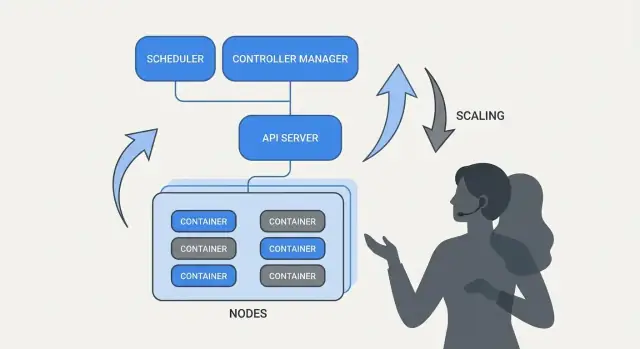
क्यों Kubernetes ने रोज़मर्रा के ऑपरेशंस बदल दिए
Kubernetes सिर्फ़ एक नया टूल नहीं लाया—इसने यह बदल दिया कि जब आप दर्जनों (या सैकड़ों) सेवाएँ चला रहे हों तो “दैनिक ऑप्स” कैसा दिखेगा। ऑर्केस्ट्रेशन से पहले, टीमें अक्सर स्क्रिप्ट्स, मैन्युअल रनबुक और जनजातीय ज्ञान जोड़कर बार‑बार उठने वाले प्रश्नों का जवाब देती थीं: यह सेवा कहाँ चलनी चाहिए? हम परिवर्तन को सुरक्षित तरीके से कैसे रोलआउट करें? अगर 2 बजे रात को कोई नोड डाउन हो जाए तो क्या होगा?
ऑर्केस्ट्रेशन असल में क्या हल करता है
मूल रूप से, ऑर्केस्ट्रेशन आपके इरादे ("इस तरह यह सेवा चले") और मशीनों के फेल होने, ट्रैफ़िक के बदलने, और लगातार डिप्लॉयमेंट जैसी अव्यवस्था के बीच समन्वय की परत है। हर सर्वर को एक अनोखा केस मानने के बजाय, ऑर्केस्ट्रेशन कंप्यूट को एक पूल और वर्कलोड्स को शेड्यूल करने योग्य यूनिट्स के रूप में देखता है जो हिल‑डुल सकती हैं।
Kubernetes ने एक मॉडल लोकप्रिय किया जहाँ टीमें बताती हैं कि वे क्या चाहती हैं, और सिस्टम लगातार वास्तविकता को उस विवरण के अनुरूप बनाए रखने का काम करता है। यह बदलाव मायने रखता है क्योंकि ऑपरेशंस हीरोइक्स की जगह दोहराए जाने योग्य प्रक्रियाओं पर आधारित हो जाते हैं।
तीन परिणाम जो टीमों ने तुरंत महसूस किए
Kubernetes ने उन परिचालन परिणामों को मानकीकृत किया जो अधिकांश सर्विस टीमों को चाहिए:
- तैनाती (Deployment): यह घोषित करने, अपडेट करने और इसकी हेल्थ वेरीफाई करने का एक सुसंगत तरीका देता है।
- स्केलिंग: एक इंस्टेंस से कई तक व्यावहारिक रास्ता, बिना सर्विस को फिर से डिजाइन किए या मशीनों को मैन्युअली प्रोविज़न किए।
- सेवा संचालन: सेवाओं के मिलने, ट्रैफ़िक राउटिंग और इंस्टेंस बदलते रहने पर काम करते रहने के स्थिर तरीके।
दायरा और स्रोतों पर एक नोट
यह लेख Kubernetes (और ब्रेंडन बर्न्स जैसे नेताओं) से जुड़ी विचारधाराओं और पैटर्न पर केंद्रित है, न कि व्यक्तिगत जीवनी पर। जब हम "कैसे शुरू हुआ" या "क्यों इस तरीके से डिजाइन किया गया" कहते हैं, तो ये दावे सार्वजनिक स्रोतों—कॉन्फ़्रेंस टॉक्स, डिज़ाइन डॉक, और अपस्ट्रीम डॉक्यूमेंटेशन—पर आधारित होने चाहिए, ताकि कहानी मिथकों पर नहीं बल्कि सत्यापन योग्य स्रोतों पर टिकी रहे।
ब्रेंडन बर्न्स और Kubernetes का ऑरिजिन स्टोरी (उच्च स्तर)
ब्रेंडन बर्न्स को आमतौर पर Kubernetes के तीन मूल सह‑आविष्कारकों में से एक के रूप में मान्यता दी जाती है, साथ में Joe Beda और Craig McLuckie। Google में शुरुआती Kubernetes काम के दौरान, बर्न्स ने तकनीकी दिशा और परियोजना को उपयोगकर्ताओं के लिए समझाने के तरीके दोनों को आकार दिया—खासकर "आप सॉफ्टवेयर का संचालन कैसे करते हैं" के आसपास, सिर्फ़ "कंटेनर कैसे चलाते हैं" नहीं। (स्रोत: Kubernetes: Up & Running, O’Reilly; Kubernetes प्रोजेक्ट रिपॉजिटरी AUTHORS/maintainers सूची)
ओपन सोर्स सहयोग ने डिज़ाइन को आकार दिया
Kubernetes को बस एक तैयार अंतर्गृह प्रणाली के रूप में "रिलीज़" नहीं किया गया; इसे सार्वजनिक रूप से contributors, उपयोग मामलों और सीमाओं के बढ़ते सेट के साथ बनाया गया। उस खुलापन ने परियोजना को ऐसे इंटरफेस की ओर धकेला जो विभिन्न वातावरणों में टिक सकें:
- छिपे हुए इम्प्लीमेंटेशन विवरणों के बजाय स्पष्ट, संस्करणबद्ध APIs
- क्लाउड प्रोवाइडर्स और ऑन‑प्रेम सेटअप्स में पोर्टेबल व्यवहार
- एक्सटेंशन पॉइंट्स ताकि कोर अपेक्षाकृत छोटा रह सके और फिर भी कई ज़रूरतों का समर्थन कर सके
यह सहयोगात्मक दबाव महत्वपूर्ण है क्योंकि इसने Kubernetes को उन साझा प्रिमिटिव्स और दोहराए जाने योग्य पैटर्न के लिए अनुकूलित किया जिसकी कई टीमें सहमति कर सकती थीं, भले ही वे टूल्स पर असहमत हों।
यहाँ "मानकीकृत" का असली मतलब
जब लोग कहते हैं कि Kubernetes ने तैनाती और ऑपरेशंस को "मानकीकृत" किया, तो आमतौर पर उनका मतलब यह नहीं होता कि इसने हर सिस्टम को एक समान बना दिया। मतलब यह है कि इसने एक सामान्य शब्दावली और वर्कफ़्लोज़ का सेट दिया जिसे टीमें बार‑बार उपयोग कर सकती हैं:
- "deployment", "service", "ingress", "job", "namespace" जैसे साझा शब्द
- जो आप चाहते हैं उसे घोषित करने का सुसंगत मॉडल (और सिस्टम को उसे पूरा करने देना)
- बदलाव रोलआउट, स्केल और फेल्योर से रिकवर करने के भविष्यनिहित तरीके
उस साझा मॉडल ने दस्तावेज़, टूलिंग और टीम प्रैक्टिसेस को एक कंपनी से दूसरी कंपनी तक ट्रांसफर करना आसान बना दिया।
Kubernetes प्रोजेक्ट बनाम इकोसिस्टम
यह उपयोगी है कि आप Kubernetes (ओपन‑सोर्स प्रोजेक्ट) को Kubernetes इकोसिस्टम से अलग करें।
प्रोजेक्ट वह कोर API और कंट्रोल‑प्लेन घटक है जो प्लेटफ़ॉर्म को इम्प्लीमेंट करते हैं। इकोसिस्टम वह सब कुछ है जो इसके चारों ओर उभरा—डिस्ट्रीब्यूशन्स, मैनेज्ड सर्विसेस, ऐड‑ऑन और संबंधित CNCF प्रोजेक्ट। कई असली‑दुनिया की "Kubernetes सुविधाएँ" जिन पर लोग भरोसा करते हैं (observability stacks, policy engines, GitOps टूल्स) उस इकोसिस्टम में रहती हैं, न कि कोर प्रोजेक्ट में।
प्रमुख विचार: घोषणात्मक इच्छित स्थिति
घोषणात्मक कॉन्फ़िगरेशन यह बताने का सरल बदलाव है कि आप सिस्टम को कैसे वर्णित करते हैं: स्टेप‑बाय‑स्टेप कमांड्स की सूची देने की जगह आप बताइए कि आप अंत में क्या चाहते हैं।
Kubernetes शब्दों में, आप प्लेटफ़ॉर्म को नहीं कहते "एक कंटेनर शुरू करो, फिर पोर्ट खोलो, फिर क्रैश होने पर इसे रीस्टार्ट करो।" आप घोषित करते हैं "इस ऐप की तीन कॉपियाँ चलनी चाहिए, इस पोर्ट पर पहुंचने योग्य, इस कंटेनर इमेज का उपयोग करते हुए।" Kubernetes वास्तविकता को उस विवरण के अनुरूप बनाने की जिम्मेदारी लेता है।
इच्छित स्थिति बनाम इम्पेरेटिव स्क्रिप्ट्स
इम्पेरेटिव ऑपरेशंस एक रनबुक की तरह होते हैं: कमांड्स की एक श्रृंखला जो पिछली बार काम कर गई थी, और बदलाव होने पर फिर से चलाई जाती है।
इच्छित स्थिति एक कॉन्ट्रैक्ट के करीब है। आप कॉन्फ़िगरेशन फ़ाइल में अभिप्रेत परिणाम रिकॉर्ड करते हैं, और सिस्टम लगातार उस परिणाम की दिशा में काम करता रहता है। अगर कुछ डिफ्ट हो जाए—एक इंस्टेंस मर जाए, एक नोड गायब हो जाए, कोई मैन्युअल बदलाव छिप जाए—तो प्लेटफ़ॉर्म असमानता का पता लगाता है और उसे सही करता है।
पहले/बाद में: रनबुक कमांड्स बनाम YAML
पहले (इम्पेरेटिव रनबुक सोच):
- किसी सर्वर में SSH करें
- नई कंटेनर इमेज खींचें
- पुरानी प्रक्रिया बंद करें
- नई प्रक्रिया शुरू करें
- लोड बैलेंसर नियम अपडेट करें
- अगर ट्रैफ़िक बढ़े, तो और सर्वरों पर दोहराएँ
यह तरीका काम कर सकता है, लेकिन इससे अक्सर "स्नोफ्लेक" सर्वर्स और एक लंबी चेकलिस्ट बन जाती है जिस पर कुछ ही लोग भरोसा करते हैं।
बाद में (घोषणात्मक इच्छित स्थिति):
apiVersion: apps/v1
kind: Deployment
metadata:
name: checkout
spec:
replicas: 3
selector:
matchLabels:
app: checkout
template:
metadata:
labels:
app: checkout
spec:
containers:
- name: app
image: example/checkout:1.2.3
ports:
- containerPort: 8080
आप फ़ाइल बदलते हैं (उदा., image या replicas अपडेट करते हैं), उसे apply करते हैं, और Kubernetes के कंट्रोलर्स यह सुनिश्चित करने के लिए काम करते हैं कि चल रही स्थिति घोषित स्थिति से मिलती हो।
यह तोइल और ड्रिफ्ट क्यों घटाता है
घोषणात्मक इच्छित स्थिति ऑपरेशनल टॉयल को घटाता है क्योंकि "इन 17 स्टेप्स को करो" को बदल कर "इसे ऐसे ही रखो" कर देता है। यह कॉन्फ़िगरेशन ड्रिफ्ट को भी कम करता है क्योंकि सत्य का स्रोत स्पष्ट और रिव्यूयोग्य है—अक्सर वर्शन कंट्रोल में—तो आश्चर्य कम दिखाई देते हैं, ऑडिट करना आसान होता है, और रोलबैक निरंतर हो सकते हैं।
कंट्रोलर्स और रिकॉन्सिलिएशन: वह सिस्टम जो चीज़ों को सही रखता है
Kubernetes "सेल्फ‑मैनेजिंग" इसलिए लगता है क्योंकि यह एक सरल पैटर्न के चारों ओर बना है: आप जो चाहते हैं उसे वर्णित करते हैं, और सिस्टम लगातार वास्तविकता को उस वर्णन के अनुरूप बनाता है। इस पैटर्न का इंजन कंट्रोलर है।
कंट्रोलर साधारण शब्दों में क्या है
एक कंट्रोलर एक लूप है जो क्लस्टर की वर्तमान स्थिति को देखता है और YAML (या API कॉल) में घोषित इच्छित स्थिति से तुलना करता है। जब यह गैप देखता है, तो वह गैप को कम करने के लिए कार्रवाई करता है।
यह एक बार चलने वाला स्क्रिप्ट नहीं है और न ही यह किसी इंसान के क्लिक का इंतज़ार करता है। यह बार‑बार चलता है—अवलोकन, निर्णय, कार्रवाई—ताकि यह किसी भी क्षण परिवर्तन पर प्रतिक्रिया कर सके।
रिकॉन्सिलिएशन: Kubernetes कैसे "सच बनाए रखता है"
उस बार‑बार होने वाले तुलना‑और‑सुधार व्यवहार को रिकॉन्सिलिएशन कहा जाता है। यह "स्व‑सुधार" के सामान्य वादे के पीछे की तंत्रिका है। सिस्टम जादुई रूप से फेल्योर को रोकता नहीं है; यह डिफ्ट को नोटिस करता है और उसे सही करता है।
ड्रिफ्ट सामान्य कारणों से हो सकता है:
- एक प्रक्रिया क्रैश हो जाती है
- एक नोड गायब हो जाता है
- कोई किसी चीज़ को ऊपर‑नीचे कर देता है
- एक डिप्लॉयमेंट अपडेट हो जाता है
रिकॉन्सिलिएशन का मतलब है कि Kubernetes उन घटनाओं को संकेत मानता है कि आपकी इरादा को फिर से जाँचना है और उसे बहाल करना है।
लोगों को जो परिणाम असल में चाहिए
कंट्रोलर्स परिचित परिचालन परिणामों में अनुवाद करते हैं:
- फ़ेल हुए पॉड्स को रिप्लेस करें: अगर एक पॉड मर जाए, तो कंट्रोलर देखता है कि आप अभी भी उसे चाहते हैं और एक नया शेड्यूल करता है।
- रेप्लिका काउंट बनाए रखें: अगर आपने 5 रेप्लिकाओं के लिए कहा और केवल 4 चल रही हैं, Kubernetes गायब एक को बनाने के लिए काम करता है।
- रोलआउट प्रगति बनाए रखें: अपडेट के दौरान कंट्रोलर्स सिस्टम को नई वर्जन की ओर बढ़ाते हैं जबकि इच्छित उपलब्धता बनाये रखते हैं।
मुख्य बात यह है कि आप लक्षणों का पीछा नहीं कर रहे—आप लक्ष्य घोषित कर रहे हैं, और कंट्रोल लूप लगातार "इसे वहीं रखना" का काम करते हैं।
क्यों यह एक फ़ीचर से आगे स्केल करता है
यह दृष्टिकोण किसी एक रिसोर्स टाइप तक सीमित नहीं है। Kubernetes उसी कंट्रोलर‑और‑रिकॉन्सिलिएशन विचार को कई ऑब्जेक्ट्स—Deployments, ReplicaSets, Jobs, Nodes, endpoints, और अधिक—पर लागू करता है। यह लगातारपन एक बड़ा कारण है कि Kubernetes एक प्लेटफ़ॉर्म बन गया: एक बार आप पैटर्न समझ लेते हैं, आप अनुमान लगा सकते हैं कि सिस्टम कैसे व्यवहार करेगा जब आप नई क्षमताएँ जोड़ते हैं (कस्टम रिसोर्सेज़ सहित)।
शेड्यूलिंग: एक मैन्युअल काम नहीं, प्रोडक्ट फ़ीचर
बाद में मोबाइल जोड़ें
जब जरूरत हो तो Flutter मोबाइल ऐप जोड़ें, बिना प्रोजेक्ट रीस्टार्ट किए।
अगर Kubernetes केवल "कंटेनर चलाता" होता, तब भी टीमों के पास सबसे कठिन हिस्सा होता: यह फैसला करना कि हर वर्कलोड कहाँ चलेगा। शेड्यूलर वह इन‑बिल्ट सिस्टम है जो Pods को स्वतः सही नोड्स पर रखता है, संसाधन आवश्यकताओं और आपके द्वारा परिभाषित नियमों के आधार पर।
यह इसलिए महत्वपूर्ण है क्योंकि प्लेसमेंट फैसले सीधे अपटाइम और लागत को प्रभावित करते हैं। एक वेब API जो भीड़ भरे नोड पर फँस जाए धीमा हो सकता है या क्रैश कर सकता है। Kubernetes इसे एक दोहराए जाने योग्य प्रोडक्ट क्षमता में बदल देता है—स्प्रेडशीट और SSH रूटीन की जगह।
शेड्यूलर किसके लिए ऑप्टिमाइज़ करता है
बुनियादी स्तर पर, शेड्यूलर उन नोड्स की तलाश करता है जो आपके Pod की रिक्वेस्ट्स पूरी कर सकें।
- CPU/मेमोरी रिक्वेस्ट्स: रिक्वेस्ट्स प्लेसमेंट निर्णयों के लिए क्षमता रिज़र्व करते हैं। यदि आप 500m CPU और 1Gi मेमोरी का अनुरोध करते हैं, Kubernetes केवल उन्हीं नोड्स पर विचार करेगा जिनमें पर्याप्त खाली जगह हो।
यह एक आदत—यथार्थपरक requests सेट करना—अक्सर यादृच्छिक अस्थिरता को कम कर देती है क्योंकि महत्वपूर्ण सेवाएँ हर चीज़ के साथ प्रतिस्पर्धा करना बंद कर देती हैं।
टीमें जिन नियमों का वाक़ई में उपयोग करती हैं
संसाधनों के अलावा, अधिकांश प्रोडक्शन क्लस्टर्स कुछ व्यावहारिक नियमों पर भरोसा करते हैं:
- Affinity / anti‑affinity: "इन्हें साथ रखें" (कैश लोकैलिटी के लिए) या "इन्हें अलग रखें" (ताकि एक नोड फेल्योर सभी रेप्लिकाओं को न ले ले)।
- Taints और tolerations: कुछ नोड्स को विशेष‑उद्देश्य के रूप में मार्क करें (GPU नोड्स, सिस्टम नोड्स, अनुपालन नोड्स) और केवल अनुमत वर्कलोड्स को ही वहाँ उतरने दें।
यह आउटेज कैसे घटाता है
शेड्यूलिंग फीचर्स टीमों को ऑपरेशनल इरादा एन्कोड करने में मदद करते हैं:
- नोड्स भर‑बँटकर रेप्लिकाओं को फैलाएँ ताकि नोड फेल्योर से बचा जा सके।
- "स्पाइकी" जॉब्स को ग्राहक‑फेसिंग सेवाओं से अलग रखें।
- महंगे नोड्स (जैसे GPU) को गलत वर्कलोड्स से बचाएँ।
मुख्य व्यावहारिक निष्कर्ष: शेड्यूलिंग नियमों को प्रोडक्ट आवश्यकताओं की तरह दर्ज करें—उन्हें लिखें, रिव्यू करें, और सुसंगत रूप से लागू करें—ताकि विश्वसनीयता किसी के 2 बजे सुबह सही नोड याद करने पर निर्भर न करे।
स्केलिंग: एक इंस्टेंस से हजारों तक बिना री‑राइट किए
Kubernetes का एक सबसे व्यावहारिक विचार यह है कि स्केलिंग के लिए आपके आवेदन को बदलने या एक नया डिप्लॉयमेंट दृष्टिकोण आविष्कार करने की ज़रूरत नहीं होनी चाहिए। अगर ऐप एक कंटेनर के रूप में चल सकता है, तो वही वर्कलोड परिभाषा आमतौर पर सैकड़ों या हजारों प्रतियों तक बढ़ सकती है।
स्केलिंग के दो स्तर
Kubernetes स्केलिंग को दो संबंधित निर्णयों में विभाजित करता है:
- कितने pods चलाने हैं (अधिक थ्रूपुट या redundancy के लिए)
- आपके पास क्लस्टर क्षमता कितनी है (पर्याप्त नोड्स—और सही आकार के नोड्स—ताकि वे pods को रख सकें)
यह विभाजन मायने रखता है: आप 200 pods मांग सकते हैं, पर अगर क्लस्टर में केवल 50 की जगह है, तो "स्केलिंग" पेंडिंग वर्क की कतार बन जाती है।
ऑटोसकेलिंग, संज्ञानात्मक रूप से (HPA, VPA, Cluster Autoscaler)
Kubernetes आम तौर पर तीन ऑटोसकेलर्स का उपयोग करता है, हर एक अलग लीवर पर फोकस करता है:
- Horizontal Pod Autoscaler (HPA): संकेतों जैसे CPU उपयोग, मेमोरी या कस्टम एप्लिकेशन मेट्रिक्स के आधार पर pods की संख्या बदलता है।
- Vertical Pod Autoscaler (VPA): प्रति‑पॉड संसाधन अनुरोध/सीमाओं को समायोजित करता है ताकि प्रत्येक पॉड को अधिक (या कम) CPU/मेमोरी मिले।
- Cluster Autoscaler: नोड्स जोड़ता/हटाता है ताकि शेड्यूलर के पास उन pods को रखने के लिए पर्याप्त जगह हो जो आपने माँगी हैं।
साथ में उपयोग करने पर, यह स्केलिंग को नीति में बदल देता है: "लेटेंसी स्थिर रखें" या "CPU लगभग X% रखें," बजाय मैन्युअल पेजिंग रूटीन के।
"अच्छी स्केलिंग" किस पर निर्भर करती है
स्केलिंग उतनी ही अच्छी है जितने अच्छे इनपुट्स:
- मेट्रिक्स: CPU आसान है पर हमेशा अर्थपूर्ण नहीं; अनुरोध दर, कतार गहराई और लेटेंसी अक्सर असली लोड को बेहतर प्रतिबिंबित करते हैं।
- रिसोर्स requests/limits: ये शेड्यूलर को बताते हैं कि एक पॉड को क्या चाहिए। इनके बिना, प्लेसमेंट और ऑटोसकेलिंग निर्णय अनुमान पर बन जाते हैं।
- लोड पैटर्न: स्पाइकी ट्रैफ़िक, धीमे warm‑ups, और भारी बैकग्राउंड जॉब्स यह बदल देते हैं कि स्केलिंग कितनी तेजी से प्रतिक्रिया देनी चाहिए।
सामान्य पिटफॉल्ट्स
दो गलतियाँ बार‑बार दिखाई देती हैं: गलत मेट्रिक पर स्केलिंग (CPU कम है जबकि requests टाइमआउट हो रहे हैं) और रिसोर्स requests का अभाव (ऑटोसकेलर्स क्षमता की भविष्यवाणी नहीं कर पाते, pods बहुत टाइट तरीके से पैक हो जाते हैं, और प्रदर्शन असंगत बन जाता है)।
सुरक्षित डिप्लॉयमेंट्स: रोलआउट, हेल्थ चेक, और रोलबैक
Kubernetes ने एक बड़ा बदलाव लोकप्रिय किया है: "डिप्लॉय करना" एक चल रहा नियंत्रण समस्या समझना, न कि 5 बजे शुक्रवार को चलाने वाली एक बार की स्क्रिप्ट होना। रोलआउट और रोलबैक फर्स्ट‑क्लास व्यवहार हैं: आप घोषित करते हैं कि आप कौन सा वर्जन चाहते हैं, और Kubernetes सिस्टम को उसकी ओर बढ़ाता है जबकि लगातार यह जांचता है कि परिवर्तन वास्तव में सुरक्षित है या नहीं।
रोलआउट्स एक नियंत्रित संक्रमण हैं
Deployment के साथ, रोलआउट पुराने Pods को नए Pods से क्रमिक रूप से बदलने की प्रक्रिया है। सब कुछ बंद करके फिर से शुरू करने की बजाय, Kubernetes कदम‑दर‑कदम सिस्टम को नए वर्जन की तरफ़ ले जाता है—जब तक नया वर्जन वास्तविक ट्रैफ़िक संभालने में सक्षम साबित न हो जाए।
अगर नया वर्जन फेल होना शुरू कर दे, तो रोलबैक इमरजेंसी प्रक्रिया नहीं है। यह सामान्य ऑपरेशन है: आप पिछले ReplicaSet (अंतिम ज्ञात‑सही वर्जन) पर लौट सकते हैं और कंट्रोलर पुरानी स्थिति बहाल कर देगा।
प्रोब्स: "चल रहा पर ठीक नहीं" रिलीज़्स को रोकना
हेल्थ चेक्स रोलआउट्स को "आशा‑आधारित" से मापनीय बनाते हैं।
- Readiness probes यह निर्धारित करते हैं कि क्या एक Pod ट्रैफ़िक प्राप्त करे। एक कंटेनर चल सकता है पर तैयार नहीं हो सकता (कैश वार्मिंग, निर्भरता का इंतज़ार)। Readiness ड्रॉप करके ऐसे इंस्टेन्स को ट्रैफ़िक नहीं भेजता।
- Liveness probes यह पता लगाती हैं कि क्या कंटेनर फंस गया या खराब है और उसे रीस्टार्ट करने की ज़रूरत है। इससे धीमे फेल होने का मोड रोकता है जहाँ प्रक्रिया तो चलती रहती है पर अनुरोधों को गलत तरीके से हैंडल करती है।
उपयुक्त प्रयोग से, प्रोब्स उन डिप्लॉयमेंट्स को घटाते हैं जो सिर्फ़ इसलिए सफल दिखते हैं क्योंकि Pods स्टार्ट हुए, पर वास्तव में अनुरोधों में विफल रहते हैं।
डिप्लॉयमेंट रणनीतियाँ: रोलिंग, ब्लू/ग्रीन, कैनरी
Kubernetes बॉक्स से बाहर rolling update सपोर्ट करता है, लेकिन टीमें अक्सर ऊपर के पैटर्न जोड़ती हैं:
- Blue/green: दो पूर्ण वातावरण रखें और तभी ट्रैफ़िक स्विच करें जब green सत्यापित हो।
- Canary: नए वर्जन को ट्रैफ़िक का एक छोटा प्रतिशत भेजें, मेट्रिक्स देखें, फिर धीरे‑धीरे बढ़ाएँ।
आप माप सकते हैं ऐसी सुरक्षा (और ऑटोमेट कर सकते हैं)
सुरक्षित रोलआउट्स संकेतों पर निर्भर करते हैं: error rate, latency, saturation और उपयोगकर्ता प्रभाव। कई टीमें रोलआउट निर्णयों को SLOs और error budgets से जोड़ती हैं—अगर एक canary बहुत सारा बजट जला देता है, तो प्रमोशन रुक जाता है।
लक्ष्य यह है कि वास्तविक संकेतों (फेल्ड readiness, बढ़ती 5xx, लेटेंसी स्पाइक्स) के आधार पर ऑटोमेटेड रोलबैक ट्रिगर्स हों, ताकि "रोलबैक" एक अनुमानित सिस्टम प्रतिक्रिया बने—ना कि देर रात का हीरो‑मोमेंट।
सेवा संचालन: डिस्कवरी, राउटिंग और स्थिर नेटवर्किंग
डिक्लेरेटिव स्पेक से बनाएं
ऑप्स-रेडी स्पेक को जल्दी से तैनात और निरंतर सुधार के लिए तैयार वास्तविक ऐप में बदलें।
एक कंटेनर प्लेटफ़ॉर्म तभी "ऑटोमेटिक" महसूस होता है जब सिस्टम के अन्य हिस्से भी तब तक आपकी ऐप तक पहुँच सकें जब वह हिले‑डुले। प्रोडक्शन क्लस्टर्स में Pods लगातार बनाए, हटाए, रिस्केड्यूल और स्केल होते रहते हैं। अगर हर बदलाव के लिए IP पतों को कॉन्फ़िग में अपडेट करना पड़े, तो ऑपरेशंस लगातार व्यस्तता बन जाएगा—और आउटेज आम हो जाएंगे।
सेवा खोज क्यों मायने रखती है
सेवा खोज वह अभ्यास है जो क्लाइंट्स को बदलते बैकएंड्स के सेट तक पहुँचने का भरोसेमंद तरीका देती है। Kubernetes में प्रमुख बदलाव यह है कि आप व्यक्तिगत इंस्टेन्सेस को टार्गेट करना बंद कर देते हैं ("10.2.3.4 को कॉल करो") और इसके बजाय एक नामित सेवा को टार्गेट करते हैं ("checkout को कॉल करो")। प्लेटफ़ॉर्म यह संभालता है कि वर्तमान में कौन से Pods उस नाम को सर्व करते हैं।
Services, selectors, और endpoints (साधारण भाषा)
एक Service Pods के एक समूह के लिए एक स्थिर फ्रन्ट‑डोर है। इसके पास क्लस्टर के अंदर एक सुसंगत नाम और वर्चुअल पता होता है, भले ही अंडरलाइनिंग पॉड्स बदलते रहें।
एक selector यह तय करता है कि Kubernetes किन Pods को उस फ्रन्ट‑डोर के पीछे रखेगा—आम तौर पर labels मैच करके, जैसे app=checkout।
Endpoints (या EndpointSlices) उन वास्तविक Pod IPs की जीवित सूची हैं जो अभी selector से मेल खाते हैं। जब Pods स्केल होते हैं, रोल आउट होते हैं, या रिस्केड्यूल होते हैं, यह सूची स्वतः अपडेट होती है—क्लाइंट्स वही Service नाम उपयोग करते रहते हैं।
स्थिर पते, लोड‑बैलेंसिंग, और ट्रैफ़िक राउटिंग
ऑपरेशनल रूप से यह देता है:
- स्थिर एड्रेसिंग: ऐप्स Pod IPs को नहीं बल्कि एक Service DNS नाम को कॉल करते हैं।
- लोड‑बैलेंसिंग: ट्रैफ़िक Service के पीछे स्वस्थ Pods में वितरित होता है।
- पूर्वानुमेय राउटिंग: आप यह अलग कर सकते हैं कि "किसे ट्रैफ़िक मिलना चाहिए" (labels/selectors) और "Pods किस नोड पर चल रहे हैं"।
क्लस्टर के बाहर से आने वाले ट्रैफ़िक (north–south) के लिए, Kubernetes आम तौर पर Ingress या नए Gateway अप्रोच का उपयोग करता है। दोनों उस नियंत्रित एंट्री‑प्वाइंट को प्रदान करते हैं जहाँ आप होस्टनेम या पाथ के आधार पर अनुरोधों को राउट कर सकते हैं, और अक्सर TLS टर्मिनेशन जैसी चिंताओं को केंद्रीकृत करते हैं। महत्वपूर्ण विचार वही है: बाहरी पहुँच को स्थिर रखें जबकि बैकएंड्स उसके नीचे बदलते रहें।
स्व‑हीलिंग: प्रोडक्शन में इसका वास्तविक मतलब
Kubernetes में "स्व‑हीलिंग" जादू नहीं है। यह विफलता पर स्वचालित प्रतिक्रियाओं का सेट है: रीस्टार्ट, रिस्केड्यूल, और रिप्लेस। प्लेटफ़ॉर्म आपकी घोषित इच्छित स्थिति को देखता है और वास्तविकता को उसके अनुरूप धकेलता रहता है।
रीस्टार्ट: जब कंटेनर क्रैश हो
यदि कोई प्रक्रिया समाप्त हो जाती है या कंटेनर अस्वस्थ हो जाता है, Kubernetes उसे उसी नोड पर रीस्टार्ट कर सकता है। यह आमतौर पर इन द्वारा चालित होता है:
- Liveness probes: "क्या यह कंटेनर अभी भी कार्य कर रहा है?" अगर नहीं, तो उसे रीस्टार्ट करें।
- Restart policies: कब रीस्टार्ट होना चाहिए के नियम।
एक सामान्य प्रोडक्शन पैटर्न: एक कंटेनर क्रैश → Kubernetes उसे रीस्टार्ट करता है → आपकी Service केवल स्वस्थ Pods को राउट करती है।
रिस्केड्यूल और रिप्लेस: जब नोड फेल हो
अगर एक पूरा नोड डाउन हो जाता है (हार्डवेयर समस्या, कर्नेल पैनिक, नेटवर्क खोना), Kubernetes नोड को अनउपलब्ध के रूप में डिटेक्ट करता है और काम को दूसरी जगह पर शिफ्ट करना शुरू कर देता है। ऊपरी स्तर पर:
- नोड को unhealthy/not ready मार्क किया जाता है।
- वहां चल रहे Pods को खोया हुआ माना जाता है।
- कंट्रोलर्स अन्य स्वस्थ नोड्स पर रिप्लेसमेंट Pods बनाकर इच्छित रेप्लिका काउंट बहाल करते हैं।
यह क्लस्टर‑स्तरीय "स्व‑हीलिंग" है: सिस्टम क्षमता को बदलता है, बजाय किसी इंसान के SSH करने के इंतज़ार के।
ऑब्ज़र्वेबिलिटी: आप कैसे जानेंगे कि यह हील कर रहा है
स्व‑हीलिंग तभी मायने रखता है जब आप इसे सत्यापित कर सकें। टीमें आम तौर पर देखते हैं:
- लॉग्स (ऐप लॉग्स और प्लेटफ़ॉर्म ईवेंट्स) यह देखने के लिए कि क्या रीस्टार्ट हुआ और क्यों
- मेट्रिक्स जैसे restart counts, failed probes, और node readiness
- अलर्ट्स जब हीलिंग काम नहीं कर रही (उदा., बार‑बार CrashLoopBackOff, रेप्लिका की कमी, या बहुत ज़्यादा evictions)
मिस‑कन्फ़िगरेशन जो स्व‑हीलिंग तोड़ते हैं
यहाँ कुछ कारण हैं जिनसे "हीलिंग" विफल हो सकती है:
- गलत या गायब liveness/readiness probes (false positives या कभी‑नहीं‑रेडी Pods)
- कोई resource requests/limits न होना, जिससे शेड्यूलिंग अनियंत्रित या OOM kills हो सकती हैं
- बहुत कम replicas (एक ही Pod continuity प्रदान नहीं कर सकता)
- अत्यधिक आक्रामक probe timings जो restart storms पैदा करें
- वर्कलोड्स जो node‑local state पर निर्भर हों बिना किसी टिकाऊ स्टोरेज रणनीति के
जब स्व‑हीलिंग अच्छी तरह सेट अप होती है, तो आउटेज छोटे और कम समय के होते हैं—और, सबसे महत्वपूर्ण, मापनीय होते हैं।
मानक APIs और विस्तार‑योग्यता: कुबेरनेट्स कैसे प्लेटफ़ॉर्म बना
एक उपयुक्त योजना चुनें
अपने लिए सही टियर के साथ सिंगल प्रोटोटाइप से टीम-तैयार काम में बदलें।
Kubernetes केवल कंटेनरों को चला सकता है, इसलिए ही नहीं जीता। यह इसलिए जीता कि इसने सबसे सामान्य ऑपरेशनल जरूरतों—डिप्लॉयिंग, स्केलिंग, नेटवर्किंग, और ऑब्ज़र्विंग वर्कलोड्स—के लिए मानक APIs पेश किए। जब टीमें एक ही "आब्जेक्ट" के आकार पर सहमत होती हैं (जैसे Deployments, Services, Jobs), तो टूल्स संगठनों में साझा किए जा सकते हैं, ट्रेनिंग सरल होती है, और देव‑ऑप्स के बीच हेंडऑफ जनजातीय ज्ञान पर निर्भर नहीं रहते।
मानक APIs टीम वर्कफ़्लोज़ कैसे बदलते हैं
एक सुसंगत API का मतलब है कि आपकी डिप्लॉयमेंट पाइपलाइन को हर ऐप की बारीकियों को जानने की ज़रूरत नहीं होती। वह वही क्रियाएं लागू कर सकती है—create, update, roll back, और health चेक—उसी Kubernetes अवधारणाओं का उपयोग करके।
यह संरेखण भी सुधारता है: सुरक्षा टीमें नीतियाँ गार्डरेल्स के रूप में व्यक्त कर सकती हैं; SREs सामान्य हेल्थ सिग्नलों के आसपास रनबुक स्टैन्डरडाइज़ कर सकते हैं; डेवलपर्स साझा शब्दावली के साथ रिलीज़ के बारे में सोच सकते हैं।
बढ़ाना: CRDs और Operators
"प्लेटफ़ॉर्म" शिफ्ट CRDs के साथ स्पष्ट हो जाता है। एक CRD आपको क्लस्टर में एक नया प्रकार जोड़ने देता है (उदा., Database, Cache, या Queue) और आप उसे बिल्ट‑इन रिसोर्स की तरह ही प्रबंधित कर सकते हैं।
एक Operator उन कस्टम ऑब्जेक्ट्स को एक कंट्रोलर के साथ जोड़ता है जो इच्छित स्थिति को लगातार वास्तविकता से मेल करता है—मैन्युअल कार्यों को ऑटोमेट करते हुए, जैसे बैकअप, फेलओवर, या वर्जन 업ग्रेड। मुख्य लाभ जादू नहीं है; बल्कि वही नियंत्रण‑लूप अप्रोच दोहराना है जिसे Kubernetes हर चीज़ पर लागू करता है।
GitOps, CI/CD और नीति‑चेक्स के साथ फ़िट
क्योंकि Kubernetes API‑ड्रिवन है, यह आधुनिक वर्कफ़्लोज़ के साथ सहज रूप से इंटीग्रेट होता है:
- GitOps: इच्छित स्थिति Git में रहती है; परिवर्तन कोड की तरह रिव्यू किया जाता है।
- CI/CD: पाइपलाइन्स manifests apply कर सकते हैं, readiness का इंतज़ार कर सकते हैं, और वर्जन प्रमोट कर सकते हैं।
- Policy checks: admission controllers जोखिम भरी कॉन्फ़िग्स को प्रोडक्शन तक पहुँचने से पहले ब्लॉक कर सकते हैं।
अगर आप इन विचारों पर बने और अधिक व्यावहारिक डिप्लॉयमेंट और ऑप्स गाइड चाहते हैं, तो /blog ब्राउज़ करें।
आज टीमें क्या लागू कर सकती हैं (Kubernetes के बाहर भी)
सबसे बड़े Kubernetes विचार—कई ब्रेंडन बर्न्स की शुरुआती फ्रेमिंग से जुड़े—अच्छी तरह से तब भी लागू होते हैं जब आप VMs, serverless, या छोटे कंटेनर सेटअप चला रहे हों।
ऐसे पैटर्न जो दिन‑प्रतिदिन के ऑप्स सुधारते हैं
"इच्छित स्थिति" लिखें और ऑटोमेशन को उसे लागू करने दें। चाहे Terraform हो, Ansible हो, या CI पाइपलाइन, कॉन्फ़िगरेशन को सत्य का स्रोत समझें। परिणाम: कम मैन्युअल डिप्लॉय स्टेप्स और बहुत कम "मेरे मशीन पर काम करता था" आश्चर्य।
रिकॉन्सिलिएशन का उपयोग करें, वन‑ऑफ स्क्रिप्ट्स नहीं। एक‑बार चलने वाली स्क्रिप्ट्स की बजाय ऐसे लूप बनाएं जो लगातार प्रमुख गुणों (वर्जन, कॉन्फ़िग, इंस्टेंस की संख्या, हेल्थ) की पुष्टि करें और ड्रिफ्ट को सही करें। यही तरीका दोहराए जाने योग्य ऑप्स और फेल्योर के बाद पूर्वानुमेय रिकवरी देता है।
शेड्यूलिंग और स्केलिंग को स्पष्ट प्रोडक्ट फीचर बनाएं। यह परिभाषित करें कि आप कब और क्यों क्षमता बढ़ाते हैं (CPU, कतार गहराई, लेटेंसी SLOs)। भले ही आपके पास Kubernetes ऑटोसकेलिंग न हो, टीमें स्केल नियम स्टैण्डरडाइज़ कर सकती हैं ताकि वृद्धि ऐप री‑राइट करने या किसी को जगाने की मांग न करे।
रोलआउट्स को मानकीकृत करें। रोलिंग अपडेट्स, हेल्थ चेक्स, और तेज़ रोलबैक प्रक्रियाएँ बदलाव के जोखिम को घटाती हैं। आप इन्हें लोड‑बैलेंसर, फीचर फ्लैग्स, और डिप्लॉयमेंट पाइपलाइन्स के साथ लागू कर सकते हैं जो वास्तविक संकेतों पर रिलीज़ को गेट करते हैं।
सुरक्षित अपनाने की चेकलिस्ट
- एक सेवा की इच्छित स्थिति परिभाषित करें: वर्जन, कॉन्फ़िग, निर्भरता, और न्यूनतम इंस्टेंस काउंट
- हेल्थ एंडपॉइंट्स जोड़ें (liveness और readiness समकक्ष) और इन्हें अपने लोड बैलेंसर या डिप्लॉय पाइपलाइन से जोड़ें
- रोलआउट स्टेप्स को ऑटोमेट करें: डिप्लॉय, वेरिफाई, ट्रैफ़िक शिफ्ट, और विफलता पर रोलबैक
- एक छोटा “reconciler” बनाएं: शेड्यूल्ड चेक्स जो ड्रिफ्ट को सुधारें (गलत कॉन्फ़िग, गायब इंस्टेंस)
- स्पष्ट सीमाओं के साथ स्केलिंग ट्रिगर्स जोड़ें (max instances, cooldowns, approval rules)
यह अपने आप क्या नहीं सुलझाता
ये पैटर्न खराब ऐप डिज़ाइन, असुरक्षित डाटा माइग्रेशन, या कॉस्ट कंट्रोल को अपने आप ठीक नहीं करेंगे। आपको अभी भी वर्शन किए गए APIs, माइग्रेशन योजनाएँ, बजट/लिमिट्स, और ऐसी ऑब्ज़र्वेबिलिटी चाहिए जो डिप्लॉय्स को ग्राहक प्रभाव से जोड़ती हो।
अगले कदम
एक ग्राहक‑सामना करने वाली सेवा चुनें और चेकलिस्ट को end‑to‑end लागू करें, फिर विस्तार करें।
अगर आप नई सेवाएँ बना रहे हैं और "कुछ तैनात करने लायक" तक जल्दी पहुँचना चाहते हैं, तो Koder.ai आपकी मदद कर सकता है—यह सामान्यतः फ्रंटएंड पर React, बैकएंड पर Go + PostgreSQL, और मोबाइल के लिए Flutter के साथ चैट‑ड्रिवन स्पेक से पूरा वेब/बैकेंड/मोबाइल ऐप जनरेट कर देता है—फिर सोर्स को एक्सपोर्ट करके आप ऊपर चर्चा किए गए Kubernetes पैटर्न (घोषणात्मक कॉन्फ़िग्स, दोहराए जाने योग्य रोलआउट्स, और रोलबैक‑फ्रेंडली ऑपरेशंस) लागू कर सकते हैं। लागत और गवर्नेंस का मूल्यांकन कर रहे टीमों के लिए /pricing देखें।