14 सित॰ 2025·8 मिनट
डेटा गुणवत्ता चेक्स और अलर्ट्स के लिए वेब ऐप कैसे बनाएं
सीखें कि कैसे एक वेब ऐप प्लान और बनाएँ जो डेटा गुणवत्ता चेक चलाए, परिणाम ट्रैक करे, और स्पष्ट स्वामित्व, लॉग और डैशबोर्ड के साथ समय पर अलर्ट भेजे।
सीखें कि कैसे एक वेब ऐप प्लान और बनाएँ जो डेटा गुणवत्ता चेक चलाए, परिणाम ट्रैक करे, और स्पष्ट स्वामित्व, लॉग और डैशबोर्ड के साथ समय पर अलर्ट भेजे।
किसी भी चीज़ को बनाने से पहले यह तय करें कि आपकी टीम वास्तव में “डेटा गुणवत्ता” से क्या मतलब रखती है। एक वेब ऐप जो डेटा गुणवत्ता निगरानी करता है तभी उपयोगी है जब सभी लोग उस परिणाम और उन निर्णयों पर सहमत हों जिन्हें यह सुरक्षित रखना चाहिए।
अधिकांश टीमें कई आयामों को मिलाकर चलती हैं। उन आयामों में से जिनकी परवाह है उन्हें चुनें, साधारण भाषा में परिभाषित करें, और उन परिभाषाओं को प्रोडक्ट आवश्यकताओं की तरह मानें:
ये परिभाषाएँ आपके डेटा वैलिडेशन नियमों की नींव बनेंगी और तय करने में मदद करेंगी कि आपकी ऐप को किन डेटा गुणवत्ता चेक्स का समर्थन करना चाहिए।
खराब डेटा के जोखिमों और जिन पर असर पड़ता है उनकी सूची बनाएं। उदाहरण:
यह आपको उस टूल से बचाएगा जो “दिलचस्प” मीट्रिक ट्रैक करे पर असल में व्यापार को चोट पहुंचाने वाली चीज़ों को छूट दे। यह वेब ऐप अलर्ट्स को भी आकार देता है: सही संदेश सही मालिक तक पहुंचे।
यह स्पष्ट करें कि आपको चाहिए:
लेटेंसी अपेक्षाओं (मिनट बनाम घंटे) के बारे में स्पष्ट रहें। यह शेड्यूलिंग, स्टोरेज और अलर्ट की तत्परता को प्रभावित करता है।
यह तय करें कि ऐप लाइव होने पर आप “बेहतर” कैसे नापेंगे:
ये मीट्रिक्स आपकी डेटा ऑब्ज़र्वेबिलिटी को केंद्रित रखेंगी और प्रतीकात्मक रूप से यह बताने में मदद करेंगी कि सादा नियम-आधारित वैलिडेशन और एनॉमली डिटेक्शन बेसिक्स में क्या प्राथमिकता है।
चेक्स बनाने से पहले यह स्पष्ट करें कि आपके पास कौन सा डेटा है, वह कहाँ रहता है, और टूटने पर उसे कौन ठीक कर सकता है। एक हल्का इन्वेंटरी अब कई सप्ताह की उलझन बचा सकता है।
हर जगह सूचीबद्ध करें जहाँ डेटा उत्पन्न होता या बदला जाता है:
प्रत्येक स्रोत के लिए एक मालिक (व्यक्ति या टीम), Slack/email संपर्क, और अपेक्षित रिफ्रेश कैडेंस कैप्चर करें। यदि स्वामित्व स्पष्ट नहीं है, तो अलर्टिंग भी अस्पष्ट होगी।
क्रिटिकल टेबल/फ़ील्ड चुनें और दस्तावेज़ करें कि उन पर क्या निर्भर करता है:
एक साधारण dependency नोट जैसे “orders.status → revenue dashboard” पर्याप्त है।
इम्पैक्ट और संभावना के आधार पर प्राथमिकता दें:
ये आपकी प्रारंभिक मॉनीटरिंग स्कोप और पहले सफलता मीट्रिक्स बनेंगे।
वे स्पेसिफिक विफलताएँ दस्तावेज़ करें जो आपने पहले महसूस की हों: साइलेंट पाइपलाइन फेलियर, धीमी पहचान, अलर्ट में संदर्भ की कमी, और अस्पष्ट स्वामित्व। इन्हें जांच/अलर्ट रूटिंग/ऑडिट लॉग / जांच व्यू जैसी कॉन्क्रीट आवश्यकताओं में बदलें। यदि आप एक छोटा आंतरिक पेज रखते हैं (उदा., /docs/data-owners), तो उसे ऐप से लिंक करें ताकि रिसपॉन्डर तेज़ी से कार्रवाई कर सकें।
स्क्रीन डिजाइन करने या कोड लिखने से पहले तय करें कि आपका प्रोडक्ट कौन से चेक्स चलाएगा। यह चयन बाकी सब कुछ आकार देता है: रूल एडिटर, शेड्यूलिंग, प्रदर्शन, और आपके अलर्ट कितने actionable होंगे।
अधिकांश टीमों को तुरंत एक कोर सेट से मूल्य मिलता है:
email में 2% से ज्यादा null न हों।”order_total 0 से 10,000 के बीच होना चाहिए।”order.customer_id customers.id में मौजूद होना चाहिए।”user_id प्रति दिन अनूठा हो।”प्रारंभिक कैटलॉग को राय-आधारित रखें। बाद में निचे के चेक्स जोड़ सकते हैं बिना UI को जटिल बनाए।
आम तौर पर तीन विकल्प होते हैं:
व्यवहारिक तरीका है “UI पहले, एस्केप हैच दूसरे”: 80% मामलों के लिए टेम्पलेट और UI रूल दें, और बाकी के लिए कस्टम SQL की अनुमति दें।
गंभीरता को अर्थपूर्ण और सुसंगत बनाएं:
ट्रिगर्स के बारे में स्पष्ट रहें: सिंगल-रन फेलियर बनाम “N रन बार विफल”, प्रतिशत-आधारित थ्रेशोल्ड, और वैकल्पिक सप्रेशन विंडो।
यदि आप SQL/स्क्रिप्ट सपोर्ट करते हैं, पहले तय करें: अनुमत कनेक्शन्स, टाइमआउट, रीड-ओनली एक्सेस, पैरामीट्राइज़्ड क्वेरीज़, और कैसे परिणाम पास/फेल + मीट्रिक्स में सामान्यीकृत होंगे। यह लचीलापन रखता है पर आपके डेटा और प्लेटफ़ॉर्म की सुरक्षा भी सुनिश्चित करता है।
एक डेटा गुणवत्ता ऐप इस बात पर सफल या विफल होता है कि कोई कितनी जल्दी तीन सवालों का जवाब दे सके: क्या फेल हुआ, क्यों यह मायने रखता है, और कौन जिम्मेदार है। अगर उपयोगकर्ताओं को लॉग खोजने या cryptic रूल नाम समझने पड़ें तो वे अलर्ट्स को अनदेखा कर देंगे और टूल पर भरोसा खो देंगे।
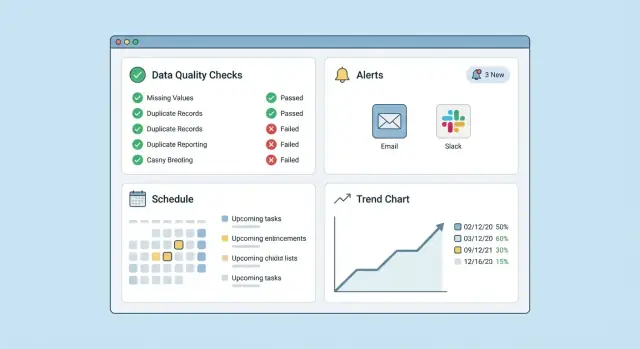
एंड-टू-एंड लाइफसायकल को सपोर्ट करने वाले कुछ ही स्क्रीन से शुरू करें:
मुख्य फ्लो स्पष्ट और दोहराने योग्य होना चाहिए:
create check → schedule/run → view result → investigate → resolve → learn.
“Investigate” को प्राथमिक कार्रवाई बनाएं। एक फेल रन से उपयोगकर्ता को dataset, फेलिंग मीट्रिक/मान देखना चाहिए, पिछले रन से तुलना करनी चाहिए, और कारण पर नोट्स कैप्चर करने चाहिए। “Learn” वह जगह है जहाँ आप सुधार प्रोत्साहित करें: थ्रेशोल्ड समायोजित करने का सुझाव दें, एक साथी चेक जोड़ने का सुझाव दें, या विफलता को किसी ज्ञात घटना से लिंक करें।
शुरू में रोल्स को न्यूनतम रखें:
हर फेल्ड रिजल्ट पेज पर यह दिखे:
एक डेटा गुणवत्ता ऐप को स्केल करना (और डिबग करना) आसान तब होता है जब आप चार चिंताओं को अलग रखें: यूज़र जो देखते हैं (UI), जो चीज़ें बदलते हैं (API), जो चेक्स चलाते हैं (workers), और जहाँ तथ्य संग्रहीत होते हैं (storage)। यह "कंट्रोल प्लेन" (कॉन्फिग और निर्णय) को "डेटा प्लेन" (चेक्स का निष्पादन और परिणाम रिकॉर्ड करना) से अलग रखता है।
"क्या टूट रहा है और किसका मालिक कौन है?" का जवाब देने वाला एक स्क्रीन से शुरू करें। एक सरल डैशबोर्ड और फ़िल्टर बहुत मदद करते हैं:
प्रत्येक रो से उपयोगकर्ता को रन विवरण पेज पर ड्रिल कर सकना चाहिए: चेक परिभाषा, उदाहरण विफलताएँ, और आखिरी ज्ञात सही रन।
API को उन ऑब्जेक्ट्स के आसपास डिज़ाइन करें जिन्हें आपकी ऐप प्रबंधित करती है:
Writes को छोटा और सत्यापित रखें; IDs और timestamps लौटाएँ ताकि UI पोल कर के रिस्पॉन्सिव रहे।
चेक्स को वेब सर्वर के बाहर चलना चाहिए। शेड्यूलर जॉब्स enqueue करे (cron जैसा) और UI से ऑन-डिमांड ट्रिगर होना चाहिए। वर्कर्स तब:
यह डिज़ाइन आपको प्रति dataset concurrency लिमिट्स और सुरक्षित retries जोड़ने देता है।
अलग स्टोरेज का उपयोग करें:
यह विभाजन dashboards को तेज़ बनाए रखता है जबकि विफलता के समय विस्तृत सुबूत भी सुरक्षित रखता है।
अगर आप MVP जल्दी भेजना चाहते हैं तो Koder.ai जैसी वाइब-कोडिंग प्लेटफ़ॉर्म React डैशबोर्ड, Go API, और PostgreSQL स्कीमा को लिखे हुए स्पेक्ट से बूटस्ट्रैप करने में मदद कर सकती है। यह कोर CRUD फ्लो और स्क्रीन जल्दी रखने में उपयोगी है; बाद में आप चेक इंजन और इंटीग्रेशन पर इटेरेट कर सकते हैं। Koder.ai सोर्स कोड एक्सपोर्ट का समर्थन करता है, इसलिए आप बने हुए सिस्टम को अपने रिपो में हॉर्न कर सकते हैं।
एक अच्छा डेटा गुणवत्ता ऐप सरफेस पर सरल लगता है क्योंकि अंदर का डेटा मॉडल अनुशासित होता है। आपका लक्ष्य हर परिणाम को समझाने योग्य बनाना है: क्या चला, किस dataset पर, किन पैरामीटर के साथ, और समय के साथ क्या बदला।
छोटे सेट के फ़र्स्ट-क्लास ऑब्जेक्ट्स से शुरू करें:
जांच के लिए raw result details (सैंपल फेल होने वाली पंक्तियाँ, offending कॉलम, क्वेरी आउटपुट स्निपेट) रखें, पर साथ ही summary metrics भी रखें जो डैशबोर्ड और ट्रेंड के लिए ऑप्टिमाइज़्ड हों। यह विभाजन चार्ट्स को तेज़ रखता है बिना डिबग संदर्भ खोए।
कभी भी CheckRun overwrite न करें। एप्पेंड-ओनली इतिहास ऑडिट के लिए आवश्यक है (“मंगलवार को हमें क्या पता था?”) और डिबग के लिए उपयोगी है (“क्या नियम बदला या डेटा बदला?”)। हर रन के साथ चेक वर्शन/कॉन्फिग हैश रिकॉर्ड करें।
Datasets और Checks पर team, domain, और PII flag जैसे टैग जोड़ें। टैग्स डैशबोर्ड फिल्टर और अनुमतियों को सपोर्ट करते हैं (उदाहरण: केवल कुछ रोल्स PII-टैग्ड dataset के raw samples देख सकें)।
निष्पादन इंजन आपकी डेटा गुणवत्ता मॉनिटरिंग ऐप का "रनटाइम" है: यह तय करता है कब चेक चलेगा, कैसे सुरक्षित रूप से चलेगा, और क्या रिकॉर्ड किया जाएगा ताकि परिणाम विश्वसनीय और दोहराये जाने योग्य हों।
एक शेड्यूलर से शुरू करें जो कैडेंस पर चेक रन ट्रिगर करे (cron-जैसा)। शेड्यूलर को भारी काम नहीं करना चाहिए—यह जॉब enqueue करने का काम करे।
एक क्यू (DB या मैसेज ब्रोक़र द्वारा बैक्ड) आपको देता है:
चेक्स अक्सर प्रोडक्शन DBs या वेयरहाउस पर क्वेरी चलाते हैं। गार्डरेल्स लगाएँ ताकि गलत कॉन्फ़िग चेक प्रदर्शन को प्रभावित न करे:
वर्कर्स को “in-progress” स्टेट्स कैप्चर करने दें और क्रैश के बाद छोड़े गए जॉब्स को सुरक्षित रूप से उठाया जा सके।
एक पास/फेल बिना संदर्भ के भरोसेमंद नहीं होता। हर परिणाम के साथ रन संदर्भ स्टोर करें:
यह आपको हफ्तों बाद भी जवाब देने में सक्षम बनाता है: "ठीक उसी समय क्या चला था?"
एक चेक सक्रिय करने से पहले ऑफर करें:
ये फीचर सरप्राइज़ को कम करते हैं और दिन एक अलर्टिंग की विश्वसनीयता बनाए रखते हैं।
अलर्टिंग वह जगह है जहाँ डेटा गुणवत्ता मॉनिटरिंग या तो विश्वास जीतती है या अनदेखी हो जाती है। लक्ष्य सब कुछ बताना नहीं है—बल्कि यह बताना है कि अगला क्या करें और यह कितना गंभीर है। हर अलर्ट तीन सवालों का जवाब दे: क्या टूटा, कितना बुरा है, और कौन जिम्मेदार है।
विभिन्न चेक्स को विभिन्न ट्रिगर की ज़रूरत होती है। कुछ व्यावहारिक पैटर्न सपोर्ट करें जो अधिकांश टीमों को कवर करें:
इन कंडीशन्स को प्रति चेक कॉन्फ़िग्योर करने योग्य बनाएं और प्रीव्यू दिखाएँ (“यह पिछले महीने 5 बार ट्रिगर करता”) ताकि उपयोगकर्ता संवेदनशीलता समायोजित कर सकें।
एक ही इन्सिडेंट के लिए बार-बार अलर्ट भेजना लोगों को नोटिफिकेशन म्यूट करने की प्रवृत्ति सिखाता है। जोड़ें:
स्टेट ट्रांज़िशन्स को भी ट्रैक करें: नए फेलियर्स पर अलर्ट करें, और वैकल्पिक रूप से रिकवरी पर सूचित करें।
रूटिंग डेटा-ड्रिवन रखनी चाहिए: dataset owner, team, severity, या tags (उदा., finance, customer-facing) के आधार पर। यह रूटिंग लॉजिक कॉड में नहीं बल्कि कॉन्फ़िगरेशन में होना चाहिए।
ईमेल और Slack ज्यादातर वर्कफ़्लोज़ कवर करते हैं और अपनाने में आसान हैं। अलर्ट payload को इस तरह डिजाइन करें कि भविष्य में webhook जोड़ना सहज हो। डीप त्रियाज के लिए सीधे investigation view का लिंक दें (उदा: /checks/{id}/runs/{runId})।
डैशबोर्ड वह जगह है जहाँ डेटा गुणवत्ता मॉनिटरिंग उपयोगी बनती है। लक्ष्य सुंदर चार्ट नहीं है—बल्कि किसी को दो सवालों का जल्दी उत्तर देना है: “क्या कुछ टूट रहा है?” और “अगला कदम क्या है?”
एक कॉम्पैक्ट “हेल्थ” व्यू से शुरू करें जो तेज़ी से लोड हो और क्या ध्यान देना है हाइलाइट करे।
दिखाएँ:
यह पहली स्क्रीन एक ऑपरेशंस कंसोल जैसा महसूस होना चाहिए: स्पष्ट स्थिति, न्यूनतम क्लिक, और सभी डेटा गुणवत्ता चेक्स में संगत लेबल।
किसी भी फेल्ड चेक से, एक डिटेल व्यू दें जो जांच को ऐप से निकलने के बिना संभाले।
शामिल करें:
यदि संभव हो तो एक-क्लिक “Open investigation” पैनल जोड़ें जिसमें runbook और क्वेरियों के लिंक हों (relative ही), उदा. /runbooks/customer-freshness और /queries/customer_freshness_debug.
विफलताएँ स्पष्ट होती हैं; धीमी деградация नहीं। प्रत्येक dataset/चेक के लिए एक ट्रेंड्स टैब जोड़ें:
ये ग्राफ्स एनॉमली डिटेक्शन बेसिक्स को व्यावहारिक बनाते हैं: लोग देख सकेंगे कि यह एक सिंगल-ऑफ़ था या पैटर्न।
हर चार्ट और तालिका को underlying run history और ऑडिट लॉग से लिंक करें। प्रत्येक पॉइंट के लिए “View run” लिंक दें ताकि टीमें इनपुट, थ्रेशोल्ड, और अलर्ट रूटिंग निर्णयों की तुलना कर सकें। यह ट्रेसबिलिटी डैशबोर्ड में भरोसा बनाती है और डेटा ऑब्ज़र्वेबिलिटी व ETL डेटा गुणवत्ता वर्कफ़्लोज़ के लिए उपयोगी बनाती है।
शुरुआती सुरक्षा निर्णय आपकी ऐप को सरल या जोखिमपूर्ण बना देंगे। एक डेटा गुणवत्ता टूल प्रोडक्शन सिस्टम्स, क्रेडेंशियल्स, और कभी-कभी रेगुलेटेड डेटा को छूता है, इसलिए इसे शुरुआत से एक आंतरिक एडमिन प्रोडक्ट की तरह ट्रीट करें।
यदि आपकी संस्था पहले से SSO उपयोग करती है तो OAuth/SAML सपोर्ट जल्द से जल्द जोड़ें। तब तक ईमेल/पासवर्ड MVP के लिए मान्य हो सकता है, पर बेसिक्स के साथ: सॉल्टेड पासवर्ड हैशिंग, रेट लिमिटिंग, अकाउंट लॉकआउट, और MFA सपोर्ट।
SSO के साथ भी एक इमरजेंसी “break-glass” admin अकाउंट सुरक्षित रूप से रखें। प्रक्रिया दस्तावेज़ करें और उपयोग सीमित रखें।
“रिज़ल्ट्स देखना” और “बिहेवियर बदलना” अलग रखें। सामान्य रोल्स:
अनुमतियाँ API पर लागू करें, सिर्फ UI पर नहीं। वर्कस्पेस/प्रोजेक्ट स्कोपिंग भी विचार करें ताकि एक टीम अनजाने में दूसरे की चेक्स न बदल सके।
कच्चे रो सैम्पल्स जो PII रख सकते हैं स्टोर करने से बचें। इसके बजाय aggregates और सारांश स्टोर करें (काउंट, null rates, min/max, histogram buckets, failing row count)। अगर डिबग के लिए सैम्पल्स आवश्यक हों तो उन्हें स्पष्ट opt-in, कम रिटेंशन, मास्किंग/रेडैक्शन, और कठिन एक्सेस कंट्रोल के साथ रखें।
लॉगिन इवेंट, चेक एडिट, अलर्ट-रूट परिवर्तन, और सीक्रेट अपडेट्स के लिए ऑडिट लॉग रखो। ऑडिट ट्रेल बदलावों के समय अनुमान कम करती है और अनुपालन में मदद करती है।
डेटाबेस क्रेडेंशियल्स और API कुंजी कभी plaintext में DB में न रखें। वॉल्ट या एन्वाइरनमेंट-आधारित सीक्रेट इंजेक्शन का उपयोग करें, और रोटेशन के लिए डिजाइन करें (कई सक्रिय वर्शन, last-rotated timestamps, और टेस्ट-कनेक्शन फ्लो)। सीक्रेट दृश्यता को केवल एडमिन तक सीमित रखें, और एक्सेस लॉग करें पर सीक्रेट वैल्यू लॉग न करें।
अपने ऐप को डेटा समस्याएं पकड़ने के भरोसे लायक बनाने से पहले यह साबित करें कि यह भरोसेमंद तरीके से फेलियर्स पता कर सकता है, फॉल्स अलार्म से बच सकता है, और क्लीनली रिकवर कर सकता है। टेस्टिंग को एक प्रोडक्ट फीचर मानें: यह उपयोगकर्ताओं को शोर से बचाता है और आपको साइलेंट गैप्स से बचाता है।
आप जिन भी चेक्स का समर्थन करते हैं (freshness, row count, schema, null rates, custom SQL, आदि) उनके लिए सैंपल datasets और golden test cases बनाएं: एक जो पास होना चाहिए और कई जो विशिष्ट तरीकों से फेल होने चाहिए। इन्हें छोटा, वर्शन-कंट्रोल्ड, और दोहराने योग्य रखें।
एक अच्छा गोल्डन टेस्ट यह बताए: अपेक्षित परिणाम क्या है? UI को क्या दिखाना चाहिए? ऑडिट लॉग में क्या लिखा जाना चाहिए?
अलर्टिंग बग्स अक्सर चेक बग्स से अधिक नुकसानदेह होते हैं। थ्रेशोल्ड्स, कूलडाउन, और रूटिंग नियमों के लिए अलर्ट लॉजिक टेस्ट करें:
अपने खुद के सिस्टम के लिए मॉनिटरिंग जोड़ें ताकि आप देख सकें जब मॉनिटर फेल हो रहा हो:
सामान्य विफलताओं को कवर करते हुए स्पष्ट ट्रबलशूटिंग पेज लिखें (प ქस्ट जाम, क्रेडेंशियल्स गायब, शेड्यूलिंग विलंब, सप्रेस्ड अलर्ट) और आंतरिक रूप से लिंक करें, उदा. /docs/troubleshooting. "सबसे पहले क्या जांचें" कदम और लॉग्स, रन IDs, और UI में हालिया इन्सिडेंट कहां मिलते हैं यह बताएं।
एक डेटा गुणवत्ता ऐप भेजना "बड़े लॉन्च" के बारे में कम और छोटे, steady कदमों में भरोसा बनाना अधिक है। आपकी पहली रिलीज़ को एंड-टू-एंड लूप साबित करनी चाहिए: चेक चलाएँ, परिणाम दिखाएँ, अलर्ट भेजें, और किसी वास्तविक मुद्दे को ठीक करने में मदद करें।
एक संकीर्ण, भरोसेमंद क्षमताओं के सेट से शुरू करें:
यह MVP लचीलापन से अधिक स्पष्टता पर फोकस करे। अगर उपयोगकर्ता समझ न पाएं कि चेक क्यों फेल हुआ, तो वे अलर्ट पर कार्रवाई नहीं करेंगे।
यदि आप UX को जल्दी मान्य करना चाहते हैं तो CRUD-भारी हिस्सों (चेक कैटलॉग, रन इतिहास, अलर्ट सेटिंग, RBAC) को Koder.ai में प्रोटोटाइप कर के "planning mode" में इटेरेट कर सकते हैं। आंतरिक टूल्स के लिए snapshot और rollback की सुविधा विशेष रूप से उपयोगी होती है जब आप अलर्ट शोर और अनुमतियाँ समायोजित कर रहे हों।
अपनी मॉनिटरिंग ऐप को प्रोडक्शन इन्फ्रास्ट्रक्चर की तरह ट्रीट करें:
एक सरल “kill switch” किसी एक चेक या पूरे इंटीग्रेशन के लिए शुरुआती अपनाने के दौरान घंटों बचा सकता है।
पहले 30 मिनट को सफल बनाएं। "Daily pipeline freshness" या "Uniqueness for primary keys" जैसे टेम्पलेट और /docs/quickstart पर एक छोटा सेटअप गाइड दें।
साथ ही एक हल्का ownership मॉडल परिभाषित करें: कौन अलर्ट प्राप्त करता है, कौन चेक एडिट कर सकता है, और विफलता के बाद “done” का क्या अर्थ है (उदा., acknowledge → fix → rerun → close)।
एक बार MVP स्थिर हो जाए, वास्तविक इन्सिडेंट्स के आधार पर विस्तार करें:
इटेरेट करें ताकि time-to-diagnosis कम हो और अलर्ट शोर घटे। जब उपयोगकर्ताओं को लगे कि ऐप लगातार उनका समय बचाता है, तो अपनाना स्वाभाविक रूप से बढ़ेगा।
Start by writing down what “data quality” means for your team—typically accuracy, completeness, timeliness, and uniqueness. Then translate each dimension into concrete outcomes (e.g., “orders load by 6am,” “email null rate < 2%”) and pick success metrics like fewer incidents, faster detection, and lower false-alert rates.
Most teams do best with both:
Decide explicit latency expectations (minutes vs hours) because it affects scheduling, storage, and how urgent alerts should be.
Prioritize the first 5–10 must-not-break datasets by:
Also record an owner and expected refresh cadence for each dataset so alerts can route to someone who can act.
A practical starter catalog includes:
These cover most high-impact failures without forcing complex anomaly detection on day one.
Use a “UI first, escape hatch second” approach:
If you allow custom SQL, enforce guardrails like read-only connections, timeouts, parameterization, and normalized pass/fail outputs.
Keep the first release small but complete:
Each failure view should clearly show , , and .
Split the system into four parts:
This separation keeps the control plane stable while the execution engine scales.
Use an append-only model:
Focus on actionability and noise reduction:
Include direct links to investigation pages (e.g., /checks/{id}/runs/{runId}) and optionally notify on recovery.
Treat it like an internal admin product:
Store both summary metrics and enough raw evidence (safely) to explain failures later, and record a config version/hash per run to distinguish “rule changed” from “data changed.”