28 दिस॰ 2025·8 मिनट
प्रदर्शन जांच के लिए Claude Code: एक मापा हुआ वर्कफ़्लो
Claude Code का उपयोग प्रदर्शन जांचों के लिए एक पुनरावृत्त लूप के साथ करें: मापें, परिकल्पना बनाएं, छोटा बदलाव करें, और शिप करने से पहले पुनःमापें।
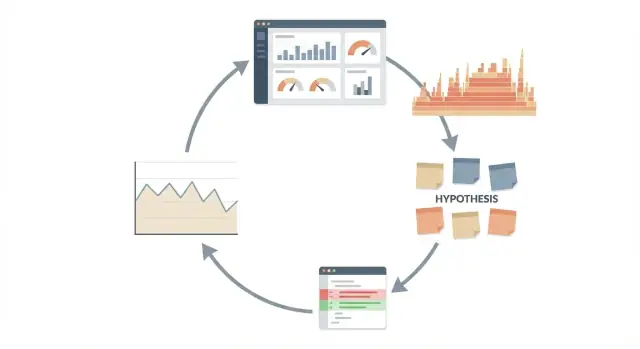
Claude Code का उपयोग प्रदर्शन जांचों के लिए एक पुनरावृत्त लूप के साथ करें: मापें, परिकल्पना बनाएं, छोटा बदलाव करें, और शिप करने से पहले पुनःमापें।
प्रदर्शन बग अनुमान लगाने को आमंत्रित करते हैं। कोई पाता है कि पेज धीमा लगता है या API टाइम आउट हो रही है, और सबसे तेज़ कदम होता है कोड "साफ़ करना", कैश जोड़ना, या लूप फिर से लिखना। समस्या यह है कि "धीमा लगता है" कोई मेट्रिक नहीं है, और "साफ़" जरूरी नहीं कि तेज़ हो।
माप के बिना, टीमें गलत चीज़ बदलकर घंटे बर्वाद कर देती हैं। हॉट पाथ डेटाबेस, नेटवर्क, या एक अप्रत्याशित अलोकेशन में हो सकता है, जबकि टीम उस कोड को पालिश कर रही होती है जो शायद ही समय लेता हो। और बुरा यह कि जो बदलाव समझदारी दिखता है वह प्रदर्शन को खराब भी कर सकता है: टाइट लूप में अतिरिक्त लॉगिंग, कैश जो मेमोरी दबाव बढ़ा दे, या पैरलल काम जो लॉक कंटेंशन पैदा करे।
अनुमान लगाने से व्यवहार टूटने का खतरा भी रहता है। जब आप तेज़ करने के लिए कोड बदलते हैं, तो आप परिणाम, त्रुटि‑हैंडलिंग, ऑर्डरिंग या रीट्राई बदल सकते हैं। अगर आप सटीकता और गति दोनों को फिर से जाँचते नहीं हैं, तो आप बेंचमार्क "जीत" सकते हैं जबकि चुपचाप एक बग शिप कर रहे हों।
प्रदर्शन को बहस की तरह नहीं बल्कि प्रयोग की तरह ट्रीट करें। लूप सरल और दोहराने योग्य है:
कई जीतें मामूली होती हैं: p95 latency से 8% घटाना, पीक मेमोरी 50 MB कम करना, या एक DB क्वेरी कटाना। वे तब तक मायने रखते हैं जब तक उन्हें मापा, सत्यापित और दोहराया जा सके।
यह एक‑ऑफ़ "इसे तेज़ करो" अनुरोध नहीं बल्कि एक लूप के रूप में सबसे अच्छा काम करता है। लूप आपको ईमानदार रखता है क्योंकि हर क्रिया साक्ष्य और एक नंबर से जुड़ी होती है जिसे आप देख सकते हैं।
एक स्पष्ट क्रम:
हर कदम आपको अलग तरह की शिथिलता से बचाता है। पहले मापना आपको ऐसी चीज़ "सुधारने" से रोकता है जो असल समस्या न हो। लिखी हुई परिकल्पना आपको पाँच चीज़ें एक साथ बदलकर अनुमान लगाने से रोकती है। न्यूनतम परिवर्तन व्यवहार तोड़ने या नए बोटलनेक्स जोड़ने के जोखिम को घटाते हैं। पुनःमापना प्लेसबो‑जीत (उदा. गर्म कैश के कारण तेज़ रन) पकड़ती है और रिग्रेशन उजागर करती है।
"पूरा" होना एक भावना नहीं है। यह एक परिणाम है: लक्ष्य मेट्रिक सही दिशा में गया, और बदलाव ने स्पष्ट रिग्रेशन नहीं किए (errors, अधिक memory, बदतर p95 latency, या आस‑पास के endpoints धीमे होना)।
रुकना कब है यह जानना भी वर्कफ़्लो का हिस्सा है। तब रुकें जब लाभ फ्लैट हो जाएँ, मेट्रिक उपयोगकर्ताओं के लिए पहले से ही पर्याप्त हो, या अगला विचार बड़े रिफैक्टर की मांग करता हो पर लाभ छोटा हो। प्रदर्शन काम हमेशा अवसर‑लागत रखता है; यह लूप आपको उस जगह समय खर्च करने में मदद करता है जहाँ यह भुगतान करता है।
यदि आप एक साथ पाँच चीज़ें मापेंगे, तो आप नहीं जान पाएँगे कि क्या सुधरा। इस जांच के लिए एक प्राथमिक मेट्रिक चुनें और बाकी को समर्थन संकेत मानें। कई यूज़र‑फेस वाले मामलों में वह मेट्रिक latency है। बैच काम के लिए यह throughput, CPU समय, memory उपयोग, या प्रति रन क्लाउड लागत हो सकती है।
परिदृश्य के बारे में सटीक हों। "API धीमा है" बहुत अस्पष्ट है। "POST /checkout एक सामान्य कार्ट (3 आइटम) के साथ" मीटर करने योग्य है। इनपुट्स को स्थिर रखें ताकि संख्याओं का मतलब हो।
कोड छूने से पहले बेसलाइन और वातावरण विवरण लिखें: डेटासेट साइज, मशीन टाइप, बिल्ड मोड, फीचर फ़्लैग, समकालन, और वार्मअप। यह बेसलाइन आपका एंकर है। इसके बिना हर बदलाव प्रगति दिख सकता है।
Latency के लिए औसत पर निर्भर न रहें; percentiles पर ध्यान दें। p50 सामान्य अनुभव दिखाता है, जबकि p95 और p99 वह दर्दनाक पूंछ दिखाते हैं जिसकी उपयोगकर्ता शिकायत करते हैं। ऐसा बदलाव जो p50 सुधारे पर p99 बिगाड़ दे सकता है, तब भी धीमा महसूस होगा।
शुरू में तय कर लें कि "महत्वपूर्ण" का अर्थ क्या है ताकि आप शोर पर जश्न न मनाएँ:
एक बार ये नियम सेट हो जाने पर आप बिना लक्ष्य‑रेखा हिलाए विचारों की जांच कर सकते हैं।
सबसे विश्वसनीय आसान संकेत से शुरू करें। किसी अनुरोध के चारों ओर एक सिंगल टाइमिंग यह बता सकती है कि क्या आपके पास असली समस्या है और इसका आकार कितनी मोटाई का है। जब आपको यह समझाने की ज़रूरत हो कि यह क्यों धीमा है तब गहरी प्रोफाइलिंग करें।
अच्छा साक्ष्य आमतौर पर कई स्रोतों के मिश्रण से आता है:
साधारण मेट्रिक्स का प्रयोग तब करें जब प्रश्न हो "क्या यह धीमा हुआ है, और कितना?" प्रोफाइलिंग तब करें जब प्रश्न हो "समय कहाँ जा रहा है?" अगर p95 latency किसी deploy के बाद दोगुना हो गया है, तो रिग्रेशन की पुष्टि के लिए पहले timings और logs देखें और स्कोप तय करें। अगर timings दिखाएँ कि देरी आपकी एप कोड में है (DB नहीं), तो एक CPU प्रोफाइलर या फ्लेम ग्राफ उस फ़ंक्शन की ओर इशारा कर सकता है जो बढ़ा है।
माप सुरक्षित रखें। प्रदर्शन डिबग के लिए जो चाहिए वह एकत्र करें, न कि उपयोगकर्ता सामग्री। aggregates (durations, counts, sizes) को प्राथमिकता दें और पहचानकर्ताओं को डिफ़ॉल्ट रूप से redact करें।
शोर वास्तविक है, इसलिए कई सैम्पल लें और आउटलाइनर्स नोट करें। वही अनुरोध 10–30 बार चलाएँ, और एक‑रन के बजाय median और p95 रिकॉर्ड करें।
ठीक वही टेस्ट रेसिपी लिखें ताकि आप बदलाव के बाद इसे दोहरा सकें: वातावरण, डेटासेट, एंडपॉइंट, रिक्वेस्ट बॉडी साइज, समकालन स्तर, और आपने नतीजे कैसे कैप्चर किए।
एक लक्षण से शुरू करें जिसे आप नाम दे सकें: "p95 latency peaks 220 ms से 900 ms तक ट्रैफ़िक पीक्स के दौरान", "CPU दो कोर पर 95% पर अटका हुआ है", या "memory प्रति घंटे 200 MB बढ़ रही है।" "धीमा लग रहा है" जैसे अस्पष्ट लक्षण यादृच्छिक बदलावों की ओर ले जाते हैं।
फिर आपने जो मापा है उसे संदिग्ध क्षेत्र में अनुवाद करें। एक फ्लेम ग्राफ अधिकांश समय JSON encoding में दिखा सकता है, एक ट्रेस धीमी कॉल पथ दिखा सकता है, या डेटाबेस स्टैट्स एक ही क्वेरी को कुल समय में डोमिनेट करते दिखा सकते हैं। उस छोटे से हिस्से को चुनें जो अधिकांश लागत की व्याख्या करे: एक फ़ंक्शन, एक SQL क्वेरी, या एक बाहरी कॉल।
एक अच्छी परिकल्पना एक वाक्य हो, परीक्षणयोग्य हो, और एक भविष्यवाणी से जुड़ी हो। आप मदद माँग रहे हैं एक विचार की जाँच करने की, न कि किसी टूल से चमत्कारिक रूप से सब कुछ तेज़ करने की।
इस फॉर्मेट का उपयोग करें:
उदाहरण: "क्योंकि प्रोफ़ाइल दिखाती है कि CPU का 38% SerializeResponse में खर्च हो रहा है, हर अनुरोध पर नया बफ़र एलोकेट करना CPU स्पाइक्स का कारण बन रहा है। अगर हम बफ़र reuse करें तो p95 latency लगभग 10–20% घटनी चाहिए और वही लोड पर CPU ~15% कम होना चाहिए।"
कोड छूने से पहले विकल्पों का नाम देकर खुद को ईमानदार रखें। शायद धीमी बात वास्तव में अपस्ट्रीम dependency है, लॉक कंटेंशन है, कैश मिस‑रेट बदला है, या रोलआउट ने payload साइज बढ़ा दिया है।
2–3 वैकल्पिक व्याख्याएँ लिखें, फिर वह चुनें जिसे आपका साक्ष्य सबसे बेहतर समर्थन देता है। अगर आपका बदलाव मेट्रिक नहीं हिलाता, तो आपके पास अगली परिकल्पना पहले से तैयार होगी।
Claude सबसे उपयोगी तब होता है जब आप इसे एक सावधान विश्लेषक की तरह ट्रीट करते हैं, ना कि एक ओरेकल की तरह। हर सुझाव को आपने जो मापा उससे जोड़ें, और सुनिश्चित करें कि हर कदम गलत साबित हो सकता है।
इसे सामान्य विवरण नहीं, बल्कि वास्तविक इनपुट दें। छोटे, केंद्रित साक्ष्य पेस्ट करें: एक प्रोफ़ाइल सारांश, धीमे अनुरोध के आसपास कुछ लॉग लाइन्स, एक क्वेरी प्लान, और विशिष्ट कोड पथ। "पहले" नंबर (p95 latency, CPU time, DB time) शामिल करें ताकि यह आपका बेसलाइन जाने।
पूछें कि डेटा क्या सुझाता है और क्या नहीं समर्थन करता। फिर प्रतिस्पर्धी व्याख्याओं को जबरदस्ती करवाएँ। एक उपयोगी प्रॉम्प्ट का अंत यह हो: "मुझे 2–3 परिकल्पनाएँ दें, और हर एक के लिए बताइए कि उसे फॉल्सिफाई करने का तरीका क्या होगा।" यह पहले संभावित कहानी पर अटकने से रोकता है।
कोड छूने से पहले उस प्रमुख परिकल्पना को वेलिडेट करने के लिए सबसे छोटा प्रयोग माँगें। इसे तेज़ और reversible रखें: किसी फ़ंक्शन के चारों ओर एक टाइमर जोड़ें, एक प्रोफ़ाइलर फ़्लैग चालू करें, या एक DB क्वेरी EXPLAIN के साथ चलाएँ।
अगर आप आउटपुट के लिए कड़ा स्ट्रक्चर चाहते हैं, तो पूछें:
यदि यह एक विशिष्ट मेट्रिक, स्थान और अपेक्षित परिणाम का नाम नहीं दे सकता, तो आप फिर से अनुमान पर लौट रहे हैं।
साक्ष्य और परिकल्पना होने के बाद, सब कुछ "साफ़ करने" की लालसा से बचें। परफ़ॉर्मेंस कार्य तब सबसे भरोसेमंद होता है जब कोड परिवर्तन छोटे और आसानी से उलटने योग्य हों।
एक समय में एक ही चीज़ बदलें। अगर आप एक ही कमिट में क्वेरी ट्वीक करें, कैश जोड़ें, और लूप रिफैक्टर करें, तो आप नहीं जान पाएँगे कि क्या मदद किया (या क्या नुकसान पहुंचाया)। सिंगल‑वेरिएबल परिवर्तन अगले माप को अर्थपूर्ण बनाते हैं।
कोड छूने से पहले संख्याओं में लिखकर बताएं कि आप क्या उम्मीद करते हैं। उदाहरण: "p95 latency 420 ms से 300 ms से कम होना चाहिए, और DB time लगभग 100 ms घटनी चाहिए।" अगर परिणाम लक्ष्य से चूकता है, तो आप जल्दी सीखते हैं कि परिकल्पना कमजोर या अपूर्ण थी।
परिवर्तन को उलटने योग्य रखें:
"न्यूनतम" का अर्थ "तुरंत छोटा" नहीं है; इसका अर्थ केंद्रित है: एक महँगे फ़ंक्शन का कैश करें, टाइट लूप में एक बार होने वाली आवंटन हटाएँ, या उन अनुरोधों के लिए काम रोक दें जिन्हें इसकी आवश्यकता नहीं।
संदेहास्पद बॉटलनेक्स के चारों ओर हल्का‑फुल्का टाइमिंग जोड़ें ताकि आप देख सकें क्या हिला। किसी कॉल से पहले और बाद का सिंगल टाइमस्टैम्प (लॉग या मेट्रिक के रूप में) यह पुष्ट कर सकता है कि आपका परिवर्तन सच में धीमी जगह पर असर कर रहा है या बस समय कहीं और शिफ्ट कर दिया।
बदलाव के बाद वही परिदृश्य फिर चलाएँ जो आपने बेसलाइन के लिए इस्तेमाल किया था: वही इनपुट्स, वही वातावरण, और वही लोड‑आकृति। अगर आपका टेस्ट कैशेस या वार्म‑अप पर निर्भर करता है, तो उसे स्पष्ट करें (उदा.: "पहला रन कोल्ड, अगले 5 रन वॉर्म")। वरना आप ऐसे सुधार पाएँगे जो केवल किस्मत थे।
परिणामों की तुलना वही मेट्रिक और वही प्रतिशत‑मानों का उपयोग करके करें। औसत दर्द छिपा सकता है, इसलिए p95 और p99 latency के साथ throughput और CPU time पर नजर रखें। संख्याएँ स्थिर हों यह देखने के लिए पर्याप्त पुनरावृत्तियाँ चलाएँ।
जश्न मनाने से पहले ऐसे रिग्रेशन चेक करें जो एक हेडलाइन नंबर में न दिखें:
फिर आशा नहीं, साक्ष्य के आधार पर निर्णय लें। अगर सुधार वास्तविक है और आपने रिग्रेशन नहीं दिए, तो इसे रखें। अगर परिणाम मिश्रित या शोर से भरे हैं, तो revert करें और नई परिकल्पना बनाएं, या परिवर्तन को और अलग कर दें।
अगर आप Koder.ai जैसे प्लेटफ़ॉर्म पर काम कर रहे हैं, तो प्रयोग से पहले एक स्नैपशॉट लेना रॉलबैक को एक कदम बना सकता है, जिससे साहसिक विचारों की जाँच आसान होती है।
अंत में, आपने क्या सीखा इसे लिख दें: बेसलाइन, बदलाव, नए नंबर, और नतीजा। यह छोटा रिकॉर्ड अगले दौर को उन्हीं भूलों को दोहराने से बचाता है।
प्रदर्शन कार्य आमतौर पर उस समय गलती पर चला जाता है जब आपने जो मापा था और जो बदला था, उनके बीच धागा खो देते हैं। साफ़ साख की चैन रखें ताकि आप आत्म‑विश्वास से कह सकें कि किसने चीज़ों को बेहतर या खराब किया।
बार‑बार होने वाली गलतियाँ:
एक छोटा उदाहरण: एक एंडपॉइंट धीमा दिखता है, इसलिए आप serializer ट्यून करते हैं क्योंकि प्रोफ़ाइल में वह हॉट दिखा। फिर आप छोटे डेटासेट में पुनःटेस्ट करते हैं और यह तेज़ दिखता है। प्रोडक्शन में p99 बदतर हो जाता है क्योंकि DB अब भी बॉटलनेक है और आपका परिवर्तन payload साइज बढ़ा गया।
यदि आप Claude Code का उपयोग करके सुधार सुझाव प्राप्त करते हैं, तो इसे कड़ा नियंत्रण में रखें। 1–2 न्यूनतम बदलाव माँगें जो पहले से इकट्ठे साक्ष्य से मेल खाते हों, और पैच स्वीकार करने से पहले पुनःमापन योजना पर ज़ोर दें।
टेस्ट अस्पष्ट होने पर स्पीड दावे ढह जाते हैं। जश्न मनाने से पहले यह सुनिश्चित करें कि आप बता सकते हैं कि आपने क्या मापा, कैसे मापा, और क्या बदला।
शुरू करें एक मेट्रिक नामकर के और बेसलाइन नतीजा लिखकर। वे विवरण शामिल करें जो संख्याएँ बदलते हैं: मशीन टाइप, CPU लोड, डेटासेट साइज, बिल्ड मोड (debug vs release), फीचर फ़्लैग, कैश स्थिति, और समकालन। अगर आप सेटअप कल दोहराने योग्य नहीं बना सकते, तो आपके पास बेसलाइन नहीं है।
चेकलिस्ट:
नंबर बेहतर दिखने के बाद, एक तेज़ रिग्रेशन पास करें। सहीपन चेक करें (उत्पादन वही है), त्रुटि दर और टाइमआउट देखें। उच्च मेमोरी, CPU स्पाइक्स, स्लो स्टार्टअप, या अधिक DB लोड जैसे साइड‑इफेक्ट्स पर नज़र रखें। ऐसा परिवर्तन जो p95 latency सुधारता है पर मेमोरी दोगुना कर देता है, गलत ट्रेड‑ऑफ हो सकता है।
एक टीम रिपोर्ट करती है कि GET /orders dev में ठीक लगता है, पर staging में मध्यम लोड पर धीमा हो जाता है। उपयोगकर्ता टाइमआउट की शिकायत कर रहे हैं, पर औसत latency अभी भी "ठीक" दिखता है, जो एक क्लासिक जाल है।
पहले बेसलाइन सेट करें। एक स्थिर लोड टेस्ट के तहत (वही डेटासेट, वही समकालन, वही अवधि), आप रिकॉर्ड करते हैं:
अब साक्ष्य इकट्ठा करें। एक त्वरित ट्रेस दिखाता है कि एंडपॉइंट ऑर्डर्स के लिए एक मुख्य क्वेरी चलाता है, फिर प्रत्येक ऑर्डर के लिए संबंधित आइटम्स को अलग‑अलग फेच करता है। आप यह भी देखते हैं कि JSON रिस्पॉन्स बड़ा है, पर DB समय भारी है।
इसे परिकल्पनाओं की सूची में बदलें जिन्हें आप जाँच सकते हैं:
सबसे मजबूत साक्ष्य के अनुरूप एक न्यूनतम परिवर्तन माँगें: एक स्पष्ट N+1 कॉल हटाएँ — ऑर्डर IDs द्वारा की गई single query में आइटम्स फेच करके (या अगर slow query plan एक फुल‑स्कैन दिखाता है तो मिसिंग index जोड़ें)। इसे reversible और एक केंद्रित कमिट में रखें।
उसी लोड टेस्ट के साथ पुनःमापें। नतीजे:
निर्णय: फ़िक्स शिप करें (स्पष्ट जीत), फिर शेष गैप और CPU स्पाइक्स पर ध्यान देने के लिए दूसरा चक्र शुरू करें, क्योंकि DB अब मुख्य बॉटलनेक नहीं रहा।
प्रदर्शन जांच में बेहतर बनने का सबसे तेज़ तरीका हर रन को एक छोटे प्रयोग की तरह ट्रीट करना है जिसे आप दोहरा सकें। जब प्रक्रिया सुसंगत होती है, तो नतीजे अधिक भरोसेमंद, तुलना योग्य और साझा करने योग्य बन जाते हैं।
एक सरल एक‑पेज टेम्पलेट मदद करता है:
निर्णय करें कि ये नोट्स कहाँ रहते हैं ताकि वे गायब न हों। एक साझा जगह साधन की तुलना में अधिक मायने रखती है: सेवा के बगल वाले रिपो फोल्डर, टीम डॉक, या टिकट नोट्स। मुख्य बात खोज‑योग्यता है। किसी को भी महीनों बाद "कैश परिवर्तन के बाद p95 spike" मिल जाना चाहिए।
सुरक्षित प्रयोग करने की आदत डालें। स्नैपशॉट और आसान रॉलबैक का उपयोग करें ताकि आप बिना डर के विचार आज़मा सकें। यदि आप Koder.ai के साथ बना रहे हैं, तो Planning Mode प्रयोग योजना लिखने, परिकल्पना परिभाषित करने, और बदलाव को सीमित रखने के लिए सुविधाजनक जगह हो सकती है, इससे पहले कि आप एक तंग डिफ़ जनरेट करें और फिर से मापें।
एक कैडेंस सेट करें। घटनाओं की प्रतीक्षा न करें। नए क्वेरीज, नए एंडपॉइंट्स, बड़े payloads, या dependency upgrades के बाद छोटे‑छोटे प्रदर्शन चेक जोड़ें। अब 10 मिनट का बेसलाइन चेक बाद में एक दिन की गेसिंग बचा सकता है।
एक संख्या से शुरू करें जो शिकायत से मेल खाती हो — आम तौर पर किसी विशिष्ट एंडपॉइंट और इनपुट के लिए p95 latency। उसी परिस्थितियों में एक बेसलाइन रिकॉर्ड करें (डेटा साइज़, समकालन, वॉर्म/कोल्ड कैश)। फिर एक चीज़ बदलें और फिर से मापें。
यदि आप बेसलाइन पुनरुत्पन्न नहीं कर सकते, तो आप अभी माप नहीं रहे हैं — आप अंदाज़ लगा रहे हैं।
एक उपयोगी बेसलाइन में शामिल होना चाहिए:
इसे कोड छूने से पहले लिखें ताकि आप लक्ष्य‑रेखा न हिलाएँ।
प्रतिशत‑मान उपयोगकर्ता अनुभव को औसत की तुलना में बेहतर दिखाते हैं। p50 सामान्य अनुभव दिखाता है, पर उपयोगकर्ता उस धीमी पूंछ की शिकायत करते हैं जो p95/p99 है।
यदि p50 बेहतर होता है पर p99 खराब हो जाता है, तो सिस्टम धीमा महसूस हो सकता है भले ही औसत बेहतर दिखे।
सरल टाइमिंग/लॉग तब उपयोग करें जब प्रश्न हो "क्या यह धीमा हुआ है और कितना?" प्रोफाइलिंग तब करें जब प्रश्न हो "समय कहाँ जा रहा है?"
प्रायोगिक प्रवाह: पहले अनुरोध टाइमिंग से रिग्रेशन की पुष्टि करें, फिर केवल उस केस में प्रोफाइल करें जब धीमा होना वास्तविक और स्कोप्ड है।
एक प्राथमिक मेट्रिक चुनें और बाकी को गार्डरेल समझें। एक सामान्य सेट है:
यह आपको एक चार्ट जीतकर चुपचाप टाइमआउट, मेमरी ग्रोथ, या बदतर टेल‑लेटेंसी पैदा करने से बचाता है।
एक वाक्य में लिखी गई, साक्ष्य‑बंधी और परीक्षण योग्य परिकल्पना होनी चाहिए:
यदि आप साक्ष्य और अपेक्षित मेट्रिक‑हिल नहीं बता सकते, तो परिकल्पना अभी परीक्षणयोग्य नहीं है।
छोटा, केंद्रित और आसानी से उलटने योग्य रखें:
छोटे डिफ़ अगला माप अर्थपूर्ण बनाते हैं और व्यवहार तोड़ने का जोखिम घटाते हैं।
वही बेसलाइन परिदृश्य (समान इनपुट, वातावरण, और लोड) पुनः चलाएँ। अगर आपका टेस्ट कैश या वॉर्म‑अप पर निर्भर है, तो उसे स्पष्ट करें। अन्यथा आप ऐसे सुधार "पाएंगे" जो किस्मत थे।
इसके बाद हेडलाइन नंबर के अलावा रिग्रेशन‑चेक करें:
अगर सुधार असली है और रिग्रेशन नहीं है, तो उसे रखें; वरना revert कर के नई परिकल्पना बनाएं या दायरा और सिकोड़ें।
कंक्रीट साक्ष्य दें और इसे परीक्षण‑चालित रखें:
अगर आउटपुट किसी विशेष मेट्रिक और पुनःपरीक्षण योजना का नाम नहीं देता, तो आप फिर से अंदाज़ पर लौट रहे हैं।
नहीं—रुकें जब:
प्रदर्शन काम का अवसर‑लागत होता है। यह लूप (measure → hypothesize → change → re‑measure) आपको केवल उन्हीं जगहों पर समय खर्च कराता है जहाँ संख्या यह साबित करती है कि यह मायने रखता है।