27 सित॰ 2025·8 मिनट
ब्लू/ग्रीन और कैनरी डिप्लॉयमेंट: एक स्पष्ट रिलीज़ रणनीति
कब ब्लू/ग्रीन बनाम कैनरी चुनें, ट्रैफिक शिफ्टिंग कैसे काम करती है, क्या मॉनिटर करें, और सुरक्षित रिलीज़ के लिए व्यावहारिक रोलआउट व रोलबैक चरण क्या हैं—सब क्लियर तरीके से।
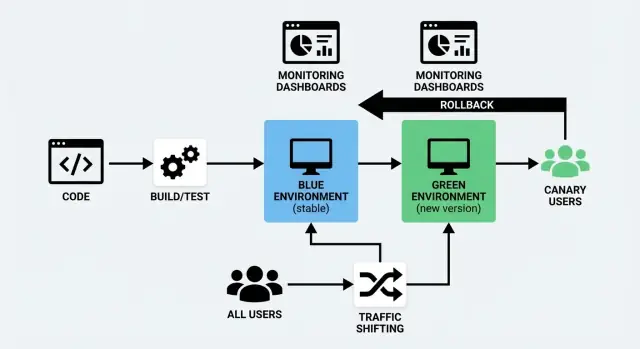
ब्लू/ग्रीन और कैनरी डिप्लॉयमेंट का मतलब
नया कोड भेजना जोखिमभरा होता है इसलिए कि आप तब तक असल व्यवहार नहीं देखते जब तक असली यूज़र उस पर नहीं आते। ब्लू/ग्रीन और कैनरी—दोनों—इस जोखिम को कम करने के सामान्य तरीके हैं और साथ ही डाउनटाइम को काफी कम रखते हैं।
सरल शब्दों में ब्लू/ग्रीन
एक ब्लू/ग्रीन डिप्लॉयमेंट दो अलग पर समान वातावरण का उपयोग करता है:
- ब्लू: वह वर्ज़न जो अभी यूज़र्स को सर्व कर रहा है ("लाइव" सेटअप)।
- ग्रीन: दूसरा, तैयार सेटअप जहाँ आप नया वर्ज़न डिप्लॉय करते हैं।
आप ग्रीन वातावरण बैकग्राउंड में तैयार करते हैं—नया बिल्ड डिप्लॉय करें, चेक चलाएँ, वॉर्म-अप करें—फिर जब आप सुनिश्चित हों तो ट्रैफिक ब्लू से ग्रीन पर स्विच कर देते हैं। कुछ गलत होने पर आप जल्दी से वापस स्विच कर सकते हैं।
कुंजी विचार "दो रंग" नहीं है, बल्कि एक साफ़, उल्टने योग्य कटओवर है।
सरल शब्दों में कैनरी
एक कैनरी रिलीज़ क्रमिक रोलआउट है। एक बार में सभी को स्विच करने के बजाय, आप नया वर्ज़न पहले यूज़र्स के एक छोटे हिस्से (उदाहरण: 1–5%) को भेजते हैं। सब कुछ ठीेक लगने पर आप धीरे-धीरे रोलआउट बढ़ाते हैं जब तक कि 100% ट्रैफिक नए वर्ज़न पर न आ जाए।
कुंजी विचार है असल ट्रैफ़िक से सीखना इससे पहले कि आप पूरी तरह प्रतिबद्ध हों।
साझा लक्ष्य: कम जोखिम और कम डाउनटाइम
दोनों दृष्टिकोण ऐसे डिप्लॉयमेंट रणनीतियाँ हैं जो लक्ष्य रखती हैं:
- जब कुछ टूटे तो यूज़र पर प्रभाव कम करना
- ज़ीरो डाउनटाइम डिप्लॉय को समर्थन देना (या जितना संभव हो नज़दीक)
- रोलबैक को कम तनावपूर्ण और अधिक पूर्वानुमेय बनाना
वे यह अलग-अलग तरीकों से करते हैं: ब्लू/ग्रीन तेज़ स्विच पर फोकस करता है, जबकि कैनरी नियंत्रित एक्सपोज़र के लिए ट्रैफिक शिफ्टिंग पर।
कोई एक "सर्वोत्तम" विकल्प नहीं
कोई भी दृष्टिकोण स्वचालित रूप से बेहतर नहीं है। सही चुनाव इस पर निर्भर करता है कि आपका प्रोडक्ट कैसे उपयोग होता है, आप अपने परीक्षणों पर कितने भरोसेमंद हैं, आपको प्रतिक्रिया कितनी जल्दी चाहिए, और आप किस प्रकार की विफलताओं से बचना चाह रहे हैं।
कई टीमें इन्हें मिलाकर भी उपयोग करती हैं—अधिकारों की सादगी के लिए ब्लू/ग्रीन और क्रमिक उपयोग के लिए कैनरी तकनीकें।
आगे के सेक्शनों में हम इन्हें सीधे तुलना करेंगे और दिखाएंगे कि कब कौन सा अच्छा काम करता है।
ब्लू/ग्रीन बनाम कैनरी: त्वरित तुलना
ब्लू/ग्रीन और कैनरी दोनों ही तरीक़े हैं बिना यूज़र्स को बाधित किए परिवर्तन रिलीज़ करने के—लेकिन वे इस बात में अलग हैं कि नया वर्ज़न कैसे ट्रैफिक पाता है।
ट्रैफिक कैसे स्विच होता है
ब्लू/ग्रीन दो पूर्ण वातावरण चलाता है: “ब्लू” (वर्तमान) और “ग्रीन” (नया)। आप ग्रीन को मान्य करते हैं, फिर सारा ट्रैफिक एक बार में स्विच करते हैं—जैसे एक नियंत्रित स्विच पलटना।
कैनरी नया वर्ज़न पहले यूज़र्स के एक छोटे हिस्से को देता है (उदाहरण 1–5%), फिर आप वास्तविक प्रदर्शन देखते हुए धीरे-धीरे ट्रैफिक शिफ्ट करते हैं।
वास्तव में मायने रखने वाले फायदे और नुकसान
| कारक | ब्लू/ग्रीन | कैनरी |
|---|---|---|
| स्पीड | सत्यापन के बाद बहुत तेज कटओवर | डिज़ाइन के अनुसार धीमा (रैम्प्ड रोलआउट) |
| जोखिम | मध्यम: स्विच के बाद खराब रिलीज़ सभी पर असर कर सकती है | कम: समस्याएँ अक्सर पूरी रोलआउट से पहले दिख जाती हैं |
| जटिलता | मध्यम (दो वातावरण, साफ़ स्विच) | अधिक (ट्रैफिक स्प्लिटिंग, विश्लेषण, क्रमिक चरण) |
| लागत | अधिक (रोलआउट के दौरान आप क्षमता दोगुनी कर रहे होते हैं) | अक्सर कम (आप मौजूदा क्षमता का उपयोग कर रैंप कर सकते हैं) |
| सबसे अच्छा उपयोग | बड़े, समन्वित बदलाव | बार-बार छोटे सुधार |
एक सरल निर्णय दिशानिर्देश
जब आप एक साफ़, पूर्वानुमेय कटओवर और तेज़ वापस-आने का विकल्प चाहते हैं—विशेषकर बड़े बदलावों, माईग्रेशन, या उन रिलीज़ के लिए जिन्हें "पुराना बनाम नया" स्पष्ट विभाजन चाहिए—तो ब्लू/ग्रीन चुनें।
जब आप अक्सर शिप करते हैं, असली उपयोग से सुरक्षित रूप से सीखना चाहते हैं, और ब्लास्ट रेडियस को कम करना पसंद करते हैं, तो कैनरी चुनें।
अगर आप अनिश्चित हैं, ऑपरेशनल सादगी के लिए ब्लू/ग्रीन से शुरू करें, फिर उच्च-जोखिम सेवाओं के लिए मॉनिटरिंग और रोलबैक व्यवहार मजबूत होने पर कैनरी जोड़ें।
कब ब्लू/ग्रीन सही है
ब्लू/ग्रीन अच्छा विकल्प है जब आप रिलीज़ को एक "स्विच" जैसा महसूस कराना चाहते हैं। आप दो प्रोडक्शन-लाइक वातावरण चलाते हैं: ब्लू (वर्तमान) और ग्रीन (नया)। ग्रीन सत्यापित होने पर आप उपयोगकर्ताओं को वहां रूट करते हैं।
जब आपको लगभग नज़दीकी-शून्य डाउनटाइम चाहिए
यदि आपका प्रोडक्ट दृश्यमान मेंटेनेंस को बर्दाश्त नहीं कर सकता—चेकआउट, बुकिंग सिस्टम, लॉग्ड-इन डैशबोर्ड—तो ब्लू/ग्रीन मदद करता है क्योंकि नया वर्ज़न शुरू, वॉर्म-अप और चेक किया जाता है उससे पहले कि असली यूज़र्स भेजे जाएँ। अधिकांश "डिप्लॉय समय" ग्राहकों के सामने नहीं, साइड में होता है।
आप सबसे सरल रोलबैक चाहते हैं
रोलबैक अक्सर केवल ट्रैफिक वापस ब्लू पर रूट करना है। यह तब मूल्यवान है जब:
- रिलीज़ को मिनटों में उल्टा करना ज़रूरी हो
- आप इमरजेंसी हॉटफिक्स से बचना चाहते हों
- आपको एक स्पष्ट, दोहरने योग्य फेलियर रिस्पॉन्स चाहिए
मुख्य लाभ यह है कि रोलबैक को फिर से बिल्ड या डिप्लॉय करने की ज़रूरत नहीं—यह ट्रैफिक स्विच है।
आपका डेटाबेस परिवर्तन संगत रखा जा सके
ब्लू/ग्रीन तब सबसे आसान है जब डेटाबेस माइग्रेशन बैकवर्ड कंपैटिबल हों, क्योंकि कुछ समय के लिए ब्लू और ग्रीन दोनों मौजूद रह सकते हैं।
अच्छे फिट में आते हैं:
- ऐडिटिव स्कीमा बदलाव (नया nullable कॉलम, नई टेबल)
- डेटा फॉर्मैट का विस्तार जिसको पुराना कोड इग्नोर कर सके
जो जोखिम भरे हैं: कॉलम हटाना, फ़ील्ड का नाम बदलना, या अर्थ बदलना—ये "स्विच-बैक" वादा तोड़ सकते हैं जब तक आप मल्टी-स्टेप माइग्रेशन न करें।
आप डुप्लिकेट वातावरण और रूटिंग कंट्रोल वहन कर सकते हैं
ब्लू/ग्रीन अतिरिक्त क्षमता (दो स्टैक्स) और ट्रैफिक निर्देशित करने का तरीका मांगता है (लोड बैलेंसर, इgress या प्लेटफ़ॉर्म राउटिंग)। यदि आपके पास पहले से ऑटोमेशन है जो वातावरण provision करता है और एक साफ रूटिंग लीवर है, तो ब्लू/ग्रीन हाई-कॉन्फिडेंस, कम ड्रामा रिलीज़ के लिए व्यवहार्य डिफ़ॉल्ट बन जाता है।
कब कैनरी रिलीज़ बेहतर है
कैनरी रिलीज़ वह रणनीति है जहाँ आप परिवर्तन को पहले असली उपयोगकर्ताओं के एक छोटे से हिस्से पर रोल आउट करते हैं, वहाँ से सीखते हैं, फिर विस्तार करते हैं। यह तब सही है जब आप बिना बड़े "सभी एक साथ" रिलीज़ के जोखिम घटाना चाहते हैं।
आपके पास बहुत ट्रैफिक और स्पष्ट संकेतक हैं
कैनरी उच्च-ट्रैफिक एप्स के लिए सबसे अच्छा काम करता है क्योंकि 1–5% भी जल्दी सार्थक डेटा दे सकता है। यदि आप पहले से स्पष्ट मेट्रिक्स (एरर रेट, लेटेंसी, कन्वर्ज़न, चेकआउट पूरा होना, API टाइमआउट) ट्रैक करते हैं, तो आप टेस्ट वातावरणों पर निर्भर रहने की बजाय असली उपयोग के पैटर्न पर रिलीज़ को मान्य कर सकते हैं।
आप प्रदर्शन और एज केस के बारे में चिंतित हैं
कुछ समस्याएं सिर्फ असली लोड पर ही दिखती हैं: धीमी DB क्वेरीज़, कैश मिस, क्षेत्रीय लेटेंसी, दुर्लभ डिवाइस या यूज़र फ्लो। कैनरी से आप पुष्टि कर सकते हैं कि बदलाव एरर्स बढ़ा नहीं रहा या प्रदर्शन घटा नहीं रहा है, इससे पहले कि आप सभी पर लागू करें।
आपको चरणबद्ध रोलआउट चाहिए, न कि एकल कटओवर
यदि आपका प्रोडक्ट बार-बार शिप होता है, कई टीमें योगदान देती हैं, या बदलाव धीरे-धीरे पेश किए जा सकते हैं (UI बदलाव, प्राइसिंग प्रयोग, सिफारिश लॉजिक), तो कैनरी रोलआउट प्राकृतिक रूप से फिट होते हैं। आप 1% → 10% → 50% → 100% कर सकते हैं, जैसा कि आप देखते हैं।
फीचर फ़्लैग्स आपके टूलकिट का हिस्सा हैं
कैनरी खासकर तब अच्छी जोड़ी बनता है जब आपके पास फीचर फ़्लैग्स हों: आप कोड को सुरक्षित रूप से डिप्लॉय कर सकते हैं, फिर फ़ंक्शनलिटी को यूज़र्स/रीजन/खाते के सब्सेट के लिए सक्षम कर सकते हैं। इससे रोलबैक कम नाटकीय हो जाता है—अक्सर केवल फ़्लैग बंद करना होता है।
यदि आप प्रोग्रेसिव डिलिवरी की ओर बढ़ रहे हैं, तो कैनरी प्रायः फ्लेक्सिबल शुरुआत होती है।
देखें: /blog/feature-flags-and-progressive-delivery
ट्रैफिक शिफ्टिंग का बेसिक (जर्गन के बिना)
ट्रैफिक शिफ्टिंग का मतलब बस यह नियंत्रित करना है कि कौन नए वर्ज़न को पाता है और कब। सभी को एक बार में पलटने के बजाय आप रिक्वेस्ट्स को धीरे-धीरे (या चयनात्मक रूप से) पुराने वर्ज़न से नए पर मूव करते हैं। यही ब्लू/ग्रीन और कैनरी—दोनों—का व्यावहारिक केंद्र है, और यही ज़ीरो डाउनटाइम डिप्लॉय को यथार्थवादी बनाता है।
"स्टीयरिंग व्हील": कहाँ ट्रैफिक रूट होता है
आप स्टैक के कुछ सामान्य पॉइंट्स पर ट्रैफिक शिफ्ट कर सकते हैं। सही विकल्प इस बात पर निर्भर करता है कि आप क्या चला रहे हैं और कितना फाइन-ग्रेन कंट्रोल चाहिए।
- लोड बैलेंसर: इनकमिंग रिक्वेस्ट्स को दो वातावरणों या सर्वरों के सेट के बीच बांटता है।
- इंग्रेस कंट्रोलर (Kubernetes): नियमों के आधार पर अलग Services को ट्रैफ़िक रूट करता है।
- सर्विस मैश: सेवाओं के बीच ट्रैफिक को सटीक नियमों और बेहतर दृश्यता के साथ नियंत्रित करता है।
- CDN / एज राउटिंग: तब उपयोगी जब आप यूज़र्स के निकट रूटिंग निर्णय चाहते हैं, अक्सर वेब ट्रैफ़िक के लिए।
आपको हर लेयर की ज़रूरत नहीं। रूटिंग फैसलों के लिए एक "स्रोत-ए-ट्रूथ" चुनें ताकि आपका रिलीज़ मैनेजमेंट अनुमान का काम न बन जाए।
ट्रैफिक स्प्लिट करने के सामान्य तरीके
अधिकतर टीमें इन तरीकों में से एक (या मिश्रण) का उपयोग करती हैं:
- प्रतिशत-आधारित: 1% → 5% → 25% → 50% → 100%। क्लासिक कैनरी पैटर्न।
- हेडर-आधारित: एक विशिष्ट हेडर वाले रिक्वेस्ट्स (उदा. QA टूल्स या इंटरनल टेस्टर्स से) को नए वर्ज़न पर रूट करें।
- यूज़र कोहॉर्ट्स: विशिष्ट समूह पहले—कर्मचारी, बीटा यूज़र्स, एक क्षेत्र, या ग्राहक टियर।
प्रतिशत समझाने में आसान है, पर कोहॉर्ट्स अक्सर सुरक्षित होते हैं क्योंकि आप नियंत्रित कर सकते हैं कौन बदलाव देखता है (और पहले घंटे में अपने सबसे बड़े ग्राहक को आश्चर्य में नहीं डालते)।
सेशन और कैश: दो “गोट्चाज़”
दो चीज़ें अक्सर अच्छी योजना को भी तोड़ देती हैं:
स्टिकी सेशन्स (सेशन अफ़िनिटी). अगर सिस्टम किसी यूज़र को एक सर्वर/वर्ज़न से जोड़ता है, तो 10% स्प्लिट 10% जैसा व्यवहार नहीं कर सकता। यह बग्स भी पैदा कर सकता है जब यूज़र सेशन के दौरान वर्ज़न बदलता है। यदि हो सके तो साझा सेशन स्टोरेज उपयोग करें या सुनिश्चित करें कि रूटिंग एक यूज़र को लगातार एक ही वर्ज़न पर रखे।
कैश वॉर्मिंग. नए वर्ज़न अक्सर कोल्ड कैशेज (CDN, एप्लिकेशन कैश, DB क्वेरी कैश) को टार्गेट करते हैं। इससे प्रदर्शन में कमी जैसा दिख सकता है भले ही कोड ठीक हो। रैंप करने से पहले विशेष रूप से हाई-ट्रैफ़िक पेज और महंगे एंडपॉइंट्स के लिए कैश वॉर्म करने का समय प्लान करें।
ट्रैफिक बदलाव को नियंत्रित ऑपरेशन बनाइए
रूटिंग परिवर्तन को प्रोडक्शन चेंज की तरह ट्रीट करें, किसी आकस्मिक बटन क्लिक की तरह नहीं।
दस्तावेज़ करें:
- कौन ट्रैफिक स्प्लिट बदल सकता है
- कैसे इसे मंजूरी दी जाती है (ऑन-कॉल? रिलीज़ मैनेजर? चेंज टिकट?)
- कहाँ यह किया जाता है (लोड बैलेंसर कॉन्फ़िग, इंग्रेस नियम, मैश पॉलिसी)
- "स्टॉप" कैसा दिखता है (रोलआउट को रोकने और रोलबैक प्लान को फॉलो करने का ट्रिगर)
यह छोटा सा गवर्नेंस यह रोकता है कि कोई भली-भांति व्यक्ति "बस इसे 50% पर धकेल दे" जबकि आप अभी भी देख रहे हैं कि कैनरी हेल्दी है या नहीं।
रोलआउट के दौरान क्या मॉनिटर करें
फुल-स्टैक तेज़ी से बनाएं
सरल चैट से React वेब ऐप और Go और PostgreSQL बैकएंड जनरेट करें।
रोलआउट केवल "क्या डिप्लॉय सफल हुआ?" नहीं है—यह है "क्या असली यूज़र्स का अनुभव बदतर हो रहा है?" ब्लू/ग्रीन या कैनरी के दौरान शांत रहने का सबसे आसान तरीका है कुछ छोटे संकेत देखना जो बताते हैं: क्या सिस्टम हेल्दी है, और क्या बदलाव ग्राहकों को नुकसान पहुँचा रहा है?
चार मुख्य संकेत: एरर, लेटेंसी, सैचुरेशन, यूज़र इम्पैक्ट
एरर रेट: HTTP 5xx, रिक्वेस्ट फेल्योर, टाइमआउट और डिपेंडेंसी एरर (DB, पेमेंट, थर्ड-पार्टी API)। एक कैनरी जो छोटी एरर्स बढ़ाता है वही सपोर्ट लोड बड़ा कर सकती है।
लेटेंसी: p50 और p95 (और अगर है तो p99) देखें। औसत लेटेंसी स्थिर होते हुए भी लॉन्ग-टेल स्लोडाउन यूज़र्स को प्रभावित कर सकता है।
सैचुरेशन: सिस्टम कितना "भरा" है—CPU, मेमोरी, डिस्क IO, DB कनेक्शन, क्व्यू डेप्थ, थ्रेड पूल। सैचुरेशन समस्याएँ अक्सर पूर्ण आउटेज से पहले दिखती हैं।
यूज़र-इम्पैक्ट संकेत: जो यूज़र्स वास्तविक रूप में अनुभव करते हैं—चेकआउट फेल्योर, साइन-इन सक्सेस रेट, सर्च परिणाम, ऐप क्रैश रेट, महत्वपूर्ण पेज लोड टाइम्स। ये अक्सर इंफ्रास्ट्रक्चर आँकड़ों से ज़्यादा मायने रखते हैं।
एक "रिलीज़ डैशबोर्ड" बनाइए जिसे हर कोई पढ़ सके
एक छोटा डैशबोर्ड बनाइए जो एक स्क्रीन पर फिट हो और रिलीज़ चैनल में शेयर किया जाए। हर रोलआउट में इसे समान रखें ताकि लोग ग्राफ़ ढूँढने में समय न गंवाएँ।
शामिल करें:
- एरर रेट (कुल + प्रमुख एंडपॉइंट्स)
- लेटेंसी (कड़ी पथों के लिए p50/p95)
- सैचुरेशन (आपके स्टैक के टॉप 3 बॉटलनेक्स, जैसे ऐप CPU, DB कनेक्शन्स, क्व्यू डेप्थ)
- यूज़र-इम्पैक्ट KPI (आपके टॉप 1–3 बिज़नेस-क्रिटिकल फ्लोज़)
यदि आप कैनरी रिलीज़ चला रहे हैं, तो वर्ज़न/इंस्टेंस ग्रुप के हिसाब से मेट्रिक्स सेगमेंट करें ताकि आप कैनरी बनाम बेसलाइन सीधे तुलना कर सकें। ब्लू/ग्रीन के लिए, कटओवर विंडो के दौरान नए एनवायरनमेंट बनाम पुराने की तुलना करें।
रोक/रोलबैक निर्णयों के लिए स्पष्ट थ्रेशहोल्ड सेट करें
शुरू करने से पहले नियम तय करें। उदाहरण थ्रेसहोल्ड:
- एरर रेट बेसलाइन से X% बढ़ जाए Y मिनट के लिए
- p95 लेटेंसी एक फिक्स्ड लिमिट पार कर जाए (या बेसलाइन से X% बढ़े)
- कोई यूज़र-इम्पैक्ट KPI न्यूनतम स्वीकार्य मान से नीचे चला जाए
सटीक संख्याएँ आपकी सेवा पर निर्भर करेंगी, पर महत्वपूर्ण हिस्सा सहमति है। यदि हर कोई रोलबैक प्लान और ट्रिगर्स जानता है, तो ग्राहक प्रभावित होने पर बहस टलती है।
रोलआउट विंडो के दौरान केंद्रित अलर्ट्स
रोलआउट विंडो के लिए (या अस्थायी रूप से) अलर्ट्स जोड़ें/कठोर करें:
- 5xx/टाइमआउट में अनपेक्षित स्पाइक
- प्रमुख रूट्स पर अचानक लेटेंसी रिग्रेशन
- कनेक्शन पूल, क्व्यूज़ में तेज़ी से वृद्धि
अलर्ट्स को actionable रखें: "क्या बदला, कहाँ, और अगला कदम क्या है।" यदि अलर्ट शोर से भरे हों तो लोग उस एक सिग्नल को भी मिस कर देंगे जो ट्रैफिक शिफ्टिंग के दौरान सच में मायने रखता है।
प्री-रिलीज़ चेक्स जो समस्याएँ पकड़ते हैं
अधिकांश रोलआउट फेल्योर बड़े बग से नहीं होते—वे छोटे मेल-नामेल से होते हैं: ग़ायब कॉन्फिग वैल्यू, खराब DB माइग्रेशन, एक्सपायर्ड सर्टिफ़िकेट, या एक इंटीग्रेशन जो नए एनवायरनमेंट में अलग व्यवहार करता है। प्री-रिलीज़ चेक्स इन्हें पकड़ने का मौका देते हैं जबकि ब्लास्ट रेडियस अभी भी छोटा है।
हेल्थ चेक और स्मोक टेस्ट से शुरू करें
किसी भी ट्रैफिक शिफ्ट से पहले (ब्लू/ग्रीन या कैनरी) पुष्टि करें कि नया वर्ज़न जीवित है और रिक्वेस्ट्स सर्व कर सकता है।
- सुनिश्चित करें कि ऐप हेल्थ एंडपॉइंट्स OK रिपोर्ट कर रहे हैं (सिर्फ प्रोसेस रन कर रहा है यह पर्याप्त नहीं)
- डिपेंडेंसी सत्यापित करें: DB, कैश, क्व्यू, ऑब्जेक्ट स्टोरेज, ईमेल/SMS प्रोवाइडर
- सीक्रेट्स और एनवायरनमेंट वेरिएबल्स मौजूद और सही स्कोप में हों
नए एनवायरनमेंट पर त्वरित एंड-टू-एंड टेस्ट चलाएँ
यूनिट टेस्ट अच्छे हैं, पर वे डिप्लॉय की गई सिस्टम को प्रमाणित नहीं करते। नया एनवायरनमेंट पर एक छोटी, ऑटोमेटेड एंड-टू-एंड सूट चलाएँ जो मिनटों में खत्म हो जाए, घंटे में नहीं।
केंद्रित रहें उन फ्लोज़ पर जो सर्विस बाउंडरी पार करते हैं (वेब → API → DB → थर्ड-पार्टी) और हर प्रमुख इंटीग्रेशन के लिए कम से कम एक "वास्तविक" रिक्वेस्ट शामिल करें।
क्रिटिकल यूज़र जर्नी की वैरिफ़िकेशन करें
ऑटोमेटेड टेस्ट कभी-कभी स्पष्ट चीज़ें भी छोड देते हैं। अपने कोर वर्कफ़्लोज़ का लक्षित, मानव-सुलभ सत्यापन करें:
- लॉगिन और पासवर्ड रीसेट
- चेकआउट या पेमेंट फ्लो (फेल्योर पाथ सहित)
- कोर "क्रिएट/अपडेट/डिलीट" एक्शन्स
यदि आप कई रोल्स सपोर्ट करते हैं (ऐडमिन बनाम कस्टमर), तो कम से कम एक जर्नी प्रति रोल का सैंपल लें।
एक प्री-रिलीज़ रेडीनेस चेकलिस्ट रखें
एक चेकलिस्ट ट्राइबल नॉलेज को दोहराने योग्य रणनीति में बदल देती है। इसे छोटा और क्रियात्मक रखें:
- DB माइग्रेशन लागू और उलटने योग्य (या स्पष्ट रूप से सुरक्षित)
- ऑब्ज़र्वेबिलिटी रेडी: लॉग्स, डैशबोर्ड, अलर्ट्स
- रोलबैक प्लान रिव्यू किया हुआ (कौन, कैसे, और "स्टॉप" क्या है)
जब ये चेक रूटीन बन जाएँ, ट्रैफिक शिफ्टिंग एक नियंत्रित कदम बन जाती है—न कि एक विश्वास का छलांग।
ब्लू/ग्रीन रोलआउट: व्यावहारिक प्लेबुक
विश्वास के साथ डिप्लॉय करें
स्नैपशॉट और रोलबैक का आसान तरीका देकर अपने ऐप को डिप्लॉय और होस्ट करें।
ब्लू/ग्रीन रोलआउट सबसे आसान तब होता है जब आप इसे एक चेकलिस्ट की तरह चलाते हैं: तैयार करें, डिप्लॉय करें, सत्यापित करें, स्विच करें, अवज़रव करें, फिर क्लीन-अप करें।
1) ग्रीन में डिप्लॉय करें (यूज़र्स को छेड़े बिना)
नया वर्ज़न ग्रीन एनवायरनमेंट में भेजें जबकि ब्लू असली ट्रैफिक सर्व करता रहे। कॉन्फ़िग्स और सीक्रेट्स मेल खाने चाहिए ताकि ग्रीन एक सच्चा मिरर हो।
2) किसी भी ट्रैफिक स्विच से पहले ग्रीन валिडेट करें
पहले उच्च-सिग्नल चेक करें: ऐप साफ़-सुथरा स्टार्ट हो, प्रमुख पेज लोड हों, पेमेंट/लॉगिन काम करें, लॉग सामान्य दिखें। यदि आपके पास ऑटोमेटेड स्मोक टेस्ट हैं तो अब चलाएँ। यह वही पल है जब ग्रीन के लिए मॉनिटरिंग डैशबोर्ड और अलर्ट सक्रिय हों यह जाँचना चाहिए।
3) DB माइग्रेशन सुरक्षित तरीके से प्लान करें (एक्सपैंड/कॉन्ट्रैक्ट)
जब DB बदलती है तो ब्लू/ग्रीन जटिल हो जाता है। एक एक्सपैंड/कॉन्ट्रैक्ट अप्रोच अपनाएं:
- एक्सपैंड: नए कॉलम/टेबल जोड़ें बैकवर्ड-कंपैटिबल तरीके से।
- ग्रीन को इस तरह डिप्लॉय करें कि वह पुराने और नए स्कीमा दोनों के साथ काम कर सके।
- कॉन्ट्रैक्ट: पुराने फ़ील्ड निकालें केवल तब जब ब्लू रिटायर हो और आप नए को स्थिर मान लें।
यह "ग्रीन काम करता है, ब्लू टूटता है" जैसी स्थिति से बचाता है।
4) कैश वॉर्म करें और बैकग्राउंड जॉब्स हैंडल करें
स्विच से पहले महत्वपूर्ण कैश (होम पेज, सामान्य क्वेरीज) वॉर्म करें ताकि यूज़र्स को "कोल्ड स्टार्ट" लागत न भुगतनी पड़े।
बैकग्राउंड जॉब्स/क्रॉन वर्कर्स के लिए तय करें कौन चलाएगा:
- कटओवर के दौरान एक वातावरण में ही जॉब्स चलाएँ ताकि डबल-प्रोसेसिंग न हो
5) ट्रैफिक स्विच करें, फिर देखें
लोड बैलेंसर/DNS/इंग्रेस से ब्लू से ग्रीन पर रूटिंग पलटें। त्रुटि दर, लेटेंसी, और बिज़नेस मेट्रिक्स एक छोटे विंडो के लिए देखें।
6) पोस्ट-स्विच सत्यापन और क्लीनअप
एक रियल-यूज़र स्टाइल स्पॉट-चेक करें, फिर ब्लू को अल्पकालिक फॉलबैक के रूप में उपलब्ध रखें। स्थिर होने पर ब्लू जॉब्स डिसेबल करें, लॉग्स आर्काइव करें, और लागत और भ्रम कम करने के लिए ब्लू को डिप्रोविजन कर दें।
कैनरी रोलआउट: व्यावहारिक प्लेबुक
कैनरी रोलआउट सीखने के बारे में है—सुरक्षित रूप से। सभी यूज़र्स को एक साथ भेजने के बजाय, आप असली ट्रैफ़िक के एक छोटे हिस्से को एक्सपोज़ करते हैं, नज़दीकी निगरानी करते हैं, और तभी विस्तार करते हैं। लक्ष्य "धीरे चलना" नहीं है—बल्कि हर स्टेप पर साक्ष्य के साथ साबित करना है कि यह सुरक्षित है।
एक सरल रैम्प प्लान (1–5% → 25% → 50% → 100%)
- कैनरी तैयार करें
नया वर्ज़न वर्तमान स्थिर वर्ज़न के साथ तैनात करें। सुनिश्चित करें कि आप परिभाषित प्रतिशत ट्रैफिक दोनों के बीच रूट कर सकते हैं, और दोनों वर्ज़न मॉनिटरिंग में दिखाई दें (अलग डैशबोर्ड या टैग मदद करते हैं)।
- स्टेज 1: 1–5%
बहुत छोटा शुरू करें। यही वह जगह है जहाँ स्पष्ट समस्याएँ जल्दी दिखती हैं: टूटे एंडपॉइंट, गायब कॉन्फ़िग, DB माइग्रेशन सरप्राइज़, या अचानक लेटेंसी स्पाइक।
स्टेज के लिए नोट रखें:
- इस रिलीज़ में क्या बदला (छोटे कॉन्फ़िग बदलाव सहित)
- आप क्या उम्मीद कर रहे थे
- आपने क्या देखा (एरर, लेटेंसी, यूज़र-इम्पैक्ट)
- स्टेज 2: 25%
यदि पहले चरण में सब ठीक है, तो लगभग चौथाई ट्रैफिक पर बढ़ाएँ। अब आप अधिक वैरायटी देखेंगे: भिन्न यूज़र बिहेवियर, लॉन्ग-टेल डिवाइसेज़, एज केस, और उच्च कंज़रेंसी।
- स्टेज 3: 50%
आधे ट्रैफिक पर क्षमता और प्रदर्शन से जुड़े मुद्दे साफ़ दिखते हैं। यदि आप स्केलिंग लिमिट तक पहुँचने वाले हैं, अक्सर पहले चेतावनी संकेत यहीं मिलते हैं।
- स्टेज 4: 100% (प्रमोशन)
जब मेट्रिक्स स्थिर हों और यूज़र इम्पैक्ट स्वीकार्य हो, तो सभी ट्रैफिक नए वर्ज़न पर शिफ्ट करें और इसे प्रमोट घोषित करें।
रैम्प अंतराल चुनना (हर स्टेप पर कितना इंतज़ार)
रैम्प टाइम जोखिम और ट्रैफिक वॉल्यूम पर निर्भर करता है:
- उच्च-जोखिम बदलाव या कम ट्रैफिक: हर स्टेज पर अधिक इंतज़ार करें ताकि पर्याप्त सिग्नल मिल सके (उदा. 30–60 मिनट या अधिक)। कम-ट्रैफिक सेवाओं को सार्थक पैटर्न देखने के लिए घंटों की ज़रूरत हो सकती है।
- कम-जोखिम बदलाव और उच्च ट्रैफिक: छोटे स्टेज काम कर सकते हैं (उदा. 5–15 मिनट), क्योंकि आप जल्दी डेटा इकट्ठा कर लेंगे।
व्यावसायिक सायकिल भी ध्यान में रखें। यदि आपके प्रोडक्ट में स्पाइक होते हैं (लंचटाइम, वीकएंड, बिलिंग रन), तो कैनरी को उन परिस्थितियों को कवर करने के लिए पर्याप्त समय चलाएँ।
प्रमोशन और रोलबैक ऑटोमेट करें
मैन्युअल रोलआउट हिचक और असंगतता पैदा करते हैं। जहाँ संभव हो ऑटोमेट करें:
- प्रमोशन जब प्रमुख मेट्रिक्स परिभाषित विंडो के लिए थ्रेशहोल्ड के भीतर रहें
- रोलबैक जब थ्रेशहोल्ड्स उल्लंघन हों (जैसे एरर रेट या लेटेंसी सीमा पार हो)
ऑटोमेशन मानव निर्णय हटा नहीं देता—यह देरी हटाता है।
हर स्टेज को एक प्रयोग मानें
हर रैंप कदम के लिए लिखें:
- चेंज सारांश (क्या अलग है)
- सक्सेस क्राइटेरिया (कौन से मेट्रिक्स स्थिर होने चाहिए)
- देखे गए परिणाम (आपने क्या देखा, ‘‘कुछ नहीं असामान्य’’ सहित)
- निर्णय (प्रमोट, होल्ड, या रोलबैक) और क्यों
ये नोट्स आपके रोलआउट इतिहास को अगले रिलीज़ के लिए प्लेबुक बनाते हैं—और भविष्य के घटनाक्रमों का निदान आसान करते हैं।
रोलबैक प्लान और फ़ेल्यर हैंडलिंग
रोलबैक आसान होता है जब आप पहले से तय कर लें कि "खराब" क्या दिखता है और कौन बटन दबा सकता है। रोलबैक प्लान निराशावाद नहीं है—यह है कि आप छोटे मुद्दों को लम्बे आउटेज में बदलने से कैसे बचाते हैं।
स्पष्ट रोलबैक ट्रिगर्स परिभाषित करें
एक छोटी सूची सिग्नलों की चुनें और स्पष्ट थ्रेशहोल्ड सेट करें ताकि घटना के दौरान बहस न हो। सामान्य ट्रिगर्स:
- एरर रेट: 5xx स्पाइक, फेल्ड चेकआउट, लॉगिन फेल्योर, API टाइमआउट
- लेटेंसी: p95/p99 सहमत सीमा से ऊपर स्थिर विंडो के लिए
- बिज़नेस KPI: कन्वर्ज़न में अचानक गिरावट, पेमेंट सक्सेस में कमी, साइन-अप में गिरावट
ट्रिगर को मापनीय बनाइए ("p95 > 800ms for 10 minutes") और एक ओनर (ऑन-कॉल, रिलीज़ मैनेजर) से जोड़ें जिसे तुरंत कार्रवाई का अधिकार हो।
रोलबैक को तेज़ (और उबाऊ) रखें
स्पीड शैली से ज़्यादा मायने रखती है। आपका रोलबैक इन में से एक होना चाहिए:
- ट्रैफिक शिफ्ट उलटना (ब्लू/ग्रीन और कैनरी के लिए सामान्य): ट्रैफिक को पहले-मालूम-अच्छे वर्ज़न पर वापस ले जाएँ
- पिछला वर्ज़न फिर से डिप्लॉय: अगर इन्फ्रास्ट्रक्चर बदला है, तो अंतिम स्टेबल बिल्ड पुश करें और हेल्थ चेक्स फिर से चलाएँ
"मैन्युअल फिक्स फिर रोलआउट जारी" को पहले कदम के रूप में टालें। पहले स्थिर करें, फिर जांच करें।
पार्टियल रोलआउट के लिए योजना बनाएं
कैनरी के साथ, कुछ यूज़र्स ने नए वर्ज़न के तहत डेटा बनाया होगा। पहले से तय करें:
- क्या "कैनरी" यूज़र्स तुरंत वापस रूट होंगे, या उन्हें जांच के दौरान कैनरी पर ही रखा जाएगा?
- यदि डेटा फॉर्मैट बदला है, क्या DB बैकवर्ड-कंपैटिबल है? अगर नहीं, रोलबैक के लिए अलग उपाय चाहिए होगा।
आफ्टर-एक्शन रिव्यू जो अगली रिलीज़ बेहतर बनाए
एक बार स्थिर होने पर, एक छोटा आफ्टर-एक्शन नोट लिखें: रोलबैक क्या ट्रिगर हुआ, कौन से सिग्नल मिस थे, और आप अगली बार चेकलिस्ट में क्या बदलेंगे। इसे एक ब्लेम-एक्सरसाइज़ की तरह न लें—इसे आपकी रिलीज़ प्रक्रिया का प्रोडक्ट इम्प्रूवमेंट साइकिल मानें।
फीचर फ़्लैग्स और प्रोग्रेसिव डिलिवरी
Koder.ai साझा करें
टीममेट्स या साथियों को इनवाइट करें और जब वे Koder.ai उपयोग करना शुरू करें तो क्रेडिट्स पाएं।
फीचर फ़्लैग्स आपको डिप्लॉय (कोड को प्रोडक्शन भेजना) और रिलीज़ (इसे लोगों के लिए चालू करना) को अलग करने देते हैं। यह बड़ा फ़ायदा है क्योंकि आप वही डिप्लॉयमेंट पाइपलाइन—ब्लू/ग्रीन या कैनरी—उपयोग करते हुए एक्सपोज़र एक साधारण स्विच से नियंत्रित कर सकते हैं।
दबाव के बिना डिप्लॉय करें, इरादा के साथ रिलीज़ करें
फ़्लैग्स के साथ आप मरज और डिप्लॉय कर सकते हैं भले ही किसी फीचर को सबके लिए तैयार न हो। कोड मौजूद है, पर निष्क्रिय। जब आप आश्वस्त हों, तो फ़्लैग धीरे-धीरे सक्षम करें—अक्सर एक नए बिल्ड को पुश करने से तेज़—और कुछ गलत होने पर आप उसी तरह फ़्लैग बंद कर सकते हैं।
लक्षित एनेबलमेंट (ऑल-ऑर-नथिंग नहीं)
प्रोग्रेसिव डिलिवरी का मतलब है जान-बूझकर एक्सेस बढ़ाना। एक फ़्लैग सक्षम किया जा सकता है:
- एक विशिष्ट यूज़र ग्रुप के लिए (आंतरिक कर्मचारी, बीटा यूज़र्स, पेड टियर)
- एक क्षेत्र के लिए (एक देश या डेटा सेंटर से शुरू)
- यूज़र्स के प्रतिशत के लिए (1% → 10% → 50% → 100%)
यह तब खासकर मददगार है जब कैनरी बताता है कि नया वर्ज़न हेल्दी है, पर आप फिर भी फीचर रिस्क अलग से मैनेज करना चाहते हों।
"फ्लैग डेट" से बचने के लिए गार्डरेल्स
फीचर फ़्लैग्स शक्तिशाली हैं, पर तभी अगर वे नियंत्रित हों। कुछ गार्डरेल्स:
- ओनरशिप: हर फ़्लैग का एक जिम्मेदार टीम/व्यक्ति हो
- एक्सपायरी: हटाने या रिव्यू करने की तिथि तय करें ताकि पुरानी फ़्लैग्स जमा न हों
- डॉक्यूमेंटेशन: लिखें कि फ़्लैग क्या करता है, किसे प्रभावित करता है, और कैसे रोलबैक करें
एक व्यवहारिक नियम: अगर कोई जवाब नहीं दे सकता "जब हम इसे बंद कर दें तो क्या होगा?" तो फ़्लैग तैयार नहीं है।
गहराई से मार्गदर्शन के लिए देखें: /blog/feature-flags-release-strategy
अपनी रणनीति चुनना और शुरू करना
ब्लू/ग्रीन बनाम कैनरी चुनना यह नहीं कि "कौन बेहतर है"—यह़ है कि आप किस जोखिम को नियंत्रित करना चाहते हैं, और आपकी टीम और टूलिंग के साथ आप क्या व्यवहारिक रूप से चला सकते हैं।
जल्दी फैसला करने का तरीका
अगर आपकी प्राथमिकता एक साफ़, पूर्वानुमेय कटओवर और आसान "पुराने वर्ज़न पर वापस" बटन है, तो आम तौर पर ब्लू/ग्रीन सरल फिट है।
यदि प्राथमिकता ब्लास्ट रेडियस घटाना और असली यूज़र ट्रैफ़िक से सीखना है, तो कैनरी सुरक्षित फिट है—खासकर जब बदलाव अक्सर हों या परीक्षण से पूरी तरह नहीं पकड़े जा सकने वाले हों।
एक व्यावहारिक नियम: उस अप्रोच से शुरू करें जिसे आपकी टीम 2 बजे रात में भी भरोसे के साथ चला सके।
छोटे से शुरू करें: एक पायलट
एक सर्विस या एक यूज़र-फेसिंग वर्कफ़्लो चुनें और कुछ रिलीज़ के लिए पायलट चलाएँ। ऐसा कुछ चुनें जो महत्वपूर्ण है पर इतना क्रिटिकल न हो कि हर कोई पिस जाए। उद्देश्य है ट्रैफिक शिफ्टिंग, मॉनिटरिंग और रोलबैक के चारों ओर मसल मेमोरी बनाना।
एक सरल रनबुक लिखें (और ओनरशिप असाइन करें)
इसे छोटा रखें—एक पेज ठीक है:
- "अच्छा" कैसा दिखता है (कुंजी मेट्रिक्स और थ्रेशहोल्ड)
- रोलआउट के दौरान कौन ज़िम्मेदार है
- कैसे पॉज़, रोलबैक, और कम्युनिकेट करना है
ओनरशिप साफ़ रखें। बिना ओनर के रणनीति सुझाव बनकर रह जाती है।
पहले वही इस्तेमाल करें जो आपके पास है
नई प्लेटफॉर्म जोड़ने से पहले उन टूल्स को देखें जिनपर आप भरोसा करते हैं: लोड बैलेंसर सेटिंग्स, डिप्लॉयमेंट स्क्रिप्ट, मौजूदा मॉनिटरिंग, और आपका इन्सिडेंट प्रोसेस। केवल तब नया टूल जोड़ें जब वह उस घर्षण को कम करे जिसे आपने पायलट में महसूस किया।
अगर आप तेज़ी से नई सेवाएँ बना और शिप कर रहे हैं, तो ऐसे प्लेटफ़ॉर्म जो ऐप जनरेशन और डिप्लॉयमेंट कंट्रोल मिलाते हैं, ऑपरेशनल ड्रैग कम कर सकते हैं। उदाहरण के लिए, Koder.ai एक ऐसा प्लेटफ़ॉर्म है जो टीमों को चैट इंटरफ़ेस से वेब, बैकएंड और मोबाइल ऐप बनाने, डेप्लॉय और होस्ट करने की सुविधाएँ देता है—with सुविधाएँ जैसे स्नैपशॉट और रोलबैक, कस्टम डोमेन, और सोर्स कोड एक्सपोर्ट। ये क्षमताएँ इस आर्टिकल के मूल लक्ष्य से मेल खाती हैं: रिलीज़ को दोहराने योग्य, दिखाई देने योग्य, और उल्टने योग्य बनाना।
सुझाए गए अगले कदम
यदि आप लागू विकल्प और समर्थित वर्कफ़्लो देखना चाहते हैं, तो /pricing और /docs/deployments की समीक्षा करें। फिर अपनी पहली पायलट रिलीज़ शेड्यूल करें, जो काम किया उसका कैप्चर करें, और हर रोलआउट के बाद अपनी रनबुक को इटरेट करें।