26 अग॰ 2025·8 मिनट
एप्लिकेशन लॉजिक में मॉडल के साथ AI‑प्रथम उत्पाद कैसे बनाएं
ऐसा व्यावहारिक मार्गदर्शन जिसमें बताया गया है कि कैसे मॉडल को एप्लिकेशन लॉजिक में शामिल करके AI‑प्रथम उत्पाद बनाएं: आर्किटेक्चर, प्रॉम्प्ट, टूल्स, डेटा, मूल्यांकन, सुरक्षा और मॉनिटरिंग।
AI-प्रथम उत्पाद का क्या मतलब है
AI-प्रथम उत्पाद बनाना सिर्फ “एक चैटबॉट जोड़ना” नहीं है। इसका मतलब है कि मॉडल आपके एप्लिकेशन लॉजिक का असली, काम करने वाला हिस्सा है—ठीक उसी तरह जैसे कोई रूल्स इंजन, सर्च इंडेक्स, या सिफारिश एल्गोरिद्म होता है।
आपकी ऐप सिर्फ AI इस्तेमाल नहीं कर रही; वह इस पर डिज़ाइन की गई है कि मॉडल इनपुट की व्याख्या करेगा, कार्रवाई चुन सकेगा, और स्ट्रक्चर्ड आउटपुट देगा जिस पर सिस्टम का बाकी हिस्सा निर्भर करेगा।
व्यवहारिक रूप से: हर निर्णय पथ को हार्ड-कोड करने की बजाय ("यदि X तो Y"), आप मॉडल को उन अस्पष्ट हिस्सों—भाषा, इरादा, अस्पष्टता, प्राथमिकता—का सामना करने देते हैं, जबकि आपका कोड उन चीज़ों को संभाले जो सटीक होना चाहिए: अनुमतियाँ, भुगतान, डेटाबेस लिखना और नीति प्रवर्तन।
कब AI-प्रथम उपयुक्त है (और कब नहीं)
AI-प्रथम तब सबसे अच्छा काम करता है जब समस्या में:
- बहुत सारे वैध इनपुट हों (फ्री टेक्स्ट, बिखरे दस्तावेज़, विविध उपयोगकर्ता उद्देश्य)
- हाथ से नियम बनाए रखना बहुत से एज केस उत्पन्न करे
- निर्णायकता की बजाय जजमेंट, संक्षेपण, या संश्लेषण में मूल्य हो
रूल-आधारित ऑटोमेशन सामान्यतः बेहतर होता है जब आवश्यकताएँ स्थिर और सटीक हों—टैक्स कैलकुलेशन, इन्वेंटरी लॉजिक, योग्यता चेक्स, या अनुपालन वर्कफ़्लो जहाँ आउटपुट हर बार समान होना चाहिए।
सामान्य उत्पाद लक्ष्य जो AI-प्रथम समर्थन करते हैं
टीमें आमतौर पर मॉडल-ड्रिवन लॉजिक को अपनाती हैं ताकि:
- गति बढ़े: ड्राफ्ट प्रतिक्रियाएँ बनाना, फ़ील्ड निकालना, अनुरोध तेज़ी से रूट करना
- अनुभव व्यक्तिगत बनें: स्पष्टीकरण, योजनाएँ, या सिफारिशें टेलर करना
- निर्णयों का समर्थन करना: ट्रेड‑ऑफ़ दिखाना, विकल्प जनरेट करना, साक्ष्य संक्षेप करना
जिन ट्रेडऑफ़ को आपको स्वीकार करना और डिज़ाइन करना चाहिए
मॉडल कभी-कभी अनपेक्षित हो सकते हैं, आत्मविश्वास से गलत उत्तर दे सकते हैं, और उनका व्यवहार प्रॉम्प्ट, प्रदाता, या प्राप्त संदर्भ बदलने पर बदल सकता है। वे प्रति‑रिक्वेस्ट लागत भी जोड़ते हैं, लेटेंसी बढ़ा सकते हैं, और सुरक्षा व भरोसा (गोपनीयता, हानिकारक आउटपुट, नीति उल्लंघन) के मुद्दे उठाते हैं।
सही मानसिकता यह है: मॉडल एक कंपोनेंट है, किसी जादुई उत्तर-डिब्बे की तरह नहीं। इसे एक निर्भरता की तरह ट्रीट करें—स्पेसिफ़िकेशन, फेलियर मोड, टेस्ट और मॉनिटरिंग के साथ—ताकि आपको लचीलापन मिलें बिना पूरी उम्मीदों पर उत्पाद को दाँव लगाने के।
सही उपयोग‑केस चुनें और सफलता परिभाषित करें
हर फीचर से मॉडल को चालक की सीट देने का लाभ नहीं मिलता। सर्वश्रेष्ठ AI-प्रथम उपयोग‑केस एक स्पष्ट नौकरी‑टू‑बी‑डन के साथ शुरू होते हैं और एक मापनीय परिणाम के साथ समाप्त होते हैं जिसे आप सप्ताह दर सप्ताह ट्रैक कर सकते हैं।
मॉडल से शुरू न करें—नौकरी से शुरू करें
एक वाक्य का जॉब स्टोरी लिखें: “जब ___, मैं चाहूँगा ___, ताकि मैं ___।” फिर परिणाम को मापनीय बनाएं।
उदाहरण: “जब मुझे लंबा ग्राहक ईमेल मिलता है, मैं चाहूँगा हमारी नीतियों के अनुरूप एक सुझाया गया जवाब मिले, ताकि मैं 2 मिनट से कम में उत्तर दे सकूँ।” यह “ईमेल में एक LLM जोड़ें” से कहीं अधिक कर्मठ है।
निर्णय‑बिंदुओं का मानचित्र बनाएं
उन क्षणों की पहचान करें जहाँ मॉडल कार्रवाई चुनेगा। ये निर्णय‑बिंदु स्पष्ट होने चाहिए ताकि आप उनका परीक्षण कर सकें।
सामान्य निर्णय‑बिंदुओं में शामिल हैं:
- इरादा क्लासिफाई करके सही वर्कफ़्लो पर रूट करना
- तय करना कि क्या एक स्पष्ट करने वाला प्रश्न पूछा जाए या आगे बढ़ें
- टूल्स का चयन करना (सर्च, CRM लुकअप, ड्राफ्टिंग, टिकट बनाना)
- तय करना कि कब मानव को एस्केलेट किया जाए
यदि आप निर्णयों को नाम नहीं दे सकते, तो आप मॉडल-ड्रिवन लॉजिक को शिप करने के लिए तैयार नहीं हैं।
व्यवहार के लिए एक्सेप्टेंस क्राइटीरिया लिखें
मॉडल व्यवहार को किसी भी अन्य उत्पाद आवश्यकता की तरह ट्रीट करें। स्पष्ट भाषा में परिभाषित करें कि “अच्छा” और “खराब” कैसा दिखता है।
उदाहरण के लिए:
- अच्छा: नवीनतम नीति का उपयोग करता है, सही ऑर्डर ID का हवाला देता है, यदि जानकारी ग़ायब है तो एक स्पष्ट प्रश्न पूछता है
- खराब: डिस्काउंट का आविष्कार करता है, असमर्थित लोकेल का संदर्भ देता है, या आवश्यक डेटा की जांच किए बिना उत्तर देता है
ये मानदंड बाद में आपके मूल्यांकन सेट के लिए आधार बन जाते हैं।
सीमाएँ जल्दी पहचान लें
उन सीमाओं की सूची बनाएं जो आपके डिज़ाइन चुनावों को आकार दें:
- समय (प्रतिक्रिया लेटेंसी लक्ष्य)
- बजट (प्रति‑टास्क लागत)
- अनुपालन (PII हैंडलिंग, ऑडिट आवश्यकताएँ)
- समर्थित लोकेल (भाषाएँ, टोन, सांस्कृतिक अपेक्षाएँ)
निगरानी योग्य सफलता मीट्रिक परिभाषित करें
नौकरी से जुड़ी कुछ मीट्रिक्स चुनें:
- टास्क पूरा होने की दर
- प्रतिनिधि मामलों पर सटीकता (या नीति अनुपालन)
- CSAT या गुणात्मक उपयोगकर्ता रेटिंग
- प्रति‑टास्क समय की बचत (या समाधान का समय)
यदि आप सफलता माप नहीं सकते, तो आप अंततः सुधार की बजाय महसूसात पर बहस करेंगे।
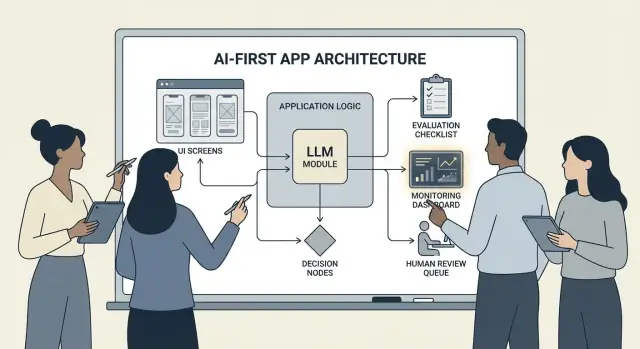
AI‑ड्रिवन यूजर फ्लो और सिस्टम सीमाएँ डिज़ाइन करें
एक AI-प्रथम फ्लो सिर्फ "एक स्क्रीन जो LLM कॉल करती है" नहीं है। यह एक एन्ड‑टू‑एन्ड यात्रा है जहाँ मॉडल कुछ निर्णय लेता है, उत्पाद उन्हें सुरक्षित ढंग से निष्पादित करता है, और उपयोगकर्ता ओरिएंटेड रहता है।
एंड‑टू‑एंड लूप का मानचित्र बनाएं
पाइपलाइन को सरल चैन के रूप में बनाएं: इन्पुट → मॉडल → एक्शंस → आउटपुट।
- इन्पुट: उपयोगकर्ता जो प्रदान करता है (टेक्स्ट, फाइलें, चयन) साथ ही एप संदर्भ (खाता स्तर, वर्कस्पेस, हाल की गतिविधि)।
- मॉडल स्टेप: वह क्या है जिसके लिए मॉडल जिम्मेदार है (क्लासिफाई, ड्राफ्ट, संक्षेप, अगली कार्रवाई चुनना)।
- एक्शंस: जो आपका सिस्टम कर सकता है (सर्च, टास्क बनाना, रिकॉर्ड अपडेट, ईमेल भेजना)।
- आउटपुट: उपयोगकर्ता क्या देखता है (एक ड्राफ्ट, व्याख्या, पुष्टि स्क्रीन, अगले कदम के साथ एरर)।
यह मानचित्र स्पष्ट करता है कि कहाँ अनिश्चितता स्वीकार्य है (ड्राफ्टिंग) और कहाँ नहीं (बिलिंग में परिवर्तन)।
सिस्टम सीमाएँ: मॉडल बनाम निर्धारक कोड
निर्धारक पाथ (अनुमतियाँ, बिजनेस नियम, कैलकुलेशन, DB लिखना) को मॉडल‑ड्रिवन निर्णयों (व्याख्या, प्राथमिकता, प्राकृतिक‑भाषा पीढ़न) से अलग करें।
एक उपयोगी नियम: मॉडल सिफारिश कर सकता है, लेकिन कोई भी अपरिवर्तनीय कार्रवाई करने से पहले कोड को सत्यापित करना चाहिए।
मॉडल कहाँ चलेगा, तय करें
रनटाइम चुनें:
- सर्वर: निजी डेटा, सुसंगत टूलिंग, और ऑडिट लॉग्स के लिए बेहतर।
- क्लाइंट: हल्के असिस्टेंस और लोकल‑प्रॉसेसिंग गोपनीयता के लिए उपयोगी, पर नियंत्रित करना कठिन।
- एज: वैश्विक लेटेंसी कम, पर निर्भरताएँ सीमित।
- हाइब्रिड: एज पर तेज़ इरादा पता करना और सर्वर पर भारी काम।
लेटेंसी, लागत और डेटा परमिशन का बजट बनाएं
प्रति‑रिक्वेस्ट लेटेंसी और लागत बजट सेट करें (रिट्राई और टूल कॉल सहित), और उसके अनुरूप UX डिज़ाइन करें (स्ट्रीमिंग, प्रोग्रेसिव परिणाम, “बैकग्राउंड में जारी रखें”)।
प्रत्येक स्टेप में आवश्यक डेटा स्रोत और परमिशन दस्तावेज़ करें: मॉडल क्या पढ़ सकता है, क्या लिख सकता है, और किस चीज़ के लिए उपयोगकर्ता की स्पष्ट पुष्टि चाहिए। यह इंजीनियरिंग और ट्रस्ट दोनों के लिए एक अनुबंध बनता है।
आर्किटेक्चर पैटर्न: ऑर्केस्ट्रेशन, स्टेट, और ट्रेसेज़
जब मॉडल आपके ऐप लॉजिक का हिस्सा होता है, तो "आर्किटेक्चर" सिर्फ सर्वर और API नहीं है—यह इस बात का ढांचा है कि आप मॉडल के निर्णयों की श्रृंखला को नियंत्रित और विश्वसनीय तरीके से कैसे चलाते हैं।
ऑर्केस्ट्रेशन: मॉडल‑वर्क का कंडक्टर
ऑर्केस्ट्रेशन वह परत है जो एक AI टास्क के एंड‑टू‑एन्ड निष्पादन को मैनेज करती है: प्रॉम्प्ट और टेम्पलेट, टूल कॉल्स, मेमोरी/कॉन्टेक्स्ट, रिट्राई, टाइमआउट, और फोलबैक।
अच्छे ऑर्केस्ट्रेटर मॉडल को पाइपलाइन का एक घटक मानते हैं। वे तय करते हैं कि कौन‑सा प्रॉम्प्ट उपयोग करना है, कब टूल कॉल करना है (सर्च, DB, ईमेल, पेमेंट), कैसे संदर्भ को कंप्रेस या प्राप्त करना है, और अगर मॉडल अमान्य लौटाए तो क्या करना है।
यदि आप आइडिया से कार्यशील ऑर्केस्ट्रेशन तक तेजी से बढ़ना चाहते हैं, तो एक vibe‑coding वर्कफ़्लो प्रोटोटाइप बनाने में मदद कर सकता है बिना ऐप के स्कैफोल्ड को फिर से बनाने के। उदाहरण के लिए, Koder.ai टीमों को चैट के माध्यम से वेब ऐप्स (React), बैकएंड (Go + PostgreSQL), और मोबाइल ऐप्स (Flutter) बनाने देता है—फिर "इन्पुट → मॉडल → टूल कॉल → वेलिडेशन → UI" जैसे फ्लोज़ पर प्लानिंग मोड, स्नैपशॉट और रोलबैक जैसी सुविधाओं के साथ इटरेट करने देता है, और जब आप रेपो अपने पास रखना चाहें तो सोर्स‑कोड एक्सपोर्ट भी देता है।
मल्टी‑स्टेप टास्क के लिए स्टेट मशीन
मल्टी‑स्टेप अनुभव (ट्रायाज → जानकारी इकट्ठा करना → पुष्टि → निष्पादित करना → संक्षेप) वर्कफ़्लो या स्टेट मशीन के रूप में मॉडल करना सबसे अच्छा होता है।
एक सरल पैटर्न: प्रत्येक चरण के पास (1) अनुमत इनपुट, (2) अपेक्षित आउटपुट, और (3) संक्रमण हों। इससे भटकती बातचीत रोकी जा सकती है और एज‑केस स्पष्ट होते हैं—जैसे उपयोगकर्ता मन बदल दे या आंशिक जानकारी दे तो क्या होता है।
सिंगल‑शॉट बनाम मल्टी‑टर्न reasoning
सिंगल‑शॉट उन संयत कार्यों के लिए अच्छा है: संदेश क्लासिफाई करना, छोटा जवाब ड्राफ्ट करना, दस्तावेज़ से फ़ील्ड निकालना। यह सस्ता, तेज़ और वैध करने में आसान है।
मल्टी‑टर्न reasoning तब बेहतर है जब मॉडल को स्पष्ट प्रश्न पूछने हों या जब टूल्स को पुनरावृत्त रूप से बुलाना पड़े (जैसे योजना → सर्च → परिष्कृत करना → पुष्टि)। इसे मजबूती से इस्तेमाल करें, और लूप्स को समय/स्टेप सीमा के साथ कैप करें।
आइडेम्पोटेंसी: दोहराए जाने वाले साइड‑इफ़ेक्ट से बचें
मॉडल रिट्राई करते हैं। नेटवर्क फेल होते हैं। उपयोगकर्ता डबल‑क्लिक करते हैं। यदि कोई AI स्टेप साइड‑इफ़ेक्ट ट्रिगर कर सकता है—ईमेल भेजना, बुकिंग, चार्ज करना—तो उसे आइडेम्पोटेंट बनाएं।
सामान्य रणनीतियाँ: प्रत्येक "निष्पादित" एक्शन के साथ एक आइडेम्पोटेंसी की जोड़ें, एक्शन रिज़ल्ट स्टोर करें, और सुनिश्चित करें कि रिट्राई में वही आउटपुट लौटे न कि उसे दोहराया जाए।
ट्रेसेज़: हर स्टेप को डिबग करने योग्य बनाएं
ट्रैसैबिलिटी जोड़ें ताकि आप जवाब दे सकें: मॉडल ने क्या देखा? उसने क्या निर्णय लिया? कौन‑से टूल चले?
प्रति रन एक स्ट्रक्चर्ड ट्रेस लॉग करें: प्रॉम्प्ट वर्शन, इनपुट, रिट्रीव किए गए संदर्भ IDs, टूल रिक्वेस्ट/रिस्पॉन्स, वेलिडेशन एरर्स, रिट्राई, और फाइनल आउटपुट। यह "AI ने कुछ अजीब किया" को एक ऑडिटेबल, ठीक करने योग्य टाइमलाइन में बदल देता है।
प्रॉम्प्टिंग को उत्पाद लॉजिक की तरह देखें: स्पष्ट कॉन्ट्रैक्ट और फॉर्मैट
जब मॉडल आपके एप्लिकेशन लॉजिक का हिस्सा हो, तो आपके प्रॉम्प्ट "कॉपी" की तरह नहीं रहते बल्कि executable स्पेसिफिकेशन बन जाते हैं। इन्हें उत्पाद आवश्यकताओं की तरह ट्रीट करें: स्पष्ट स्कोप, प्रेडिक्टेबल आउटपुट, और चेंज कंट्रोल।
सिस्टम प्रॉम्प्ट से कॉन्ट्रैक्ट शुरू करें
आपका सिस्टम प्रॉम्प्ट मॉडल की भूमिका, वह क्या कर सकता/नहीं कर सकता, और आपके उत्पाद के लिए महत्वपूर्ण सुरक्षा नियम निर्धारित करना चाहिए। इसे स्थिर और पुन:उपयोग योग्य रखें।
शामिल करें:
- भूमिका और लक्ष्य: वह कौन है (उदा., “सपोर्ट ट्रायाज असिस्टेंट”) और सफलता कैसी दिखती है।
- स्कोप सीमाएँ: किन अनुरोधों को उसे नकारना या एस्केलेट करना चाहिए।
- सुरक्षा नियम: PII हैंडलिंग, मेडिकल/कानूनी डिस्क्लेमर, अनुमान न लगाना।
- टूल नीति: कब टूल कॉल करना चाहिए बनाम सीधे उत्तर देना।
इनपुट/आउटपुट के साथ प्रॉम्प्ट संरचित करें
प्रॉम्प्ट को API परिभाषा की तरह लिखें: वे सटीक इनपुट सूचीबद्ध करें जो आप प्रदान करते हैं (उपयोगकर्ता टेक्स्ट, खाता स्तर, लोकेल, नीति स्निपेट्स) और वे सटीक आउटपुट जो आप अपेक्षित करते हैं। 1–3 उदाहरण जोड़ें जो असली ट्रैफिक से मेल खाते हों, जिसमें जटिल एज‑केस भी शामिल हों।
एक उपयोगी पैटर्न है: संदर्भ → कार्य → प्रतिबंध → आउटपुट फॉर्मैट → उदाहरण।
मशीन‑रीडेबल परिणामों के लिए सीमित फॉर्मैट का उपयोग करें
यदि कोड को आउटपुट पर कार्रवाई करनी है, तो गद्य पर भरोसा न करें। JSON माँगे जो एक स्कीमा से मेल खाता हो और बाकी सब कुछ अस्वीकार करें।
{
"type": "object",
"properties": {
"intent": {"type": "string"},
"confidence": {"type": "number", "minimum": 0, "maximum": 1},
"actions": {
"type": "array",
"items": {"type": "string"}
},
"user_message": {"type": "string"}
},
"required": ["intent", "confidence", "actions", "user_message"],
"additionalProperties": false
}
प्रॉम्प्ट वर्ज़न करें और सुरक्षित रोल‑आउट करें
प्रॉम्प्ट्स को वर्शन कंट्रोल में रखें, रिलीज़ टैग करें, और फीचर की तरह रोल आउट करें: स्टेज्ड डिप्लॉयमेंट, जहां उपयुक्त A/B, और तेज़ रोलबैक। हर रिस्पॉन्स के साथ प्रॉम्प्ट वर्शन लॉग करें ताकि डिबग आसान हो।
प्रॉम्प्ट टेस्ट सूट बनाएं
छोटा, प्रतिनिधि केस सेट (हैप्पी पाथ, अस्पष्ट अनुरोध, नीति उल्लंघन, लंबा इनपुट, अलग‑अलग लोकेल) बनाएं। हर प्रॉम्प्ट परिवर्तन पर इन्हें ऑटोमैटिक रूप से चलाएँ, और जब आउटपुट कॉन्ट्रैक्ट तोड़ें तो बिल फेल कर दें।
टूल कॉलिंग: मॉडल फैसला करे, कोड निष्पादित करे
इसे मोबाइल पर लाएँ
उसी चैट वर्कफ़्लो का इस्तेमाल कर अपने AI-फर्स्ट प्रोडक्ट में Flutter मोबाइल ऐप जोड़ें।
टूल कॉलिंग ज़िम्मेदारियों को सबसे साफ़ ढंग से विभाजित करती है: मॉडल तय करता है क्या होना चाहिए और कौन‑सी क्षमता इस्तेमाल करनी है, जबकि आपका एप्लिकेशन कोड कार्रवाई संपादित करता है और सत्यापित परिणाम लौटाता है।
इससे तथ्य, कैलकुलेशन, और साइड‑इफ़ेक्ट्स (टिकट बनाना, रिकॉर्ड अपडेट, ईमेल भेजना) निर्धारक, ऑडिटेबल कोड में रहते हैं—बजाय फ्री‑फॉर्म टेक्स्ट पर भरोसा करने के।
छोटा, इरादापूर्ण टूलसेट डिज़ाइन करें
शुरू में कुछ ऐसे टूल रखें जो 80% अनुरोधों को कवर करें और सुरक्षित रखना आसान हों:
- सर्च (आपका डॉक/हेल्प सेंटर) ताकि प्रोडक्ट सवालों का जवाब मिल सके
- DB लुकअप (पहले केवल पढ़ने के लिए) उपयोगकर्ता/खाता/ऑर्डर स्थिति के लिए
- कैलकुलेटर मूल्य निर्धारण, टोटल्स, कन्वर्ज़न और नियम‑आधारित गणित के लिए
- टिकटिंग जब उपयोगकर्ता को मानव फॉलो‑अप की आवश्यकता हो तो सपोर्ट रिक्वेस्ट खोलने के लिए
हर टूल का उद्देश्य संकुचित रखें। "कुछ भी" करने वाला टूल टेस्ट करना कठिन और दुरुपयोग के लिए आसान बन जाता है।
इनपुट का सत्यापन करें, आउटपुट को सैनिटाइज़ करें
मॉडल को एक अनविश्वसनीय कॉलर की तरह ट्रीट करें।
- टूल इनपुट वेलिडेट करें सख्त स्कीमा (टाइप्स, रेंज, एनम्स) के साथ। असुरक्षित आर्ग्यूमेंट्स को अस्वीकार या मरम्मत करें (उदा., गायब IDs, बेहद व्यापक क्वेरीज)।
- टूल आउटपुट सैनिटाइज़ करें मॉडल को देने से पहले: सीक्रेट्स हटाएँ, फार्मैट सामान्य करें, और केवल वह फ़ील्ड लौटाएँ जिसकी मॉडल को ज़रूरत है।
यह रिट्रीवल‑इंजेक्शन के जोखिम को कम करता है और आकस्मिक डेटा लीक को सीमित करता है।
टूल पर परमिशन और रेट‑लिमिट जोड़ें
हर टूल को लागू करना चाहिए:
- परमिशन चेक्स (कौन किस रिकॉर्ड/एक्शन तक पहुँच सकता है)
- रेट‑लिमिट्स (प्रति उपयोगकर्ता/सेशन/टूल) दुरुपयोग और अनियंत्रित लूप्स कम करने के लिए
यदि कोई टूल स्टेट बदल सकता है (टिकटिंग, रिफंड), तो मजबूत ऑथराइज़ेशन और ऑडिट लॉग की आवश्यकता रखें।
हमेशा “नो टूल” पाथ सपोर्ट करें
कभी‑कभी सबसे अच्छा कदम कोई कदम न लेना है: मौजूदा संदर्भ से उत्तर देना, एक स्पष्ट प्रश्न पूछना, या सीमाएँ समझाना।
"नो टूल" को पहले दर्जे का परिणाम बनाएं ताकि मॉडल सिर्फ व्यर्थ टूल कॉल न करे।
डेटा और RAG: मॉडल को आपकी वास्तविकता में ग्राउंड करें
यदि आपके उत्पाद के उत्तर आपकी नीतियों, इन्वेंटरी, अनुबंधों, या आंतरिक ज्ञान से मेल खाने चाहिए, तो आपको मॉडल को अपने डेटा में ग्राउंड करने का तरीका चाहिए—सिर्फ उसके सामान्य ट्रेनिंग के बजाय।
RAG बनाम फाइन‑ट्यूनिंग बनाम सरल कॉन्टेक्स्ट
- सरल कॉन्टेक्स्ट (प्रॉम्प्ट में कुछ पैराग्राफ पेस्ट करना) तब काम करता है जब ज्ञान छोटा, स्थिर हो, और आप हर बार भेजने का खर्च उठा सकते हों (उदा., छोटा प्राइसिंग टेबल)।
- RAG (Retrieval‑Augmented Generation) उस समय सबसे अच्छा है जब जानकारी बड़ी, बार‑बार बदलने वाली, या उद्धरण मांगने वाली हो (उदा., हेल्प‑सेंटर आर्टिकल्स, प्रोडक्ट डॉक, खाता‑विशिष्ट डेटा)।
- फाइन‑ट्यूनिंग तब अच्छा है जब आप सुसंगत शैली/फॉर्मैट चाहते हैं या डोमेन‑विशिष्ट पैटर्न—not facts स्टोर करने का प्राथमिक तरीका नहीं बनाना चाहिए। इसे RAG के साथ जोड़कर इस्तेमाल करें ताकि तथ्य अद्यतित रहें।
इनजेशन बेसिक्स: चंकिंग, मेटाडेटा, फ्रेशनेस
RAG की गुणवत्ता काफी हद तक इनजेशन समस्या है।
दस्तावेज़ों को मॉडल के लिए उपयुक्त आकार के चंक्स में विभाजित करें (अक्सर कुछ सौ टोकन्स), और उन्हें प्राकृतिक सीमाओं (हेडिंग्स, FAQ एंट्री) के अनुसार अलाइन करें। मेटाडेटा स्टोर करें जैसे: डॉक टाइटल, सेक्शन हेडिंग, प्रोडक्ट/वर्शन, ऑडियंस, लोकेल, और परमिशन।
ताज़गी की योजना बनाएं: री‑इंडेक्सिंग शेड्यूल करें, "अंतिम अपडेट" ट्रैक करें, और पुराने चंक्स को एक्सपायर करें। एक स्टेल चंक जो ऊंचा रैंक करता है वह धीरे‑धीरे फ़ीचर खराब कर देगा।
उद्धरण और संतुलित उत्तर
मॉडल को स्रोत उद्धरण देने के लिए कहें: (1) उत्तर, (2) स्निपेट IDs/URLs की सूची, और (3) एक आत्म‑विश्वास स्टेटमेंट।
यदि रिट्रीवल पतला है, तो मॉडल को निर्देश दें कि जो वह पुष्टि नहीं कर सकता वह बताए और अगले कदम सुझाए ("मैं वह नीति नहीं ढूँढ पाया; यहाँ संपर्क कौन है")। रिक्तियों को भरने न दें।
निजी डेटा: एक्सेस कंट्रोल और रेडैक्शन
रिट्रीवल से पहले एक्सेस निश्चहित करें (यूज़र/ऑर्ग परमिशन के द्वारा फ़िल्टर करें) और जनरेशन से पहले रेडक्ट भी करें (संवेदी फ़ील्ड हटाएँ)।
एम्बेडिंग्स और इंडेक्सेस को संवेदनशील डेटा स्टोर्स की तरह ट्रीट करें और ऑडिट लॉग रखें।
जब रिट्रीवल फेल हो: ग्रेसफ़ुल फॉलबैक
यदि टॉप रिज़ल्ट निरर्थक या खाली हों, तो फॉलबैक करें: एक स्पष्ट करने वाला प्रश्न पूछना, मानव सपोर्ट पर रूट करना, या एक गैर‑RAG मोड जिसमें सीमाएँ बताईं जाएँ बजाय अनुमान लगाने के।
विश्वसनीयता: गार्ड्रेल्स, वेलिडेशन और कैशिंग
जब मॉडल आपके ऐप लॉजिक में बैठता है, तो "अच्छा अधिकांश समय" काफी नहीं है। विश्वसनीयता का मतलब है उपयोगकर्ता सुसंगत व्यवहार देखें, आपका सिस्टम सुरक्षित रूप से आउटपुट ले सके, और विफलताएँ गरैस्फुल तरीके से घटें।
पहले विश्वसनीयता लक्ष्य परिभाषित करें
लिखित लिखें कि फीचर के लिए "विश्वसनीय" क्या मतलब है:
- सुसंगत आउटपुट: समान इनपुट समान उत्तर (टोन, विवरण स्तर, प्रतिबंध) दें
- स्थिर फॉर्मैट: रिस्पॉन्स हर बार पार्सेबल होना चाहिए (JSON, बुलेट, फ़ील्ड)
- सीमित व्यवहार: मॉडल क्या नहीं करेगा इसकी स्पष्ट सीमाएँ (अनुमान न करें, स्रोत बताएं, अनिश्चित होने पर प्रश्न पूछें)
ये लक्ष्य प्रॉम्प्ट और कोड दोनों के लिए एक्सेप्टेंस क्राइटीरिया बन जाते हैं।
गार्ड्रेल्स: वेलिडेट, फ़िल्टर, और पॉलिसी लागू करें
मॉडल आउटपुट को अनट्रस्टेड इनपुट की तरह ट्रीट करें।
- स्कीमा वेरिफिकेशन: सख्त फॉर्मैट (उदा., JSON) की आवश्यकता और जो पार्स न हो उसे अस्वीकार करें।
- कंटेंट फ़िल्टर: प्रोफेनी चेक्स, PII डिटेक्टर, या पॉलिसी वेरिफायर इंस्टॉल करें—यूज़र इनपुट और मॉडल आउटपुट दोनों पर।
- बिजनेस नियम: मूल्य सीमा, योग्यता नियम, अनुमत क्रियाएँ कोड में लागू करें भले ही प्रॉम्प्ट उन्हें बताता हो।
यदि वेलिडेशन फेल हो, तो एक सुरक्षित फॉलबैक लौटाएँ (स्पष्ट प्रश्न पूछना, सरल टेम्पलेट पर स्विच करना, या मानव को रूट करना)।
वास्तव में मदद करने वाले रिट्राई
अंधाधुंध रिपीटेशन से बचें। फेलियर मोड को संबोधित करने वाले बदले हुए प्रॉम्प्ट के साथ रिट्राई करें:
- "केवल वैध JSON लौटाएँ। कोई मार्कडाउन नहीं।"
- "यदि निश्चित नहीं, तो
confidenceको low पर सेट करें और एक प्रश्न पूछें।"
रिट्राई कैप करें और हर फेलियर के कारण को लॉग करें।
निर्धारक पोस्ट‑प्रोसेसिंग
कोड का उपयोग करके मॉडल के परिणाम को सामान्य करें:
- यूनिट्स, तारीखें, और नामों को कैनोनिकलाइज़ करें
- आइटम्स को डुप्लिकेट न करें
- रैंकिंग नियम या थ्रेशोल्ड लागू करें
यह वैरिएंस घटाता है और आउटपुट को टेस्ट करना आसान बनाता है।
गोपनीयता समस्याएँ नहीं बनाने वाली कैशिंग
बार‑बार आने वाले रिज़ल्ट्स (समान क्वेरीज, साझा एम्बेडिंग्स, टूल रिस्पॉन्स) कैश करें ताकि लागत और लेटेंसी घटे।
प्राथमिकताएँ:
- उपयोगकर्ता‑विशिष्ट डेटा के लिए कम TTL
- कैश कीज़ में कच्चे PII को शामिल न करें (या सावधानीपूर्वक हैश करें)
- संवेदनशील फ्लोज़ के लिए "डू नॉट कैश" फ्लैग
अच्छी तरह से की गई कैशिंग स्थिरता बढ़ाती है और उपयोगकर्ता के विश्वास को बनाए रखती है।
सुरक्षा और भरोसा: UX को तोड़े बिना जोखिम घटाएँ
अपने ब्रांड पर लॉन्च करें
जब आपका ऐप यूज़र्स के लिए तैयार हो, तो उसे अपने डोमेन पर होस्ट करें।
सुरक्षा अलग से कोई अनुपालन परत नहीं है जिसे आप अंत में जोड़ दें। AI-प्रथम उत्पादों में, मॉडल शब्दावली, निर्णय और कार्रवाई प्रभावित कर सकता है—इसलिए सुरक्षा आपके उत्पाद कॉन्ट्रैक्ट का हिस्सा होनी चाहिए: असिस्टेंट क्या कर सकता है, क्या मना है, और कब मदद माँगनी चाहिए।
डिज़ाइन के लिए प्रमुख सुरक्षा चिंताएँ
उन जोखिमों का नाम लें जिनका आपका ऐप वास्तविक रूप से सामना कर सकता है, और फिर हर एक के लिए एक कंट्रोल मैप करें:
- संवेदनशील डेटा: व्यक्तिगत पहचान, क्रेडेंशियल्स, निजी दस्तावेज़, और जो भी रेगुलेटेड हो
- हानिकारक निर्देश: आत्म‑हंसा, हिंसा, गैरकानूनी गतिविधि, या असुरक्षित मेडिकल/फाइनेंशियल कार्रवाइयों को सक्षम करने वाले निर्देश
- पूर्वाग्रह और अन्यायपूर्ण परिणाम: ग्रुप्स के बीच सेवा की गुणवत्ता या सिफारिशों में असमानता
अलाउड/ब्लॉक्ड टॉपिक्स + एस्केलेशन पाथ
एक स्पष्ट नीति लिखें जो उत्पाद लागू कर सके। इसे ठोस रखें: श्रेणियाँ, उदाहरण, और अपेक्षित जवाब।
तीन‑स्तरीय उपयोग करें:
- अनुमत: सामान्य रूप से उत्तर दें।
- सीमित: प्रतिबंधों के साथ उत्तर दें (उदा., सामान्य जानकारी ही, कदम‑दर‑कदम नहीं)।
- ब्लॉक्ड: अस्वीकार करें और एस्केलेशन पाथ पर रूट करें (सपोर्ट, संसाधन, या मानव एजेंट)।
एस्केलेशन एक उत्पाद फ्लो होना चाहिए, सिर्फ़ अस्वीकार संदेश नहीं। "किसी व्यक्ति से बात करें" विकल्प दें, और हैंडऑफ में उपयोगकर्ता द्वारा पहले साझा किया गया संदर्भ शामिल करें (अनुमति के साथ)।
उच्च‑प्रभाव क्रियाओं के लिए मानव समीक्षा
यदि मॉडल वास्तविक परिणाम ट्रिगर कर सकता है—भुगतान, रिफंड, खाता परिवर्तन, रद्दीकरण, डेटा मिटाना—तो एक चेकपॉइंट जोड़ें।
अच्छे पैटर्न: पुष्टि स्क्रीन, "ड्राफ्ट फिर अनुमोदन", सीमाएँ (राशि कैप), और एज‑केस के लिए मानव समीक्षा कतार।
खुलासे, सहमति, और परीक्षण योग्य नीतियाँ
उपयोगकर्ताओं को बताएं जब वे AI के साथ बातचीत कर रहे हैं, कौन‑सा डेटा इस्तेमाल हो रहा है, और क्या स्टोर किया जा रहा है। चर्चित संवाद या सिस्टम‑इम्प्रूवमेंट के लिए डेटा उपयोग पर सहमति माँगें।
आंतरिक सुरक्षा नीतियों को कोड की तरह ट्रीट करें: संस्करण करें, कारण दस्तावेज़ करें, और परीक्षण जोड़ें (उदाहरण प्रॉम्प्ट + अपेक्षित आउटपुट) ताकि सुरक्षा हर प्रॉम्प्ट या मॉडल अपडेट के साथ regress न करे।
मूल्यांकन: किसी अन्य महत्वपूर्ण कंपोनेंट की तरह मॉडल का परीक्षण करें
यदि एक LLM आपके उत्पाद को बदल सकता है, तो आपको यह साबित करने का एक दुहराने योग्य तरीका चाहिए कि यह अभी भी काम कर रहा है—उपयोगकर्ताओं से पहले।
प्रॉम्प्ट्स, मॉडल वर्शन, टूल स्कीमा, और रिट्रीवल सेटिंग्स को रिलीज‑योग्य आर्टिफैक्ट मानें जिनके लिए परीक्षण जरूरी है।
वास्तविकता से मूल्यांकन सेट बनाएं
वास्तविक उपयोगकर्ता इरादों को संग्रहित करें: सपोर्ट टिकट्स, सर्च क्वेरीज, चैट लॉग्स (सहमति के साथ), और इन्हें टेस्ट केस में बदल दें जिनमें शामिल हों:
- सामान्य हैप्पी‑पाथ अनुरोध
- अस्पष्ट प्रॉम्प्ट जिनके लिए स्पष्ट प्रश्न चाहिए
- एज‑केस (गायब डाटा, विरोधाभासी प्रतिबंध, असामान्य फ़ॉर्मैट)
- नीति‑संवेदनशील परिदृश्य (व्यक्तिगत डेटा, निषिद्ध कंटेंट)
प्रत्येक केस में अपेक्षित व्यवहार शामिल करें: उत्तर, लिया गया निर्णय (उदा., "टूल A को कॉल करें"), और कोई जरूरी संरचना (JSON फ़ील्ड, उद्धरण शामिल इत्यादि)।
उत्पाद जोखिम के अनुरूप मीट्रिक्स चुनें
एक स्कोर गुणवत्ता को पकड़ने के लिए पर्याप्त नहीं होगा। कुछ मीट्रिक्स चुनें जो उपयोगकर्ता परिणामों से संबंधित हों:
- सटीकता / टास्क सफलता: क्या उपयोगकर्ता का लक्ष्य पूरा हुआ?
- ग्राउंडेडनेस: क्या दावे प्रदान किए गए संदर्भ/स्रोत से समर्थित हैं?
- फॉर्मैट वैधता: क्या आउटपुट कॉन्ट्रैक्ट (JSON, टेबल, बुलेट) से मेल खाता?
- रिफ्यूज़ल रेट: क्या उसने जहाँ अस्वीकार करना चाहिए वहाँ अस्वीकार किया—और जहाँ नहीं करना चाहिए वहाँ नहीं किया?
कुशलता और लेटेंसी को भी ट्रैक करें; एक “बेहतर” मॉडल जो प्रतिक्रिया समय दो गुना कर दे वह कन्वर्ज़न को नुकसान पहुँचा सकता है।
हर परिवर्तन के लिए ऑफ़लाइन इवैल्स चलाएं
रिलीज़ से पहले और हर प्रॉम्प्ट, मॉडल, टूल, या रिट्रीवल परिवर्तन के बाद ऑफ़लाइन इवैल्यूएशन चलाएँ। परिणामों को वर्शन करें ताकि आप रन की तुलना कर सकें और जल्दी पता लगा सकें कि क्या टूटा।
गार्ड्रेल्स के साथ ऑनलाइन टेस्ट जोड़ें
वास्तविक परिणामों (कम्पलीशन रेट, एडिट्स, उपयोगकर्ता रेटिंग) को मापने के लिए A/B टेस्ट का उपयोग करें, पर सुरक्षा प्रतिबंध जोड़ें: स्टॉप कंडिशंस परिभाषित करें (जैसे Invalid आउटपुट, रिफ्यूज़ल spike, या टूल त्रुटियाँ) और जब थ्रेसहोल्ड पार हो तो ऑटोमैटिक रोलबैक करें।
प्रोडक्शन में मॉनिटरिंग: ड्रिफ्ट, फेल्यर्स, और फ़ीडबैक
पूरा ऐप स्टैक रिलीज़ करें
एक ही बातचीत से React वेब ऐप और Go व PostgreSQL बैकएंड बनाएं।
एक AI-प्रथम फीचर शिप करना खत्म नहीं है। असली उपयोगकर्ता आने पर मॉडल नए वाक्यांश, एज‑केस, और बदलते डेटा का सामना करेगा। मॉनिटरिंग इसे "स्टेजिंग में काम किया" से "माह भर बाद भी काम करता रहे" में बदल देती है।
जिन चीज़ों को लॉग करें (बिना सीक्रेट्स इकट्ठा किए)
फेलियर को पुनरुत्पादित करने के लिए पर्याप्त संदर्भ कैप्चर करें: उपयोगकर्ता इरादा, प्रॉम्प्ट वर्शन, टूल कॉल्स, और मॉडल का अंतिम आउटपुट।
इनपुट/आउटपुट को प्राइवेसी‑सेफ रेडैक्शन के साथ लॉग करें। लॉग्स को संवेदनशील डेटा जैसा ट्रीट करें: ईमेल, फोन नंबर, टोकन और फ्री‑फॉर्म टेक्स्ट जो व्यक्तिगत विवरण रख सकता है, हटाएँ। एक "डिबग मोड" रखें जिसे आप अस्थायी रूप से सक्रिय कर सकें बजाय डिफ़ॉल्ट रूप से अधिकतम लॉगिंग के।
सही संकेतों पर नज़र रखें
एरर रेट्स, टूल फेल्यर्स, स्कीमा उल्लंघन, और ड्रिफ्ट पर निगरानी रखें। ठोस तौर पर ट्रैक करें:
- टूल‑कॉल सक्सेस रेट और टाइमआउट (क्या मॉडल ने सही टूल चुना और क्या वह निष्पादित हुआ?)
- आउटपुट फॉर्मैट/स्कीमा अनुपालन (क्या वेलिडेटर्स ने अस्वीकृत किया?)
- फॉलबैक उपयोग (कितनी बार आपको सुरक्षित/सरल पाथ पर जाना पड़ा)
- कंटेंट‑सेफ़्टी ब्लॉक्स (कितनी बार अस्वीकार या सैनिटाइज़ किया गया)
ड्रिफ्ट के लिए, मौजूदा ट्रैफ़िक की तुलना बेसलाइन से करें: विषय‑मिश्रण, भाषा, औसत प्रॉम्प्ट लंबाई, और "अज्ञात" इरादों में परिवर्तन। ड्रिफ्ट हमेशा खराब नहीं होता—पर यह पुनर्मूल्यांकन का संकेत है।
अलर्ट, रनबुक, और इंसिडेंट रिस्पॉन्स
अलर्ट थ्रेसहोल्ड और ऑन‑कॉल रनबुक सेट करें। अलर्ट्स को क्रियाओं से मैप करें: प्रॉम्प्ट वर्शन रोलबैक करें, किसी बेकर टूल को डिसेबल करें, वेलिडेशन कड़ी करें, या फॉलबैक पर स्विच करें।
अनुपयुक्त या गलत व्यवहार के लिए इंसिडेंट रिस्पॉन्स योजना बनाएं। परिभाषित करें कि कौन‑कौन सुरक्षा स्वीच पलट सकता है, उपयोगकर्ताओं को कैसे नोटिफ़ाई करेंगे, और घटना से क्या सीखा गया इसे कैसे डॉक्यूमेंट करेंगे।
उपयोगकर्ता फ़ीडबैक से लूप बंद करें
फ़ीडबैक लूप्स इस्तेमाल करें: थम्ब्स अप/डाउन, कारण कोड, बग रिपोर्ट्स। हल्के "क्यों?" विकल्प माँगे (गलत तथ्य, निर्देश का पालन नहीं, असुरक्षित, बहुत धीमा) ताकि आप मुद्दों को सही फिक्स (प्रॉम्प्ट, टूल, डेटा, या पॉलिसी) पर रूट कर सकें।
मॉडल‑ड्रिवन लॉजिक के लिए UX: पारदर्शिता और नियंत्रण
जब मॉडल‑ड्रिवन फीचर काम करता है तो जादुई लगता है—और विफल होने पर भंगुर। UX को अनिश्चितता को मानकर डिज़ाइन करना चाहिए और फिर भी उपयोगकर्ताओं को कार्य पूरा करने में मदद करनी चाहिए।
"क्यों" दिखाएँ बिना उपयोगकर्ता ओवरव्हेल्म किए
जब उपयोगकर्ता देख सके कि आउटपुट कहाँ से आया है तो वे AI आउटपुट पर अधिक भरोसा करते हैं—क्योंकि इससे उन्हें निर्णय लेने में मदद मिलती है कि कार्रवाई करनी चाहिए या नहीं।
प्रोग्रेसिव डिस्क्लोज़र का उपयोग करें:
- शुरुआत परिणाम के साथ करें (उत्तर, ड्राफ्ट, सिफारिश)
- एक "क्यों?" या "शो वर्क" टॉगल दें जो प्रमुख इनपुट दिखाए: उपयोगकर्ता अनुरोध, चलाए गए टूल, और परामर्श किए गए स्रोत/रिकॉर्ड
- यदि आप रिट्रीवल करते हैं, तो उद्धरण दिखाएँ जो सीधे स्निपेट पर जंप करें (उदा., “आधारित: नीति §3.2”)। इसे स्किमेबल रखें।
यदि आपके पास गहरा एक्सप्लेनेर है तो उसे आंतरिक लिंक से जोड़ें (उदा., /blog/rag-grounding) बजाय UI को भारी करने के।
अनिश्चितता के लिए डिज़ाइन करें (बिना डराने वाले चेतावनियों के)
मॉडल कैलकुलेटर नहीं है। इंटरफ़ेस को आत्म‑विश्वास संप्रेषित करना चाहिए और सत्यापन को आमंत्रित करना चाहिए।
प्रायोगिक पैटर्न:
- सादे शब्दों में आत्म‑विश्वास संकेत (“संभवतः सही”, “समीक्षा की जरूरत”) जटिल प्रतिशतों के बजाय
- विकल्प प्रदान करें, न कि एकल उत्तर: “यहाँ 3 तरीके हैं जवाब देने के।” इससे गलत पहले उत्तर की लागत कम होती है
- उच्च‑प्रभाव क्रियाओं के लिए पुष्टि (ईमेल भेजना, डेटा मिटाना, भुगतान करना)। एक स्पष्ट प्रश्न पूछें: “क्या आप यह संदेश 12 प्राप्तकर्ताओं को भेजना चाहते हैं?”
सुधार और रिकवरी को आसान बनाएं
उपयोगकर्ता बिना फिर से शुरू किए आउटपुट को निर्देशित कर सकें:
- इनलाइन एडिटिंग और "Apply changes" ताकि मॉडल उपयोगकर्ता के संशोधनों से आगे बढ़ सके
- "Regenerate" पर कंट्रोल (टोन, लंबाई, प्रतिबंध) ताकि यह एक अंधा रिरोल न हो
- "Undo" और दृश्य इतिहास ताकि गलतियाँ उलटी जा सकें
एक एस्केप हैच दें
जब मॉडल फेल कर दे—या उपयोगकर्ता अनिश्चित हो—एक निर्धारक फ्लो या मानव मदद का विकल्प दें।
उदाहरण: “मैन्युअल फॉर्म पर स्विच करें”, “टेम्पलेट इस्तेमाल करें”, या “सपोर्ट से संपर्क करें” (उदा., /support)। यह शेमफुल फॉलबैक नहीं है; यह टास्क पूरा करने और भरोसा बनाए रखने का तरीका है।
प्रोटोटाइप से प्रोडक्शन तक (बिना सब कुछ फिर से बनाने के)
अधिकतर टीमें इसलिए फेल नहीं होतीं कि LLM सक्षम नहीं हैं; वे इसलिए फेल होती हैं क्योंकि प्रोटोटाइप से एक विश्वसनीय, टेस्टेबल, मॉनिटर करने योग्य फीचर तक का रास्ता अपेक्षा से लंबा होता है।
एक व्यावहारिक तरीका है कि आप जल्दी "प्रोडक्ट स्केलेटन" को स्टैंडर्डाइज करें: स्टेट मशीनें, टूल स्कीमा, वेलिडेशन, ट्रेसेज़, और डिप्लॉय/रोलबैक स्टोरी। प्लेटफ़ॉर्म जैसे Koder.ai यहां मददगार हो सकते हैं जब आप तेजी से AI‑प्रथम वर्कफ़्लो स्पिन‑अप करना चाहते हैं—UI, बैकएंड, और DB एक साथ बनाना—और फिर स्नैपशॉट/रोलबैक के साथ सुरक्षित रूप से इटरेट करना। जब आप ऑपरेशनलाइज़ करने के लिए तैयार हों, तो आप सोर्स‑कोड एक्सपोर्ट कर सकते हैं और अपनी पसंदीदा CI/CD और ऑब्ज़र्वबिलिटी स्टैक के साथ आगे बढ़ सकते हैं।