07 मई 2025·8 मिनट
डेटाबेस शार्डिंग कैसे काम करता है — और इसे समझना क्यों मुश्किल है
Shardिंग डेटा को नोड्स में बाँटकर डेटाबेस को स्केल करता है, लेकिन यह राउटिंग, रीबैलेंसिंग और नए फेलियर मोड जोड़ता है जो सिस्टम को समझना कठिन बनाते हैं।
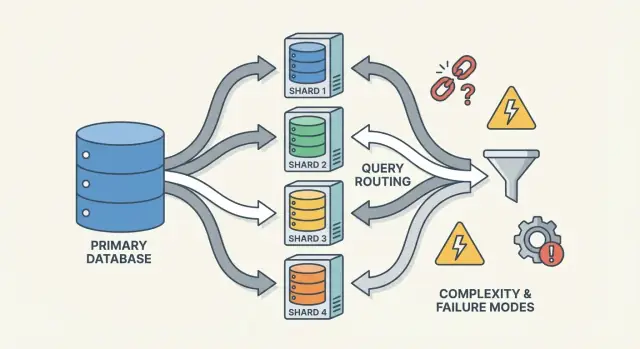
Shardिंग डेटा को नोड्स में बाँटकर डेटाबेस को स्केल करता है, लेकिन यह राउटिंग, रीबैलेंसिंग और नए फेलियर मोड जोड़ता है जो सिस्टम को समझना कठिन बनाते हैं।
Shardिंग (जिसे horizontal partitioning भी कहा जाता है) का मतलब है कि आपके एप्लिकेशन के लिए जो एक डेटाबेस दिखता है, उसके डेटा को कई मशीनों में बाँटना—जिन्हें shards कहते हैं। हर शार्ड केवल कुछ रोज़ रखता है, लेकिन साथ मिलकर वे पूरा dataset बनाते हैं.
एक उपयोगी मानसिक मॉडल है लॉजिकल स्ट्रक्चर और फ़िज़िकल प्लेसमेंट के बीच का फर्क:
एप्लिकेशन के नज़रिए से आप चाहते हैं कि क्वेरीज ऐसे चलें जैसे यह एक टेबल हो। अंदरूनी तौर पर सिस्टम को तय करना होगा कि कौन से शार्ड(स) से बात करनी है।
Shardिंग replication से अलग है। Replication एक ही डेटा की कॉपीज़ बनाता है कई नोड्स पर—मुख्यत: हाई अवेलेबिलिटी और रीड स्केलिंग के लिए।Shardिंग डेटा को बाँटता है ताकि हर नोड पर अलग रिकॉर्ड हों।
यह vertical scaling से भी अलग है, जहाँ आप एक डेटाबेस रखते हैं पर उसे बड़े मशीन पर ले जाते हैं (ज़्यादा CPU/RAM/फास्ट डिस्क)। वर्टिकल स्केलिंग सरल हो सकती है, पर व्यावहारिक सीमाएँ और तीव्र लागत बढ़ना भी आम है।
Shardिंग क्षमता बढ़ाती है, मगर यह अपने आप आपका डेटाबेस "आसान" या हर क्वेरी तेज़ नहीं बना देती।
इसलिए शार्डिंग को सबसे अच्छा इस रूप में समझा जाना चाहिए कि यह स्टोरेज और थ्रूपुट को स्केल करता है—हर डेटाबेस व्यवहार का मुफ्त अपग्रेड नहीं।
Shardिंग किसी की पहली पसंद कम ही होती है। टीमें आम तौर पर तब शार्ड की ओर जाती हैं जब सफल सिस्टम भौतिक सीमाओं तक पहुँचता है—या ऑपरेशनल दर्द बार-बार होने लगे। प्रेरणा कम "हम शार्ड करना चाहते हैं" और ज्यादा "हमें बिना एक डेटाबेस को सिंगल पॉइंट ऑफ फेलियर और महँगा बनाए, बढ़ते रहने का रास्ता चाहिए" होती है।
एक सिंगल डेटाबेस नोड कई तरीकों से जगह को खत्म कर सकता है:
जब ये समस्याएँ नियमित रूप से दिखती हैं, तो अक्सर समस्या एक खराब क्वेरी नहीं होती—बल्कि एक मशीन बहुत ज़्यादा जिम्मेदारी उठाती है।
डेटाबेस शार्डिंग डेटा और ट्रैफ़िक को कई नोड्स पर फैलाती है ताकि क्षमता मशीनें जोड़कर बढ़े न कि एक महँगे अपग्रेड से। सही तरीके से किया जाए तो यह वर्कलोड्स को अलग-थलग रखता है (ताकि एक टेनेंट की spike बाकी का latency खराब न करे) और लागत नियंत्रित कर सकता है क्योंकि बहुत बड़े प्रीमियम इंस्टेंस से बचा जा सके।
दोहराए जाने वाले पैटर्न में पी95/पी99 लेटेंसी में लगातार वृद्धि पीक के दौरान, बढ़ा हुआ replication lag, बैकअप/रिस्टोर का समय मंज़ूर विंडो से बाहर जाना, और "छोटे" स्कीमा बदलाव बड़े इवेंट बन जाना शामिल हैं।
कमीट करने से पहले, टीमें आमतौर पर सरल विकल्प निकाल देती हैं: इंडेक्सिंग और क्वेरी सुधार, कैशिंग, रीड रिप्लिकास, एकल डेटाबेस के भीतर पार्टिशनिंग, पुराने डेटा का आर्काइव करना, और हार्डवेयर अपग्रेड।Shardिंग स्केल सॉल्व कर सकता है, पर यह समन्वय, ऑपरेशनल जटिलता, और नए फेलियर मोड जोड़ता है—इसलिए मानक ऊँचा होना चाहिए।
एक शार्डेड डेटाबेस कोई एक चीज़ नहीं है—यह मेलजोल करने वाले छोटे हिस्सों का सिस्टम है। शार्डिंग को “सोचने में मुश्किल” इसलिए लगता है क्योंकि करेक्टनेस और प्रदर्शन उन टुकड़ों के इंटरैक्शन पर निर्भर करते हैं, सिर्फ़ डेटाबेस इंजन पर नहीं।
एक shard डेटा का एक उपसमूह होता है, आमतौर पर अपनी सर्वर/क्लस्टर पर स्टोर। हर शार्ड में आम तौर पर होता है:
एप्लिकेशन के नज़रिए से शार्ड्ड सेटअप अक्सर एक लॉजिकल डेटाबेस जैसा दिखना चाहती है। पर अंदर, एक इंडेक्स लुकअप जो सिंगल-नोड डेटाबेस में "एक" था, अब "सही शार्ड ढूँढो, फिर लुकअप करो" बन सकता है।
एक router (कभी-कभी coordinator, query router, या proxy कहा जाता है) ट्रैफिक कॉप होता है। यह व्यावहारिक सवाल का जवाब देता है: दी गई रिक्वेस्ट के लिए, कौन सा शार्ड इसे हैंडल करेगा?
दो आम पैटर्न हैं:
राउटर्स ऐप की जटिलता कम करते हैं, पर वे भी बैटलनेकल या नया फेल्योर पॉइंट बन सकते हैं अगर सतर्कता से डिज़ाइन न किए जाएँ।
Shardिंग metadata पर निर्भर करती है—एक source-of-truth जो बताती है:
यह जानकारी अक्सर एक config सर्विस (या छोटे "control plane" डेटाबेस) में रहती है। अगर metadata stale या inconsistent है, तो राउटर्स गलत जगह ट्रैफ़िक भेज सकते हैं—भले ही हर शार्ड बिल्कुल हेल्दी हो।
अंत में, शार्डिंग उन बैकग्राउंड प्रक्रियाओं पर निर्भर करती है जो सिस्टम को समय के साथ ज़िंदा रखती हैं:
ये जॉब्स शुरू में नज़रअंदाज़ करने में आसान होते हैं, पर वे कई प्रोडक्शन सरप्राइज़ का स्रोत बनते हैं—क्योंकि वे सिस्टम के आकार को तब बदलते हैं जबकि यह ट्रैफ़िक सर्व कर रहा होता है।
एक shard key वह फ़ील्ड (या फ़ील्ड का संयोजन) है जिसका सिस्टम उपयोग करता है यह तय करने के लिए कि एक रो/डॉक्यूमेंट किस शार्ड में रहेगा। यह एकल चुनाव चुपचाप प्रदर्शन, लागत, और यहाँ तक कि बाद की सुविधाओं को भी निर्धारित कर देता है—क्योंकि यह नियंत्रित करता है कि रिक्वेस्ट एक शार्ड पर राउट हो पाएँगी या कई पर फैला दी जाएँगी।
एक अच्छा key सामान्यतः:
user_id बनाम country)एक सामान्य उदाहरण है multi-tenant ऐप में tenant_id से शार्डिंग: अधिकतर पढ़ाई और लिखाई एक ही टेनेंट के लिए एक ही शार्ड पर रहती है, और टेनेंट पर्याप्त संख्या में होते हैं ताकि लोड फैल सके।
कुछ keys लगभग निश्चित रूप से दर्द देती हैं:
भले ही low-cardinality key फ़िल्टरिंग के लिए सुविधाजनक लगे, यह अक्सर नियमित क्वेरीज को scatter-gather बना देता है क्योंकि मैच करने वाली रोज़ हर जगह होंगी।
लोड बैलेंसिंग के लिए सबसे अच्छा shard key हमेशा प्रोडक्ट क्वेरीज के लिए सबसे अच्छा नहीं होता।
user_id) के अनुरूप हो, और कुछ "ग्लोबल" क्वेरीज (उदा., एडमिन रिपोर्टिंग) धीमी हो जाएँगी या अलग पाइपलाइन्स की ज़रूरत पड़ेगी।region) चुनें, और आप हॉटस्पॉट्स व असमान क्षमता का जोखिम उठाते हैं।अधिकतर टीमें इस ट्रेड-ऑफ़ के हिसाब से डिज़ाइन करती हैं: shard key को सबसे आम, latency-संवेदनशील ऑपरेशन्स के लिए ऑप्टिमाइज़ करें—बाकी काम इंडेक्स, डिनॉर्मलाइज़ेशन, रिप्लिका, या समर्पित एनालिटिक्स टेबल्स से संभालें।
एक "सर्वश्रेष्ठ" तरीका नहीं है। जो रणनीति आप चुनते हैं वह प्रभावित करती है कि क्वेरी राउट करना कितना आसान है, डेटा कितना समान रूप से फैलता है, और किस तरह के एक्सेस पैटर्न हर्ट करेंगे।
Range sharding में हर शार्ड किसी key space का लगातार हिस्सा रखता है—उदा.:
राउटिंग सरल है: key देखें, शार्ड चुनें।
कठिनाई हॉटस्पॉट्स है। अगर नए यूज़र्स हमेशा बढ़ते IDs पाते हैं, तो "अंतिम" शार्ड write बोतलनैक बन जाएगा। Range sharding असमान वृद्धि के प्रति संवेदनशील है। फायदा: range क्वेरीज ("Oct 1–Oct 31 के सभी ऑर्डर") प्रभावी हो सकती हैं क्योंकि डेटा भौतिक रूप से समूहित होता है।
Hash sharding में shard key को एक हैश फंक्शन में डाला जाता है और परिणाम से शार्ड चुना जाता है। यह सामान्यतः डेटा को अधिक समान रूप से फैलाता है, जिससे "हर चीज़ नव शार्ड पर जा रही है" की समस्या से बचा जा सकता है।
ट्रेड-ऑफ़: range क्वेरीज मुश्किल हो जाती हैं। "IDs X से Y के बीच वाले ग्राहक" अब छोटे सेट की शार्ड्स में नहीं आ सकते; कई शार्ड्स को छूना पड़ सकता है।
एक व्यावहारिक डिटेल जो टीमें अक्सर कम आंका करती हैं, वह है consistent hashing. सीधे shard count पर मैप करने के बजाय (जो नए शार्ड जोड़ने पर सब कुछ शिफ्ट कर देता है), कई सिस्टम hash ring और "वर्चुअल नोड्स" का उपयोग करते हैं ताकि कैपेसिटी जोड़ने पर केवल कुछ कीज़ ही मूव हों।
Directory sharding एक स्पष्ट मैप (lookup table/service) रखता है key → shard location के लिए। यह सबसे लचीला है: आप किसी विशेष टेनेंट को समर्पित शार्ड पर रख सकते हैं, एक ग्राहक को बिना सबको मूव किए शिफ्ट कर सकते हैं, और असमान शार्ड साइज का समर्थन कर सकते हैं।
नुकसान अतिरिक्त निर्भरता है। अगर डायरेक्टरी स्लो, stale, या अनुपलब्ध है, तो राउटिंग प्रभावित होगी—भले ही शार्ड्स हेल्दी हों।
वास्तविक सिस्टम अक्सर तरीके मिलाते हैं। एक कॉम्पोज़िट shard key (उदा., tenant_id + user_id) टेनेंट्स को अलग रखता है और एक ही टेनेंट के भीतर लोड फैलाता है। सब-शार्डिंग समान है: पहले टेनेंट के हिसाब से रूट करें, फिर उस टेनेंट के समूह के भीतर hash करें ताकि एक बड़े टेनेंट का एक शार्ड पर वर्चस्व न रहे।
एक शार्डेड डेटाबेस के दो बिल्कुल अलग "क्वेरी पाथ" होते हैं। यह समझना कि आप किस पाथ पर हैं, अधिकतर प्रदर्शन आश्चर्यों और शार्डिंग के अनियमित अनुभवों को समझाता है।
आदर्श परिणाम है कि क्वेरी ठीक एक शार्ड पर राउट हो। अगर रिक्वेस्ट में shard key शामिल है (या कुछ ऐसा जिसे राउटर शार्ड से मैप कर सके), तो सिस्टम सीधे सही जगह भेज सकता है।
इसीलिए टीमें आम पढ़ाइयों को "shard-key aware" बनाने पर जोर देती हैं। एक शार्ड का मतलब कम नेटवर्क होप्स, सरल निष्पादन, कम लॉक, और कम समन्वय। लेटेंसी ज्यादातर डेटाबेस के काम की होती है, क्लस्टर के बीच बहस की नहीं।
जब क्वेरी स्पष्ट रूप से राउट नहीं हो सकती (उदा., यह किसी non-shard-key फ़ील्ड पर फ़िल्टर करती है), सिस्टम इसे कई/सभी शार्ड्स पर प्रसारित कर सकता है। हर शार्ड स्थानीय रूप से क्वेरी चलाता है, फिर राउटर (या एक coordinator) परिणामों को मर्ज करता है—सॉर्ट करना, डुप्लिकेट हटाना, लिमिट लागू करना, और आंशिक एग्रीगेट्स जोड़ना।
यह फैन-आउट टेल लेटेंसी को बढ़ा देता है: भले ही 9 शार्ड्स तेज़ उत्तर दें, एक धीमा शार्ड पूरे अनुरोध को होल्ड कर सकता है। यह लोड को भी गुणा कर देता है: एक यूज़र रिक्वेस्ट N शार्ड रिक्वेस्ट्स बन जाती है।
शार्ड्स के पार जोइन्स महँगे होते हैं क्योंकि जो डेटा पहले "अंदर" मिल जाता था, अब शार्ड्स के बीच या किसी coordinator पर आना चाहिए। यहां तक कि सरल एग्रीगेशन्स (COUNT, SUM, GROUP BY) भी दो-चरण की योजना मांग सकती हैं: हर शार्ड पर आंशिक नतीजे निकालो, फिर उन्हें मर्ज करो।
ज़्यादातर सिस्टम डिफ़ॉल्ट रूप से लोकल इंडेक्स को रखते हैं: हर शार्ड केवल अपना डेटा इंडेक्स करता है। वे बनाए रखने में सस्ते होते हैं, पर वे राउटिंग में मदद नहीं करते—इसलिए क्वेरीज फिर भी scatter हो सकती हैं।
ग्लोबल इंडेक्स गैर-shard-key फ़ील्ड्स पर लक्षित राउटिंग सक्षम कर सकते हैं, पर वे लिखने का ओवरहेड, अतिरिक्त समन्वय, और अपने स्केलिंग/कंसिस्टेंसी सिरदर्द जोड़ते हैं।
लिखना वह जगह है जहाँ शार्डिंग "सिर्फ़ स्केल" जैसा महसूस करना बंद कर देती है और फीचर डिज़ाइन बदलने लगती है। एक लिखाई जो एक शार्ड को छूती है वह तेज़ और सरल हो सकती है। एक लिखाई जो कई शार्ड्स को छूती है वह धीमी, फेल-प्रोन, और सही बनाना आश्चर्यजनक रूप से कठिन हो सकता है।
अगर हर रिक्वेस्ट को ठीक एक शार्ड पर राउट किया जा सके (आमतौर पर shard key के जरिए), तो डेटाबेस अपनी सामान्य ट्रांज़ैक्शन मशीनरी का उपयोग कर सकता है। आप उस शार्ड के भीतर एटोमिकिटी और आइसोलेशन पाते हैं, और अधिकांश ऑपरेशनल समस्याएँ परिचित सिंगल-नोड समस्याओं जैसी दिखती हैं—बस N बार।
जैसे ही आपको दो शार्ड्स पर एक ही "लॉजिकल एक्शन" में डेटा अपडेट करने की ज़रूरत पड़ती है (उदा., पैसे ट्रांसफर करना, एक ऑर्डर को ग्राहक बदलना, कहीं और संग्रहीत एग्रीगेट अपडेट करना), आप वितरित ट्रांज़ैक्शन क्षेत्र में आ जाते हैं।
डिस्ट्रिब्यूटेड ट्रांज़ैक्शन्स कठिन हैं क्योंकि उन्हें उन मशीनों के बीच समन्वय की ज़रूरत होती है जो धीमी हो सकती हैं, पार्टिशन हो सकती हैं, या कभी भी रिस्टार्ट हो सकती हैं। two-phase commit–style प्रोटोकॉल अतिरिक्त राउंड ट्रिप्स जोड़ते हैं, timeouts पर ब्लॉक कर सकते हैं, और फेल्योर को अस्पष्ट बना देते हैं: क्या शार्ड B ने परिवर्तन apply किया था जब coordinator मर गया? क्लाइंट फिर retry करे तो क्या डबल-apply होगा? अगर आप retry नहीं करते तो क्या आप उसे खो देंगे?
कुछ आम तरकीबें यह घटाती हैं कि कितनी बार आपको मल्टी-शार्ड ट्रांज़ैक्शन की ज़रूरत पड़ती है:
Shardेड सिस्टम्स में retries अनिवार्य हैं—इन्हें अनदेखा नहीं किया जा सकता। लिखाइयों को idempotent बनाइए स्थिर ऑपरेशन IDs (उदा., idempotency key) का उपयोग करके और डेटाबेस में "पहले से लागू" मार्कर स्टोर करके। इस तरह, अगर timeout हो और क्लाइंट retry करे, तो दूसरा प्रयास no-op बन जाएगा न कि डबल चार्ज, डुप्लिकेट ऑर्डर, या inconsistent काउंटर।
Shardिंग आपके डेटा को मशीनों में बाँटती है, पर यह redundancy की ज़रूरत को हटाती नहीं है। रिप्लिकेशन वह है जो किसी शार्ड को उपलब्ध रखता है जब कोई नोड मर जाए—और यही यह भी कठिन बनाती है कि "अभी क्या सही है?" का जवाब देना।
अधिकांश सिस्टम हर शार्ड के भीतर रिप्लिकेट करते हैं: एक प्राइमरी (लीडर) नोड writes स्वीकार करता है, और एक या अधिक रिप्लिका उन बदलाओं की नकल करते हैं। अगर प्राइमरी फेल हो तो सिस्टम एक रिप्लिका को प्रमोट करता है (failover)। रिप्लिका पढ़ने में भी मदद कर सकती हैं ताकि लोड कम हो।
ट्रेड-ऑफ़ समय है। एक read replica कुछ मिलीसेकंड—या सेकंड—पीछे हो सकती है। वह गैप सामान्य है, पर जब यूज़र उम्मीद करे कि "मैंने अभी अपडेट किया, इसलिए मुझे दिखना चाहिए", तब यह मायने रखता है।
Shardेड सेटअप्स में आप अक्सर पाते हैं कि एक शार्ड के भीतर मजबूत कंसिस्टेंसी और शार्ड्स के पार कमजोर गारंटियाँ होती हैं, खासकर जब मल्टी-शार्ड ऑपरेशन्स शामिल हों।
Shardिंग में "सिंगल सोर्स ऑफ़ ट्रुथ" आमतौर पर मतलब होता है: किसी दिए हुए डेटा पीस के लिए लिखने की एक अधिकृत जगह होती है (आमतौर पर शार्ड का लीडर)। पर वैश्विक स्तर पर, ऐसी कोई मशीन नहीं है जो तुरंत हर चीज़ की ताज़ा स्थिति की पुष्टि कर सके। आपके पास कई स्थानीय ट्रुथ्स होते हैं जिन्हें रिप्लिकेशन के ज़रिए सिंक में रखा जाना चाहिए।
जब जाँच करने वाला डेटा अलग शार्ड्स पर होता है तब constraints मुश्किल हो जाते हैं:
ये चुनाव केवल इम्प्लीमेंटेशन विवरण नहीं हैं—ये परिभाषित करते हैं कि आपके प्रोडक्ट के लिए "सही" का क्या अर्थ है।
रीबैलेंसिंग वह है जो शार्डेड डेटाबेस को उपयोगी बनाये रखता है जैसे-जैसे वास्तविकता बदलती है। डेटा असमान रूप से बढ़ता है, एक "संतुलित" shard key स्क्यू में चल सकता है, आप नई नोड्स जोड़ते हैं, या किसी हार्डवेयर को रिटायर करना होता है। इन में से कोई भी एक शार्ड को बोतलनैक बना सकता है—भले ही मूल डिज़ाइन परफेक्ट दिखता हो।
एक सिंगल डेटाबेस के विपरीत, शार्डिंग राउटिंग लॉजिक में डेटा का लोकेशन बेक कर देता है। जब आप डेटा मूव करते हैं, तो आप सिर्फ़ बाइट्स नकल नहीं कर रहे—आप यह बदल रहे हैं कि क्वेरीज को कहाँ भेजना है। इसका मतलब है कि रीबैलेंसिंग उतनी ही metadata और क्लाइंट्स के बारे में है जितनी स्टोरेज के बारे में।
अधिकांश टीमें स्टॉप-द-वर्ल्ड विंडो से बचने के लिए एक ऑनलाइन वर्कफ़्लो की कोशिश करती हैं:
अगर क्लाइंट्स राउटिंग निर्णय cache करते हैं तो शार्ड मैप परिवर्तन ब्रेकिंग इवेंट हो सकता है। अच्छे सिस्टम राउटिंग मेटाडेटा को कॉन्फ़िगरेशन जैसा मानते हैं: संस्करणित रखें, बार-बार रिफ्रेश करें, और स्पष्ट हों कि जब कोई क्लाइंट मूवेड की को हिट करे तो क्या होगा (redirect, retry, या proxy)।
रीबैलेंसिंग अक्सर अस्थायी प्रदर्शन dips करता है (अतिरिक्त writes, कैश चर्न, बैकग्राउंड कॉपी लोड)। आंशिक मूव्स आम हैं—कुछ रेंजेज़ पहले माइग्रेट होते हैं—इसलिए क्लियर ऑब्ज़र्वेबिलिटी और रोलबैक प्लान चाहिए (उदा., मैप वापस फ्लिप कर देना और dual-writes ड्रेन करना) पहले कटओवर शुरू करने से।
Shardिंग यह मानकर चलती है कि काम फैल जाएगा। चौंकाने वाली बात यह है कि क्लस्टर कागज़ पर "समान" दिख सकता है (हर शार्ड में समान रोज़), पर प्रोडक्शन में बेहद असमान व्यवहार कर सकता है।
हॉटस्पॉट तब होता है जब आपकी keyspace का छोटा सा हिस्सा ज्यादातर ट्रैफ़िक पाता है—सोचिए एक सेलेब्रिटी अकाउंट, एक लोकप्रिय प्रोडक्ट, कोई टेनेंट जो भारी बैच जॉब चला रहा है, या टाइम-आधारित की जहाँ "आज" सभी लिखाइयों को आकर्षित करता है। अगर वे कीज़ एक शार्ड से मैप होती हैं तो वह शार्ड बोतलनैक बन जाएगा भले ही बाकी शार्ड्स खाली हों।
"स्क्यू" एक चीज नहीं है:
वे हमेशा मेल नहीं खाते। कम डेटा वाला शार्ड भी सबसे हॉट हो सकता है अगर वह सबसे अनुरोधित कीज़ का मालिक हो।
स्क्यू पकड़ने के लिए महँगी ट्रेसिंग जरूरी नहीं। पर-शार्ड डैशबोर्ड से शुरू करें:
अगर किसी शार्ड की लेटेंसी उसकी QPS के साथ बढ़ती है जबकि बाकी फ़्लैट हैं, तो आपके पास संभावित हॉटस्पॉट है।
फिक्स अक्सर सादगी के बदले संतुलन लेते हैं:
Shardिंग सिर्फ़ अधिक सर्वर जोड़ना नहीं है—यह अधिक तरीकों को जोड़ देता है जिनमें चीज़ें गलत हो सकती हैं, और उनसे निपटने के अधिक जगहें। कई घटनाएँ "डेटाबेस डाउन है" नहीं होती, बल्कि "एक शार्ड डाउन है" या "सिस्टम यह तय नहीं कर रहा कि डेटा कहाँ रहता है" जैसी होती हैं।
कुछ पैटर्न बार-बार दिखते हैं:
एक सिंगल-नोड डेटाबेस में, आप एक लॉग टेल करते हैं और एक सेट मीट्रिक्स देखते हैं। शार्डेड सिस्टम में, आपको एक रिक्वेस्ट को शार्ड्स के पार फ़ॉलो करने वाली ऑब्ज़र्वेबिलिटी चाहिए।
हर रिक्वेस्ट में correlation IDs का उपयोग करें और उन्हें API लेयर से राउटर तक और हर शार्ड तक propagate करें। इसे distributed tracing के साथ जोड़ें ताकि एक scatter-gather क्वेरी दिखा सके कि कौन सा शार्ड धीमा था या फेल हुआ। मीट्रिक्स को प्रति शार्ड तोड़कर रखें (लेटेंसी, कतार गहराई, error rate), वरना एक हॉट शार्ड फ़्लीट एवरेज में छिप जाएगा।
Shardिंग विफलताएँ अक्सर करेक्टनेस बग के रूप में दिखती हैं:
"डेटाबेस को रिस्टोर कर दें" बन जाता है "कई पार्ट्स को सही क्रम में रिस्टोर करें"। आपको अक्सर पहले metadata रिस्टोर करनी होगी, फिर हर शार्ड, फिर यह सत्यापित करना होगा कि शार्ड सीमाएँ और राउटिंग नियम उस रिस्टोर पॉइंट-इन-टाइम से मेल खाते हैं। DR योजनाओं में अभ्यास शामिल होना चाहिए जो साबित करें कि आप एक संगत क्लस्टर फिर से जोड़ सकते हैं—सिर्फ़ व्यक्तिगत मशीनें नहीं।
Shardिंग को अक्सर "स्केलिंग स्विच" माना जाता है, पर यह स्थायी रूप से सिस्टम जटिलता बढ़ा देता है। अगर आप बिना नोड्स के बीच डेटा बाँटे अपने प्रदर्शन और भरोसेमंदी लक्ष्य पूरे कर सकते हैं, तो सामान्यतः सरल आर्किटेक्चर, आसान डीबगिंग, और कम ऑपरेशनल एज केस मिलेंगे।
Shardिंग से पहले प्रयास करें जो एक लॉजिकल डेटाबेस बरकरार रखे:
एक व्यावहारिक तरीका शार्डिंग के जोखिम कम करने का है कि आप प्लंबिंग (राउटिंग बाउंड्रीज़, idempotency, माइग्रेशन वर्कफ़्लो, और ऑब्ज़र्वेबिलिटी) को प्रोटोटाइप कर लें पहले कि आप प्रोडक्शन डेटाबेस को इसके लिए समर्पित करें।
उदाहरण के लिए, Koder.ai के साथ आप चैट से जल्दी एक छोटा, वास्तविक-सदृश सर्विस स्पिन कर सकते हैं—अक्सर एक React admin UI प्लस Go बैकएंड और PostgreSQL—और shard-key-aware APIs, idempotency keys, और "cutover" बिहेवियर को सेफ़ सैंडबॉक्स में एक्सपेरिमेंट कर सकते हैं। क्योंकि Koder.ai planning mode, snapshots/rollback, और source code export सपोर्ट करता है, आप शार्डिंग-संबंधी डिज़ाइन निर्णयों को इटेरेट कर सकते हैं और फिर तैयार कोड और रनबुक्स को अपने मुख्य स्टैक में ले जा सकते हैं जब आप आश्वस्त हों।
Shardिंग बेहतर फिट तब होती है जब आपका dataset या लिखने की throughput स्पष्ट रूप से सिंगल नोड की सीमाएँ पार कर जाए और आपके क्वेरी पैटर्न अधिकतर shard key द्वारा भरोसेमंदी से राउटेबल हों (कम क्रॉस-शार्ड जोइन्स, न्यूनतम scatter-gather क्वेरीज)।
यह तब खराब फिट है जब आपका प्रोडक्ट बहुत सारी ad-hoc क्वेरीज, बार-बार मल्टी-एंटिटी ट्रांज़ैक्शन्स, वैश्विक यूनिकनेस constraints माँगता है, या जब टीम ऑपरेशनल वर्कलोड (रीबैलेंसिंग, रिसार्डिंग, incident response) संभालने में सक्षम न हो।
पूछें:
चाहे आप शार्डिंग टालें, फिर भी माइग्रेशन पाथ डिज़ाइन करें: उन पहचानकर्ताओं का चुनाव करें जो भविष्य के shard key को रोके नहीं, सिंगल-नोड धारणाओं को हार्डकोड करने से बचें, और यह अभ्यास करें कि आप न्यूनतम डाउनटाइम में डेटा कैसे मूव करेंगे। सबसे अच्छा समय रिसार्डिंग की योजना बनाने का उस वक्त है जब आपको इसकी ज़रूरत न हो।
Shardिंग (horizontal partitioning) एक ही लॉजिकल डेटासेट को कई मशीनों ("shards") में बाँट देता है, जहाँ हर शार्ड अलग--अलग रेकॉर्ड रखता है.
Replication के विपरीत, replication अलग-अलग नोड्स पर एक ही डेटा की प्रतिलिपियाँ बनाता है—ज्यादातर उपलब्धता और पढ़ने के स्केल के लिए।
Vertical scaling यानी एक ही डेटाबेस सर्वर को बेहतर CPU/RAM/डिस्क देना ऑपरेशन के लिहाज से सरल है, लेकिन सीमा और लागत जल्दी पहुँच सकती है.
Shardिंग में आउट-बाय-ऐड मशीनें जोड़कर स्केल किया जाता है; यह राउटिंग, रीबैलेंसिंग और क्रॉस-शार्ड सहीपन की चुनौतियाँ भी लाता है।
टीम तब शार्ड करती हैं जब एक नोड लगातार बोतलनैक बन जाता है, जैसे:
Shardिंग डेटा और ट्रैफ़िक फैलाकर क्षमता बढ़ाती है ताकि नयी मशीनें जोड़कर स्केल किया जा सके।
एक सामान्य शार्डेड सिस्टम में शामिल हैं:
प्रदर्शन और करेक्टनेस इन टुकड़ों की संगति पर निर्भर करते हैं।
Shard कीज़ वे फ़ील्ड(स) होते हैं जिनसे सिस्टम तय करता है कि एक रो किस शार्ड में रखी जाएगी। यह बड़े पैमाने पर निर्धारित करता है कि रिक्वेस्ट एक शार्ड पर जाएगी (तेज़) या कई पर (धीरा)।
अच्छी shard कीज़ आम तौर पर high cardinality, even distribution, और आपके आम एक्सेस पैटर्न से मेल खाती हैं (उदा., tenant_id या user_id).
आम “खराब” shard कीज़ में शामिल हैं:
ये अक्सर हॉटस्पॉट बनाते हैं या साधारण क्वेरीज को scatter-gather में बदल देते हैं।
प्रमुख रणनीतियाँ:
अगर क्वेरी shard key (या कुछ जो उसे मैप करता हो) शामिल करती है तो राउटर उसे एक शार्ड पर भेज सकता है—यह तेज़ पाथ है.
अगर सटीक राउटिंग संभव नहीं है, तो सिस्टम कई/सभी शार्ड्स पर क्वेरी भेज सकता है (scatter-gather). ऐसे में एक धीमा शार्ड पूरी रिक्वेस्ट की लेटेंसी बढ़ा देता है और हर यूज़र रिक्वेस्ट N शार्ड रिक्वेस्ट्स में बदल जाती है।
Single-shard writes सामान्य ट्रांज़ैक्शन मशीनरी का उपयोग कर सकती हैं और अपेक्षाकृत सरल रहती हैं.
Cross-shard writes distributed coordination की ज़रूरत होती है (अक्सर two-phase commit जैसी प्रक्रियाएँ), जो लेटेंसी बढ़ाती हैं और फेलियर की अस्पष्टता लाती हैं।
राहत के कुछ पैटर्न:
Shardिंग जटिलता और ऑपरेशनल बोझ बढ़ा देती है। पहले ये विकल्प आज़माएँ:
Shardिंग तब उपयुक्त है जब सिंगल-नोड सीमाएँ स्पष्ट हों और क्रिटिकल क्वेरीज का बड़ा हिस्सा shard-key के जरिए राउटेबल हो।