित तब है जब स्रोत-ऑफ-ट्रुथ, IDs, और स्टेटस ट्रांज़िशंस पहले से डिज़ाइन्ड हों।
संदर्भ आर्किटेक्चर (एक जिसे आप डिप्लॉय कर सकें)
Frontend (ब्राउज़र/मोबाइल)
- UI स्टेट: खुले पैनल, ड्राफ्ट प्रॉम्प्ट टेक्स्ट, चुना हुआ मॉडल, अस्थायी “typing” संकेतक।
- कैश्ड सर्वर स्टेट: हाल की बातचीतें, अंतिम ज्ञात जॉब स्टेट, आंशिक स्ट्रीम बफ़र।
- एक सिंगल रिक्वेस्ट पाइपलाइन हमेशा संलग्न करती है:
session_id,conversation_id, और नयाrequest_id।
Backend (API + वर्कर्स)
- API सेवा: इनपुट वैलिडेट करती है, रिकॉर्ड बनाती है, स्ट्रीमिंग रिस्पॉन्स देती है।
- टिकाऊ स्टोर (SQL/NoSQL): बातचीतें, संदेश, टूल कॉल्स, जॉब स्टेट।
- कतार + वर्कर्स: लंबी-चलने वाली टास्क (RAG इंडेक्सिंग, फ़ाइल पार्सिंग, इमेज जनरेशन)।
- कैश (वैकल्पिक): हॉट रीड्स (कन्वर्सेशन सारांश, एम्बेडिंग मेटाडेटा), हमेशा वर्ज़न/टाइमस्टैम्प के साथ की-वाले।
नोट: इसे सुसंगत रखने का एक व्यावहारिक तरीका है कि आप अपना बैकएंड स्टैक पहले से स्टैण्डर्डाइज़ कर लें। उदाहरण के लिए, Koder.ai-जनरेटेड बैकएंड आमतौर पर Go के साथ PostgreSQL (और फ्रंटेंड पर React) उपयोग करते हैं, जो SQL में अधिकारिक स्टेट को केंद्रीकृत करना और क्लाइंट कैश को डिस्पोज़ेबल रखना सरल बनाता है।
पहले अपना स्टेट मॉडल डिज़ाइन करें
स्क्रीन बनाने से पहले, उन फ़ील्ड्स को परिभाषित करें जिन पर आप हर परत में भरोसा करेंगे:
- IDs और ओनरशिप:
user_id,org_id,conversation_id,message_id,request_id. - टाइमस्टैम्प और क्रमबद्धता:
created_at,updated_at, और संदेशों के लिए एक स्पष्टsequence. - स्टेटस फ़ील्ड्स:
queued | running | streaming | succeeded | failed | canceled(जॉब्स और टूल कॉल्स के लिए)। - वर्ज़निंग:
etagयाversionसंघर्ष-सुरक्षित अपडेट्स के लिए।
यह क्लासिक बग रोकता है जहाँ UI "ठीक दिखता है" पर रीट्राईज़, रीफ़्रेश, या समवर्ती संपादनों का मेल नहीं बैठा पाता।
एकसार API शेप्स का उपयोग करें
फीचर्स के बीच एंडपॉइंट्स को अनुमान्य रखें:
GET /conversations(लिस्ट)GET /conversations/{id}(गेट)POST /conversations(क्रिएट)POST /conversations/{id}/messages(एपेंड)PATCH /jobs/{id}(स्टेटस अपडेट)GET /streams/{request_id}याPOST .../stream(स्ट्रीम)
हर जगह एक समान एंवेलप स्टाइल लौटाएँ (एरर्स सहित) ताकि फ्रंटेंड यूनिफॉर्मली स्टेट अपडेट कर सके।
जहाँ स्टेट टूट सकता है वहाँ ऑब्ज़रवेबिलिटी जोड़ें
हर AI कॉल के लिए request_id लॉग और लौटाएँ। टूल-कॉल इनपुट/आउटपुट (रेडक्शन के साथ), लेटेंसी, रीट्राईज़, और अंतिम स्टेट रिकॉर्ड करें। यह जवाब देना आसान बनाता है: "मॉडल ने क्या देखा, कौन से टूल रन हुए, और हमने क्या स्टोर किया?"
बिल्ड चेकलिस्ट (सामान्य स्टेट बग से बचने के लिए)
- बैकएंड स्रोत-ऑफ-ट्रुथ है; फ्रंटेंड कैश स्पष्ट और डिस्पोज़ेबल है।
- हर राइट idempotent है (रीट्राई करने पर सुरक्षित)
request_id(और/या Idempotency-Key) का उपयोग। - स्टेटस ट्रांज़िशंस स्पष्ट और वैलिडेटेड हैं (कोई चुप्पी से
queuedसेsucceededपर झपटा नहीं)। - स्ट्रीमिंग अपडेट्स IDs/sequence द्वारा मर्ज होते हैं, न कि "आख़िरी संदेश जीतता है" के नियम से।
- संघर्ष
version/etagया सर्वर-साइड मर्ज नियमों के जरिए हैंडल होते हैं। - PII और सीक्रेट्स कभी क्लाइंट स्टेट में नहीं; लॉग्स डिफ़ॉल्ट रूप से रेडैक्ट करें।
- डिबगिंग के लिए एक डैशबोर्ड हो: रिक्वेस्ट्स, टूल कॉल्स, जॉब स्टेट, और एरर्स।
जब आप तेज़ बिल्ड साइकिल (AI-असिस्टेड जनरेशन सहित) अपनाते हैं, तो इन चेकलिस्ट आइटम्स को ऑटोमैटिकली लागू करने वाले गार्डरेल जोड़ने पर विचार करें—स्कीमा वैलिडेशन, idempotency, और इवेंटेड स्ट्रीमिंग—ताकि "तेजी से आगे बढ़ना" स्टेट ड्रिफ्ट में परिवर्तित न हो। व्यवहार में, यही वह जगह है जहाँ Koder.ai जैसा एंड-टू-एंड प्लेटफ़ॉर्म उपयोगी हो सकता है: यह डिलीवरी को तेज़ करता है, जबकि आपको स्रोत कोड एक्सपोर्ट करने और वेब, बैकएंड, और मोबाइल बिल्ड्स में स्टेट-हैंडलिंग पैटर्न सुसंगत रखने की अनुमति देता है।