03 नव॰ 2025·8 मिनट
मल्टी-टेनेन्ट SaaS पैटर्न: अलगाव, पैमाना, और AI-आधारित डिजाइन
साझा-सॉफ़्टवेयर (मल्टी-टेनेन्ट) के सामान्य पैटर्न, टेनेन्ट अलगाव के ट्रेड-ऑफ़ और स्केलिंग रणनीतियाँ सीखें। जानें कि AI-निर्मित आर्किटेक्चर डिजाइन और समीक्षा को कैसे तेज करते हैं।
मल्टी-टेनेनेंसी का मतलब (जैर्गन के बिना)
मल्टी-टेनेनेंसी का मतलब है कि एक ही सॉफ़्टवेयर उत्पाद एक ही चलती हुई प्रणाली से कई ग्राहकों (टेनेन्ट्स) को सेवा देता है। हर टेनेन्ट को ऐसा लगता है जैसे उनका "अपना ऐप" है, लेकिन पीछे की तरफ इन्फ्रास्ट्रक्चर के कुछ हिस्से—जैसे वही वेब सर्वर, वही कोडबेस और अक्सर वही डेटाबेस—शेयर होते हैं।
एक उपयोगी मानसिक मॉडल है एक अपार्टमेंट बिल्डिंग। हर किसी के पास अपनी लॉक की हुई यूनिट होती है (उनका डेटा और सेटिंग्स), पर आप बिल्डिंग के लिफ्ट, पाइपलाइन और रखरखाव टीम साझा करते हैं (ऐप का कंप्यूट, स्टोरेज और ऑपरेशन्स)।
टीमें मल्टी-टेनेनेंसी क्यों चुनती हैं
ज्यादातर टीमें मल्टी-टेनेन्ट SaaS इसलिए नहीं चुनती कि यह फैशनेबल है—वे इसे इसलिए चुनते हैं क्योंकि यह कुशल है:
- प्रति ग्राहक कम लागत: साझा इन्फ्रास्ट्रक्चर आम तौर पर हर ग्राहक के लिए पूरा स्टैक स्पिन अप करने से सस्ता होता है।
- सरल ऑपरेशन्स: मॉनिटरिंग, पैचिंग और सिक्योरिटी के लिए एक ही प्लेटफ़ॉर्म होता है (सैकड़ों छोटे डिप्लॉयमेंट्स की बजाय)।
- तेज़ शिपिंग: सुधार सभी को एक साथ मिलते हैं, और आप ग्राहकों के बीच "वर्जन ड्रिफ्ट" से बचते हैं।
कहाँ गलत हो सकता है
दो क्लासिक फेल्योर मोड हैं: सिक्योरिटी और परफॉरमेंस।
सिक्योरिटी पर: अगर टेनेन्ट सीमाओं को हर जगह लागू नहीं किया गया है, तो एक बग ग्राहक-से-ग्राहक डेटा लीक कर सकता है। ये लीक अक्सर नाटकीय "हैक" नहीं होते—ये आम गलतियाँ होती हैं जैसे एक फ़िल्टर गायब होना, एक गलत कॉन्फ़िगर किया गया परमिशन चेक, या एक बैकग्राउंड जॉब जो टेनेन्ट संदर्भ के बिना चलता है।
परफॉरमेंस पर: साझा संसाधनों का अर्थ है कि एक व्यस्त टेनेन्ट दूसरों को धीमा कर सकता है। यह "नोइज़ी नेबर" प्रभाव के रूप में दिखता है—धीमी क्वेरीज, बर्स्ट वर्कलोड्स, या एक ग्राहक द्वारा असमान API उपयोग।
कवर किए जाने वाले पैटर्न्स का त्वरित अवलोकन
यह लेख उन बिल्डिंग ब्लॉक्स को कवर करेगा जो टीमें इन जोखिमों को संभालने के लिए उपयोग करती हैं: डेटा अलगाव (डेटाबेस, स्कीमा, या पंक्तियाँ), टेनेन्ट-अवेयर पहचान और परमिशन, नोइज़ी-नेबर कंट्रोल, और स्केलिंग व चेंज मैनेजमेंट के ऑपरेशनल पैटर्न।
मूल ट्रेड-ऑफ: अलगाव बनाम दक्षता
मल्टी-टेनेनेंसी एक स्पेक्ट्रम के बारे में निर्णय है: आप टेनेन्ट्स के बीच कितना साझा करते हैं बनाम प्रति-टेनेन्ट कितना समर्पित रखते हैं। नीचे दिए गए हर आर्किटेक्चर पैटर्न इस लाइन पर एक अलग बिंदु है।
साझा बनाम समर्पित संसाधन: मूल स्पेक्ट्रम
एक छोर पर, टेनेन्ट लगभग सब कुछ साझा करते हैं: वही एप इंस्टेंस, वही डेटाबेस, वही क्यूज़, वही कैश—लॉजिकल रूप से tenant_id और एक्सेस रूल्स से अलग किए गए। यह आम तौर पर चलाने में सबसे सस्ता और आसान होता है क्योंकि आप क्षमता को पूल करते हैं।
दूसरे छोर पर, टेनेन्ट्स को सिस्टम का अपना "स्लाइस" मिलता है: अलग डेटाबेस, अलग कंप्यूट, कभी-कभी अलग डिप्लॉयमेंट भी। इससे सुरक्षा और नियंत्रण बढ़ता है, पर ऑपरेशनल ओवरहेड और लागत भी बढ़ती है।
क्यों अलगाव और लागत विपरीत दिशाओं में खींचते हैं
अलगाव इस संभावना को घटाता है कि एक टेनेन्ट दूसरे का डेटा एक्सेस कर पाए, उनके परफॉरमेंस बजट का उपयोग कर ले, या असामान्य उपयोग पैटर्न से प्रभावित हो। यह कुछ ऑडिट और कंप्लायंस आवश्यकताओं को पूरा करना भी आसान बनाता है।
दक्षता तब बेहतर होती है जब आप कई टेनेन्ट्स के बीच बेरोजगार क्षमता को अमोर्टाइज करते हैं। साझा इन्फ्रास्ट्रक्चर आपको कम सर्वर चलाने, सरल डिप्लॉयमेंट पाइपलाइनों को बनाए रखने, और कुल मांग के आधार पर स्केल करने देता है बजाय हर-टेनेन्ट के वर्स्ट-केस की मांग के।
सामान्य निर्णय चालक
आपका "सही" बिंदु शायद दार्शनिक नहीं होगा—यह बाधाओं द्वारा संचालित होगा:
- SLA और ग्राहक अपेक्षाएँ: कठोर अपटाइम या लेटेंसी लक्ष्य आपको अधिक अलगाव की ओर धकेलते हैं।
- कम्प्लायंस और डेटा रेजिडेंसी: आवश्यकताएँ समर्पित स्टोरेज या समर्पित एन्वायर्नमेंट्स को मजबूर कर सकती हैं।
- विकास चरण: शुरुआती उत्पाद तेज़ी से आगे बढ़ने के लिए अधिक साझा से शुरू करते हैं; बाद में आप बड़े ग्राहकों के लिए समर्पित विकल्प पेश कर सकते हैं।
- ऑपरेशनल परिपक्वता: अधिक अलगाव सामान्यतः निगरानी, पैच और माइग्रेट करने के लिए और चीज़ें जोड़ देता है।
पैटर्न चुनने के लिए एक सरल मानसिक मॉडल
दो प्रश्न पूछें:
-
अगर एक टेनेन्ट ग़लत व्यवहार करे या समझौता हो जाए, तो ब्लास्ट रेडियस क्या होगा?
-
उस ब्लास्ट रेडियस को कम करने की व्यावसायिक लागत क्या है?
यदि ब्लास्ट रेडियस बहुत छोटा होना चाहिए, तो अधिक समर्पित कंपोनेंट चुनें। यदि लागत और गति सबसे महत्वपूर्ण हैं, तो अधिक साझा रखें—और साझा को सुरक्षित रखने के लिए मजबूत एक्सेस कंट्रोल, रेट लिमिट्स, और प्रति-टेनेन्ट मॉनिटरिंग में निवेश करें।
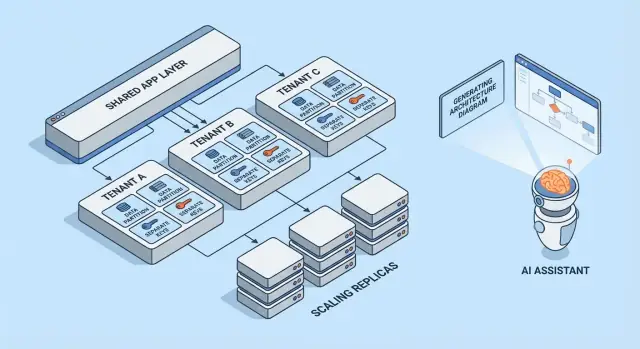
मल्टी-टेनेन्ट मॉडल्स का संक्षिप्त परिचय
मल्टी-टेनेनेंसी एक अलग आर्किटेक्चर नहीं है—यह ग्राहकों के बीच इन्फ्रास्ट्रक्चर को साझा (या न साझा) करने के तरीकों का सेट है। सर्वोत्तम मॉडल इस बात पर निर्भर करता है कि आपको कितना अलगाव चाहिए, आप कितने टेनेन्ट्स की उम्मीद करते हैं, और आपकी टीम कितना ऑपरेशनल ओवरहेड संभाल सकती है।
1) सिंगल-टेनेन्ट (डेडिकेटेड) — बेसलाइन
हर ग्राहक को अपना ऐप स्टैक मिलता है (या कम से कम उनका अपना अलग रनटाइम और डेटाबेस)। यह सुरक्षा और परफॉरमेंस के लिहाज़ से समझने में सबसे सरल है, पर प्रति टेनेन्ट सबसे महंगा होता है और आपकी ऑपरेशंस को स्केल करने में धीमा कर सकता है।
2) साझा एप + साझा DB — सबसे कम लागत, सबसे ज़्यादा सावधानी चाहिए
सभी टेनेन्ट एक ही एप्लिकेशन और डेटाबेस पर चलते हैं। लागत आम तौर पर सबसे कम होती है क्योंकि आप पुन:उपयोग को अधिकतम करते हैं, पर आपको हर जगह टेनेन्ट कॉन्टेक्स्ट के बारे में बहुत सावधान होना होगा (क्वेरीज, कैशिंग, बैकग्राउंड जॉब्स, एनालिटिक्स एक्सपोर्ट)। एक ग़लती क्रॉस-टेनेन्ट डेटा लीक बन सकती है।
3) साझा एप + अलग DB — अधिक मजबूत अलगाव, अधिक ऑप्स
एप्लिकेशन साझा है, पर हर टेनेन्ट का अपना डेटाबेस (या डेटाबेस इंस्टेंस) होता है। इससे घटनाओं के ब्लास्ट-रेडियस पर बेहतर कंट्रोल मिलता है, टेनेन्ट-स्तरीय बैकअप/रिस्टोर आसान होते हैं, और कम्प्लायंस चर्चाएँ सरल हो सकती हैं। ट्रेड-ऑफ ऑपरेशनल है: अधिक डेटाबेस प्रोविजन, मॉनिटर, माइग्रेट और सुरक्षित करने होते हैं।
4) "बड़े टेनेन्ट्स" के लिए हाइब्रिड मॉडल
कई SaaS उत्पाद मिश्रित तरीके अपनाते हैं: अधिकांश ग्राहक साझा इन्फ्रास्ट्रक्चर में रहते हैं, जबकि बड़े या रेगुलेटेड टेनेन्ट को समर्पित डेटाबेस या समर्पित कंप्यूट मिलता है। हाइब्रिड अक्सर व्यावहारिक अंत स्थिति होती है, पर इसे स्पष्ट नियम चाहिए: कौन पात्र है, इसकी लागत क्या है, और अपग्रेड कैसे रोल आउट होंगे।
यदि आप हर मॉडल के अंदर अलगाव तकनीकों पर गहराई से जाना चाहते हैं, तो देखें /blog/data-isolation-patterns।
डेटा अलगाव पैटर्न्स (DB, स्कीमा, रो)
डेटा अलगाव एक सरल प्रश्न का जवाब देता है: "क्या एक ग्राहक कभी दूसरे ग्राहक का डेटा देख सकता है या प्रभावित कर सकता है?" तीन सामान्य पैटर्न हैं, जिनके अलग-अलग सुरक्षा और ऑपरेशनल प्रभाव हैं।
रो-लेवल अलगाव (साझा टेबल्स + tenant_id)
सभी टेनेन्ट वही टेबल्स साझा करते हैं, और हर रो में एक tenant_id कॉलम होता है। यह छोटे से मध्यम टेनेन्ट्स के लिए सबसे कुशल मॉडल है क्योंकि यह इन्फ्रास्ट्रक्चर को कम रखता है और रिपोर्टिंग/एनालिटिक्स को सरल बनाता है।
जोखिम भी स्पष्ट है: अगर कोई क्वेरी tenant_id फ़िल्टर करना भूल जाए, तो आप डेटा लीक कर सकते हैं। यहां कुछ निवारक उपाय हैं:
- साझा डेटा-एक्सेस लेयर में टेनेन्ट फ़िल्टरिंग को लागू करना (ताकि डेवलपर्स हैंड-रोल्ड फ़िल्टर न लिखें)
- जहाँ उपलब्ध हो, डेटाबेस सुविधाओं जैसे row-level security (RLS) का उपयोग करना
- स्वचालित परीक्षण जोड़ना जो जानबूझकर क्रॉस-टेनेन्ट एक्सेस आजमाते हैं
- सामान्य एक्सेस पाथ्स के लिए इंडेक्सिंग (अक्सर
(tenant_id, created_at)या(tenant_id, id)) ताकि टेनेन्ट-स्कोप्ड क्वेरीज तेज़ रहें
प्रति-टेनेन्ट स्कीमा (इसी डेटाबेस में, अलग स्कीमाएँ)
हर टेनेन्ट को अपना स्कीमा मिलता है (नैमस्पेसेस जैसे tenant_123.users, tenant_456.users)। यह रो-लेवल साझा की तुलना में अलगाव बढ़ाता है और टेनेन्ट एक्सपोर्ट या टेनेन्ट-विशिष्ट ट्यूनिंग को आसान बना सकता है।
ट्रेड-ऑफ ऑपरेशनल ओवरहेड है। माइग्रेशन्स को कई स्कीम्स में चलाना होता है, और फेल्योर अधिक जटिल हो सकते हैं: आप 9,900 टेनेन्ट सफलतापूर्वक माइग्रेट कर सकते हैं और 100 पर अटक सकते हैं। मॉनिटरिंग और टूलिंग यहाँ महत्वपूर्ण है—आपकी माइग्रेशन प्रक्रिया में स्पष्ट रिट्राय और रिपोर्टिंग व्यवहार होना चाहिए।
प्रति-टेनेन्ट डेटाबेस (अलग डेटाबेस)
हर टेनेन्ट को अलग डेटाबेस मिलता है। अलगाव मजबूत होता है: एक्सेस सीमाएँ स्पष्ट होती हैं, एक टेनेन्ट की शोरगुल करने वाली क्वेरीज दूसरे को कम प्रभावित करती हैं, और किसी एक टेनेन्ट को बैकअप से रिस्टोर करना साफ़-सुथरा होता है।
लागत और स्केलिंग मुख्य नकारात्मक बिंदु हैं: अधिक डेटाबेस मैनेज करने होते हैं, अधिक कनेक्शन पूल्स, और संभावित रूप से अधिक अपग्रेड/माइग्रेशन काम। कई टीमें इस मॉडल को उच्च-मूल्य या रेगुलेटेड टेनेन्ट्स के लिए रिज़र्व करते हैं, जबकि छोटे टेनेन्ट साझा इन्फ्रास्ट्रक्चर पर रहते हैं।
जब टेनेन्ट बड़े होते हैं तो शार्डिंग और प्लेसमेंट रणनीतियाँ
वास्तविक सिस्टम अक्सर इन पैटर्न्स को मिलाते हैं। एक सामान्य रास्ता है शुरुआती विकास के लिए रो-लेवल अलगाव, फिर बड़े टेनेन्ट्स को अलग स्कीमा या डेटाबेस में "ग्रैजुएशन" करना।
शार्डिंग एक प्लेसमेंट लेयर जोड़ता है: यह तय करना कि कौन सा टेनेन्ट किस डेटाबेस क्लस्टर में रहता है (क्षेत्र, साइज़ टियर, या हैशिंग द्वारा)। प्रमुख बात यह है कि टेनेन्ट प्लेसमेंट को स्पष्ट और बदलने योग्य बनाएँ—ताकि आप एक टेनेन्ट को बिना ऐप को फिर से लिखे मूव कर सकें, और नए शार्ड जोड़कर स्केल कर सकें।
पहचान, एक्सेस, और टेनेन्ट संदर्भ
मल्टी-टेनेनेंसी आश्चर्यजनक रूप से साधारण तरीकों से फेल होती है: एक फ़िल्टर गायब होना, कैश्ड ऑब्जेक्ट का टेनेन्ट्स के बीच साझा होना, या एक एडमिन फ़ीचर जो "किसके लिए" अनुरोध है यह भूल जाए। समाधान कोई एक बड़ी सुरक्षा सुविधा नहीं है—यह अनुरोध के पहले बाइट से लेकर अंतिम डेटाबेस क्वेरी तक एक सुसंगत टेनेन्ट संदर्भ है।
टेनेन्ट पहचान (आप कैसे जानते हैं "कौन")
अधिकांश SaaS उत्पाद एक प्राथमिक पहचानकर्ता पर टिक जाते हैं और बाकी सब सुविधाजनक मानते हैं:
- सबडोमेन:
acme.yourapp.comउपयोगकर्ताओं के लिए आसान है और टेनेन्ट-ब्रांडेड अनुभवों के साथ अच्छा काम करता है। - हेडर: API क्लाइंट्स और आंतरिक सेवाओं के लिए उपयोगी (पर सत्यापित होना चाहिए)।
- टोकन क्लेम: एक साइन किया गया JWT (या सेशन) में
tenant_idशामिल होता है, जो छेड़छाड़ को कठिन बनाता है।
एक सत्य स्रोत चुनें और उसे हर जगह लॉग करें। यदि आप कई संकेत (सबडोमेन + टोकन) को सपोर्ट करते हैं, तो प्राथमिकता परिभाषित करें और अस्पष्ट अनुरोधों को अस्वीकार करें।
अनुरोध स्कोपिंग (हर क्वेरी कैसे इन-टेनेन्ट रहती है)
एक अच्छा नियम: एक बार जब आप tenant_id को हल कर लें, तो सब कुछ डाउनस्ट्रीम इसे एक ही जगह (रिक्वेस्ट कॉन्टेक्स्ट) से पढ़े, फिर से व्युत्पन्न न करे।
सामान्य गार्डरेल्स में शामिल हैं:
- मिडलवेयर जो
tenant_idको रिक्वेस्ट कॉन्टेक्स्ट में अटैच करता है - डेटा एक्सेस हेल्पर्स जो
tenant_idको एक पैरामीटर के रूप में आवश्यक बनाते हैं - डेटाबेस लागूकरण (जैसे रो-लेवल नीतियाँ) ताकि गलतियाँ बंद होकर फेल हों
handleRequest(req):
tenantId = resolveTenant(req) // subdomain/header/token
req.context.tenantId = tenantId
return next(req)
ऑथराइज़ेशन बेसिक्स (एक टेनेन्ट के भीतर भूमिकाएँ)
प्रमाणीकरण (यूज़र कौन है) और ऑथराइज़ेशन (वे क्या कर सकते हैं) को अलग रखें।
टिपिकली SaaS भूमिकाएँ Owner / Admin / Member / Read-only होती हैं, पर मुख्य बात स्कोप है: एक उपयोगकर्ता Tenant A में Admin और Tenant B में Member हो सकता है। परमिशन्स को पर-टेनेन्ट स्टोर करें, न कि ग्लोबली।
क्रॉस-टेनेन्ट लीक रोकना (टेस्ट्स और गार्डरेल्स)
क्रॉस-टेनेन्ट एक्सेस को टॉप-टियर घटना की तरह ट्रीट करें और इसे प्रोक्टिवली रोकें:
- स्वचालित परीक्षण जोड़ें जो Tenant A के रूप में प्रमाणीकृत होकर Tenant B का डेटा पढ़ने की कोशिश करते हैं
- लिंटर्स, क्वेरी बिल्डर्स, और अनिवार्य टेनेन्ट पैरामीटर जैसे उपायों से मिसिंग टेनेन्ट फ़िल्टर बग्स को शिप करना कठिन बनाएं
- संदेहास्पद पैटर्न पर लॉग और अलर्ट करें (उदा., टोकन और सबडोमेन के बीच टेनेन्ट मिसमैच)
यदि आप एक विस्तृत ऑपरेशनल चेकलिस्ट चाहते हैं, तो इन नियमों को अपने इंजीनियरिंग रनबुक में लिंक करें: /security और उन्हें अपने कोड के साथ संस्करणित रखें।
डेटाबेस के परे अलगाव
प्रैक्टिकल तरीके से सुरक्षित माइग्रेशन
स्कीमा बदलावों के साथ प्रयोग करें, और अगर माइग्रेशन गलत हो जाए तो जल्दी रोलबैक करें.
डेटाबेस अलगाव कहानी का केवल आधा हिस्सा है। कई वास्तविक मल्टी-टेनेन्ट घटनाएँ ऐप के चारों ओर साझा प्लंबिंग में होती हैं: कैश, क्यूज़, और स्टोरेज। ये परतें तेज़, सुविधाजनक और गलती से ग्लोबल बनाना आसान हैं।
साझा कैश: की टकराव और डेटा लीक रोकें
यदि कई टेनेन्ट Redis या Memcached साझा करते हैं, तो मुख्य नियम सरल है: कभी भी टेनेन्ट-अज्ञेय कीज़ ना रखें।
एक व्यावहारिक पैटर्न है हर की को एक स्थिर टेनेन्ट पहचान के साथ प्रेफ़िक्स करना (न कि ईमेल डोमेन या डिस्प्ले नाम)। उदाहरण: t:{tenant_id}:user:{user_id}। इससे दो बातें होती हैं:
- जहां दो टेनेन्ट्स के अंदरूनी IDs समान हों वहां टकराव नहीं होता
- सपोर्ट घटनाओं या माइग्रेशन्स के दौरान बुल्क इनवैलिडेशन संभव होती है (प्रेफ़िक्स द्वारा डिलीट)
यह भी तय करें कि क्या ग्लोबली साझा करना अनुमति है (उदा., पब्लिक फ़ीचर फ्लैग्स, स्टैटिक मेटाडेटा) और इसे दस्तावेज़ित करें—गलती से ग्लोबल होना क्रॉस-टेनेन्ट एक्सपोज़र का सामान्य स्रोत है।
टेनेन्ट-अवेयर रेट लिमिट्स और क्वोटा
भले ही डेटा अलग हो, टेनेन्ट अभी भी साझा कंप्यूट के माध्यम से एक-दूसरे को प्रभावित कर सकते हैं। एज पर टेनेन्ट-अवेयर लिमिट्स जोड़ें:
- प्रति टेनेन्ट API रेट लिमिट्स (और अक्सर प्रति-यूज़र भी)
- महँगी ऑपरेशन्स (एक्सपोर्ट, रिपोर्ट जनरेशन, AI कॉल्स) के लिए क्वोटा
लिमिट को स्पष्ट (हेडर्स, UI नोटिस) बनाएं ताकि ग्राहक समझें कि थ्रॉटलिंग नीति है, अस्थिरता नहीं।
बैकग्राउंड जॉब्स: क्यूज़ को टेनेन्ट द्वारा विभाजित करें
एक ही साझा क्यू एक व्यस्त टेनेन्ट को वर्कर समय पर हावी होने दे सकता है।
सामान्य फिक्स:
- टियर/प्लान के अनुसार अलग क्यूज़ (
free,pro,enterprise) - टेनेन्ट बकेट द्वारा विभाजित क्यूज़ (tenant_id को N क्यूज़ में हैश करें)
- टेनेन्ट-अवेयर शेड्यूलिंग ताकि हर टेनेन्ट को उचित हिस्सा मिले
हमेशा जॉब पेलोड और लॉग्स में टेनेन्ट संदर्भ प्रवाहित करें ताकि गलत-टेनेन्ट साइड-इफेक्ट से बचा जा सके।
फ़ाइल/ऑब्जेक्ट स्टोरेज: अलग पाथ, नीतियाँ और कुंजियाँ
S3/GCS-स्टाइल स्टोरेज के लिए, अलगाव आम तौर पर पाथ और पॉलिसी-आधारित होता है:
- सख्त अलगाव के लिए प्रति-टेनेन्ट बकेट (मजबूत सीमाएँ, अधिक ओवरहेड)
- टेनेन्ट प्रेफिक्स के साथ साझा बकेट (सरल, पर सावधान IAM और साइन किए URL की आवश्यकता)
जो भी आप चुनें, हर अपलोड/डाउनलोड पर टेनेन्ट ओनरशिप को सत्यापित करना लागू करें—केवल UI पर भरोसा न करें।
नोइज़ी नेबर्स और निष्पक्ष संसाधन उपयोग को संभालना
मल्टी-टेनेन्ट सिस्टम इन्फ्रास्ट्रक्चर साझा करते हैं, जिसका अर्थ है कि एक टेनेन्ट गलती से (या जानबूझ कर) अपेक्षित से अधिक संसाधन ले सकता है। यही नोइज़ी नेबर समस्या है: एक जोरदार वर्कलोड बाकी सबको धीमा कर देता है।
"नोइज़ी नेबर" कैसा दिखता है
मान लें एक रिपोर्टिंग फ़ीचर साल भर का डेटा CSV में एक्सपोर्ट करता है। टेनेन्ट A ने 9:00 AM पर 20 एक्सपोर्ट शेड्यूल कर दिए। वे एक्सपोर्ट CPU और DB I/O को संतृप्त कर देते हैं, इसलिए टेनेन्ट B की सामान्य ऐप स्क्रीन टाइमआउट करने लगती हैं—भले ही B ने कुछ असामान्य न किया हो।
संसाधन नियंत्रण: लिमिट्स, क्वोटा, और वर्कलोड शेपिंग
इसे रोकना स्पष्ट संसाधन सीमाओं से शुरू होता है:
- रेट लिमिट्स (प्रति सेकंड अनुरोध) प्रति टेनेन्ट और प्रति एンドपॉइंट, ताकि महँगे APIs को स्पैम न किया जा सके।
- क्वोटा (दैनिक/मासिक) जैसे एक्सपोर्ट, ईमेल, AI कॉल्स, या बैकग्राउंड जॉब्स के लिए।
- वर्कलोड शेपिंग: भारी कार्यों (एक्सपोर्ट्स, इम्पोर्ट्स, री-इंडेक्सिंग) को ऐसे क्यूज़ में डालें जिनमें प्रति-टेनेन्ट समकालन और प्रायोरिटी नियम हों।
एक व्यावहारिक पैटर्न है इंटरैक्टिव ट्रैफ़िक को बैच वर्क से अलग रखना: यूज़र-फ़ेसिंग अनुरोधों को फास्ट लेन पर रखें, और बाकी सब नियंत्रित क्यूज़ में धकेलें।
प्रति-टेनेन्ट सर्किट ब्रेकर्स और बल्खहेड्स
सीफ़्टी वॉल्व्स जोड़ें जो तब ट्रिगर हों जब कोई टेनेन्ट थ्रेशोल्ड पार कर दे:
- सर्किट ब्रेकर्स: अस्थायी रूप से महँगी ऑपरेशन्स को रिजेक्ट या.defer करें जब त्रुटि दर, लेटेंसी, या क्यू गहराई टेनेन्ट के लिए सीमाएँ पार कर जाएँ।
- बल्खहेड्स: साझा पूल्स (DB कनेक्शन्स, वर्कर थ्रेड्स, कैश) को अलग करें ताकि एक टेनेन्ट वैश्विक क्षमता को समाप्त न कर सके।
अच्छे तरीके से किया जाए तो टेनेन्ट A अपनी एक्सपोर्ट स्पीड को प्रभावित कर सकता है बिना टेनेन्ट B को डाउन किए।
कब एक टेनेन्ट को समर्पित क्षमता पर ले जाएँ
जब कोई टेनेन्ट लगातार साझा मान्यताओं को पार कर रहा हो: लगातार हाई थ्रूपुट, अप्रत्याशित स्पाइक्स जो बिज़नेस-क्रिटिकल ईवेंट से जुड़ी हों, कठोर कम्प्लायंस आवश्यकताएँ, या जब उनका वर्कलोड कस्टम ट्यूनिंग मांगता हो। एक सरल नियम: अगर दूसरे टेनेन्ट्स की रक्षा के लिए किसी भुगतान करने वाले ग्राहक को स्थायी रूप से थ्रॉटल करना पड़ता है, तो समर्पित क्षमता (या उच्चतर टियर) पर ले जाना बेहतर है बजाय लगातार फायरफाइटिंग के।
ऐसे स्केलिंग पैटर्न जो मल्टी-टेनेन्ट SaaS में काम करते हैं
हर जगह टेनेंट संदर्भ लागू करें
Koder.ai से ऐसे मिडलवेयर और डेटा-एक्सेस पैटर्न माँगें जो टेनेंट संदर्भ को सुसंगत रखें.
मल्टी-टेनेन्ट स्केलिंग "ज़्यादा सर्वर" के बारे में कम और एक टेनेन्ट की वृद्धि को सभी के लिए चौंकाने वाला बनने से रोकने के बारे में ज़्यादा है। सर्वश्रेष्ठ पैटर्न स्केल को पूर्वानुमेय, मापनीय और उलटने योग्य बनाते हैं।
स्टेटलेस सर्विसेज़ के लिए हॉरिजॉन्टल स्केलिंग
अपनी वेब/API टियर को स्टेटलेस बनाकर शुरू करें: सेशंस को साझा कैश में स्टोर करें (या टोकन-आधारित ऑथ का उपयोग करें), अपलोड्स को ऑब्जेक्ट स्टोरेज में रखें, और लंबी चलने वाली कामों को बैकग्राउंड जॉब्स में धकेलें। एक बार अनुरोध लोकल मेमोरी या डिस्क पर निर्भर न रहे, तब आप लोड बैलांसर के पीछे इंस्टेंस जोड़कर जल्दी स्केल आउट कर सकते हैं।
एक व्यावहारिक टिप: एज पर टेनेन्ट कॉन्टेक्स्ट रखें (सबडोमेन या हेडर्स से व्युत्पन्न) और इसे हर रिक्वेस्ट हैंडलर तक पास करें। स्टेटलेस का मतलब टेनेन्ट-निरपेक्ष नहीं है—बल्कि ऐसा होना चाहिए कि टेनेन्ट-अवेयर हो पर स्टिकी सर्वर न चाहिए।
प्रति-टेनेन्ट हटस्पॉट्स: पहचानना और स्मूद करना
ज्यादातर स्केलिंग समस्याएँ "एक टेनेन्ट अलग है" प्रकार की होती हैं। हटस्पॉट्स देखें जैसे:
- एक टेनेन्ट जो असामान्य रूप से अधिक ट्रैफ़िक जेनरेट कर रहा है
- कुछ टेनेन्ट्स जिनके बहुत बड़े डेटासेट हैं
- बैची उपयोग (महीने के अंत की रिपोर्ट्स, नाइटली इम्पोर्ट्स)
स्मूथिंग रणनीतियों में प्रति-टेनेन्ट रेट लिमिट्स, क्यू-आधारित इनजेशन, टेनेन्ट-विशिष्ट रीड पाथ्स का कैशिंग, और भारी टेनेन्ट्स को अलग वर्कर पूल्स में शार्ड करना शामिल है।
रीड रेप्लिकास, पार्टिशनिंग, और असिंक वर्कलोड्स
रीड-हेवी वर्कलोड्स (डैशबोर्ड्स, सर्च, एनालिटिक्स) के लिए रीड रेप्लिकास का उपयोग करें और राइट्स को प्राइमरी पर रखें। पार्टिशनिंग (टेनेन्ट, समय, या दोनों द्वारा) इंडेक्स छोटे रखने और क्वेरीज तेज रखने में मदद करता है। महँगे टास्क—एक्सपोर्ट्स, ML स्कोरिंग, वेबहुक्स—के लिए असिंक जॉब्स को प्राथमिकता दें और आइडेम्पोटेंसी रखें ताकि रिट्राय से लोड बढ़े नहीं।
कैपेसिटी प्लानिंग सिग्नल और सरल थ्रेशोल्ड्स
सिग्नल सरल और टेनेन्ट-अवेयर रखें: p95 लेटेंसी, त्रुटि दर, क्यू गहराई, DB CPU, और प्रति-टेनेन्ट रिक्वेस्ट दर। आसान थ्रेशोल्ड्स सेट करें (उदा., "क्यू डैप्थ \u003e N 10 मिनट के लिए" या "p95 \u003e X ms") जो ऑटो-स्केल या अस्थायी टेनेन्ट कैप्स को ट्रिगर करें—उससे पहले कि दूसरे टेनेन्ट्स को एहसास हो।
प्रति-टेनेन्ट ऑब्ज़र्वबिलिटी और ऑपरेशंस
मल्टी-टेनेन्ट सिस्टम आम तौर पर पहले वैश्विक रूप से फेल नहीं होते—वे आम तौर पर एक टेनेन्ट, एक प्लान टियर, या एक नोइज़ी वर्कलोड के लिए फेल होते हैं। यदि आपके लॉग्स और डैशबोर्ड्स सेकंडों में "कौन सा टेनेन्ट प्रभावित है?" का जवाब नहीं दे पाते, तो ऑन-कॉल समय अनुमान लगाने में बदल जाता है।
टेनेन्ट-अवेयर लॉग्स, मेट्रिक्स, और ट्रेसेस
टेलीमेट्री में एक सुसंगत टेनेन्ट संदर्भ से शुरू करें:
- लॉग्स: हर रिक्वेस्ट और बैकग्राउंड जॉब पर
tenant_id,request_id, और एक स्थिरactor_id(यूज़र/सर्विस) शामिल करें। - मेट्रिक्स: काउंटर और लेटेंसी हिस्टोग्राम टेनेन्ट टियर द्वारा ब्रेकडाउन के साथ जारी करें (उदा.,
tier=basic|premium) और उच्च-स्तरीय एンドपॉइंट द्वारा (कच्चे URLs नहीं)। - ट्रेसेस: ट्रेस एट्रिब्यूट्स के रूप में टेनेन्ट संदर्भ प्रवाहित करें ताकि आप किसी स्लो ट्रेस को एक टेनेन्ट तक फ़िल्टर कर सकें और देख सकें समय कहाँ बित रहा है (DB, कैश, थर्ड-पार्टी कॉल)।
कार्डिनैलिटी को नियंत्रित रखें: सभी टेनेन्ट्स के लिए प्रति-टेनेन्ट मेट्रिक्स महंगे पड़ सकते हैं। एक सामान्य समझौता है कि डिफ़ॉल्ट रूप से टियर-स्तरीय मेट्रिक्स रखें और आवश्यकता पर पर-टेनेन्ट ड्रिल-डाउन दें (उदा., "टॉप 20 टेनेन्ट्स द्वारा ट्रैफ़िक" के लिए ट्रेसेस सैम्पल करना)।
टेलीमेट्री में संवेदनशील डेटा लीक से बचाव
टेलीमेट्री एक डेटा एक्सपोर्ट चैनल है। इसे प्रोडक्शन डेटा की तरह ही ट्रीट करें।
सामग्री के स्थान पर IDs पसंद करें: नाम, ईमेल, टोकन्स, या क्वेरी पेलोड्स की बजाय customer_id=123 लॉग करें। लॉगर/SDK लेयर पर रेडैक्शन लागू करें, और सामान्य सीक्रेट्स (Authorization हेडर्स, API कीज़) को ब्लॉकलिस्ट करें। सपोर्ट वर्कफ़्लोज़ के लिए कोई भी डिबग पेलोड्स अलग, एक्सेस-नियंत्रित सिस्टम में स्टोर करें—शेयर किए गए लॉग्स में नहीं।
टियर के अनुसार SLOs (अतिरिक्त वादा किए बिना)
ऐसे SLOs परिभाषित करें जो आप वास्तव में लागू कर सकें। प्रीमियम टेनेन्ट्स को कड़ाई वाले लेटेंसी/त्रुटि बजट मिल सकते हैं, पर केवल तब जब आपके पास कंट्रोल भी हों (रेट लिमिट्स, वर्कलोड अलगाव, प्रायोरिटी क्यूज़)। टियर SLOs को टारगेट के रूप में प्रकाशित करें, और उन्हें प्रति-टियर और उच्च-मूल्य टेनेन्ट्स के चुने हुए सेट के लिए ट्रैक करें।
ऑन-कॉल रनबुक्स: मल्टी-टेनेन्ट SaaS में सामान्य घटनाएँ
आपके रनबुक्स की शुरुआत "प्रभावित टेनेन्ट(स) की पहचान करें" से होनी चाहिए और फिर सबसे तेज़ अलग करने वाली कार्रवाई:
- नोइज़ी नेबर: टेनेन्ट को थ्रॉटल करें, भारी जॉब्स को पॉज़ करें, या उन्हें कम-प्राथमिकता क्यू में मूव करें।
- DB हटسپॉट्स/रनअवे क्वेरीज: क्वेरी टाइमआउट सक्षम करें, टेनेन्ट द्वारा शीर्ष क्वेरीज जांचें, इंडेक्स लागू करें या एンドपॉइंट को सीमित करें।
- टेनेन्ट संदर्भ बग्स (डेटा मिक्स-अप): तुरंत फ़ीचर फ्लैग या एンドपॉइंट को डिसेबल करें और एक्सेस चेक्स में टेनेन्ट स्कोपिंग सत्यापित करें।
- बैकग्राउंड जॉब पाइलअप्स: पर-टेनेन्ट क्यूज़ को ड्रेन करें, concurrency को कैप करें, और आइडेम्पोटेंसी सुरक्षा के साथ रिप्ले करें।
ऑपरेशनल लक्ष्य सरल है: टेनेन्ट द्वारा डिटेक्ट करें, टेनेन्ट द्वारा कंटेन करें, और बिना सबको प्रभावित किए रिकवरी करें।
डिप्लॉयमेंट्स, माइग्रेशन्स, और टेनेन्ट-बाय-टेनेन्ट रिलीज़
मल्टी-टेनेन्ट SaaS शिपिंग की लय बदल देता है। आप "एक ऐप" deploy नहीं कर रहे—आप साझा रनटाइम और साझा डेटा पाथ्स deploy कर रहे हैं जिन पर कई ग्राहक निर्भर हैं। लक्ष्य नए फीचर्स ऐसे डिलीवर करना है कि हर टेनेन्ट पर समकालिक बिग-बैंग अपग्रेड ज़रूरी न हो।
रोलिंग डिप्लॉयज और लो-डाउनटाइम माइग्रेशन्स
ऐसे डिप्लॉयमेंट पैटर्न पसंद करें जो मिश्रित वर्जन्स को एक छोटे विंडो के लिए सहन कर सकें (blue/green, canary, rolling)। यह तभी काम करता है जब आपके डेटाबेस परिवर्तन भी चरणबद्ध हों।
एक व्यावहारिक नियम है विस्तार → माइग्रेट → संकुचन:
- विस्तार (Expand): नए कॉलम/टेबल/इंडेक्स जोड़ें बिना पुराने को तोड़े।
- माइग्रेट (Migrate): बैचों में डेटा बैकफिल करें (अक्सर प्रति-टेनेन्ट) और सत्यापित करें।
- संकुचन (Contract): पुराने फ़ील्ड्स निकालें केवल तब जब सभी ऐप इंस्टेंसेज उनसे मुक्त हों।
हॉट टेबल्स के लिए बैकफिल्स को क्रमिक रूप से (और थ्रॉटल कर) चलाएँ, वरना आप माइग्रेशन के दौरान खुद एक नोइज़ी-नेबर घटना बना देंगे।
सुरक्षित रोलआउट के लिए प्रति-टेनेन्ट फीचर फ्लैग्स
टेनेन्ट-स्तरीय फीचर फ्लैग्स आपको कोड को ग्लोबली शिप करने में सक्षम करते हैं जबकि व्यवहार को चयनात्मक रूप से सक्षम करना आसान बनाते हैं।
यह समर्थन करता है:
- कुछ टेनेन्ट्स के लिए अर्ली एक्सेस प्रोग्राम
- प्रभावित टेनेन्ट्स के लिए केवल फीचर डिसेबल करके तेज़ रोलबैक
- A/B प्रयोग बिना डिप्लॉयमेंट विभाजन के
फ़्लैग सिस्टम को ऑडिटेबल रखें: किसने क्या सक्षम किया, किस टेनेन्ट के लिए, और कब।
संस्करणन और बैकवर्ड कम्पैटिबिलिटी अपेक्षाएँ
अनुमान लगाएँ कि कुछ टेनेन्ट्स विन्यास, इंटीग्रेशन्स, या उपयोग पैटर्न में पीछे रह सकते हैं। APIs और इवेंट्स को स्पष्ट वर्शनिंग के साथ डिजाइन करें ताकि नए प्रोड्यूसर्स पुराने कंज्यूमर्स को ब्रेक न करें।
आंतरिक अपेक्षाएँ सामान्यतः:
- माइग्रेशन विंडोज़ के दौरान नए और पुराने शेप्स दोनों को पढ़ने में नई रिलीज़ सक्षम होनी चाहिए।
- डिप्रेकेशन्स के लिए प्रकाशित टाइमलाइन चाहिए (भले ही यह सिर्फ आंतरिक नोट्स और ग्राहक ईमेल टेम्पलेट हो)।
टेनेन्ट-विशेष कॉन्फ़िगरेशन मैनेजमेंट
टेनेन्ट कॉन्फ़िग को प्रोडक्ट सतह की तरह ट्रीट करें: इसे वैलिडेशन, डिफ़ॉल्ट, और चेंज हिस्ट्री चाहिए।
कॉन्फ़िगरेशन को कोड से अलग स्टोर करें (और आदर्श रूप से रनटाइम सीक्रेट्स से अलग), और जब कॉन्फ़िग अमान्य हो तो एक सेफ-मोड फ़ॉलबैक सपोर्ट करें। एक हल्का इंटरनल पेज जैसे /settings/tenants इन्सिडेंट रिस्पॉन्स और स्टैज्ड रोलआउट के दौरान घंटे बचा सकता है।
AI-जनित आर्किटेक्चर कैसे मदद करते हैं (और उनकी सीमाएँ)
कोडबेस का स्वामित्व रखें
जब आपकी आर्किटेक्चर परिपक्व हो, स्रोत कोड एक्सपोर्ट के साथ पूर्ण स्वामित्व बनाए रखें.
AI मल्टी-टेनेन्ट SaaS के लिए शुरुआती आर्किटेक्चर सोच को तेज़ कर सकता है, पर यह इंजीनियरिंग जजमेंट, टेस्टिंग, या सिक्योरिटी रिव्यू का विकल्प नहीं है। इसे उच्च-गुणवत्ता ब्रेनस्टॉर्मिंग पार्टनर मानें जो ड्राफ्ट बनाता है—फिर हर अनुमान को सत्यापित करें।
AI-जनित आर्किटेक्चर को क्या करना चाहिए (और क्या नहीं)
AI विकल्पों का निर्माण करने और सामान्य विफलता मोड (जैसे टेनेन्ट कॉन्टेक्स्ट कहाँ खो सकता है, या साझा संसाधन कहाँ आश्चर्य पैदा कर सकते हैं) को हाइलाइट करने में उपयोगी है। इसे आपका मॉडल तय नहीं करना चाहिए, कम्प्लायंस गारंटी नहीं देनी चाहिए, और प्रदर्शन सत्यापित नहीं करना चाहिए। यह आपकी असली ट्रैफ़िक, टीम की क्षमताओं, या लेगेसी इंटीग्रेशन्स में छिपे किन्हीं एज केस को नहीं देख सकता।
इनपुट्स जो मायने रखते हैं: आवश्यकताएँ, बाधाएँ, जोखिम, वृद्धि
आउटपुट की गुणवत्ता उस पर निर्भर करती है जो आप उसे देते हैं। सहायक इनपुट्स में शामिल हैं:
- आज बनाम 12–24 महीनों में टेनेन्ट काउंट, और प्रति-टेनेन्ट अपेक्षित डेटा वॉल्यूम
- अलगाव आवश्यकताएँ (अनुबंधीय, नियामक, ग्राहक अपेक्षाएँ)
- बजट और ऑपरेशनल क्षमता (ऑन-कॉल परिपक्वता, SRE सपोर्ट, टूलिंग)
- लेटेंसी लक्ष्य, पीक उपयोग पैटर्न, और टेनेन्ट द्वारा बर्स्टिनेस
- जोखिम सहिष्णुता: अगर एक टेनेन्ट दूसरे को प्रभावित करे तो क्या होगा?
AI से पैटर्न विकल्प और ट्रेड-ऑफ़ निकालवाना
2–4 उम्मीदवार डिजाइन पूछें (उदा.: डेटाबेस-प्रति-टेनेन्ट बनाम स्कीमा-प्रति-टेनेन्ट बनाम रो-लेवल अलगाव) और ट्रेड-ऑफ़ का स्पष्ट सारांश मांगें: लागत, ऑपरेशनल जटिलता, ब्लास्ट-रेडियस, माइग्रेशन प्रयास, और स्केलिंग सीमाएँ। AI उन गोटचाज़ को सूचीबद्ध करने में अच्छा है जिन्हें आप अपनी टीम के लिए डिजाइन प्रश्नों में बदल सकते हैं।
यदि आप "ड्राफ्ट आर्किटेक्चर" से कार्यशील प्रोटोटाइप तक जल्दी जाना चाहते हैं, तो एक vibe-coding प्लेटफ़ॉर्म जैसे Koder.ai आपको चैट के जरिए उन चयनों को एक वास्तविक ऐप स्केलेटन में बदलने में मदद कर सकता है—अक्सर React फ्रंटेंड और Go + PostgreSQL बैकएंड के साथ—ताकि आप जल्दी टेनेन्ट कॉन्टेक्स्ट प्रॉपैगेशन, रेट लिमिट्स, और माइग्रेशन वर्कफ़्लो को मान्य कर सकें। प्लानिंग मोड और स्नैपशॉट/रोलबैक जैसी सुविधाएँ विशेष रूप से उपयोगी हैं जब आप मल्टी-टेनेन्ट डेटा मॉडल पर इटरेट कर रहे हों।
AI से थ्रेट मॉडल और चेकलिस्ट आइटम बनवाना
AI एक साधारण थ्रेट मॉडल ड्राफ्ट कर सकता है: एंट्री पॉइंट्स, ट्रस्ट बाउंड्रीज़, टेनेन्ट-कॉन्टेक्स्ट प्रॉपैगेशन, और सामान्य गलतियाँ (जैसे बैकग्राउंड जॉब्स पर ऑथोराइज़ेशन चेक्स का मिस होना)। इसे PRs और रनबुक्स के लिए रिव्यू चेकलिस्ट बनाने में उपयोग करें—पर वास्तविक सुरक्षा विशेषज्ञता और अपनी पिछली घटनाओं के साथ सत्यापित करें।
आपकी टीम के लिए एक व्यावहारिक चयन चेकलिस्ट
मल्टी-टेनेन्ट दृष्टिकोण चुनना "बेस्ट प्रैक्टिस" से अधिक फिट के बारे में है: आपका डेटा संवेदनशीलता, आपकी वृद्धि दर, और आप कितना ऑपरेशनल जटिलता उठा सकते हैं।
कदम-दर-कदम चेकलिस्ट (30-मिनट वर्कशॉप के लिए)
-
डेटा: किन डेटा को टेनेन्ट्स के बीच साझा किया गया है (यदि कोई)? क्या कभी भी सह-स्थित नहीं होना चाहिए?
-
पहचान: टेनेन्ट पहचान कहाँ रहती है (इनवाइट लिंक, डोमेन, SSO क्लेम)? हर अनुरोध पर टेनेन्ट संदर्भ कैसे स्थापित होता है?
-
अलगाव: अपना डिफ़ॉल्ट अलगाव स्तर तय करें (रो/स्कीमा/डेटाबेस) और अपवादों की पहचान करें (उदा., एंटरप्राइज़ ग्राहक जिन्हें मजबूत अलगाव चाहिए)।
-
स्केलिंग: पहली स्केलिंग प्रेसर की पहचान करें जिसकी आप उम्मीद करते हैं (स्टोरेज, रीड ट्रैफ़िक, बैकग्राउंड जॉब्स, एनालिटिक्स) और उसे संबोधित करने वाला सरलतम पैटर्न चुनें।
इंजीनियरों और सिक्योरिटी रिव्यूअर्स के साथ सत्यापित करने के प्रश्न
- अगर एक डेवलपर फ़िल्टर भूल जाता है तो हम क्रॉस-टेनेन्ट एक्सेस कैसे रोकेंगे?
- प्रति-टेनेन्ट ऑडिट कहानी क्या है (किसने क्या किया, कब)?
- हम प्रति-टेनेन्ट डेटा डिलीशन और रिटेंशन को कैसे संभालते हैं?
- एक खराब माइग्रेशन या रनअवे क्वेरी का ब्लास्ट-रेडियस क्या है?
- क्या हम पर-टेनेन्ट थ्रॉटल, रेट-लिमिट, और बजट कर सकते हैं?
गहरे डिजाइन वर्क की आवश्यकता संकेत करने वाले रेड फ्लैग्स
- "हम बाद में टेनेन्ट चेक जोड़ देंगे।"
- साझा एडमिन टूल्स जो बिना कठोर नियंत्रण के सब कुछ देख सकते हैं।
- प्रति-टेनेन्ट बैकअप/रिस्टोर या इन्सिडेंट रिस्पॉन्स की कोई योजना नहीं।
- एक ही क्यू/वर्कर पूल और बिना पर-टेनेन्ट फेयरनेस के।
नमूना "सिफारिश: अगले कदम" सारांश
सिफारिश: रो-लेवल अलगाव के साथ शुरू करें + सख्त टेनेन्ट-कॉन्टेक्स्ट प्रवर्तन, प्रति-टेनेन्ट थ्रॉटल्स जोड़ें, और उच्च-जोखिम टेनेन्ट्स के लिए स्कीमा/डेटाबेस अलगाव की अपग्रेड पथ परिभाषित करें।
अगले कार्य (2 सप्ताह): टेनेन्ट सीमाओं का थ्रेट-मॉडल बनाएं, एक एンドपॉइंट में प्रवर्तन का प्रोटोटाइप बनाएं, और स्टेजिंग कॉपी पर माइग्रेशन की रिहर्सल चलाएँ। रोलआउट मार्गदर्शन के लिए देखें /blog/tenant-release-strategies।