10 नव॰ 2025·8 मिनट
AI-निर्मित प्रणालियों में स्कीमा परिवर्तन और माइग्रेशन: एक मार्गदर्शिका
जानें कि AI-निर्मित प्रणालियाँ स्कीमा परिवर्तनों को कैसे सुरक्षित तरीके से हैंडल करती हैं: वर्शनिंग, बैकवर्ड-कम्पैटिबल रोलआउट, डेटा माइग्रेशन, टेस्टिंग, ऑब्ज़र्वेबिलिटी और रोलबैक रणनीतियाँ।
AI-निर्मित प्रणालियों में “स्कीमा” का मतलब
एक स्कीमा बस डेटा की आकार-रचना और प्रत्येक फ़ील्ड का अर्थ के बारे में साझा समझ है। AI-निर्मित प्रणालियों में वह समझ सिर्फ़ डेटाबेस तालिकाओं तक सीमित नहीं रहती—और यह टीमों की अपेक्षा से अधिक बार बदलती है।
स्कीमा सिर्फ डेटाबेस की चीज़ नहीं है
आप कम से कम चार सामान्य स्तरों पर स्कीमा का सामना करेंगे:
- डेटाबेस: टेबल/कॉलम नाम, डेटा प्रकार, constraints, index और रिलेशनशिप।
- APIs: request/response JSON की संरचना, आवश्यक बनाम वैकल्पिक फ़ील्ड, enums, एरर फॉर्मेट, pagination कन्वेंशन्स।
- इवेंट्स और संदेश: स्ट्रीम, क्यू और वेबहुक में भेजे जाने वाले payloads (अक्सर उपभोक्ताओं के जरिए निहित रूप से versioned)।
- कॉन्फ़िग और कॉन्ट्रैक्ट: फीचर फ्लैग, environment variables, YAML/JSON कॉन्फ़िग, और "छुपे हुए कॉन्ट्रैक्ट" जैसे फ़ाइल फ़ॉर्मेट और नामकरण कन्वेंशन्स।
यदि सिस्टम के दो हिस्से डेटा का आदान-प्रदान करते हैं, तो वहाँ एक स्कीमा है—भले ही किसी ने उसे कागज पर ना लिखा हो।
क्यों AI-निर्मित प्रणालियों में स्कीमा अधिक बदलते हैं
AI-जनित कोड विकास को तेज़ कर सकता है, पर यह churn भी बढ़ाता है:
- उत्पन्न कोड सबसे ताज़ा prompt और context को दर्शाता है, इसलिए छोटे prompt परिवर्तन भी फ़ील्ड नाम, nesting, defaults, या validations बदल सकते हैं।
- जब किसी चीज़ को भेजना सस्ता हो तो requirements तेज़ी से विकसित होते हैं—नए endpoints या pipeline स्टेप जल्दी बन जाते हैं।
- असंगत कन्वेंशन्स (snake_case बनाम camelCase,
idबनामuserId) तब आती हैं जब कई जनरेशन या refactor टीमों में होते हैं।
नतीजा यह है कि producers और consumers के बीच “कॉन्ट्रैक्ट ड्रिफ्ट” अधिक बार होता है।
यदि आप vibe-coding वर्कफ़्लो (उदाहरण के लिए, चैट के जरिए handlers, DB access layers और integrations जनरेट करना) का उपयोग कर रहे हैं, तो यह बेहतर होगा कि उस वर्कफ़्लो में दिन एक से ही स्कीमा अनुशासन डाल दें। Koder.ai जैसी प्लेटफ़ॉर्म्स टीमों को React/Go/PostgreSQL और Flutter ऐप्स चैट इंटरफ़ेस से जल्दी बनाकर मदद करती हैं—लेकिन जितनी तेज़ी से आप शिप कर सकते हैं, उतना ही ज़रूरी है इंटरफ़ेस का versioning, payload वेलिडेशन और deliberate rollouts।
इस गाइड का लक्ष्य
यह पोस्ट वास्तविक तरीकों पर केंद्रित है जो उत्पादन को स्थिर रखते हुए तेज़ी से iterate करने में मदद करें: बैकवर्ड संगतता बनाए रखना, सुरक्षित तरीके से बदलाव रोल आउट करना, और बिना आश्चर्य के डेटा माइग्रेट करना।
हम क्या कवर नहीं करेंगे
हम थ्योरी-भारी मॉडलिंग, फॉर्मल मेथड्स, या vendor-विशिष्ट फीचर्स में गहराई से नहीं जाएंगे। जोर उन पैटर्न्स पर है जिन्हें आप किसी भी स्टैक में लागू कर सकते हैं—चाहे आपकी प्रणाली हाथ से कोड की गई हो, AI-सहायता वाली हो, या मुख्यतः AI-जनित हो।
क्यों AI-जनित कोड के साथ स्कीमा परिवर्तन अधिक होते हैं
AI-जनित कोड स्कीमा परिवर्तनों को “सामान्य” बना देता है—यह इसलिए नहीं कि टीमें लापरवाही कर रही हैं, बल्कि क्योंकि सिस्टम के इनपुट अधिक बार बदलते हैं। जब आपका एप्लिकेशन व्यवहार आंशिक रूप से prompts, मॉडल संस्करणों, और जनरेट किए गए glue कोड द्वारा संचालित होता है, तो डेटा की आकृति समय के साथ किसी न किसी तरह से ड्रीफ़्ट करने की अधिक संभावना रहती है।
व्यावहारिक दुनिया में सामान्य ट्रिगर
कुछ पैटर्न बार-बार स्कीमा churn का कारण बनते हैं:
- नए प्रोडक्ट फीचर्स: नया फ़ील्ड जोड़ना (उदा.,
risk_score,explanation,source_url) या किसी एक कॉन्सेप्ट को कई में बाँटना (उदा.,addressकोstreet,city,postal_codeमें बाँटना)। - मॉडल आउटपुट में बदलाव: नया मॉडल अधिक विस्तृत संरचनाएँ, भिन्न enum मान, या अलग नामकरण दे सकता है ("confidence" बनाम "score").
- प्रॉम्प्ट अपडेट: गुणवत्ता सुधारने के लिए प्रॉम्प्ट बदलने से अनिच्छात रूप से फ़ॉर्मैटिंग, आवश्यक फ़ील्ड, या नेस्टिंग बदल सकती है।
जोखिमभरे पैटर्न जो AI सिस्टम्स को नाज़ुक बनाते हैं
AI-जनित कोड अक्सर जल्दी "काम कर लेता है", पर इसमें नाज़ुक मान्यताएँ एन्कोड हो सकती हैं:
- अस्पष्ट मान्यताएँ: कोड चुपचाप मान लेता है कि कोई फ़ील्ड हमेशा मौजूद है, हमेशा न्यूमेरिक है, या किसी सीमा के भीतर है।
- छुपा हुआ कपलिंग: एक सर्विस दूसरे की आंतरिक फ़ील्ड नामों या ऑर्डरिंग पर निर्भर करती है बजाय किसी परिभाषित इंटरफ़ेस के।
- बेहिसाब फ़ील्ड्स: मॉडल एक नया property देना शुरू कर देता है, और डाउनस्ट्रीम कोड उस पर निर्भर हो जाता है बिना किसी स्पष्ट सहमति के कि वह कॉन्ट्रैक्ट का हिस्सा है।
क्यों AI परिवर्तन आवृत्ति को बढ़ाता है
कोड जनरेशन तेज़ iteration को बढ़ावा देता है: आप handlers, parsers, और DB access layers को requirements के बदलते ही फिर से जनरेट कर देते हैं। यह गति उपयोगी है, पर इसके कारण छोटे इंटरफ़ेस-परिवर्तन बार-बार शिप करना आसान हो जाता है—कभी-कभी बिना ध्यान दिए।
सुरक्षित मानसिकता यह है कि हर स्कीमा को एक कॉन्ट्रैक्ट की तरह समझें: डेटाबेस तालिकाएँ, API payloads, इवेंट्स, और यहां तक कि संरचित LLM रिस्पॉन्स। यदि कोई consumer उस पर निर्भर है, तो उसे version करें, validate करें, और जानबूझकर बदलें।
स्कीमा परिवर्तनों के प्रकार: Additive बनाम Breaking
स्कीमा परिवर्तन समान नहीं होते। सबसे उपयोगी पहला प्रश्न यह है: क्या पुराने consumers बिना किसी बदलाव के काम करते रहेंगे? अगर हाँ, तो यह आम तौर पर additive है। अगर नहीं, तो यह breaking है—और इसे समन्वित rollout योजना की ज़रूरत है।
Additive परिवर्तन (आम तौर पर सुरक्षित)
Additive परिवर्तन मौजूदा अर्थ को बदले बिना उसे बढ़ाते हैं।
सामान्य डेटाबेस उदाहरण:
- एक कॉलम जोड़ना जिसे default दिया गया हो या NULL की अनुमति हो (उदा.,
preferred_language)। - एक नई तालिका या इंडेक्स जोड़ना।
- JSON ब्लॉब में एक वैकल्पिक फ़ील्ड जोड़ना जो कॉलम में स्टोर है।
गैर-डेटाबेस उदाहरण:
- API response में नया property जोड़ना (ग्राहक जो अनजान फ़ील्ड्स को इग्नोर करते हैं, वे काम करते रहेंगे)।
- स्ट्रीम/क्यू संदेश में नया इवेंट फ़ील्ड जोड़ना।
- एक नए फीचर-फ़्लैग वैल्यू को जोड़ना जबकि मौजूदा व्यवहार को default के रूप में रखना।
Additive तभी "सुरक्षित" है जब पुराने consumers tolerant हों: उन्हें अनजान फ़ील्ड्स को इग्नोर करना आना चाहिए और वे नए फ़ील्ड्स की आवश्यकता नहीं रखें।
Breaking परिवर्तन (जोखिमभरे)
Breaking परिवर्तन उस चीज़ को बदलते या हटाते हैं जिस पर consumers पहले से निर्भर हैं।
टिपिकल डेटाबेस breaking परिवर्तन:
- एक कॉलम का प्रकार बदलना (string → integer, timestamp precision बदलना)।
- फ़ील्ड/कॉलम का नाम बदलना (जो कुछ भी पुराने नाम पढ़ रहा है वह फेल हो जाएगा)।
- कोई कॉलम/टेबल ड्रॉप करना जो अभी भी क्वेरी किया जा रहा हो।
गैर-डेटाबेस breaking परिवर्तन:
- request/response JSON फ़ील्ड का नाम बदलना/हटाना।
- इवेंट semantics बदलना (एक ही फ़ील्ड नाम, पर अलग अर्थ)।
- वेबहुक payload संरचना बिना version bump के बदलना।
हमेशा consumer असर लिखें
मर्ज करने से पहले दस्तावेज़ करें:
- कौन इसे उपभोग करता है (सर्विसेज, dashboards, डेटा पाइपलाइन्स, पार्टनर)।
- संगतता (बैकवर्ड/फॉरवर्ड, और कितने समय तक)।
- फेल्यर मोड (parsing errors, silent data corruption, गलत बिजनेस लॉजिक)।
यह छोटा "इम्पैक्ट नोट" स्पष्टता लाता है—खासकर जब AI-जनित कोड implicitly स्कीमा परिवर्तन प्रस्तुत करता है।
स्कीमा और इंटरफेस के लिए वर्शनिंग रणनीतियाँ
Versioning यह बताने का तरीका है कि "यह बदल गया है, और यहाँ कितना जोखिम है।" लक्ष्य कागजी कार्रवाई नहीं है—बल्कि यह है कि जब क्लाइंट्स, सर्विसेज, या डेटा पाइपलाइन्स अलग-अलग गति से अपडेट हों तो silent breakage रोका जाए।
सामान्य भाषा में सेमैंटिक वर्शनिंग मानसिकता
Major / Minor / Patch की तरह सोचें, भले ही आप सचमुच 1.2.3 न प्रकाशित करें:
- Major: breaking change। पुराने consumers बिना बदलाव के fail कर सकते हैं।
- Minor: सुरक्षित विस्तार। पुराने consumers अभी भी काम करेंगे; नए consumers नई क्षमताएँ उपयोग कर सकते हैं।
- Patch: बग फिक्स या स्पष्टता जो अर्थ नहीं बदलती।
एक सरल नियम जो टीमों को बचाता है: कभी मौजूदा फ़ील्ड का अर्थ चुपचाप बदलें नहीं। अगर status=\"active\" पहले "paying customer" का मतलब था, तो उसे "account exists" के रूप में repurpose न करें। नई फ़ील्ड या नई वर्ज़न जोड़ें।
वर्शनड एंडपॉइंट्स बनाम वर्शनड फील्ड्स
आपके पास आम तौर पर दो व्यावहारिक विकल्प होते हैं:
- वर्शनड एंडपॉइंट्स (उदा.,
/api/v1/ordersऔर/api/v2/orders):
जब बदलाव सचमुच breaking या व्यापक हों तो यह अच्छा है। यह स्पष्ट है, पर यह duplication और लंबे समय तक मेंटेनेंस बना सकता है अगर आप कई संस्करण रखते हैं।
- वर्शनड फ़ील्ड्स / additive evolution (उदा.,
new_fieldजोड़ें,old_fieldरखें):
जब आप परिवर्तनों को additively कर सकें तब यह अच्छा है। पुराने क्लाइंट जो समझते नहीं हैं वे अनजान फ़ील्ड्स को इग्नोर कर देते हैं; नए क्लाइंट नया फ़ील्ड पढ़ते हैं। समय के साथ, पुरानी फ़ील्ड को deprecate और हटाने की स्पष्ट योजना बनाएं।
इवेंट स्कीमा और रजिस्ट्रीज़
स्ट्रीम्स, क्यूज़, और वेबहुक के लिए, consumers अक्सर आपके deployment नियंत्रण के बाहर होते हैं। एक स्कीमा रजिस्ट्री (या कोई केंद्रीकृत स्कीमा कैटलॉग जो compatibility checks करता हो) यह लागू करने में मदद करता है जैसे "केवल additive परिवर्तन allowed हैं" और यह स्पष्ट करता है कि कौन से producers और consumers किन वर्ज़न पर निर्भर हैं।
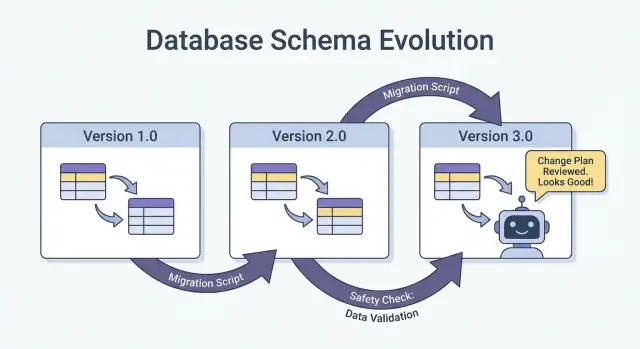
सुरक्षित रोलआउट: Expand/Contract (सबसे विश्वसनीय पैटर्न)
स्कीमा परिवर्तन शिप करने का सबसे सुरक्षित तरीका—ख़ासकर जब आपके पास कई सर्विसेज, जॉब्स, और AI-जनित कंपोनेंट्स हों—है expand → backfill → switch → contract पैटर्न। यह downtime को कम करता है और “all-or-nothing” deployments से बचाता है जहाँ एक पिछड़ा हुआ consumer production तोड़ दे।
चार चरण (और वे क्यों काम करते हैं)
1) Expand: नया स्कीमा एक बैकवर्ड-कम्पैटिबल तरीके से पेश करें। मौजूदा रीडर्स और राइटर्स बिना बदलाव के काम करते रहें।
2) Backfill: ऐतिहासिक डेटा के लिए नए फ़ील्ड्स भरें (या संदेशों को पुनःप्रोसेस करें) ताकि सिस्टम consistent बन जाये।
3) Switch: राइटर्स और रीडर्स को अपडेट करें ताकि वे नए फ़ील्ड/फॉर्मैट का उपयोग करें। यह धीरे-धीरे (canary, percentage rollout) किया जा सकता है क्योंकि स्कीमा दोनों का समर्थन करता है।
4) Contract: पुराने फ़ील्ड/फॉर्मैट को तभी हटाएँ जब आपको पूरा भरोसा हो कि कोई उस पर निर्भर नहीं है।
दो-फ़ेज (expand → switch) और तीन-फ़ेज (expand → backfill → switch) रोलआउट्स downtime घटाते हैं क्योंकि वे tight coupling से बचते हैं: राइटर्स पहले जा सकते हैं, रीडर्स बाद में जा सकते हैं, और विपरीत भी हो सकता है।
उदाहरण: एक कॉलम जोड़ें, बैकफिल करें, फिर इसे required बनाएं
मान लीजिए आप customer_tier जोड़ना चाहते हैं।
- Expand:
customer_tierको nullable के रूप में जोड़ें और default NULL रखें। - Backfill: एक जॉब चलाकर मौजूदा पंक्तियों के लिए tiers गणना करें।
- Switch: ऐप और पाइपलाइन्स को हमेशा
customer_tierलिखने के लिए अपडेट करें, और रीडर्स को इसे प्राथमिकता देने के लिए अपडेट करें। - Contract: मॉनिटरिंग के बाद इसे NOT NULL बनाएं (और वैकल्पिक रूप से लेगेसी लॉजिक हटाएँ)।
समन्वयन: writers और readers का सहमति होना ज़रूरी
हर स्कीमा को producers (writers) और consumers (readers) के बीच एक कॉन्ट्रैक्ट की तरह मानें। AI-निर्मित प्रणालियों में यह आसानी से छूट सकता है क्योंकि नए कोड पथ तेजी से प्रकट होते हैं। रोलआउट्स को स्पष्ट बनाएं: दस्तावेज़ करें कौन सा वर्ज़न क्या लिखता है, कौन सी सर्विसेज दोनों पढ़ सकती हैं, और सटीक "contract date" कब है जब पुराने फ़ील्ड हटाए जा सकेंगे।
डेटाबेस माइग्रेशन्स: बिना प्रोडक्शन तोड़े डेटा कैसे बदलें
परिवर्तनों को सुरक्षित रूप से लागू करें
जब रीडर्स और राइटर्स नए स्कीमा पर सहमत हों, तब अपना ऐप डिप्लॉय और होस्ट करें।
डेटाबेस माइग्रेशन्स उन "निर्देशों" की तरह हैं जो उत्पादन डेटा और संरचना को एक सुरक्षित स्थिति से दूसरी स्थिति में ले जाते हैं। AI-निर्मित प्रणालियों में वे और भी ज़्यादा मायने रखते हैं क्योंकि जनरेट किया गया कोड गलती से किसी कॉलम के मौजूद होने का अनुमान लगा सकता है, फ़ील्ड्स को असंगत रूप से rename कर सकता है, या constraints बदल सकता है बिना मौजूदा rows को ध्यान में रखे।
migration फ़ाइलें बनाम auto-migrations
Migration फ़ाइलें (source control में चेक की जाती हैं) स्पष्ट कदम होते हैं जैसे "add column X", "create index Y", या "copy data from A to B"। वे audit-able, review-able, और staging/production में दोहराए जाने योग्य होते हैं।
Auto-migrations (ORM/framework द्वारा जनरेट) शुरुआती विकास और प्रोटोटाइपिंग के लिए सुविधाजनक हैं, पर वे जोखिमभरे ऑपरेशन्स (कॉलम ड्रॉप करना, टेबल rebuild करना) या परिवर्तनों को अनचाहे क्रम में व्यवस्थित कर सकते हैं।
एक व्यावहारिक नियम: auto-migrations का उपयोग ड्राफ्ट के लिए करें, फिर किसी भी चीज़ के लिए जो प्रोडक्शन को छूती है reviewed migration फ़ाइल में बदल दें।
Idempotency और ordering
माइग्रेशन्स को जहाँ संभव हो idempotent बनाएं: उन्हें फिर से चलाना डेटा को भ्रष्ट या आंशिक कामयाब होने पर फेल नहीं करना चाहिए। "create if not exists" पसंद करें, नए कॉलम पहले nullable के रूप में जोड़ें, और डेटा परिवर्तनों को checks के साथ सुरक्षित रखें।
साथ ही एक स्पष्ट ordering रखें। हर environment (local, CI, staging, prod) को वही migration अनुक्रम लागू करना चाहिए। प्रोडक्शन में मैन्युअल SQL से "fix" न करें जब तक कि आप उसे बाद में migration में कैप्चर न करें।
तालिका को लॉक किए बिना लंबे समय चलने वाले माइग्रेशन्स
कुछ स्कीमा बदलाव बड़े टेबल को लॉक करने पर लेखन (या पढ़ने) को ब्लॉक कर सकते हैं। जोखिम कम करने के उच्च-स्तरीय तरीके:
- अपने डेटाबेस द्वारा सपोर्ट किए गए online/lock-minimizing ऑपरेशन्स का उपयोग करें (उदा., concurrent index builds)।
- बदलावों को चरणों में बाँटें: पहले नई संरचनाएँ जोड़ें, बैचों में backfill करें, फिर ऐप को switch करें।
- भारी ऑपरेशन्स को low-traffic विंडो के दौरान शेड्यूल करें, timeouts और मॉनिटरिंग के साथ।
मल्टी-टेनेंट और शार्डेड सेटअप
मल्टी-टेनेंट डेटाबेस के लिए, हर टेनेंट पर नियंत्रित लूप में माइग्रेशन्स चलाएँ, progress tracking और सुरक्षित retries के साथ। शार्ड्स के लिए, हर शार्ड को अलग प्रोडक्शन सिस्टम की तरह मानें: शार्ड-बाय-शार्ड माइग्रेट करें, हेल्थ सत्यापित करें, फिर आगे बढ़ें। इससे blast radius सीमित रहता है और रोलबैक संभव बनता है।
बैकफिल और रीप्रोसेसिंग: मौजूदा डेटा को अपडेट करना
बैकफिल तब होता है जब आप नए जोड़े गए फ़ील्ड्स (या corrected values) को मौजूदा रिकॉर्ड्स के लिए भरते हैं। रीप्रोसेसिंग तब होती है जब आप ऐतिहासिक डेटा को फिर से किसी पाइपलाइन से चलाते हैं—आम तौर पर क्योंकि बिजनेस नियम बदल गए हैं, कोई बग फिक्स हुआ है, या मॉडल/आउटपुट फॉर्मैट अपडेट हुआ है।
दोनों स्कीमा परिवर्तनों के बाद सामान्य हैं: नए डेटा के लिए नया आकार लिखना आसान है, पर उत्पादन प्रणालियाँ कल के डेटा पर भी निर्भर करती हैं।
सामान्य दृष्टिकोण
ऑनलाइन बैकफिल (प्रोडक्शन में, धीरे-धीरे). आप एक नियंत्रित जॉब चलाते हैं जो छोटे बैचों में रिकॉर्ड्स अपडेट करता है जबकि सिस्टम लाइव रहता है। यह महत्वपूर्ण सेवाओं के लिए सुरक्षित है क्योंकि आप लोड को throttle कर सकते हैं, pause और resume कर सकते हैं।
बATCH बैकफिल (ऑफ़लाइन या शेड्यूल्ड जॉब्स). आप बड़े हिस्सों को low-traffic विंडो में प्रोसेस करते हैं। यह संचालन के लिहाज़ से सरल है, पर डेटाबेस लोड में spikes पैदा कर सकता है और गलतियों से recover करने में अधिक समय लग सकता है।
रीड पर लेज़ी बैकफिल. जब कोई पुराना रिकॉर्ड पढ़ा जाता है, तो एप्लिकेशन गायब फ़ील्ड्स की गणना/पॉप्युलेट करके उसे वापस लिख देता है। यह लागत को समय पर फैलाता है और एक बड़ा जॉब टालता है, पर पहली बार पढ़ने पर धीमा बनता है और "पुराना" डेटा लंबी अवधि तक अप्रतिबद्ध रह सकता है।
व्यवहार में टीमें अक्सर संयोजन करती हैं: लंबी-पूंछ वाले रिकॉर्ड्स के लिए लेज़ी बैकफिल और सबसे ज़्यादा एक्सेस किए जाने वाले डेटा के लिए ऑनलाइन जॉब।
बैकफिल को कैसे सत्यापित करें
सत्यापन स्पष्ट और मापनीय होना चाहिए:
- Counts: कितनी rows/events को अपडेट होना चाहिए बनाम कितनी अपडेट हुईं।
- Checksums/aggregates: कुलों की तुलना करें (उदा., राशि का योग, distinct IDs) पहले/बाद में।
- Sampling: सांख्यिकीय रूप से महत्वपूर्ण नमूने की spot-check, किन मामलों सहित।
डाउनस्ट्रीम प्रभावों का भी सत्यापन करें: dashboards, search indexes, caches, और कोई भी एक्सपोर्ट जो अपडेटेड फ़ील्ड्स पर निर्भर करता है।
लागत, समय, और स्वीकृति मानदंड
बैकफिल तेज़ी (अधिक तेज़ पूरा करना) को जोखिम और लागत (लोड, compute, और ऑपरेशनल ओवरहेड) के साथ trade-off करता है। पहले से acceptance criteria सेट करें: "पूरा" का क्या मतलब है, अपेक्षित रनटाइम, अधिकतम स्वीकार्य त्रुटि दर, और यदि सत्यापन फेल हो तो क्या करना है (pause, retry, या rollback)।
इवेंट और मैसेज स्कीमा विकास (Streams, Queues, Webhooks)
स्कीमा अनुशासन के साथ बनाएं
React, Go और PostgreSQL ऐप को चैट में बनाएं, साथ ही स्कीमा और माइग्रेशन्स को स्पष्ट रखें।
स्कीमा सिर्फ डेटाबेस में नहीं रहते। जब भी एक सिस्टम दूसरे को डेटा भेजता है—Kafka topics, SQS/RabbitMQ queues, webhook payloads, यहां तक कि object storage में लिखे गए "events"—आपने एक कॉन्ट्रैक्ट बनाया है। Producers और consumers स्वतंत्र रूप से चलते हैं, इसलिए ये कॉन्ट्रैक्ट किसी एक एप्लिकेशन की आंतरिक तालिकाओं की तुलना में अधिक बार टूटते हैं।
सबसे सुरक्षित डिफॉल्ट: इवेंट्स को बैकवर्ड-कम्पैटिबली विकसित करें
इवेंट स्ट्रीम और वेबहुक payloads के लिए, ऐसे बदलाव पसंद करें जिन्हें पुराने consumers इग्नोर कर सकें और नए consumers अपना सकें।
व्यावहारिक नियम: फ़ील्ड जोड़ें, हटाएँ या rename न करें। यदि आपको किसी चीज़ को deprecate करना है, तो कुछ समय तक उसे भेजते रहें और उसे deprecated के रूप में दस्तावेज़ करें।
उदाहरण: OrderCreated इवेंट का विस्तार करके वैकल्पिक फ़ील्ड जोड़ें।
{
"event_type": "OrderCreated",
"order_id": "o_123",
"created_at": "2025-12-01T10:00:00Z",
"currency": "USD",
"discount_code": "WELCOME10"
}
पुराने consumers order_id और created_at पढ़ते हैं और बाकी को इग्नोर कर देते हैं।
Consumer-driven contracts (साधारण भाषा में)
Producer यह अनुमान लगाने की बजाय कि क्या दूसरों को टूटेगा, consumers प्रकाशित करें कि वे किन चीज़ों पर निर्भर हैं (फ़ील्ड्स, प्रकार, required/optional नियम)। Producer तब बदलावों को उन अपेक्षाओं के खिलाफ validate करता है इससे पहले कि वे शिप हों। यह विशेष रूप से उपयोगी है AI-जनित कोडबेस में, जहाँ मॉडल "helpfully" फ़ील्ड का नाम बदल सकता है या प्रकार बदल सकता है।
"Unknown fields" को सुरक्षित तरीके से संभालना
पार्सर्स को tolerant बनाएं:
- अनजान फ़ील्ड्स को डिफ़ॉल्ट रूप से इग्नोर करें (केवल इसलिए फ़ेल न करें क्योंकि कोई नया key आया)।
- नए फ़ील्ड्स को वैकल्पिक मानें जब तक आपको वास्तव में उनकी ज़रूरत न हो।
- अप्रत्याशित फ़ील्ड्स को low-level पर log करें ताकि आप adoption issues को बिना paging के देख सकें।
जब आपको breaking change की ज़रूरत हो, तो एक नया इवेंट टाइप या versioned नाम उपयोग करें (उदा., OrderCreated.v2) और दोनों को तब तक समानांतर चलाएँ जब तक सभी consumers migrate न कर लें।
AI आउटपुट को स्कीमा की तरह मानना: प्रॉम्प्ट, मॉडल, और संरचित रिस्पॉन्स
जब आप किसी सिस्टम में LLM जोड़ते हैं, तो उसके आउटपुट तेज़ी से एक de facto स्कीमा बन जाते हैं—भले ही किसी ने औपचारिक स्पेक न लिखा हो। डाउनस्ट्रीम कोड जल्दी ही मान लेता है कि "वहाँ एक summary फ़ील्ड होगा", "पहली पंक्ति शीर्षक है", या "बुलेट डैश से अलग होते हैं"। ये मान्यताएँ समय के साथ कठोर हो जाती हैं, और मॉडल बिहेवियर में छोटा सा शिफ्ट इन्हें उसी तरह तोड़ सकता है जैसे डेटाबेस कॉलम rename करना।
स्पष्ट संरचना पसंद करें (और उसे validate करें)
"सुंदर टेक्स्ट" पार्स करने की बजाय, संरचित आउटपुट (आम तौर पर JSON) माँगें और उन्हें सिस्टम में आने से पहले validate करें। इसे आप "best effort" से एक कॉन्ट्रैक्ट की ओर ले जा रहे हैं।
व्यावहारिक तरीका:
- मॉडल रिस्पॉन्स के लिए एक JSON स्कीमा (या typed interface) परिभाषित करें।
- अवैध रिस्पॉन्स को reject या quarantine करें (उन्हें चुपचाप coercion न करें)।
- validation errors को log करें ताकि आप देख सकें क्या बदल रहा है।
यह विशेष रूप से महत्वपूर्ण है जब LLM रिस्पॉन्स डेटा पाइपलाइन्स, ऑटोमेशन, या उपयोगकर्ता-देखे जाने योग्य कंटेंट को फ़ीड करते हैं।
मॉडल ड्रिफ्ट की योजना बनाएं
इसी प्रॉम्प्ट के साथ भी आउटपुट समय के साथ बदल सकते हैं: फ़ील्ड छूट सकती हैं, अतिरिक्त keys आ सकते हैं, और प्रकार बदल सकते हैं (""42"" बनाम 42, arrays बनाम strings)। इन्हें स्कीमा विकास की घटनाएँ समझें।
कई प्रभावी रोकथाम:
- जहाँ संभव हो फ़ील्ड्स को वैकल्पिक रखें, और defaults स्पष्ट रूप से सेट करें।
- अनजान keys की अनुमति दें पर उन्हें सुरक्षित रूप से इग्नोर करें (जब तक कि आप compliance के लिए strict न हों)।
- "गार्डरेल" चेक जोड़ें (उदा., required फ़ील्ड्स, max lengths, enum मान)।
प्रॉम्प्ट परिवर्तनों को API परिवर्तनों की तरह ट्रीट करें
एक प्रॉम्प्ट भी एक इंटरफ़ेस है। यदि आप इसे संपादित करते हैं, तो उसे वर्ज़न करें। prompt_v1, prompt_v2 रखें, और धीरे-धीरे रोलआउट करें (फीचर फ्लैग्स, canaries, या per-tenant toggles)। बदलाव को promote करने से पहले एक fixed evaluation सेट के साथ टेस्ट करें, और तब तक पुराने वर्ज़न चालू रखें जब तक डाउनस्ट्रीम consumers अनुकूलित न हो जाएँ। सुरक्षित रोलआउट मैकेनिक्स पर अधिक के लिए अपना दृष्टिकोण /blog/safe-rollouts-expand-contract से लिंक करें।
स्कीमा परिवर्तनों के लिए टेस्टिंग और वैलिडेशन
स्कीमा परिवर्तन आमतौर पर उबाऊ, महँगे तरीके से फेल होते हैं: किसी environment में नया कॉलम गायब होना, कोई consumer अभी भी पुराने फ़ील्ड की उम्मीद करना, या माइग्रेशन खाली डेटा पर ठीक चलकर प्रोडक्शन में time out करना। टेस्टिंग इन्हें "सरप्राइज" से predictable, ठीक होने योग्य काम में बदलती है।
तीन स्तर के टेस्ट (और वे क्या पकड़ते हैं)
Unit tests लोकल लॉजिक को रखें: mapping functions, serializers/deserializers, validators, और query builders। यदि कोई फ़ील्ड rename हुआ या प्रकार बदला, तो unit tests उसी कोड के पास फेल होना चाहिए जिसे अपडेट करना है।
Integration tests सुनिश्चित करते हैं कि आपका ऐप असली dependencies के साथ काम करता है: वास्तविक डेटाबेस इंजन, वास्तविक migration टूल, और वास्तविक message फॉर्मैट। यहाँ आपको ऐसी समस्याएँ पकड़ती हैं जैसे "ORM मॉडल बदला पर migration नहीं बनी", या "नया index नाम conflict करता है"।
End-to-end tests उपयोगकर्ता या वर्कफ़्लो आउटकम्स का अनुकरण करते हैं: डेटा बनाएं, उसे migrate करें, APIs के माध्यम से वापस पढ़ें, और सत्यापित करें कि डाउनस्ट्रीम consumers अभी भी सही तरीके से बरताव करते हैं।
प्रोड्यूसर और कंज्यूमर के लिए Contract tests
स्कीमा विकास अक्सर सीमाओं पर टूटता है: सर्विस-टू-सर्विस APIs, स्ट्रीम्स, क्यूज़, वेबहुक। दोनों पक्षों पर contract tests जोड़ें:
- Producers प्रमाणित करें कि वे सहमति हुए कॉन्ट्रैक्ट के अनुरूप events/responses emit कर सकते हैं।
- Consumers प्रमाणित करें कि वे rollout के दौरान पुराने और नए वर्ज़न्स दोनों को parse कर सकते हैं।
माइग्रेशन टेस्टिंग: साफ़ पर्यावरणों पर apply और rollback करें
माइग्रेशन्स को उसी तरह टेस्ट करें जैसा आप उन्हें deploy करेंगे:
- एक clean database snapshot से शुरू करें।
- सभी migrations क्रम में लागू करें।
- सत्यापित करें कि ऐप पढ़/लिख सकता है और लिख/लिख सकता है।
- rollback (यदि समर्थित हो) चलाएँ या "down" migration चलाकर पुष्टि करें कि यह काम करने वाली स्थिति में वापस आता है।
पुराने और नए स्कीमा वर्ज़न्स के लिए fixtures
छोटी fixtures सेट रखें जो दर्शाती हों:
- पिछले स्कीमा के तहत लिखा गया डेटा (legacy rows/events)।
- नए स्कीमा के तहत लिखा गया डेटा।
ये fixtures regressions को स्पष्ट बनाते हैं, खासकर जब AI-जनित कोड मामूली रूप से फ़ील्ड नाम, optionality, या formatting बदल देता है।
ऑब्ज़र्वेबिलिटी: टूटने का जल्दी पता लगाना
मोबाइल क्लाइंट्स को स्थिर रखें
एक Flutter मोबाइल ऐप बनाएं जो आपके बैकएंड स्कीमा बदलने पर भी संगत बना रहे।
स्कीमा बदलाव ज़्यादातर समय पर तेज़ी से जोरदार तरीके से फेल नहीं होते। ज़्यादातर बार टूटना parsing errors, "unknown field" वॉर्निंग्स, गायब डेटा, या बैकग्राउंड जॉब्स के पीछे छूटने के रूप में धीरे-धीरे दिखता है। अच्छी ऑब्ज़र्वेबिलिटी उन कमजोर संकेतों को actionable फीडबैक में बदल देती है जब आप अभी भी rollout रोक सकते हैं।
रोलआउट के दौरान क्या मॉनिटर करें
बेसिक्स (ऐप हेल्थ) से शुरुआत करें, फिर स्कीमा-विशिष्ट संकेत जोड़ें:
- Errors: 4xx/5xx में spike, पर साथ ही "soft" errors जैसे JSON parsing failures, failed deserialization, और retries।
- Latency: p95/p99 response times और queue processing time। स्कीमा बदलाव joins, बड़े payloads, या अतिरिक्त validation जोड़ सकते हैं।
- Data quality signals: महत्वपूर्ण कॉलम्स में null-rate में वृद्धि, इवेंट वॉल्यूम में अचानक गिरावट, नए "default" वैल्यूज़ का बहुत बार आना, या पुराने और नए प्रतिनिधित्व के बीच mismatch।
- Pipeline lag: स्ट्रीम्स/क्यूज़ में consumer lag, webhook delivery backlog, और migration job throughput।
कुंजी है before vs. after की तुलना करना और इसे client version, schema version, और traffic segment (canary बनाम stable) के हिसाब से स्लाइस करना।
उपयोगी डैशबोर्ड्स
दो डैशबोर्ड व्यू बनाएं:
-
ऐप्लिकेशन व्यवहार डैशबोर्ड
- Request rate, error rate, latency (RED)
- Top exceptions (message के अनुसार grouped)
- Validation/parsing error count और प्रतिशत
- Payload size distribution (अनपेक्षित बड़े संदेश पकड़ने के लिए)
-
माइग्रेशन और बैकग्राउंड जॉब डैशबोर्ड
- Migration job progress (% complete), rows processed/sec, ETA
- Failure rate और retry count
- Queue depth / consumer lag
- Dead-letter queue volume (यदि लागू हो)
यदि आप expand/contract रोलआउट चलाते हैं, तो एक पैनल शामिल करें जो पुराने बनाम नए स्कीमा द्वारा reads/writes दिखाता हो ताकि आप देख सकें कब अगले चरण पर जाना सुरक्षित है।
स्कीमा-विशिष्ट फेल्यर्स के लिए अलर्ट्स
ऐसी चीज़ों पर paging करें जो संकेत दें कि डेटा ड्रॉप या गलत तरीके से पढ़ा जा रहा है:
- Schema validation error rate एक कम थ्रेशोल्ड से ऊपर (अक्सर <0.1% भी अर्थपूर्ण होता है)
- Parsing/deserialization failures (खासकर यदि एक producer/consumer में केंद्रित हों)
- Unexpected field / missing required field warnings जो ऊपर की ओर ट्रेंड कर रहे हों
- Migration job stalled (N मिनट के लिए कोई प्रगति नहीं) या lag throughput से तेज़ी से बढ़ना
संदर्भ के बिना कच्चे 500s पर noisy alerts से बचें; alerts को schema rollout टैग्स जैसे schema version और endpoint से जोड़ें।
त्वरित डिबग के लिए वर्ज़न लॉग करें
ट्रांज़िशन के दौरान include और log करें:
- Schema version (उदा.,
X-Schema-Versionheader, message metadata field) - Producer और consumer app version
- Model version / prompt version जब AI-जनित आउटपुट संरचित डेटा को फ़ीड करते हों
यह एक छोटा सा बदलाव "क्यों यह payload फेल हुआ?" का जवाब मिनटों में देने लायक बनाता है, न कि दिनों में—खासकर जब अलग-अलग सर्विसेज (या अलग-अलग AI मॉडल वर्ज़न्स) एक साथ लाइव हों।
रोलबैक, रिकवरी, और बदलाव प्रबंधन
स्कीमा परिवर्तन दो तरह से फेल होते हैं: परिवर्तन स्वयं गलत होता है, या उसके आसपास का सिस्टम उम्मीद के मुताबिक व्यवहार नहीं करता (खासकर जब AI-जनित कोड सूक्ष्म मान्यताएँ जोड़ देता है)। किसी भी तरह, हर माइग्रेशन को शिप करने से पहले एक रोलबैक कहानी चाहिए—भले ही वह कहानी स्पष्ट रूप से "कोई रोलबैक नहीं" ही क्यों न हो।
"कोई रोलबैक नहीं" चुनना वैध हो सकता है जब परिवर्तन reversible न हो (उदा., कॉलम ड्रॉप कर देना, पहचानकर्ताओं का rewrite, या रिकॉर्ड्स का destructive deduplication)। पर "कोई रोलबैक नहीं" योजना की अनुपस्थिति नहीं है; यह निर्णय forward fixes, restores, और containment की दिशा में योजना को खिसकाता है।
व्यवहारिक रोलबैक विकल्प जो असली में काम करते हैं
Feature flags / config gates: नए रीडर्स, राइटर्स, और API फ़ील्ड्स को फ्लैग के पीछे रखें ताकि आप नया व्यवहार बिना redeploy किए बंद कर सकें। यह तब विशेष रूप से उपयोगी है जब AI-जनित कोड syntactically सही पर semantic रूप से गलत हो सकता है।
Dual-write को disable करने का विकल्प रखें: यदि आप expand/contract रोलआउट के दौरान पुराने और नए दोनों स्कीमाओं में लिख रहे हैं, तो एक kill switch रखें। नया write path बंद करने से divergence रोकता है जब आप जाँच कर रहे हों।
Readers को revert करें (सिर्फ़ writers नहीं): कई incidents इसलिए होते हैं क्योंकि consumers नए फ़ील्ड्स या नई तालिकाएँ बहुत जल्दी पढ़ना शुरू कर देते हैं। सेवाओं को आसानी से पिछले स्कीमा वर्ज़न पर point करने या नए फ़ील्ड्स को ignore करने का विकल्प रखें।
reversibility की सीमाएँ जानें
कुछ माइग्रेशन्स साफ़ तरीके से undo नहीं होते:
- Destructive transformations (उदा., hashing, lossy normalization).
- बिना preserved copy के drops/renames.
- backfills जो "source of truth" मानों को overwrite कर देते हैं.
इनके लिए, backup से restore, events से replay, या raw inputs से recompute की योजना बनाएं—और सत्यापित करें कि आपके पास वे inputs अभी भी मौजूद हैं।
प्री-फ्लाइट चेकलिस्ट (शिप करने से पहले)
- Rollback निर्णय दस्तावेज़ित हो ("revert", "forward fix", या "कोई रोलबैक नहीं + restore path")।
- स्पष्ट stop बटन: फ्लैग्स और/या dual-write disable switch।
- बैकअप/स्नैपशॉट सत्यापित; restore कम से कम एक बार टेस्ट किया गया।
- माइग्रेशन idempotent है; reruns डेटा को भ्रष्ट नहीं करेंगे।
- मॉनिटरिंग और अलर्टिंग सेट की हुई है (error rates, schema validation failures, और lag)।
- जिम्मेदारी निर्धारित: किसने approve किया, किसने चलाया, रोलआउट के दौरान कौन on-call है।
अच्छा बदलाव प्रबंधन rollbacks को दुर्लभ बनाता है—और जब वे होते हैं तो recovery को बोरिंग बना देता है।
यदि आपकी टीम AI-सहायता से तेज़ी से इटरट करती है, तो इन प्रथाओं को ऐसे टूलिंग के साथ जोड़े जो सुरक्षित प्रयोग का समर्थन करती हों। उदाहरण के लिए, Koder.ai में upfront change design के लिए planning mode और generated परिवर्तन के अचानक कॉन्ट्रैक्ट शिफ्ट होने पर तेज़ recovery के लिए snapshots/rollback शामिल हैं। तेज़ कोड जनरेशन और अनुशासित स्कीमा विकास मिलकर आपको तेज़ी से आगे बढ़ने देते हैं बिना प्रोडक्शन को टेस्ट-एंवायरनमेंट मानने के।