15 जून 2025·8 मिनट
AI से बैकएंड स्कीमा, API और डेटा मॉडल डिजाइन कराना
देखिए कि एआई-जनित स्कीमा और API कैसे डिलीवरी तेज़ करते हैं, कहाँ वे असफल होते हैं, और बैकएंड डिज़ाइन की समीक्षा, परीक्षण और शासन के लिए एक व्यावहारिक वर्कफ़्लो।
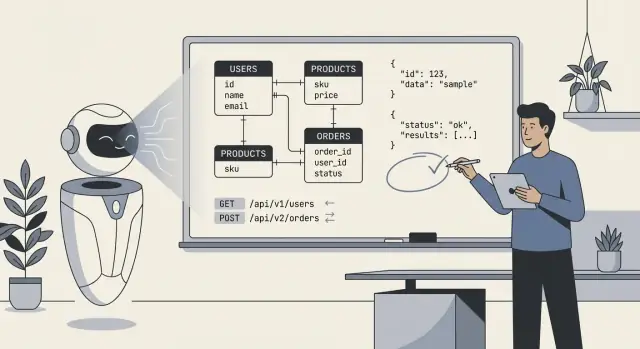
देखिए कि एआई-जनित स्कीमा और API कैसे डिलीवरी तेज़ करते हैं, कहाँ वे असफल होते हैं, और बैकएंड डिज़ाइन की समीक्षा, परीक्षण और शासन के लिए एक व्यावहारिक वर्कफ़्लो।
जब लोग कहते हैं “AI ने हमारा बैकएंड डिज़ाइन किया,” तो वे आमतौर पर इस बात का संकेत देते हैं कि मॉडल ने कोर तकनीकी ब्लूप्रिंट का पहला ड्राफ्ट बनाया: डेटाबेस टेबल्स (या कलेक्शन्स), उन हिस्सों के बीच संबंध, और वे API जो डेटा पढ़ते/लिखते हैं। व्यावहारिक रूप में, यह कम "AI ने सब कुछ बनाया" और ज्यादा "AI ने एक स्ट्रक्चर प्रस्तावित किया जिसे हम लागू और परिशोधित कर सकते हैं" होता है।
कम से कम, AI जनरेट कर सकता है:
users, orders, subscriptions, साथ ही फ़ील्ड और बेसिक प्रकार।AI "टाइपिकल" पैटर्न्स का अनुमान लगा सकता है, पर जब रिक्वायरमेंट्स अस्पष्ट या डोमेन-विशेष हों तो वह विश्वसनीय रूप से सही मॉडल चुन नहीं पाएगा। उसे पता नहीं होगा आपके असली नीतियाँ जैसे:
cancelled बनाम refunded बनाम voided)।AI आउटपुट को एक तेज़, संरचित प्रारंभिक बिंदु के रूप में देखें—विकल्पों का अन्वेषण करने और चूकें पकड़ने के लिए उपयोगी—पर इसे बिना समीक्षा के शिप करने योग्य स्पेक न मानें। आपका काम है स्पष्ट नियम और एज केस देना, और फिर AI के आउटपुट की वैसी ही समीक्षा करना जैसे आप एक जूनियर इंजीनियर के पहले ड्राफ्ट की समीक्षा करते हैं: सहायक, कभी-कभी प्रभावशाली, पर कभी-कभी सूक्ष्म तरीकों से गलत।
AI शीघ्रता से स्कीमा या API ड्राफ्ट कर सकता है, पर वह उन खोयी हुई सूचनाओं का आविष्कार नहीं कर सकता जो बैकएंड को आपके प्रोडक्ट के अनुकूल बनाती हैं। सर्वोत्तम परिणाम तब मिलते हैं जब आप AI को एक तेज़ जूनियर डिज़ाइनर की तरह ट्रीट करें: आप स्पष्ट बंधन दें, और वह विकल्प प्रस्तावित करे।
टेबल्स, एंडपॉइंट्स या मॉडल माँगने से पहले आवश्यक बातें लिखें:
जब रिक्वायरमेंट्स अस्पष्ट होती हैं, AI डिफ़ॉल्ट्स "अनुमान" कर लेता है: हर जगह ऑप्शनल फ़ील्ड्स, सामान्य स्टेटस कॉलम, अस्पष्ट ओनरशिप, और असंगत नामकरण। इससे ऐसे स्कीमा बनते हैं जो समझने में ठीक दिखते हैं पर वास्तविक उपयोग में टूट जाते हैं—विशेषकर पर्मिशन्स, रिपोर्टिंग, और एज-केसेस (रिफंड्स, कैंसलेशन, आंशिक शिपमेंट्स, मल्टी-स्टेप अप्रूवल) के इर्द‑गिर्द। बाद में आप माइग्रेशन, वर्कअराउंड और उलझी APIs के साथ भुगतान करेंगे।
इसे अपने प्रॉम्प्ट में चिपकाएँ:
Product summary (2–3 sentences):
Entities (name → definition):
-
Workflows (steps + states):
-
Roles & permissions:
- Role:
- Can:
- Cannot:
Reporting questions we must answer:
-
Integrations (system → data we store):
-
Constraints:
- Compliance/retention:
- Expected scale:
- Latency/availability:
Non-goals (what we won’t support yet):
-
AI सबसे अच्छा तब है जब आप उसे एक तेज़ ड्राफ्ट मशीन की तरह इस्तेमाल करते हैं: यह मिनटों में एक तार्किक फर्स्ट-पास डेटा मॉडल और मिलते-जुलते एंडपॉइंट्स स्केच कर सकता है। यह स्पीड आपके काम करने के तरीके को बदल देती है—न कि क्योंकि आउटपुट जादुई रूप से "सही" है, बल्कि क्योंकि आप कुछ ठोस पर तुरंत इटरेट कर सकते हैं।
सबसे बड़ा लाभ कोल्ड स्टार्ट को खत्म करना है। AI को एंटिटीज़, प्रमुख यूज़र फ्लोज़, और प्रतिबंधों का छोटा विवरण दें, और वह टेबल्स/कलेक्शन्स, रिलेशनशिप्स, और बेसलाइन API सरफेस का प्रस्ताव दे सकता है। यह तब विशेष रूप से मूल्यवान है जब आपको जल्दी डेमो चाहिए या आप अस्थिर रिक्वायरमेंट्स का अन्वेषण कर रहे हैं।
स्पीड का लाभ विशेष रूप से उन मामलों में होता है:
इंसान थकते हैं और ड्रिफ्ट कर जाते हैं। AI ऐसा नहीं करता—इसलिए यह सारा बैकएंड समान कन्वेंशंस दोहराने में अच्छा है:
createdAt, updatedAt, customerId)/resources, /resources/:id) और पेलोडयह सुसंगति आपके बैकएंड को डाक्यूमेंट, टेस्ट और हैंड-ऑफ करने में आसान बनाती है।
AI पूर्णता में भी अच्छा है। यदि आप एक पूरा CRUD सेट मांगते हैं साथ ही सामान्य ऑपरेशंस (सर्च, लिस्ट, बल्क अपडेट), तो यह अक्सर एक अधिक व्यापक प्रारंभिक सरफेस जनरेट करेगा बनिस्बत किसी जल्दबाज़ मानव ड्राफ्ट के।
एक सामान्य त्वरित लाभ है स्टैंडर्डाइज्ड एरर्स: सभी एंडपॉइंट्स में एक समान एरर एन्वेलप (code, message, details)। भले ही आप बाद में इसे परिष्कृत करें, शुरुआत में एक ही शेप होना मिश्रित एड‑हॉक प्रतिक्रियाओं को रोकता है।
कुंजी मानसिकता: AI पहले 80% को जल्दी पैदा करे, फिर आप अपना समय उस 20% पर लगाएँ जिसे जजमेंट चाहिए—बिजनेस नियम, एज‑केसेस, और मॉडल के पीछे का "क्यों"।
AI-जनित स्कीमा अक्सर पहली नज़र में "क्लीन" दिखते हैं: टिडी टेबल्स, समझदार नाम, और रिलेशनशिप्स जो हैप्पी पाथ से मेल खाते हैं। समस्याएँ आमतौर पर तब सामने आती हैं जब असली डेटा, असली यूज़र्स, और असली वर्कफ़्लो सिस्टम को हिट करते हैं।
AI दोनों चरमों के बीच झूल सकता है:
एक त्वरित स्मेल‑टेस्ट: यदि आपकी सबसे आम पेजेज़ को 6+ joins चाहिए, तो आप ओवर‑नॉर्मलाइज़्ड हो सकते हैं; यदि अपडेट के लिए एक ही मान कई रो में बदलना पड़ता है, तो अंडर‑नॉर्मलाइज़्ड कर रहे हैं।
AI अक्सर "उबाऊ" रिक्वायरमेंट्स को छोड़ देता है जो असल बैकएंड डिज़ाइन चलाते हैं:
deleted_at जोड़ना पर यूनिकनेस नियम या क्वेरी पैटर्न को अपडेट न करना।created_by/updated_by, परिवर्तन इतिहास, या इम्म्यूटेबल इवेंट लॉग्स का अभाव।AI अनुमान लगा सकता है:
ये त्रुटियाँ आमतौर पर अजीब माइग्रेशन्स और एप्लिकेशन-साइड वर्कअराउंड्स के रूप में उभरती हैं।
ज्यादातर जनरेट किए गए स्कीमा यह प्रतिबिंब नहीं करते कि आप कैसे क्वेरी करेंगे:
यदि मॉडल आपके ऐप की टॉप 5 क्वेरीज़ बयान नहीं कर सकता, तो वह उन क्वेरीज़ के लिए स्कीमा भरोसेमंद तरीके से डिजाइन नहीं कर सकता।
AI अक्सर एक ऐसा API बनाकर देता है जो "स्टैंडर्ड" दिखता है। यह लोकप्रिय फ्रेमवर्क और पब्लिक APIs के परिचित पैटर्न्स की नकल करेगा, जो वक़्त बचाने में मददगार हो सकता है। जोखिम यह है कि यह उन चीज़ों के लिए अनुकूलन कर सकता है जो संभाव्य लगते हैं बजाय उन चीज़ों के जो आपके प्रोडक्ट, आपके डेटा मॉडल और आपके भविष्य के बदलावों के लिए सही हैं।
रिसोर्स मॉडलिंग की बेसिक्स। स्पष्ट डोमेन देने पर AI समझदार संज्ञाएँ और URL स्ट्रक्चर चुनता है (उदा., /customers, /orders/{id}, /orders/{id}/items)। यह एंडपॉइंट्स में सुसंगत नामकरण दोहराने में भी अच्छा है।
कॉमन एंडपॉइंट स्कैफ़ोल्डिंग। AI अक्सर आवश्यक चीजें शामिल करता है: लिस्ट बनाम डिटेल एंडपॉइंट्स, create/update/delete ऑपरेशंस, और प्रत्याशित रिक्वेस्ट/रेस्पॉन्स शेप्स।
बेसलाइन कन्वेंशंस। यदि आप स्पष्ट रूप से कहें, तो यह पेजिनेशन, फ़िल्टरिंग, और सॉर्टिंग को स्टैण्डर्डाइज कर सकता है। उदाहरण: ?limit=50&cursor=... (कर्सर पेजिनेशन) या ?page=2&pageSize=25 (पेज-आधारित), साथ में ?sort=-createdAt और फ़िल्टर्स जैसे ?status=active।
लीकी एब्स्ट्रैक्शंस। क्लासिक विफलता आंतरिक टेबल्स को सीधे "रिसोर्स" के रूप में एक्सपोज़ करना है, खासकर जब स्कीमा में जॉइन टेबल्स, डिनॉर्मलाइज़्ड फ़ील्ड्स, या ऑडिट कॉलम होते हैं। इससे /user_role_assignments जैसे एंडपॉइंट्स बन सकते हैं जो इम्प्लीमेंटेशन‑डिटेल दिखाते बजाय यूज़र‑फेसिंग कॉन्सेप्ट के। यह API को उपयोग करने और बदलने दोनों को कठिन बना देता है।
असंगत एरर हैंडलिंग। AI कभी-कभी स्टाइल मिला‑जुला कर देता है: कभी 200 के साथ एरर बॉडी, कभी उपयुक्त 4xx/5xx। आपको एक स्पष्ट कॉन्ट्रैक्ट चाहिए:
400, 401, 403, 404, 409, 422){ "error": { "code": "...", "message": "...", "details": [...] } })वर्ज़निंग को बाद का विचार बनाना। कई AI-जनित डिज़ाइन्स वर्ज़निंग स्ट्रैटेजी को तब तक स्किप कर देते हैं जब तक कि दर्दनाक अनुभव न हो। दिन एक तय करें क्या आप path वर्ज़निंग (/v1/...) या हेडर-बेस्ड वर्ज़निंग उपयोग करेंगे, और क्या बदलाव ब्रेकिंग मानेंगे। नियम होने से आकस्मिक ब्रेकेज़ रोके जा सकते हैं।
AI को गति और सुसंगति के लिए उपयोग करें, पर API डिज़ाइन को एक प्रोडक्ट इंटरफ़ेस की तरह ट्रीट करें। यदि कोई एंडपॉइंट आपकी डेटाबेस को सीधे प्रतिबिंबित करता है बजाय आपके यूज़र के मानसिक मॉडल के, तो यह संकेत है कि AI ने आसान जनरेशन को प्राथमिकता दी—लंबे समय की उपयोगिता के लिए यह उपयुक्त नहीं है।
AI को एक तेज़ जूनियर डिज़ाइनर की तरह ट्रीट करें: ड्राफ्ट बनाने में महान, अंतिम सिस्टम के लिए ज़िम्मेदार नहीं। लक्ष्य है इसकी स्पीड का उपयोग करना जबकि आपकी आर्किटेक्चर इरादा‑पूर्ण, समीक्षनीय और टेस्ट‑ड्रिवन बनी रहे।
यदि आप Koder.ai जैसे vibe-coding टूल का उपयोग कर रहे हैं, तो जिम्मेदारियाँ अलग रखना और भी महत्वपूर्ण हो जाता है: प्लेटफ़ॉर्म तेज़ी से बैकएंड ड्राफ्ट और इम्प्लिमेंट कर सकता है (उदा., Go सर्विसेज़ के साथ PostgreSQL), पर आपको फिर भी इनवेरिएंट्स, ऑथोराइज़ेशन बॉउंड्रीज़, और माइग्रेशन नियम परिभाषित करने होंगे जिनके साथ आप रहना चाहते हैं।
एक तंग प्रॉम्प्ट के साथ शुरू करें जो डोमेन, कंस्ट्रेंट्स, और "सफलता कैसी दिखेगी" बताए। पहले कॉन्सेप्चुअल मॉडल (एंटिटीज़, रिलेशनशिप्स, इनवेरिएंट्स) मांगें, न कि टेबल्स।
फिर निश्चित लूप में इटरेट करें:
यह लूप इसलिए काम करता है क्योंकि यह "AI सुझावों" को उन आर्टिफैक्ट्स में बदल देता है जिन्हें साबित या अस्वीकार किया जा सके।
तीन लेयर्स अलग रखें:
AI से इनको अलग‑अलग सेक्शन में आउटपुट करने के लिए कहें। जब कुछ बदलता है (उदा., नया स्टेटस या नियम), पहले कॉन्सेप्चुअल लेयर अपडेट करें, फिर स्कीमा और API से मेल कराएँ। इससे अनजाने कपलिंग घटती है और रिफैक्टर्स कम दर्दनाक होते हैं।
हर इटरेशन एक ट्रेल छोड़े। छोटे ADR-शैली के सार (एक पेज या उससे कम) का उपयोग करें जिसमें शामिल हो:
deleted_at”)।जब आप AI को फ़ीडबैक चिपकाएँ, तो संबंधित निर्णय नोट्स शब्दशः शामिल करें। इससे मॉडल पिछली पसंद भूलने से बचेगा और आपकी टीम महीनों बाद बैकएंड को समझ सकेगी।
AI को मोड़ना सबसे आसान तब है जब आप प्रॉम्प्ट को एक स्पेक‑लेखन अभ्यास की तरह ट्रीट करें: डोमेन को परिभाषित करें, कंस्ट्रेंट्स बताएं, और ठोस आउटपुट (DDL, एंडपॉइंट टेबल्स, उदाहरण) की माँग करें। लक्ष्य "क्रिएटिव होने" का नहीं—"सटीक होने" का होना चाहिए।
डेटा मॉडल और उन नियमों की माँग करें जो उसे संगत रखते हैं।
अगर आपके पास कन्वेंशंस हैं तो बताएं: नामकरण शैली, ID प्रकार (UUID vs bigint), nullable नीति, और इंडेक्सिंग अपेक्षाएँ।
एकल रूट्स की सूची के बजाय API टेबल माँगे जिसमें स्पष्ट कॉन्ट्रैक्ट हो।
बिजनेस व्यवहार जोड़ें: पेजिनेशन स्टाइल, सॉर्टिंग फ़ील्ड्स, और फ़िल्टरिंग कैसे काम करती है।
मॉडल को रिलीज़‑सोच में रखें।
billing_address to Customer. Provide a safe migration plan: forward migration SQL, backfill steps, feature-flag rollout, and a rollback strategy. API must remain compatible for 30 days; old clients may omit the field.”अस्पष्ट प्रॉम्प्ट्स अस्पष्ट सिस्टम बनाएँगे।
बेहतर आउटपुट के लिए प्रॉम्प्ट कसा करें: नियम, एज‑केसेस, और डिलिवरेबल का फॉर्मैट बताइए।
AI एक अच्छा ड्राफ्ट बना सकता है, पर उसे सुरक्षित रूप से शिप करने के लिए इंसानी पास अभी भी ज़रूरी है। इस चेकलिस्ट को एक "रिलीज गेट" समझें: यदि आप किसी आइटम का आत्मविश्वास से उत्तर नहीं दे सकते, तो रुकिए और उसे प्रोडक्शन डेटा बनने से पहले ठीक कीजिए।
(tenant_id, slug))।_id सफ़िक्स, timestamps) और समान रूप से लागू करें।सिस्टम के नियम लिखित में कन्फर्म करें:
मर्ज करने से पहले एक त्वरित “हैप्पी पाथ + वर्स्ट पाथ” रिव्यू चलाइए: एक सामान्य रिक्वेस्ट, एक इनवैलिड रिक्वेस्ट, एक अनऑथराइज़्ड रिक्वेस्ट, एक उच्च‑वॉल्यूम परिदृश्य। यदि API का व्यवहार आपको अचरज में डालता है, तो वह आपके यूज़र्स को भी अचरज में डाल देगा।
AI एक संभाव्य स्कीमा और API सरफेस शीघ्रता से जनरेट कर सकता है, पर वह यह सिद्ध नहीं कर सकता कि बैकएंड वास्तविक ट्रैफ़िक, वास्तविक डेटा, और भविष्य के बदलावों के तहत सही तरीके से व्यवहार करेगा। AI आउटपुट को ड्राफ्ट मानें और टेस्ट्स के साथ उसे एंकर करें जो व्यवहार को लॉक करें।
हैप्पी पाथ के अलावा रिक्वेस्ट्स, रिस्पॉन्स, और एरर सिमैंटिक्स को वेलिडेट करने वाले कॉन्ट्रैक्ट टेस्ट्स से शुरू करें। छोटे सुइट बनाएं जो सर्विस के असली इंस्टेंस (या कंटेनर) के खिलाफ चलें।
फोकस रखें:
400 बनाम 404 बनाम 409 conflicts)यदि आप OpenAPI स्पेसिफिकेशन प्रकाशित करते हैं, तो उससे टेस्ट जेनरेट करें—पर स्पेस में एक्सप्रेस न हो सकने वाले पेचीदा हिस्सों के लिए हाथ से लिखे हुए केस भी जोड़ें (ऑथराइज़ेशन नियम, बिजनेस कॉन्स्ट्रेंट्स)।
AI-जनित स्कीमा अक्सर ऑपरेशनल विवरण छोड़ देते हैं: सेफ डिफॉल्ट्स, बैकफिल्स, और रिवर्सिबिलिटी। ऐसे माइग्रेशन टेस्ट जोड़ें जो:
प्रोडक्शन के लिए स्क्रिप्टेड रोलबैक प्लान रखें: यदि माइग्रेशन धीमा है, तालिकाओं को लॉक कर देता है, या कम्पैटिबिलिटी तोड़ता है तो क्या करना है।
सामान्य एंडपॉइंट्स का बेंचमार्क न लें। प्रतिनिधि क्वेरी पैटर्न (टॉप लिस्ट व्यूज़, सर्च, जॉइन्स, एग्रीगेशन) पकड़ें और उन्हीं पर लोड टेस्ट चलाएँ।
नापें:
यहाँ AI डिज़ाइन्स आमतौर पर फेल होते हैं: "रिजनबल" टेबल्स जो लोड पर महँगे जॉइन्स पैदा करती हैं।
स्वचालित चेक्स जोड़ें जो:
यह भी बेसिक सिक्योरिटी टेस्ट AI की सबसे costly गलतियों—ऐसे एंडपॉइंट्स जो काम करते हैं पर बहुत कुछ एक्सपोज़ कर देते हैं—को रोकते हैं।
AI एक अच्छा "वर्ज़न 0" स्कीमा ड्राफ्ट कर सकता है, पर आपका बैकएंड वर्ज़न 50 से गुजरता है। वह फर्क जो बैकएंड को लंबा चलने लायक बनाता है बनाम टूट जाने वाला सिस्टम, यह है कि आप कैसे उसे विकसित करते हैं: माइग्रेशन्स, नियंत्रित रिफैक्टर्स, और इरादे की स्पष्ट डाक्यूमेंटेशन।
हर स्कीमा बदलाव को माइग्रेशन मानें, भले ही AI कहे "बस टेबल बदलो।" स्पष्ट, रिवर्सिबल स्टेप्स का उपयोग करें: पहले नए कॉलम जोड़ें, बैकफिल करें, फिर कॉन्स्ट्रेंट्स सख्त करें। नष्टात्मक परिवर्तनों (rename/drop) से बचें जब तक आप साबित न कर लें कि कुछ उस पर निर्भर नहीं है।
जब आप AI से स्कीमा अपडेट माँगें, तो वर्तमान स्कीमा और आपकी माइग्रेशन नियम (उदा., “कोई कॉलम ड्रॉप नहीं; expand/contract पैटर्न”) शामिल करें। इससे यह कम होगा कि वह ऐसा परिवर्तन प्रस्तावित करे जो सिद्धांत में सही दिखे पर प्रोडक्शन में जोखिम भरा हो।
ब्रेकिंग चेंजिस शायद ही कभी एक ही क्षण हों; वे संक्रमण होते हैं।
AI स्टेप‑बाय‑स्टेप प्लान (SQL स्निपेट्स और रोलआउट ऑर्डर सहित) देने में मदद कर सकता है, पर आप रनटाइम इम्पैक्ट—लॉक्स, लंबी ट्रांज़ैक्शन्स, और क्या बैकफिल resumable है—को वेरिफाई करें।
रिफैक्टर्स का लक्ष्य परिवर्तन को अलगाव में रखना चाहिए। यदि आप नॉर्मलाइज़ करना चाहते हैं, टेबल को स्प्लिट करना है, या इवेंट लॉग पेश करना है, तो कम्पैटिबिलिटी लेयर्स रखें: व्यूज़, ट्रांसलेशन कोड, या "शैडो" टेबल्स। AI से ऐसा रिफैक्टर्स का प्रस्ताव माँगें जो मौजूदा API कॉन्ट्रैक्ट्स को बनाए रखें, और यह सूची दें कि क्वेरीज, इंडेक्सेस, और कॉन्स्ट्रेंट्स में क्या बदलना होगा।
ज़्यादातर लॉन्ग‑टर्म ड्रिफ्ट इसलिए होती है क्योंकि अगला प्रॉम्प्ट मूल इरादे भूल जाता है। एक छोटा "डेटा मॉडल कॉन्ट्रैक्ट" दस्तावेज़ रखें: नामकरण नियम, ID रणनीति, टाइमस्टैम्प सिमेंटिक्स, सॉफ्ट‑डिलीट पॉलिसी, और इनवेरिएंट्स ("order total व्युत्पन्न है, स्टोर नहीं किया जाता")। इसे अपनी इंटरनल docs (उदा., /docs/data-model) में लिंक करें और भविष्य के AI प्रॉम्प्ट्स में दोहराएँ ताकि सिस्टम एक ही सीमाओं के भीतर डिज़ाइन करे।
AI शीघ्रता से टेबल्स और एंडपॉइंट्स ड्राफ्ट कर सकता है, पर वह आपका रिस्क "ओन" नहीं करता। सुरक्षा और प्राइवेसी को प्रॉम्प्ट में पहली कक्षा की आवश्यकता के रूप में जोड़ें, और फिर रिव्यू में सत्यापित करें—विशेषकर संवेदनशील डेटा के आसपास।
किसी भी स्कीमा को स्वीकार करने से पहले फ़ील्ड्स को संवेदनशीलता के अनुसार लेबल करें (public, internal, confidential, regulated)। यह क्लासीफिकेशन तय करेगा क्या एन्क्रिप्ट, मास्क, या मिनिमाइज़ किया जाना चाहिए।
उदाहरण: पासवर्ड कभी स्टोर न करें (सिर्फ सॉल्टेड हैश), टोकन्स छोटा‑जीवन वाले और एट‑रेस्ट एन्क्रिप्टेड हों, और ईमेल/फ़ोन जैसे PII एडमिन व्यूज़ और एक्सपोर्ट्स में मास्किंग की आवश्यकता हो सकती है। यदि कोई फ़ील्ड प्रोडक्ट वैल्यू के लिए जरूरी नहीं है, तो उसे स्टोर न करें—AI अक्सर "अच्छा होगा" वाले अट्रिब्यूट जोड़ देता है जो एक्सपोज़र बढ़ाते हैं।
AI-जनित APIs अक्सर सरल "रोल चेक्स" पर डिफॉल्ट करते हैं। RBAC समझने में आसान है, पर ओनरशिप नियमों ("यूज़र केवल अपनी इनवॉइसेज़ देख सकता है") या संदर्भ नियमों ("सपोर्ट केवल एक्टिव टिकट के दौरान डेटा देख सकता है") में यह टूट जाता है। ABAC इनको बेहतर हैंडल करता है पर इसके लिए स्पष्ट नीतियाँ चाहिए।
आप जिस पैटर्न का उपयोग कर रहे हैं उसे स्पष्ट करें, और सुनिश्चित करें कि हर एंडपॉइंट इसे लगातार लागू करे—विशेषकर लिस्ट/सर्च एंडपॉइंट्स जो सामान्य रिसाव बिंदु हैं।
जनरेटेड कोड अक्सर त्रुटियों के दौरान पूरे रिक्वेस्ट बॉडी, हेडर्स, या DB रोज़ लॉग कर सकता है। इससे पासवर्ड्स, ऑथ टोकन्स और PII लॉग्स/एपीएम टूल्स में लीक हो सकते हैं।
डिफॉल्ट्स सेट करें: स्ट्रक्चर्ड लॉग्स, लॉग करने के लिए अलाउलिस्ट फ़ील्ड्स, सीक्रेट्स (Authorization, cookies, reset tokens) का रेडैक्शन, और वैलिडेशन फेल्यर्स पर कच्चा पेलोड लॉग न करें।
दिन एक से डिलीशन के लिए डिज़ाइन करें: यूज़र-प्रेरित डिलीट्स, अकाउंट क्लोज़र, और "राइट टू बी फ़ॉर्गॉटन" वर्कफ़्लो। डेटा क्लास के अनुसार रिटेंशन विंडोज़ परिभाषित करें (उदा., ऑडिट इवेंट बनाम मार्केटिंग इवेंट्स), और सुनिश्चित करें कि आप साबित कर सकें क्या कब डिलीट किया गया।
यदि आप ऑडिट लॉग्स रखते हैं, तो न्यूनतम पहचानकर्ता स्टोर करें, उन्हें कड़े एक्सेस के साथ सुरक्षित रखें, और दस्तावेज़ बनाएं कि आवश्यकता पड़ने पर डेटा कैसे एक्सपोर्ट या डिलीट किया जाएगा।
AI तब सबसे अच्छा है जब आप उसे एक तेज़ जूनियर आर्किटेक्ट की तरह उपयोग करते हैं: फर्स्ट ड्राफ्ट बनाने में तेज़, डोमेन‑महत्वपूर्ण ट्रेडऑफ़्स में कमजोर। सही सवाल यह नहीं है "क्या AI मेरा बैकएंड डिजाइन कर सकता है?" बल्कि "कौन से हिस्से AI सुरक्षित रूप से ड्राफ्ट कर सकते हैं, और किन हिस्सों के लिए एक्सपर्ट ओनरशिप चाहिए?" है।
AI सच में समय बचा सकता है जब आप बना रहे हों:
यहाँ AI स्पीड, सुसंगति और कवरेज के कारण मूल्यवान है—खासकर जब आप पहले से जानते हैं कि प्रोडक्ट कैसे व्यवहार करना चाहिए और गलतियाँ पहचान सकते हैं।
सावधान रहें (या AI-जनित डिज़ाइन को सिर्फ प्रेरणा मानें) जब आप काम कर रहे हों:
इन क्षेत्रों में डोमेन एक्सपर्टीज़ AI स्पीड से ज़्यादा महत्वपूर्ण हैं। सूक्ष्म रिक्वायरमेंट्स—कानूनी, क्लिनिकल, एकाउंटिंग, ऑपरेशनल—अक्सर प्रॉम्प्ट में नहीं होते, और AI आत्मविश्वास से गैप्स भर देगा।
एक व्यावहारिक नियम: AI को विकल्प प्रस्तावित करने दें, पर डेटा मॉडल इनवेरिएंट्स, ऑथराइज़ेशन बॉउन्ड्रीज़, और माइग्रेशन रणनीति के लिए फाइनल रिव्यू अनिवार्य रखें। अगर आप यह नाम नहीं बता सकते कि कौन स्कीमा और API कॉन्ट्रैक्ट्स के लिए जिम्मेदार है, तो AI‑डिज़ाइन किया बैकएंड शिप न करें।
यदि आप वर्कफ़्लोज़ और गार्डरेल्स का मूल्यांकन कर रहे हैं तो संबंधित निर्देशनों को देखें /blog. यदि आप इन प्रैक्टिसेज़ को अपनी टीम के प्रोसेस में लागू करने में मदद चाहते हैं तो /pricing देखें।
यदि आप चैट के माध्यम से इटरेट कर एक वर्किंग ऐप जनरेट करना, और स्रोत कोड एक्सपोर्ट व रोलबैक‑फ्रेंडली स्नैपशॉट के ज़रिये नियंत्रण बनाए रखना पसंद करते हैं, तो Koder.ai विशेष रूप से उसी शैली के बिल्ड‑एंड‑रिव्यू लूप के लिए डिज़ाइन किया गया है।
यह आमतौर पर मतलब होता है कि मॉडल ने एक प्रारंभिक ड्राफ्ट बनाया:
एक मानव टीम को अभी भी बिजनेस नियम, सुरक्षा सीमाएँ, क्वेरी प्रदर्शन और माइग्रेशन सेफ्टी वेरिफाई करके प्रोडक्शन के लिए तैयार करना होता है।
AI से स्कीमा या API मांगने से पहले निम्न स्पष्ट इनपुट दें जिन्हें AI सुरक्षित रूप से अनुमान नहीं लगा सकता:
जितना स्पष्ट करेंगे, AI उतना कम कमजोर डिफ़ॉल्ट्स से भर देगा।
पहले कॉन्सेप्चुअल मॉडल (बिजनेस कांसेप्ट + इनवेरिएंट्स) बनाइए, फिर उससे क्रमशः बनाइए:
इन लेयर्स को अलग रखने से स्टोरेज बदलने पर API न टूटे और API बदलने पर बिजनेस नियम गलती से प्रभावित न हों।
आम समस्याएँ:
tenant_id नहीं)\n- सॉफ्ट-डिलीट की गलतियाँ (deleted_at को यूनिकनेस/क्वेरी में न मिलाना)AI को अपने टॉप क्वेरीज़ के बारे में कहें और फिर वेरिफाई करें:
tenant_id + created_at)यदि आप टॉप 5 क्वेरीज़ नहीं बता सकते, तो किसी भी इंडेक्स योजना को अधूरा मानें।
AI अच्छे स्टैंडर्ड स्कैफ़ोल्डिंग पर सक्षम है, पर ध्यान दें कि:
200 बॉडी में एरर, कभी 4xx/5xx)API को प्रोडक्ट इंटरफ़ेस की तरह डिज़ाइन करें: रिसोर्सेज़ को यूज़र के मानसिक मॉडल के हिसाब से बनाइए, न कि DB इम्प्लीमेंटेशन के अनुसार।
एक सुरक्षित वर्कफ़्लो अपनाइए:
यह लूप AI के सुझावों को प्रूवेबल आर्टिफैक्ट्स में बदल देता है—जिन्हें स्वीकार या अस्वीकार किया जा सके।
एक सुसंगत एरर एन्वेलेट और HTTP कोड नीति अपनाएँ। उदाहरण के लिए:
400, 401, 403, 404, 409, , पहले ऐसे टेस्ट करें जो व्यवहार लॉक करें:
टेस्ट्स वह तरीका हैं जिससे आप डिज़ाइन के मालिक बनते हैं न कि AI की धारणाओं के वारिस।
AI को ड्राफ्ट्स के लिए प्रयोग करें जब पैटर्न अच्छे से समझे हुए हों (CRUD-heavy MVPs, आंतरिक टूल)। सावधानी बरतें जब:
नीतिगत रूप से: AI ऑप्शन्स प्रस्तावित करे, पर स्कीमा इनवेरिएंट्स, ऑथराइज़ेशन और रोलआउट/माइग्रेशन पर मानव साइन-ऑफ आवश्यक होना चाहिए।
एक स्कीमा साफ़ दिख सकता है और फिर भी रीयल वर्कफ़्लो और लोड पर फेल कर सकता है।
422429{"error":{"code":"...","message":"...","details":[...]}}
सुनिश्चित करें कि एरर मैसेज़ इंटर्नल्स (SQL, स्टैक ट्रेस, सीक्रेट्स) लीक न करें और सभी एंडपॉइंट्स पर सुसंगत रहें।