24 अग॰ 2025·8 मिनट
बहु-कदम उपयोगकर्ता ऑनबोर्डिंग के लिए वेब ऐप कैसे बनाएँ
जानें कि कैसे एक वेब ऐप डिज़ाइन और बनाएं जो बहु-कदम उपयोगकर्ता ऑनबोर्डिंग फ्लोज़ बनाता, ट्रैक करता और सुधारता है—स्पष्ट स्टेप्स, डेटा मॉडल और टेस्टिंग के साथ।
जानें कि कैसे एक वेब ऐप डिज़ाइन और बनाएं जो बहु-कदम उपयोगकर्ता ऑनबोर्डिंग फ्लोज़ बनाता, ट्रैक करता और सुधारता है—स्पष्ट स्टेप्स, डेटा मॉडल और टेस्टिंग के साथ।
एक बहु-कदम ऑनबोर्डिंग फ्लो स्क्रीन के एक निर्देशित अनुक्रम की तरह होता है जो नए उपयोगकर्ता को “साइन्ड अप” से लेकर “प्रोडक्ट इस्तेमाल करने लायक” स्थिति तक ले जाता है। सब कुछ एक बार में मांगने के बजाय, आप सेटअप को छोटे-छोटे कदमों में बाँटते हैं जिन्हें एक बार में या समय के साथ पूरा किया जा सकता है।
जब सेटअप एक सिंगल फ़ॉर्म से अधिक हो—खासकर जब उसमें विकल्प, पूर्वशर्तें, या अनुपालन जांच शामिल हों—तब आपको बहु-कदम ऑनबोर्डिंग की ज़रूरत होती है। यदि आपका प्रोडक्ट संदर्भ माँगता है (उद्योग, भूमिका, प्राथमिकताएँ), या सत्यापन (ईमेल/फोन/पहचान), या आरम्भिक कॉन्फ़िगरेशन (वर्कस्पेस, बिलिंग, इंटीग्रेशन), तो स्टेप-आधारित फ्लो चीज़ों को समझने लायक बनाए रखता है और त्रुटियाँ कम करता है।
बहु-कदम ऑनबोर्डिंग हर जगह है क्योंकि यह उन कार्यों का समर्थन करता है जो स्वाभाविक रूप से चरणों में होते हैं, जैसे:
एक अच्छा ऑनबोर्डिंग फ्लो सिर्फ़ “स्क्रीन पूरे होने” के बारे में नहीं है; यह उपयोगकर्ताओं को जल्दी से मूल्य तक पहुँचाने के बारे में है। सफलता को ऐसे मापें जो आपके प्रोडक्ट से मेल खाते हों:
फ्लो को resume और continuity भी सपोर्ट करनी चाहिए: उपयोगकर्ता बीच में छोड़कर लौट सकते हैं बिना प्रगति खोए, और उन्हें अगले लॉजिक-आधारित कदम पर लैंड होना चाहिए।
बहु-कदम ऑनबोर्डिंग किसी-न-किसी तरह से असफल हो जाती है:
आपका लक्ष्य ऑनबोर्डिंग को एक मार्गदर्शित रास्ता बनाना है, परीक्षा नहीं: हर कदम का स्पष्ट उद्देश्य, विश्वसनीय प्रगति ट्रैकिंग, और उपयोगकर्ता के छोड़े स्थान पर आसानी से वापस आने का तरीका।
स्क्रीन ड्रॉ करने या कोड लिखने से पहले तय करें कि आपका ऑनबोर्डिंग क्या हासिल करने की कोशिश कर रहा है—और किसके लिए। एक बहु-कदम फ्लो तब ही “अच्छा” होता है जब यह सही लोगों को सही एंड-स्टेट तक कम से कम भ्रम के साथ reliably पहुँचाए।
अलग उपयोगकर्ता अलग संदर्भ, अनुमति और तात्कालिकता के साथ आते हैं। शुरुआत में अपने प्रमुख एंट्री पर्सोनास का नाम दें और उनके बारे में जो पहले से पता है वह लिखें:
प्रत्येक प्रकार के लिए प्रतिबंधों (उदा., “कंपनी नाम संपादित नहीं कर सकता”), आवश्यक डेटा (उदा., “वर्कस्पेस चुनना ज़रूरी है”) और संभावित शॉर्टकट (उदा., “SSO के जरिए पहले से सत्यापित”) की सूची बनाएं।
आपका ऑनबोर्डिंग एंड-स्टेट स्पष्ट और मापनीय होना चाहिए। “डन” सिर्फ़ “सभी स्क्रीन पूरे किए” नहीं है; यह एक बिज़नेस-रेडी स्थिति होनी चाहिए, जैसे:
कम्प्लीशन क्राइटेरिया को बैकएंड के लिए चेक करने लायक चेकलिस्ट के रूप में लिखें, न कि अस्पष्ट लक्ष्यों के रूप में।
निर्धारित करें कि कौन से कदम अनिवार्य हैं और कौन से वैकल्पिक हैं। फिर निर्भरताएँ डॉक्यूमेंट करें (“टीम को इनवाइट नहीं कर सकते जब तक वर्कस्पेस मौजूद नहीं है”)।
अंत में, स्किप नियमों को स्पष्ट रूप से परिभाषित करें: कौन से स्टेप्स किस उपयोगकर्ता प्रकार द्वारा किस शर्तों में स्किप किए जा सकते हैं (उदा., “यदि SSO से ऑथेंटिकेटेड → ईमेल सत्यापन स्किप करें”) और क्या स्किप किए गए स्टेप्स बाद में सेटिंग्स में फिर से किए जा सकते हैं।
स्क्रीन या API बनानें से पहले ऑनबोर्डिंग को एक फ्लो मैप के रूप में ड्रॉ करें: एक छोटा डायग्राम जो हर स्टेप, अगला कदम कहाँ जा सकता है, और बाद में कैसे लौट सकते हैं दिखाता है।
स्टेप्स को छोटे, क्रिया-केंद्रित नाम दें (नियमित रूप से क्रियाएँ सहायक होती हैं): “Create password,” “Confirm email,” “Add company details,” “Invite teammates,” “Connect billing,” “Finish.” पहले पास को सरल रखें, फिर आवश्यक फ़ील्ड और निर्भरताएँ जोड़ें (उदा., बिलिंग प्लान चयन से पहले नहीं हो सकती)।
एक उपयोगी जाँच: हर स्टेप एक प्रश्न का जवाब दे—या “आप कौन हैं?” “आपको क्या चाहिए?” या “प्रोडक्ट कैसे कॉन्फ़िगर होना चाहिए?” अगर एक स्टेप तीनों करने की कोशिश करता है तो उसे बाँट दें।
अधिकांश प्रोडक्ट्स को एक अधिकांशतः लीनियर बैकबोन से लाभ होता है और केवल तब कंडीशनल ब्रांच रखें जब अनुभव सच में अलग हो। सामान्य ब्रांच नियम:
इनको मैप पर “if/then” नोट्स के रूप में डॉक्यूमेंट करें (उदा., “If region = EU → show VAT step”)। यह फ्लो को समझने योग्य रखता है और भूल-भुलैया बनने से बचाता है।
हर जगह की सूची बनाएं जहाँ से उपयोगकर्ता फ्लो में प्रवेश कर सकता है:
/settings/onboarding)हर एंट्री को उपयोगकर्ता को सही अगले स्टेप पर लाना चाहिए, हमेशा स्टेप एक पर नहीं।
मान लें कि उपयोगकर्ता आधे में छोड़ देंगे। तय करें कि वापस आने पर क्या होगा:
आपका मैप एक स्पष्ट “रिज़्यूम” पथ दिखाना चाहिए ताकि अनुभव नाज़ुक न लगे।
अच्छा ऑनबोर्डिंग मार्गदर्शित रास्ता जैसा महसूस होता है, परीक्षा जैसा नहीं। लक्ष्य है निर्णय थकान को कम करना, उम्मीदों को स्पष्ट करना, और जब कुछ गलत हो तो उपयोगकर्ताओं की तेज़ी से मदद करना।
एक विजार्ड तब अच्छा है जब स्टेप्स का क्रम जरूरी हो (उदा., पहचान → बिलिंग → अनुमति)। एक चेकलिस्ट उन ऑनबोर्डिंग के लिए मुफ़ीद है जिन्हें किसी भी क्रम में किया जा सकता है (उदा., “लोगो जोड़ें,” “टीम को इनवाइट करें,” “कैलेंडर कनेक्ट करें”)। गाइडेड टास्क्स (प्रोडक्ट के अंदर एम्बेडेड टिप्स और कॉलआउट) तब अच्छे हैं जब सीखना करने के दौरान होना चाहिए, न कि फ़ॉर्म भरते हुए।
अगर आप अनिश्चित हैं, तो चेकलिस्ट + हर टास्क के लिए डीप लिंक से शुरू करें, फिर केवल आवश्यक स्टेप्स को गेट करें।
प्रोग्रेस फ़ीडबैक से यह जवाब मिलना चाहिए: “और कितना बचा है?” चुनें:
लंबे फ्लो के लिए “Save and finish later” भी जोड़ें।
साधारण लेबल इस्तेमाल करें (“Business name,” न कि “Entity identifier”)। माइक्रोकॉपी जोड़ें जो बताये कि आप क्यों पूछ रहे हैं (“We use this to personalize invoices”)। जहाँ संभव हो, मौजूदा डेटा से प्रीफिल करें और सुरक्षित डिफ़ॉल्ट चुनें।
त्रुटियों को एक आगे का रास्ता बनाकर डिजाइन करें: फ़ील्ड को हाइलाइट करें, बताएं क्या करना है, उपयोगकर्ता इनपुट रखें, और पहले अमान्य फ़ील्ड पर फोकस करें। सर्वर-साइड विफलताओं के लिए, रीट्राय विकल्प दिखाएं और प्रगति को संरक्षित रखें ताकि उपयोगकर्ताओं को पूरे स्टेप को दोहराना न पड़े।
टैप टार्गेट बड़े रखें, मल्टी-कॉलम फ़ॉर्म से बचें, और प्राथमिक क्रिया को हमेशा दृश्य रखें। फुल कीबोर्ड नेविगेशन, स्पष्ट फोकस स्टेट, लेबल्ड इनपुट और स्क्रीन-रीडर के अनुकूल प्रोग्रेस टेक्स्ट सुनिश्चित करें (केवल विज़ुअल बार नहीं)।
एक स्मूद बहु-कदम ऑनबोर्डिंग फ्लो उस डेटा मॉडल पर निर्भर करता है जो तीन प्रश्नों का भरोसेमंद उत्तर दे सके: उपयोगकर्ता को अगला क्या दिखना चाहिए, उन्होंने अब तक क्या प्रदान किया है, और वे किस फ्लो की परिभाषा फ़ॉलो कर रहे हैं।
शुरूआत एक छोटे सेट टेबल/कलेक्शन के साथ करें और ज़रूरत पड़ने पर बढ़ाएँ:
यह विभाजन “कन्फ़िगरेशन” (Flow/Step) और “यूज़र डेटा” (StepResponse/Progress) को साफ़ अलग रखता है।
शुरू से तय करें कि क्या फ्लो वर्ज़नड होंगे। अधिकांश प्रोडक्ट्स में जवाब हाँ होता है।
जब आप स्टेप एडिट करते हैं (नाम बदलना, reorder, required फ़ील्ड जोड़ना), आप नहीं चाहेंगे कि बीच में वाले उपयोगकर्ता अचानक वैलिडेशन फेल हों या अपनी जगह खो दें। एक सरल तरीका:
id और version हो (या इम्म्यूटेबल flow_version_id)।flow_version_id की ओर पॉइंट करे।प्रगति सेव करने के लिए ऑटोसेव (जैसे टाइप करते ही) और एक्सप्लिसिट “Next” सेव के बीच चुनाव करें। कई टीमें दोनों का मेल करती हैं: ड्राफ्ट्स ऑटोसेव करें, लेकिन स्टेप को “complete” तभी मार्क करें जब Next क्लिक हो।
रिपोर्टिंग और ट्रबलशूटिंग के लिए टाइमस्टैम्प ट्रैक करें: started_at, completed_at, और last_seen_at (साथ में प्रति-स्टेप saved_at)। ये फ़ील्ड ऑनबोर्डिंग एनालिटिक्स पावर करते हैं और सपोर्ट टीम को समझने में मदद करते हैं कि उपयोगकर्ता कहाँ अटक गया था।
जब आप ऑनबोर्डिंग को एक स्टेट मशीन की तरह समझते हैं तो यह सबसे आसान बन जाता है: उपयोगकर्ता का ऑनबोर्डिंग सेशन हमेशा एक “स्टेट” में होता है (करंट स्टेप + स्टेटस), और आप केवल कुछ विशिष्ट ट्रांज़िशन की अनुमति देते हैं।
फ्रंटएंड को किसी भी URL पर कूदने देने के बजाय, हर स्टेप के लिए सीमित स्टेटस सेट परिभाषित करें (उदा.: not_started → in_progress → completed) और स्पष्ट ट्रांज़िशन परिभाषित करें (उदा.: start_step, save_draft, submit_step, go_back, reset_step)।
यह आपको पूर्वानुमेय व्यवहार देता है:
एक स्टेप तभी “completed” मानी जानी चाहिए जब दोनों शर्तें पूरी हों:
सर्वर के फैसले को स्टेप के साथ स्टोर करें, जिसमें कोई एरर कोड्स भी रहें। इससे UI और बैकएंड के बीच असहमति नहीं रहती।
एक सामान्य किनारा: उपयोगकर्ता किसी पहले के स्टेप को एडिट करता है और बाद के स्टेप्स गलत हो जाते हैं। उदाहरण: “Country” बदलने से “Tax details” या “Available plans” अमान्य हो सकते हैं।
इसका समाधान निर्भरताओं को ट्रैक करना और हर सबमिट के बाद डाउनस्ट्रीम स्टेप्स को पुनः-मूल्यांकन करना है। सामान्य परिणाम:
needs_review पर मार्क करें (या in_progress पर रीवर्ट करें)।“Back” का समर्थन होना चाहिए, पर यह सुरक्षित होना चाहिए:
इससे अनुभव लचीला रहता है और साथ ही सत्र की स्थिति संगत और लागू रहने योग्य बनी रहती है।
आपका बैकएंड API इस बात का “स्रोत-सत्य” है कि उपयोगकर्ता ऑनबोर्डिंग में कहाँ है, उसने अब तक क्या भरा है, और वह आगे क्या कर सकता है। एक अच्छा API फ्रंटएंड को सरल रखता है: यह करंट स्टेप रेंडर करने, डेटा सुरक्षित रूप से सबमिट करने, और रिफ्रेश या नेटवर्क हिचकिचाहट के बाद रिकवर करने की अनुमति देता है।
कम से कम, इन कार्यों के लिए डिज़ाइन करें:
GET /api/onboarding → करंट स्टेप की की, कम्प्लीशन %, और रेंडर करने के लिए किसी भी सेव्ड ड्राफ्ट वैल्यूज़ लौटाता है।PUT /api/onboarding/steps/{stepKey} with { "data": {…}, "mode": "draft" | "submit" }POST /api/onboarding/steps/{stepKey}/nextPOST /api/onboarding/steps/{stepKey}/previousPOST /api/onboarding/complete (सर्वर सत्यापित करता है कि सभी आवश्यक स्टेप्स संतुष्ट हैं)रिस्पॉन्स को सुसंगत रखें। उदाहरण के लिए, सेव करने के बाद अपडेटेड प्रोग्रेस के साथ सर्वर-निर्धारित अगले स्टेप को लौटाएँ:
{ "currentStep": "profile", "nextStep": "team", "progress": 0.4 }
उपयोगकर्ता डबल-क्लिक करेंगे, खराब कनेक्शन पर रीट्राय करेंगे, या फ्रंटएंड टाइमआउट के बाद रिक्वेस्ट फिर भेज देगा। “सेव” को सुरक्षित बनाने के तरीके:
PUT/POST रिक्वेस्ट्स के लिए Idempotency-Key हेडर स्वीकार करें और (userId, endpoint, key) से डुप्लीकेशन करें।PUT /steps/{stepKey} को उस स्टेप के स्टोर किए गए पेलोड का पूरा ओवरराइट माना जाए (या पार्टियल मर्ज नियम स्पष्ट रूप से डॉक्यूमेंट करें)।version (या etag) जोड़ें ताकि स्टेल रीट्राय नए डेटा को ओवरराइट न कर सके।ऐसे मैसेज लौटाएँ जिन्हें UI फील्ड्स के पास दिखा सके:
{
"error": "VALIDATION_ERROR",
"message": "Please fix the highlighted fields.",
"fields": {
"companyName": "Company name is required",
"teamSize": "Must be a number"
}
}
403 (not allowed) को 409 (conflict / wrong step) और 422 (validation) से अलग रखें ताकि फ्रंटएंड सही प्रतिक्रिया दे सके।
यूज़र और एडमिन क्षमताओं को अलग करें:
GET /api/admin/onboarding/users/{userId} या ओवरराइड) को रोल-गेटेड और ऑडिटेड करें।यह सीमा आकस्मिक प्रिविलेज लीक को रोकती है जबकि सपोर्ट/ऑप्स टीमों को उपयोगकर्ताओं की मदद करने की अनुमति देती है।
फ्रंटएंड का काम नेटवर्क में समस्याएँ होते हुए भी ऑनबोर्डिंग को स्मूद महसूस कराना है। इसका मतलब है पूर्वानुमेय राउटिंग, भरोसेमंद “रिज़्यूम” व्यवहार, और डेटा सेव होने पर स्पष्ट फ़ीडबैक।
हर स्टेप के लिए एक URL (उदा., /onboarding/profile, /onboarding/billing) आम तौर पर सबसे आसान होता है। यह ब्राउज़र बैक/फॉरवर्ड, ईमेल से डीप लिंकिंग, और रिफ्रेश पर कॉन्टेक्स्ट बनाए रखने को सपोर्ट करता है।
बहुत छोटे फ्लो के लिए एक सिंगल पेज आंतरिक स्टेट के साथ ठीक हो सकता है, पर यह रिफ्रेश, क्रैश और “लिंक शेयर करके जारी रखें” के मामलों में जोखिम बढ़ाता है। इस दृष्टिकोण का उपयोग करते हैं तो मजबूत परसिस्टेंस और इतिहास प्रबंधन चाहिए।
स्टेप कम्प्लीशन और लेटेस्ट सेव्ड डेटा सर्वर पर स्टोर करें, केवल लोकल स्टोरेज पर नहीं। पेज लोड पर करंट ऑनबोर्डिंग स्टेट (करंट स्टेप, कम्प्लीटेड स्टेप्स, और ड्राफ्ट वैल्यूज़) फेच करें और उसी से रेंडर करें।
यह सक्षम बनाता है:
ऑप्टिमिस्टिक UI घर्षण घटा सकता है, पर इसे गार्ड रैल्स चाहिए:
जब उपयोगकर्ता वापस आएँ, तो उन्हें सीधे स्टेप एक पर नहीं डालें। इस तरह प्रॉम्प्ट करें: “You’re 60% done—continue where you left off?” और दो क्रियाएँ दें:
/onboarding पर लौटने का लिंक दे)यह छोटा सा स्पर्श परित्याग कम करता है और उन उपयोगकर्ताओं का सम्मान भी करता है जो अभी पूरा नहीं करना चाहते।
वैलिडेशन वही जगह है जहाँ ऑनबोर्डिंग स्मूद महसूस होगी या निराशाजनक बनेगी। लक्ष्य है गलतियों को जल्दी पकड़ना, उपयोगकर्ताओं को आगे बढ़ाना, और फिर भी सिस्टम को सुरक्षित रखना जब डेटा अपूर्ण या संदिग्ध हो।
क्लाइंट-साइड वैलिडेशन का उपयोग करें ताकि स्पष्ट त्रुटियों को नेटवर्क रिक्वेस्ट से पहले रोका जा सके। इससे चर्न कम होता है और हर स्टेप अधिक उत्तरदायी लगता है।
सामान्य चेक्स में required फ़ील्ड्स, लंबाई सीमाएँ, बेसिक फ़ॉर्मैटिंग (email/phone), और सरल क्रॉस-फ़ील्ड नियम (password confirmation) शामिल हैं। संदेश विशिष्ट रखें (“Enter a valid work email”) और फ़ील्ड के पास दिखाएँ।
सर्वर-साइड वैलिडेशन को सत्य की स्रोत मानें। UI चाहे कितनी भी परफेक्ट वैलिडेशन दे, उपयोगकर्ता इसे बायपास कर सकते हैं।
सर्वर वैलिडेशन को लागू करना चाहिए:
फ़ील्ड-लेवल संरचित एरर्स लौटाएँ ताकि फ्रंटएंड सही फ़ील्ड हाइलाइट कर सके।
कुछ वैलिडेशन बाहरी या देरी वाले संकेतों पर निर्भर होते हैं: ईमेल यूनिकनेस, इनविटेशन कोड, फ्रॉड संकेत, या दस्तावेज़ सत्यापन।
इनको स्पष्ट स्टेटस (उदा., pending, verified, rejected) के साथ हैंडल करें और UI में स्पष्ट स्थिति दिखाएँ। यदि चेक पेंडिंग है, तो उपयोगकर्ता को तब तक आगे बढ़ने दें जहाँ तक संभव हो और बताएं कि आप उन्हें कैसे सूचित करेंगे या कौन सा स्टेप अगले खुलेगा।
बहु-कदम ऑनबोर्डिंग में अक्सर आंशिक डेटा सामान्य है। प्रति स्टेप तय करें कि:
व्यावहारिक दृष्टिकोण: “हमेशा ड्राफ्ट सेव करें, केवल स्टेप कम्प्लीशन पर ब्लॉक करें।” यह सेशन रिज़्यूम को सपोर्ट करता है बिना आपके डेटा की गुणवत्ता मानक कम किए।
बहु-कदम ऑनबोर्डिंग के लिए एनालिटिक्स को दो सवालों का जवाब देना चाहिए: “लोग कहाँ अटकते हैं?” और “किस परिवर्तन से कम्प्लीशन बेहतर होगा?” कुंजी यह है कि हर स्टेप के लिए एक छोटा सेट स्थिर इवेंट्स ट्रैक करें, और इन्हें उस तरीके से डिज़ाइन करें कि फ्लो बदलने पर भी तुलना हो सके।
हर स्टेप के लिए एक जैसे कोर इवेंट्स ट्रैक करें:
step_viewed (उपयोगकर्ता ने स्टेप देखा)step_completed (उपयोगकर्ता ने सबमिट किया और वैलिडेशन पास हुआ)step_failed (सबमिशन प्रयास किया लेकिन वैलिडेशन या सर्वर चेक फेल हुए)flow_completed (उपयोगकर्ता अंतिम सफलता स्थिति पर पहुँचा)हर इवेंट के साथ एक छोटा, स्थिर कॉन्टेक्स्ट पेलोड शामिल करें: user_id, flow_id, flow_version, step_id, step_index, और session_id (ताकि आप "एक सत्र" और "कई दिनों में" अलग कर सकें)। यदि आप रिज़्यूम सपोर्ट करते हैं तो step_viewed पर resume=true/false भी जोड़ें।
किसी स्टेप पर ड्रॉप-ऑफ़ मापने के लिए, समान flow_version के लिए step_viewed बनाम step_completed की गिनती तुलना करें। समय मापने के लिए टाइमस्टैम्प कैप्चर करें और निकाले:
step_viewed → step_completed का समयstep_viewed → अगले step_viewed का समय (उपयोगकर्ताओं के स्किप करने पर उपयोगी)टाइम मेट्रिक्स को वर्ज़न के अनुसार ग्रुप करें; अन्यथा सुधार पुरानी और नई वर्ज़न मिल जाने से छुप सकते हैं।
अगर आप A/B टेस्ट कर रहे हैं (कॉपी या स्टेप्स का रीयोर्ड), तो इसे एनालिटिक्स पहचान का हिस्सा बनाएं:
experiment_id और variant_id जोड़ेंstep_id स्थिर रखें भले ही डिस्प्ले टेक्स्ट बदलेstep_id वही रखें और स्थिति के लिए step_index पर भरोसा करेंएक सिंपल डैशबोर्ड बनाएं जो दिखाए: कम्प्लीशन रेट, स्टेप के अनुसार ड्रॉप-ऑफ़, मध्यकालीन समय प्रति स्टेप, और “टॉप फेल्ड फील्ड्स” ( step_failed मेटाडाटा से)। CSV एक्सपोर्ट जोड़ें ताकि टीमें स्प्रेडशीट में प्रगति देख सकें और बिना सीधे एनालिटिक्स टूल के शेयर कर सकें।
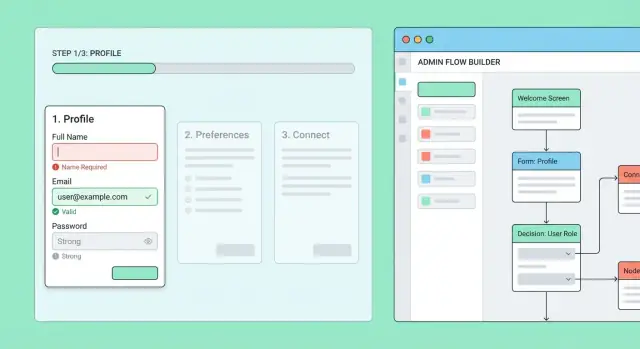
बहु-कदम ऑनबोर्डिंग सिस्टम को दिन-प्रतिदिन ऑपरेशनल कंट्रोल की ज़रूरत पड़ेगी: प्रोडक्ट चेंज, सपोर्ट एक्सेप्शन्स, और सेफ एक्सपेरिमेंटेशन। एक छोटा इन्टरनल एडमिन एरिया इंजीनियरिंग को बॉतलनेक बनने से रोकेगा।
एक सरल “फ्लो बिल्डर” बनाकर शुरू करें जो अधिकृत स्टाफ को ऑनबोर्डिंग फ्लो और उसके स्टेप्स बनाने और एडिट करने दे।
प्रत्येक स्टेप को एडिटेबल रखें:
एक प्रीव्यू मोड जोड़ें जो एंड-यूज़र जैसा रेंडर दिखाए—यह रियल यूज़र्स तक पहुँचने से पहले कंफ्यूज़िंग कॉपी, गायब फ़ील्ड्स और ब्रांचिंग बग पकड़ेगा।
लाइव फ्लो को सीधे एडिट करने से बचें। इसके बजाय वर्ज़न पब्लिश करें:
रोलआउट्स को वर्ज़न के अनुसार कॉन्फ़िगर करें:
यह रिस्क कम करता है और तुलना के लिए साफ़ तुलना देता है जब आप कम्प्लीशन और ड्रॉप-ऑफ़ मापते हैं।
सपोर्ट टीमों को उपयोगकर्ताओं को बिना मैन्युअल DB एडिट के अनब्लॉक करने वाले टूल चाहिए:
हर एडमिन क्रिया लॉग हो: किसने क्या बदला, कब बदला, और पहले/बाद के मान। एक्सेस को रोल्स (view-only, editor, publisher, support override) द्वारा सीमित करें ताकि संवेदनशील क्रियाएँ नियंत्रित और ट्रेस योग्य रहें।
लॉन्च से पहले यह मानकर चलें कि: उपयोगकर्ता अप्रत्याशित पथ लेंगे, और कुछ बीच में फेल होगा (नेटवर्क, वैलिडेशन, परमिशन)। एक अच्छा लॉन्च चेकलिस्ट फ्लो को सही साबित करता है, उपयोगकर्ता डेटा की रक्षा करता है, और जब वास्तविकता आपके प्लान से भिन्न हो तो जल्दी चेतावनी देता है।
वर्कफ़्लो लॉजिक (स्टेट्स और ट्रांज़िशन) के लिए यूनिट टेस्ट से शुरू करें। इन टेस्ट्स को सत्यापित करना चाहिए कि हर स्टेप:
फिर इंटीग्रेशन टेस्ट जोड़ें जो आपके API को एक्सरसाइज करें: स्टेप पेलोड सेव करना, प्रगति रिज़्यूम करना, और अमान्य ट्रांज़िशन रिजेक्ट करना। इंटीग्रेशन टेस्ट्स अक्सर “लोकल में काम करता है” समस्याएँ पकड़ते हैं जैसे मिसिंग इंडेक्स, चेरीज़ेशन बग, या फ्रंटएंड-बैकएंड वर्ज़न मिसमैच।
E2E टेस्ट कम से कम कवर करें:
E2E परिदृश्यों को छोटा पर सार्थक रखें—उन कुछ पाथ्स पर ध्यान दें जो अधिकतर उपयोगकर्ताओं और राजस्व/एक्टिवेशन प्रभाव का प्रतिनिधित्व करते हैं।
लीस्ट प्रिविलेज लागू करें: ऑनबोर्डिंग एडमिन को स्वतः उपयोगकर्ता रिकॉर्ड का पूरा एक्सेस नहीं मिलना चाहिए, और सर्विस अकाउंट्स को केवल ज़रूरी तालिकाएँ/एन्डपॉइंट्स तक सीमित रखें।
जहाँ जरूरी हो एन्क्रिप्ट करें (उदा., टोकन, संवेदनशील पहचानकर्ता, रेगुलेटेड फ़ील्ड्स) और लॉग्स को डेटा लीक रिस्क मानें। कच्चे फॉर्म पेलोड्स लॉग करने से बचें; स्टेप IDs, एरर कोड्स और टाइमिंग लॉग करें। अगर डिबगिंग के लिए पेलोड स्निपेट्स लॉग करने की ज़रूरत हो तो फ़ील्ड्स को लगातार रेडैक्ट करें।
ऑनबोर्डिंग को एक प्रोडक्ट फनल और API की तरह इंस्ट्रूमेंट करें।
स्टेप के अनुसार एरर्स, सेव लेटेंसी (p95/p99), और रिज्यूम विफलताओं को ट्रैक करें। रिलीज़ के बाद कम्प्लीशन रेट में अचानक गिरावट, किसी एक स्टेप पर वैलिडेशन फेल्स का स्पाइक, या API एरर रेट में वृद्धि के लिए अलर्ट सेट करें। यह आपको टूटे हुए स्टेप को सपोर्ट टिकट्स बढ़ने से पहले ठीक करने देता है।
अगर आप स्टेप-आधारित ऑनबोर्डिंग सिस्टम स्क्रैच से बना रहे हैं, तो ज़्यादातर समय वही बिल्डिंग ब्लॉक्स लेते हैं जो ऊपर वर्णित हैं: स्टेप राउटिंग, परसिस्टेंस, वैलिडेशन, प्रोग्रेस/स्टेट लॉजिक, और एडमिन इंटरफ़ेस वर्ज़निंग और रोलआउट के लिए। Koder.ai इन हिस्सों को तेज़ी से प्रोटोटाइप और शिप करने में मदद कर सकता है—आमतौर पर एक React फ्रंटएंड, Go बैकएंड, और PostgreSQL डेटा मॉडल के साथ जो फ्लोज़, स्टेप्स और स्टेप रिस्पॉन्स को साफ़ मैप करता है।
Koder.ai सोर्स कोड एक्सपोर्ट, होस्टिंग/डिप्लॉयमेंट, और रोलबैक के साथ स्नैपशॉट्स सपोर्ट करता है, इसलिए यह ऑनबोर्डिंग वर्ज़न्स पर सुरक्षित रूप से इटरेट करने और अगर रोलआउट कम्प्लीशन को खराब करे तो जल्दी रिकवर करने में उपयोगी है।
जब सेटअप एक साधारण फ़ॉर्म से अधिक हो—खासकर जब इसमें पूर्वशर्तें (जैसे वर्कस्पेस बनाना), सत्यापन (ईमेल/फोन/KYC), कॉन्फ़िगरेशन (बिलिंग/इंटीग्रेशन) या रोल/प्लान/रीजन के अनुसार शाखाएँ शामिल हों—तब बहु-कदम फ्लो उपयोगी होता है।
यदि उपयोगकर्ताओं को सही जवाब देने के लिए संदर्भ चाहिए, तो कदमों में बाँटना गलतियों और ड्रॉप-ऑफ को कम करता है।
सफलता को स्क्रीन पूरे करने से अलग रखें—यह उस मूल्य तक पहुँचने के बारे में है जो उपयोगकर्ता को मिलता है। सामान्य मीट्रिक्स:
साथ ही resume success को भी ट्रैक करें (उपयोगकर्ता बीच में छोड़कर बिना प्रगति खोए वापस आ सकें)।
प्रत्येक उपयोगकर्ता प्रकार की सूची बनाकर शुरू करें (उदा., सेल्फ-सर्व नए उपयोगकर्ता, इनवाइटेड उपयोगकर्ता, एडमिन-निर्मित अकाउंट) और हर एक के लिए परिभाषित करें:
फिर skip rules को एन्कोड करें ताकि हर पर्सोना सही अगले कदम पर पहुंचे, न कि हमेशा पहले कदम पर।
“Done” को बैकएंड द्वारा जाँचे जाने योग्य मानदंड के रूप में लिखें, न कि केवल UI स्क्रीन की समाप्ति के रूप में। उदाहरण:
इस तरह सर्वर विश्वसनीय रूप से तय कर सकता है कि ऑनबोर्डिंग पूरी हुई है—भले ही UI बदल जाए।
अधिकतर मामलों में एक ज्यादातर लीनियर बैकबोन से शुरू करें और तभी कंडीशनल ब्रांच जोड़ें जब अनुभव सचमुच अलग हो (रोल, प्लान, रीजन, उपयोग केस)।
ब्रांचेस को स्पष्ट if/then नियमों के रूप में दस्तावेज़ करें (उदा., “If region = EU → show VAT step”) और स्टेप नामों को क्रिया-केंद्रित रखें (“Confirm email”, “Invite teammates”)।
अक्सर बेहतर होता है हर स्टेप के लिए एक URL (उदा., /onboarding/profile)—यह रिफ्रेश सुरक्षा, डीप लिंक्स और ब्राउज़र बैक/फॉरवर्ड का समर्थन करता है।
केवल बहुत छोटे फ्लो के लिए ही एकल पेज के साथ आंतरिक स्टेट का उपयोग करें—और तब भी केवल तभी जब आप मजबूत परसिस्टेंस सुनिश्चित कर सकें।
सर्वर को सत्य की स्रोत मानें:
यह रिफ्रेश सुरक्षा, क्रॉस-डिवाइस जारी रखने और फ्लो अपडेट होने पर स्थिरता देता है।
एक व्यावहारिक न्यूनतम मॉडल:
फ्लो परिभाषाओं को वर्शन करें ताकि इन-प्रोग्रेस उपयोगकर्ता तब भी टूटें नहीं जब आप स्टेप जोड़ें/रियोर्डर करें। प्रोग्रेस को किसी विशिष्ट पर रेफ़रेंस कराएं।
ऑनबोर्डिंग को एक स्टेट मशीन की तरह देखें और स्पष्ट ट्रांज़िशन परिभाषित करें (उदा., start_step, save_draft, submit_step, go_back)।
एक स्टेप “completed” तभी माना जाए जब:
जब किसी पहले के उत्तर बदलते हैं, तो डाउनस्ट्रीम स्टेप्स को या पर मार्क करें और निर्भरता पुनः-मूल्यांकन करें।
एक अच्छा बेसलाइन API आमतौर पर शामिल करता है:
GET /api/onboarding (करंट स्टेप + प्रोग्रेस + ड्राफ्ट्स)PUT /api/onboarding/steps/{stepKey} with mode: draft|submitPOST /api/onboarding/complete (सर्वर सभी आवश्यकताओं को सत्यापित करता है)रिलायबिलिटी के लिए (जैसे ) जोड़ें ताकि retries/double-clicks सुरक्षित हों, और स्ट्रक्चर्ड फ़ील्ड-लेवल एरर्स लौटाएँ (403/409/422 का अर्थ बनाए रखें)।
flow_version_idneeds_reviewin_progressIdempotency-Key