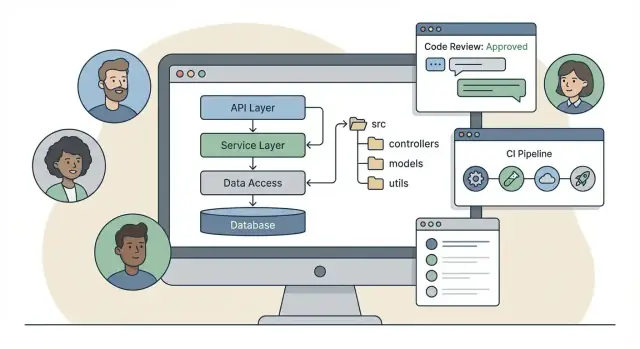
“स्टैक चुनना” से परे: बैकएंड फ्रेमवर्क क्यों मायने रखते हैं
एक बैकएंड फ्रेमवर्क सिर्फ लाइब्रेरीज़ का संग्रह नहीं है। लाइब्रेरीज़ विशिष्ट काम करती हैं (रूटिंग, वैलिडेशन, ORM, लॉगिंग)। एक फ्रेमवर्क एक opinionated “काम करने का तरीका” जोड़ता है: डिफ़ॉल्ट प्रोजेक्ट संरचना, सामान्य पैटर्न, बिल्ट-इन टूलिंग, और यह कि हिस्से कैसे जुड़ते हैं।
फ्रेमवर्क रोज़ाना के फैसलों को आकार देते हैं
एक बार फ्रेमवर्क स्थापित हो जाए, यह सैकड़ों छोटे निर्णयों का मार्गदर्शन करता है:
- नया कोड कहाँ रखा जाए (features, modules, services)
- अनुरोध ऐप के माध्यम से कैसे चलता है (controllers, middleware, handlers)
- auth, validation, errors जैसी cross-cutting चिंताओं को कैसे संभाला जाए
- टीमें चीज़ों का नाम कैसे रखें, टेस्ट कैसे लिखें, और PRs कैसे रिव्यू करें
इसी कारण से दो टीमें जो “एक ही API” बना रही हैं, तब भी बहुत अलग कोडबेस बन सकती हैं—भले ही वे एक ही भाषा और डेटाबेस उपयोग करें। फ्रेमवर्क की कन्वेंशंस यह तय करती हैं कि “यहाँ हम यह कैसे करते हैं” का डिफ़ॉल्ट जवाब क्या होगा।
गति और सुसंगति बनाम लचीलापन
फ्रेमवर्क अक्सर लचीलापन के बदले अनुमानित संरचना देते हैं। फ़ायदा यह है कि ऑनबोर्डिंग तेज़ होती है, बहस कम होती है, और पुन:उपयोगी पैटर्न अनपेक्षित जटिलता घटाते हैं। नुकसान यह है कि जब आपके उत्पाद को असामान्य वर्कफ़्लो, परफ़ॉर्मेंस ट्यूनिंग, या गैर-मानक आर्किटेक्चर की ज़रूरत हो, तो फ्रेमवर्क कन्वेंशंस प्रतिबंधित महसूस कर सकती हैं।
अच्छा निर्णय यह नहीं है कि “फ्रेमवर्क या नहीं,” बल्कि आप कितनी कन्वेंशन चाहते हैं—और क्या आपकी टीम समय के साथ कस्टमाइज़ेशन की लागत उठाने को तैयार है।
किसे परवाह करनी चाहिए
- इंजीनियर्स: पैटर्न फिर से नहीं बनाना पड़ता, फीचर्स पे ज्यादा समय मिलता है
- टेक लीड्स: आर्किटेक्चर, टेस्टिंग, और कोड रिव्यू के स्पष्ट मानक
- प्रोडक्ट टीमें: कोडबेस बढ़ने पर अधिक भविष्यवाणी योग्य डिलीवरी और कम गुणवत्ता regressions
फ्रेमवर्क डिफ़ॉल्ट जो आपके प्रोजेक्ट स्ट्रक्चर को परिभाषित करते हैं
ज़्यादातर टीमें खाली फ़ोल्डर से नहीं शुरू करतीं—वे फ्रेमवर्क की “सिफारिश की गई” लेआउट से शुरू करती हैं। वे डिफ़ॉल्ट्स यह तय करते हैं कि लोग कोड कहाँ रखेंगे, क्या सामान्य नाम है, और रिव्यू में क्या “सामान्य” लगेगा।
दो सामान्य डिफ़ॉल्ट माइंडसेट
कुछ फ्रेमवर्क क्लासिक लेयर्ड संरचना को बढ़ावा देते हैं: controllers / services / models। इसे सीखना आसान है और यह अनुरोध हैंडलिंग से साफ़ मेल खाती है:
/src
/controllers
/services
/models
/repositories
दूसरे फ्रेमवर्क feature modules की ओर झुकते हैं: एक फीचर के लिए सब कुछ एक साथ समूहित करें (HTTP हैंडलर्स, डोमेन नियम, परसिस्टेंस)। इससे लोकल रीजनिंग को बढ़ावा मिलता है—जब आप “Billing” पर काम करते हैं, तो एक फ़ोल्डर खोलते हैं:
/src
/modules
/billing
/http
/domain
/data
कोई भी स्वाभाविक रूप से बेहतर नहीं है, पर हर एक आदतों को आकार देती है। लेयर्ड संरचनाएँ cross-cutting मानकों (logging, validation, error handling) को केंद्रीकृत करना आसान बना सकती हैं। मॉड्यूल-प्रथम संरचनाएँ जैसे-जैसे कोडबेस बढ़ता है, “हॉरिज़ॉन्टल स्क्रॉलिंग” कम कर सकती हैं।
स्कैफोल्डिंग टूल लंबे समय तक पैटर्न बना देते हैं
CLI जनरेटर (scaffolding) चिपकने वाले होते हैं। अगर जनरेटर हर endpoint के लिए controller + service जोड़े बनाता है, तो लोग वही करते रहेंगे—भले ही सरल फ़ंक्शन काम कर देता हो। अगर यह एक मॉड्यूल उत्पन्न करता है जिसमें स्पष्ट सीमाएँ हों, तो टीमें डेडलाइन के दबाव में भी उन सीमाओं का सम्मान करने की अधिक संभावना रखती हैं।
यह वही डायनामिक “vibe-coding” वर्कफ़्लोज़ में भी दिखती है: अगर आपके प्लेटफ़ॉर्म की डिफ़ॉल्ट्स एक पूर्वानुमेय लेआउट और स्पष्ट मॉड्यूल सीमाएँ पैदा करती हैं, तो टीमें कोडबेस को बढ़ते समय संबंधित बनाए रखती हैं। उदाहरण के लिए, Koder.ai चैट प्रॉम्प्ट से फुल-स्टैक ऐप्स जेनरेट करता है, और व्यावहारिक लाभ (गति से परे) यह है कि आपकी टीम जल्दी में भी लगातार संरचनाओं और पैटर्न पर स्टैंडर्डाइज़ कर सकती है—फिर उन पर किसी भी अन्य कोडबेस की तरह iterate कर सकती है (जब चाहें स्रोत कोड export भी कर सकते हैं)।
“फैट कंट्रोलर्स” से बचना
कंट्रोलर्स को स्टार बनाने वाले फ्रेमवर्क टीमों को बिजनेस नियमों को request handlers में ठूँसने के लिए प्रलोभित कर सकते हैं। एक उपयोगी नियम: कंट्रोलर्स केवल HTTP → application call का अनुवाद करें, और उससे ज़्यादा कुछ नहीं। बिजनेस लॉजिक को सर्विस/use-case लेयर (या मॉड्यूल डोमेन लेयर) में रखें, ताकि उसे HTTP के बिना टेस्ट किया जा सके और background jobs या CLI टास्क द्वारा reuse किया जा सके।
अपनी संरचना के लिए एक त्वरित जाँच
यदि आप एक वाक्य में यह नहीं बता पा रहे कि “pricing लॉजिक कहाँ रहता है?”, तो आपके फ्रेमवर्क डिफ़ॉल्ट्स आपके डोमेन के साथ टकरा रहे हो सकते हैं। जल्दी समायोजन करें—फ़ोल्डर्स बदलना आसान है; आदतें नहीं।
अनुरोध प्रवाह: रूटिंग, कंट्रोलर्स, और मिडलवेयर कन्वेंशंस
एक बैकएंड फ्रेमवर्क सिर्फ लाइब्रेरीज़ का सेट नहीं है—यह परिभाषित करता है कि एक अनुरोध आपके कोड के माध्यम से कैसे यात्रा करे। जब हर कोई एक ही अनुरोध पथ का पालन करता है, तो फीचर्स तेज़ी से शिप होते हैं और रिव्यू शैली की बजाय correctness पर केन्द्रित होते हैं।
रूटिंग: आपके सिस्टम का सार्वजनिक तालिका
Routes आपके API के टेबल ऑफ़ कंटेंट की तरह पढ़ने चाहिए। अच्छे फ्रेमवर्क इम्प्लाइस करते हैं कि routes:
- घोषणात्मक हों (आप स्कैन करके समझ सकें कि क्या एक्सपोज़ है)
- सुसंगत हों (पूरे कोडबेस में वही URL पैटर्न और HTTP verbs)
- एज के पास रहें (routing config में बिजनेस नियम नहीं होने चाहिए)
एक व्यावहारिक कन्वेंशन यह है कि रूट फ़ाइलें mapping पर केन्द्रित रहें: GET /orders/:id -> OrdersController.getById, न कि “अगर user VIP है तो X करो।”
कंट्रोलर्स/हैंडलर्स: पतले अनुरोध अनुवादक
कंट्रोलर्स (या हैंडलर्स) सबसे अच्छे तब काम करते हैं जब वे HTTP और आपके कोर लॉजिक के बीच अनुवादक हों:
- इनपुट पढ़ें (params, headers, body)
- एक service/use-case कॉल करें
- प्रतिक्रिया लौटाएँ
जब फ्रेमवर्क parsing, validation, और response formatting के लिए हेल्पर्स देता है, टीमें लॉजिक को कंट्रोलर्स में ढेर करने के लियें प्रेरित हो सकती हैं। स्वास्थ्यवर्धक पैटर्न है “thin controllers, thick services”: request/response चिंताओं को कंट्रोलर्स में रखें, और बिजनेस निर्णयों को एक अलग लेयर में रखें जो HTTP नहीं जानती।
मिडलवेयर/फिल्टर्स: cross-cutting चिंताओं के लिए एक जगह
मिडलवेयर (या फिल्टर्स/इंटरसेप्टर्स) वही जगह है जहां teams repeated व्यवहार जैसे authentication, logging, rate limiting, और request IDs रखते हैं। मुख्य कन्वेंशन: मिडलवेयर को अनुरोध को enrich या guard करना चाहिए, उत्पाद नियम लागू नहीं करने चाहिए।
उदाहरण के लिए, auth middleware req.user अटैच कर सकता है, और कंट्रोलर्स उस पहचान को core logic में पास कर सकते हैं। लॉगिंग मिडलवेयर यह निर्धारित कर सकता है कि क्या लॉग होगा बिना हर कंट्रोलर को फिर से बनाने के।
नामकरण कन्वेंशंस जो रिव्यू friction हटाते हैं
पूर्वानुमेय नामों पर सहमति बनाएं:
OrdersController, OrdersService, CreateOrder (use-case)authMiddleware, requestIdMiddlewarevalidateCreateOrder (schema/validator)
जब नाम इरादा encode करते हैं, तो कोड रिव्यू व्यवहार पर ध्यान केंद्रित करते हैं, न कि इस पर कि चीज़ें “कहाँ रखी जानी चाहिए थीं।”
लेयर्स और सीमाएँ: बिजनेस लॉजिक कहाँ रहता है
एक बैकएंड फ्रेमवर्क आपको सिर्फ endpoints भेजने में मदद नहीं करता—यह आपकी टीम को कोड का एक विशेष “आकृति” की ओर भी प्रेरित करता है। यदि आप जल्दी सीमाएँ परिभाषित नहीं करते, तो डिफ़ॉल्ट गुरुत्वाकर्षण अक्सर यही होता है: कंट्रोलर्स ORM को कॉल करते हैं, ORM DB को कॉल करता है, और बिजनेस नियम हर जगह बिखर जाते हैं।
एक व्यावहारिक लेयर्ड आर्किटेक्चर
एक साधा, टिकाऊ विभाजन इस प्रकार दिखता है:
- Presentation layer: HTTP चिंताएँ (routing, controllers, auth middleware)। अनुरोध को ऐप कमांड में बदलता है और रिस्पॉन्स लौटाता है।
- Application layer: Use-cases (उदा.,
CreateInvoice, CancelSubscription)। काम और ट्रांज़ैक्शन्स को ऑर्केस्ट्रेट करता है, लेकिन फ्रेमवर्क-लीन रहता है।
- Domain layer: कोर बिजनेस नियम और कॉन्सेप्ट (entities, policies, domain services)। इसे SQL जैसा नहीं पढ़ना चाहिए—यह बिजनेस जैसा पढ़ना चाहिए।
- Data layer: Repositories, ORM models/mappers, queries, migrations।
जो फ्रेमवर्क “controllers + services + repositories” जेनरेट करते हैं वे सहायक हो सकते हैं—यदि आप इसे directional flow के रूप में देखें, न कि एक आवश्यकता कि हर फीचर को हर लेयर चाहिए।
ORMs और repositories सीमाओं को कैसे प्रभावित करते हैं
एक ORM यह रस्क कर देता है कि डेटाबेस मॉडल्स को हर जगह पास करना सुविधाजनक है क्योंकि वे पहले से ही लगभग validated होते हैं। Repositories मदद करते हैं एक संकुचित इंटरफ़ेस देकर (“get customer by id”, “save invoice”), ताकि आपका एप्लिकेशन और डोमेन कोड ORM विवरणों पर निर्भर न रहे।
“सब कुछ डेटाबेस पर निर्भर है” डिज़ाइनों से बचने के लिए:
- ORM entities सीधे कंट्रोलर्स से वापस न करें।
- query shapes को data layer में रखें; नियम domain में रखें।
- use-cases के लिए domain-friendly inputs/outputs पसंद करें।
सर्विस लेयर कब जोड़ना चाहिए (और कब नहीं)
जब लॉजिक endpoints के माध्यम से reuse होती है, ट्रांज़ैक्शन्स की आवश्यकता होती है, या नियमों को लगातार लागू करना आवश्यक हो, तब service/application use-case layer जोड़ें। जिन्हें वास्तव में कोई बिजनेस बिहेवियर नहीं है उन सरल CRUD के लिए छोड़ दें—वहाँ पर लेयर्स जोड़ना ceremony पैदा कर सकता है बिना स्पष्टता के।
डिपेंडेंसी इंजेक्शन और मॉड्यूलर डिज़ाइन आदतें
डिपेंडेंसी इंजेक्शन (DI) उन फ्रेमवर्क डिफ़ॉल्ट्स में से एक है जो पूरी टीम को प्रशिक्षित करते हैं। जब यह फ्रेमवर्क में बेक्ड इन होता है, आप random जगहों पर “new-ing up” करना बंद कर देते हैं और डिपेंडेंसीज़ को घोषित, वायर, और swap करने योग्य मानना शुरू कर देते हैं।
DI क्या प्रोत्साहित करता है (और क्या जटिल कर सकता है)
DI टीमों को छोटे, केंद्रित कंपोनेंट्स की तरफ़ धकेलता है: एक कंट्रोलर एक सर्विस पर निर्भर करता है, एक सर्विस एक रिपॉज़िटरी पर निर्भर करती है, और प्रत्येक भाग की स्पष्ट भूमिका होती है। इससे टेस्टेबिलिटी बेहतर होती है और implementations बदलना आसान हो जाता है (उदा., असली पेमेंट गेटवे बनाम mock)।
नुकसान यह है कि DI जटिलता छुपा सकता है। यदि हर क्लास पाँच अन्य क्लासेज़ पर निर्भर है, तो यह समझना मुश्किल हो जाता है कि वास्तव में एक अनुरोध पर क्या चलता है। Misconfigured containers भी ऐसी त्रुटियाँ पैदा कर सकते हैं जो उस कोड से दूर लगती हैं जिसे आप एडिट कर रहे थे।
Constructor injection और interface-driven डिज़ाइन
ज़्यादातर फ्रेमवर्क constructor injection को बढ़ावा देते हैं क्योंकि यह डिपेंडेंसीज़ को स्पष्ट बनाता है और “service locator” पैटर्न को रोकता है।
एक मददगार आदत है constructor injection को interface-driven डिज़ाइन के साथ जोड़ना: कोड एक स्थिर कॉन्ट्रैक्ट (EmailSender जैसे) पर निर्भर करे न कि किसी विशिष्ट vendor client पर। इससे provider switch या refactor पर बदलाव सीमित रहते हैं।
cohesive मॉड्यूल बिना circular dependencies के
DI तब सबसे अच्छा काम करता है जब आपके मॉड्यूल kohesive हों: एक मॉड्यूल एक फंक्शनालिटी slice का मालिक हो (orders, billing, auth) और छोटा public surface एक्सपोज़ करे।
Circular dependencies एक सामान्य failure मोड हैं। अक्सर ये संकेत करते हैं कि boundaries अस्पष्ट हैं—दो मॉड्यूल ऐसे concepts साझा करते हैं जो अपना मॉड्यूल डिज़र्व करते हैं, या एक मॉड्यूल बहुत ज़्यादा कर रहा है।
wiring कहाँ होता है इस पर सहमति
टीमों को यह तय करना चाहिए कि कहाँ dependencies register हों: एक single composition root (startup/bootstrap), साथ में मॉड्यूल-स्तरीय wiring मॉड्यूल इन्टरनल्स के लिए।
वायरिंग को केंद्रीकृत रखने से कोड रिव्यू आसान होते हैं: रिव्यूअर नए डिपेंडेंसीज़ देख सकते हैं, पुष्टि कर सकते हैं कि वे justified हैं, और “container sprawl” को रोक सकते हैं जो DI को एक रहस्य बना देता है।
API कॉन्ट्रैक्ट्स: वैलिडेशन, एरर्स, और डेटा शेप्स
अपने प्रोजेक्ट लेआउट को मानकीकृत करें
अपनी टीम के लिए एक सुसंगत संरचना के साथ पूरा-स्टैक ऐप जेनरेट करें।
एक बैकएंड फ्रेमवर्क यह प्रभावित करता है कि आपकी टीम पर “अच्छा API” कैसा दिखता है। यदि वैलिडेशन एक first-class फीचर है (decorators, schemas, pipes, request guards), तो लोग endpoints को स्पष्ट इनपुट और पूर्वानुमेय आउटपुट के आसपास डिजाइन करते हैं—क्योंकि सही काम करना आसान होता है बनाम उसे छोड़ना।
वैलिडेशन आपके endpoints के आकार को प्रभावित करता है
जब वैलिडेशन सीमा पर रहता है (बिजनेस लॉजिक से पहले), टीमें request payloads को एक कॉन्ट्रैक्ट के रूप में ट्रीट करना शुरू कर देती हैं, न कि “क्लाइंट जो भी भेजे।” इससे प्रायः होता है:
- स्पष्ट required बनाम optional fields (और कम “null means unknown” बहसें)
- फॉर्मैट (dates, IDs, enums) और constraints (min/max, length) के लिए स्पष्ट नियम
- खराब अनुरोधों का जल्दी रिजेक्शन, जिससे सेवा कोड बिजनेस नियमों पर केंद्रित रहता है
यह वही जगह है जहाँ फ्रेमवर्क साझा कन्वेंशंस को बढ़ावा देते हैं: वैलिडेशन कहाँ परिभाषित है, त्रुटियाँ कैसे surfaced होती हैं, और unknown fields की अनुमति है या नहीं।
केंद्रीकृत एरर्स क्लाइंट की अपेक्षाएँ सुसंगत बनाते हैं
जो फ्रेमवर्क global exception filters/handlers सपोर्ट करते हैं वे सुसंगति को साध्य बनाते हैं। हर कंट्रोलर अपना अनूठा रिस्पॉन्स न बनाए—बदले में आप मानकीकृत कर सकते हैं:
- Error envelope (उदा.
code, message, details, traceId)
- HTTP status mapping (validation → 400, auth → 401/403, not found → 404)
- Logging और correlation IDs ताकि सपोर्ट एक विफल अनुरोध को debug कर सके
एक सुसंगत error shape फ्रंट-एंड की branching logic घटाती है और API डॉक्स को भरोसेमंद बनाती है।
DTOs और view models आपके इनर्नल्स की रक्षा करते हैं
कई फ्रेमवर्क आपको DTOs (input) और view models (output) की ओर बढ़ाते हैं। यह अलगाव स्वस्थ है: यह आंतरिक फील्ड्स के अनजाने खुलासे को रोकता है, क्लाइंट्स को डेटाबेस स्कीमा से जोड़े जाने से बचाता है, और refactors को सुरक्षित बनाता है। एक व्यावहारिक नियम: कंट्रोलर्स DTOs में बोलें; सर्विसेज़ domain models में।
वर्शनिंग और backward compatibility के बुनियादी
छोटी APIs भी विकसित होती हैं। फ्रेमवर्क रूटिंग कन्वेंशंस अक्सर निर्धारित करते हैं कि वर्शनिंग URL-आधारित है (/v1/...) या हेडर-आधारित। जो भी चुनें, शुरुआत में बेसिक्स सेट करें: बिना deprecation विंडो के फ़ील्ड्स कभी न हटाएँ, fields को backward-compatible तरीके से जोड़ें, और बदलावों को एक जगह दस्तावेज़ करें (उदा., /docs या /changelog)।
फ्रेमवर्क टूलिंग द्वारा प्रभावित परीक्षण रणनीति
एक बैकएंड फ्रेमवर्क सिर्फ फीचर शिप करने में मदद नहीं करता; यह निर्धारित करता है कि आप उन्हें कैसे टेस्ट करेंगे। बिल्ट-इन टेस्ट रनर, बूटस्ट्रैपिंग यूटिलिटीज़, और DI कंटेनर अक्सर यह तय करते हैं कि क्या आसान है—और जो आसान होगा वही आपकी टीम वास्तव में करेगी।
फ्रेमवर्क हेल्पर्स: यूनिट बनाम इंटीग्रेशन बनाम E2E
कई फ्रेमवर्क एक “test app” bootstrapper प्रदान करते हैं जो कंटेनर को स्पिन अप कर सकता है, routes रजिस्टर कर सकता है, और in-memory अनुरोध चला सकता है। यह टीमों को जल्दी integration tests की ओर ले जाता है—क्योंकि वे यूनिट टेस्ट से सिर्फ कुछ लाइनों अधिक होते हैं।
एक व्यावहारिक विभाजन ऐसा दिखता है:
- Unit tests शुद्ध बिजनेस लॉजिक के लिए (कोई फ्रेमवर्क बूट नहीं, कोई DB नहीं)।
- Integration tests मॉड्यूल्स/सर्विसेज़ के लिए जो फ्रेमवर्क कंटेनर के माध्यम से वायर होते हैं।
- End-to-end tests असली HTTP व्यवहार (routing, middleware, auth, error mapping) के लिए।
बैकएंड सर्विसेज़ के लिए टेस्ट पिरामिड
ज़्यादातर सेवाओं के लिए गति परफेक्ट पिरामिड से ज़्यादा मायने रखती है। अच्छा नियम: बहुत सारे छोटे यूनिट टेस्ट रखें, सीमाओं (DB, queues) के आसपास integration tests का एक लक्षित सेट रखें, और एक पतली E2E परत जो कॉन्ट्रैक्ट साबित करे।
यदि आपका फ्रेमवर्क request simulation को सस्ता बनाता है, तो आप integration tests पर थोड़ा अधिक निर्भर हो सकते हैं—फिर भी domain logic को अलग रखें ताकि unit tests स्थिर रहें।
DI और runtime के अनुसार मॉकिंग
मॉकिंग रणनीति को उसी तरह फ़ॉलो करना चाहिए जिस तरह आपका फ्रेमवर्क डिपेंडेंसीज़ को हल करता है:
- monkey-patching imports के बजाय DI bindings को ओवरराइड करना प्राथमिकता दें (सच client के बजाय fake लगाएं)
- जहाँ संभव हो in-memory adapters का उपयोग करें (उदा., in-memory repositories) ताकि brittle mocks से बचा जा सके
- मॉकिंग मॉड्यूल बॉउंडरी पर करें, बिजनेस लॉजिक के अंदर नहीं, ताकि refactors से टेस्ट टूटें नहीं
CI के लिए तेज़, विश्वसनीय टेस्ट
फ्रेमवर्क बूट टाइम CI को डोमिनेट कर सकता है। तेज़ रखने के लिए महंगे सेटअप को cache करें, DB migrations को पूरे सूट के लिए एक बार चलाएँ, और केवल वहीं parallelization करें जहाँ isolation गारंटीड हो। Failure diagnosis आसान बनाएं: consistent seeding, deterministic clocks, और strict cleanup hooks “retry on fail” से बेहतर हैं।
कोडबेस स्केल करना: मॉड्यूल्स, पैकेजेस, और साझा कोड
ऑपेरेबिलिटी जोड़ें
ऐसा ऐप जेनरेट करके जल्दी लॉगिंग और ऑपरेशनल डिफ़ॉल्ट सेट करें जिसे आप आगे विकसित कर सकें।
फ्रेमवर्क सिर्फ पहला API शिप करने में नहीं मदद करता—यह तय करता है कि आपका कोड कैसे बढ़ेगा जब “एक सेवा” दर्जनों फीचर्स, टीमें, और एकीकरणों में बदल जाएगा। मॉड्यूल और पैकेज मैकेनिक्स जो आपका फ्रेमवर्क सरल बनाता है वे अक्सर आपका दीर्घकालिक आर्किटेक्चर बन जाते हैं।
मॉड्युलैरिटी पैटर्न जो फ्रेमवर्क बढ़ावा देते हैं
ज़्यादातर बैकएंड फ्रेमवर्क डिज़ाइन द्वारा modularity की ओर धकेलते हैं: apps, plugins, blueprints, modules, feature folders, या packages। जब यह डिफ़ॉल्ट होता है, टीमें नई क्षमताओं को “एक और मॉड्यूल” की तरह जोड़ने लगती हैं बजाय पूरे प्रोजेक्ट में नई फाइलें बिखेरने के।
एक व्यावहारिक नियम: प्रत्येक मॉड्यूल को एक मिनी-प्रोडक्ट की तरह ट्रीट करें जिसमें अपना public surface (routes/handlers, service interfaces), निजी अंदरूनी, और टेस्ट हों। यदि आपका फ्रेमवर्क auto-discovery (उदा., module scanning) सपोर्ट करता है, तो इसे सावधानी से उपयोग करें—explicit imports अक्सर डिपेंडेंसीज़ को समझने में आसान बनाते हैं।
कोर डोमेन बनाम इंफ्रास्ट्रक्चर मॉड्यूल्स
जैसे-जैसे कोडबेस बढ़ता है, बिजनेस नियमों को adapters के साथ मिलाना महंगा पड़ता है। एक उपयोगी विभाजन है:
- Core domain modules: बिजनेस नियम, नीतियाँ, domain services, और domain models (ऐसी चीजें जो डेटाबेस स्वैप करते समय भी टिकनी चाहिए)
- Infrastructure modules: डेटाबेस क्लाइंट्स, ORM models, message brokers, HTTP clients, caches, auth providers
यह फ्रेमवर्क कन्वेंशंस पर निर्भर करता है: अगर फ्रेमवर्क “service classes” को बढ़ावा देता है, तो domain services को core मॉड्यूल्स में रखें और फ्रेमवर्क-विशिष्ट वायरिंग (controllers, middleware, providers) को किनारों पर रखें।
साझा पुस्तकालय बनाम copy-paste: निर्णय नियम
टीमें अक्सर बहुत जल्दी शेयर कर देती हैं। छोटी कोड की कॉपी करना तब तक पसंद करें जब तक यह स्थिर न हो, फिर निकालें जब:
- दो या अधिक टीमें एक ही लॉजिक बनाए रख रही हों
- एक बग फिक्स को कई जगह लागू करना पड़े
- आप एक स्पष्ट API परिभाषित कर सकें और उसे version कर सकें
यदि आप extract करते हैं, तो internal packages (या workspace libraries) प्रकाशित करें जिनकी कड़ी ownership और changelog अनुशासन हो।
मॉड्यूलर मोनोलिथ → माइक्रोसर्विसेज के लिए तैयारी
एक मॉड्यूलर मोनोलिथ अक्सर “मिडल-स्केल” के लिए सबसे अच्छा होता है। यदि मॉड्यूल्स की सीमाएँ स्पष्ट हों और cross-imports कम हों, तो आप बाद में कम झंझट के साथ किसी मॉड्यूल को सर्विस में बदल सकते हैं। मॉड्यूल्स को बिजनेस क्षमताओं के आसपास डिज़ाइन करें, न कि तकनीकी लेयर्स के आधार पर। गहराई के लिए देखें /blog/modular-monolith।
कॉन्फ़िगरेशन, वातावरण, और ऑपरेशनल रेडीनेस
फ्रेमवर्क की कॉन्फ़िग मॉडल यह निर्धारित करती है कि आपकी डिप्लॉयमेंट्स कितनी सुसंगत (या अराजक) लगेंगी। जब कॉन्फ़िग एड-हॉक फाइलों, रैंडम env vars, और “बस इस एक कॉन्स्टेंट” के बीच बिखरी होती है, टीमें अंतर समझने के बजाय फ़ीचर बनाना छोड़ कर debug करते हैं।
कॉन्फ़िग स्टाइल = सुसंगति
ज़्यादातर फ्रेमवर्क आपको एक प्राथमिक ट्रूथ सोर्स की ओर प्रवृत्त करते हैं: कॉन्फ़िग फाइलें, environment variables, या code-based configuration (modules/plugins)। जो भी रास्ता चुनें, शुरुआत में इसे मानकीकृत करें:
- Files लोकल विकास और स्पष्ट डिफ़ॉल्ट्स के लिए अच्छे हैं (उदा.,
config/default.yml).
- Environment variables deployment-time फ़र्क़ और container प्लेटफ़ॉर्म के लिए उपयुक्त हैं।
- Code-based config शक्तिशाली हो सकती है, पर यह महत्वपूर्ण सेटिंग्स को लॉजिक के पीछे छुपा सकती है।
एक अच्छा कन्वेंशन: डिफ़ॉल्ट्स versioned config files में रहें, environment variables प्रति वातावरण override करें, और कोड एक typed config object से पढ़े। इससे यह स्पष्ट रहता है कि किसी incident में मान बदलने के लिए कहाँ देखना है।
सीक्रेट्स: उन्हें अलग श्रेणी मानें
फ्रेमवर्क अक्सर env vars पढ़ने, secret stores इंटीग्रेट करने, या स्टार्टअप पर कॉन्फ़िग validate करने के हेल्पर्स देते हैं। उस टूलिंग का उपयोग करें ताकि secrets को गलत तरीके से हैंडल करना मुश्किल हो:
- कभी भी secrets को repo में commit न करें ("temporary" keys सहित)
- लॉग्स और error pages में secrets न डालें
- लोकल
.env फैलाव के बजाय runtime injection (CI/CD, container orchestrator, या secret manager) पसंद करें
आप जो ऑपरेशनल आदत बनाना चाहते हैं वह सरल है: डेवेलपर्स लोकल में safe placeholders के साथ चला सकें, जबकि असल credentials सिर्फ उन्हीं वातावरणों में मौजूद हों जिनको उन्हें चाहिए।
वातावरण समानता: dev, staging, production
फ्रेमवर्क डिफ़ॉल्ट या तो parity को प्रोत्साहित कर सकते हैं (हर जगह वही boot process) या special cases बना सकते हैं (“production अलग server entrypoint उपयोग करता है”)। एक ही startup कमांड और एक ही config schema पर लक्ष्य रखें, केवल मान बदलें।
Staging को rehearsal की तरह ट्रीट करें: वही feature flags, वही migrations path, वही background jobs—बस छोटा स्केल।
कॉन्फ़िग को API की तरह डॉक्यूमेंट करें
जब कॉन्फ़िग डॉक्यूमेंट नहीं होती, तो साथी अनुमान लगाते हैं—और अनुमान outages बन जाते हैं। रेपो में एक छोटा, maintained संदर्भ रखें (उदा., /docs/configuration) जिसमें सूची हो:
- प्रत्येक config key और वह क्या नियंत्रित करती है
- अपेक्षित प्रकार/फ़ॉर्मैट (string, URL, integer)
- डिफ़ॉल्ट मान और सुरक्षित उदाहरण
- कौन से वातावरण इसे सेट करना चाहिए
कई फ्रेमवर्क बूट पर कॉन्फ़िग validate कर सकते हैं। इसे डॉक्यूमेंटेशन के साथ जोड़ दें और आप “works on my machine” को एक दुर्लभ अपवाद बना देंगे बजाय कि बार-बार होने वाले मुद्दे के।
फ्रेमवर्क द्वारा निर्धारित ऑब्ज़रवबिलिटी मानक
एक बैकएंड फ्रेमवर्क उस बेसलाइन को सेट करता है जिससे आप प्रोडक्शन में सिस्टम को समझते हैं। जब observability पहले से बनाई गई (या मजबूती से प्रोत्साहित की जाती है), टीमें लॉग्स और मैट्रिक्स को “बाद में” काम नहीं मानतीं और उन्हें API का हिस्सा मानकर डिजाइन करती हैं।
लॉगिंग, ट्रेसिंग, और मैट्रिक्स: जो आपको “मुफ़्त” मिलता है
कई फ्रेमवर्क structured logging, distributed tracing, और metrics collection के लिए सामान्य टूलिंग के साथ सीधे इंटीग्रेट करते हैं। यह एकरूपता कोड संगठन को प्रभावित करती है: आप cross-cutting चिंताओं को केंद्रीकृत करने (logging middleware, tracing interceptors, metrics collectors) की प्रवृत्ति रखते हैं बजाय हर कंट्रोलर में print statements बिखेरने के।
एक अच्छा मानक यह है कि हर request-संबंधित लॉग लाइन में कुछ आवश्यक फ़ील्ड्स हों:
correlation_id (या request_id) ताकि सेवाओं में लॉग्स जोड़े जा सकेंroute और method यह समझने के लिए कि कौन सा endpoint शामिल हैuser_id या account_id (यदि उपलब्ध) सपोर्ट investigations के लिएduration_ms और status_code परफ़ॉर्मेंस और विश्वसनीयता के लिए
फ्रेमवर्क कन्वेंशंस (जैसे request context objects या middleware pipelines) correlation IDs बनाने और पास करने को आसान बनाते हैं, ताकि डेवलपर्स हर फीचर के लिए पैटर्न फिर से न बनाएं।
हेल्थ चेक और readiness endpoints
फ्रेमवर्क डिफ़ॉल्ट अक्सर यह निर्धारित करते हैं कि health checks first-class नागरिक हैं या बाद की सोच। मानक endpoints जैसे /health (liveness) और /ready (readiness) टीम की "done" की परिभाषा बन जाते हैं, और यह आपको साफ़ सीमाओं की ओर धकेलता है:
- liveness: “क्या प्रोसेस चल रहा है?”
- readiness: “क्या यह ट्रैफ़िक सर्व कर सकता है?” (उदा., DB कनेक्शन, migrations लागू)
जब ये endpoints जल्दी मानकीकृत होते हैं तो ऑपरेशनल आवश्यकताएँ रैंडम फीचर कोड में रिसने बंद हो जाती हैं।
ऑब्ज़रवबिलिटी का उपयोग रिफैक्टरिंग को मार्गदर्शित करने के लिए
ऑब्ज़रवबिलिटी डेटा निर्णय लेने का एक टूल भी है। यदि ट्रेसेस दिखाते हैं कि एक endpoint बार-बार एक ही dependency में समय खर्च कर रहा है, तो यह मॉड्यूल निकालने, कैशिंग जोड़ने, या क्वेरी फिर से डिज़ाइन करने का स्पष्ट संकेत है। यदि लॉग्स inconsistent error shapes दिखाते हैं, तो यह centralized error handling लागू करने का प्रोत्साहन है। दूसरे शब्दों में: फ्रेमवर्क के observability hooks सिर्फ debugging में मदद नहीं करते—वे आपको कोडबेस को आत्मविश्वास के साथ reorganize करने में मदद करते हैं।
टीम वर्कफ़्लो: कन्वेंशंस, टूलिंग, और कोड रिव्यू
कंट्रोलर्स को पतला रखें
स्वचालित रूप से पतले कंट्रोलर्स और स्पष्ट सर्विस लेयर बनाएं, फिर प्रॉम्प्ट्स से इटरेट करें।
एक बैकएंड फ्रेमवर्क सिर्फ कोड को व्यवस्थित नहीं करता—यह टीम के काम करने के “घर के नियम” भी सेट करता है। जब हर कोई एक ही कन्वेंशंस का पालन करता है (फाइल प्लेसमेंट, नामकरण, डिपेंडेंसीज़ कैसे वायर होती हैं), रिव्यूज़ तेज़ हो जाती हैं और ऑनबोर्डिंग आसान होता है।
कोड जनरेशन और स्कैफोल्ड्स: उपयोग करे, पूजा न करे
Scaffolding टूल कुछ मिनटों में नए endpoints, मॉड्यूल्स, और टेस्ट को स्टैंडर्डाइज़ कर सकते हैं। जाल यह है कि जनरेटर्स को अपने डोमेन मॉडल निर्धारित करने दें।
Generators का प्रयोग consistent shells (routes/controllers, DTOs, test stubs) बनाने के लिए करें, फिर तुरंत आउटपुट को संपादित कर लें ताकि यह आपकी आर्किटेक्चर नियमों से मेल खाए। एक अच्छी पॉलिसी: generators की अनुमति है, पर अंतिम कोड को अभी भी सोचा-समझा डिज़ाइन जैसा दिखना चाहिए—न कि सिर्फ टेम्पलेट डंप।
यदि आप AI-assisted workflow उपयोग कर रहे हैं, तो वही अनुशासन लागू करें: generated code को scaffolding समझें। प्लेटफ़ॉर्म जैसे Koder.ai पर आप चैट के जरिए तेज़ी से iterate कर सकते हैं और फिर भी अपनी टीम कन्वेंशंस (मॉड्यूल सीमाएँ, DI पैटर्न, error shapes) को रिव्यूज़ के जरिए लागू कर सकते हैं—क्योंकि गति तभी मददगार होती है जब संरचना भविष्यणीय बनी रहे।
फ्रेमवर्क आदियों के साथ सुसंगत स्टाइल गाइड
फ्रेमवर्क अक्सर एक idiomatic संरचना सुझाते हैं: वैलिडेशन कहाँ रहती है, त्रुटियाँ कैसे उठाईं जाती हैं, सेवाओं का नामकरण कैसा है। उन अपेक्षाओं को एक छोटे टीम स्टाइल गाइड में कैप्चर करें जिसमें:
- नामकरण कन्वेंशंस जो फ्रेमवर्क प्रिमिटिव्स से मेल खाते हों (उदा., Controller, Service, Module)
- फ़ोल्डर सीमाएँ (कंट्रोलर में क्या allowed है बनाम domain/service layer में क्या)
- एक “अच्छे” endpoint की उदाहरण इम्प्लीमेंटेशन
इसे हल्का और actionable रखें; /contributing से लिंक दें।
लिंटिंग, फॉर्मैटिंग, और pre-commit hooks
मानकों को ऑटोमेटिक बनाइए। फॉर्मैटर और लिंटर को फ्रेमवर्क कन्वेंशंस (imports, decorators/annotations, async patterns) के अनुसार कन्फ़िगर करें। फिर उन्हें pre-commit hooks और CI के जरिए लागू करें, ताकि रिव्यूज़ डिजाइन पर केन्द्रित हों न कि whitespace और नामकरण पर।
PR टेम्पलेट्स और आर्किटेक्चर-संबंधी रिव्यू चेकलिस्ट
एक फ्रेमवर्क-आधारित चेकलिस्ट drift को रोकता है। एक PR टेम्पलेट जोड़ें जो रिव्यूअर्स से पुष्टि करने के लिए कहे:
- नए endpoints routing/controller कन्वेंशंस का पालन करते हैं
- validation और error responses टीम मानक से मेल खाते हैं
- डिपेंडेंसी सीमाओं का सम्मान किया गया है (कंट्रोलर्स से सीधे DB कॉल नहीं, आदि)
- टेस्ट फ्रेमवर्क की सिफारिशों के अनुसार हैं
समय के साथ ये छोटे वर्कफ़्लो गार्डरेल्स ही कोडबेस को रख-रखाव योग्य बनाये रखते हैं जब टीम बढ़ती है।
बिना दर्दनाक रिराइट के फ्रेमवर्क चुनना और विकसित करना
फ्रेमवर्क चुनाव पैटर्न लॉक करते हैं—डायरेक्टरी लेआउट, कंट्रोलर स्टाइल, DI, यहाँ तक कि लोग कैसे टेस्ट लिखते हैं। उद्देश्य परफेक्ट फ्रेमवर्क चुनना नहीं है; उद्देश्य ऐसा फ्रेमवर्क चुनना है जो आपकी टीम के सॉफ्टवेयर शिप करने के तरीकों के अनुकूल हो, और जब आवश्यकता बदले तो परिवर्तन संभव रखें।
टीम के आकार और लक्ष्यों के लिए फिट का मूल्यांकन
शुरुआत अपनी delivery बाधाओं से करें, फीचर चेकलिस्ट से नहीं। छोटी टीमें मजबूत कन्वेंशंस, batteries-included टूलिंग, और तेज़ ऑनबोर्डिंग से लाभ उठाती हैं। बड़ी टीमें अक्सर स्पष्ट मॉड्यूल सीमाएँ, स्थिर extension पॉइंट्स, और पैटर्न चाहती हैं जो hidden coupling बनाने को मुश्किल बनाते हैं।
व्यावहारिक प्रश्न पूछें:
- क्या आप कम से कम पुलिसिंग के साथ सुसंगत संरचना लागू कर सकते हैं रिव्यू में?
- क्या फ्रेमवर्क सही चीज़ को आसान बनाता है (validation, error handling, logging), या हर टीम अपना तरीक़ा ईजाद करती है?
- क्या अपग्रेड्स predictable हैं (स्पष्ट changelogs, deprecation paths), और क्या ecosystem आपकी ज़रूरतों के लिए परिपक्व है?
रिराइट का पूर्वाभास देने वाले रेड-फ़्लैग्स
एक रिराइट अक्सर उन छोटी परेशानियों का परिणाम होता है जिन्हें लंबा समय अनदेखा किया गया हो। देखें:
- अस्पष्ट सीमाएँ: बिजनेस लॉजिक controllers, middleware, या ORM models में फैल रही है
- धीमे टेस्ट: integration tests जो मिनट लेते हैं, टीमें उन्हें छोड़ने लगती हैं
- brittle upgrades: बार-बार ब्रेकिंग चेंजेस, आंतरिक APIs पर भारी निर्भरता, या community workarounds सामान्य हो जाना
इंक्रीमेंटल रिफैक्टोरिंग पैटर्न्स जो डिलीवरी जारी रखते हैं
आप feature काम बंद किए बिना भी विकसित कर सकते हैं द्वारा seams जोड़कर:
- Strangler approach: नए मॉड्यूल के माध्यम से छोटे सेट endpoints रूट करें जबकि पुरानी प्रणाली चलती रहे
- Adapter layers: फ्रेमवर्क-विशिष्ट प्रिमिटिव्स को अपने इंटरफेस के पीछे रैप करें (request context, logger, repositories)
- “Ports and adapters” सीमाएँ: डोमेन लॉजिक को plain मॉड्यूल्स में ले जाएँ जिनमें न्यूनतम फ्रेमवर्क इम्पोर्ट हों, फिर किनारों पर उन्हें वायर करें
गोद लेने की चेकलिस्ट और अगले कदम
किसी बड़े कदम से पहले (या अगले मेजर अपग्रेड से पहले), एक छोटा trial करें:
- एक वास्तविक endpoint end-to-end बनाएं: auth, validation, error responses, और logging.
- दो टेस्ट लिखें: डोमेन लॉजिक के लिए एक तेज़ unit test और HTTP लेयर के लिए एक integration test.
- एक बदलाव नकल करें: फ़ील्ड जोड़ें, रिस्पॉन्स version करें, और एक मॉड्यूल रिफैक्टर करें.
- पिछले मेजर वर्जन के अपग्रेड नोट्स पढ़ें—क्या उससे आपको नुकसान होता?
यदि आप विकल्पों का व्यवस्थित मूल्यांकन चाहते हैं, तो एक हल्का RFC बनाएं और कोडबेस में /docs/decisions के साथ स्टोर करें ताकि भविष्य की टीमें समझें कि आपने क्यों क्या चुना—और कैसे इसे सुरक्षित रूप से बदलना है।
एक अतिरिक्त परिप्रेक्ष्य: यदि आपकी टीम तेज़ बिल्ड लूप्स (चैट-ड्रिवन डेवलपमेंट सहित) के साथ प्रयोग कर रही है, तो यह मूल्यांकन करें कि क्या आपका वर्कफ़्लो अभी भी वही आर्किटेक्चरल आर्टिफैक्ट्स उत्पन्न करता है—स्पष्ट मॉड्यूल्स, लागू योग्य कॉन्ट्रैक्ट्स, और ऑपरेबल डिफ़ॉल्ट्स। सबसे अच्छे स्पीडअप्स (चाहे फ्रेमवर्क CLI से हों या किसी प्लेटफ़ॉर्म जैसे Koder.ai से) वे हैं जो cycle time घटाते हैं बिना उन कन्वेंशंस को खोये जो बैकएंड को मेंटेनेबल रखते हैं।