03 अक्टू॰ 2025·8 मिनट
बाहरी बनाम आंतरिक डेटा — Pat Helland के ऐप सबक
Pat Helland के "बाहरी बनाम आंतरिक डेटा" सिद्धांत से सीखें कि स्पष्ट सीमाएँ कैसे तय करें, idempotent कॉल्स कैसे डिजाइन करें, और नेटवर्क फेल होते समय स्टेट को कैसे reconcile करें।
Pat Helland के "बाहरी बनाम आंतरिक डेटा" सिद्धांत से सीखें कि स्पष्ट सीमाएँ कैसे तय करें, idempotent कॉल्स कैसे डिजाइन करें, और नेटवर्क फेल होते समय स्टेट को कैसे reconcile करें।
जब आप एक ऐप बनाते हैं, तो आसानी से यह सोचना शुरू कर देते हैं कि अनुरोध व्यवस्थित रूप से, एक-एक कर, सही क्रम में पहुंचते हैं। असल नेटवर्क वैसा नहीं होता। यूज़र ने स्क्रीन फ्रीज़ होने पर "Pay" दो बार दबा दिया। मोबाइल कनेक्शन बटन दबाने के ठीक बाद कट गया। एक वेबहुक देर से आया, या दो बार आया। कभी-कभी वह बिल्कुल नहीं आता।
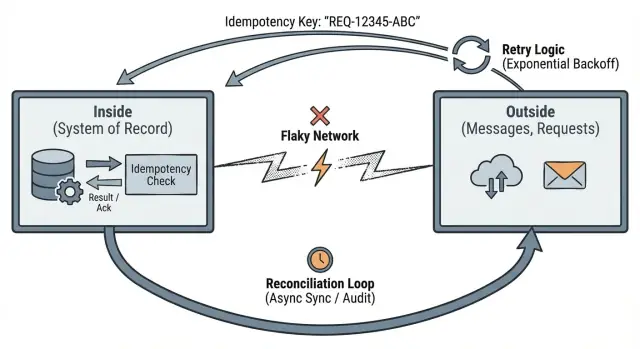
Pat Helland का विचार डेटा on the outside vs inside इस सभ्भर समस्या को सोचने का साफ़ तरीका देता है।
"बाहर" वह सब है जिसे आपका सिस्टम नियंत्रित नहीं करता। यह वह जगह है जहाँ आप अन्य लोगों और सिस्टम्स से बात करते हैं, और जहाँ डिलीवरी अनिश्चित होती है: ब्राउज़र और मोबाइल ऐप से HTTP अनुरोध, कतारों से संदेश, थर्ड‑पार्टी वेबहुक्स (पेमेंट, ईमेल, शिपिंग), और क्लाइंट, प्रॉक्सी, या बैकग्राउंड जॉब्स द्वारा ट्रिगर किए गए retries।
बाहर पर मानें कि संदेश देर से आ सकते हैं, डुप्लिकेट हो सकते हैं, या गलत क्रम में आ सकते हैं। भले ही कुछ "आम तौर पर विश्वसनीय" दिखे, उस दिन के लिए डिजाइन करें जब वह भरोसेमंद न रहे।
"अंदर" वह है जिसे आपका सिस्टम भरोसेमंद बना सकता है। यह वह टिकाऊ स्टेट है जिसे आप स्टोर करते हैं, वे नियम जो आप लागू करते हैं, और वे तथ्य जिन्हें आप बाद में साबित कर सकते हैं:
अंदर वह जगह है जहाँ आप इनवरिएंट्स की रक्षा करते हैं। अगर आप "प्रति ऑर्डर एक भुगतान" का वादा करते हैं, तो वह वादा अंदर लागू होना चाहिए, क्योंकि बाहर पर भरोसा नहीं किया जा सकता।
मनस्थितिपरिवर्तन सरल है: परफेक्ट डिलीवरी या परफेक्ट टाइमिंग मानकर मत चलिए। हर बाहरी इंटरैक्शन को एक अविश्वसनीय सुझाव की तरह ट्रीट करें जो दोहराया जा सकता है, और अंदर को सुरक्षित रूप से प्रतिक्रिया देने के काबिल बनाइये।
यह छोटे टीमों और सरल ऐप्स के लिए भी मायने रखता है। पहला नेटवर्क गड़बड़ जो डुप्लिकेट चार्ज या अटका हुआ ऑर्डर बनाता है, वह सैद्धांतिक से निकलकर रिफंड, सपोर्ट टिकट और भरोसे का नुकसान बन जाता है।
एक ठोस उदाहरण: एक यूज़र "Place order" दबाता है, ऐप एक अनुरोध भेजता है, और कनेक्शन कट जाता है। यूज़र फिर से कोशिश करता है। अगर आपके अंदर यह पहचानने का तरीका नहीं है कि "यह वही कोशिश है", तो आप दो ऑर्डर बना सकते हैं, इन्वेंटरी दो बार रिज़र्व कर सकते हैं, या दो कन्फर्मेशन्स ईमेल कर सकते हैं।
Helland का बिंदु सीधा है: बाहरी दुनिया अनिश्चित है, लेकिन आपके सिस्टम के अंदर चीज़ें सुसंगत रहनी चाहिए। नेटवर्क पैकेट्स खो देता है, फ़ोन सिग्नल खो देते हैं, क्लॉक्स drift करते हैं, और यूज़र्स refresh दबाते हैं। आपका ऐप इन चीज़ों को कंट्रोल नहीं कर सकता। जो वह नियंत्रित कर सकता है वह है कि जब डेटा एक साफ़ बॉर्डर पार कर जाए तो आप उसे "सत्य" के रूप में क्या स्वीकार करते हैं।
किसी को मोबाइल से कॉफ़ी ऑर्डर करते हुए कल्पना कीजिए जब बिल्डिंग में Wi‑Fi खराब है। वे "Pay" दबाते हैं। स्पिनर चलता है। नेटवर्क कट जाता है। वे फिर से दबाते हैं।
शायद पहला अनुरोध आपके सर्वर तक पहुँचा, पर रिस्पॉन्स वापस नहीं आया। या शायद कोई भी अनुरोध नहीं पहुँचा। यूज़र की नज़रों में दोनों संभावनाएँ एक जैसी दिखती हैं।
यही समय और अनिश्चितता है: आप अभी तक नहीं जानते कि क्या हुआ, और बाद में आपको पता चल सकता है। आपका सिस्टम इंतज़ार के दौरान समझदारी से व्यव्हार करना चाहिए।
एक बार आप यह स्वीकार कर लेते हैं कि बाहर अविश्वसनीय है, तो कुछ "अजीब" व्यवहार सामान्य दिखने लगते हैं:
बाहरी डेटा एक दावा है, तथ्य नहीं। "मैंने भुगतान किया" एक बयान है जो एक अविश्वसनीय चैनल के ऊपर भेजा गया। वह तथ्य तब बनता है जब आप उसे अंदर अपनी प्रणाली में टिकाऊ, सुसंगत तरीके से रिकॉर्ड कर लेते हैं।
यह आपको तीन व्यावहारिक आदतों की ओर ले जाता है: स्पष्ट सीमाएँ परिभाषित करें, retries को idempotency से सुरक्षित बनाएं, और जब वास्तविकता मेल न खाए तो reconciliation की योजना बनाएं।
"बाहर बनाम अंदर" विचार एक व्यावहारिक प्रश्न से शुरू होता है: आपकी सिस्टम की सच्चाई कहाँ से शुरू और कहाँ खत्म होती है?
बॉर्डर के अंदर आप मजबूत गारंटी दे सकते हैं क्योंकि आप डेटा और नियमों को नियंत्रित करते हैं। बॉर्डर के बाहर आप सर्वश्रेष्ठ‑प्रयास करते हैं और मानते हैं कि संदेश खो सकते हैं, डुप्लिकेट हो सकते हैं, देर से आ सकते हैं, या गलत क्रम में पहुँच सकते हैं।
वास्तविक ऐप्स में यह बॉर्डर अक्सर इन जगहों पर दिखता है:
एक बार यह रेखा खींचने के बाद, तय करें कि किन इनवरिएंट्स को अंदर गैर-परक्राम्य (non-negotiable) माना जाएगा। उदाहरण:
बॉर्डर को यह भी स्पष्ट भाषा चाहिए कि "हम कहाँ हैं"। बहुत सी विफलताएँ "हमने आपको सुना" और "हमने इसे पूरा कर लिया" के बीच के गैप में रहती हैं। एक सहायक पैटर्न तीन अर्थ अलग करने का है:
जब टीमें इसे स्किप कर देती हैं, तो वे ऐसे बग बनाते हैं जो केवल लोड के दौरान या आंशिक आउटेज के समय होते हैं। एक सिस्टम "paid" का अर्थ पैमेंट कैप्चर समझता है; दूसरा इसे पेमेंट प्रयास शुरू होने के रूप में लेता है। वह mismatch डुप्लिकेट, अटके ऑर्डर और सपोर्ट टिकट बनाता है जिन्हें कोई दोहरा नहीं पाता।
Idempotency का मतलब है: अगर वही अनुरोध दो बार भेजा गया तो सिस्टम उसे एक ही अनुरोध के रूप में ट्रीट करे और वही आउटकम लौटाए।
Retries सामान्य हैं। टाइमआउट होते हैं। क्लाइंट खुद को रिपीट करते हैं। अगर बाहर बार‑बार कर सकता है, तो अंदर को उसे स्थिर स्टेट परिवर्तन में बदलना होगा।
एक सरल उदाहरण: एक मोबाइल ऐप "pay $20" भेजता है और कनेक्शन कट जाता है। ऐप फिर retry करता है। बिना idempotency के ग्राहक से दो बार चार्ज हो सकता है। idempotency के साथ, दूसरा अनुरोध पहले चार्ज का ही परिणाम लौटाता है।
अधिकांश टीमें इनमें से एक पैटर्न का उपयोग करती हैं (कभी-कभी मिश्रित):
Idempotency-Key: ...)। सर्वर उस की और अंतिम रिस्पॉन्स को रिकॉर्ड करता है।जब एक डुप्लिकेट आता है, तो सबसे अच्छा व्यवहार आम तौर पर "409 conflict" या एक सामान्य एरर नहीं होता। यह वही परिणाम लौटाना है जो आपने पहली बार लौटाया था, उसी रीसोर्स ID और स्टेटस सहित। वही क्लाइंट और बैकग्राउंड जॉब्स के लिए retries को सुरक्षित बनाता है।
Idempotency रिकॉर्ड आपकी बॉर्डर के अंदर टिकाऊ स्टोरेज में होना चाहिए, मेमोरी में नहीं। अगर आपकी API रिस्टार्ट है और भूल जाती है, तो सुरक्षा गारंटी चली जाएगी।
रिकॉर्ड को उतना समय रखें जितना रीअलिस्टिक retries और देर से डिलीवरी कवर करें। विंडो बिज़नेस रिस्क पर निर्भर है: कम‑जोखिम वाले create के लिए मिनट से घंटे, पेमेंट/ईमेल/शिपमेंट जैसे महंगे मामलों के लिए दिन, और अगर पार्टनर विस्तारित अवधि के लिए retry कर सकते हैं तो और लंबा।
डिस्ट्रिब्यूटेड ट्रांज़ैक्शन सुखदायक लगते हैं: सर्विसेज़, कतारों और डेटाबेस में एक बड़ा कमिट। व्यवहार में वे अक्सर अप्राप्य, धीमे, या बहुत नाजुक होते हैं। एक बार नेटवर्क हॉप शामिल हुआ, आप यह नहीं मान सकते कि सब कुछ साथ में कमिट होगा।
एक आम जाल वह workflow बनाना है जो तभी काम करे जब हर स्टेप अभी सफल हो: save order, charge card, reserve inventory, send confirmation। अगर स्टेप 3 टाइमआउट हो जाए, तो क्या वह फेल हुआ या सफल? यदि आप retry करते हैं, तो क्या आप डबल‑चार्ज या डबल‑रिज़र्व कर देंगे?
दो व्यावहारिक दृष्टिकोण इससे बचते हैं:
प्रति workflow एक स्टाइल चुनें और उसी के साथ बने रहें। कभी‑कभी "हम आउटबॉक्स करते हैं" और कभी‑कभी "हम synchronous सफलता मानते हैं" मिलाने से ऐसे एज‑केस बनते हैं जिन्हें टेस्ट करना मुश्किल होता है।
एक सरल नियम मददगार है: अगर आप सीमाओं के पार एटॉमिक कमिट नहीं कर सकते, तो retries, duplicates, और delays के लिए डिजाइन करें।
Reconciliation एक बुनियादी सत्य स्वीकारना है: जब आपका ऐप नेटवर्क के ऊपर अन्य सिस्टम्स से बात करता है, तो कभी‑कभी आप यह टाल नहीं पाएंगे कि क्या हुआ इस पर असहमति हो जाएगी। अनुरोध टाइमआउट होते हैं, callback देर से आते हैं, और लोग क्रियाओं को फिर से करते हैं। Reconciliation वह तरीका है जिससे आप mismatches का पता लगाते हैं और उन्हें समय के साथ ठीक करते हैं।
बाहरी सिस्टम्स को स्वतंत्र सत्य के स्रोत के रूप में ट्रीट करें। आपका ऐप अपनी आंतरिक रिकॉर्ड रखता है, पर उसे यह तुलना करने का तरीका चाहिए कि साझेदारों, प्रोवाइडरों और उपयोगकर्ताओं ने वास्तव में क्या किया।
अधिकांश टीमें कुछ नीरस उपकरणों का उपयोग करती हैं (नीरस अच्छा है): एक वर्कर जो pending क्रियाओं को फिर से कोशिश करता और बाहरी स्थिति फिर से जांचता है, असंगतियों के लिए शेड्यूल्ड स्कैन, और सपोर्ट के लिए एक छोटा एडमिन रिपेयर एक्शन ताकि retry, cancel, या mark as reviewed किया जा सके।
रिकंसाइलेशन तभी काम करती है जब आप जानते हों कि क्या तुलना करनी है: आंतरिक लेजर बनाम प्रोवाइडर लेजर (payments), ऑर्डर स्टेट बनाम शिपमेंट स्टेट (fulfillment), सब्सक्रिप्शन स्टेट बनाम बिलिंग स्टेट।
स्टेट्स को मरम्मत‑योग्य बनाएं। सीधे "created" से "completed" पर न कूदें, होल्डिंग स्टेट्स जैसे pending, on hold, या needs review का उपयोग करें। इससे यह कहना सुरक्षित होता है "हमें अभी यकीन नहीं है", और reconciliation के लिए एक स्पष्ट जगह मिलती है।
महत्वपूर्ण परिवर्तनों पर एक छोटा ऑडिट ट्रेल कैप्चर करें:
उदाहरण: अगर आपका ऐप शिपमेंट लेबल माँगता है और नेटवर्क कट जाता है, तो आंतरिक रूप से आपके पास "no label" रह सकता है जबकि कैरियर ने वास्तव में एक बना दिया हो। एक recon वर्कर correlation ID से खोज कर सकता है, लेबल मौजूद पाए और ऑर्डर को आगे बढ़ा सकता है (या यदि विवरण मेल नहीं खाते तो रिव्यू के लिए मार्क कर सकता है)।
एक बार आप स्वीकार कर लें कि नेटवर्क फेल होगा, लक्ष्य बदल जाता है। आप हर स्टेप को एक ही बार में सफल बनाने की कोशिश नहीं कर रहे; आप हर स्टेप को फिर से चलाने के लिए सुरक्षित और मरम्मत करने में आसान बनाना चाहते हैं।
एक वाक्य की बॉर्डर स्टेटमेंट लिखें। स्पष्ट हों कि आपका सिस्टम क्या मालिक है (source of truth), क्या वह नकल करता है, और क्या वह केवल दूसरों से मांगता है।
हैप्पी पाथ से पहले विफलता मोड सूचीबद्ध करें। कम से कम: टाइमआउट (आप नहीं जानते कि यह काम कर गया), डुप्लिकेट अनुरोध, आंशिक सफलता (एक स्टेप हुआ, अगला नहीं हुआ), और आउट‑ऑफ‑ऑर्डर इवेंट्स।
प्रत्येक इनपुट के लिए एक idempotency रणनीति चुनें। सिंक्रोनस APIs के लिए यह अक्सर idempotency key और स्टोर किए गए परिणाम होते हैं। संदेशों/इवेंट्स के लिए यह आम तौर पर एक यूनिक मैसेज ID और "क्या मैंने इसे प्रोसेस किया?" रिकॉर्ड होता है।
इरादा (intent) को पर्सिस्ट करें, फिर कार्य करें। पहले कुछ टिकाऊ स्टोर करें जैसे "PaymentAttempt: pending" या "ShipmentRequest: queued", फिर बाहरी कॉल करें, फिर परिणाम स्टोर करें। एक स्थिर संदर्भ ID लौटाएँ ताकि retries उसी intent की ओर इशारा करें न कि नया बनाने के लिए।
reconciliation और एक मरम्मत पथ बनाएं, और उन्हें दिखाई देने योग्य बनाएं। Reconciliation एक जॉब हो सकती है जो "बहुत देर से pending" रिकॉर्ड्स को स्कैन कर बाहरी सिस्टम्स को फिर से चेक करे। मरम्मत पथ एक सुरक्षित एडमिन एक्शन हो सकता है जैसे "retry", "cancel", या "mark resolved", साथ में एक ऑडिट नोट। मूलभूत ऑब्ज़रवबिलिटी जोड़ें: correlation IDs, स्पष्ट स्टेट फ़ील्ड्स, और कुछ काउंट्स (pending, retries, failures)।
उदाहरण: यदि चेकआउट का टाइमआउट ठीक उसी समय हुआ जब आप पेमेंट प्रोवाइडर को कॉल कर रहे थे, तो अनुमान न लगाएँ। प्रयास स्टोर करें, attempt ID लौटाएँ, और उपयोगकर्ता को उसी idempotency key के साथ retry करने दें। बाद में reconciliation पुष्टि कर सकती है कि प्रोवाइडर ने चार्ज किया या नहीं और प्रयास को डबल‑चार्ज किए बिना अपडेट कर सकती है।
एक ग्राहक "Place order" दबाता है। आपकी सेवा प्रोवाइडर को पेमेंट अनुरोध भेजती है, पर नेटवर्क फ़्लैकी है। प्रोवाइडर की अपनी सच्चाई है, और आपकी डेटाबेस की भी। वे तब तक ड्रीफ्ट करेंगे जब तक आप डिज़ाइन करके उन्हें सिंक नहीं रखते।
आपकी नज़र में बाहर संदेशों का एक स्ट्रीम है जो देर से, दोहराया हुआ, या अनुपस्थित हो सकता है:
इनमें से किसी भी स्टेप की गारंटी "एक बार बिल्कुल" नहीं होती। वे केवल "शायद" की गारंटी देते हैं।
अपनी बॉर्डर के अंदर टिकाऊ तथ्य और बाहरी इवेंट्स को उन तथ्यों से जोड़ने के लिए न्यूनतम जानकारी स्टोर करें।
जब ग्राहक पहली बार ऑर्डर करता है, तो order रिकॉर्ड एक स्पष्ट स्टेट जैसे pending_payment में बनाइए। साथ ही एक payment_attempt रिकॉर्ड बनाइए जिसमें एक यूनिक प्रोवाइडर संदर्भ और ग्राहक क्रिया से जुड़ा idempotency_key हो।
अगर क्लाइंट टाइमआउट और फिर retry करता है, तो आपकी API को दूसरा ऑर्डर नहीं बनाना चाहिए। उसे idempotency_key देख कर वही order_id और वर्तमान स्टेट लौटाना चाहिए। यही एक चुनाव नेटवर्क फेलियर्स पर डुप्लिकेट से बचाता है।
अब वेबहुक दो बार आता है। पहला callback payment_attempt को authorized पर अपडेट करता है और ऑर्डर को paid में ले जाता है। दूसरा callback वही हैंडलर हिट करता है, पर आप पहचान लेते हैं कि आपने उस प्रोवाइडर इवेंट को पहले ही प्रोसेस कर लिया था (प्रोवाइडर इवेंट ID स्टोर करके, या वर्तमान स्टेट चेक करके) और कुछ नहीं करते। आप फिर भी 200 OK लौट सकते हैं, क्योंकि परिणाम पहले से ही सच है।
अंत में, reconcilation गंदे मामलों को हैंडल करती है। अगर किसी विलंब के बाद ऑर्डर अभी भी pending_payment है, तो एक बैकग्राउंड जॉब स्टोर किए गए संदर्भ का उपयोग करते हुए प्रोवाइडर से क्वेरी करता है। अगर प्रोवाइडर कहता है "authorized" पर आपने वेबहुक मिस कर दिया था, तो आप अपने रिकॉर्ड अपडेट कर देंगे। अगर प्रोवाइडर कहता है "failed" पर आपने उसे paid मार्क कर दिया था, तो आप उसे review के लिए flag कर सकते हैं या compensating action जैसे refund ट्रिगर कर सकते हैं।
अधिकांश डुप्लिकेट रिकॉर्ड और "अटके" वर्कफ़्लो इस बात से आते हैं कि आप बाहर हुई घटनाओं (एक अनुरोध आया, एक संदेश मिला) को उस चीज़ के साथ मिला देते हैं जो आपने अंदर टिकाऊ रूप से कमिट किया है।
एक क्लासिक विफलता: क्लाइंट "place order" भेजता है, आपका सर्वर काम शुरू करता है, नेटवर्क कट जाता है, और क्लाइंट फिर से कोशिश करता है। अगर आप प्रत्येक retry को पूरी तरह नया सत्य मानते हैं, तो आपको डबल चार्ज, डुप्लिकेट ऑर्डर, या कई ईमेल मिलेंगे।
आम कारण:
एक मुद्दा सब कुछ और खराब कर देता है: कोई ऑडिट ट्रेल नहीं। अगर आप फ़ील्ड ओवरराइट करते हैं और केवल नवीनतम स्टेट रखते हैं, तो आप वह सबूत खो देते हैं जिसकी आपको बाद में reconciliation के लिए जरूरत है।
एक अच्छा सैनीटी चेक है: "अगर मैं इस हैंडलर को दो बार चलाऊँ, क्या मुझे वही परिणाम मिलता है?" अगर उत्तर नहीं है, तो डुप्लिकेट एक दुर्लभ एज‑केस नहीं; यह गारंटीकृत समस्या है।
अगर आप एक चीज़ याद रखें: आपका ऐप तब भी सही रहना चाहिए जब संदेश देर से आएँ, दो बार आएँ, या बिल्कुल न आएँ।
इस चेकलिस्ट का उपयोग कमजोर बिंदुओं का पता लगाने के लिए करें इससे पहले कि वे डुप्लिकेट रिकॉर्ड, गायब अपडेट, या अटके वर्कफ़्लो बन जाएँ:
अगर आप इनमें से किसी का तुरंत जवाब नहीं दे सकते, तो यह अक्सर बताता है कि कोई बॉर्डर धुंधला है या कोई स्टेट ट्रांज़िशन गायब है।
प्रायोगिक अगले कदम:
पहले बॉर्डर और स्टेट्स का स्केच बनाएं। प्रत्येक वर्कफ़्लो के लिए एक छोटा स्टेट सेट परिभाषित करें (उदाहरण: Created, PaymentPending, Paid, FulfillmentPending, Completed, Failed)।
सबसे अधिक जोखिम वाले लिखावों पर idempotency जोड़ें। सबसे पहले high-risk writes: create order, capture payment, issue refund। PostgreSQL में idempotency कीज़ को unique constraint के साथ स्टोर करना एक सुरक्षित शुरुआत है।
reconciliation को एक सामान्य फीचर मानें। एक जॉब शेड्यूल करें जो "बहुत देर से pending" रिकॉर्ड्स को खोजे, बाहरी सिस्टम्स को फिर से चेक करे, और लोकल स्टेट की मरम्मत करे।
सुरक्षित रूप से iterate करें। ट्रांज़िशन और retry नियम समायोजित करें, फिर उसी अनुरोध को जानबूझकर दोबारा भेजकर और उसी इवेंट को फिर से प्रोसेस करके टेस्ट करें।
यदि आप जल्दी बना रहे हैं किसी चैट‑ड्रिवन प्लेटफ़ॉर्म जैसे Koder.ai (koder.ai) पर, तब भी इन नियमों को अपने जनरेट किए हुए सर्विसेज़ में शुरुआत में शामिल करना उपयोगी है: गति ऑटोमेशन से आती है, पर विश्वसनीयता स्पष्ट सीमाओं, idempotent हैंडलर्स, और reconciliation से आती है।
"Outside" वह सब कुछ है जो आपका सिस्टम नियंत्रित नहीं करता: ब्राउज़र, मोबाइल नेटवर्क, कतारें, थर्ड‑पार्टी वेबहुक्स, retries और टाइमआउट। मानकर चलें कि संदेश देर से आ सकते हैं, डुप्लिकेट हो सकते हैं, खो सकते हैं, या गलत क्रम में आ सकते हैं。
"Inside" वह है जो आप नियंत्रण में रखते हैं: आपका संग्रहीत स्टेट, आपके नियम, और वे तथ्य जिन्हें आप बाद में प्रमाणित कर सकते हैं (आम तौर पर आपकी डेटाबेस में)।
क्योंकि नेटवर्क आपको सच नहीं बताता।
क्लाइंट का टाइमआउट यह नहीं दर्शाता कि सर्वर ने अनुरोध प्रोसेस किया या नहीं। एक वेबहुक दो बार आना यह नहीं दर्शाता कि प्रोवाइडर ने क्रिया दो बार की। अगर आप हर संदेश को "नया सत्य" मानते हैं, तो आप डुप्लिकेट ऑर्डर, डबल चार्ज और अटके वर्कफ़्लो बना देंगे।
एक स्पष्ट बॉन्ड्री वह बिंदु है जहाँ एक अविश्वसनीय संदेश एक टिकाऊ तथ्य बन जाता है।
आम बॉन्ड्री के उदाहरण:
एक बार डेटा बॉर्डर पार कर जाए, आप अंदर इनवरिएंट्स लागू करते हैं (जैसे "ऑर्डर केवल एक बार भुगतान हो सकता है").
इडेम्पोटेंसी का मतलब: अगर वही अनुरोध दो बार भेजा गया तो सिस्टम उसे एक ही अनुरोध की तरह ट्रीट करे और वही परिणाम लौटाए।
व्यावहारिक पैटर्न:
इसे केवल मेमोरी में न रखें। अपनी बॉर्डर के अंदर स्टोर करें (उदाहरण: PostgreSQL) ताकि सर्विस रेस्टार्ट पर सुरक्षा न भुल जाए।
रिटेंशन का नियम:
इसे इतना रखें कि वास्तविक retries और देरी के दौरान कवर हो सके।
अनिश्चितता स्वीकार करने वाले स्टेट्स का प्रयोग करें।
साधारण सेट:
pending_* (हमने intent स्वीकार कर लिया है पर परिणाम नहीं जानते)succeeded / failed (हमने अंतिम परिणाम रिकॉर्ड कर लिया)needs_review (मismatch मिला है और मानव या विशेष जॉब की जरूरत है)यह टाइमआउट के दौरान अनुमान लगाने से रोकता है और reconciliation आसान बनाता है।
क्योंकि आप नेटवर्क के पार कई सिस्टमों में एक साथ एटॉमिक कमिट नहीं कर सकते।
यदि आप "save order → charge card → reserve inventory" को सिंक्रोनसली करते हैं और किसी स्टेप का टाइमआउट हो जाता है तो यह स्पष्ट नहीं रहेगा कि वह स्टेप सफल हुआ या नहीं। रिट्राई करने पर डुप्लिकेट हो सकते हैं; न करने पर कार्य अधूरा रह सकता है।
आउटबॉक्स/इनबॉक्स या सागा-शैली compensation चुनें; दोनों ही partial success के लिए डिजाइन हैं।
आउटबॉक्स/इनबॉक्स पैटर्न नेटवर्क की अशुद्धियों का नाटक किए बिना क्रॉस-सिस्टम मैसेजिंग को विश्वसनीय बनाता है।
रिकंसाइलेशन यह मानकर चलता है कि आपके और किसी बाहरी सिस्टम के बीच कभी-कभी असहमति होगी।
अच्छे डिफ़ॉल्ट्स:
needs_review मार्क करनायह भुगतान, fulfillment, सब्सक्रिप्शन या किसी भी वेबहुक वाले काम के लिए अनिवार्य है।
हाँ। तेज़ी से बनाना नेटवर्क फेलियर को नहीं हटाता—यह आपको बस जल्दी उस समस्या तक पहुँचा देता है।
यदि आप Koder.ai से सर्विस जनरेट कर रहे हैं, तो इन डिफ़ॉल्ट्स को शुरू में शामिल करें:
इस तरह retries और डुप्लिकेट कॉलबैक महंगे नहीं बल्कि सामान्य बन जाते हैं।