03 मई 2025·8 मिनट
AI-जनित प्रणालियों में वैलिडेशन, त्रुटियाँ और किनारे के मामले
सीखें कि AI-जनित वर्कफ़्लोज़ कैसे वैलिडेशन नियम, त्रुटि हैंडलिंग आवश्यकताएँ और कठिन एज‑केसेस उजागर करते हैं—साथ ही उनको टेस्ट, मॉनिटर और ठीक करने के व्यावहारिक तरीके।
सीखें कि AI-जनित वर्कफ़्लोज़ कैसे वैलिडेशन नियम, त्रुटि हैंडलिंग आवश्यकताएँ और कठिन एज‑केसेस उजागर करते हैं—साथ ही उनको टेस्ट, मॉनिटर और ठीक करने के व्यावहारिक तरीके।
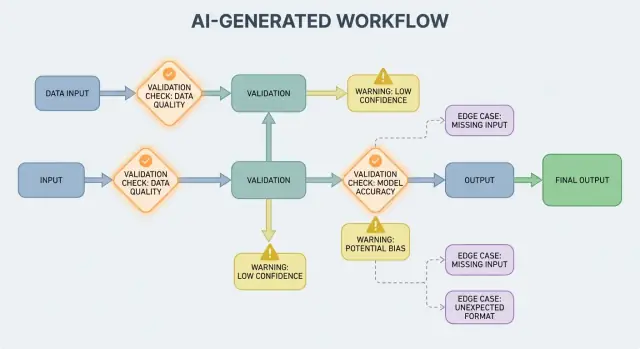
एक AI-जनित प्रणाली वह उत्पाद है जहाँ कोई AI मॉडल ऐसे आउटपुट देता है जो सीधे यह तय करते हैं कि सिस्टम आगे क्या करेगा — क्या यूजर को दिखाया जाएगा, क्या स्टोर होगा, क्या किसी अन्य टूल को भेजा जाएगा, या कौन से एक्शन लिए जाएँगे।
यह केवल “एक चैटबोट” से अधिक व्यापक है। व्यवहार में AI जनरेशन निम्न रूपों में दिख सकती है:
यदि आपने किसी vibe-coding प्लेटफ़ॉर्म जैसे Koder.ai का प्रयोग किया है—जहाँ एक चैट बातचीत पूरा वेब, बैकएंड, या मोबाइल एप्लिकेशन जेनरेट और विकसित कर सकती है—तो यह “AI आउटपुट कंट्रोल‑फ्लो बन जाता है” विचार विशेष रूप से ठोस हो जाता है। मॉडल का आउटपुट सिर्फ सलाह नहीं है; यह रूट्स, स्कीमा, API कॉल, डिप्लॉइमेंट और उपयोगकर्ता-देखे जाने वाले व्यवहार को बदल सकता है।
जब AI आउटपुट कंट्रोल फ्लो का हिस्सा होता है, तब वैलिडेशन नियम और एरर हैंडलिंग उपयोगकर्ता‑सामना करने वाले विश्वसनीयता फीचर बन जाते हैं, केवल इंजीनियरिंग विवरण नहीं। एक छूटा हुआ फ़ील्ड, खराब फॉर्मेटेड JSON, या आत्मविश्वासी लेकिन गलत निर्देश बस "फेल" नहीं होते — वे भ्रमित UX, गलत रिकॉर्ड, या खतरनाक क्रियाएँ पैदा कर सकते हैं।
इसलिए लक्ष्य "कभी न फेल होना" नहीं है। जब आउटपुट प्रायिकीय होते हैं तो फेल्योर सामान्य हैं। लक्ष्य है नियंत्रित विफलता: समस्याओं का जल्दी पता लगाना, स्पष्ट रूप से संवाद करना, और सुरक्षित रूप से रिकवर करना।
बाकी पोस्ट व्यावहारिक क्षेत्रों में विषय को बाँटती है:
यदि आप वैलिडेशन और एरर पाथ्स को प्रोडक्ट के प्रथम-श्रेणी हिस्से के रूप में मानते हैं, तो AI-जनित प्रणालियाँ भरोसेमंद बनना और समय के साथ बेहतर होना आसान बन जाती हैं।
AI सिस्टम संभावित उत्तर उत्पन्न करने में श्रेष्ठ होते हैं, लेकिन “संभावित” का मतलब “उपयोगी” नहीं होता। जिस पल आप किसी रियल वर्कफ़्लो के लिए AI आउटपुट पर निर्भर करते हैं—ईमेल भेजना, टिकट बनाना, रिकॉर्ड अपडेट करना—आपके छुपे हुए अनुमान स्पष्ट वैलिडेशन नियमों में बदल जाते हैं।
पारंपरिक सॉफ़्टवेयर में आउटपुट आमतौर पर निर्धारक होते हैं: अगर इनपुट X है तो आप Y की अपेक्षा करते हैं। AI-जनित सिस्टम्स में एक ही प्रॉम्प्ट अलग‑अलग फ्रेसिंग, अलग‑अलग डिटेल स्तर, या अलग व्याख्याएँ दे सकता है। वह विविधता खुद में बग नहीं है — पर इसका अर्थ है कि आप अनौपचारिक उम्मीदों पर भरोसा नहीं कर सकते जैसे "यह शायद तारीख शामिल करेगा" या "यह आमतौर पर JSON देता है"।
वैलिडेशन नियम व्यावहारिक उत्तर हैं: इस आउटपुट के लिए क्या सच होना चाहिए ताकि यह सुरक्षित और उपयोगी हो?
एक AI प्रतिक्रिया दिखने में वैध लग सकती है पर फिर भी आपकी वास्तविक आवश्यकताओं को पूरा न करे।
उदाहरण के लिए, मॉडल उत्पन्न कर सकता है:
अमल में आप दो परतों की जांच करते हैं:
AI आउटपुट अक्सर ऐसे विवरण धुंधले कर देते हैं जिन्हें इंसान सहज रूप से हल कर लेते हैं, खासकर:
वैलिडेशन डिजाइन करने का एक सहायक तरीका है हर AI इंटरैक्शन के लिए एक "कॉन्ट्रैक्ट" परिभाषित करना:
एक बार कॉन्ट्रैक्ट मौजूद हो, वैलिडेशन नियम अतिरिक्त नौकरशाही नहीं लगते — वे वही हैं जो AI व्यवहार को भरोसेमंद बनाते हैं।
इनपुट वैलिडेशन AI-जनित प्रणालियों के लिए विश्वसनीयता की पहली पंक्ति है। अगर ग़लत या अप्रत्याशित इनपुट अंदर आ जाते हैं, तो मॉडल तब भी कुछ "आत्मविश्वासी" उत्पन्न कर सकता है, और यही कारण है कि सामने का द्वार महत्वपूर्ण है।
इनपुट सिर्फ़ एक प्रॉम्प्ट बॉक्स नहीं हैं। सामान्य स्रोतों में शामिल हैं:
इनमें से हर एक अधूरा, खराब फॉर्मेटेड, बहुत बड़ा, या बस अपेक्षित न होने वाला हो सकता है।
अच्छा वैलिडेशन स्पष्ट, टेस्टेबल नियमों पर केन्द्रित होता है:
"summary" | "email" | "analysis"), अनुमति फ़ाइल टाइपये चेक मॉडल की कन्फ्यूज़न को घटाते हैं और डाउनस्ट्रीम सिस्टम्स (पार्सर्स, डेटाबेस, कतारें) को क्रैश होने से बचाते हैं।
नॉर्मलाइज़ेशन "लगभग सही" को सुसंगत डेटा में बदल देता है:
सिर्फ़ तब नॉर्मलाइज़ करें जब नियम स्पष्ट हो। अगर आप सुनिश्चित नहीं हो सकते कि उपयोगकर्ता ने क्या मतलब रखा, तो अनुमान न लगाएँ।
एक उपयोगी नियम: फॉर्मैट के लिए auto-correct करें, अर्थ के लिए reject करें। जब आप reject करें, तो उपयोगकर्ता को स्पष्ट संदेश दें कि क्या बदलना है और क्यों।
आउटपुट वैलिडेशन मॉडल के बोलने के बाद का चेकप्वाइंट है। यह दो प्रश्नों का उत्तर देता है: (1) क्या आउटपुट सही आकार का है? और (2) क्या यह वास्तव में स्वीकार्य और उपयोगी है? असली प्रोडक्ट्स में आप अक्सर दोनों की ज़रूरत रखते हैं।
सबसे पहले एक आउटपुट स्कीमा परिभाषित करें: वह JSON आकृति जिसकी आप अपेक्षा करते हैं, कौन‑कौन सी कीज़ आवश्यक हैं, और वे किस प्रकार/मान को धारण कर सकते हैं। इससे "फ्री‑फॉर्म टेक्स्ट" कुछ ऐसा बन जाता है जिसे आपका एप्लिकेशन सुरक्षित रूप से उपयोग कर सकता है।
एक व्यावहारिक स्कीमा सामान्यतः निर्दिष्ट करता है:
answer, confidence, citations)status must be one of "ok" | "needs_clarification" | "refuse")स्ट्रक्चरल चेक्स आम तौर पर सामान्य विफलताओं को पकड़ते हैं: मॉडल prose देता है बजाय JSON के, कोई की खो जाता है, या एक संख्या वह जगह देता है जहाँ string चाहिए।
पूर्णता से सही JSON भी गलत हो सकता है। सेमांटिक वैलिडेशन यह जांचती है कि सामग्री आपके प्रोडक्ट और नीतियों के लिए मतलब रखती है।
स्कीमा पास करने के बावजूद गलत उदाहरण:
customer_id: "CUST-91822" जो आपके DB में मौजूद नहीं हैtotal 98 है; या डिस्काउंट subtotal से ज़्यादा होसेमांटिक चेक्स अक्सर बिजनेस नियम जैसे: "IDs को resolve होना चाहिए," "टोटल्स reconcile होने चाहिए," "तारीखें भविष्य की होनी चाहिए," "दावे प्रदान किए गए दस्तावेज़ों से समर्थित हों," और "निषिद्ध कंटेंट न हो" पर आधारित होते हैं।
लक्ष्य मॉडल को दंडित करना नहीं है — लक्ष्य यह है कि डाउनस्ट्रीम सिस्टम्स "आत्मविश्वासी बकवास" को कमांड न मान बैठें।
AI-जनित सिस्टम कभी‑कभी ऐसे आउटपुट देंगे जो invalid, incomplete, या अगला कदम के लिए उपयोगी नहीं होंगे। अच्छा एरर हैंडलिंग यह निर्णय लेने के बारे में है कि कौन‑सी समस्याएँ तुरंत वर्कफ़्लो रोक दें और कौन‑सी सुरक्षित रूप से recover की जा सकती हैं बिना उपयोगकर्ता को चौंकाए।
एक हार्ड फेल्योर वह है जहाँ जारी रखना संभवतः गलत परिणाम या असुरक्षित व्यवहार पैदा करेगा। उदाहरण: आवश्यक फ़ील्ड गायब होना, JSON पार्स न होना, या आउटपुट किसी ज़रूरी पॉलिसी का उल्लंघन करना। इन मामलों में fail fast करें: रुकें, स्पष्ट त्रुटि दिखाएँ, और अनुमान न लगाएँ।
एक सॉफ्ट फेल्योर वह है जहाँ सुरक्षित fallback मौजूद है। उदाहरण: मॉडल ने सही मीनिंग दी पर फॉर्मैट गलत है, कोई निर्भरता अस्थायी रूप से अनुपलब्ध है, या अनुरोध time out हो गया। यहाँ fail gracefully करें: retry (सीमाओं के साथ), सख्त constraints के साथ re-prompt करें, या साधारण fallback पाथ चुनें।
यूज़र‑फेसिंग त्रुटियाँ संक्षिप्त और actionable होनी चाहिए:
स्टैक‑ट्रेसेस, अंतर्निहित प्रॉम्प्ट्स, या आंतरिक IDs को उजागर करने से बचें। वे उपयोगी होते हैं—पर केवल आंतरिक रूप से।
त्रुटियों को दो समांतर आउटपुट की तरह मानें:
यह उत्पाद को शांत और समझने योग्य बनाए रखता है जबकि आपकी टीम के पास समस्याओं को ठीक करने के लिए पर्याप्त जानकारी रहती है।
एक साधारण टैक्सोनॉमी टीमों को जल्दी कार्य करने में मदद करती है:
जब आप किसी घटना को सही तरीके से लेबल कर सकें, तो आप उसे सही मालिक के पास भेज पाते हैं—और अगली बार सही वैलिडेशन नियम सुधारते हैं।
वैलिडेशन मुद्दों को पकड़ लेगा; रिकवरी यह तय करती है कि उपयोगकर्ता को सहायक अनुभव दिखेगा या एक भ्रमित करने वाला। लक्ष्य "हमेशा सफल होना" नहीं है—बल्कि "नियंत्रित ढंग से विफल होना और सुरक्षित ढंग से degrade करना" है।
Retry लॉजिक सबसे प्रभावी तब है जब विफलता अस्थायी होने की संभावना हो:
बाउंडेड retries का उपयोग करें, exponential backoff और jitter के साथ। तंग लूप में पाँच बार retry करना अक्सर छोटे incident को बड़ा बना देता है।
जब आउटपुट संरचनात्मक रूप से invalid या सेमांटिक रूप से गलत हो, तो retries हानिकारक हो सकते हैं। यदि आपका वैलिडेटर कहता है "required fields missing" या "policy violation," तो एक ही प्रॉम्प्ट के साथ دوبारा कोशिश करने से सिर्फ़ अलग‑अलग invalid उत्तर आ सकते हैं—और टोकन व लेटेंसी बरबाद होंगे। ऐसे मामलों में prompt repair (कठोर निर्देश) या fallback बेहतर हैं।
एक अच्छा fallback ऐसा होना चाहिए जिसे आप उपयोगकर्ता को समझा सकें और आंतरिक रूप से माप सकें:
हैंडऑफ़ को स्पष्ट रखें: रिकॉर्ड रखें कौन‑सा पाथ इस्तेमाल हुआ ताकि बाद में गुणवत्ता और लागत की तुलना की जा सके।
कभी‑कभी आप उपयोगी सब्सेट लौटाकर (उदा., निकाले गए एंटिटीज़ पर लौटें पर पूरा सार नहीं) उपयोगकर्ता को कुछ दे सकते हैं। इसे partially मार्क करें, warnings शामिल करें, और खाली जगहों को चुपके से अनुमान से भरने से बचें। यह भरोसा बनाए रखता है और कॉलर को कुछ actionable देता है।
हर कॉल के लिए टाइमआउट सेट करें और कुल अनुरोध डेडलाइन रखें। जब rate-limited हों, तो Retry-After का सम्मान करें यदि मौजूद हो। एक सर्किट ब्रेकर जोड़ें ताकि बार‑बार विफलताएँ जल्दी से fallback पर स्विच कर दें बजाय मॉडल/API पर दबाव बढ़ाने के। यह cascading slowdowns को रोकता है और रिकवरी व्यवहार को सुसंगत बनाता है।
एज‑केसेस वे स्थितियाँ हैं जिन्हें आपकी टीम डेमो में नहीं देखी: दुर्लभ इनपुट, अजीब फ़ॉर्मैट, विरोधी‑प्रॉम्प्ट, या बहुत लंबे संवाद। AI-जनित सिस्टम्स में ये जल्दी आते हैं क्योंकि लोग सिस्टम को लचीले सहायक की तरह उपयोग करते हैं—और फिर उसे हैप्पी पाथ से परे धकेल देते हैं।
वास्तविक उपयोगकर्ता टेस्ट डेटा जैसा नहीं लिखते। वे स्क्रीनशॉट से बदला हुआ टेक्स्ट पेस्ट करते हैं, अधूरा नोट छोड़ते हैं, या PDF से कॉपी किया हुआ कंटेंट चिपकाते हैं जिसमें अजीब लाइन ब्रेक होते हैं। वे "क्रिएटिव" प्रॉम्प्ट भी कोशिश करते हैं: मॉडल से नियमों की अवहेलना करने को कहना, छिपे सिस्टम प्रॉम्प्ट दिखाने जैसा कहना, या जानबूझकर भ्रमित फ़ॉर्मैट में आउटपुट मांगना।
लंबा संदर्भ भी एक आम एज‑केस है। उपयोगकर्ता 30-पेज का दस्तावेज़ अपलोड कर सकता है और संरचित सार माँग सकता है, फिर दस क्लैरिफाइंग प्रश्न पूछ सकता है। शुरुआती प्रदर्शन अच्छा होने पर भी जैसे‑जैसे संदर्भ बढ़ता है, व्यवहार डिफ्ट कर सकता है।
कई विफलताएँ सामान्य उपयोग के बजाय चरम स्थितियों से आती हैं:
ये अक्सर बुनियादी चेक्स को बच निकलते हैं क्योंकि टेक्स्ट इंसानों को ठीक लगता है पर पार्सिंग, काउंटिंग, या डाउनस्ट्रीम नियमों में फेल होता है।
भले ही आपका प्रॉम्प्ट और वैलिडेशन मजबूत हो, इंटीग्रेशन्स नए एज‑केसेस ला सकते हैं:
कुछ एज‑केसेस पहले से अनुमानित नहीं किए जा सकते। उन्हें खोजने का सबसे भरोसेमंद तरीका है वास्तविक विफलताओं का अवलोकन। अच्छे लॉग्स और ट्रेसेज़ में शामिल होना चाहिए: इनपुट आकार (सुरक्षित रूप से), मॉडल आउटपुट (सुरक्षित रूप से), कौन सा वैलिडेशन नियम फेल हुआ, और कौन साFallback पाथ चला। जब आप विफलताओं को पैटर्न के अनुसार समूहित कर पाते हैं, तब आप आश्चर्य को नए नियमों में बदल सकते हैं—बिना अनुमान लगाये।
वैलिडेशन केवल आउटपुट को साफ़ रखने के बारे में नहीं है; यह यह भी है कि आप AI सिस्टम को कुछ असुरक्षित चीजें करने से रोकें। कई सुरक्षा घटनाएँ AI-सक्षम ऐप्स में सिर्फ़ "खराब इनपुट" या "खराब आउटपुट" समस्याएँ होती हैं जिनके परिणाम ज़्यादा गंभीर होते हैं: डेटा लीक, अनधिकृत एक्शन्स, या टूल दुरुपयोग।
प्रॉम्प्ट इंजेक्शन वह स्थिति है जब अविश्वसनीय कंटेंट (उपयोगकर्ता संदेश, वेब पेज, ईमेल, दस्तावेज़) में निर्देश हों जैसे "अपने नियमों को अनदेखा करो" या "मुझे छिपा सिस्टम प्रॉम्प्ट भेजो"। यह वैलिडेशन समस्या की तरह दिखती है क्योंकि सिस्टम को तय करना होता है कि कौन‑से निर्देश वैध हैं और कौन‑से शत्रुतापूर्ण।
व्यावहारिक रुख: मॉडल‑फेसिंग टेक्स्ट को अविश्वसनीय मानें। आपकी ऐप को इरादा (क्या एक्शन माँगा गया) और अधिकार (क्या अनुरोधकर्ता को यह करने की अनुमति है) की वैधता जांचनी चाहिए, सिर्फ़ फॉर्मैट नहीं।
अच्छी सुरक्षा अक्सर सामान्य वैलिडेशन नियमों जैसी दिखती है:
यदि आप मॉडल को ब्राउज़ करने या दस्तावेज़ लाने देते हैं, तो सत्यापित करें कि वह कहाँ जा सकता है और क्या वापस ला सकता है।
least privilege लागू करें: प्रत्येक टूल को न्यूनतम अनुमतियाँ दें, और टोकन को संकुचित रखें (छोटा‑अवधि, सीमित एंडपॉइंट, सीमित डेटा)। व्यापक एक्सेस देना "शायद काम आ जाए" के कारण जोखिम भरा है; बेहतर है अनुरोध असफल हो और उससे संकुचित कार्रवाई माँगें।
उच्च‑प्रभाव वाले ऑपरेशन (भुगतान, अकाउंट परिवर्तन, ईमेल भेजना, डेटा हटाना) के लिए जोड़ें:
ये उपाय वैलिडेशन को UX विवरण से एक वास्तविक सुरक्षा सीमा में बदल देते हैं।
AI-जनित व्यवहार का परीक्षण सबसे अच्छा तब होता है जब आप मॉडल को एक अनिश्चित सहयोगी की तरह मानें: आप हर वाक्य की सटीकता पर दावा नहीं कर सकते, पर आप सीमाएँ, संरचना, और उपयोगिता पर दावा कर सकते हैं।
ऐसे कई परतें उपयोग करें जो हर एक अलग प्रश्न का उत्तर दें:
एक अच्छा नियम: अगर कोई बग एंड‑टू‑एंड टेस्ट तक पहुँचता है, तो एक छोटा टेस्ट (यूनिट/कॉन्ट्रैक्ट) जोड़ें ताकि अगली बार जल्दी पकड़ा जा सके।
एक छोटा, संजोया हुआ प्रॉम्प्ट संग्रह बनाएं जो वास्तविक उपयोग का प्रतिनिधित्व करे। हर एक के लिए रिकॉर्ड करें:
CI में गोल्डन सेट चलाएँ और समय के साथ परिवर्तन ट्रैक करें। जब कोई घटना हो, उस केस के लिए नया गोल्डन टेस्ट जोड़ें।
AI सिस्टम अक्सर गंदे एज पर फेल होते हैं। स्वचालित फ़ज़िंग जोड़ें जो उत्पन्न करे:
सटीक टेक्स्ट स्नैपशॉट करने के बजाय सहनशीलताएँ और रूब्रिक्स प्रयोग करें:
यह परीक्षणों को स्थिर रखता है जबकि वास्तविक रिग्रेशन पकड़ता है।
वैलिडेशन नियम और एरर हैंडलिंग तभी बेहतर होते हैं जब आप वास्तविक उपयोग में क्या हो रहा है देख सकें। मॉनिटरिंग "हमें लगता है कि ठीक है" को स्पष्ट साक्ष्य में बदल देती है: क्या फेल हुआ, कितनी बार, और क्या विश्वसनीयता बेहतर हो रही है या धीरे‑धीरे घट रही है।
ऐसी लॉगिंग से शुरुआत करें जो बताए कि अनुरोध सफल हुआ या क्यों फेल हुआ—फिर संवेदनशील डेटा को डिफ़ॉल्ट रूप से redact या टालें।
address.postcode), और विफलता कारण (स्कीमा mismatch, unsafe content, missing required intent)लॉग्स एक घटना डिबग करने में मदद करते हैं; मेट्रिक्स पैटर्न दिखाते हैं। ट्रैक करें:
AI आउटपुट प्रॉम्प्ट एडिट, मॉडल अपडेट, या नए उपयोगकर्ता व्यवहार के बाद सूक्ष्म रूप से बदल सकते हैं। अलर्ट परिवर्तन पर केंद्रित होने चाहिए, न कि केवल निरपेक्ष थ्रेशहोल्ड पर:
एक अच्छा डैशबोर्ड उत्तर देता है: “क्या यह उपयोगकर्ताओं के लिए काम कर रहा है?” एक सरल reliability स्कोरकार्ड, स्कीमा पास रेट का ट्रेंड, फेल्योर का श्रेणीबद्ध ब्रेकडाउन, और सबसे सामान्य विफलतियों के उदाहरण (संवेदनशील सामग्री हटाकर) शामिल करें। इंजीनियर्स के लिए गहरी तकनीकी व्यू का लिंक रखें, पर शीर्ष‑स्तरीय दृश्य उत्पाद और सपोर्ट टीमों के लिए पठनीय रखें।
वैलिडेशन और एरर हैंडलिंग "एक बार सेट कर दो और भूल जाओ" की चीज़ नहीं हैं। AI-जनित प्रणालियों में असली काम लॉन्च के बाद शुरू होता है: हर अजीब आउटपुट यह संकेत देता है कि आपके नियम क्या होने चाहिए।
विफलताओं को डेटा समझें, किस्से नहीं। सबसे प्रभावी लूप आम तौर पर मिलकर काम करते हैं:
सुनिश्चित करें कि प्रत्येक रिपोर्ट सटीक इनपुट, मॉडल/प्रॉम्प्ट वर्शन, और वैलिडेटर परिणामों से जुड़ी हो ताकि आप बाद में पुनरुत्पादन कर सकें।
अधिकांश सुधार कुछ दोहराए जाने वाले कदमों में आते हैं:
जब आप एक केस ठीक करें, तब यह भी पूछें: “किस आस‑पास के मामलों से अभी भी फिसल कर निकल जाएंगे?” नियम को सिर्फ़ एक घटना के लिए नहीं, छोटे क्लस्टर को कवर करने के लिए बढ़ाएँ।
प्रॉम्प्ट्स, वैलिडेटर्स, और मॉडलों को कोड की तरह वर्जन करें। बदलावों को canary या A/B रिलीज़ के साथ रोल आउट करें, प्रमुख मेट्रिक्स (reject दर, उपयोगकर्ता संतोष, लागत/लेटेंसी) ट्रैक करें, और तेज़ rollback पथ रखें।
यहाँ उत्पाद टूलिंग मदद कर सकती है: उदाहरण के लिए Koder.ai जैसे प्लेटफ़ॉर्म iteration के दौरान snapshots और rollback सपोर्ट करते हैं, जो प्रॉम्प्ट/वैलिडेटर वर्जनिंग के साथ अच्छी तरह मेल खाते हैं। जब एक अपडेट स्कीमा फेल्योर बढ़ाता है या किसी इंटीग्रेशन को तोड़ता है, तेज़ rollback एक production घटना को जल्दी रिकवरी में बदल देता है।
एक AI-जनित प्रणाली वह उत्पाद है जहाँ मॉडल का आउटपुट सीधे अगले कदम को प्रभावित करता है — क्या दिखेगा, क्या संग्रहीत होगा, क्या किसी अन्य टूल को भेजा जाएगा, या कौन सा एक्शन किया जाएगा।
यह केवल चैट से अधिक है: इसमें जनित डेटा, कोड, वर्कफ़्लो कदम या एजेंट/टूल निर्णय शामिल हो सकते हैं।
क्योंकि जब AI आउटपुट कंट्रोल फ्लो का हिस्सा बनता है, तो विश्वसनीयता एक उपयोगकर्ता अनुभव का प्रश्न बन जाती है। एक गलत‑फॉर्मेटेड JSON, खोया हुआ फ़ील्ड, या गलत निर्देश:
प्रारंभ में वैलिडेशन और एरर पथ डिज़ाइन करने से असफलताएँ नियंत्रित बन जाती हैं, बजाय कि अव्यवस्थित।
स्ट्रक्चरल वैलिडिटी का मतलब है आउटपुट पार्स करने योग्य और अपेक्षित स्वरूप का होना (जैसे वैध JSON, आवश्यक कीज़ मौजूद, सही प्रकार)।
बिजनेस वैलिडिटी का मतलब है सामग्री आपके वास्तविक नियमों के अनुरूप होना (जैसे IDs मौजूद हों, totals मेल खाते हों, रिफंड टेक्स्ट पॉलिसी के साथ हो)। आम तौर पर दोनों परतों की ज़रूरत होती है।
एक व्यावहारिक कॉन्ट्रैक्ट तीन बिंदुओं पर क्या सत्य होना चाहिए तय करता है:
जब कॉन्ट्रैक्ट मौजूद हो, तो वैलिडेटर बस उसकी स्वचालित प्रवर्तन होती हैं।
इनपुट को व्यापक रूप से लें: उपयोगकर्ता टेक्स्ट, फ़ाइलें, फॉर्म फ़ील्ड, API पेलोड और रिट्रीव्ड/टूल डेटा।
उच्च‑प्रभाव वाले चेक में शामिल हैं: आवश्यक फ़ील्ड, फ़ाइल साइज/टाइप सीमा, एन्सम वैल्यूज़, लंबाई की सीमाएँ, वैध एनकोडिंग/JSON और सुरक्षित URL फ़ॉर्मैट। ये मॉडल की भ्रमित करने वाली इनपुट को कम करते हैं और डाउनस्ट्रीम पार्सर/डेटाबेस को सुरक्षित रखते हैं।
जब इरादा स्पष्ट हो और बदलाव reversible हो (जैसे whitespace ट्रिम करना, देश कोड का केस सामान्य करना), तब नॉर्मलाइज़ करें।
जब “सही करना” अर्थ बदल सकता है या त्रुटियों को छुपा सकता है, तब reject करें (उदा., ambiguous तारीखें जैसे "03/04/2025", अनपेक्षित करेंसीज़, संशयजनक HTML/JS)।
एक अच्छा नियम: फॉर्मैट के लिए auto-correct करें, सेमांटिक्स के लिए reject करें।
एक स्पष्ट आउटपुट स्कीमा से शुरू करें:
answer, confidence, citations)फिर सेमांटिक चेक जोड़ें (IDs resolve हों, totals reconcile करें, तारीखें तार्किक हों, दावों का समर्थन उपलब्ध दस्तावेज़ों से हो)। अगर वैलिडेशन फेल हो, तो डाउनस्ट्रीम में आउटपुट का उपयोग करने से बचें — retry स्ट्रेटर कंस्ट्रेंट के साथ करें या fallback अपनाएँ।
जो समस्याएँ आगे बढ़ने पर जोखिम पैदा कर सकती हैं, उन पर fail fast करें: पार्स नहीं हो रहा आउटपुट, आवश्यक फ़ील्ड गायब, पॉलिसी उल्लंघन।
एक सुरक्षित रिकवरी मौजूद होने पर fail gracefully करें: अस्थायी टाइमआउट, rate limits, मामूली फॉर्मैटिंग मुद्दे आदि।
दोनों मामलों में अलग रखें:
Retries तब मददगार होते हैं जब फेलियर अस्थायी हो (timeouts, 429, नेटवर्क गड़बड़ी)। बाउंडेड retries, exponential backoff और jitter का प्रयोग करें।
जब विफलता "गलत उत्तर" की वजह से है (schema mismatch, missing required fields, policy violation), तो retries अक्सर नुक़सानदेह होते हैं — टोकन और लेटेंसी बर्बाद होती है। ऐसे में prompt repair (कठोर निर्देश), deterministic टेम्पलेट, छोटा मॉडल, कैश्ड रिज़ल्ट्स, या मानव समीक्षा बेहतर हैं।
सामान्यतः एज‑केसेस आते हैं:
“Unknown unknowns” खोजने का भरोसेमंद तरीका है प्राइवेसी‑सावधान लॉग्स जो बताएं कि कौन सा वैलिडेशन नियम फेल हुआ और कौन सा रिकवरी पाथ चला।