क्यों ऑब्ज़रवेबिलिटी प्लेटफ़ॉर्म में बदल जाती है
एक ऑब्ज़रवेबिलिटी टूल आपको किसी सिस्टम के बारे में ख़ास सवालों के जवाब देने में मदद करता है—आम तौर पर चार्ट, लॉग, या क्वेरी रिज़ल्ट दिखाकर। यह कुछ ऐसा है जिसे आप किसी समस्या के समय “उपयोग” करते हैं।
एक ऑब्ज़रवेबिलिटी प्लेटफ़ॉर्म ज़्यादा व्यापक होता है: यह तय करता है कि टेलीमेट्री कैसे इकट्ठा होगी, टीमें कैसे उसका अन्वेषण करेंगी, और घटनाओं को end-to-end कैसे हैंडल किया जाएगा। यह कुछ ऐसा बन जाता है जिसे आपकी संस्था रोज़ाना कई सर्विसेज़ और टीमों में "चलाती" है।
चार्ट से परिणामों तक
अधिकांश टीमें डैशबोर्ड्स से शुरू करती हैं: CPU चार्ट, एरर‑रेट ग्राफ़, शायद कुछ लॉग सर्च। यह उपयोगी है, लेकिन असली लक्ष्य खूबसूरत चार्ट नहीं—यह है तेज़ डिटेक्शन और तेज़ रिज़ॉल्यूशन।
प्लेटफ़ॉर्म शिफ्ट तब होता है जब आप पूछना बंद कर देते हैं, “क्या हम इसे ग्राफ़ कर सकते हैं?” और शुरू करते हैं पूछना:
- क्या ऑन‑कॉल इंजीनियर मिनटों में रूट कॉज़ पा सकता है, घंटों में नहीं?
- क्या हम सही अलर्ट को ऑटोमैटिक सही टीम तक रूट कर सकते हैं?
- क्या हम बार‑बार होने वाले इन्सिडेंट पैटर्न को दोहराने योग्य प्लेबुक में बदल सकते हैं?
ये आउटकम‑फोकस्ड सवाल हैं, और इनके लिए विज़ुअलाइज़ेशन से ज़्यादा चाहिए: साझा डेटा स्टैण्डर्ड्स, सुसंगत इंटीग्रेशन, और वर्कफ़्लो जो टेलीमेट्री को कार्रवाई से जोड़ते हैं।
आप वाक़ई में क्या खरीद रहे हैं — तीन स्तम्भ
जैसे-जैसे Datadog जैसे प्लेटफ़ॉर्म विकसित होते हैं, "प्रोडक्ट सरफ़ेस" सिर्फ डैशबोर्ड नहीं रह जाता। यह तीन इंटरलॉकिंग स्तम्भ हैं:
- टेलीमेट्री: लॉग, मैट्रिक्स, और ट्रेसेस जो सुसंगत तरीके से कलेक्ट की जाती हैं और भरोसेमंद टैगिंग होती है।
- इंटीग्रेशन: प्री‑बिल्ट कनेक्शन जो अपनाने को आसान बनाते हैं और कस्टम ग्लू के बिना कवरेज बढ़ाते हैं।
- वर्कफ़्लो: इन्सिडेंट रिस्पांस, अलर्ट रूटिंग, ओनरशिप, और फॉलो‑अप—ताकि सीखना संचयित हो सके।
प्लेटफ़ॉर्म वैल्यू कम्पाउंड होती है
एक अकेला डैशबोर्ड एक टीम की मदद कर सकता है। एक प्लेटफ़ॉर्म हर ऑनबोर्ड की गई सर्विस, जोड़ी गई इंटीग्रेशन, और स्टैण्डर्ड की गई वर्कफ़्लो के साथ मजबूत होता जाता है। समय के साथ यह कम ब्लाइंड स्पॉट, कम डुप्लिकेट टूलिंग, और छोटे इन्सिडेंट्स में बदल जाता है—क्योंकि हर सुधार रीयूज़ेबल बन जाता है, वन‑ऑफ नहीं।
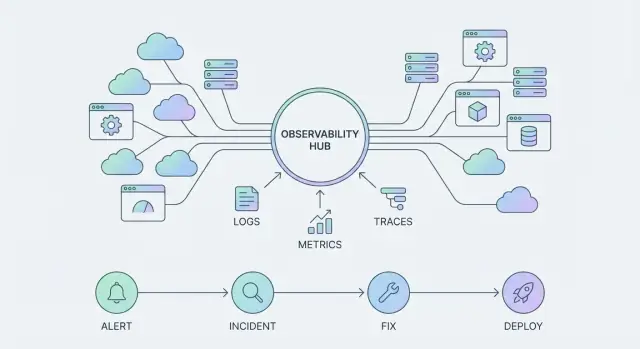
टेलीमेट्री प्रोडक्ट सरफ़ेस बन जाती है
जब ऑब्ज़रवेबिलिटी "एक टूल जिसे हम क्वेरी करते हैं" से बदलकर "एक प्लेटफ़ॉर्म जिस पर हम बिल्ड करते हैं" बन जाती है, तो टेलीमेट्री कच्चे उत्सर्जन से आगे बढ़कर प्रोडक्ट सरफ़ेस बन जाती है। आप जो एमिट करते हैं—और कितनी सुसंगतता से करते हैं—यह निर्धारित करता है कि आपकी टीमें क्या देख सकती हैं, ऑटोमेशन कहां कर सकती हैं, और किस पर भरोसा कर सकती हैं।
मूल टेलीमेट्री प्रकार (और वे किस काम आते हैं)
अधिकांश टीमें कुछ संकेतों के आसपास मानकीकृत होती हैं:
- Metrics: समय के साथ संख्यात्मक ट्रेंड्स (लेटेंसी, एरर रेट, सैचुरेशन)।
- Logs: जांच और ऑडिट के लिए विस्तृत, मानवीय रूप से पठनीय रिकॉर्ड।
- Traces: सेवाओं के पार अनुरोध पाथ ताकि पता चले समय और फेल्योर कहाँ हो रहे हैं।
- Events: अलग‑थलग “कुछ बदला” रिकॉर्ड (डिप्लॉय, फीचर फ्लैग, इन्सिडेंट)।
- Profiles: CPU/मेमोरी व्यवहार ताकि महँगे कोड पाथ मिल सकें।
अलग‑अलग, हर सिग्नल उपयोगी है। साथ में, वे आपके सिस्टम का एक एकीकृत इंटरफ़ेस बन जाते हैं—जो आप डैशबोर्ड, अलर्ट, इन्सिडेंट टाइमलाइन और पोस्टमॉर्टेम्स में देखते हैं।
मात्रा से ज़्यादा स्थिरता मायने रखती है
एक सामान्य विफलता है सबकुछ इकट्ठा करना पर नामकरण असंगत रखना। अगर एक सर्विस userId उपयोग करती है, दूसरी uid, और तीसरी कुछ नहीं लॉग करती, तो आप भरोसेमंद तरीके से डेटा को स्लाइस नहीं कर सकते, सिग्नल जॉइन नहीं कर सकते, या रीयुज़ेबल मॉनिटर नहीं बना सकते।
टीमें कुछ कन्वेंशंस—सर्विस नाम, एन्वायरनमेंट टैग, रिक्वेस्ट IDs, और कोर एट्रिब्यूट्स—पर सहमत होकर अधिक वैल्यू पाती हैं बनिस्बत इन्गेस्टेड वॉल्यूम दोगुना करने के।
हाई‑कार्डिनैलिटी का असली मतलब (और क्यों ज़रूरी है)
High‑cardinality फ़ील्ड ऐसे एट्रिब्यूट हैं जिनके कई संभावित मान होते हैं (जैसे user_id, order_id, session_id)। ये “केवल एक ग्राहक” जैसी समस्याओं के डिबग के लिए शक्तिशाली हैं, लेकिन यदि हर जगह उपयोग हों तो लागत बढ़ा सकते हैं और क्वेरीज धीमी कर सकते हैं।
प्लेटफ़ॉर्म अप्रोच इंटेंशनल होता है: हाई‑कार्डिनैलिटी को वहां रखें जहाँ इसका स्पष्ट इन्वेस्टिगेशनल वैल्यू हो, और ग्लोबल एग्रीगेट्स के लिए इससे बचें।
एकीकृत संदर्भ कोरिलेशन का काम घटाता है
जब मैट्रिक्स, लॉग्स, ट्रेसेस, इवेंट्स और प्रोफाइल्स एक ही संदर्भ साझा करते हैं (service, version, region, request ID), तो इंजीनियर्स साक्ष्य जोड़ने में कम समय लगाते हैं और असली समस्या ठीक करने में ज़्यादा। उपकरणों के बीच कूदने और अटकलें लगाने के बजाय, आप लक्षण से रूट कॉज़ तक एक धागा फॉलो करते हैं।
डेटा कलेक्शन से टेलीमेट्री रणनीति तक
ज्यादातर टीमें शुरुआत में बस “डेटा इन करें” से शुरू करती हैं। यह जरूरी है, पर यह रणनीति नहीं है। एक टेलीमेट्री रणनीति वही है जो ऑनबोर्डिंग को तेज़ रखती है और आपके डेटा को इतना सुसंगत बनाती है कि साझा डैशबोर्ड, भरोसेमंद अलर्ट और सार्थक SLOs चल सकें।
आम इनगेशन पाथ और उनके फायदे
Datadog आम तौर पर टेलीमेट्री कुछ व्यावहारिक मार्गों से पाती है:
- Hosts/VMs पर एजेंट्स: इन्फ्रास्ट्रक्चर मैट्रिक्स, लॉग्स, और APM जल्दी इकट्ठा करने का सबसे तेज़ तरीका, बिना बड़े कोड बदलाव के।
- कलेक्टर्स और गेटवे (जैसे OpenTelemetry Collector): तब उपयोगी जब आप सेंट्रल कंट्रोल, मल्टी‑डेस्टिनेशन रूटिंग, रिडैक्शन, या स्टैण्डर्ड प्रोसेसिंग चाहते हैं।
- APIs और डायरेक्ट SDKs: कस्टम इवेंट्स, बिज़नेस मैट्रिक्स या जहाँ एजेंट संभव नहीं वहाँ मददगार।
- Serverless integrations: मैनेज्ड रनटाइम्स के लिए सुविधाजनक, पर आपको सावधानी से सोचना होगा कि आप क्या एमिट करते हैं।
स्पीड बनाम स्टैंडर्डाइज़ेशन: किसे प्राथमिकता दें
शुरू में, स्पीड जीतती है: टीमें एक एजेंट इंस्टॉल कर देती हैं, कुछ इंटीग्रेशन चालू कर देती हैं, और तुरंत वैल्यू देखती हैं। जोखिम यह है कि हर टीम अपने टैग्स, सर्विस नाम और लॉग फॉर्मैट गढ़ ले—जिससे क्रॉस‑सर्विस व्यू गड़बड़ और अलर्ट अनट्रस्टवर्थ हो जाते हैं।
एक सरल नियम: "क्विक स्टार्ट" ऑनबोर्डिंग की अनुमति दें, पर 30 दिनों के अंदर स्टैण्डर्डाइज़ करने की आवश्यकता रखें। यह टीमों को गति देता है बिना अव्यवस्था को स्थायी बनाए।
एक हल्का नामकरण और टैगिंग कन्वेंशन
एक बड़ा टैक्सोनॉमी चाहिए नहीं। हर सिग्नल (लॉग्स, मैट्रिक्स, ट्रेसेस) के साथ एक छोटा सेट शुरू करें:
service: छोटा, स्थिर, लोअरकेस (उदा., checkout-api)env: prod, staging, devteam: ओनिंग टीम पहचान (उदा., payments)version: डिप्लॉय वर्शन या git SHA
यदि एक और चाहिए जो जल्दी लाभ दे, तो tier (frontend, backend, data) जोड़ें ताकि फ़िल्टरिंग सरल हो।
सैंपलिंग, रिटेंशन और लागत‑सजग डिफ़ॉल्ट्स
कॉस्ट के मुद्दे अक्सर बहुत उदार डिफ़ॉल्ट्स से आते हैं:
- Traces: हाई‑वॉल्यूम एंडपॉइंट्स के लिए हेड‑बेस्ड सैंपलिंग से शुरू करें; क्रिटिकल फ्लोज़ के लिए 100% रखें।
- Logs: डिफ़ॉल्ट रखें “error + महत्वपूर्ण बिज़नेस ईवेंट्स”, फिर समय‑बॉक्स्ड रिटेंशन के साथ info/debug जोड़ें जहाँ ज़रूरी हो।
- Retention: उच्च‑रेज़ोल्यूशन डेटा को कम समय रखें (दिनों में), और प्रमुख एग्रीगेट्स को लंबे समय के लिए रखें (हफ्ते/महीने)।
लक्ष्य कम इकट्ठा करना नहीं—बल्कि सही डेटा सुसंगत रूप से इकट्ठा करना है, ताकि आप उपयोग बढ़ाते हुए आश्चर्य न देखें।
इंटीग्रेशन असली वितरण चैनल हैं
लोग अक्सर ऑब्ज़रवेबिलिटी टूल्स को “कुछ जो आप इंस्टॉल करते हैं” समझते हैं। असल में, वे एक संगठन में वैसे ही फैलते हैं जैसे अच्छे कनेक्टर्स फैलते हैं: एक‑एक इंटीग्रेशन के जरिए।
“इंटीग्रेशन” का असल मतलब
एक इंटीग्रेशन सिर्फ डेटा पाइप नहीं है। इसमें आम तौर पर तीन हिस्से होते हैं:
- डेटा स्रोत: आपके मौजूदा सिस्टम्स (क्लाउड प्रोवाइडर, Kubernetes, DBs, CI/CD, SaaS) से मैट्रिक्स/लॉग/ट्रेस/टोपोलॉजी खींचना
- एनरिचमेंट: संदर्भ जोड़ना ताकि टेलीमेट्री तुरंत उपयोगी हो—सर्विस नाम, एन्व, ओनरशिप टैग, डिप्लॉय वर्शन, क्लाउड मेटाडेटा
- एक्शंस: जो आप सीखते हैं उसके साथ कुछ करना—टिकट बनाना, ऑन‑कॉल पेज करना, डिप्लॉय को एनोटेट करना, स्केल करना, या रनबुक ट्रिगर करना
आख़िरी हिस्सा ही इंटीग्रेशन्स को वितरण में बदलता है। अगर टूल केवल पढ़ता है, तो यह सिर्फ़ डैशबोर्ड डेस्टिनेशन है। अगर यह लिख भी सकता है, तो यह रोज़ के काम का हिस्सा बन जाता है।
इंटीग्रेशन अपनाने को तेज़ क्यों करते हैं
अच्छे इंटीग्रेशन सेटअप सेटअप टाइम घटाते हैं क्योंकि वे समझदार डिफ़ॉल्ट्स के साथ आते हैं: प्रीबिल्ट डैशबोर्ड, सिफारिश किए गए मॉनिटर, पार्सिंग नियम, और सामान्य टैग। हर टीम अलग‑अलग “CPU डैशबोर्ड” या “Postgres अलर्ट” न बनाकर, आप एक स्टैण्डर्ड शुरुआत पाते हैं जो बेस्ट‑प्रैक्टिस से मेल खाती है।
टीमें फिर भी कस्टमाइज़ करती हैं—पर साझा बेसलाइन से। यह मानकीकरण खासकर टूल कंसॉलिडेशन के समय मायने रखता है: इंटीग्रेशन्स रिपीटेबल पैटर्न बनाते हैं जिन्हें नई सर्विसेज़ कॉपी कर सकती हैं।
द्विदिश इंटीग्रेशन्स को प्राथमिकता दें
विकल्पों का मूल्यांकन करते समय पूछें: क्या यह संकेत इनगेस्ट कर सकता है और एक्शन ले सकता है? उदाहरण: आपके टिकटिंग सिस्टम में इन्सिडेंट खोलना, इन्सिडेंट चैनलों को अपडेट करना, या किसी PR/डिप्लॉय व्यू में ट्रेस लिंक अटैच करना। बिडायरेक्शनल सेटअप्स वही हैं जहाँ वर्कफ़्लोज़ “नैटिव” लगने लगते हैं।
एक सरल शॉर्टलिस्ट विधि
छोटे और प्रत्याश्य योग्य से शुरू करें:
- क्रिटिकल इन्फ्रास्ट्रक्चर पहले (क्लाउड प्रोवाइडर, Kubernetes, लोड बैलेंसर, कोर DB)
- फिर डिप्लॉय पाइपलाइन (CI/CD, फीचर फ्लैग, रिलीज़ ट्रैकिंग) ताकि टेलीमेट्री परिवर्तन के साथ लाइन हो
- जब टैगिंग और ओनरशिप कन्वेंशन स्थिर हों तो टीम‑बाय‑टीम SaaS जोड़ें (क्यूज़, कैश, ऑथ, पेमेंट्स)
एक रूले‑ऑफ‑थम्ब: उन इंटीग्रेशन्स को प्राथमिकता दें जो तुरंत इन्सिडेंट रिस्पॉन्स में सुधार लाते हैं, न कि सिर्फ़ और चार्ट जोड़ते हैं।
स्टैण्डर्ड व्यूज़: सर्विस, डैशबोर्ड और मॉनिटर
स्टैण्डर्ड व्यूज़ वह जगह हैं जहाँ ऑब्ज़रवेबिलिटी प्लेटफ़ॉर्म रोज़मर्रा में उपयोगी बनता है। जब टीमें एक ही मेंटल मॉडल साझा करती हैं—"एक सर्विस क्या है", "स्वस्थ क्या दिखता है", और "पहले कहाँ क्लिक करें"—तब डिबग तेज़ होता है और हैंडऑफ़ साफ़ होते हैं।
गोल्डन सिग्नल से शुरू करें (और इन्हें दिखें बनाएं)
एक छोटा सेट गोल्डन सिग्नल चुनें और हर एक के लिए एक ठोस, रीयूज़ेबल डैशबोर्ड बनाएं। अधिकांश सेवाओं के लिए यह है:
- Latency (कुंजी एंडपॉइंट्स के लिए p95/p99)
- Traffic (requests per second, jobs processed)
- Errors (दर और टॉप एरर प्रकार)
- Saturation (CPU, मेमोरी, क्यू डेप्थ, DB कनेक्शन्स)
कुंजी है सुसंगतता: एक डैशबोर्ड लेआउट जो सर्विसेज़ में काम करे, दस अलग‑अलग बेज़िक डैशबोर्ड से बेहतर है।
सर्विस कैटलॉग साझा ओनरशिप बनाता है
एक सर्विस कैटलॉग (यहाँ तक कि हल्का‑फुल्का) “किसी को देखना चाहिए” को बदल देता है—"यह टीम इसका ओनर है" में। जब सेवाओं पर ओनर्स, एन्वायरनमेंट और डिपेंडेंसीज़ टैग हों, प्लेटफ़ॉर्म बुनियादी सवाल तुरंत जवाब दे सकता है: इस सर्विस पर कौन से मॉनिटर लागू हैं? मुझे कौन से डैशबोर्ड खोलने चाहिए? किसे पेज किया जाए?
यह स्पष्टता इन्सिडेंट के दौरान स्लैक पिंग‑पॉन्ग घटाती है और नए इंजीनियरों को सेल्फ‑सर्व करने में मदद करती है।
जो बिल्डिंग ब्लॉक्स स्केल करते हैं
इन्हें वैकल्पिक नहीं बल्कि मानक आर्टिफैक्ट मानें:
- डैशबोर्ड गोल्डन सिग्नल और प्रमुख डिपेंडेंसीज़ के लिए
- मॉनिटर SLOs या यूज़र‑इम्पैक्टिंग लक्षणों से जुड़े
- नोटबुक्स जांच और पोस्ट‑इन्सिडेंट टाइमलाइन के लिए
- रनबुक्स (मॉनिटर्स से लिंक किए हुए) पहले 5–10 मिनट की रिस्पॉन्स के लिए
बचने योग्य एंटी‑पैटर्न
वेनिटी डैशबोर्ड (कोई निर्णय पीछे नहीं), एक‑ऑफ़ अलर्ट्स जो कभी ट्यून नहीं हुए, और बिना डॉक्यूमेंटेड क्वेरीज (केवल एक व्यक्ति समझता है) प्लेटफ़ॉर्म शोर बनाते हैं। अगर कोई क्वेरी मायने रखती है, तो उसे सेव करें, नाम दें, और एक सर्विस व्यू से लिंक करें।
वर्कफ़्लो: जहाँ ऑब्ज़रवेबिलिटी बिज़नेस वैल्यू देती है
प्लेटफ़ॉर्म ग्लू का प्रोटोटाइप बनाएं
एक दोपहर में अपनी प्लेटफ़ॉर्म टीम के लिए तेज़ React और Go प्रोटोटाइप बनाएं।
ऑब्ज़रवेबिलिटी तभी “वास्तविक” बनती है जब यह समस्या और एक भरोसेमंद फ़िक्स के बीच का समय छोटा कर देती है। यह वर्कफ़्लो के जरिए होता है—दोहराने योग्य रास्ते जो आपको सिग्नल से कार्रवाई तक और कार्रवाई से सीख तक ले जाते हैं।
इन्सिडेंट जर्नी: अलर्ट → ट्रायज → कम्यूनिकेट → मिटिगेट → सीख
एक स्केलेबल वर्कफ़्लो सिर्फ किसी को पेज करना नहीं है।
एक अलर्ट को एक केंद्रित ट्रायज लूप खोलना चाहिए: इम्पैक्ट की पुष्टि करें, प्रभावित सर्विस पहचानें, और सबसे प्रासंगिक संदर्भ (हाल के डिप्लॉय, डिपेंडेंसी हेल्थ, एरर स्पाइक्स, सैचुरेशन सिग्नल) खींचें। इसके बाद, कम्यूनिकेशन तकनीकी घटना को समन्वित प्रतिक्रिया में बदल देता है—कौन घटना का मालिक है, उपयोगकर्ता क्या देख रहे हैं, और अगली अपडेट कब होगी।
मिटिगेशन वह जगह है जहाँ आप चाहते हैं कि “सेफ़ मूव्स” आपके पास तुरंत हों: फीचर फ्लैग्स, ट्रैफ़िक शिफ्टिंग, रोलबैक, रेट‑लिमिट्स, या जाना‑माना वर्कअराउंड। अंत में, सीखना एक हल्की समीक्षा के साथ लूप बंद करता है जो रिकॉर्ड करती है कि क्या बदला, क्या काम किया, और अगला ऑटोमेट करने योग्य कदम क्या है।
इन्सिडेंट टूलिंग + ChatOps = सहयोग, हीरोइक्स नहीं
Datadog जैसे प्लेटफ़ॉर्म तब वैल्यू जोड़ते हैं जब वे साझा काम का समर्थन करते हैं: इन्सिडेंट चैनल, स्टेटस अपडेट, हैंडऑफ़, और सुसंगत टाइमलाइन। ChatOps इंटीग्रेशन अलर्ट्स को संरचित बातचीत में बदल सकते हैं—इन्सिडент बनाना, रोल्स असाइन करना, और थ्रेड में महत्वपूर्ण ग्राफ़ और क्वेरीज पोस्ट करना ताकि हर कोई वही सबूत देखे।
एक अच्छे रनबुक में वास्तव में क्या होता है
एक उपयोगी रनबुक संक्षिप्त, राय‑आधारित, और सुरक्षित होनी चाहिए। इसमें शामिल होना चाहिए: लक्ष्य (सर्विस बहाल करना), स्पष्ट ओनर्स/ऑन‑कॉल रोटेशन, स्टेप‑बाय‑स्टेप चेक्स, सही डैशबोर्ड/मॉनिटर के लिंक, और "सेफ़ एक्शंस" जो जोखिम कम करते हैं (रोलबैक स्टेप्स के साथ)। अगर इसे 3 AM पर चलाना सुरक्षित नहीं है, तो यह पूरा नहीं है।
इन्सिडेंट्स को डिप्लॉय्स और चेंजेस से लिंक करें
जब इन्सिडेंट्स को ऑटोमैटिकली डिप्लॉय्स, कॉन्फ़िग चेंजेस, और फीचर‑फ्लैग फ्लिप्स के साथ कोरिलेट किया जाता है, तो रूट कॉज़ तेज़ मिलता है। “क्या बदला?” को एक प्रथम‑कक्षा व्यू बनाएं ताकि ट्रायज साक्ष्य से शुरू हो, अटकलों से नहीं।
SLOs और एरर बजट एक टीम ऑपरेटिंग सिस्टम के रूप में
SLO क्या है (और यह “ग्रीन डैशबोर्ड” से बेहतर क्यों है)
एक SLO (Service Level Objective) उपयोगकर्ता अनुभव के बारे में एक साधारण वादा है—जैसे "30 दिनों में 99.9% अनुरोध सफल हों" या "p95 पेज लोड 2 सेकंड से कम हो"।
यह "ग्रीन डैशबोर्ड" से बेहतर है क्योंकि डैशबोर्ड अक्सर सिस्टम हेल्थ दिखाते हैं (CPU, मेमोरी, क्यू), न कि कस्टमर इम्पैक्ट। एक सर्विस हरी दिख सकती है और फिर भी उपयोगकर्ताओं को विफल कर रही हो। SLOs टीम को वही मापने पर मजबूर करते हैं जो उपयोगकर्ता महसूस करते हैं।
एरर बजेट: जोखिम के बारे में साझा भाषा
एरर बजेट वह अनुमति दी गई अनरेलाईबिलिटी है जो आपके SLO से निकलती है। अगर आप 30 दिनों में 99.9% सफलता वादा करते हैं, तो उस विंडो में लगभग 43 मिनट की त्रुटियों की अनुमति है।
यह निर्णयों के लिए एक प्रायोगिक ऑपरेटिंग सिस्टम बनाता है:
- बजेट हेल्दी: फीचर शिप करें, प्रयोग करें, समझौता करें
- बजेट बर्निंग: रिलीज़ धीमी करें, विश्वसनीयता पर ध्यान दें
- बजेट समाप्त: जोखिम भरे डिप्लॉय रोकें और मुख्य विफलता स्रोत ठीक करें
इसके बजाय कि रिलीज़ मीटिंग में राय पर बहस हो, आप एक संख्या पर बहस कर रहे हैं जिसे हर कोई देख सकता है।
बर्न रेट पर अलर्ट करें, हर स्पाइक पर नहीं
SLO अलर्टिंग तब सबसे अच्छा काम करती है जब आप बर्न रेट (आप कितनी तेज़ी से एरर बजेट इस्तेमाल कर रहे हैं) पर अलर्ट करते हैं, न कि रॉ एरर काउंट पर। इससे शोर कम होता है:
- एक छोटा स्पाइक जो खुद ठीक हो जाए शायद किसी को पेज न करे।
- एक लगातार समस्या जो बजेट जल्दी ख़त्म कर देगी, वह स्पष्ट, कार्रवाईयोग्य अलर्ट ट्रिगर करेगी।
कई टीमें दो विंडो उपयोग करती हैं: एक फास्ट बर्न (तेज़ पेज) और एक स्लो बर्न (टिकट/नोटिफ़ाई)।
एक हल्का SLO स्टार्टर सेट
छोटे से शुरू करें—दो से चार SLOs जो आप वास्तव में उपयोग करेंगे:
- Availability: सफल अनुरोधों का % (उदा., HTTP 2xx/3xx) 30 दिनों में
- Latency: p95 लेटेंसी एक थ्रेशोल्ड के अन्दर (जरूरत पड़ें तो रीड बनाम राइट अलग)
- Checkout / क्रिटिकल एंडपॉइंट: बिज़नेस के लिए सबसे महत्वपूर्ण पाथ का सक्सेस रेट
- Freshness (यदि लागू): बैकग्राउंड जॉब्स X मिनट में पूरे होते हैं
जब ये स्थिर हों, तो आप विस्तार कर सकते हैं—अन्यथा आप सिर्फ़ और डैशबोर्ड बना लेंगे। अधिक के लिए देखें /blog/slo-monitoring-basics।
अलर्टिंग जो स्केल करे बिना लोगों को जलाए
पहले वर्कफ़्लो डिज़ाइन करें
कोड जनरेट करने से पहले प्लानिंग मोड का उपयोग करके अलर्ट, मालिक और रनबुक को मैप करें।
अलर्टिंग वह जगह है जहाँ कई ऑब्ज़रवेबिलिटी प्रोग्राम ठहर जाते हैं: डेटा है, डैशबोर्ड अच्छे लगते हैं, पर ऑन‑कॉल अनुभव शोर से भर जाता है और भरोसा खो देता है। यदि लोग अलर्ट्स अनदेखा करना सीख जाते हैं, तो आपका प्लेटफ़ॉर्म बिज़नेस की रक्षा करने की क्षमता खो देता है।
अलर्ट थकान क्यों होती है (और सिग्नल डुप्लिकेट क्यों होते हैं)
सबसे सामान्य कारण लगातार मिलते हैं:
- बहुत से “FYI” अलर्ट जो कार्रवाई नहीं मांगते
- संदर्भ के बिना थ्रेशोल्ड्स की नकल (वही CPU नियम अलग वर्कलोड पर)
- एक ही लक्षण पर कई टूल/टीमें अलर्ट कर रही हों—उदा., APM एरर‑रेट मॉनिटर और लॉग‑आधारित एरर मॉनिटर दोनों एक ही घटना के लिए पेज कर दें
- शोर वाले मैट्रिक्स (स्पाइकी लेटेंसी पर्सेंटाइल्स, ऑटोस्केलिंग प्रभाव) जो वास्तविक समस्याओं के बजाय उतार‑चढ़ाव ट्रिगर करते हैं
Datadog की भाषा में, डुप्लिकेट सिग्नल अक्सर तब दिखते हैं जब मॉनिटर अलग‑अलग "सरफ़ेस" (मैट्रिक्स, लॉग्स, ट्रेसेस) से बनाए जाते हैं बिना यह तय किए कि कौन सा canonical पेज करेगा।
रूटिंग: ओनरशिप, गंभीरता, और क्वायट आवर्स
अलर्टिंग को स्केल करने की शुरुआत ऐसे रूल्स से होती है जो इंसानों के लिए समझदारी दिखाते हैं:
- ओनरशिप: हर मॉनिटर का स्पष्ट ओनर (सर्विस/टीम) और एसकलेशन पथ होना चाहिए
- सीवेरिटी: पेजिंग सिर्फ इसलिए करें जब यूज़र‑इम्पैक्ट हो; कम गंभीर के लिए टिकट या चैट नोटिफ़ाइ करें
- मेंटेनेंस विंडोज़: योजनाबद्ध डिप्लॉयस, माइग्रेशंस, और लोड टेस्ट पेज न करें
ऐसे सरल नियम जो अलर्ट्स को कार्रवाईयोग्य रखें
उपयोगी डिफ़ॉल्ट: लक्षणों पर अलर्ट करें, हर मैट्रिक चेंज पर नहीं। उपयोगकर्ताओं को महसूस होने वाली चीज़ों पर पेज करें (एरर रेट, फेल्ड चेकआउट, स्थायी लेटेंसी, SLO बर्न), न कि "इनपुट्स" (CPU, pod count) पर जब तक वे भरोसेमंद रूप से इम्पैक्ट नहीं दिखाते।
एक काम करने वाला समीक्षा कड़ियाँ
ऑपरेशंस का हिस्सा बनाएं: मासिक मॉनिटर प्रूनिंग और ट्यूनिंग। न कभी फायर हुए मॉनिटर हटा दें, बार‑बार फायर होने वाले थ्रेशोल्ड्स समायोजित करें, और डुप्लिकेट्स मर्ज करें ताकि हर इन्सिडेंट का एक प्राथमिक पेज हो और सहायक संदर्भ मौजूद हों।
यह ठीक होने पर, अलर्टिंग एक ऐसा वर्कफ़्लो बन जाती है जिस पर लोग भरोसा करते हैं—न कि एक पृष्ठभूमि शोर जनरेटर।
गवर्नेंस: प्लेटफ़ॉर्म बड़े होने पर उपयोगी कैसे रहता है
ऑब्ज़रवेबिलिटी को "प्लेटफ़ॉर्म" कहना सिर्फ़ लॉग्स, मैट्रिक्स, ट्रेसेस और कई इंटीग्रेशन्स होने का मतलब नहीं है। इसका अर्थ गवर्नेंस भी है: वे स्थिरता और गार्ड्रेल्स जो सिस्टम को उपयोगी रखते हैं जब टीमें, सर्विसेज़, डैशबोर्ड, और अलर्ट्स बढ़ते हैं।
बिना गवर्नेंस के, Datadog (या कोई भी प्लेटफ़ॉर्म) एक शोर भरा स्क्रैपबुक बन सकता है—सैकड़ों थोड़े‑बहुत अलग डैशबोर्ड, असंगत टैग्स, अस्पष्ट ओनरशिप, और अलर्ट्स जिन पर कोई भरोसा नहीं करता।
गवर्नेंस एक लोग‑और‑प्रक्रिया की समस्या है
अच्छा गवर्नेंस यह स्पष्ट करता है कि कौन क्या तय करता है, और जब प्लेटफ़ॉर्म गन्दा हो जाए तो किसे जवाबदेह होना चाहिए:
- प्लेटफ़ॉर्म टीम: मानक (टैगिंग, नामकरण, डैशबोर्ड पैटर्न) परिभाषित करती है, साझा कंपोनेंट देती है, और इंटीग्रेशन्स रखती है
- सर्विस ओनर्स: अपनी सर्विस के टेलीमेट्री की गुणवत्ता के उत्तरदायी होते हैं
- सिक्योरिटी व कम्प्लायंस: डेटा हैंडलिंग नियम तय करती है (PII, रिटेंशन, एक्सेस) और हाई‑रिस्क इंटीग्रेशन्स की समीक्षा करती है
- लीडरशिप: गवर्नेंस को बिज़नेस प्राथमिकताओं के साथ संरेखित करती है और संसाधन देती है
“ऑब्ज़रवेबिलिटी स्प्रॉल” रोकने वाले व्यावहारिक कंट्रोल्स
कुछ हल्के कंट्रोल्स लंबी नीति दस्तावेज़ों से ज़्यादा असर करते हैं:
- टेम्पलेट्स by default: सर्विस टाइप (API, वर्कर, DB) के लिए स्टार्टर डैशबोर्ड और मॉनिटर पैक
- टैगिंग नीति: एक छोटा अनिवार्य सेट (जैसे
service, env, team, tier) और वैकल्पिक टैग्स के नियम। CI में लागू करें जहाँ संभव हो
- एक्सेस और ओनरशिप: संवेदनशील डेटा के लिए रोल‑बेस्ड एक्सेस और डैशबोर्ड/मॉनिटर के लिए ओनर आवश्यक करें
- हाई‑इम्पैक्ट चेंजिस के लिए अप्रूवल फ्लो: ऐसे मॉनिटर जो लोगों को पेज करते हैं, लॉग पाइपलाइन्स जो कॉस्ट प्रभावित करते हैं, और संवेदनशील डेटा खींचने वाली इंटीग्रेशन्स की समीक्षा अनिवार्य करें
रीयूज़ बनाम पुनराविष्कार
गुणवत्ता स्केल करने का तेज़ तरीका वही साझा करना है जो काम करता है:
- शेयरड लाइब्रेरीज़: आंतरिक पैकेज/स्निपेट्स जो लॉगिंग फील्ड्स, ट्रेस एट्रिब्यूट्स, और सामान्य मैट्रिक्स को स्टैण्डर्ड करते हैं
- रीयूज़ेबल डैशबोर्ड और मॉनिटर: सेंट्रल कैटलॉग जहां से टीमें क्लोन करके अनुकूलित कर सकती हैं
- वर्जनड स्टैंडर्ड्स: प्रमुख एसेट्स को कोड की तरह ट्रीट करें—परिवर्तन डॉक्यूमेंट करें, पुराने पैटर्न डिप्रिकेट करें, और अपडेट्स एक जगह घोषित करें
यदि आप चाहते हैं कि यह टिके, तो गवर्ने किया हुआ रास्ता आसान बनाएं—कम क्लिक, तेज़ सेटअप, और स्पष्ट ओनरशिप।
लागत, वैल्यू, और प्लेटफ़ॉर्म फ़्लाइव्हील
एक बार ऑब्ज़रवेबिलिटी प्लेटफ़ॉर्म जैसा व्यवहार करने लगती है, यह प्लेटफ़ॉर्म इकोनॉमिक्स का पालन करने लगती है: जितनी अधिक टीमें इसे अपनाती हैं, उतनी अधिक टेलीमेट्री पैदा होती है, और यह और उपयोगी बनता है।
यह एक फ़्लाइव्हील बनाता है:
- और सर्विसेज़ ऑनबोर्ड → बेहतर क्रॉस‑सर्विस विजिबिलिटी
- बेहतर विज़िबिलिटी → तेज़ निदान, कम रिपीट इन्सिडेंट, टूल पर अधिक भरोसा
- अधिक भरोसा → और टीमें इंस्ट्रूमेंट और इंटीग्रेट करती हैं → और डेटा
ख़याल रखें कि यही लूप लागत भी बढ़ा देता है। अधिक होस्ट्स, कंटेनर्स, लॉग्स, ट्रेसेस, साइनथेटिक्स और कस्टम मैट्रिक्स बजट से तेज़ी से बढ़ सकते हैं अगर आप सावधानी से प्रबंधित न करें।
व्यावहारिक लागत लीवर्स (सिग्नल न मारते हुए)
आपको सब कुछ बंद नहीं करना है। डेटा को आकार देकर शुरू करें:
- सैंपलिंग: क्रिटिकल एंडपॉइंट्स के लिए हाई‑फिडेलिटी ट्रेस रखें, बाकी जगह ज़्यादा सैंपलिंग करें
- रिटेंशन टियर्स: कच्चे हाई‑वॉल्यूम लॉग्स का छोटा रिटेंशन; curated सिक्योरिटी/ऑडिट स्ट्रीम्स का लंबा रिटेंशन
- लॉग फ़िल्टरिंग और पार्सिंग: शुरुआती शोर (हेल्थ चेक, स्टेटिक एसेट रिक्वेस्ट) ड्रॉप करें और पार्सिंग स्टैण्डर्ड करें ताकि आप एट्रिब्यूट्स के आधार पर रूट कर सकें
- मैट्रिक एग्रीगेशन: अनबाउंड कार्डिनैलिटी की जगह पर्सेंटाइल्स, रेट्स और रोल‑अप्स को प्राथमिकता दें
लागत को परिणामों से जोड़ने वाले KPIs
कुछ मेट्रिक्स ट्रैक करें जो दिखाएं कि प्लेटफ़ॉर्म लाभ लौटा रहा है:
- MTTD (mean time to detect)
- MTTR (mean time to resolve)
- इन्सिडेंट काउंट और रिपीट इन्सिडेंट्स (वही रूट कॉज़)
- डिप्लॉय फ़्रीक्वेंसी (और चेंज फेल्योर रेट यदि आप ट्रैक करते हैं)
त्रैमासिक “वैल्यू बनाम कॉस्ट” रिव्यू (बिना दोषारोपण)
इसे एक प्रोडक्ट रिव्यू बनाएं, ऑडिट नहीं। प्लेटफ़ॉर्म ओनर्स, कुछ सर्विस टीमें, और फाइनेंस को बुलाएं। समीक्षा करें:
- टॉप कॉस्ट ड्राइवर्स डेटा प्रकार (लॉग्स/मैट्रिक्स/ट्रेसेस) और टीम के हिसाब से
- टॉप विन्स: कहाँ इन्सिडेंट्स छोटे हुए, आउटेज टल गए, टॉइल घटा
- 2–3 सहमत क्रियाएँ (उदा., सैंपलिंग नियम समायोजित करना, रिटेंशन टियरिंग जोड़ना, शोरयुक्त इंटीग्रेशन ठीक करना)
लक्ष्य साझा ओनरशिप है: लागत बेहतर इंस्ट्रूमेंटेशन निर्णयों का इनपुट बने, ऑब्ज़रवेशन बंद करने का कारण न बने।
इसका मतलब आपके ऑब्ज़रवेबिलिटी टूल स्टैक के लिए
ऑब्ज़र्वेबिलिटी हब लॉन्च करें
एक हल्का ऑब्ज़र्वेबिलिटी हब बनाएं जो सेवाओं को मालिकों, डैशबोर्ड और रनबुक से जोड़ता है।
यदि ऑब्ज़रवेबिलिटी प्लेटफ़ॉर्म बन रही है, तो आपका "टूल स्टैक" पॉइंट सॉल्यूशन्स का संग्रह नहीं रहकर साझा इंफ्रास्ट्रक्चर जैसा काम करने लगता है। यह शिफ्ट टूल स्प्रॉल को सिर्फ़ नापसंद समस्या से ज़्यादा बना देता है: यह डुप्लिकेट इंस्ट्रूमेंटेशन, परिभाषाओं का असंगति (क्या एक एरर माना जाता है?), और ऑन‑कॉल लोड बढ़ाने वाली स्थिति पैदा करता है क्योंकि सिग्नल्स लॉग्स, मैट्रिक्स, ट्रेसेस और इन्सिडेंट्स में मेल नहीं खाते।
कंसॉलिडेशन का मतलब जरूरी नहीं कि "सब कुछ एक विक्रेता से"—बल्कि यह कम सिस्टम ऑफ़ रिकॉर्ड, स्पष्ट ओनरशिप, और उन जगहों की संख्या को कम करना है जहाँ लोगों को आउटेज के दौरान देखना पड़ता है।
कंसॉलिडेशन क्या हल कर सकता है
टूल स्प्रॉल आमतौर पर तीन जगहों में छुपी लागत दिखाती है: UIs के बीच समय खर्च करना, नाज़ुक इंटीग्रेशन्स जिन्हें आपको मेंटेन करना पड़ता है, और टेढा‑मेढा गवर्नेंस (नामकरण, टैग्स, रिटेंशन, एक्सेस)।
एक अधिक कंसॉलिडेटेड प्लेटफ़ॉर्म अप्रोच कॉन्टेक्स्ट स्विचिंग घटा सकती है, सर्विस व्यू स्टैण्डर्डाइज़ कर सकती है, और इन्सिडेंट वर्कफ़्लो को रिपीटेबल बना सकती है।
एक निर्णय चेकलिस्ट (त्वरित पर व्यावहारिक)
अपने स्टैक का मूल्यांकन करते समय (Datadog या विकल्प सहित) इनपर दबाव डालें:
- मस्ट‑हैव इंटीग्रेशन्स: क्लाउड प्रोवाइडर, Kubernetes, CI/CD, इन्सिडेंट मैनेजमेंट, पेजिंग, और प्रमुख डेटा स्टोर्स—साथ ही कोई भी बिज़नेस सिस्टम "बिना इसके हम शिप नहीं कर सकते"
- वर्कफ़्लोज़: क्या आप अलर्ट → ओनर → रनबुक → टाइमलाइन → पोस्टमॉर्टम बिना मैन्युअल कॉपी/पेस्ट के कर सकते हैं?
- गवर्नेंस: टैगिंग स्टैंडर्ड्स, एक्सेस कंट्रोल्स, रिटेंशन, और डैशबोर्ड/मॉनिटर स्प्रॉल के गार्ड्रेल्स
- प्राइसिंग मॉडल: क्या लागत किस चीज़ से बढ़ती है (होस्ट्स, कंटेनर्स, ingest किए गए लॉग्स, इंडेक्स्ड ट्रेसेस)? क्या आप ग्रोथ का फ़ोरकास्ट कर सकते हैं बिना आश्चर्य के?
स्पष्ट सफलता मेट्रिक के साथ पायलट चलाएँ
1–2 सर्विस चुनें। एक सफलता मेट्रिक तय करें जैसे “रूट कॉज़ पहचानने का समय 30 मिनट से 10 मिनट हो जाए” या “नॉइज़ी अलर्ट्स 40% घटें।” ज़रूरी ही इंस्ट्रूमेंट करें, और दो हफ्तों में नतीजे रिव्यू करें।
आंतरिक सीख केंद्रीकृत रखें—पायलट रनबुक, टैगिंग नियम, और डैशबोर्ड एक जगह लिंक करें (उदा., /blog/observability-basics)।
एक व्यावहारिक अपनाने की योजना जो आप कॉपी कर सकते हैं
आप "Datadog रोलआउट" एक बार में नहीं करते। आप छोटे से शुरू करते हैं, जल्दी मानक तय करते हैं, फिर जो काम करे उसे स्केल करते हैं।
30/60/90‑दिन रोलआउट
Days 0–30: Onboard (तेज़ वैल्यू दिखाएँ)
1–2 क्रिटिकल सर्विस और एक ग्राहक‑सामना यात्रा चुनें। लॉग्स, मैट्रिक्स, और ट्रेसेस सुसंगत रूप से इंस्ट्रूमेंट करें, और जिन इंटीग्रेशन्स पर आप निर्भर हैं उन्हें कनेक्ट करें (क्लाउड, Kubernetes, CI/CD, ऑन‑कॉल)।
Days 31–60: Standardize (इसे रिपीटेबल बनाएं)
जो सीखा उसे डिफ़ॉल्ट्स में बदलें: सर्विस नामकरण, टैगिंग, डैशबोर्ड टेम्पलेट्स, मॉनिटर नामकरण, और ओनरशिप। गोल्डन सिग्नल व्यू बनाएं (latency, traffic, errors, saturation) और सबसे महत्वपूर्ण एंडपॉइंट्स के लिए एक न्यूनतम SLO सेट तैयार करें।
Days 61–90: Scale (बिना अराजकता के बढ़ाएं)
अतिरिक्त टीमों को वही टेम्पलेट दें और ऑनबोर्ड करें। गवर्नेंस पेश करें (टैग नियम, आवश्यक मेटाडेटा, नए मॉनिटर के लिए समीक्षा प्रक्रिया) और प्लेटफ़ॉर्म स्वस्थ रखने के लिए कॉस्ट बनाम यूज़ेज़ ट्रैक करना शुरू करें।
Koder.ai कहाँ फिट बैठता है (व्यावहारिक रूप से)
जब आप ऑब्ज़रवेबिलिटी को प्लेटफ़ॉर्म मानते हैं, तो अक्सर आप इसके आस‑पास छोटे “ग्लू” ऐप्स चाहते हैं: सर्विस कैटलॉग UI, रनबुक हब, इन्सिडент टाइमलाइन पेज, या एक इंटरनल पोर्टल जो ओनर्स → डैशबोर्ड → SLOs → प्लेबुक्स को लिंक करे।
यह वह हल्का‑वज़न इंटरनल टूलिंग है जिसे आप जल्दी Koder.ai पर बना सकते हैं—एक vibe‑coding प्लेटफ़ॉर्म जो चैट के ज़रिये वेब ऐप्स जनरेट करने देता है (आमतौर पर React फ्रंटेंड, Go + PostgreSQL बैकेंड), सोर्स कोड एक्सपोर्ट और डिप्लॉय/होस्टिंग सपोर्ट के साथ। टीमें इसे गवर्नेंस और वर्कफ़्लोस को आसान बनाने वाली ऑपरेशनल सतहों को त्वरित प्रोटोटाइप और शिप करने के लिए उपयोग करती हैं बिना पूरी प्रोडक्ट टीम को रोडमैप से हटाए।
पहले सप्ताह में शिप करने योग्य तेज़ जीतें
- टॉप 10 मॉनिटर availability, error rate, latency, saturation और प्रमुख डिपेंडेंसीज़ के लिए
- डिप्लॉयमेंट मार्कर्स डैशबोर्ड और ट्रेसेस पर परिवर्तन‑कोरिलेशन के लिये
- इन्सिडेंट टेम्पलेट: क्या हुआ, प्रभाव, टाइमलाइन, ओनर्स, डैशबोर्ड/क्वेरी लिंक, अगले कदम
टिकने वाली ट्रेनिंग
दो 45‑मिनट सत्र चलाएँ: (1) “यहाँ हम कैसे क्वेरी करते हैं” साझा क्वेरी पैटर्न्स के साथ (सर्विस, env, region, version द्वारा), और (2) “ट्रबलशूटिंग प्लेबुक” एक सरल फ्लो के साथ: इम्पैक्ट कन्फर्म करें → डिप्लॉय मार्कर्स देखें → सर्विस को संकुचित करें → ट्रेसेस देखें → डिप्लॉय/डिपेंडेंसी हेल्थ कन्फर्म करें → रोलबैक/मिटिगेशन तय करें।
कॉपी/पेस्ट चेकलिस्ट