26 अग॰ 2025·8 मिनट
AI-संचालित एडमिन डैशबोर्ड के लिए वेब ऐप कैसे बनाएं
AI इनसाइट्स, सुरक्षित पहुँच, विश्वसनीय डेटा और मापनीय गुणवत्ता के साथ एक एडमिन डैशबोर्ड वेब ऐप डिज़ाइन, बनान और लॉन्च करने की चरण-दर-चरण योजना।
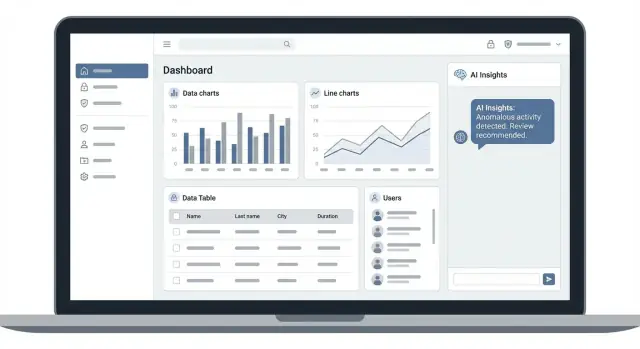
AI इनसाइट्स, सुरक्षित पहुँच, विश्वसनीय डेटा और मापनीय गुणवत्ता के साथ एक एडमिन डैशबोर्ड वेब ऐप डिज़ाइन, बनान और लॉन्च करने की चरण-दर-चरण योजना।
चार्ट स्केच करने या LLM चुनने से पहले यह साफ़ कर लें कि यह एडमिन डैशबोर्ड किसके लिए है और किन निर्णयों में मदद करेगा। एडमिन डैशबोर्ड अक्सर तब फेल होते हैं जब वे “सबके लिए” बनने की कोशिश करते हैं और किसी के भी लिए उपयोगी नहीं रहते।
उन प्रमुख भूमिकाओं को सूचीबद्ध करें जो डैशबोर्ड में रोज़ आती हैं—आम तौर पर ops, support, finance और product। हर भूमिका के लिए वे 3–5 प्रमुख निर्णय लिखें जो वे हर दिन या सप्ताह लेते हैं। उदाहरण:
अगर कोई विजेट किसी निर्णय में मदद नहीं करता, तो वह शायद शोर है।
“AI-संचालित एडमिन डैशबोर्ड” को एक सामान्य चैटबॉट के बजाय कुछ ठोस सहायक फीचर्स में बदलें। सामान्य उच्च-मूल्य AI फीचर्स में शामिल हैं:
उन वर्कफ़्लोज़ को अलग करें जिन्हें तुरंत अपडेट चाहिए (fraud checks, outages, stuck payments) और जिन्हें hourly/daily अपडेट करना ठीक है (साप्ताहिक वित्त सारांश, cohort रिपोर्ट)। यह निर्णय जटिलता, लागत और AI उत्तरों की ताज़गी तय करता है।
ऐसे आउटकम चुनें जो वास्तविक ऑपरेशनल वैल्यू दर्शाते हैं:
यदि आप सुधर नहीं माप सकते, तो यह बताना मुश्किल होगा कि AI फीचर्स काम कर रहे हैं या सिर्फ अतिरिक्त काम पैदा कर रहे हैं।
स्क्रीन डिज़ाइन करने या AI जोड़ने से पहले यह स्पष्ट कर लें कि आपका डैशबोर्ड किन डेटा पर निर्भर करेगा—और वो डेटा एक-दूसरे से कैसे जुड़ता है। बहुत से एडमिन डैशबोर्ड दर्द असाइनमेंट की परिभाषाओं में मिसमैच या छुपे स्रोतों से आता है (“एक सक्रिय यूज़र क्या गिना जाता है?”)।
शुरू में हर जगह की सूची बनाएं जहाँ "सच" मौजूद है। कई टीमों के लिए इसमें शामिल हैं:
हर स्रोत के लिए पकड़ें: किसका मालिक है, कैसे एक्सेस होता है (SQL, API, एक्सपोर्ट), और सामान्य join keys क्या हैं (email, account_id, external_customer_id)। वही keys बाद में डेटा जॉइन करने लायक बनाते हैं।
एडमिन डैशबोर्ड सबसे अच्छा तब काम करते हैं जब वे कुछ ही एंटिटीज़ के इर्द‑गिर्द बने होते हैं जो हर जगह दिखती हैं। सामान्यतः शामिल होते हैं: users, accounts, orders, tickets, और events। ओवर‑मॉडलिंग मत करें—उन कुछ चीज़ों को चुनें जिनको एडमिन सचमुच सर्च और ट्रबलशूट करते हैं।
एक साधारण डोमेन मॉडल कुछ इस तरह दिख सकता है:
यह परफेक्ट DB डिज़ाइन के बारे में नहीं है—यह तय करने के बारे में है कि एडमिन जब एक रिकॉर्ड खोलते हैं तो वे किस पर ध्यान दे रहे हैं।
हर महत्वपूर्ण फ़ील्ड और मैट्रिक के लिए यह रिकॉर्ड करें कि परिभाषा किसकी है। उदाहरण के लिए, Finance “MRR” का मालिक हो सकता है, Support “First response time” का, और Product “Activation” का। जब ownership स्पष्ट होती है तो conflicts सुलझाना आसान होता है और नंबर चुपचाप बदलने से बचा जा सकता है।
डैशबोर्ड अक्सर अलग‑अलग फ्रेशनेस ज़रूरत वाले डेटा को मिलाते हैं:
लेट इवेंट्स और corrections (बाद में पोस्ट हुए refunds, डिलीवर्ड ब्लॉक इवेंट, मैनुअल adjustments) के लिए भी योजना बनाएं। तय करें कि आप कितनी पीछे तक backfills की अनुमति देंगे, और कैसे corrected history दिखाएंगे ताकि एडमिन का भरोसा न टूटे।
एक सरल डेटा शब्दकोश बनाएँ (एक डॉक ठीक है) जो नामकरण और अर्थ को स्टैंडर्ड करे। शामिल करें:
यह डैशबोर्ड एनालिटिक्स और बाद के LLM इंटीग्रेशन के लिए संदर्भ बन जाएगा—क्योंकि AI वही बताएगा जो उसे दिए गए परिभाषाओं तक सीमित किया गया है।
एक अच्छा एडमिन डैशबोर्ड स्टैक नवाचार से ज़्यादा अनुमानित प्रदर्शन के बारे में है: तेज पेज लोड, सुसंगत UI, और AI जोड़ने का साफ़ रास्ता बिना मूल ऑपरेशंस को उलझाए।
एक मुख्यधारा फ्रेमवर्क चुनें जिसे आपकी टीम रख-रखाव कर सके। React (Next.js के साथ) या Vue (Nuxt के साथ) दोनों एडमिन पैनल के लिए अच्छे हैं।
डिज़ाइन को सुसंगत रखने और डिलीवरी तेज़ करने के लिए एक कंपोनेंट लाइब्रेरी उपयोग करें:
कंम्पोनेंट लाइब्रेरीज़ एक्सेसिबिलिटी और सामान्य पैटर्न (tables, filters, modals) भी संभालती हैं, जो कस्टम विजुअल्स से ज़्यादा मायने रखती हैं एडमिन UI में।
दोनों काम करते हैं, पर निरंतरता चुनाव से ज़्यादा महत्वपूर्ण है।
/users, /orders, /reports?from=...&to=...。यदि अनिश्चित हैं, REST से शुरू करें अच्छे क्वेरी पैरामीटर्स और pagination के साथ। बाद में GraphQL गैटवे जोड़ा जा सकता है।
अधिकांश AI-सक्षम एडमिन प्रोडक्ट्स के लिए:
एक सामान्य पैटर्न है “महंगे विजेट्स को कैश करें” (top KPIs, summary cards) छोटा TTL देकर ताकि डैशबोर्ड snappy रहे।
LLM इंटीग्रेशन सर्वर‑साइड रखें ताकि keys सुरक्षित रहें और डेटा एक्सेस नियंत्रित रहे।
यदि आपका लक्ष्य जल्दी MVP दिखाना है (RBAC, tables, drill-down पेज, और AI हेल्पर्स के साथ), तो vibe‑coding प्लेटफ़ॉर्म जैसे Koder.ai निर्माण/इटरेट साइकिल को छोटा कर सकते हैं। आप स्क्रीन और वर्कफ़्लो चैट में बयान करके React फ्रंटएंड, Go + PostgreSQL बैकएंड जेनरेट कर सकते हैं और बाद में स्रोत कोड export कर सकते हैं। प्लानिंग मोड और snapshots/rollback जैसी सुविधाएँ प्रॉम्प्ट टेम्पलेट्स और AI UI के साथ इटरेशन करते समय उपयोगी हैं बिना मुख्य ऑपरेशंस को तोड़े।
[Browser]
|
v
[Web App (React/Vue)]
|
v
[API (REST or GraphQL)] ---> [Auth/RBAC]
| |
| v
| [LLM Service]
v
[PostgreSQL] <--> [Redis Cache]
|
v
[Job Queue + Workers] (async AI/report generation)
यह सेटअप सरल रहता है, धीरे‑धीरे स्केल करता है, और AI फीचर्स को additive रखता है न कि हर रिक्वेस्ट पाथ में उलझा देता है।
एडमिन डैशबोर्ड उस पर निर्भर करते हैं कि कोई कितनी जल्दी जवाब दे सके: “क्या गलत है?” और “अब मुझे क्या करना चाहिए?” UX को वास्तविक एडमिन काम के इर्द‑गिर्द डिज़ाइन करें और खो जाने को मुश्किल बनाएं।
उन शीर्ष टास्क से शुरू करें जो एडमिन रोज़ करते हैं (रिफंड करना, यूज़र अनब्लॉक करना, स्पाइक की जांच, प्लान अपडेट)। नेविगेशन को उन जॉब्स के चारों ओर समूहित करें—भले ही बैकएंड में डेटा कई टेबल में फैला हो।
एक सरल संरचना जो अक्सर काम करती है:
एडमिन कुछ कार्रवाइयों को बार‑बार दोहराते हैं: search, filter, sort, compare। नेविगेशन ऐसा रखें कि ये हमेशा उपलब्ध और सुसंगत हों।
चार्ट ट्रेंड के लिए अच्छे हैं, पर एडमिन अक्सर सटीक रिकॉर्ड चाहते हैं। उपयोग करें:
शुरू से ही बेसिक्स जोड़ें: पर्याप्त कंट्रास्ट, विजिबल फोकस स्टेट्स, और टेबल कंट्रोल्स/डायलॉग के लिए कीबोर्ड नेविगेशन।
हर विजेट के लिए empty/loading/error स्टेट्स भी प्लान करें:
जब UX दबाव में भी अनुमानित रहता है, एडमिन उस पर भरोसा करते हैं और तेज़ काम करते हैं।
एडमिन डैशबोर्ड खोलते हैं ताकि निर्णय लें, समस्याएँ सुलझाएँ, और ऑपरेशन्स चलें। आपके AI फीचर्स को repetitive काम हटाना, जांच समय घटाना, और गल्तियों को कम करना चाहिए—न कि एक और मैनेजमेंट सरफेस जोड़ना।
ऐसे छोटे सेट चुनें जो मैन्युअल कदमों को सीधे बदलते हैं। शुरुआती अच्छे उम्मीदवार संकुचित, समझने योग्य और वैलिडेट करने में आसान होते हैं।
आम उदाहरण:
AI को टेक्स्ट लिखने के लिए उपयोग करें जहाँ आउटपुट एडिटेबल और कम‑जोखिम हो (सारांश, ड्राफ्ट, इंटरनल नोट)। AI को सुझाव देने के लिए उपयोग करें जहाँ मानव नियंत्रण आवश्यक हो (अनुशंसित अगले कदम, संबंधित रिकॉर्ड के लिंक, प्री‑फिल्टर्ड व्यूज़)।
एक व्यावहारिक नियम: यदि गलती से पैसे, परमिशन, या कस्टमर एक्सेस बदल सकता है, AI को प्रस्ताव देना चाहिए—न कि निष्पादित करना।
हर AI फ़्लैग या सिफारिश के साथ एक छोटा “क्यों मैं यह देख रहा/रही हूँ?” स्पष्टीकरण शामिल करें। इसे उपयोग किए गए संकेतों का हवाला देना चाहिए (उदा., “14 दिनों में 3 failed payments” या “error rate release 1.8.4 के बाद 0.2% से 1.1% हुआ”)। यह भरोसा बनाता है और एडमिन को खराब डेटा पकड़ने में मदद करता है।
तय करें कि AI कब इंकार करे (missing permissions, sensitive requests, unsupported operations) और कब clarification माँगे (अस्पष्ट अकाउंट, conflicting metrics, incomplete time range)। इससे अनुभव केंद्रित रहता है और confident पर बेकार आउटपुट से बचाव होता है।
एक एडमिन डैशबोर्ड में पहले से ही डेटा हर जगह है: बिलिंग, सपोर्ट, प्रोडक्ट इस्तेमाल, ऑडिट लॉग, और इंटरनल नोट्स। एक AI असिस्टेंट उतना ही उपयोगी है जितना कि आप शीघ्र, सुरक्षित और सुसंगत रूप से संदर्भ जोड़ सकें।
उन एडमिन टास्क से शुरू करें जिन्हें आप तेज़ करना चाहते हैं (उदा., “यह अकाउंट ब्लॉक क्यों हुआ?” या “इस ग्राहक के हाल के incidents का सारांश दें”)। फिर छोटे, अनुमानित संदर्भ इनपुट्स की परिभाषा करें:
यदि कोई फ़ील्ड AI के जवाब को नहीं बदलता, तो उसे शामिल न करें।
संदर्भ को अपने आप में एक प्रोडक्ट API समझें। सर्वर‑साइड “context builder” बनाएं जो हर entity (account/user/ticket) के लिए न्यूनतम JSON पैलोड बनाए। केवल जरूरी फ़ील्ड शामिल करें, और संवेदनशील डेटा (tokens, पूर्ण कार्ड विवरण, पूर्ण पते, कच्चे संदेश) को स्ट्रिप या मास्क करें।
डिबग और ऑडिट के लिए मेटाडेटा जोड़ें:
context_versiongenerated_atsources: कौन‑से सिस्टम ने डेटा दियाredactions_applied: क्या हटाया/मास्क किया गयाहर टिकट, नोट और पॉलिसी को प्रॉम्प्ट में घुसा देने की कोशिश नहीं करें—यह स्केल नहीं करेगा। इसके बजाय, सर्चेबल कंटेंट (नोट्स, KB आर्टिकल, प्लेबुक) को इंडेक्स में रखें और केवल सबसे प्रासंगिक स्निपेट्स को अनुरोध समय पर हासिल करें।
एक सरल पैटर्न:
यह प्रॉम्प्ट छोटे रखता है और उत्तरों को असली रिकॉर्ड्स पर आधारित बनाता है।
AI कॉल्स कभी‑कभी फेल होंगी। इसके लिए डिज़ाइन करें:
कई एडमिन प्रश्न दोहराते हैं (“account health summarize करें”)। परिणामों को entity + prompt version के हिसाब से कैश करें, और व्यवसायिक अर्थ के अनुसार expire करें (उदा., लाइव मैट्रिक्स के लिए 15 मिनट, सारांशों के लिए 24 घंटे)। हमेशा “as of” timestamps दिखाएँ ताकि एडमिन जानें उत्तर कितना ताज़ा है।
एडमिन डैशबोर्ड उच्च‑ट्रस्ट वातावरण होते हैं: AI ऑपरेशनल डेटा देखता है और निर्णयों को प्रभावित कर सकता है। अच्छा prompting “चतुर शब्द” से ज़्यादा पूर्वानुमेय संरचना, सख्त सीमाएँ, और ट्रेसबिलिटी के बारे में है।
हर AI अनुरोध को एक API कॉल जैसा मानें। इनपुट्स स्पष्ट फॉर्मेट (JSON या bullet fields) में दें और विशिष्ट आउटपुट स्कीमा मांगें।
उदाहरण के लिए:
यह “freeform creativity” को कम करता है और UI में दिखाने से पहले प्रतिक्रियाओं को वैलिडेट करना आसान बनाता है।
टेम्पलेट्स को फीचर्स के across सुसंगत रखें:
स्पष्ट नियम जोड़ें: कोई सीक्रेट्स नहीं, प्रदान किए गए से आगे व्यक्तिगत डेटा नहीं, और जोखिम‑भरे काम (users delete करना, refunds करना, permissions बदलना) बिना मानवीय पुष्टि के न करें।
जहाँ संभव हो, citations अनिवार्य करें: हर दावे को एक स्रोत रिकॉर्ड (ticket ID, order ID, event timestamp) से लिंक करें। अगर मॉडल cite नहीं कर सकता, तो उसे कहना चाहिए।
प्रॉम्प्ट्स, रिट्रीव्ड context identifiers, और आउटपुट्स को लॉग करें ताकि आप इश्यूज़ रीप्रोड्यूस कर सकें। संवेदनशील फ़ील्ड (tokens, emails, addresses) को रेडैक्ट करें और एक्सेस‑कंट्रोल्ड लॉग रखें। यह तब अनमोल होता है जब कोई एडमिन पूछे, “AI ने यह सुझाने का आधार क्या लिया?”
एडमिन डैशबोर्ड शक्ति केंद्रित होते हैं: एक क्लिक में प्राइसिंग बदल सकती है, यूज़र्स डिलीट हो सकते हैं, या निजी डेटा एक्सपोज़ हो सकता है। AI‑सक्षम डैशबोर्ड के लिए दांव और भी बड़े हैं—एक असिस्टेंट सुझाव दे सकता है जो निर्णयों को प्रभावित करे। सुरक्षा को एक कोर फ़ीचर मानें, न कि बाद में जोड़ा जाने वाला लेयर।
जब आपका डेटा मॉडल और रूट्स अभी विकसित हो रहे हों तब RBAC जल्दी लागू करें। छोटे रोल्स का सेट परिभाषित करें (उदा.: Viewer, Support, Analyst, Admin) और permissions को रोल्स से जोड़े—व्यक्तिगत यूज़र्स से नहीं। इसे साधारण और स्पष्ट रखें।
एक व्यावहारिक तरीका permissions matrix बनाए रखना है (यहाँ तक कि डॉक में भी) जो जवाब देता है: “कौन यह देख सकता है?” और “कौन इसे बदल सकता है?”। यह आपकी API और UI को गाइड करेगा और बढ़ने पर अनजाने privilege creep से रोकेगा।
कई टीमें सिर्फ “पेज एक्सेस” पर रुक जाती हैं। इसके बजाय कम से कम दो स्तर अलग रखें:
यह विभाजन जोखिम घटाता है जब आपको व्यापक visibility देनी हो (उदा., support स्टाफ) पर critical settings बदलने की अनुमति नहीं देनी।
UI में बटन छिपाएँ UX के लिए, पर सुरक्षा UI चेक पर निर्भर न करें। हर endpoint को कॉलर के रोल/permissions validate करने चाहिए:
“महत्वपूर्ण कार्रवाइयों” को इतना कंटेक्स्ट के साथ लॉग करें कि यह जवाब दे सके किसने क्या कब और कहाँ बदला। कम से कम capture करें: actor user ID, action type, target entity, timestamp, before/after values (या diff), और request metadata (IP/user agent)। ऑडिट लॉग्स append‑only, searchable और edits से सुरक्षित रखें।
आप अपनी सुरक्षा धारणाएँ और ऑपरेटिंग नियम (session handling, admin access process, incident response basics) लिखें। यदि आप सुरक्षा पेज रखते हैं तो उसे उत्पाद डॉक से लिंक करें (देखें /security) ताकि एडमिन और ऑडिटर्स को पता रहे क्या उम्मीद करनी चाहिए।
आपका API आकार या तो एडमिन अनुभव को snappy रखेगा—या फ्रंटएंड को हर स्क्रीन पर बैकएंड से लड़ना पड़ेगा। सबसे सरल नियम: endpoints उस तरह डिज़ाइन करें जैसा UI को वास्तव में चाहिए (list views, detail pages, filters, और कुछ aggregates), और response formats को predictable रखें।
प्रत्येक मुख्य स्क्रीन के लिए छोटे endpoints सेट परिभाषित करें:
GET /admin/users, GET /admin/ordersGET /admin/orders/{id}GET /admin/metrics/orders?from=...&to=...“सब कुछ वापिस कर देने” वाले endpoints से बचें जैसे GET /admin/dashboard—ये अनंत तक बढ़ जाते हैं, cache करना मुश्किल होता है, और आंशिक UI अपडेट दर्दनाक बनाते हैं।
एडमिन तालिकाओं की जान consistency है। समर्थन करें:
limit, cursor या page)sort=created_at:desc)status=paid&country=US)Filters समय के साथ स्थिर रखें (मत silently meanings बदलें), क्योंकि एडमिन URLs बुकमार्क और views साझा करेंगे।
बड़े एक्सपोर्ट, लंबी रिपोर्ट्स, और AI generation asynchronous होने चाहिए:
POST /admin/reports → job_id लौटाएGET /admin/jobs/{job_id} → status + progressGET /admin/reports/{id}/download जब तैयार होइसी पैटर्न से “AI summaries” या “draft replies” के लिए भी UI responsive रहती है।
Errors को स्टैंडर्डाइज़ करें ताकि frontend उन्हें स्पष्ट दिखा सके:
{ "error": { "code": "VALIDATION_ERROR", "message": "Invalid date range", "fields": { "to": "Must be after from" } } }
यह आपके AI फीचर्स के लिए भी मददगार है: आप actionable failures दिखा सकते हैं बजाय vague “कुछ गड़बड़ हुई” के।
एक बेहतरीन एडमिन डैशबोर्ड फ्रंटएंड मॉड्यूलर महसूस कराता है: आप नया रिपोर्ट या AI हेल्पर जोड़ सकते हैं बिना पूरे UI को री‑बिल्ड किए। एक छोटे सेट के reusable blocks को स्टैंडर्डाइज़ करें, फिर उनका बिहेवियर पूरे ऐप में सुसंगत रखें।
हर स्क्रीन पर पुन: उपयोग होने वाला core “dashboard kit” बनाएं:
ये ब्लॉक्स स्क्रीन को सुसंगत रखते हैं और one-off UI निर्णयों को कम करते हैं।
एडमिन अक्सर views को बुकमार्क और लिंक शेयर करते हैं। मुख्य state URL में रखें:
?status=failed&from=...&to=...)?orderId=123 side panel खोलने के लिए)Saved views जोड़ें (“My QA queue”, “Refunds last 7 days”) जो filters का नामित सेट स्टोर करें। इससे उपयोगकर्ता बार‑बार वही क्वेरी न बनाकर तेज महसूस करते हैं।
AI आउटपुट को ड्राफ्ट मानें, अंतिम उत्तर नहीं। साइड पैनल (या “AI” टैब) में दिखाएँ:
हमेशा AI कंटेंट लेबल करें और दिखाएँ कि कौन‑से रिकॉर्ड संदर्भ के रूप में उपयोग हुए थे।
यदि AI किसी कार्रवाई का सुझाव देता है (user को flag करना, refund, block payment), तो एक review step आवश्यक रखें:
जो मायने रखता है उसे ट्रैक करें: search उपयोग, filter बदलाव, exports, AI open/click‑through, regenerate दर, और feedback। ये संकेत UI बेहतर करने में मदद करेंगे और बतायेंगे कौन‑से AI फीचर्स वास्तव में समय बचा रहे हैं।
एडमिन डैशबोर्ड का परीक्षण पिक्सेल‑परफेक्ट UI से कम और वास्तविक स्थितियों में आत्मविश्वास अधिक है: stale data, slow queries, imperfect inputs, और तेज़‑क्लिक करने वाले power users।
उन वर्कफ़्लोज़ की एक छोटी सूची से शुरू करें जो कभी भी टूटनी नहीं चाहिए। इन्हें end-to-end (ब्राउज़र + बैकएंड + DB) में ऑटोमेट करें ताकि आप integration bugs पकड़ सकें, न कि सिर्फ़ यूनिट‑लेवल।
सामान्य “must-pass” फ्लोज़: लॉगिन (roles के साथ), global search, रिकॉर्ड एडिट करना, रिपोर्ट एक्सपोर्ट, और कोई भी approval/review action। कम से कम एक टेस्ट ऐसा रखें जो वास्तविक dataset आकार कवर करे—क्योंकि performance regressions छोटे fixtures में छिपे रहते हैं।
AI फीचर्स के लिए अपना टेस्ट आर्टिफैक्ट बनाएं: 20–50 prompts जो वास्तविक एडमिन सवालों जैसे हों, हर एक के साथ अपेक्षित “अच्छा” उत्तर और कुछ “खराब” उदाहरण (hallucinations, policy violations, या missing citations)।
इसे अपने रेपो में versioned रखें ताकि prompts, tools, या models में बदलाव को कोड की तरह रिव्यू किया जा सके।
कुछ सरल मैट्रिक्स ट्रैक करें:
adversarial इनपुट्स (प्रॉम्प्ट इंजेक्शन प्रयास) का भी परीक्षण करें ताकि गार्डरेल्स कायम रहें।
मॉडल डाउनटाइम की योजना बनाएं: AI पैनल डिसेबल करें, plain analytics दिखाएँ, और मूल क्रियाएँ उपयोग योग्य रखें। यदि आपके पास feature flag सिस्टम है तो AI को flag के पीछे रखें ताकि जल्दी rollback संभव हो।
अंततः गोपनीयता की समीक्षा करें: लॉग रेडैक्ट करें, कच्चे प्रॉम्प्ट्स न रखें जो संवेदनशील पहचानकर्ता शामिल कर सकते हैं, और डिबग/एवैल्यूएशन के लिए केवल जरूरी डेटा रखें। /docs/release-checklist में एक सरल चेकलिस्ट टीम को लगातार शिप करने में मदद करेगी।
AI‑सक्षम एडमिन डैशबोर्ड का लॉन्च एक घटना नहीं है—यह “works on my machine” से “operators द्वारा ट्रस्टेड” में नियंत्रित संक्रमण है। सबसे सुरक्षित तरीका है लॉन्च को इंजीनियरिंग वर्कफ़्लो मानना: साफ़ environments, दृश्यता, और एक जानबूझकर फीडबैक लूप के साथ।
डेव, स्टेज और प्रोड अलग रखें—हर एक के अलग DB, API keys, और AI provider क्रेडेंशियल्स। स्टेज प्रोड की सेटिंग्स को नज़दीकी आइना होना चाहिए (feature flags, rate limits, background jobs) ताकि आप वास्तविक व्यवहार को वेरिफाई कर सकें बिना लाइव ऑपरेशंस जोखिम में डाले।
कॉनफिगरेशन environment variables और सुसंगत deployment प्रक्रिया के माध्यम से रखें। यह rollbacks को अनुमानित बनाता है और “स्पेशल‑केस” प्रोड बदलाओं से बचाता है।
यदि आप किसी प्लेटफ़ॉर्म का उपयोग करते हैं जो snapshots और rollback सपोर्ट करता है (उदा., Koder.ai का built-in snapshot flow), तो AI फीचर इटरेशन के लिए भी वही अनुशासन इस्तेमाल करें: फीचर फ्लैग के पीछे शिप करें, मापें, और अगर prompts या retrieval से admin भरोसा घटता है तो जल्दी rollback करें।
ऐसी मॉनिटरिंग सेट करें जो सिस्टम हेल्थ और यूज़र अनुभव दोनों को ट्रैक करे:
डेटा फ्रेशनेस के लिए alerts जोड़ें (उदा., “sales totals last updated 6+ hours ago”) और डैशबोर्ड लोड टाइम्स के लिए (उदा., p95 > 2s)। ये दो समस्याएँ एडमिन के लिए सबसे अधिक भ्रम पैदा करती हैं क्योंकि UI "ठीक" दिख सकता है पर डेटा stale या slow हो सकता है।
एक छोटा MVP शिप करें, फिर वास्तविक उपयोग के आधार पर विस्तार करें: कौन‑सी रिपोर्ट रोज़ खोली जाती है, कौन‑सी AI सिफारिशें स्वीकार की जाती हैं, कहाँ एडमिन हिचकिचाते हैं। नए AI फीचर्स को फ्लैग के पीछे रखें, छोटे experiments चलाएँ, और व्यापक पहुँच से पहले मेट्रिक्स रिव्यू करें।
अगले कदम: /docs में एक internal runbook प्रकाशित करें, और यदि आप tiers या उपयोग सीमाएँ पेश करते हैं तो उन्हें /pricing पर स्पष्ट करें।
Start by listing the primary admin roles (support, ops, finance, product) and the 3–5 decisions each role makes weekly. Then design widgets and AI helpers that directly support those decisions.
A good filter is: if a widget doesn’t change what someone does next, it’s likely noise.
It should mean a small set of concrete helpers embedded in workflows, not a generic chatbot.
Common high-value options:
Use real-time where someone must react immediately (fraud checks, outages, stuck payments). Use hourly/daily refresh for reporting-heavy workflows (finance summaries, cohort analysis).
This choice affects:
Start by inventorying every place “truth” lives:
For each, capture , access method (SQL/API/export), and the (account_id, external_customer_id, email). Those keys determine how well you can connect admin views and AI context.
Pick a small set of core entities admins actually search and troubleshoot (often: Account, User, Order/Subscription, Ticket, Event).
Write a simple relationship model (e.g., Account → Users/Orders; User → Events; Account/User → Tickets) and document metric ownership (e.g., Finance owns MRR).
This keeps screens and AI prompts grounded in shared definitions.
A practical baseline is:
Keep LLM calls server-side to protect keys and enforce access control.
Design navigation around jobs, not tables. Keep frequent tasks (search/filter/sort/compare) always available.
Practical UI patterns:
Build AI features that reduce repetitive work and shorten investigations:
Rule of thumb: if a mistake affects money, permissions, or access, AI should suggest, not execute.
Create a server-side context builder that returns minimal, safe JSON per entity (account/user/ticket). Include only fields that change the answer, and mask sensitive data.
Add metadata for debugging and audits:
context_versiongenerated_atsourcesImplement RBAC early and enforce it on the server for every action (including AI-generated reports and exports).
Also add:
redactions_appliedFor large text (tickets, notes, KB), use retrieval: fetch only relevant snippets and pass them with citations.