15 सित॰ 2025·8 मिनट
डेविड पैटरसन, RISC सोच और को‑डिज़ाइन का स्थायी प्रभाव
जानिए कैसे डेविड पैटरसन की RISC सोच और हार्डवेयर‑सॉफ़्टवेयर को‑डिज़ाइन ने प्रदर्शन‑प्रति‑वाट सुधारा, CPU डिज़ाइनों को आकार दिया और आज RISC‑V को प्रभावित कर रहा है।
जानिए कैसे डेविड पैटरसन की RISC सोच और हार्डवेयर‑सॉफ़्टवेयर को‑डिज़ाइन ने प्रदर्शन‑प्रति‑वाट सुधारा, CPU डिज़ाइनों को आकार दिया और आज RISC‑V को प्रभावित कर रहा है।
डेविड पैटरसन को अक्सर “RISC के पायनियर” के रूप में पेश किया जाता है, लेकिन उनका स्थायी प्रभाव किसी एक CPU डिज़ाइन से कहीं अधिक व्यापक है। उन्होंने कंप्यूटरों के बारे में एक व्यावहारिक चिंतन‑शैली लोकप्रिय की: प्रदर्शन को एक नापने‑योग्य चीज़ मानो, उसे सरल बनाओ, और अंत‑से‑अंत सुधारो—चिप द्वारा समझे जाने वाले निर्देशों से लेकर उन सॉफ़्टवेयर टूल्स तक जो वे निर्देश जनरेट करते हैं।
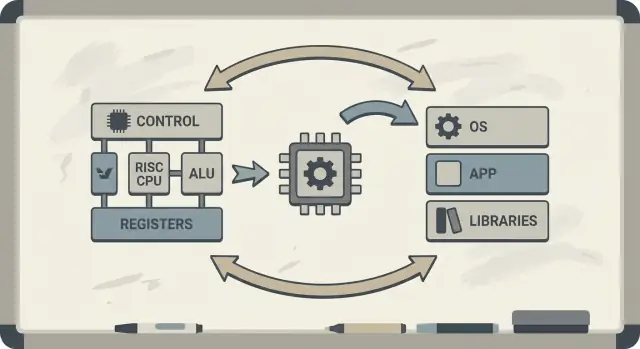
RISC (Reduced Instruction Set Computing) यह विचार है कि जब प्रोसेसर एक छोटे सेट के सरल निर्देशों पर ध्यान केंद्रित करता है तो वह तेज़ और अधिक पूर्वानुमानशील चल सकता है। जटिल ऑपरेशनों के एक बड़े मेन्यू को हार्डवेयर में बनाने के बजाय, आम ऑपरेशनों को तेज़, नियमित और पाइपलाइन करने में आसान बनाओ। फायदा यह नहीं कि “कम क्षमता” है—बल्कि सरल निर्माण‑ब्लॉक्स, जब कुशलता से निष्पादित हों, वास्तविक वर्कलोड में अक्सर जीतते हैं।
पैटरसन ने हार्डवेयर–सॉफ्टवेयर को‑डिज़ाइन का भी समर्थन किया: एक फीडबैक लूप जहाँ चिप आर्किटेक्ट्स, कंपाइलर लेखक और सिस्टम डिजाइनर एक साथ इटरैट करते हैं।
यदि एक प्रोसेसर सरल पैटर्न्स को अच्छी तरह से निष्पादित करने के लिए डिज़ाइन किया गया है, तो कंपाइलर भरोसेमंद तरीके से उन पैटर्न्स का उत्पादन कर सकते हैं। अगर कंपाइलर दिखाते हैं कि वास्तविक प्रोग्राम किसी विशेष ऑपरेशन (जैसे मेमोरी एक्सेस) में समय खर्च करते हैं, तो हार्डवेयर उन मामलों से निपटने के लिए समायोजित किया जा सकता है। इसलिए ISA की चर्चा स्वाभाविक रूप से कंपाइलर ऑप्टिमाइज़ेशन, कैशिंग और पाइपलाइनिंग से जुड़ जाती है।
आप जानेंगे कि RISC विचार प्रदर्शन‑प्रति‑वाट से कैसे जुड़ते हैं (सिर्फ कच्ची गति नहीं), कैसे “पूर्वानुमानशीलता” आधुनिक CPUs और मोबाइल चिप्स को अधिक कुशल बनाती है, और कैसे ये सिद्धांत आज के डिवाइसेस—लैपटॉप से लेकर क्लाउड सर्वर्स तक—में दिखते हैं।
यदि आप गहराई में जाने से पहले प्रमुख अवधारणाओं का नक्शा चाहते हैं, तो /blog/key-takeaways-and-next-steps पर आगे जाएँ।
प्रारंभिक माइक्रोप्रोसेसर कड़ी सीमाओं में बनाए जाते थे: चिप्स में सर्किटरी के लिए सीमित जगह थी, मेमोरी महंगी थी, और स्टोरेज धीमा था। डिजाइनर सस्ते और “पर्याप्त रूप से तेज़” कंप्यूटर भेजने की कोशिश कर रहे थे, अक्सर छोटे कैश (या बिना कैश के), संयमित क्लॉक स्पीड और सॉफ़्टवेयर की अपेक्षा के मुकाबले बहुत सीमित मुख्य मेमोरी के साथ।
उस समय एक लोकप्रिय विचार यह था कि अगर CPU अधिक शक्तिशाली, उच्च‑स्तरीय निर्देश प्रदान करे—ऐसे निर्देश जो एक साथ कई कदम कर सकें—तो प्रोग्राम तेज़ चलेंगे और लिखने में आसान होंगे। यदि एक निर्देश "कई का काम" कर सकता है, तो सोच यह थी कि कुल मिलाकर कम निर्देशों की ज़रूरत होगी, जिससे समय और मेमोरी बचेगी।
यह कई CISC (complex instruction set computing) डिज़ाइनों के पीछे की अंतर्दृष्टि है: प्रोग्रामरों और कंपाइलरों को भव्य ऑपरेशनों के बड़े टूलबॉक्स से लैस करो।
पकड़ यह थी कि वास्तविक प्रोग्राम (और जो कंपाइलर उन्हें अनुवाद करते थे) लगातार उस जटिलता का लाभ नहीं उठाते थे। कई सबसे जटिल निर्देश शायद ही कभी उपयोग होते थे, जबकि सरल ऑपरेशनों का एक छोटा सेट—डेटा लोड करना, स्टोर करना, जोड़ना, तुलना करना, ब्रांच—बार‑बार दिखाई देता था।
इसी बीच, जटिल निर्देशों के एक विशाल मेन्यू का समर्थन करना CPUs को बनाना कठिन और ऑप्टिमाइज़ करना धीमा कर देता था। जटिलता चिप एरिया और डिजाइन प्रयास कोconsume कर लेती थी जो सामान्य, रोजमर्रा के ऑपरेशनों को तेज़ और पूर्वानुमानशील बनाने में लगाया जा सकता था।
RISC उसी अंतर का उत्तर था: CPU को उन चीज़ों पर केंद्रित करो जो सॉफ़्टवेयर वास्तव में सबसे ज़्यादा करता है, और उन पाथ्स को तेज़ बनाओ—फिर कंपाइलरों को और “ऑर्केस्ट्रेशन” का काम व्यवस्थित रूप से करने दो।
CISC (Complex Instruction Set Computing) को एक ऐसे वर्कशॉप के रूप में सोचें जिसमें कई विशेष, शानदार उपकरण हैं—प्रत्येक एक कदम में बहुत कुछ कर सकता है। एक अकेला "निर्देश" मेमोरी से डेटा लोड कर सकता है, गणना कर सकता है, और परिणाम स्टोर कर सकता है—सब एक साथ।
RISC (Reduced Instruction Set Computing) ऐसे भरोसेमंद उपकरणों का छोटा सेट रखने जैसा है जिन्हें आप लगातार इस्तेमाल करते हैं—और सब कुछ दोहराए जाने वाले चरणों से बनाते हैं। प्रत्येक निर्देश आम तौर पर एक छोटा, स्पष्ट कार्य करता है।
जब निर्देश सरल और अधिक एकरूप होते हैं, तो CPU उन्हें एक साफ़ असेंबली लाइन (एक पाइपलाइन) के साथ निष्पादित कर सकता है। वह असेंबली लाइन डिजाइन करने में आसान है, उच्च क्लॉक स्पीड पर चलाने में आसान है, और व्यस्त रखने में आसान है।
CISC‑शैली के “एक‑काफी‑कुछ करो” निर्देशों के साथ, CPU को अक्सर जटिल निर्देश को डीकोड करके आंतरिक छोटे कदमों में तोड़ना पड़ता है। इससे जटिलता बढ़ सकती है और पाइपलाइन को सुचारू रखने में मुश्किल आ सकती है।
RISC का लक्ष्य पूर्वानुमानशील निर्देश समय है—कई निर्देश लगभग समान समय लेते हैं। पूर्वानुमानशीलता CPU को कार्य शेड्यूल करने में मदद करती है और कंपाइलरों को ऐसा कोड जेनरेट करने में मदद करती है जो पाइपलाइन को भरा रखे बजाय इसके कि वह स्टॉल करे।
RISC आमतौर पर एक ही काम के लिए अधिक निर्देशों की जरूरत होती है। इसका मतलब हो सकता है:
लेकिन यह तब भी अच्छा सौदा हो सकता है यदि प्रत्येक निर्देश तेज़ हो, पाइपलाइन स्मूद रहे, और समग्र डिज़ाइन सरल हो। वास्तविकता में, अच्छी तरह ऑप्टिमाइज़्ड कंपाइलर और अच्छा कैशिंग “अधिक निर्देशों” की बुराई को ऑफसेट कर सकते हैं—और CPU जटिल निर्देशों को सुलझाने में कम समय बिताकर उपयोगी काम करने में अधिक समय लगा सकता है।
बर्कले RISC सिर्फ एक नया निर्देश सेट नहीं था। यह एक शोध दृष्टिकोण था: कागज़ पर जो सुंदर लगता है उससे शुरू मत करो—पहले वास्तविक प्रोग्राम क्या करते हैं यह मापो, फिर CPU को उसी वास्तविकता के चारों ओर ढालो।
वैचारिक स्तर पर, बर्कले टीम का लक्ष्य एक ऐसा CPU कोर था जो इतना सरल हो कि वह बहुत तेज़ और पूर्वानुमानशील तरीके से चले। कई जटिल निर्देश “ट्रिक्स” को हार्डवेयर में भरने के बजाय, वे कंपाइलर पर अधिक काम छोड़ते थे: सीधे निर्देश चुनना, उन्हें अच्छी तरह शेड्यूल करना, और डेटा को संभवतः रजिस्टर में रखना।
इस श्रम‑विभाजन का महत्व था। एक छोटा, साफ़ कोर पाइपलाइन करना अधिक आसान है, उस पर विचार करना आसान है, और अक्सर प्रति ट्रांज़िस्टर तेज़ होता है। कंपाइलर, पूरे प्रोग्राम को देखकर, ऐसे तरीके से आगे की योजना बना सकता है जो हार्डवेयर ऑन‑द‑फ्लाई आसानी से नहीं कर सकता।
डेविड पैटरसन ने मापन पर ज़ोर दिया क्योंकि कंप्यूटर डिज़ाइन मिथकों से भरा है—ऐसे फीचर्स जो उपयोगी लगते हैं पर वास्तविक कोड में शायद ही दिखते हैं। बर्कले RISC ने बेन्चमार्क्स और वर्कलोड ट्रेसेस का उपयोग कर के हॉट पाथ्स पर ध्यान केंद्रित करने का आग्रह किया: वे लूप्स, फ़ंक्शन कॉल्स और मेमोरी एक्सेस जो रनटाइम का अधिकांश हिस्सा नियंत्रित करते हैं।
यह सीधे "सामान्य केस को तेज़ बनाओ" सिद्धांत से जुड़ा है। यदि अधिकांश निर्देश सरल ऑपरेशंस और लोड्स/स्टोर्स हैं, तो उन बार‑बार आने वाले मामलों को ऑप्टिमाइज़ करना दुर्लभ, जटिल निर्देशों को तेज़ करने से अधिक भुगतान कर देता है।
टिकाऊ सबक यह है कि RISC एक आर्किटेक्चर और एक माइंडसेट दोनों था: जो अक्सर होता है उसे सरल बनाओ, डेटा से सत्यापित करो, और हार्डवेयर और सॉफ़्टवेयर को एक एकल सिस्टम मानकर ट्यून करो।
हार्डवेयर–सॉफ़्टवेयर को‑डिज़ाइन यह विचार है कि आप CPU को अलग से डिजाइन नहीं करते। आप चिप और कंपाइलर (और कभी‑कभी ऑपरेटिंग सिस्टम) को एक साथ ध्यान में रखकर डिजाइन करते हैं, ताकि वास्तविक प्रोग्राम तेज़ और कुशलता से चलें—केवल सिंथेटिक "बेस्ट‑केस" निर्देश अनुक्रम नहीं।
को‑डिज़ाइन एक इंजीनियरिंग लूप की तरह काम करता है:
ISA विकल्प: निर्देश सेट आर्किटेक्चर (ISA) यह तय करता है कि CPU किसे आसानी से व्यक्त कर सकता है (उदाहरण के लिए, "लोड/स्टोर" मेमोरी एक्सेस, कई रजिस्टर, सरल एड्रेसिंग मोड)।
कंपाइलर रणनीतियाँ: कंपाइलर अनुकूलित करता है—हॉट वेरिएबल्स को रजिस्टर में रखना, स्टॉल से बचने के लिए निर्देशों को पुनर्व्यवस्थित करना, और कॉलिंग कन्वेंशंस चुनना जो ओवरहेड कम करें।
वर्कलोड परिणाम: आप वास्तविक प्रोग्राम्स (कंपाइलर, डेटाबेस, ग्राफिक्स, OS कोड) को मापते हैं और देखते हैं कि समय और ऊर्जा कहाँ जाती है।
अगला डिज़ाइन: आप उन मापों के आधार पर ISA और माइक्रोआर्किटेक्चर (पाइपलाइन की गहराई, रजिस्टर की संख्या, कैश साइज) को समायोजित करते हैं।
यहाँ एक छोटा‑सा लूप (C) है जो इस संबंध को उजागर करता है:
for (int i = 0; i < n; i++)
sum += a[i];
RISC‑स्टाइल ISA पर, कंपाइलर आम तौर पर sum और i को रजिस्टर में रखता है, a[i] के लिए सरल load निर्देशों का उपयोग करता है, और जब तक कोई लोड फ्लाइट में है तब CPU को व्यस्त रखने के लिए instruction scheduling करता है।
यदि एक चिप जटिल निर्देश या विशेष हार्डवेयर जोड़ती है जिसे कंपाइलर शायद ही उपयोग करे, तो वह एरिया फिर भी पावर और डिजाइन प्रयास खपत करता है। इस बीच, वे "बोरिंग" चीज़ें जिन पर कंपाइलर निर्भर करते हैं—पर्याप्त रजिस्टर, पूर्वानुमानशील पाइपलाइन्स, कुशल कॉलिंग कन्वेंशंस—कम अनुदानित रह सकती हैं।
पैटरसन की RISC सोच ने सिलिकॉन को वहां खर्च करने पर ज़ोर दिया जहाँ वास्तविक सॉफ़्टवेयर वाकई लाभ उठा सकता है।
एक प्रमुख RISC विचार CPU की "असेंबली लाइन" को व्यस्त रखने को आसान बनाना था। वह असेंबली लाइन पाइपलाइन है: एक निर्देश को पूरी तरह खत्म करने से पहले अगला शुरू करने के बजाय, प्रोसेसर काम को स्टेजेस (fetch, decode, execute, write‑back) में बाँटता है और उन्हें ओवरलैप करता है। जब सब कुछ सुचारू चलता है, आप लगभग एक निर्देश प्रति चक्र पूरा करते हैं—जैसे कि कई स्टेशनों वाले फैक्टरी में कारें आगे बढ़ रही हों।
पाइपलाइन्स सबसे अच्छा तब काम करते हैं जब लाइन पर हर आइटम एक जैसा हो। RISC निर्देश अपेक्षाकृत एकरूप और पूर्वानुमानशील (अक्सर फिक्स्ड‑लेंज, सरल एड्रेसिंग) डिज़ाइन किए गए थे। इससे "विशेष मामलों" की संख्या घटती है जहाँ किसी निर्देश को अतिरिक्त समय या असामान्य संसाधनों की ज़रूरत होती है।
वास्तविक प्रोग्राम पूरी तरह स्मूद नहीं होते। कभी‑कभी एक निर्देश को पिछले वाले के परिणाम पर निर्भरता होती है (आप किसी मान का उपयोग उससे पहले नहीं कर सकते जब तक वह तैयार न हो)। कभी‑कभी CPU को मेमोरी से डेटा आने का इंतज़ार करना पड़ता है, या उसे अभी तक पता नहीं है कि ब्रांच किस दिशा लेगा।
ये स्थितियाँ स्टॉल्स पैदा करती हैं—छोटे विराम जहाँ पाइपलाइन का भाग निष्क्रिय बैठा रहता है। सहज ज्ञान यह है: स्टॉल्स तब होते हैं जब अगला स्टेज उपयोगी काम नहीं कर सकता क्योंकि उसे आवश्यक चीज़ अभी नहीं मिली है।
यही वह जगह है जहाँ हार्डवेयर–सॉफ़्टवेयर को‑डिज़ाइन स्पष्ट रूप से सामने आता है। यदि हार्डवेयर पूर्वानुमानशील है, तो कंपाइलर मदद कर सकता है—निर्देशों के क्रम को (प्रोग्राम अर्थ न बदलते हुए) पुनर्व्यवस्थित करके "गैप्स" भर सकता है। उदाहरण के लिए, किसी मान के उत्पादन की प्रतीक्षा करते समय कंपाइलर एक स्वतंत्र निर्देश शेड्यूल कर सकता है जो उस मान पर निर्भर न हो।
लाभ साझा ज़िम्मेदारी है: CPU सामान्य केस में सरल और तेज़ रहता है, जबकि कंपाइलर अधिक योजना करता है। मिलकर वे स्टॉल्स घटाते हैं और थ्रूपुट बढ़ाते हैं—अक्सर वास्तविक प्रदर्शन ऐसा बढ़ाते हुए बिना ज्यादा जटिल ISA की ज़रूरत के।
एक CPU कुछ साइकलों में सरल ऑपरेशंस निष्पादित कर सकता है, लेकिन मुख्य मेमोरी (DRAM) से डेटा लाना सैकड़ों साइकिल ले सकता है। यह अंतर इसलिए है क्योंकि DRAM भौतिक रूप से दूर है, क्षमता और लागत के लिए ऑप्टिमाइज़्ड है, और लेटेंसी (एक रिक्वेस्ट में लगने वाला समय) और बैंडविड्थ (एक सेकंड में कितने बाइट्स मूव कर सकते हैं) दोनों से सीमित है।
जैसे‑जैसे CPUs तेज़ हुए, मेमोरी उसी दर से पीछे नहीं रही—यह बढ़ता हुआ असंतुलन अक्सर "मेमोरी वॉल" कहा जाता है।
कैशेस छोटे, तेज़ मेमोरियाँ हैं जो CPU के निकट रखी जाती हैं ताकि हर एक्सेस पर DRAM टैक्स न देना पड़े। वे इसलिए काम करती हैं क्योंकि वास्तविक प्रोग्राम्स में लोकैलिटी होती है:
आधुनिक चिप्स कैशेस (L1, L2, L3) को स्टैक करते हैं, यह प्रयास करते हुए कि "वर्किंग सेट" कोर के पास रहे।
यहाँ हार्डवेयर–सॉफ़्टवेयर को‑डिज़ाइन अपना लाभ देता है। ISA और कंपाइलर मिलकर निर्धारण करते हैं कि कोई प्रोग्राम कितना कैश‑प्रेशर बनाएगा।
दैनिक शब्दों में, मेमोरी वॉल का मतलब है कि उच्च क्लॉक‑स्पीड वाला CPU भी सुस्त महसूस कर सकता है: बड़ी ऐप खोलना, डेटाबेस क्वेरी चलाना, फीड स्क्रॉल करना, या बड़ा डेटा प्रोसेस करना अक्सर कैश मिसेस और मेमोरी बैंडविड्थ पर बोतल‑गला बनते हैं—सिर्फ़ कच्ची अंकगणितीय गति पर नहीं।
लंबे समय तक CPU चर्चा ऐसी लगी कि कौन‑सी चिप किसी टास्क को सबसे तेज़ी से खत्म करती है। लेकिन वास्तविक कंप्यूटर भौतिक सीमाओं के अंदर रहते हैं—बैटरी क्षमता, गर्मी, फैन शोर, और बिजली बिल।
इसलिए प्रदर्शन‑प्रति‑वाट एक मुख्य मीट्रिक बन गया: आप जो उपयोगी काम ऊर्जा खर्च पर करते हैं।
इसे शक्ति‑कुशलता के रूप में सोचें, न कि पीक ताकत के रूप में। दो प्रोसेसर रोजमर्रा के उपयोग में समान महसूस कर सकते हैं, पर एक कम पावर लेते हुए वही काम कर सकता है, जिससे बैटरी जीवन बेहतर होता है और डेटा‑सेंटर में कूलिंग/पावर लागत घटती है।
लैपटॉप और फ़ोनों में यह सीधे बैटरी जीवन और आराम को प्रभावित करता है। डेटा‑सेंटर्स में, यह हजारों मशीनों को पावर और कूल करने की लागत को प्रभावित करता है, और यह भी कि आप सर्वर्स को कितनी घनत्व में पैक कर सकते हैं बिना ओवरहीटिंग के।
RISC सोच CPU डिज़ाइन को हार्डवेयर में कम चीज़ें करने और अधिक पूर्वानुमानशील बनाने की ओर ढकेलती है। एक सरल कोर कई कारणों से ऊर्जा घटा सकता है:
मकसद यह नहीं कि "सरल हमेशा बेहतर है"। बल्कि यह है कि जटिलता की एक ऊर्जा लागत होती है, और एक अच्छी‑चुनी गई ISA और माइक्रोआर्किटेक्चर थोड़ा कुशलता का व्यापार करके बहुत ऊर्जा‑लाभ दे सकती है।
फ़ोन बैटरी और गर्मी के बारे में सोचते हैं; सर्वर पावर‑डिलीवरी और कूलिंग के बारे में। विभिन्न वातावरण, वही सबक: सबसे तेज़ चिप हमेशा सर्वोत्तम कंप्यूटर नहीं होती। विजेता अक्सर वे डिज़ाइन होते हैं जो स्थिर थ्रूपुट देते हुए ऊर्जा‑उपयोग को नियंत्रित कर सकें।
RISC को अक्सर सारांशित किया जाता है कि "सरल निर्देश जीतते हैं", पर अधिक टिकाऊ पाठ महीन है: निर्देश सेट मायने रखता है, फिर भी कई वास्तविक‑दुनिया लाभ इस बात से आए कि चिप्स कैसे बनाए गए—not सिर्फ ISA की कागज़ पर दिखने वाली परिभाषा से।
प्रारंभिक RISC तर्कों ने संकेत दिया कि एक साफ़, छोटा ISA अपने आप कंप्यूटरों को तेज़ बना देगा। व्यवहार में, बड़े स्पीडअप अक्सर उन इम्प्लीमेंटेशन विकल्पों से आये जो RISC ने आसान बनाए: सरल डीकोडिंग, गहरी पाइपलाइनिंग, ऊँचे क्लॉक्स, और कंपाइलर जो काम को पूर्वानुमानित तरीके से शेड्यूल कर सके।
इसीलिए दो CPUs जिनके ISA अलग हैं, उनके प्रदर्शन में आश्चर्यजनक रूप से पास‑पास आ सकते हैं यदि उनकी माइक्रोआर्किटेक्चर, कैश साइज, ब्रांच‑प्रेडिक्शन और मैन्युफैक्चरिंग प्रोसेस अलग‑अलग हों। ISA नियम सेट करता है; माइक्रोआर्किटेक्चर गेम खेलता है।
पैटरसन‑युग का एक प्रमुख बदलाव था डेटा से डिजाइन करना, धारणाओं से नहीं। जिन निर्देशों को उपयोगी लगते थे उनके बजाय, टीमें जो प्रोग्राम वास्तव में करती थीं उसे मापतीं और सामान्य केस को ऑप्टिमाइज़ करती थीं।
यह मानसिकता अक्सर "फ़ीचर‑ड्रिवन" डिज़ाइन को पीछे छोड़ देती—जहाँ जटिलता लाभ से तेज़ी से बढ़ती है। यह व्यापार‑ऑफ्स को भी स्पष्ट बनाती है: एक ऐसा निर्देश जो कुछ लाइनों को बचाता है वह अतिरिक्त चक्र, पावर, या चिप एरिया का खर्च कर सकता है—और वे लागतें हर जगह दिखाई देती हैं।
RISC सोच ने केवल "RISC चिप्स" को आकार नहीं दिया। समय के साथ, कई CISC CPUs ने RISC‑सदृश आंतरिक तकनीकें अपनाईं (उदाहरण के लिए, जटिल निर्देशों को आंतरिक रूप से सरल ऑपरेशनों में तोड़ना) जबकि उनकी अनुकूलता‑युक्त ISA बनी रही।
अत: परिणाम "RISC ने CISC हराया" नहीं था। यह उन डिज़ाइनों की ओर विकास था जो मापन, पूर्वानुमानशीलता, और कड़ा हार्डवेयर–सॉफ्टवेयर समन्वय महत्व देते हैं—चाहे ISA पर कोई लोगो कुछ भी हो।
RISC प्रयोगशाला तक ही सीमित नहीं रहा। प्रारंभिक शोध से आधुनिक प्रैक्टिस तक का एक स्पष्ट धागा MIPS से RISC‑V तक जाता है—दो ISA जिनोंने सरलता और स्पष्टता को फीचर बनाया, न कि बाधा।
MIPS को अक्सर एक शिक्षण ISA के रूप में याद किया जाता है, और कारण स्पष्ट है: नियम समझाने में आसान हैं, निर्देश फॉर्मैट सुसंगत हैं, और मूल लोड/स्टोर मॉडल कंपाइलर को रास्ता देता है।
उस स्पष्टता का सिर्फ अकादमिक ही नहीं, व्यावहारिक फायदा भी हुआ। MIPS प्रोसेसर वर्षों तक असली उत्पादों में भेजे गए (वर्कस्टेशन्स से लेकर एम्बेडेड सिस्टम तक), आंशिक रूप से इसलिए क्योंकि एक सरलीकृत ISA तेज़ पाइपलाइन्स, पूर्वानुमानशील कंपाइलर और कुशल टूलचेन बनाना आसान बनाता है। जब हार्डवेयर बिहेवियर नियमित होता है, तो सॉफ़्टवेयर उसके आसपास योजना बना सकता है।
RISC‑V ने RISC सोच में नई दिलचस्पी पैदा की क्योंकि उसने वह कदम उठाया जो MIPS ने नहीं किया: यह एक खुला ISA है। इसका मतलब निकास‑प्रेरणाएँ बदल जाती हैं। विश्वविद्यालय, स्टार्टअप और बड़ी कंपनियाँ प्रयोग कर सकती हैं, सिलिकॉन शिप कर सकती हैं, और टूलिंग साझा कर सकती हैं बिना ISA तक पहुँच के लिए जटिल समझौतों के।
को‑डिज़ाइन के लिए यह openness मायने रखती है क्योंकि "सॉफ़्टवेयर पक्ष" (कंपाइलर, OS, रनटाइम) सार्वजनिक रूप से हार्डवेयर के साथ विकसित हो सकता है, कम कृत्रिम बाधाओं के साथ।
एक और कारण कि RISC‑V को को‑डिज़ाइन के साथ अच्छा जोड़ा जाता है वह इसका मॉड्युलर दृष्टिकोण है। आप एक छोटे बेस ISA से शुरू करते हैं, फिर विशिष्ट जरूरतों के लिए एक्सटेंशन्स जोड़ते हैं—जैसे वेक्टर मैथ, एम्बेडेड प्रतिबंध, या सुरक्षा फीचर्स।
यह एक स्वस्थ ट्रेड‑ऑफ को प्रोत्साहित करता है: हर संभव फीचर को एक मोनोलिथिक डिज़ाइन में भरने के बजाय, टीमें हार्डवेयर फीचर्स को उस सॉफ़्टवेयर के अनुरूप कर सकती हैं जो वे वास्तव में चलाती हैं।
यदि आप गहरा परिचय चाहते हैं, तो देखें /blog/what-is-risc-v।
को‑डिज़ाइन RISC युग का ऐतिहासिक नोट नहीं है—यह आधुनिक कंप्यूटिंग को तेज़ और अधिक कुशल बनाए रखने का तरीका है। प्रमुख विचार अभी भी पैटरसन‑शैली का है: आप केवल हार्डवेयर से या केवल सॉफ़्टवेयर से "जीत" नहीं सकते। जीत तब होती है जब दोनों एक दूसरे की ताकत और सीमाओं के अनुरूप हों।
स्मार्टफोन और कई एम्बेडेड डिवाइस RISC सिद्धांतों पर भारी रूप से निर्भर करते हैं (अक्सर ARM‑आधारित): सरल निर्देश, पूर्वानुमानशील निष्पादन, और ऊर्जा उपयोग पर जोर।
यह पूर्वानुमानशीलता कंपाइलरों को प्रभावी कोड जेनरेट करने में मदद करती है और डिज़ाइनरों को ऐसे कोर बनाने में मदद करती है जो स्क्रॉल करते समय कम ऊर्जा घूँट लेते हैं, पर कैमरा पाइपलाइन या गेम के लिए तेजी से बर्स्ट कर सकते हैं।
लैपटॉप और सर्वर भी धीरे‑धीरे वही लक्ष्य अपनाते हैं—विशेषकर प्रदर्शन‑प्रति‑वाट के मामले में। भले ही ISA पारंपरिक रूप से “RISC” न हो, कई आंतरिक डिज़ाइन विकल्प RISC‑सदृश कुशलता की ओर लक्ष्य करते हैं: गहरी पाइपलाइनिंग, चौड़ी निष्पादन इकाइयाँ, और आक्रामक पावर प्रबंधन जो वास्तविक सॉफ़्टवेयर बिहेवियर के अनुरूप ट्यून किए जाते हैं।
GPUs, AI एक्सेलेरेटर्स (TPUs/NPUs), और मीडिया इंजन को‑डिज़ाइन का व्यावहारिक रूप हैं: सभी कार्य को सामान्य‑उद्देश्य CPU से होकर नहीं गुजारने के बजाय, प्लेटफ़ॉर्म ऐसे हार्डवेयर प्रदान करता है जो सामान्य कैलकुलेशन पैटर्न से मेल खाता है।
इसे "सिर्फ़ एक्स्ट्रा हार्डवेयर" नहीं बोलने का कारण यह है कि आसपास का सॉफ़्टवेयर स्टैक भी अनिवार्य है:
यदि सॉफ़्टवेयर एक्सेलेरेटर को निशाना नहीं बनाती, तो सैद्धांतिक गति सैद्धांतिक ही रहती है।
समान विनिर्देशों वाले दो प्लेटफ़ॉर्म अलग‑अलग महसूस कर सकते हैं क्योंकि "वास्तविक उत्पाद" में कंपाइलर, लाइब्रेरी और फ्रेमवर्क शामिल होते हैं। एक अच्छी‑ऑप्टिमाइज़्ड मैथ लाइब्रेरी (BLAS), एक अच्छा JIT, या एक स्मार्ट कंपाइलर बिना चिप बदले बड़े लाभ दे सकते हैं।
इसलिए आधुनिक CPU डिज़ाइन अक्सर बेन्चमार्क‑ड्रिवन होता है: हार्डवेयर टीमें देखती हैं कि कंपाइलर और वर्कलोड वास्तव में क्या करते हैं, फिर फीचर्स (कैशेस, ब्रांच‑प्रेडिक्शन, वेक्टर निर्देश, प्रीफेचिंग) समायोजित करती हैं ताकि सामान्य केस तेज़ हो सके।
जब आप किसी प्लेटफ़ॉर्म (फ़ोन, लैपटॉप, सर्वर, या एम्बेडेड बोर्ड) का मूल्यांकन करें, तो को‑डिज़ाइन संकेतों के लिए देखें:
आधुनिक कंप्यूटिंग प्रगति केवल एक "तेज़ CPU" के बारे में कम और उस पूरे हार्डवेयर‑प्लस‑सॉफ़्टवेयर सिस्टम के बारे में अधिक है जिसे वास्तविक वर्कलोड के चारों ओर मापा और डिज़ाइन किया गया है।
RISC सोच और पैटरसन का व्यापक संदेश कुछ टिकाऊ सबकों में समेटा जा सकता है: जो तेज़ होना चाहिए उसे सरल बनाओ, जो वास्तव में होता है उसे मापो, और हार्डवेयर और सॉफ़्टवेयर को एक ही सिस्टम मानकर ट्यून करो—क्योंकि उपयोगकर्ता पूरे सिस्टम का अनुभव करते हैं, न कि घटकों का।
पहला, सरलता एक रणनीति है, न कि सिर्फ़ सौंदर्यबोध। एक साफ़ ISA और पूर्वानुमानशील निष्पादन कंपाइलरों के लिए अच्छा कोड जेनरेट करना और CPU के लिए उस कोड को कुशलता से चलाना आसान बनाते हैं।
दूसरा, मापन धारणाओं से बेहतर है। प्रतिनिधि वर्कलोड के साथ बेन्चमार्क करो, प्रोफाइलिंग डेटा इकट्ठा करो, और वास्तविक बॉटलनेक्स को डिज़ाइन निर्णयों को निर्देशित करने दो—चाहे आप कंपाइलर ऑप्टिमाइज़ेशन ट्यून कर रहे हों, CPU SKU चुन रहे हों, या किसी क्रिटिकल हॉट पाथ को फिर से डिज़ाइन कर रहे हों।
तीसरा, को‑डिज़ाइन वह जगह है जहाँ लाभ जमा होते हैं। पाइपलाइन‑फ्रेंडली कोड, कैश‑अवेयर डेटा स्ट्रक्चर, और वास्तविक प्रदर्शन‑प्रति‑वाट लक्ष्य अक्सर सांकेतिक पीक थ्योरिटिकल थ्रूपुट के पीछे भागने की तुलना में अधिक व्यावहारिक गति देतें हैं।
यदि आप कोई प्लेटफ़ॉर्म चुन रहे हैं (x86, ARM, या RISC‑V आधारित सिस्टम), तो उसे वैसे ही मूल्यांकन करें जैसे आपके उपयोगकर्ता करेंगे:
यदि आपका काम इन मापों को शिप्ड सॉफ़्टवेयर में बदलना है, तो बिल्ड‑मेजर‑लूप छोटा करना मददगार हो सकता है। उदाहरण के लिए, टीमें Koder.ai का उपयोग करके चैट‑ड्राइवेन वर्कफ़्लो (वेब, बैकएंड, मोबाइल) के ज़रिये वास्तविक एप्लिकेशन प्रोटोटाइप और विकसित करती हैं, और हर परिवर्तन के बाद वही एंड‑टू‑एंड बेन्चमार्क फिर चलाती हैं। प्लानिंग मोड, स्नैपशॉट्स, और रोलबैक जैसी सुविधाएँ वही "मापो, फिर डिज़ाइन करो" अनुशासन समर्थन करती हैं जिसे पैटरसन ने प्रोत्साहित किया—बस आधुनिक प्रोडक्ट डेवलपमेंट पर लागू।
गहराई से पढ़ने के लिए परफॉर्मेंस‑प्रति‑वाट की मूल बातें देखें /blog/performance-per-watt-basics। यदि आप वातावरणों की तुलना कर रहे हैं और लागत/प्रदर्शन ट्रेड‑ऑफ का सरल अनुमान चाहते हैं, तो /pricing सहायक हो सकता है।
टिकाऊ निष्कर्ष: सरलता, मापन और को‑डिज़ाइन के विचार आज भी लाभ दे रहे हैं, भले ही कार्यान्वयन MIPS‑युग की पाइपलाइनों से लेकर आधुनिक हेटेरोजीनियस कोर्स और RISC‑V जैसे नए ISAs तक विकसित हो गए हों।
RISC (Reduced Instruction Set Computing) छोटे, सरल और नियमित निर्देशों पर ज़ोर देता है जो पाइपलाइन और ऑप्टिमाइज़ेशन के लिए आसान होते हैं। लक्ष्य "कम क्षमता" नहीं है, बल्कि उन ऑपरेशनों पर अधिक पूर्वानुमानशील और कुशल निष्पादन हासिल करना है जिन्हें वास्तविक प्रोग्राम सबसे ज़्यादा इस्तेमाल करते हैं (लोड/स्टोर, अंकगणित, ब्रांच)।
CISC कई जटिल और विशेष निर्देशों का एक बड़ा सेट देता है, कभी‑कभी एक ही निर्देश में कई चरण बँधे होते हैं। RISC साधारण बिल्डिंग ब्लॉक्स (अक्सर लोड/स्टोर + ALU ऑप्स) का इस्तेमाल करता है और उन ब्लॉक्स को प्रभावी रूप से जोड़ने के लिए कंपाइलरों पर ज़्यादा निर्भर करता है। आधुनिक CPUs में यह अंतर धुंधला हो गया है क्योंकि कई CISC चिप्स जटिल निर्देशों को आंतरिक रूप से सरल ऑपरेशनों में बदल देते हैं।
सरल, एकरूप निर्देश CPU की पाइपलाइन (निर्देश निष्पादन के लिए "असेंबली लाइन") को सुचारू रखना आसान बनाते हैं। इससे थ्रूपुट बेहतर होता है (लगभग एक निर्देश प्रति चक्र) और विशेष मामलों को हैंडल करने में लगने वाला अतिरिक्त समय घटता है—जो प्रदर्शन और ऊर्जा दोनों के लिए फायदेमंद हो सकता है।
एक पूर्वानुमानशील ISA और निष्पादन मॉडल कंपाइलरों को भरोसेमंद रूप से अनुमति देते हैं कि वे:
इससे पाइपलाइन बुलबुले और बेकार काम घटते हैं, और बिना जटिल हार्डवेयर जोड़ने के वास्तविक प्रदर्शन में सुधार होता है।
हार्डवेयर–सॉफ्टवेयर को‑डिज़ाइन एक आवर्तक लूप है जहाँ ISA विकल्प, कंपाइलर रणनीतियाँ और मापी गई वर्कलोड परिणाम एक दूसरे को सूचित करते हैं। CPU को अलग से डिजाइन करने के बजाय, टीमें हार्डवेयर, टूलचेन और कभी‑कभी OS/runtime को साथ‑साथ ट्यून करती हैं ताकि वास्तविक प्रोग्राम तेज़ और कुशलता से चलें।
पाइपलाइन तब रुकती है जब वह अगले काम के लिए आवश्यक कुछ का इंतज़ार कर रही होती है:
RISC‑शैली की पूर्वानुमानशीलता हार्डवेयर और कंपाइलरों दोनों को इन रुकावटों की आवृत्ति और लागत कम करने में मदद करती है।
“मेमोरी वॉल” तेज़ CPU निष्पादन और धीमी मुख्य‑मेमोरी (DRAM) एक्सेस के बीच बढ़ते अंतर को दर्शाता है। कैशेस (L1/L2/L3) स्थानीयता (टेम्पोरल और स्पेशियल) का फायदा उठाकर इसे कम करते हैं, लेकिन कैश मिसेस अक्सर रनटाइम का प्रभुत्व कर लेते हैं—जिससे बहुत तेज़ कोर पर भी प्रोग्राम मेमोरी‑बाउंड महसूस हो सकते हैं।
यह एक कुशलता का मीट्रिक है: ऊर्जा की एक इकाई में आप कितना उपयोगी काम करवा रहे हैं। व्यवहार में इसका असर बैटरी लाइफ, ताप, फैन शोर और डेटा‑सेंटर के पावर/कूलिंग खर्च पर पड़ता है। RISC‑प्रेरित डिज़ाइन अक्सर पूर्वानुमानशील निष्पादन और कम बेकार स्विचिंग की ओर झुकते हैं, जो प्रदर्शन‑प्रति‑वाट को बेहतर बना सकता है।
कई CISC डिज़ाइनों ने आंतरिक तौर पर RISC‑सदृश तकनीकें अपनाईं (पाइपलाइनिंग, सरल माइक्रो‑ऑप्स, कैश/ब्रांच‑प्रेडिक्शन) जबकि अपना लेगेसी ISA बनाए रखा। लंबी अवधि में जीत वह मानसिकता रही: असली वर्कलोड को मापो, सामान्य केस को ऑप्टिमाइज़ करो, और हार्डवेयर को कंपाइलर/सॉफ्टवेयर बिहेवियर के अनुरूप बनाओ—ISA के लोगो से परे।
RISC‑V एक खुला ISA है जिसका बेस छोटा और मॉड्यूलर है—इससे यह को‑डिज़ाइन के अनुकूल बनता है: टीमें हार्डवेयर फीचर्स को विशिष्ट सॉफ़्टवेयर जरूरतों के साथ मेल कर सकती हैं और टूलचेन सार्वजनिक रूप से विकसित कर सकती हैं। यह "सादा कोर + मजबूत टूल्स + मापन" वाले दृष्टिकोण का आधुनिक जारीवापी रूप है। अधिक के लिए देखें /blog/what-is-risc-v।