पहले हम वेब, मोबाइल और बैकएंड से क्या मतलब लेते थे
सालों तक “वेब”, “मोबाइल” और “बैकएंड” सिर्फ लेबल नहीं थे—ये सीमाएँ थीं जिन्होंने टीमों के सॉफ़्टवेयर बनाने के तरीके को आकार दिया।
पारंपरिक विभाजन
वेब आमतौर पर ब्राउज़र में चलने वाली चीज़ें थी: पेज, कंपोनेंट्स, स्टेट मैनेजमेंट, और वह UI लॉजिक जो स्क्रीन को इंटरैक्टिव बनाता है। वेब टीमें तेज़ इटरेशन, रेस्पॉन्सिव लेआउट और ब्राउज़र कम्पैटिबिलिटी के लिए ऑप्टिमाइज़ करती थीं।
मोबाइल का मतलब नेटिव iOS/Android ऐप्स (और बाद में क्रॉस‑प्लेटफ़ॉर्म फ्रेमवर्क) था। मोबाइल डेवलपर्स ऐप‑स्टोर रिलीज़, डिवाइस परफॉर्मेंस, ऑफ़लाइन बिहेवियर, पुश नोटिफिकेशन्स, और प्लेटफ़ॉर्म‑विशेष UI पैटर्न की परवाह करते थे।
बैकएंड का मतलब उन सेवाओं से था जो पर्दे के पीछे चलती थीं: डेटाबेस, बिज़नेस नियम, ऑथेंटिकेशन, इंटीग्रेशन्स, क्यूज़, और API जो वेब/मोबाइल को फ़ीड करते थे। बैकएंड का ध्यान अक्सर भरोसेमंदी, डेटा एकरूपता, स्केलेबिलिटी और साझा लॉजिक पर रहता था।
टीमें इन लाइनों के चारों ओर क्यों व्यवस्थित थीं
यह विभाजन समन्वय‑ओवरहेड घटाता था क्योंकि हर परत के अपने टूल, रिलीज़ साइकिल, और विशेषज्ञता होती थी। टीमें अक्सर इस हकीकत को प्रतिबिंबित करती थीं:
- अलग रेपो (वेब ऐप, iOS ऐप, एंड्रॉयड ऐप, बैकएंड)
- अलग डिप्लॉयमेंट पाइपलाइन्स (ऐप स्टोर बनाम सर्वर डिप्लॉय)
- विशिष्ट कौशल सेट (UI/UX इम्प्लीमेंटेशन बनाम वितरित सिस्टम)
इससे स्वामित्व भी स्पष्ट रहता था: लॉगिन स्क्रीन टूटे तो यह “वेब” या “मोबाइल” था; लॉगिन API फेल हो तो यह “बैकएंड” था।
दिन‑प्रतिदिन में “सीमाएँ धुँधली होना” का क्या मतलब है
धुँधला होना मतलब ये परतें गायब हो जाती हैं नहीं। मतलब यह है कि काम अब उतना साफ़‑साफ़ अलग नहीं काटा जा रहा।
एक ही उत्पाद बदलाव — मान लीजिए, “ऑनबोर्डिंग सुधारें” — अब अधिकतर UI, API‑शेप, डेटा ट्रैकिंग, और प्रयोग (experiments) को एक पैकेट की तरह स्पैन करता है। सीमाएँ मौजूद रहती हैं, लेकिन कम कठोर लगती हैं: अधिक साझा कोड, अधिक साझा टूलिंग, और अक्सर वही लोग कई परतों में बदलाव करते हैं।
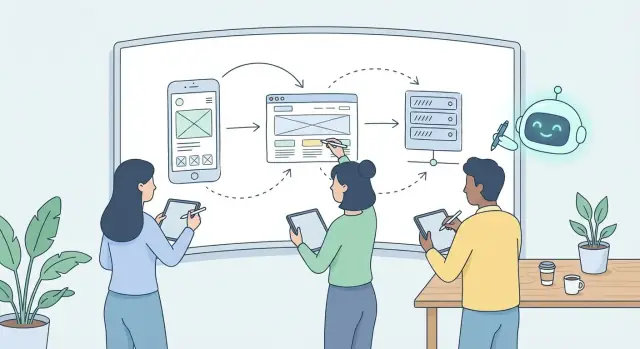
कैसे AI कार्य की इकाई को परतों से फीचरों पर बदलता है
सालों तक टीमें काम परतों के हिसाब से व्यवस्थित रही: “वेब पेज बनाता है,” “मोबाइल स्क्रीन बनाता है,” “बैकएंड एन्डपॉइंट जोड़ता है,” “डेटा टीम टेबल बनाती है।” यह विभाजन समझ में आता था जब हर परत अलग टूल, गहरा संदर्भ और बहुत मैनुअल गोंद चाहती थी।
AI‑सहायता वाला विकास कार्य की इकाई को ऊपर की ओर धकेलता है—परतों से फीचर‑स्तर तक।
“एक स्क्रीन लिखो” से “पूरा फीचर बनाओ” प्रॉम्प्ट तक
जब आप किसी AI टूल से कहते हैं “एक checkout स्क्रीन जोड़ो,” तो वह शायद सिर्फ़ एक UI फाइल पर नहीं रुकेगा। एक अच्छा प्रॉम्प्ट स्वाभाविक रूप से इरादे को शामिल करता है: उपयोगकर्ता क्या करने की कोशिश कर रहा है, किस डेटा की ज़रूरत है, सफलता/विफलता पर क्या होता है, और इसे कैसे स्टोर किया जाना चाहिए।
यह लोगों को ऐसे प्रॉम्प्ट्स की ओर धकेलता है जैसे:
- “‘Save for later’ फीचर end-to-end बनाओ, जिसमें UI, API और persistence शामिल हों।”
मिक्स्ड आउटपुट डिफ़ॉल्ट हैं
AI आउटपुट अक्सर एक बंडल के रूप में आते हैं: एक UI कंपोनेंट, एक API रूट, एक वैलिडेशन नियम, और एक डेटाबेस बदलाव—कभी‑कभी माइग्रेशन स्क्रिप्ट और बुनियादी टेस्ट तक। यह "बहुत चालाक" होने का मामला नहीं है; यह फीचर के काम करने के तरीके से मेल खाता है।
यही कारण है कि AI स्वाभाविक रूप से फीचर‑ओरिएंटेड है, न कि लेयर‑ओरिएंटेड: यह क्लिक → रिक्वेस्ट → लॉजिक → स्टोरेज → रिस्पॉन्स → रेंडर जैसी यूज़र स्टोरी को फ़ॉलो करते हुए जेनरेट करता है।
स्कोपिंग और हैंडऑफ में क्या बदलता है
वर्क प्लानिंग "परत‑वार टिकट" से बदलकर "एक फीचर‑स्लाइस के साथ स्पष्ट स्वीकार्यता मानदंड" की तरफ बढ़ती है। अलग‑अलग हैंडऑफ (वेब → बैकएंड → डेटा) के बजाय टीमें उस एक मालिक की ओर लक्ष्य करती हैं जो फीचर को परतों के पार ड्राइव करे, और जोखिम वाले हिस्सों की विशेषज्ञ समीक्षा कराई जाती है।
व्यवहारिक परिणाम: समन्वय‑देरी घटती है—पर स्पष्टता की उम्मीदें बढ़ती हैं। अगर फीचर अच्छी तरह परिभाषित नहीं है (एज़‑केस, परमिशन, एरर स्टेट्स), तो AI ऐसे कोड जेनरेट कर देगा जो पूरा दिखता है पर असल आवश्यकताओं से चूक सकता है।
साझा कोड और टूलिंग की ओर टेक‑स्टैक में बदलाव
AI‑सहायता विकास “अलग स्टैक्स” (वेब के लिए एक, मोबाइल के लिए एक, बैकएंड के लिए एक) से साझा बिल्डिंग‑ब्लॉक्स की ओर बढ़ने को तेज़ कर देता है। जब कोड तेजी से ड्राफ्ट किया जा सकता है, तो बाधा बन जाती है एकरूपता: क्या सभी चैनल एक ही नियम, एक ही डेटा शेप, और एक ही UI पैटर्न का उपयोग कर रहे हैं?
फ्रंट और बैक दोनों पर एक JavaScript/TypeScript टूलचेन
टीमें TypeScript पर मानकीकरण कर रही हैं, सिर्फ इसलिए नहीं कि यह ट्रेंडी है, बल्कि इसलिए कि इससे शेयरिंग सुरक्षित होती है। वही types API रिस्पांस को वर्णित कर सकते हैं, बैकएंड वैलिडेशन चला सकते हैं, और फ्रंटेंड फॉर्म्स चला सकते हैं।
टूलिंग भी समाहित होती है: फॉर्मैटिंग, लिंटिंग, और टेस्टिंग एकीकृत होते हैं ताकि परिवर्तन किसी हिस्से को तोड़ें जबकि दूसरे हिस्से में “पास” हो रहे हों।
मोनोरेपो और साझा पैकेज सामान्य रूप से
मोनोरेपो साझा कोड को व्यावहारिक बनाते हैं। लॉजिक को कॉपी करने के बजाय टीमें पुन:उपयोगी पैकेज निकालती हैं:
- Types और schemas (एक “User” या “Order” कैसा दिखता है)
- Validators (सुनिश्चित करना कि इनपुट हर जगह नियमों से मेल खाती है)
- UI components (बटन, फॉर्म कंट्रोल्स, लेआउट प्रिमिटिव्स)
यह drift घटाता है—खासकर जब AI कई जगहों पर कोड जेनरेट करता है। एक साझा पैकेज जेनरेटेड कोड को संरेखित रख सकता है।
क्रॉस‑प्लेटफ़ॉर्म UI फ्रेमवर्क और डिज़ाइन सिस्टम
क्रॉस‑प्लेटफ़ॉर्म फ्रेमवर्क और डिज़ाइन सिस्टम UI लेयर पर भी वही विचार आगे बढ़ाते हैं: कंपोनेंट्स को एक बार परिभाषित करें, फिर वेब और मोबाइल में पुन:उपयोग करें। भले ही अलग‑अलग ऐप्स बने रहें, साझा tokens (रंग, स्पेसिंग, टाइपोग्राफी) और कंपोनेंट APIs फीचर को लगातार लागू करना आसान बनाते हैं।
एक स्रोत‑सत्य से जेनरेटेड API क्लाइंट
एक और बड़ा बदलाव है API क्लाइंट्स का स्वचालित जेनरेशन (अक्सर OpenAPI या समान स्पेस से)। हर प्लेटफ़ॉर्म पर नेटवर्क कॉल मैन्युअली लिखने के बजाय, टीमें टाइप्ड क्लाइंट जेनरेट करती हैं ताकि वेब, मोबाइल, और बैकएंड कॉन्ट्रैक्ट्स सिंक में रहें।
जब सीमाएँ धुँधली होती हैं, तो ‘‘स्टैक’’ तकनीकों के बारे में कम और साझा प्रिमिटिव्स—types, schemas, components, और generated clients—के बारे में ज़्यादा होता है, जो फीचर को कम हैंडऑफ और कम सरप्राइज़ के साथ शिप करने देते हैं।
AI हर किसी को आंशिक फुल‑स्टैक डेवलपर बनाता है
AI‑सहायता विकास लोगों को उनकी “लेन” से बाहर निकालता है क्योंकि यह missing संदर्भ को तेज़ी से भर सकता है।
एक फ्रंट‑एंड डेवलपर “add caching with ETags and rate limiting” कह सकता है और सर्वर‑साइड चेंज का कार्यरूप पा सकता है, जबकि बैकएंड डेवलपर “यह स्क्रीन तेज़ महसूस कराओ” कह सकता है और skeleton loading, optimistic UI, और retry व्यवहार के सुझाव पा सकता है।
फ्रंट‑एंड डेवलपर्स अब कैशिंग, auth और rate limits को छूते हैं
जब AI सेकंडों में एक middleware या API gateway नियम ड्राफ्ट कर सकता है, तो “मैं बैकएंड नहीं लिखता” की प्रतिरोधक क्षमता घट जाती है। इससे फ्रंट‑एंड काम का स्वरूप बदलता है:
- Caching:
Cache‑Control, ETags, या क्लाइंट‑साइड cache invalidation को UI परफॉर्मेंस टास्क का हिस्सा माना जाता है।
- Auth: टोकन रिफ्रेश, secure cookie settings, और "401 पर क्या होता है" में क्लाइंट और सर्वर दोनों बदलाव कर सकते हैं।
- Rate limits: यदि infinite scroll API पर हिट कर रहा है, तो फिक्स में UI थ्रॉटलिंग के साथ सर्वर‑साइड लिमिट और फ्रेंडली एरर रिस्पोंस शामिल हो सकते हैं।
बैकएंड डेवलपर्स अब UX और लोडिंग स्टेट्स पर प्रभाव डालते हैं
बैकएंड निर्णय यूज़र एक्सपीरियंस को आकार देते हैं: रिस्पॉन्स टाइम, आंशिक विफलताएँ, और कौन‑सा डाटा जल्दी स्ट्रीम किया जा सकता है। AI बैकएंड डेवलपर्स को UX‑जागरूक बदलाव सुझाने और लागू करने में आसान बनाता है, जैसे:
- आंशिक परिणाम लौटाना (एक
warnings फील्ड के साथ)
- smoother scrolling के लिए cursor‑based pagination सपोर्ट करना
- initial render के लिए lightweight “summary”レス्पॉन्स भेजना और फिर विवरण लाना
एक फीचर, कई परतें: pagination, validation, error handling
Pagination एक अच्छा उदाहरण है। API को स्थिर cursors और predictable ordering चाहिए; UI‑ को “कोई और परिणाम नहीं” संभालना, retries, और तेज़ back/forward नेविगेशन चाहिए।
वैलिडेशन भी इसी तरह है: सर्वर‑साइड नियम निर्णायक हैं, लेकिन UI को उन्हें तुरंत फ़ीडबैक देने के लिए प्रतिबिंबित करना चाहिए। AI अक्सर दोनों पक्षों को एक साथ जेनरेट करता है—साझा schemas, सुसंगत error codes, और मैसेज जो फॉर्म फील्ड्स से साफ़‑साफ़ मैप हों।
एरर हैंडलिंग भी क्रॉस‑लेयर बन जाती है: एक 429 (rate limited) सिर्फ़ स्टेटस कोड नहीं होना चाहिए; उसे एक UI स्टेट चलाना चाहिए (“30 सेकंड में पुनः प्रयास करें”) और शायद बैकऑफ रणनीति को भी प्रेरित करना चाहिए।
इससे estimation और ownership पर क्या असर पड़ता है
जब एक “फ्रंटेंड” टास्क में चुपचाप API tweaks, कैशिंग हेडर्स, और auth edge cases शामिल हों, तो पुराने सीमाओं पर आधारित estimates टूट जाते हैं।
टीमें बेहतर करती हैं जब ownership को फीचर‑आउटकम (उदाहरण: “search तुरंत और भरोसेमंद लगे”) द्वारा परिभाषित किया जाता है और चेकलिस्ट में क्रॉस‑लेयर विचार शामिल होते हैं, भले ही अलग लोग अलग हिस्सों को लागू करें।
Backend‑for‑Frontend और UI‑आकृति वाले APIs का उदय
बनाएँ और इनाम पाएं
जो आप बनाते हैं उसे साझा करके या दूसरों को Koder.ai आज़माने के लिए आमंत्रित करके क्रेडिट पाएं।
Backend‑for‑Frontend (BFF) एक पतली सर्वर लेयर है जो विशेष रूप से एक ही क्लाइंट अनुभव के लिए बनाई जाती है—अक्सर वेब के लिए एक और मोबाइल के लिए एक। सामान्य API को हर ऐप कॉल करने और फिर डिवाइस पर reshape करने के बजाय, BFF ऐसे एंडपॉइंट देता है जो पहले से UI की जरूरतों से मेल खाते हैं।
वेब + मोबाइल के साथ BFF लोकप्रिय क्यों हैं
वेब और मोबाइल स्क्रीन अक्सर अवधारणाएँ साझा करते हैं पर विवरण अलग होते हैं: pagination नियम, कैशिंग, ऑफ़लाइन व्यवहार, और "तेज़" क्या महसूस होता है। एक BFF हर क्लाइंट को ठीक वही माँगने देता है जिसकी उसे ज़रूरत है बिना एक‑साइज‑फिट‑सभी API में समझौता किए।
प्रोडक्ट टीम्स के लिए, यह रिलीज़ भी सरल बना सकता है: UI परिवर्तन छोटी BFF अपडेट के साथ शिप हो सकते हैं, बिना हर बार व्यापक प्लेटफ़ॉर्म अनुबंध पर बातचीत के।
UI‑आकृति वाले AI‑जनरेटेड एंडपॉइंट
AI‑सहायता विकास के साथ टीमें अक्सर UI आवश्यकताओं से सीधे एंडपॉइंट जेनरेट करती हैं: “checkout summary को totals, shipping options, और payment methods एक कॉल में चाहिए।” यह स्क्रीन‑आकृति वाले APIs को प्रोत्साहित करता है—एंडपॉइंट्स जो स्क्रीन या उपयोगकर्ता यात्रा के आधार पर डिज़ाइन किए जाते हैं न कि केवल डोमेन एंटिटी के अनुसार।
यह round trips घटाकर और क्लाइंट कोड छोटा रखकर फायदेमंद हो सकता है। जोखिम यह है कि API मौजूदा UI का आईना बनकर रह सकता है, जिससे भविष्य की redesigns महँगी हो सकती हैं अगर BFF बिना संरचना के बढ़ता गया।
ट्रेड‑ऑफ: गति बनाम लॉजिक की नकल
BFF विकास को तेज़ कर सकता है, पर यह लॉजिक की नकल भी कर सकता है:
- वेब और मोबाइल BFFs में वैलिडेशन और फॉर्मेटिंग दोहराई जा सकती है
- समान aggregation कोड कई जगह में बनाए रखना पड़ सकता है
- कोर सर्विसेज़ से ऊपर बिज़नेस नियमों का रिसाव कई “सत्य के स्रोत” बना सकता है
एक अच्छा नियम है: BFF को ऑर्केस्ट्रेट और डेटा को आकार देना चाहिए, न कि कोर व्यवसाय व्यवहार को परिभाषित करना।
कब BFF जोड़ें (या टालें)
BFF तब जोड़ें जब आपके पास जटिल स्क्रीन‑विशेष संयोजन हो, प्रति दृश्य कई नेटवर्क कॉल हों, या अलग‑अलग क्लाइंट ज़रूरतें लगातार टकरा रही हों।
बचें जब आपकी उत्पाद छोटी हो, UI अभी अस्थिर हो, या आप सावधानीपूर्वक डिज़ाइन किए API और हल्के क्लाइंट‑साइड कम्पोज़िशन से ज़रूरतें पूरी कर सकें।
यदि आप BFF जोड़ते हैं, तो सीमा जल्दी निर्धारित करें: साझा बिज़नेस नियम कोर सर्विसेज़ में रहें, और BFF UI‑मैत्रीपूर्ण aggregation, caching, और authorization‑aware डेटा शेपिंग पर ध्यान दे।
कोड रिव्यू मुख्य कौशल बन जाता है
जब AI असाइन कर सकता है React कंपोनेंट, मोबाइल स्क्रीन, और डेटाबेस क्वेरी मिनटों में, तो “कोड लिखना” बदलकर “कोड की समीक्षा करना” बन जाता है। थ्रूपुट बढ़ता है, पर सूक्ष्म गलतियों का जोखिम भी बढ़ता है—खासकर जब बदलाव UI, API, और डेटा परतों को पार करता है।
रिव्यू अब सिंटैक्स नहीं, सिस्टम व्यवहार के बारे में है
AI आमतौर पर पठनीय कोड बना सकता है। उच्च‑मूल्य वाले रिव्यू प्रश्न हैं:
- क्या यह बदलाव प्रोडक्ट इरादे और किनारों से मेल खाता है?
- क्या यह असली डेटा, असली लेटेंसी, और असली उपयोगकर्ताओं के साथ सही व्यवहार करेगा?
- क्या हमने अनजाने में सुरक्षा/गोपनीयता का छेद बना दिया?
जो व्यक्ति परतों के पार बिंदुओं को जोड़ सकता है, वह सिर्फ़ स्टाइल सुधारने वाले से अधिक मूल्यवान बन जाता है।
परतों में क्या रिव्यु करें
कुछ बार‑बार होने वाले विफलता‑बिंदुओं पर ध्यान दें:
- डेटा एक्सेस: N+1 क्वेरीज, missing indexes, over‑fetching, और payload bloat
- सुरक्षा: सही सीमा पर auth checks, हर ऑपरेशन के लिए permission checks, टोकन्स का सुरक्षित हैंडलिंग, इनपुट वैलिडेशन, और rate limiting मान्यताएँ
- UX किनारे‑केसेस: लोडिंग और खाली स्टेट्स, मोबाइल पर ऑफ़लाइन/खराब नेटवर्क बिहेवियर, उपयोगकर्ता को मदद करने वाले एरर मैसेज, और पहुंच (accessibility) के बुनियादी सिद्धांत
- API कॉन्ट्रैक्ट्स: बैकवर्ड कम्पैटिबिलिटी, सुसंगत नामकरण, और UI के लिए शेप किए गए रिस्पॉन्स जो आंतरिक तालिकाओं को लीक न करें
गति के साथ तालमेल रखने के लिए चेकलिस्ट और टेस्ट
तेज़ आउटपुट को तंग गार्डरेल चाहिए। PR में हल्के चेकलिस्ट रिव्यूअर को संगत रहने में मदद करते हैं, जबकि स्वचालित टेस्ट मानव-भूल पकड़ते हैं।
अच्छे “AI‑स्पीड” क्षतिपूर्ति में शामिल हैं:
- APIs और schema बदलावों के लिए contract tests
- कुछ महत्वपूर्ण end-to-end फ्लोज़
- CI में linting/formatting और security scan
पेयरिंग: मानव डोमेन ज्ञान + AI स्पीड
व्यवहारिक पैटर्न है कि एक डोमेन विशेषज्ञ (प्रोडक्ट, अनुपालन, या प्लेटफ़ॉर्म संदर्भ) को एक बिल्डर के साथ पेयर किया जाए जो AI को ड्राइव करे। बिल्डर तेज़ी से जेनरेट और इटरेट करता है; डोमेन विशेषज्ञ वह कठिन प्रश्न पूछता है: “यदि उपयोगकर्ता निलंबित हो तो क्या होगा?” “कौन‑सा डेटा संवेदनशील माना जाता है?” “क्या यह इस बाजार में अनुमति है?”
यह संयोजन कोड रिव्यू को एक क्रॉस‑स्टैक गुणवत्ता अभ्यास बनाता है, न कि एक बाधा।
जब सीमाएँ धुँधली हों तो सुरक्षा और डेटा संबंधी चिंताएँ
जब AI एक ऐसा “फीचर” शिप करने में मदद करता है जो UI, API, और स्टोरेज को एक ही पास में छूता है, तो सुरक्षा मुद्दे अब "किसी और की समस्या" नहीं रहते। जोखिम यह नहीं है कि टीमें सुरक्षा भूल जाएँ—बल्कि छोटी गलतियाँ छूट जाती हैं क्योंकि अब कोई भी स्पष्ट रूप से उस सीमा का मालिक नहीं होता।
बार‑बार दिखने वाले क्रॉस‑लेयर जोखिम
कुछ समस्याएँ बार‑बार आती हैं जब AI‑जनरेटेड बदलाव कई परतों को स्पैन करते हैं:
- सीक्रेट्स का लीक होना: API keys क्लाइंट कोड में कॉपी हो जाना, उदाहरण
.env मान कमिट होना, या टोकन्स को logs में प्रिंट करना
- कमज़ोर authentication/authorization: एंडपॉइंट बिना उपयोगकर्ता पहचान जाँचे बनाना, या UI‑लेवल gating को असली access control समझना
- इंजेक्शन बग्स: SQL/NoSQL इंजेक्शन, असुरक्षित स्ट्रिंग इंटरपोलेशन, और सर्वर‑साइड रिक्वेस्ट फोर्जरी जब इनपुट्स सर्विसेज़ के बीच आगे बढ़ाएँ जाते हैं
छूट जाने वाले डेटा‑हैंडलिंग बेसिक्स
धुंधली सीमाएँ यह भी धुंधला कर देती हैं कि “डेटा” का क्या अर्थ है। इन्हें प्राथमिक डिजाइन निर्णय मानें:
- PII: क्या शामिल है (ईमेल, फोन, सटीक स्थान, उपकरण आईडी) और कहाँ दिखाई दे सकता है
- लॉगिंग: डिफ़ॉल्ट रूप से पेलोड लॉग न करें; पहचानकर्ताओं और टोकन्स को redact करें; स्पष्ट log levels सेट करें
- एनालिटिक्स इवेंट्स: कच्चा उपयोगकर्ता कंटेंट इवेंट प्रॉपर्टीज़ के रूप में न भेजें; schemas स्पष्ट रखें
- रिटेंशन: डेटा कितनी देर तक स्टोर किया जाता है, बैकअप सहित, और किसे एक्सेस है
AI‑सहायता काम के साथ स्केल करने वाले सुरक्षित डिफ़ॉल्ट
"डिफ़ॉल्ट पथ" को सुरक्षित बनाएं ताकि AI‑जेनरेटेड कोड गलत होने की संभावना कम हो:
- Least privilege: scoped tokens, न्यूनतम IAM रोल्स, जहाँ संभव read‑only
- Input validation: API सीमा पर वैलिडेट करें; अज्ञात फ़ील्ड रिजेक्ट करें; आकार सीमाएँ लागू करें
- Dependency hygiene: lockfiles, स्वचालित ऑडिट्स, और नए पैकेज जोड़ने की नीति
सुरक्षा‑रेडी प्रॉम्प्ट + रिव्यू चेकलिस्ट
AI से क्रॉस‑लेयर बदलाव जेनरेट करने से पहले एक मानक प्रॉम्प्ट का उपयोग करें:
Before generating code: list required authZ checks, input validation rules, sensitive data fields, logging/redaction rules, and any new dependencies. Do not place secrets in client code. Ensure APIs enforce permissions server-side.
फिर संक्षिप्त चेकलिस्ट के साथ रिव्यू करें: सर्वर पर authZ लागू है, सीक्रेट्स उजागर नहीं हुए, इनपुट्स वैलिडेट और इनकोड किए गए हैं, लॉग्स/इवेंट्स redact किए गए हैं, और नए dependencies का औचित्य स्पष्ट है।
प्रोजेक्ट मैनेजमेंट: एस्टिमेशन, स्वामित्व, और रिलीज़
प्रॉडक्शन-जैसे सेटअप में सत्यापित करें
विचार से होस्टेड ऐप तक जाएँ ताकि आप असली यूज़र फ्लो जल्दी टेस्ट कर सकें।
AI‑सहायता विकास काम के बोर्ड पर दिखने के तरीके को बदल देता है। एक ही फीचर मोबाइल स्क्रीन, वेब फ्लो, API एंडपॉइंट, एनालिटिक्स इवेंट्स, और परमिशन नियम को छू सकता है—अक्सर एक ही पुल‑रिक्वेस्ट में।
यह ट्रैक करना कठिन बनाता है कि समय कहाँ गया, क्योंकि “फ्रंटेंड” और “बैकएंड” कार्य अब साफ़‑साफ़ पृथक नहीं हैं।
परतों के पार फीचर होने पर एस्टिमेशन
जब फीचर परतों को स्पैन करता है, तो "कितने एंडपॉइंट" या "कितने स्क्रीन" पर आधारित पुराने एस्टिमेट असली प्रयास को चूकते हैं: एकीकरण, किनारे‑केस, और वैलिडेशन। अधिक भरोसेमंद तरीका है उपयोगकर्ता प्रभाव और जोखिम के हिसाब से एस्टिमेट करना।
एक व्यावहारिक पैटर्न:
- काम को ऐसे स्लाइस में तोड़ें जो उपयोगकर्ता यात्रा का एक पूरा कदम डिलीवर करें (आंशिक कंपोनेंट नहीं)
- इंटीग्रेशन और रोलआउट के लिए स्पष्ट समय जोड़ें (फ़ीचर फ्लैग्स, माइग्रेशन्स, ऐप स्टोर रिव्यू)
- "अज्ञात" को पहले‑क्लास टास्क मानें: सबसे कठिन हिस्सा जल्दी प्रोटोटाइप करें, फिर पुनः‑अनुमान लगाएँ
परिणामों द्वारा परिभाषित स्वामित्व
कंपोनेंट्स द्वारा स्वामित्व असाइन करने की बजाय (वेब वेब का मालिक, बैकएंड बैकएंड का), स्वामित्व को परिणामों द्वारा परिभाषित करें: एक उपयोगकर्ता यात्रा या प्रोडक्ट लक्ष्य। एक टीम (या एक व्यक्ति) end‑to‑end अनुभव का मालिक हो, जिसमें सफलता मीट्रिक्स, एरर हैंडलिंग, और सपोर्ट रेडीनेस शामिल हों।
यह विशेषज्ञ भूमिकाएँ हटा नहींता—बल्कि जवाबदेही को स्पष्ट करता है। विशेषज्ञ अभी भी समीक्षा और मार्गदर्शन करते हैं, पर फीचर का मालिक सुनिश्चित करता है कि सारे हिस्से साथ शिप हों।
बेहतर टिकट: "किया हुआ" का सच क्या है
सीमाएँ धुँधली होने पर, टिकटों को तेज़ परिभाषाएँ चाहिए। मजबूत टिकट में शामिल हों:
- उपयोगकर्ता‑दृश्य के रूप में लिखे गए قبول्यता मानदंड
- एरर स्टेट्स (धीमे नेटवर्क, अमान्य इनपुट, आंशिक विफलताएँ पर क्या होता है)
- प्रदर्शन लक्ष्य (उदा., पेज लोड समय, API लेटेंसी, बैटरी प्रभाव)
- लॉगिंग/एनालिटिक्स अपेक्षाएँ (इवेंट्स, डैशबोर्ड, अलर्ट)
वेब, मोबाइल, बैकएंड के पार रिलीज़ और वर्जनिंग
क्रॉस‑लेयर काम सबसे ज़्यादा रिलीज़ समय पर फेल होता है। वर्ज़निंग और रिलीज़ चरणों को स्पष्ट रूप से संप्रेषित करें: कौन‑से बैकएंड बदलाव पहले deploy होने चाहिए, क्या API बैकवर्ड‑कम्पैटिबल है, और मोबाइल के लिए न्यूनतम वर्ज़न क्या है।
एक साधारण रिलीज़ चेकलिस्ट मदद करती है: फीचर फ्लैग योजना, रोलआउट क्रम, मॉनिटरिंग संकेत, और रोलबैक कदम—वेब, मोबाइल, और बैकएंड के बीच साझा ताकि प्रोडक्शन में कोई आश्चर्य न हो।
क्रॉस‑लेयर बदलावों के लिए टेस्टिंग और ऑब्ज़रवेबिलिटी
जब AI आपको UI, मोबाइल स्क्रीन, और बैकएंड एंडपॉइंट्स जोड़ने में मदद करता है, तो यह आसान होता है कुछ ऐसा शिप करना जो "तैयार" दिखता है पर सीमाओं में फेल हो जाता है।
तेज़ टीमें टेस्टिंग और ऑब्ज़रवेबिलिटी को एक ही सिस्टम मानती हैं: टेस्ट अनुमानित ब्रेकेज़ पकड़ते हैं; ऑब्ज़रवेबिलिटी अजीब ब्रेकेज़ की व्याख्या करती है।
AI "ग्लू" जेनरेट करते समय बग कहाँ छिपते हैं
AI एडाप्टर्स बनाने में अच्छा है—फील्ड मैप करना, JSON को reshape करना, डेट्स कन्वर्ट करना, कॉलबैक्स वायर करना। यही जगहें हैं जहाँ सूक्ष्म दोष रहते हैं:
- क्लाइंट में किसी फ़ील्ड का नाम बदला गया पर API पुराने नाम पर लौटता है
- Null/empty हैंडलिंग वेब और मोबाइल में अलग हो जाती है
- टाइमज़ोन, मुद्रा फॉर्मेटिंग, और राउंडिंग परतों के बीच अलग तरीके से व्यवहार करते हैं
- एरर स्टेट्स सुसंगत नहीं होते (उदा., मोबाइल को कोड चाहिए, बैकएंड संदेश भेजता है)
ये मुद्दे अक्सर यूनिट टेस्ट को बचाकर निकल जाते हैं क्योंकि हर परत अपने‑अपने टेस्ट पास कर लेती है जबकि इंटीग्रेशन में धीरे‑धीरे drift आ जाता है।
क्लाइंट और API के बीच कॉन्ट्रैक्ट टेस्ट जोड़ें
कॉन्ट्रैक्ट टेस्ट "हैंडशेक" टेस्ट हैं: वे सत्यापित करते हैं कि क्लाइंट और API अभी भी अनुरोध/प्रतिक्रिया शेप और मुख्य व्यवहार पर सहमत हैं।
इन्हें केंद्रित रखें:
- आवश्यक फ़ील्ड्स, प्रकार, और सामान्य एरर रिस्पांस वैध करें
- वर्ज़निंग नियमों को कवर करें (क्या बिना क्लाइंट तोड़े बदला जा सकता है)
- CI में हर बदलाव पर कॉन्ट्रैक्ट रन करवाएँ
यह विशेष रूप से महत्वपूर्ण है जब AI अस्पष्ट प्रॉम्प्ट के आधार पर एंडपॉइंट्स जेनरेट या refactor करता है।
महत्वपूर्ण यूज़र फ्लोज़ के लिए end‑to‑end टेस्ट्स उपयोग करें
कुछ राजस्व‑या‑ट्रस्ट‑महत्वपूर्ण फ्लोज़ चुनें (signup, checkout, password reset) और उन्हें वेब/मोबाइल + बैकएंड + डेटाबेस के पार end‑to‑end टेस्ट करें।
100% E2E कवरेज का लक्ष्य न रखें—उन जगहों पर उच्च आत्म‑विश्वास हासिल करें जहाँ विफलताएँ सबसे ज़्यादा नुक़सान पहुँचाती हैं।
फीचर के आधार पर ऑब्ज़रवेबिलिटी: लॉग्स, मेट्रिक्स, ट्रेसेस
जब सीमाएँ धुँधली हों, तब “कौन सी टीम इसका मालिक है” के आधार पर डिबग करना टूट जाता है। फीचर द्वारा इंस्ट्रूमेंट करें:
- लॉग्स संगत पहचानकर्ताओं के साथ (user/session/request/feature flag)
- मेट्रिक्स सफलता‑दर, लेटेंसी, और एरर‑रेट प्रति एंडपॉइंट और फ्लो के लिए
- ट्रेसेस जो एक यूज़र एक्शन को client → API → सेवाओं तक दिखाएँ
यदि आप मिनटों में जवाब दे सकें “क्या बदला, कौन प्रभावित है, और कहाँ फेल हो रहा है”, तो क्रॉस‑लेयर विकास तेज़ रहते हुए भी असंगत नहीं होगा।
ऐसी आर्किटेक्चर पैटर्न जो AI‑सहायता टीमों के साथ काम करती हैं
जल्दी BFF प्रोटोटाइप बनाएं
हैंडऑफ देरी के बिना UI-आधारित endpoints और मेल खाती क्लाइंट लॉजिक बनाएं।
AI टूल कई परतों में एक साथ बदलाव करना आसान बनाते हैं—यह गति के लिए अच्छा है और समन्वय के लिए जोखिम भी। बेहतर आर्किटेक्चर पैटर्न इसका विरोध नहीं करते; वे इसे स्पष्ट सीमाओं में चैनल करते हैं जहाँ मनुष्य सिस्टम के बारे में सोच सकते हैं।
API‑first बनाम schema‑first बनाम feature‑first
API‑first एंडपॉइंट्स और कॉन्ट्रैक्ट्स के साथ शुरू करता है, फिर क्लाइंट्स और सर्वर्स उन्हें लागू करते हैं। यह तब प्रभावी है जब आपके कई उपभोक्ता हों और आपको एक भविष्यवाणी योग्य एकीकरण चाहिए।
Schema‑first एक स्तर गहरा शुरू करता है: साझा schema (OpenAPI या GraphQL) में डेटा मॉडल और ऑपरेशन्स परिभाषित करें, फिर क्लाइंट्स, स्टब्स, और डॉक्स जेनरेट करें। यह अक्सर AI‑सहायता टीमों के लिए मध्यम मार्ग है क्योंकि schema एक स्रोत‑सत्य बन जाता है जिसे AI विश्वसनीय रूप से फ़ॉलो कर सकता है।
Feature‑first काम को उपयोगकर्ता नतीजों (जैसे “checkout” या “प्रोफ़ाइल संपादन”) द्वारा व्यवस्थित करता है और क्रॉस‑लेयर बदलावों को एक मालिकान सतह के पीछे बांधता है। यह उस तरीके से मेल खाता है जिस तरह AI प्रॉम्प्ट में सोचता है: फीचर अनुरोध स्वाभाविक रूप से UI, API, और डेटा को स्पैन करता है।
व्यवहारिक तरीका है feature‑first delivery और उसके नीचे schema‑first contracts।
साझा schemas क्रॉस‑टीम friction कम करते हैं
जब सब एक ही कॉन्ट्रैक्ट को लक्ष्य करते हैं, तो “यह फील्ड क्या मतलब रखता है?” की बहसें कम होती हैं। OpenAPI/GraphQL schemas से आप कर सकते हैं:
- वेब और मोबाइल के लिए टाइप्ड क्लाइंट जेनरेट करना
- अनुरोध/प्रतिक्रिया को ऑटोमैटिकली वैलिडेट करना
- बिना मैनुअल रिपीट के docs को सटीक रखना
कुंजी यह है कि schema को वर्ज़न्ड प्रोडक्ट सतह के रूप में ट्रीट करें, न कि एक बाद की बात के रूप में।
यदि आप एक primer चाहते हैं, तो हल्का और आंतरिक रखें: /blog/api-design-basics.
मॉड्यूल, डोमेन्स, और इंटरफेसेज़ के साथ सीमाएँ स्पष्ट रखें
धुंधली टीम लाइन्स का मतलब कोड का धुंधला होना नहीं होना चाहिए। स्पष्टता बनाए रखें:
- डोमेन मॉड्यूल: कोड को व्यवसाय क्षमता (Payments, Catalog) के आधार पर समूहित करें, न कि “फ्रंटेंड/बैकएंड” के अनुसार
- स्पष्ट इंटरफेसेज़: क्षमताओं को अच्छे नाम वाले सर्विस इंटरफेसेज़ और API कॉन्ट्रैक्ट्स के माध्यम से एक्सपोज़ करें
- डिपेंडेंसी दिशा: डोमेन्स UI विवरणों पर निर्भर न करें; UI डोमेन सर्विसेज़ पर निर्भर करें
यह AI‑जनरेटेड बदलावों को एक “बॉक्स” के भीतर रहने में मदद करता है, जिससे रिव्यू तेज और रेग्रेशन दुर्लभ होते हैं।
तेज़ चलें बिना कड़ा coupling बनाए
फीचर‑फर्स्ट काम को जटिल कोड में नहीं बदलने के लिए:
- composition को साझा ग्लोबल utilities पर प्राथमिकता दें
- UI‑आकृति APIs को किनारे (BFF या gateway) पर रखें, कोर डोमेन्स के अंदर नहीं
- contract tests लागू करें ताकि परतों के पार बदलाव जल्दी फेल हों
लक्ष्य सख्त पृथक्करण नहीं—बल्कि पूर्वानुमेय कनेक्शन‑पॉइंट हैं जिन्हें AI फॉलो कर सके और मनुष्य भरोसा कर सके।
गुणवत्ता खोए बिना अपनी टीम को कैसे अनुकूल करें
AI टीमों को तेज़ करने में मदद कर सकता है, पर गार्डरेल्स के बिना गति फिर से‑वर्क में बदल जाती है। लक्ष्य यह नहीं कि हर कोई “सब कुछ” कर सके, बल्कि यह है कि क्रॉस‑लेयर बदलाव सुरक्षि