18 अग॰ 2025·8 मिनट
क्रिस लैटनर का LLVM: आधुनिक टूलचेन के पीछे नीरव इंजन
जानिए कैसे क्रिस लैटनर का LLVM आधुनिक भाषाओं और टूल्स के पीछे एक मॉड्युलर कम्पाइलर प्लेटफ़ॉर्म बन गया—जो अनुकूलन, बेहतर डायग्नोस्टिक्स और तेज़ बिल्ड्स को सक्षम करता है।
सरल भाषा में: LLVM क्या है
LLVM को अक्सर उन कई कम्पाइलरों और डेवलपर टूल्स का "इंजन रूम" समझना सबसे उपयोगी होता है।
जब आप C, Swift, या Rust जैसी भाषा में कोड लिखते हैं, तो किसी न किसी चीज़ को उस कोड को CPU के चलाने योग्य निर्देशों में बदलना पड़ता है। पारंपरिक कम्पाइलर अक्सर पूरे पाइपलाइन के हर हिस्से को खुद बनाते थे। LLVM एक अलग तरीका अपनाता है: यह एक उच्च-गुणवत्ता, पुन:उपयोग योग्य कोर प्रदान करता है जो कठिन और महंगे काम—अनुकूलन, विश्लेषण, और कई तरह के प्रोसेसर के लिए मशीन कोड जनरेट करना—हैंडल करता है।
कई भाषाओं के लिए साझा आधार
LLVM ज़्यादातर मामलों में कोई एकल "कम्पाइलर जिसे आप सीधे उपयोग करें" नहीं है। यह कम्पाइलर अवसंरचना है: वह बिल्डिंग ब्लॉक्स जिनको भाषा टीमें टूलचेन में जोड़ सकती हैं। एक टीम सिंटैक्स, सेमांटिक्स और डेवलपर-फ़ेसिंग सुविधाओं पर ध्यान दे सकती है, और भारी काम LLVM को सौंप सकती है।
यह साझा आधार एक बड़ा कारण है कि आधुनिक भाषाएँ जल्दी और भरोसेमंद टूलचेन ला सकती हैं बिना दशक भर के कम्पाइलर काम को हर बार दोहराए।
यदि आप कम्पाइलर विशेषज्ञ नहीं भी हैं तो भी क्यों मायने रखता है
LLVM डेवलपर एक्सपीरियंस में रोज़मर्रा के रूप में दिखता है:
- गति: यह उच्च-स्तरीय कोड को कई प्लेटफ़ॉर्म पर कुशल मशीन कोड में बदल सकता है।
- बेहतर त्रुटि संदेश और डिबगिंग: LLVM के आसपास का इकोसिस्टम समृद्ध डायग्नोस्टिक्स और बेहतर टूलिंग सक्षम करता है।
- सिर्फ़ "संकलन" से ज़्यादा: स्टैटिक एनालिसिस, सैनीटाइज़र, कोड कवरेज और अन्य डेवलपर सहायक साधारणतः उसी आंतरिक प्रतिनिधित्व और लाइब्रेरीज़ पर बनते हैं।
यह लेख क्या करेगा (और क्या नहीं)
यह क्रिस लैटनर द्वारा आरंभ की गई विचारधारा का एक मार्गदर्शित टूर है: LLVM किस तरह संरचित है, मध्य-परत क्यों मायने रखती है, और यह अनुकूलन एवं मल्टी-प्लेटफ़ॉर्म समर्थन कैसे सक्षम करती है। यह कोई पाठ्यपुस्तक नहीं है—हम सहज ज्ञान और वास्तविक दुनिया के प्रभाव पर ध्यान रखेंगे न कि औपचारिक सिद्धांतों पर।
क्रिस लैटनर का मूल दृष्टिकोण
क्रिस लैटनर एक कम्प्यूटर वैज्ञानिक और इंजीनियर हैं जिन्होंने शुरुआती 2000 के दशक में स्नातक शोधकर्ता के रूप में LLVM शुरू किया—उनकी व्यावहारिक निराशा यह थी कि कम्पाइलर तकनीक शक्तिशाली तो थी, पर पुनःउपयोग करना कठिन था। यदि आप नई प्रोग्रामिंग भाषा, बेहतर अनुकूलन या नए CPU का समर्थन चाहते थे, तो अक्सर आपको एक घनिष्ठ रूप से जुड़ा "ऑल-इन-वन" कम्पाइलर छेड़ना पड़ता था जहाँ हर बदलाव के साइड-इफेक्ट होते थे।
जिन समस्याओं को उन्होंने हल करना चाहा
उस समय कई कम्पाइलर एक बड़े, एकल मशीन की तरह बने होते थे: भाषा को समझने वाला भाग, अनुकूलन करने वाला भाग और मशीन कोड जनरेट करने वाला भाग गहरे रूप से इंटरट्वाइन्ड होते थे। इससे वे अपने मूल उद्देश्य के लिए प्रभावी थे, पर अनुकूलन और विस्तारण महंगा था।
लैटनर का लक्ष्य "एक भाषा के लिए कम्पाइलर" नहीं था। इसका उद्देश्य एक साझा आधार बनाना था जो कई भाषाओं और टूल्स को पॉवर दे सके—बिना यह कि हर कोई बार-बार वही जटिल हिस्से दोहराए। उनका दांव यह था कि यदि आप पाइपलाइन के मध्य को मानकीकृत कर सकें, तो किनारों पर तेज़ी से नवाचार कर सकते हैं।
क्यों "मॉड्युलर अवसंरचना" नई थी
मुख्य बदलाव यह था कि कम्पाइलेशन को अलग-थलग बिल्डिंग ब्लॉक्स के रूप में माना गया जिनकी स्पष्ट सीमाएँ हों। मॉड्युलर दुनिया में:
- एक भाषा टीम पार्सिंग और डेवलपर-फ़ेसिंग सुविधाओं पर ध्यान दे सकती है,
- एक अनुकूलन टीम प्रदर्शन में सुधार कर सकती है एक बार और व्यापक रूप से साझा कर सकती है,
- हार्डवेयर सपोर्ट जोड़े बिना पूरे ऊपर के हिस्से का पुन:डिज़ाइन करना।
यह अलगाव अब जाहिर लगता है, पर तब कई प्रोडक्शन कम्पाइलरों के विकास के तरीके के विपरीत था।
खुले स्रोत के रूप में बनाया गया—दूसरों द्वारा उपयोग के लिए
LLVM को जल्दी ही ओपन सोर्स के रूप में रिलीज़ किया गया, जो इस लिहाज़ से मायने रखता था क्योंकि साझा अवसंरचना तभी काम करती है जब कई समूह उस पर भरोसा कर सकें, उसका निरीक्षण कर सकें और उसे बढ़ा सकें। समय के साथ, विश्वविद्यालयों, कंपनियों और स्वतंत्र योगदानकर्ताओं ने लक्ष्य (targets) जोड़कर, कोनों की समस्याएँ ठीक कर के, प्रदर्शन सुधार कर के और उसके चारों ओर नए टूल बनाकर परियोजना का आकार बढ़ाया।
यह सामुदायिक पहल सिर्फ़ नेक इरादा नहीं थी—यह डिज़ाइन का हिस्सा थी: कोर को व्यापक उपयोगी बनाओ, और इसे एक साथ बनाए रखना सार्थक हो जाएगा।
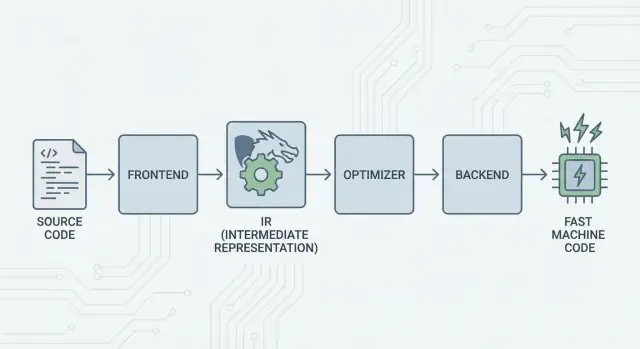
बड़ा विचार: फ्रंटएंड, साझा कोर, और बैकएंड
LLVM का मूल विचार सरल है: कम्पाइलर को तीन प्रमुख हिस्सों में बाँट दो ताकि कई भाषाएँ सबसे कठिन काम साझा कर सकें।
1) फ्रंटएंड: "प्रोग्रामर का अर्थ क्या था?"
एक फ्रंटएंड किसी विशिष्ट प्रोग्रामिंग भाषा को समझता है। यह आपका स्रोत कोड पढ़ता है, नियम (सिंटैक्स और टाइप) जांचता है और उसे एक संरचित प्रतिनिधित्व में बदल देता है।
मुख्य बिंदु: फ्रंटएंड को हर CPU विवरण जानने की ज़रूरत नहीं है। उनका काम भाषा अवधारणाओं—फंक्शन्स, लूप्स, वेरिएबल्स—को कुछ अधिक सार्वभौमिक में ट्रांसलेट करना है।
2) साझा मध्य: N×M काम की जगह एक सामान्य कोर
पारंपरिक रूप से, कम्पाइलर बनाते समय वही काम बार-बार करना पड़ता था:
- N भाषाएँ और M चिप टार्गेट्स हों तो आपके पास N×M संयोजनों का बोझ बन जाता है।
LLVM इसे घटा देता है:
- N फ्रंटएंड जो साझा रूप में अनुवाद करते हैं
- M बैकएंड जो उस साझा रूप से मशीन कोड बनाते हैं
यह "साझा रूप" LLVM का केंद्र है: एक सामान्य पाइपलाइन जहाँ अनुकूलन और विश्लेषण रहते हैं। मध्य में किए गए सुधार (बेहतर अनुकूलन, बेहतर डिबग जानकारी) कई भाषाओं को एक साथ लाभ पहुंचा सकते हैं, बजाय इसके कि हर कम्पाइलर में फिर से लागू किए जाएँ।
3) बैकएंड: "इसे उस CPU पर तेज़ कैसे चलाएँ?"
एक बैकएंड साझा प्रतिनिधित्व लेकर मशीन-विशिष्ट आउटपुट बनाता है: x86, ARM इत्यादि के लिए निर्देश। यहाँ रेजिस्टर्स, कॉलिंग कन्वेंशन और इंस्ट्रक्शन सेलेक्शन जैसे विवरण मायने रखते हैं।
पाइपलाइन की एक सहज तस्वीर
कम्पाइलेशन को एक यात्रा मार्ग की तरह सोचिए:
- स्रोत कोड एक भाषा-विशिष्ट देश (फ्रंटएंड) से शुरू होता है।
- यह एक साझा, मानकीकृत "मिडल लैंग्वेज" (LLVM का कोर प्रतिनिधित्व और पासेस) में प्रवेश करता है।
- फिर यह एक स्थानीय ट्रेन सिस्टम लेकर किसी विशिष्ट गंतव्य शहर (आपके टार्गेट मशीन के लिए बैकएंड) पहुँचता है।
परिणाम है एक मॉड्युलर टूलचेन: भाषाएँ विचार व्यक्त करने पर ध्यान रख सकती हैं, जबकि LLVM का साझा कोर उन विचारों को कई प्लेटफ़ॉर्म पर कुशलता से चलाने पर ध्यान देता है।
LLVM IR: पुन:उपयोग सक्षम करने वाली मध्य परत
LLVM IR (इंटरमीडिएट रिप्रेजेंटेशन) वह "साझा भाषा" है जो प्रोग्रामिंग भाषा और आपके CPU द्वारा चलाए जाने वाले मशीन कोड के बीच बैठती है।
एक कम्पाइलर फ्रंटएंड (जैसे C/C++ के लिए Clang) आपका स्रोत कोड इस साझा रूप में बदलता है। फिर LLVM के अनुकूलक और कोड जनरेटर IR पर काम करते हैं, न कि मूल भाषा पर। अंत में, एक बैकएंड IR को किसी विशिष्ट टार्गेट (x86, ARM आदि) के निर्देशों में बदल देता है।
टूल्स और CPUs के बीच एक सामान्य भाषा
LLVM IR को ऐसे ब्रिज की तरह सोचें:
- ऊपर: कई स्रोत भाषाएँ जुड़ सकती हैं (C, C++, Rust, Swift, Julia आदि)।
- नीचे: कई CPUs लक्षित किए जा सकते हैं।
- बीच में: वही विश्लेषण और अनुकूलन टूल्स पुन:उपयोग किए जा सकते हैं।
यही कारण है कि लोग अक्सर LLVM को "कम्पाइलर अवसंरचना" कहते हैं न कि सिर्फ़ "एक कम्पाइलर।" IR वही साझा अनुबंध है जो उस अवसंरचना को पुन:उपयोगी बनाता है।
IR कैसे पुन:उपयोग सक्षम करता है (और सबका काम बचाता है)
एक बार कोड LLVM IR में होने पर, अधिकांश अनुकूलन पासेस यह जानने की ज़रूरत नहीं रखते कि वह मूल रूप से C++ टेम्पलेट्स, Rust इटरेटर, या Swift जेनरिक्स से आया था। वे ज़्यादातर सार्वभौमिक विचारों पर काम करते हैं जैसे:
- “यह मान स्थिर है।”
- “यह गणना बार-बार हो रही है; क्या हम परिणाम पुन:उपयोग कर सकते हैं?”
- “यह मेमोरी लोड सुरक्षित रूप से हटा या स्थानांतरित किया जा सकता है।”
इसलिए भाषा टीमें अपना पूरा अनुकूलक स्टैक बनाने और बनाए रखने की ज़रूरत नहीं समझतीं। वे फ्रंटएंड—पार्सिंग, टाइप चेकिंग, भाषा-विशिष्ट नियम—पर ध्यान दे सकती हैं और फिर भारी काम LLVM को सौंप सकती हैं।
यह अवधारणात्मक रूप में कैसा दिखता है
LLVM IR मशीन कोड के लिए साफ़ मैप करने के लिए पर्याप्त निचला-स्तरीय है, पर अभी भी विश्लेषण के लिए संरचित है। अवधारणात्मक रूप से, यह सरल निर्देशों (add, compare, load/store), स्पष्ट नियंत्रण प्रवाह (ब्रांच) और मजबूत-टाइपेड मानों से बना है—मानव द्वारा आमतौर पर नहीं लिखा जाने वाला, बल्कि कम्पाइलरों के लिए डिज़ाइन किया गया एक सुव्यवस्थित असेंबली जैसा।
अनुकूलन कैसे काम करते हैं (गणित के बिना)
जब लोग "कम्पाइलर अनुकूलन" सुनते हैं, तो वे अक्सर रहस्यमय तरकीबों की कल्पना करते हैं। LLVM में, अधिकांश अनुकूलन बेहतर रूप से समझे जा सकते हैं एक तरह के सुरक्षित, मैकेनिकल प्रोग्राम-राइट्स के रूप में—ऐसे परिवर्तन जो प्रोग्राम का व्यवहार बनाए रखते हैं, पर उसे तेज़ या छोटा बनाते हैं।
इसे आविष्कार करने के बजाय संपादन की तरह सोचें
LLVM आपका कोड (LLVM IR में) लेता है और छोटे सुधार बार-बार लागू करता है, ठीक जैसे किसी ड्राफ्ट को पालिश किया जा रहा हो:
- डुप्लिकेट काम हटाना: यदि कोई मान दो बार निकाला जा रहा है और बीच में कुछ भी बदलता नहीं है, तो LLVM इसे एक बार करके परिणाम पुन:उपयोग कर सकता है।
- सपाट तर्क को सरल बनाना: स्थिर अभिव्यक्तियों को शुरुआती चरण में जोड़-घटाकर सरल किया जा सकता है (उदा.,
3 * 4को12में बदलना), ताकि CPU रनटाइम पर कम करे। - लूप्स को सुसंगत बनाना: लूप-संबंधी पासेस दोहराए जाने वाले चेक्स को कम कर सकते हैं, अपरिवर्ती काम को लूप से बाहर ले जा सकते हैं, या पैटर्न पहचान कर उन्हें अधिक कुशलता से चला सकते हैं।
ये परिवर्तन जानबूझकर संरक्षणवादी होते हैं। एक पास केवल तभी री-राइट करता है जब वह साबित कर सके कि री-राइट प्रोग्राम का अर्थ नहीं बदलेगा।
परिचित उदाहरण
यदि आपका प्रोग्राम कॉन्सेप्चुअली ये करता है:
- हर लूप इटरेशन में एक ही कॉन्फ़िग वैल्यू पढ़ता है
- एक ही इनपुट पर एक ही गणना कई स्थानों पर करता है
- किसी संदर्भ में हमेशा सत्य/असत्य रहने वाली शर्त की जांच करता है
…तो LLVM कोशिश करता है उसे इस रूप में बदलने की—"एक बार सेटअप करो", "परिणाम पुन:उपयोग करो", और "निरर्थक ब्रांच हटाओ"। यह कम जादू और अधिक हाउसकीपिंग है।
वास्तविक व्यापार-ऑफ: कम्पाइल समय बनाम रनटाइम
अनुकूलन मुफ्त नहीं है: अधिक विश्लेषण और अधिक पासेस आमतौर पर धीमी कम्पाइलेशन का कारण बनते हैं, भले ही अंतिम प्रोग्राम तेज़ चले। इसलिए टूलचेन स्तर प्रदान करते हैं जैसे "थोड़ा अनुकूलन" बनाम " aggressively अनुकूलन"।
प्रोफाइल्स यहाँ मदद करते हैं। प्रोफ़ाइल-गाइडेड अनुकूलन (PGO) में आप प्रोग्राम चलाते हैं, वास्तविक उपयोग डेटा इकट्ठा करते हैं, और फिर पुनःकम्पाइल करते हैं ताकि LLVM वास्तविकता में महत्वपूर्ण पाथ्स पर ज़्यादा ध्यान दे—इससे व्यापार-ऑफ अधिक अनुमान्य बन जाता है।
बैकएंड: बिना सब कुछ फिर से लिखे कई CPUs तक पहुँच
अपनी रफ्तार पर स्केल करें
इसे कितना आगे ले जाना है, उसके अनुसार Free, Pro, Business या Enterprise चुनें।
एक कम्पाइलर के दो बहुत अलग काम होते हैं। पहले, उसे आपका स्रोत कोड समझना होता है। दूसरा, उसे ऐसा मशीन कोड बनाना होता है जो किसी विशिष्ट CPU चला सके। LLVM बैकएंड्स उस दूसरे काम पर केंद्रित होते हैं।
एक बैकएंड वास्तव में क्या करता है
LLVM IR को एक "यूनिवर्सल रेसिपी" समझिए कि प्रोग्राम को क्या करना है। एक बैकएंड उस रेसिपी को किसी विशेष प्रोसेसर परिवार के सटीक निर्देशों में बदल देता है—डेस्कटॉप और सर्वरों के लिए x86-64, फ़ोन्स और नए लैपटॉप के लिए ARM64, या वेब के लिए WebAssembly इत्यादि।
ठोस रूप में, एक बैकएंड जिम्मेदार होता है:
- इंस्ट्रक्शन सेलेक्शन: IR ऑपरेशन्स का वास्तविक CPU निर्देशों में मैपिंग
- रजिस्टर एलोकेशन: यह चुनना कि कौन से मान तेज़ CPU रजिस्टरों में रहें और कौन मेमोरी में
- शेड्यूलिंग: निर्देशों को इस तरह क्रमबद्ध करना ताकि CPU उन्हें कुशलता से चला सके
- असेंबली/ऑब्जेक्ट आउटपुट: ऐसा कोड इमिट करना जिसे लिंकक और OS समझें
साझा अवसंरचना नए हार्डवेयर सपोर्ट को आसान क्यों बनाती है
बिना साझा कोर के, हर भाषा को हर CPU के लिए यह सब फिर से लागू करना पड़ेगा—एक विशाल काम और लगातार मेंटेनेंस बोझ।
LLVM इसे उलट देता है: फ्रंटएंड्स (जैसे Clang) एक बार LLVM IR बनाते हैं, और बैकएंड्स "अंतिम माइल" हर टार्गेट के लिए संभालते हैं। नए CPU के सपोर्ट को जोड़ना आम तौर पर एक बैकएंड लिखने (या मौजूदा को बढ़ाने) जितना होता है, न कि हर कम्पाइलर को फिर से लिखने जैसा।
मल्टी-प्लेटफ़ॉर्म टीमों के लिए पोर्टेबिलिटी
जिन परियोजनाओं को Windows/macOS/Linux, x86 और ARM, या यहां तक कि ब्राउज़र पर चलाना है, LLVM का बैकएंड मॉडल व्यावहारिक लाभ देता है। आप एक कोडबेस और एक बिल्ड पाइपलाइन रख सकते हैं, फिर बस अलग बैकएंड चुन कर या क्रॉस-कम्पाइल करके टार्गेट बदल सकते हैं।
यह पोर्टेबिलिटी LLVM के व्यापक उपयोग का कारण है: यह सिर्फ़ गति के बारे में नहीं है—यह बार-बार दोहराए जाने वाले प्लेटफ़ॉर्म-विशिष्ट कम्पाइलर काम से बचना भी है जो टीमों को धीमा करता है।
Clang: जहाँ कई डेवलपर्स पहली बार LLVM का अनुभव पाते हैं
Clang वह C, C++, और Objective-C का फ्रंटएंड है जो LLVM में प्लग होता है। अगर LLVM वह साझा इंजन है जो अनुकूलन और मशीन कोड जनरेट कर सकता है, तो Clang वह हिस्सा है जो आपकी सोर्स फाइलें पढ़ता है, भाषा नियमों को समझता है, और जो आपने लिखा है उसे LLVM के काम करने योग्य रूप में बदलता है।
Clang क्यों ध्यान खींचा
कई डेवलपर्स ने कम्पाइलर पेपर्स पढ़ कर LLVM नहीं खोजा—वे इसे तब अनुभव करते हैं जब वे कम्पाइलर बदलते हैं और फीडबैक अचानक बेहतर हो जाता है।
Clang के डायग्नोस्टिक्स पठनीय और विशिष्ट होने के लिए जाने जाते हैं। अस्पष्ट त्रुटियों के बजाय, यह अक्सर उस सटीक टोकन की ओर इशारा करता है जिसने समस्या पैदा की, संबंधित लाइन दिखाता है, और बताता है कि उसने क्या अपेक्षा की थी। यह दैनिक काम में महत्वपूर्ण है क्योंकि "कम्पाइल, ठीक करो, दोहराओ" लूप कम निराशाजनक बन जाता है।
Clang साफ़, अच्छी तरह दस्तावेज़ीकृत इंटरफ़ेस भी एक्सपोज़ करता है (खासकर libclang और व्यापक Clang टूलिंग इकोसिस्टम के माध्यम से)। इससे एडिटर्स, IDEs और अन्य डेवलपर टूल्स को गहरी भाषा समझ को इंटीग्रेट करना आसान हुआ बिना अपने आप C/C++ पार्सर फिर से बनाने के।
यह दैनिक वर्कफ़्लो में कैसे दिखता है
एक बार कोई टूल विश्वसनीय रूप से आपका कोड पार्स और विश्लेषण कर सके, तो आप ऐसी सुविधाएँ पाते हैं जो टेक्स्ट एडिटिंग से ज़्यादा संरचित प्रोग्राम के साथ काम करने जैसा लगता है:
- सटीक कोड नेविगेशन ("जम्प टू डेफिनिशन", "फाइंड रेफरेंसेज़") यहाँ तक कि बड़े, मैक्रो-भरे C++ प्रोजेक्ट्स में भी
- रिफैक्टरिंग सपोर्ट जो प्रतीकों और स्कोप्स को समझता है, सिर्फ़ सर्च-एंड-रिप्लेस नहीं
- Inline hints और quick fixes जो वास्तविक सिंटैक्स और टाइप जानकारी पर चलते हैं
यही कारण है कि Clang अक्सर LLVM का पहला टच-पॉइंट होता है: यह वह जगह है जहाँ व्यावहारिक डेवलपर एक्सपीरियंस में सुधार होते हैं। भले ही आप कभी भी LLVM IR या बैकएंड के बारे में न सोचें, तब भी आपके एडिटर की स्मार्ट ऑटो-कम्प्लीट, सटीक स्थैतिक चेक्स और आसान बिल्ड एरर आप अनुभव करते हैं।
क्यों कई आधुनिक भाषाएँ LLVM पर बनती हैं
LLVM भाषा टीमों के लिए इसलिए आकर्षक है क्योंकि यह उन्हें भाषा पर ध्यान केंद्रित करने देता है बजाय कि उत्पादन-गुणवत्ता वाले अनुकूलक और कोड जनरेटर को वर्षों में विकसित करने के।
तेज़ टाइम-टू-मार्केट
नई भाषा बनाना पहले से ही पार्सिंग, टाइप-चेकिंग, डायग्नोस्टिक्स, पैकेज टूलिंग, डॉक्यूमेंटेशन और कम्युनिटी सपोर्ट शामिल करता है। यदि आपको एक प्रोडक्शन-ग्रेड अनुकूलक, कोड जनरेटर, और प्लेटफ़ॉर्म सपोर्ट भी ज़ीरो से बनाना पड़े, तो शिपिंग में वर्षों की देरी हो सकती है।
LLVM एक रेडी-मेड कम्पाइलेशन कोर प्रदान करता है: रजिस्टर अलोकेशन, इंस्ट्रक्शन सेलेक्शन, परिपक्व अनुकूलन पासेस, और सामान्य CPUs के लिए टार्गेट। टीमें एक फ्रंटएंड प्लग कर सकती हैं जो उनकी भाषा को LLVM IR में निचे उतार दे, और फिर मौजूदा पाइपलाइन का भरोसा कर के macOS, Linux, और Windows के लिए नेटिव कोड पैदा कर सकती हैं।
उच्च प्रदर्शन (बिना हीरोवाद के)
LLVM का अनुकूलक और बैकएंड लंबी अवधि की इंजीनियरिंग और लगातार रीयल-वर्ल्ड टेस्टिंग का परिणाम हैं। इसका मतलब यह होता है कि LLVM अपनाने वाली भाषाओं के लिए एक मजबूत बेसलाइन प्रदर्शन मिलता है—अक्सर आरंभ में ही पर्याप्त अच्छा, और समय के साथ LLVM के सुधारों के साथ बेहतर होता जाता है।
इसीलिए कई जानी-मानी भाषाएँ इसके चारों ओर बनी हैं:
- Swift LLVM का उपयोग करके एप्पल प्लेटफ़ॉर्म्स के लिए अत्यधिक अनुकूलित नेटिव बाइनरी बनाती है।
- Rust कोड जनरेशन और कई आर्किटेक्चर टार्गेट के लिए LLVM पर निर्भर करती है।
- Julia तेज़ संख्यात्मक कोड और स्पेशलाइज़्ड वर्कलोड्स के लिए रनटाइम संकलन सक्षम करने के लिए LLVM का उपयोग करती है।
हर भाषा को LLVM की ज़रूरत नहीं होती
LLVM चुनना एक व्यापार-ऑफ है, आवश्यक नहीं। कुछ भाषाएँ छोटे बाइनरज़, अल्ट्रा-फास्ट कम्पाइलिंग, या टूलचेन पर कड़ाई से नियंत्रण प्राथमिकता देती हैं। कुछ के पास पहले से स्थापित कम्पाइलर होते हैं (जैसे GCC-आधारित इकोसिस्टम) या वे सरल बैकएंड पसंद करते हैं।
LLVM लोकप्रिय इसलिए है क्योंकि यह एक मजबूत डिफ़ॉल्ट है—न कि इसलिए कि यह एकमात्र वैध रास्ता है।
JIT और रनटाइम संकलन: तेज़ फ़ीडबैक लूप्स
अपना डोमेन इस्तेमाल करें
जब साझा करने का समय हो तो अपना कस्टम डोमेन लगाएँ।
"जस्ट-इन-टाइम" (JIT) संकलन को सबसे आसान तरीके से समझिए कि यह चलाने के दौरान संकलन है। सभी कोड को पहले से अनुवाद करने की बजाय, एक JIT इंजन तब तक प्रतीक्षा करता है जब तक कि किसी कोड के हिस्से की ज़रूरत न पड़े, फिर उस हिस्से को ऑन-द-फ़्लाई संकलित कर देता है—अक्सर वास्तविक रनटाइम जानकारी (जैसे कि सटीक प्रकार और डेटा के आकार) का उपयोग कर बेहतर विकल्प लेने के लिए।
JIT तेज़ क्यों महसूस हो सकता है
क्योंकि आपको सब कुछ पहले से संकलित नहीं करना पड़ता, JIT सिस्टम इंटरैक्टिव काम के लिए त्वरित प्रतिक्रिया दे सकते हैं। आप एक स्निपेट लिखते हैं, इसे तुरंत चलाते हैं, और सिस्टम केवल अभी ज़रूरी हिस्से को संकलित करता है। यदि वही कोड बार-बार चलता है, तो JIT संकलित परिणाम कैश कर सकता है या "हॉट" सेक्शन्स को अधिक आक्रामक रूप से फिर से संकलित कर सकता है।
जहाँ रनटाइम संकलन व्यावहारिक रूप से मदद करता है
JIT तब चमकता है जब वर्कलोड डायनेमिक या इंटरैक्टिव हों:
- REPLs और नोटबुक्स: स्निपेट्स को तुरंत एवैल्यूएट करें जबकि भारी लूप्स के लिए नेटिव-स्पीड निष्पादन भी मिले।
- प्लगइन्स और एक्सटेंशन्स: एप्लिकेशन रनटाइम पर यूज़र कोड लोड कर सकता है और उसे होस्ट CPU से मेल खाने के लिए संकलित कर सकता है।
- डायनेमिक वर्कलोड्स: जब इनपुट काफी बदलते हों, रनटाइम प्रोफाइलिंग यह मार्गदर्शन कर सकती है कि किस पाथ पर अनुकूलन करना है।
- साइंटिफिक कम्प्यूटिंग: जिन्केर्नल्स (विशेष मैट्रिक्स साइज, मॉडल आकार, या हार्डवेयर फीचर के लिए) मांग पर संकलित किए जा सकते हैं।
LLVM की भूमिका (हाइप के बिना)
LLVM हर प्रोग्राम को जादुई रूप से तेज़ नहीं बनाता, और यह अकेले पूरा JIT नहीं है। जो यह प्रदान करता है वह है एक टूलकिट: एक स्पष्ट IR, अनुकूलन पासेस का बड़ा सेट, और कई CPUs के लिए कोड जनरेशन। प्रोजेक्ट्स उन बिल्डिंग ब्लॉक्स के ऊपर JIT इंजन बना सकते हैं, स्टार्टअप समय, पीक परफॉर्मेंस, और जटिलता के बीच सही ट्रेडऑफ़ चुनते हुए।
प्रदर्शन, पूर्वानुमेयता, और वास्तविक-दुनिया के व्यापार-ऑफ
LLVM-आधारित टूलचेन अतिशय तेज़ कोड पैदा कर सकते हैं—पर "तेज़" एक ही, स्थिर गुण नहीं है। यह बिल्कुल उसी कम्पाइलर संस्करण, लक्ष्य CPU, अनुकूलन सेटिंग्स, और यहाँ तक कि आप कम्पाइलर से क्या मान रहे हैं, उन पर निर्भर करता है।
क्यों "एक ही स्रोत, अलग परिणाम" होता है
दो कम्पाइलर एक ही स्रोत पढ़ सकते हैं और फिर भी अलग मशीन कोड जेनरेट कर सकते हैं। इसका कुछ हिस्सा जानबूझकर होता है: हर कम्पाइलर के अपने अनुकूलन पासेस, हीयूरिस्टिक्स, और डिफ़ॉल्ट सेटिंग्स होती हैं। LLVM के भीतर भी, Clang 15 और Clang 18 अलग इनलाइनिंग निर्णय, अलग लूप वेक्टराइज़ेशन, या अलग इंस्ट्रक्शन शेड्यूल कर सकते हैं।
यह अनिश्चित या अस्पष्ट व्यवहार (undefined/unspecified behavior) के कारण भी हो सकता है। अगर आपका प्रोग्राम गलती से किसी ऐसी चीज़ पर निर्भर करता है जिसे मानक गारंटी नहीं करता (जैसे C में साइन किए गए ओवरफ्लो), तो अलग कम्पाइलर—या अलग फ्लैग—पर वे "अनुकूलन" ऐसे तरीके अपनाएंगे जो परिणाम बदल सकते हैं।
डिटर्मिनिज़्म, डिबग बिल्ड्स, और रिलीज़ बिल्ड्स
लोग अक्सर अपेक्षा करते हैं कि कम्पाइलेशन डिटर्मिनिस्टिक हो: वही इनपुट, वही आउटपुट। व्यवहार में, आप काफी हद तक पास होंगे, पर हमेशा समान बाइनरी नहीं मिलती। बिल्ड पाथ्स, टाइमस्टैम्प्स, लिंक ऑर्डर, प्रोफ़ाइल-गाइडेड डेटा, और LTO विकल्प अंतिम आर्टिफैक्ट को प्रभावित कर सकते हैं।
व्यावहारिक अंतर ज्यादा यह है कि डिबग बनाम रिलीज़। डिबग बिल्ड्स आमतौर पर कई अनुकूलनों को अक्षम करते हैं ताकि स्टेप-बाय-स्टेप डिबगिंग और पठनीय स्टैक ट्रेस संभव रहे। रिलीज़ बिल्ड्स आक्रामक रूप से ट्रांसफ़ॉर्म्स को सक्षम करते हैं जो कोड को रीऑर्डर कर सकते हैं, फ़ंक्शन्स इनलाइन कर सकते हैं, और वेरिएबल्स हटा सकते हैं—परformance के लिए बेहतरीन, पर डिबग कठिन कर सकते हैं।
व्यावहारिक सलाह: अनुमान ना लगाएं, मापें
प्रदर्शन को एक मापन समस्या मानें:
- प्रतिनिधि हार्डवेयर और वास्तविक डेटा सेट्स पर बेंचमार्क करें।
- कैश्स वॉर्म अप करें और कई पुनरावृत्तियाँ चलाएँ।
- स्पष्ट फ्लैग्स के साथ बिल्ड्स की तुलना करें (उदा.,
-O2बनाम-O3, LTO सक्षम/अक्षम, या-marchके साथ टार्गेट चुनना)।
छोटे फ्लैग बदलाव प्रदर्शन को किसी भी दिशा में बदल सकते हैं। सबसे सुरक्षित वर्कफ़्लो है: एक परिकल्पना चुनें, उसे मापें, और बेंचमार्क्स को उपयोगकर्ताओं के वास्तविक उपयोग के करीब रखें।
संकलन से आगे की टूलिंग: विश्लेषण, डिबगिंग, और सुरक्षा
पहला वर्ज़न पाएं
त्वरित फीडबैक के लिए वेब, बैकएंड या मोबाइल ऐप तेजी से प्रोटोटाइप करें।
LLVM को अक्सर एक कम्पाइलर टूलकिट कहा जाता है, पर कई डेवलपर्स इसका प्रभाव उन टूल्स के माध्यम से महसूस करते हैं जो कम्पाइलिंग के चारों ओर बैठते हैं: विश्लेषक, डिबगर, और सुरक्षा जाँचें जो बिल्ड्स और टेस्ट्स के दौरान चालू की जा सकती हैं।
विश्लेषण और इंस्ट्रूमेंटेशन "ऐड-ऑन" के रूप में
क्योंकि LLVM एक अच्छी तरह परिभाषित IR और पास पाइपलाइन दिखाता है, अतिरिक्त चरण बनाना स्वाभाविक है जो गति के अलावा किसी और उद्देश्य के लिए कोड की जाँच या री-राइट करें। एक पास प्रोफाइलिंग के लिए काउंटर डाल सकता है, संदिग्ध मेमोरी ऑपरेशन्स को चिन्हित कर सकता है, या कवरेज डेटा एकत्र कर सकता है।
मुख्य बिंदु यह है कि ये सुविधाएँ हर भाषा टीम को वही प्लम्बिंग फिर से नहीं बनानी पड़तीं।
सैनीटाइज़र्स: स्रोत के पास बग पकड़ना
Clang और LLVM ने रनटाइम "सैनीटाइज़र्स" का परिवार लोकप्रिय किया जो प्रोग्राम्स को टेस्टिंग के दौरान आम बग क्लासेज़ का पता लगाने के लिए इंस्ट्रूमेंट करते हैं—आउट-ऑफ़-बाउंड्स मेमोरी एक्सेस, यूज़-आफ्टर-फ्री, डेटा रेस, और अनिर्दिष्ट व्यवहार पैटर्न। ये जादुई सुरक्षा कवच नहीं हैं और सामान्यतः प्रोग्राम को धीमा करते हैं, इसलिए इन्हें मुख्यतः CI और प्री-रिलीज़ टेस्टिंग में इस्तेमाल किया जाता है। पर जब ये ट्रिगर करते हैं, तो अक्सर ये सटीक स्रोत स्थान और पठनीय स्पष्टीकरण देते हैं—जो व्यवधानकारी क्रैशेस का पीछा करते समय जरूरी होता है।
बेहतर डायग्नोस्टिक्स = तेज़ ऑनबोर्डिंग
टूलिंग क्वालिटी संचार के बारे में भी है। साफ चेतावनियाँ, कार्रवाई योग्य त्रुटि संदेश, और सुसंगत डिबग इन्फो नवागंतुकों के लिए "रहस्य" घटाते हैं। जब टूलचेन समझाता है क्या हुआ और इसे कैसे ठीक करें, तो डेवलपर्स कम समय कम्पाइलर क्विर्क्स याद रखने में और अधिक समय कोडबेस सीखने में बिताते हैं।
LLVM अपने आप में परफ़ेक्ट डायग्नोस्टिक्स या सुरक्षा की गारंटी नहीं देता, पर यह एक साझा आधार प्रदान करता है जो इन डेवलपर-फेसिंग टूल्स को बनाना, बनाए रखना और साझा करना व्यावहारिक बनाता है।
कब LLVM का उपयोग करें (और कब न करें)
LLVM को "अपनी खुद की कम्पाइलर और टूलिंग किट बनाओ" के रूप में सोचना सबसे ठीक है। यह लचीलेपन ही इसका कारण है कि यह कई आधुनिक टूलचेन चलाता है—पर यही कारण है कि यह हर प्रोजेक्ट के लिए सही उत्तर नहीं होता।
जब LLVM बेहतर फिट है
LLVM तब चमकता है जब आप गंभीर कम्पाइलर इंजीनियरिंग को दोहराए बिना पुन:उपयोग करना चाहते हैं।
यदि आप एक नई प्रोग्रामिंग भाषा बना रहे हैं, LLVM आपको एक सिद्ध अनुकूलन पाइपलाइन, कई CPU के लिए परिपक्व कोड जनरेशन, और अच्छे डिबग समर्थन का रास्ता दे सकता है।
यदि आप क्रॉस-प्लेटफ़ॉर्म एप्लिकेशन शिप कर रहे हैं, LLVM का बैकएंड इकोसिस्टम अलग आर्किटेक्चर को समर्थन देने का काम कम कर देता है। आप अपनी भाषा या प्रोडक्ट लॉजिक पर ध्यान रख सकते हैं, बजाय अलग-थलग कोड जेनरेटर लिखने के।
यदि आपका लक्ष्य डेवलपर टूलिंग—लिंटर्स, स्टैटिक एनालिसिस, कोड नेविगेशन, रिफैक्टरिंग—है, तो LLVM (और उससे जुड़ा इकोसिस्टम) एक मजबूत आधार है क्योंकि कम्पाइलर पहले से ही कोड संरचना और प्रकार को "समझता" है।
जब यह ओवरकिल हो सकता है
यदि आप छोटी एम्बेडेड प्रणालियों पर काम कर रहे हैं जहाँ बिल्ड साइज, मेमोरी, और कम्पाइल समय कड़ाई से सीमित हैं, तो LLVM भारी हो सकता है।
यह बहुत विशिष्ट पाइपलाइनों के लिए भी खराब फिट हो सकता है जहाँ आप सामान्य-उद्देश्य अनुकूलनों को नहीं चाहते, या जहाँ आपकी "भाषा" एक फिक्स्ड DSL है जिसका सीधे-सीधे मशीन कोड मैपिंग सरल हो।
एक सरल चेकलिस्ट
इन तीन प्रश्नों से पूछें:
- क्या हमें अब या जल्द ही कई प्लेटफ़ॉर्म/CPUs को लक्षित करने की ज़रूरत है?
- क्या हम मौजूदा अनुकूलनों और डिबग इन्फो से लाभ उठाएंगे बजाय अपने आप बनाने के?
- क्या हम एक इकोसिस्टम मार्ग (टूलिंग, इंटीग्रेशन, hiring) चाहते हैं बजाय सबसे छोटे, कस्टम कम्पाइलर के?
यदि आपने ज़्यादातर सवालों का जवाब "हाँ" दिया, तो LLVM आम तौर पर एक व्यावहारिक दांव है। यदि आपका लक्ष्य मुख्यतः एक छोटे, सरल कम्पाइलर तक सीमित है जो एक संकुचित समस्या हल करे, तो हल्का दृष्टिकोण जीत सकता है।
उत्पाद टीमों के लिए एक व्यावहारिक नोट: LLVM के लाभ बिना कम्पाइलर विशेषज्ञ बने हुए
अधिकांश टीमें "LLVM अपनाना" एक प्रोजेक्ट के रूप में नहीं चाहतीं। वे परिणाम चाहते हैं: क्रॉस-प्लेटफ़ॉर्म बिल्ड्स, तेज़ बाइनरीज़, अच्छे डायग्नोस्टिक्स, और भरोसेमंद टूलिंग।
इसीलिए प्लेटफ़ॉर्म जैसे Koder.ai इस संदर्भ में दिलचस्प होते हैं। यदि आपका वर्कफ़्लो ऊपरी-स्तर ऑटोमेशन (प्लानिंग, स्कैफ़ोल्डिंग जनरेशन, तंग लूप में इटरेशन) से चला रहा है, तो आप LLVM से अप्रत्यक्ष रूप से फायदे उठाते हैं—चाहे आप React वेब ऐप बना रहे हों, PostgreSQL वाले Go बैकएंड, या Flutter मोबाइल क्लाइंट। Koder.ai का चैट-ड्रिवन "vibe-coding" तरीका उत्पाद तेज़ी से शिप करने पर केंद्रित है, जबकि आधुनिक कम्पाइलर अवसंरचना (LLVM/Clang और साथी, जहाँ लागू) बैकग्राउंड में अनुकूलन, डायग्नोस्टिक्स, और पोर्टेबिलिटी का नीरव काम करती रहती है।