“AI for CRUD” का असली मतलब
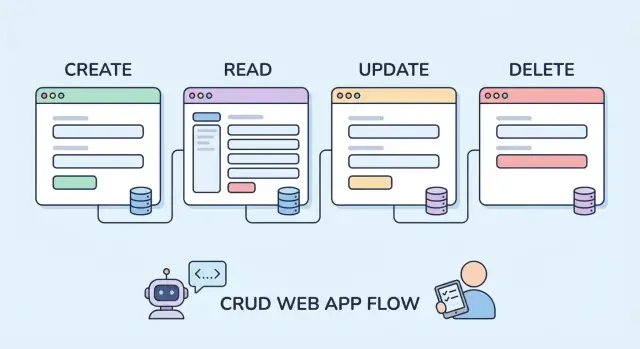
CRUD ऐप्स वे रोज़मर्रा के टूल हैं जो लोगों को डेटा Create, Read, Update, और Delete करने देते हैं—सोचें ग्राहक सूचियाँ, इन्वेंटरी ट्रैकर, अपॉइंटमेंट सिस्टम, आंतरिक डैशबोर्ड, और एडमिन पैनल। ये आम हैं क्योंकि अधिकतर बिजनेस संरचित रिकॉर्ड और दोहराए जाने वाले वर्कफ़्लो पर चलते हैं।
जब लोग “AI for CRUD apps” कहते हैं, तो वे आमतौर पर ऐसा AI नहीं समझते जो जादुई रूप से पूरा उत्पाद अकेले भेज दे। वे ऐसे असिस्टेंट की बात करते हैं जो रूटीन इंजीनियरिंग काम तेज़ करता है और ड्राफ्ट बनाकर देता है जिन्हें आप एडिट, रिव्यू और हार्डन कर सकते हैं।
“ऑटोमेट” दिखता कैसे है
व्यवहार में, AI ऑटोमेशन ज़्यादातर इस तरह होता है:
- सुझाव देता है: आपके विवरण के आधार पर फ़ील्ड नाम, एंडपॉइंट, UI लेआउट, या वैलिडेशन नियम प्रस्तावित करता है।
- ड्राफ्ट बनाता है: मॉडल्स, फॉर्म्स, कंट्रोलर्स, माइग्रेशन्स, और बेसिक टेस्ट के स्टार्टर कोड जेनरेट करता है।
- पूरा करता है: दोहराए जाने वाले स्निपेट्स भरता है (फ़ील्ड मैपिंग, रूट वायरिंग, स्टैंडर्ड एरर मैसेज)।
यह विशेष रूप से बॉयलरप्लेट पर घंटे बचा सकता है—क्योंकि CRUD ऐप्स अक्सर पैटर्न्स का पालन करते हैं।
तेज़ी बनाम गारंटी
AI आपको तेज़ी दे सकता है, पर इसका अर्थ यह नहीं कि परिणाम अपने आप सही होगा। जनरेट किया गया कोड:
- डोमेन शब्दों को गलत समझ सकता है (“customer” बनाम “account”, “archived” बनाम “deleted”)
- असुरक्षित डिफ़ॉल्ट लगा सकता है (बहुत वाइड परमिशन, मिसिंग एज केस)
- ऐसा कोड बना सकता है जो कम्पाइल तो हो पर आपके असली बिजनेस नियमों से मेल न खाए
इसलिए सही अपेक्षा है गति में वृद्धि, निश्चितता में नहीं। फिर भी आप रिव्यू, टेस्ट और निर्णय लेते हैं।
असली विभाजन: patterned बनाम निर्णय-भारित काम
जहाँ काम पैटर्न्ड और “सही जवाब” ज्यादातर स्टैण्डर्ड है, वहाँ AI सबसे मज़बूत है: स्कैफ़ोल्डिंग, CRUD एंडपॉइंट्स, बेसिक फॉर्म्स, और अनुमाननीय टेस्ट।
मानव तब आवश्यक रहते हैं जब निर्णय संदर्भ-निर्भर हों: डेटा का अर्थ, एक्सेस कंट्रोल, सुरक्षा/प्राइवेसी, एज केस, और वे नियम जो आपके ऐप को यूनिक बनाते हैं।
जहाँ CRUD ऐप्स प्रेडिक्टेबल होते हैं (और जहाँ नहीं)
CRUD ऐप्स अक्सर उन्हीं Lego ब्रिक्स से बने होते हैं: डेटा मॉडल्स, माइग्रेशन्स, फॉर्म्स, वैलिडेशन, लिस्ट/डीटेल पेज, टेबल्स और फ़िल्टर्स, एंडपॉइंट्स (REST/GraphQL/RPC), सर्च और पेजिनेशन, ऑथ, और परमिशन्स। वही रिपीटबिलिटी ही AI-असिस्टेड जेनरेशन को तेज़ महसूस करवा सकती है—कई प्रोजेक्ट्स एक जैसे शेप्स साझा करते हैं, भले ही बिजनेस डोमेन बदल रहा हो।
प्रेडिक्टेबल हिस्से
पैटर्न हर जगह दिखते हैं:
- “Create/Edit” स्क्रीन अक्सर मॉडल फ़ील्ड्स की नकल करती हैं।
- इंडेक्स पेजेज़ एक ही जरूरतों का पालन करते हैं: sort, filter, paginate।
- एंडपॉइंट्स आमतौर पर स्टैंडर्ड ऑपरेशन्स से मैप होते हैं: list, get, create, update, delete।
- वैलिडेशन अक्सर टाइप/फॉर्मेट चेक्स के रूप में शुरू होती है (required fields, min/max length, email format)।
इन पैटर्न्स की वजह से AI अच्छा पहला ड्राफ्ट बना सकता है: बेसिक मॉडल्स, स्कैफ़ोल्डेड रूट्स, सिंपल कंट्रोलर्स/हैंडलर्स, स्टैण्डर्ड UI फॉर्म्स, और स्टार्टर टेस्ट। यह फ्रेमवर्क्स और कोड जनरेटर जैसा ही है—AI बस आपके नेमिंग और कन्वेंशन्स के हिसाब से तेज़ एडाप्ट कर देता है।
अनप्रेडिक्टेबल हिस्से
CRUD ऐप्स “स्टैण्डर्ड” तब बंद हो जाते हैं जब आप वहाँ अर्थ जोड़ते हैं:
- Permissions: “कौन एडिट कर सकता है?” अक्सर सिर्फ “admin बनाम user” नहीं होता। यह conditional होता है (टीम सदस्यता, रिकॉर्ड ownership, स्थिति, क्षेत्र)।
- डेटा इंटीग्रिटी: एक छोटा सा गलती रिश्ते, यूनिक नियम, या cascading delete में डेटा को silently करप्ट कर सकता है—या वैध वर्कफ़्लो को ब्लॉक कर सकता है।
- स्टेट और बिजनेस ट्रांज़िशंस: “draft → submitted → approved” नियम सिर्फ DB स्कीमा में नहीं रहते।
- एज केस: इम्पोर्ट्स, concurrency, आंशिक अपडेट्स, और “soft delete” व्यवहार assumptions को तोड़ सकते हैं।
ये वे इलाके हैं जहाँ एक छोटी चूक बड़े मुद्दे बना सकती है: अनधिकृत एक्सेस, irreversible deletions, या records जो reconcile नहीं हो पाते।
व्यावहारिक नियम
AI का उपयोग पैटर्न्स को ऑटोमेट करने में करें, फिर परिणामों की जानबूझकर जाँच करें। यदि आउटपुट किसी के डेटा को देखने/बदलने को प्रभावित करता है, या यह तय करता है कि डेटा समय के साथ सही रहेगा या नहीं, तो इसे उच्च-जोखिम मानें और प्रोडक्शन-क्रिटिकल कोड की तरह वेरिफाई करें।
कार्य जो AI अच्छी तरह ऑटोमेट करता है: बॉयलरप्लेट और स्कैफ़ोल्डिंग
AI तब सबसे अच्छा होता है जब काम दोहराए जाने वाला, संरचनात्मक रूप से अनुमाननीय, और सत्यापित करना आसान हो। CRUD ऐप्स में ऐसा बहुत कुछ है: कई मॉडल्स, एंडपॉइंट्स, और स्क्रीन पर वही पैटर्न दोहराते हैं। इस तरह उपयोग करने पर AI घंटे बचा सकता है बिना उत्पाद के अर्थ की ज़िम्मेदारी लिए।
किसी फीचर का “आकार” स्कैफ़ोल्ड करना
किसी एंटिटी (फ़ील्ड्स, रिश्ते, और बेसिक एक्शन्स) का स्पष्ट विवरण मिलने पर AI जल्दी से स्केलेटन ड्राफ्ट कर सकता है: मॉडल परिभाषाएँ, कंट्रोलर्स/हैंडलर्स, रूट्स, और बेसिक पेजेज़। फिर भी आपको नेमिंग, डेटा टाइप्स और रिश्तों की पुष्टि करनी होगी—पर एक पूरा ड्राफ्ट शुरू करने से हर फ़ाइल स्क्रैच से बनाने से तेज़ होता है।
REST या GraphQL हैंडलर्स के लिए बॉयलरप्लेट
कॉमन ऑपरेशन्स—list, detail, create, update, delete—के लिए AI हैंडलर कोड जेनरेट कर सकता है जो पारंपरिक संरचना का पालन करता है: इनपुट पार्स करना, डेटा-एक्सेस लेयर कॉल करना, और response लौटाना।
यह विशेष रूप से उपयोगी है जब आप कई समान एंडपॉइंट्स एक साथ सेटअप कर रहे हों। कुंजी है एजेस की जाँच: फ़िल्टरिंग, पेजिनेशन, एरर कोड, और कोई भी "स्पेशल केस" जो स्टैण्डर्ड न हो।
सरल एडमिन डैशबोर्ड और व्यूज
CRUD अक्सर आंतरिक टूलिंग चाहिए: list/detail पेज, बेसिक फॉर्म्स, टेबल व्यूज़, और एक एडमिन-स्टाइल नेविगेशन। AI इन स्क्रीन का फ़ंक्शनल पहला वर्ज़न जल्दी बना सकता है।
इन्हें प्रोटोटाइप मान कर हार्डन करें: empty states, loading states और यह कि UI लोग वास्तव में कैसे सर्च और स्कैन करते हैं।
दोहराए कोड का सुरक्षित रिफैक्टर
AI मेकेनिकल रिफैक्टर—फ़ाइलों में फ़ील्ड्स का नाम बदलना, मॉड्यूल्स मूव करना, हेल्पर्स निकालना, या पैटर्न्स स्टैण्डर्ड करना—में काफी मददगार हो सकता है। यह डुप्लिकेशन कहाँ है यह भी सुझा सकता है।
फिर भी, टेस्ट चलाएँ और diffsInspect करें—क्योंकि रिफैक्टर्स सूक्ष्म तरीकों से फेल होते हैं जब दो “समकक्ष” केस वास्तव में समतुल्य नहीं होते।
शुरुआती दस्तावेज़ और कमेंट्स (समीक्षा के साथ)
AI README सेक्शन्स, एंडपॉइंट डिस्क्रिप्शन्स, और इनलाइन कमेंट्स ड्राफ्ट कर सकता है जो इरादे को समझाते हैं। यह ऑनबोर्डिंग और कोड रिव्यूज के लिए उपयोगी है—बशर्ते आप उसकी हर दावे की जाँच करें। पुरानी या गलत डॉक्यूमेंटेशन न होना बेहतर है।
डेटा मॉडल्स और माइग्रेशन्स: सहायक ड्राफ्ट, जोखिम भरे अनुमान
शुरुआत में डेटा मॉडलिंग में AI वाकई उपयोगी हो सकता है क्योंकि यह सामान्य भाषा वाले एंटिटीज़ को पहला-पास स्कीमा में बदलने में अच्छा है। यदि आप कहते हैं “Customer, Invoice, LineItem, Payment,” तो यह टेबल/कलेक्शन्स, टाइपिकल फील्ड्स, और तर्कसंगत डिफ़ॉल्ट (IDs, timestamps, status enums) ड्राफ्ट कर सकता है।
कहाँ AI तुरंत मदद करता है
सिधे बदलावों के लिए AI उबाऊ हिस्सों को तेज़ कर देता है:
- वर्णित एंटिटीज़ से बेसिक स्कीमा प्रस्ताव बनाना
- सरल फ़ील्ड जोड़ने या नाम बदलने के लिए माइग्रेशन्स जेनरेट करना
- सामान्य फ़िल्टर/सॉर्ट के लिए इंडेक्स सुझाना (उदा:
tenant_id + created_at, status, email), बशर्ते आप इन्हें असली क्वेरीज के खिलाफ वेरिफाई करें
यह खासकर एक्सप्लोरेशन में मददगार है: आप मॉडल पर जल्दी इटरेट कर सकते हैं, फिर जब वर्कफ़्लो स्पष्ट हो तो इसे टाइट करें।
कहाँ अक्सर चूक होती है
डेटा मॉडल्स में वे "गोट्चाज़" छिपे होते हैं जिन्हें AI छोटे प्रॉम्प्ट से भरोसेमंद तरीके से नहीं निकाल सकता:
- रिश्ते: one-to-many बनाम many-to-many, optional बनाम required लिंक, और ownership का अर्थ
- cascading deletes: पैरेंट हटाने पर क्या होना चाहिए—hard delete, soft delete, restrict, archive, या reassign
- Multi-tenant डेटा: क्या tenant-scoped होना चाहिए, cross-tenant पढ़ने से कैसे रोका जाए, और कौन से यूनिक constraints "per tenant" होने चाहिए
ये सिंटैक्स की समस्याएँ नहीं हैं; ये बिजनेस और रिस्क निर्णय हैं।
मानव जांच: प्रोडक्शन डेटा पर सुरक्षित बदलाव
एक माइग्रेशन जो "सही" है फिर भी unsafe हो सकती है। असली डेटा पर कुछ भी चलाने से पहले आपको तय करना होगा:
- क्या यह बड़ी टेबल को री-राइट करेगा या लिखने को लॉक करेगा?
- क्या मौजूदा पंक्तियाँ नई constraints का उल्लंघन कर सकती हैं?
- क्या परिवर्तन को expand/migrate/contract स्टेप्स में बाँटना चाहिए?
AI माइग्रेशन और रोलआउट प्लान ड्राफ्ट कर सकता है, पर प्लान को प्रपोज़ल मानें—आपकी टीम इसके नतीजों की ज़िम्मेदार है।
फॉर्म्स और वैलिडेशन: तेज़ जेनरेशन, सावधान से सेमान्टिक्स
फॉर्म्स वह जगह हैं जहाँ CRUD ऐप्स असली मनुष्यों से मिलते हैं। AI यहाँ वाकई उपयोगी है क्योंकि काम दोहराया जाता है: स्कीमा को इनपुट्स में बदलना, बेसिक वैलिडेशन वायर करना, और क्लाइंट/सर्वर को सिंक में रखना।
क्या AI अच्छा जेनरेट करता है
कोई डेटा मॉडल (या सैंपल JSON पेलोड) मिलते ही AI जल्दी से ड्राफ्ट कर सकता है:
- कॉमन टाइप्स के साथ फॉर्म फ़ील्ड्स (text, number, date, select, checkbox)
- लेबल्स, प्लेसहोल्डर्स और लेआउट डिफ़ॉल्ट के साथ सिंपल UI कंपोनेंट्स
- बेसिक validators: required, min/max, length limits, email/URL format checks
- दोनों साइड पर समानांतर वैलिडेशन स्टब्स (क्लाइंट-साइड चेक्स साथ ही सर्वर-साइड गार्ड्स)
यह "पहला उपयोगयोग्य वर्ज़न" काफी तेज़ बनाता है, खासकर स्टैण्डर्ड एडमिन-स्टाइल स्क्रीन के लिए।
जहाँ सेमान्टिक्स पेचीदा होते हैं
वैलिडेशन सिर्फ खराब डेटा को रिजेक्ट करना नहीं है; यह इरादे को व्यक्त करना है। AI भरोसेमंद तरीके से तय नहीं कर सकता कि आपके उपयोगकर्ताओं के लिए “सही” क्या है।
आपको अभी भी निर्णय लेना होगा जैसे:
- सही एरर मैसेज: स्पष्ट, विशिष्ट, और आपकी टोन के अनुरूप (और स्क्रीन रीडर्स के लिए सुलभ)
- समावेशी UX: नाम, पते, और फोन नंबर बहुत भिन्न होते हैं; "invalid" होना कभी-कभी उत्पाद निर्णय होता है, तकनीकी नहीं
- एज केस: optional middle names, non-Gregorian dates, शून्य मान जो मायने रखते हों, या "N/A" वर्कफ़्लो
एक आम विफलता मोड है AI ऐसे नियम लागू कर देना जो लोङिकली सही लगते हैं पर आपके बिजनेस के लिए गलत होते हैं (उदा., फ़ोन के लिए कड़ा फॉर्मैट ज़ोर देना या नामों में एपोस्ट्रॉफी को रिजेक्ट करना)।
नियम कहाँ रहने चाहिए
AI विकल्प प्रस्तावित कर सकता है, पर आप स्रोत-ऑफ़-ट्रुथ चुनते हैं:
- UI वैलिडेशन तेजी से फीडबैक के लिए (पर कभी अकेला गेट न हो)
- API वैलिडेशन वेब, मोबाइल, इम्पोर्ट्स, और इंटीग्रेशन्स में संगति के लिए
- DB constraints उन invariants के लिए जिन्हें आप कभी नहीं तोड़ना चाहते (unique keys, foreign keys, non-null)
एक व्यावहारिक तरीका: AI को पहला पास बनवाएँ, फिर हर नियम की समीक्षा करें और पूछें, “यह यूज़र सुविधा है, API कांट्रैक्ट है, या हार्ड डेटा invariant?”
API और क्वेरी लॉजिक: पैटर्न वाले काम पर तेज, पर तेज धार वाले किनारे
अपना सोर्स रखें
जब आप रिपॉज़िटरी की मालिकाना हक लेना चाहें, तब पूरा सोर्स कोड एक्सपोर्ट करके नियंत्रण रखें।
CRUD APIs अक्सर पुनरावर्ती पैटर्न का पालन करते हैं: रिकॉर्ड्स की सूची, एक ID द्वारा लाना, बनाना, अपडेट करना, हटाना, और कभी-कभी सर्च। इसलिए ये AI सहायता के लिए एक मिठास वाला क्षेत्र हैं—खासतौर पर जब आपको कई संसाधनों पर समान एंडपॉइंट्स चाहिए।
AI कहाँ सबसे अधिक मदद करता है
AI आमतौर पर स्टैण्डर्ड list/search/filter एंडपॉइंट्स और उनके आस-पास के “ग्लू कोड” का ड्राफ्ट करने में अच्छा होता है। उदाहरण के लिए, यह जल्दी जेनरेट कर सकता है:
- एक सुसंगत सेट एंडपॉइंट्स (
GET /orders, GET /orders/:id, POST /orders, आदि)
- फिल्टर्स के लिए क्वेरी-बिल्डर स्कैफ़ोल्डिंग जैसे status, date ranges, और text search
- मैपिंग कोड (DTOs, serializers, view models) ताकि responses विभिन्न एंडपॉइंट्स में सुसंगत दिखें
अंतिम बिंदु जितना सुनाई देता है उससे ज्यादा मायने रखता है: असंगत API शेप्स फ्रंट-एंड टीम्स और इंटीग्रेशन्स के लिए छुपा हुआ काम बनाते हैं। AI ऐसे पैटर्न लागू करने में मदद कर सकता है, जैसे “हमेशा { data, meta } लौटाएँ” या “तिथियाँ हमेशा ISO-8601 स्ट्रिंग हों।”
पेजिनेशन और सॉर्टिंग: तेज़ पैटर्न, वास्तविक ट्रेडऑफ़
AI पेजिनेशन और सॉर्टिंग जल्दी जोड़ सकता है, पर यह आपके डेटा के लिए सही रणनीति विश्वसनीय रूप से नहीं चुनेगा।
ऑफ़सेट पेजिनेशन (?page=10) सरल है, पर बदलते datasets के लिए धीमा और असंगत हो सकता है। कर्सर पेजिनेशन ("next cursor" टोकन का उपयोग) स्केल पर बेहतर प्रदर्शन देता है, पर इसे सही तरीके से लागू करना कठिन है—खासतौर पर जब उपयोगकर्ता कई फ़ील्ड पर sort कर सकते हैं।
आपको तय करना होगा कि आपके प्रोडक्ट के लिए “सही” क्या है: स्थिर ऑर्डरिंग, उपयोगकर्ता कितनी दूर वापस ब्राउज़ कर पाएँ, और क्या महंगे काउंट्स वहन किए जा सकते हैं।
आम AI पिटफॉल्स जिन पर ध्यान दें
क्वेरी कोड में छोटी गलतियाँ बड़े आउटेज बना सकती हैं। AI-जनरेटेड API लॉजिक अक्सर समीक्षा मांगता है:
- N+1 क्वेरीज (लूप में रिलेटेड रिकॉर्ड्स एक-एक करके फेच करना)
- मिसिंग लिमिट्स (अनबाउंडेड लिस्ट, महंगे सर्च, “सब कुछ डाउनलोड कर दो” एंडपॉइंट)
- असुरक्षित डायनामिक फिल्टर्स/सॉर्ट्स (यूज़र इनपुट को सीधे क्वेरी में इंटरपोलेट करना)
मानव समीक्षा: प्रदर्शन अपेक्षाएँ सेट करें
जनरेटेड कोड को स्वीकार करने से पहले उसे यथार्थवादी डेटा वॉल्यूम के खिलाफ चेक करें। औसत ग्राहक के पास कितने रिकॉर्ड होंगे? 10k बनाम 10M पंक्तियों पर “सर्च” का अर्थ क्या है? किन एंडपॉइंट्स को इंडेक्स, कैशिंग, या स्ट्रिक्ट रेट लिमिट्स की ज़रूरत है?
AI पैटर्न ड्राफ्ट कर सकता है, पर मानवों को गार्डरेल्स सेट करने होंगे: प्रदर्शन बजट, सुरक्षित क्वेरी नियम, और क्या API लोड के दौरान कर सकता है।
टेस्टिंग: AI कई टेस्ट लिख सकता है, पर आप सही टेस्ट चुनते हैं
AI आश्चर्यजनक रूप से तेज़ी से बहुत सारा टेस्ट कोड बना सकता है—खासतौर पर उन CRUD ऐप्स के लिए जहाँ पैटर्न दोहराते हैं। जाल यह सोचना है कि "ज़्यादा टेस्ट" अपने आप "बेहतर गुणवत्ता" हो। AI मात्रा देता है; आपको तय करना है कि क्या मायने रखता है।
कहाँ AI तुरंत मदद करता है
यदि आप AI को एक फ़ंक्शन सिग्नेचर, अपेक्षित व्यवहार का संक्षिप्त वर्णन, और कुछ उदाहरण देते हैं, तो यह यूनिट टेस्ट्स जल्दी ड्राफ्ट कर सकता है। यह "create → read → update → delete" जैसी हैपी‑पाथ इंटीग्रेशन टेस्ट्स बनाने में भी प्रभावी है, जिसमें रिक्वेस्ट्स वायर करना, स्टेटस कोड पर असर्शन, और response शेप की जाँच शामिल है।
एक और मजबूत उपयोग है: टेस्ट डेटा स्कैफोल्डिंग। AI फैक्ट्रीज़/फिक्स्चर्स (users, records, related entities) और कॉमन मॉकिंग पैटर्न (time, UUIDs, बाहरी कॉल्स) ड्राफ्ट कर सकता है ताकि आप हर बार रिपीट करने वाला सेटअप हाथ से न लिखें।
क्या इंसानों को तय करना चाहिए
AI कवरेज नंबर और स्पष्ट परिदृश्यों के लिए अनुकूल होता है। आपका काम मैटिंग मामलों का चयन करना है:
- Regressions: उन बग्स के लिए टेस्ट जो पहले शिप हो चुके हैं।
- Permissions: यह सत्यापित करें कि कौन पढ़/बनाता/एडिट/डिलीट कर सकता है—और कौन नहीं कर सकता।
- Concurrency: समकालीन अपडेट्स, stale writes, idempotency, duplicate submissions।
- Failures: अमान्य इनपुट, मिसिंग रिलेशन्स, DB त्रुटियाँ, नेटवर्क टाइमआउट्स, और आंशिक सफलता।
एक व्यावहारिक नियम: AI को पहला ड्राफ्ट बनाने दें, फिर हर टेस्ट की समीक्षा कर पूछें, “यह प्रोडक्शन में किस विफलता को पकड़ेगा?” अगर उत्तर “कोई नहीं” है, तो उसे हटाएँ या वास्तविक व्यवहार की रक्षा करने के लिए फिर लिखें।
ऑथ और परमिशन्स: AI मदद करता है, रिस्क मानवों के पास है
CRUD ड्राफ्ट तेज़ी से
चैट में अपना CRUD फ़ीचर बताएं और समीक्षा व कड़ा करने के लिए एक कार्यशील ड्राफ्ट पाएं।
Authentication (यूज़र कौन है) सामान्यतः CRUD ऐप्स में सीधा होता है। Authorization (वह क्या कर सकता/नहीं कर सकता) वही जगह है जहाँ प्रोजेक्ट्स फट जाते हैं, ऑडिट होते हैं, या चुपचाप महीनों तक डेटा लीक हो जाता है। AI मैकेनिक्स तेज़ कर सकता है, पर रिस्क की ज़िम्मेदारी यह नहीं ले सकता।
कहाँ AI तुरंत मदद करता है
यदि आप AI को स्पष्ट requirements टेक्स्ट दें ("Managers किसी भी ऑर्डर को एडिट कर सकते हैं; customers केवल अपने ही देख सकते हैं; support refund कर सकता है पर address नहीं बदल सकता"), तो यह RBAC/ABAC नियमों का पहला ड्राफ्ट बना सकता है और रोल्स, एट्रीब्यूट्स, और रिसोर्सेस पर मैप कर सकता है। इसे स्टार्टिंग स्केच मानें, निर्णय नहीं।
AI inconsistent authorization पहचानने में भी उपयोगी हो सकता है, ख़ासतौर पर बड़े कोडबेस में जहाँ कई handlers/controllers हों। यह ऐसे एंडपॉइंट्स स्कैन कर सकता है जो authenticate करते हैं पर permissions लागू करना भूल जाते हैं, या जहाँ "admin-only" एक्शन किसी कोड पाथ में गार्ड छोड़ दे रहे हों।
अंत में, यह प्लम्बिंग जेनरेट कर सकता है: मिडलवैर स्टब्स, पॉलिसी फाइल्स, डेकोरेटर्स/एनोटेशन्स, और बॉयलरप्लेट चेक्स।
जहाँ मानव निर्णय आवश्यक है
आपको threat model पर निर्णय लेना होगा (कौन सिस्टम злоउपयोग कर सकता है), least-privilege डिफ़ॉल्ट्स (यदि कोई रोल गायब हो तो क्या होता है), और audit needs (क्या लॉग होना चाहिए, कितना रखा जाए, और किसे देखा जा सकता है)। ये निर्णय आपके बिजनेस पर निर्भर करते हैं, आपके फ्रेमवर्क पर नहीं।
त्वरित समीक्षा चेकलिस्ट
- हर read path संरक्षित है (list, search, export, “download CSV”, background jobs)।
- हर write path संरक्षित है (create, update, delete, bulk actions, imports)।
- Ownership नियम server-side लागू हैं (छिपे फॉर्म फील्ड्स पर कभी भरोसा न करें)।
- प्रिविलेज्ड एक्शन्स लॉग हों—कौन/क्या/कब (और आदर्श रूप में क्यों)।
AI आपको “implemented” तक पहुँचने में मदद कर सकता है। “Safe” तक पहुँचना केवल आपके हाथ में है।
एरर हैंडलिंग और ऑब्ज़र्वेबिलिटी: अच्छे डिफ़ॉल्ट, कठिन निर्णय
AI यहाँ मददगार है क्योंकि एरर हैंडलिंग और ऑब्ज़र्वेबिलिटी परिचित पैटर्न का पालन करते हैं। यह जल्दी से "काफ़ी अच्छा" डिफ़ॉल्ट सेटअप सुझा सकता है—फिर आप इन्हें अपने प्रोडक्ट, रिस्क प्रोफ़ाइल और टीम की ज़रूरतों के मुताबिक परिष्कृत करते हैं।
क्या AI भरोसेमंद तरह से ड्राफ्ट कर सकता है
AI निम्नलिखित बेसलाइन प्रैक्टिस का सुझाव दे सकता है:
- रिक्वेस्ट्स, DB कॉल्स, और थर्ड‑पार्टी APIs के आसपास बेसिक लॉगिंग
- फ्लेकी डिपेंडेंसीज़ के लिए retry पैटर्न (backoff और एक max attempt limit के साथ)
- सुसंगत स्टेटस कोड्स और स्ट्रक्चर्ड एरर रिस्पॉन्स
API एरर फॉर्मैट का एक टाइपिकल AI-जनरेटेड स्टार्टिंग पॉइंट ऐसा दिख सकता है:
{
"error": {
"code": "VALIDATION_ERROR",
"message": "Email is invalid",
"details": [{"field": "email", "reason": "format"}],
"request_id": "..."
}
}
यह संगति क्लाइंट एप्स को बनाना और सपोर्ट करना आसान बनाती है।
मेट्रिक्स और डैशबोर्ड: अच्छे शुरुआती ड्राफ्ट
AI मीट्रिक नाम और शुरुआती डैशबोर्ड का प्रस्ताव दे सकता है: request rate, latency (p50/p95), error rate by endpoint, queue depth, और database timeouts। इन्हें आरम्भिक आइडियाज मानें, न कि अंतिम निगरानी रणनीति।
कठिन निर्णय मानवों के
जो जोखिम भरा हिस्सा है वह यह नहीं कि लॉग जोड़ना है—यह तय करना है कि क्या लॉग किया जाए और क्या नहीं।
आप तय करते हैं:
- क्या सुरक्षित है लॉग करने के लिए (और क्या कभी लॉग नहीं होना चाहिए): passwords, tokens, व्यक्तिगत डेटा, पेमेंट डिटेल्स
- PII कैसे संभालें: redaction, hashing, या पूरी तरह से संग्रह से बचना
- रिटेंशन: लॉग्स और ट्रेसेस कितने समय तक रखें और किसकी पहुँच हो
अंततः, यह परिभाषित करें कि "healthy" का अर्थ आपके यूज़र्स के लिए क्या है: “successful checkouts,” “projects created,” “emails delivered,” सिर्फ़ "सर्वर चालू हैं" नहीं। वह परिभाषा ऐसे अलर्ट चलाएगी जो असली कस्टमर इम्पैक्ट संकेत करें, हल्ला नहीं।
बिजनेस नियम: वह हिस्सा जिसे AI बिना आपके नहीं "जान" सकता
CRUD ऐप्स सरल दिखते हैं क्योंकि स्क्रीन परिचित हैं: एक रिकॉर्ड बनाओ, फ़ील्ड अपडेट करो, सर्च करो, हटाओ। कठिन हिस्सा वह सब है जो आपकी संस्था उन क्रियाओं से मतलब लेती है।
AI कंट्रोलर्स, फॉर्म्स, और DB कोड जल्दी जेनरेट कर सकता है—पर वह उन नियमों को नहीं निकाल सकता जो आपके ऐप को आपके बिजनेस के लिए सही बनाते हैं। वे नियम नीति दस्तावेज़ों, ट्राइबल ज्ञान, और रोज़मर्रा के एज‑केस निर्णयों में रहते हैं।
असली काम को कोड में बदलना
एक भरोसेमंद CRUD वर्कफ़्लो अक्सर एक निर्णय-वृक्ष छिपाता है:
- कौन किसी चीज़ को बनाकर, एडिट करके, या रद्द कर सकता है?
- "Approved" का क्या अर्थ है, और अस्वीकृति होने पर क्या होता है?
- कौन से अपवाद वैध हैं, और उन्हें कौन मना सकता/दे सकता है?
अप्रूवल्स एक अच्छा उदाहरण हैं। “Manager approval required” सरल सुनाई देता है जब तक आप परिभाषित न करें: यदि मैनेजर छुट्टी पर है तो क्या, राशि अप्रूवल के बाद बदलती है तो क्या, या अनुरोध दो विभागों में फैला हो तो क्या? AI अनुमोदन स्टेट मशीन का स्कैफ़ोल्ड बना सकता है, पर नियम आपको देने होंगे।
अस्पष्टता और विरोधाभासी आवश्यकताएँ
स्टेकहोल्डर्स अक्सर बिना महसूस किए असहमत होते हैं। एक टीम चाहता है “तेज़ प्रोसेसिंग,” दूसरी चाहती है “कठोर नियंत्रण।” AI उत्साहपूर्वक वह लागू कर देगा जो हाल में, स्पष्ट रूप से या आत्मविश्वास से लिखा गया हो।
मानवों को संघर्ष सुलझाने और एक सिंगल स्रोत‑ऑफ़‑ट्रुथ लिखने की ज़रूरत है: नियम क्या है, क्यों है, और सफलता कैसा दिखती है।
परिभाषाएँ जो भविष्य के अराजकता को रोकें
छोटी नामकरण पसंद बड़ी डाउनस्ट्रीम प्रभाव पैदा करती हैं। कोड जेनरेट करने से पहले सहमत हों:
- Statuses (draft, submitted, approved, fulfilled, archived)
- Timestamps (created_at, submitted_at, approved_at) और कौन से वैकल्पिक हैं
- Ownership (किसका रिकॉर्ड किस चरण में “own” करता है और ट्रांसफर कौन कर सकता है)
जानबूझकर ट्रेडऑफ़ चुनना
बिजनेस नियम ट्रेडऑफ़ मजबूर करते हैं: सादगी बनाम लचीलापन, कड़ाई बनाम गति। AI विकल्प दे सकता है, पर वह आपका रिस्क‑टॉलरेंस नहीं जानता।
एक व्यावहारिक तरीका: 10–20 “rule examples” साधारण भाषा में लिखें (अपवाद सहित), फिर AI से उन्हें वैलिडेशन्स, ट्रांज़िशन्स, और constraints में ट्रांसलेट करवाएँ—और हर एज‑कंडीशन की समीक्षा करके आकस्मिक परिणामों को रोकें।
सुरक्षा, प्राइवेसी, और अनुपालन: अनिवार्य मानव निगरानी
ड्राफ्ट से डिप्लॉय तक
जब यह तैयार हो, तब बिल्ट-इन डिप्लॉयमेंट और होस्टिंग के साथ एक इन-हाउस CRUD टूल शिप करें।
AI CRUD कोड जल्दी जेनरेट कर सकता है, पर सुरक्षा और अनुपालन "काफ़ी अच्छा" पर काम नहीं करते। एक जनरेटेड कंट्रोलर जो रिकॉर्ड सेव कर JSON लौटाए वह डेमो में ठीक दिख सकता है—और फिर भी प्रोडक्शन में एक ब्रेक/ब्रीच बना सकता है। AI आउटपुट को तब तक अनट्रस्टेड मानें जब तक समीक्षा न हो जाए।
जोखिम भरे पैटर्न जो AI गलती से ला सकता है
आम पिटफॉल्स साफ‑सुथरे दिखने वाले कोड में भी दिखते हैं:
- Mass assignment: पूरे रिक्वेस्ट ऑब्जेक्ट को स्वीकार करके persist करना यूज़र्स को ऐसे फ़ील्ड सेट करने दे सकता है जो उन्हें नहीं करने चाहिए (उदा.,
role=admin, isPaid=true)।
- Injection risks: स्ट्रिंग-निर्मित क्वेरीज, अनएस्केप्ड फ़िल्टर्स, या असुरक्षित “search” एंडपॉइंट SQL/NoSQL injection फिर ला सकते हैं।
- Unsafe file uploads: फ़ाइल प्रकार चेक मिस करना, अपलोड्स को पब्लिक पाथ में स्टोर करना, या मैलवेयर स्कैनिंग छोड़ देना।
टूटी एक्सेस कंट्रोल और डेटा लीक
CRUD ऐप्स सबसे ज़्यादा seam पर फेल होते हैं: list endpoints, “export CSV,” admin views, और multi-tenant filtering। AI स्कोप क्वेरीज (उदा., account_id द्वारा) भूल सकता है या UI पर निर्भर मान सकता है। मानवों को वेरिफाई करना चाहिए:
- हर read/write path server-side authorization लागू करे
- एरर मैसेज और लॉग संवेदनशील फ़ील्ड नहीं लीक करें
- पेजिनेशन, सर्च, और बल्क एक्शन्स दूसरे यूज़र्स का डेटा एनेमेरट न कर सकें
अनुपालन कोड स्निपेट नहीं है
डेटा रेजिडेंसी, ऑडिट ट्रेल्स, और कंसेंट जैसी आवश्यकताएँ आपके बिजनेस, भौगोलिक स्थान और कॉन्ट्रैक्ट्स पर निर्भर करती हैं। AI पैटर्न सुझा सकता है, पर आपको परिभाषित करना होगा कि “compliant” का क्या अर्थ है: क्या लॉग होगा, कितनी देर रखा जाएगा, किसे पहुँच होगी, और deletion requests कैसे हैंडल होंगी।
मानव ज़िम्मेदारियाँ (कोई शॉर्टकट नहीं)
सिक्योरिटी रिव्यू चलाएँ, डिपेंडेंसीज़ की जाँच करें, और incident response प्लान बनाएं (अलर्ट्स, सीक्रेट्स रोटेशन, रोलबैक स्टेप्स)। स्पष्ट "stop the line" रिलीज़ क्राइटेरिया सेट करें: यदि एक्सेस नियम अस्पष्ट हैं, संवेदनशील डेटा हैंडलिंग अनवेरिफाइड है, या ऑडीटेबिलिटी मिसिंग है, तो रिलीज़ को रोकें जब तक समाधान न हो।
एक व्यावहारिक वर्कफ़्लो: AI को उपयोगी बनाएं बिना नियंत्रण खोए
AI CRUD काम में तब सबसे ज़्यादा उपयोगी होता है जब आप इसे तेज़ ड्राफ्ट पार्टनर की तरह ट्रीट करें—लेखक की तरह नहीं। लक्ष्य सरल है: विचार से वर्किंग कोड तक का रास्ता छोटा करें, जबकि सटीकता, सुरक्षा, और उत्पाद इरादा की जवाबदेही बनाए रखें।
ऐसे टूल्स जैसे Koder.ai इस मॉडल में फिट होते हैं: आप CRUD फीचर को चैट में वर्णित कर सकते हैं, UI और API दोनों में वर्किंग ड्राफ्ट जेनरेट कर सकते हैं, और फिर गार्डरिल्स (जैसे planning mode, snapshots, rollback) के साथ इटरेट कर सकते हैं जबकि मानव परमिशन्स, माइग्रेशन्स, और बिजनेस नियमों के लिए ज़िम्मेदार बने रहते हैं।
1) सीमाएँ और acceptance criteria के साथ प्रॉम्प्ट करें
"एक user management CRUD" माँगने के बजाय किसी विशिष्ट परिवर्तन के साथ बॉर्डर दें।
शामिल करें: framework/version, मौजूदा कन्वेंशन्स, डेटा सीमाएँ, एरर व्यवहार, और "done" का अर्थ क्या है। उदाहरण acceptance criteria: “Duplicates को reject करें, 409 लौटाएँ”, “सिर्फ़ soft-delete”, “Audit log आवश्यक”, “N+1 नहीं”, “मौजूदा टेस्ट सूट पास होना चाहिए।” इससे संभव‑पर‑गलत कोड कम मिलेगा।
2) विकल्प जेनरेट करें, फिर जानबूझकर चुनें
AI से 2–3 approaches माँगें (उदा., “single table बनाम join table”, “REST बनाम RPC endpoint shape”), और trade-offs मांगें: प्रदर्शन, जटिलता, माइग्रेशन रिस्क, परमिशन मॉडल। एक विकल्प चुनें और कारण टिकट/PR में रिकॉर्ड करें ताकि भविष्य के बदलाव drift न करें।
3) उच्च-जोखिम क्षेत्रों के लिए कोड-रिव्यू गेट्स जोड़ें
कुछ फ़ाइलों को “हमेशा मानव-रिव्यू” मानें:
- Permissions/auth: रोल्स, scopes, object-level checks
- Migrations: defaults, backfills, indexes, reversibility
- Data access: query filters, tenant boundaries, pagination
- Logging/observability: PII redaction, correlation IDs, error levels
इसे अपने PR टेम्पलेट (या /contributing) में चेकलिस्ट बनायें।
4) स्रोत-ऑफ़-ट्रुथ स्पेक रखें
कोर एंटिटीज़, वैलिडेशन नियम, और परमिशन निर्णयों के लिए एक छोटा, संपादन योग्य स्पेक (मॉड्यूल README, ADR, या /docs पेज) बनाए रखें। प्रॉम्प्ट में प्रासंगिक अंश पेस्ट करें ताकि जनरेटेड कोड संरेखित रहे बजाय कि नियम "इजाद" करे।
5) "यह शिप हुआ" से परे सफलता मापें
आउटकम ट्रैक करें: CRUD परिवर्तनों का सायकल टाइम, बग रेट (खासतौर पर परमिशन/वैलिडेशन दोष), सपोर्ट टिकट्स, और उपयोगकर्ता सफलताएँ (टास्क कम्प्लीशन, कम मैन्युअल वर्कअराउंड)। यदि ये बेहतर नहीं हो रहे, तो प्रॉम्प्ट कसें, गेट्स जोड़ें, या AI के दायरे को कम करें।