21 सित॰ 2025·8 मिनट
निम्न विलंबता के लिए Disruptor पैटर्न: पूर्वानुमानित रीयल‑टाइम डिज़ाइन
न्यूनतम विलंबता के लिए Disruptor पैटर्न सीखें और कतारें, मेमोरी और आर्किटेक्चर विकल्पों से कैसे पूर्वानुमानित रीयल‑टाइम प्रतिक्रिया समय डिजाइन करें वह जानें।
न्यूनतम विलंबता के लिए Disruptor पैटर्न सीखें और कतारें, मेमोरी और आर्किटेक्चर विकल्पों से कैसे पूर्वानुमानित रीयल‑टाइम प्रतिक्रिया समय डिजाइन करें वह जानें।
स्पीड के दो पहलू होते हैं: थ्रूपुट और लेटेंसी। थ्रूपुट वह है जितना काम आप प्रति सेकंड खत्म करते हैं (रिक्वेस्ट, संदेश, फ्रेम)। लेटेंसी वह है कि एक एकल कार्य शुरू से खत्म होने तक कितना समय लेता है।
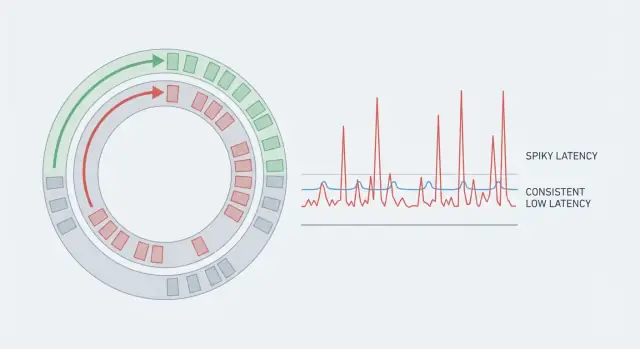
एक सिस्टम का थ्रूपुट बढ़िया हो सकता है और फिर भी धीमा महसूस करे अगर कुछ रिक्वेस्ट अन्य से बहुत लंबे समय ले लें। इसलिए औसत अक्सर भ्रामक होता है। यदि 99 क्रियाएँ 5 ms लेती हैं और एक क्रिया 80 ms, तो औसत ठीक दिखेगा, पर जिसने वह 80 ms पाइ वह स्टटर महसूस करेगा। रीयल‑टाइम सिस्टम्स में वही दुर्लभ स्पाइक्स पूरी कहानी होते हैं क्योंकि वे लय तोड़ देते हैं।
पूर्वानुमानित लेटेंसी का मतलब है कि आप सिर्फ कम औसत का लक्ष्य नहीं रखते। आप सुसंगतता चाहते हैं, ताकि अधिकांश ऑपरेशन एक तंग रेंज के भीतर खत्म हों। इसलिए टीमें tail (p95, p99) देखती हैं। वहीं पर विराम छिपते हैं।
50 ms की एक स्पाइक आवाज़ और वीडियो में मायने रख सकती है (ऑडियो ग्लिट्स), मल्टिप्लेयर गेम्स में (रबर‑बैंडिंग), रीयल‑टाइम ट्रेडिंग में (छूटी कीमतें), औद्योगिक मॉनिटरिंग में (देर से अलार्म), और लाइव डैशबोर्ड में (नंबर्स छलांग, अलर्ट अविश्वसनीय लगते हैं)।
सरल उदाहरण: एक चैट ऐप ज्यादातर समय संदेश जल्दी देता है। लेकिन यदि बैकग्राउंड में एक पॉज़ किसी एक संदेश को 60 ms देर से पहुँचाए, तो टाइपिंग संकेत टिमटिमाते हैं और बातचीत लैगी लगती है जबकि सर्वर औसत पर “तेज़” दिखता है।
अगर आप चाहते हैं कि रीयल‑टाइम असली लगे, तो आपको कम आश्चर्य चाहिए, सिर्फ तेज़ कोड नहीं।
अधिकांश रीयल‑टाइम सिस्टम्स इसलिए धीमे नहीं होते कि CPU संघर्ष कर रहा है। वे इसलिए धीमे महसूस होते हैं क्योंकि काम अपना अधिकतर जीवन प्रतीक्षा में बिताता है: शेड्यूल होने की प्रतीक्षा, कतार में प्रतीक्षा, नेटवर्क की प्रतीक्षा, या स्टोरेज की प्रतीक्षा।
end‑to‑end लेटेंसी वह पूरा समय है जब “कुछ हुआ” से लेकर “यूज़र परिणाम देखता है” तक। भले ही आपका हैंडलर 2 ms में चले, रिक्वेस्ट फिर भी 80 ms ले सकती है अगर यह पाँच जगहों पर रुकती हो।
पथ को तोड़ने का एक उपयोगी तरीका है:
ये इंतज़ारे ऊपर ऊपर जोड़ते हैं। यहाँ‑वहाँ कुछ मिलीसेकंड एक “तेज़” कोड पाथ को धीमे अनुभव में बदल देते हैं।
टेल लेटेंसी वह जगह है जहाँ यूज़र्स शिकायतें शुरू करते हैं। औसत लेटेंसी ठीक दिख सकती है, पर p95 या p99 का अर्थ है सबसे धीमे 5% या 1% रिक्वेस्ट। आउट्लायर्स आमतौर पर दुर्लभ पॉज़ से आते हैं: एक GC साइकिल, होस्ट पर noisy neighbor, थोड़ी लॉक कंटेंशन, एक कैश रिफिल, या एक बर्स्ट जो कतार बनाता है।
ठोस उदाहरण: एक प्राइस अपडेट नेटवर्क पर 5 ms में आता है, एक व्यस्त वर्कर के लिए 10 ms प्रतीक्षा करता है, अन्य इवेंट्स के पीछे 15 ms बैठता है, फिर डेटाबेस स्टाल के कारण 30 ms रुक जाता है। आपका कोड अभी भी 2 ms चला, पर यूज़र ने 62 ms इंतज़ार किया। लक्ष्य यह है कि हर स्टेप पूर्वानुमानित हो, सिर्फ गणना तेज़ न हो।
एक तेज़ एल्गोरिथ्म तब भी धीमा महसूस करवा सकता है जब प्रति रिक्वेस्ट समय ऊँचा‑नीचा होता रहे। यूज़र्स स्पाइक्स नोटिस करते हैं, औसत नहीं। यह swing जिटर है, और अक्सर ऐसी चीजों से आता है जिन्हें आपका कोड पूरी तरह नियंत्रित नहीं करता।
CPU कैश और मेमोरी व्यवहार छिपे हुए लागतें हैं। यदि हॉट डेटा कैश में नहीं बैठता, तो CPU RAM के इंतज़ार में स्टॉल हो जाता है। ऑब्जेक्ट‑heavy स्ट्रक्चर, बिखरा मेमोरी, और "एक और lookup" बार‑बार कैश मिस में बदल सकते हैं।
मेमोरी अलोकेशन अपनी यादृच्छिकता लाती है। बहुत सारे short‑lived ऑब्जेक्ट्स बनाना heap पर दबाव बढ़ाता है, जो बाद में pauses (garbage collection) के रूप में दिखते हैं या allocator कंटेंशन। GC न होने पर भी बार‑बार अलोकेशन मेमोरी fragment और locality खराब कर सकते हैं।
थ्रेड शेड्यूलिंग भी आम स्रोत है। जब एक थ्रेड deschedule होता है, तो context switch ओवरहेड होता है और आप cache warmth खो देते हैं। एक व्यस्त मशीन पर, आपका “रीयल‑टाइम” थ्रेड unrelated कामों के पीछे प्रतीक्षा कर सकता है।
लॉक कंटेंशन वह जगह है जहाँ पूर्वानुमानित सिस्टम अक्सर टूटते हैं। एक लॉक जो “आमतौर पर फ्री” होता है, convoy में बदल सकता है: थ्रेड्स जागते हैं, लॉक के लिए झगड़ते हैं, और एक दूसरे को फिर से सोने पर भेज देते हैं। काम हो जाता है, पर टेल लेटेंसी फैल जाती है।
I/O प्रतीक्षाएँ अक्सर सब कुछ दबाकर रख देती हैं। एक सिंगल syscall, पूरा नेटवर्क बफर, TLS हैंडशेक, डिस्क फ्लश, या स्लो DNS lookup एक तीखा स्पाइक बना सकते हैं जिसे कोई माइक्रो‑ऑप्टिमाइज़ेशन ठीक नहीं करेगा।
अगर आप जिटर की तलाश कर रहे हैं, तो कैश मिस (आम तौर पर pointer‑heavy संरचनाओं और रैंडम एक्सेस से), बार‑बार अलोकेशन्स, बहुत सारे थ्रेड्स या noisy neighbors से context switches, लॉक कंटेंशन, और किसी भी blocking I/O (नेटवर्क, डिस्क, लॉगिंग, सिंक्रोनस कॉल) की तलाश से शुरू करें।
उदाहरण: एक प्राइस‑टिकर सर्विस माइक्रोसेकंड में अपडेट्स कैलकुलेट कर सकती है, पर एक synchronized logger कॉल या एक contended metrics लॉक कभी‑कभी कई दसों मिलीसेकंड जोड़ सकता है।
Martin Thompson लो‑लेटेंसी इंजीनियरिंग में जाना जाता है यह ध्यान देकर कि सिस्टम दबाव में कैसा व्यवहार करते हैं: सिर्फ औसत तेज़ी नहीं, बल्कि पूर्वानुमानित तेज़ी। LMAX टीम के साथ उन्होंने Disruptor पैटर्न को लोकप्रिय किया, जो इवेंट्स को सिस्टम में छोटे और सुसंगत देरी के साथ आगे बढ़ाने का एक संदर्भ तरीका है।
Disruptor दृष्टिकोण उन चीज़ों का जवाब है जो कई “तेज़” ऐप्स को अनिश्चित बनाती हैं: कंटेंशन और समन्वय। सामान्य कतार अक्सर लॉक या भारी एटॉमिक्स पर निर्भर करती हैं, थ्रेड्स को उठाती‑बिठाती हैं, और जब प्रोड्यूसर और कंज्यूमर साझा संरचनाओं पर लड़ते हैं तब प्रतीक्षा का बर्स्ट बना देती हैं।
कतार के बजाय, Disruptor एक रिंग बफर का उपयोग करता है: एक फिक्स्ड‑साइज़ सर्कुलर एरे जो स्लॉट्स में इवेंट रखते हैं। प्रोड्यूसर अगले स्लॉट का दावा करते हैं, डेटा लिखते हैं, फिर एक सीक्वेंस नंबर प्रकाशित करते हैं। कंज्यूमर उस सीक्वेंस का पालन करके क्रम में पढ़ते हैं। चूँकि बफ़र प्री‑अलोकेटेड होता है, आप बार‑बार अलोकेशन्स से बचते हैं और गैर्बेज कलेक्टर पर दबाव कम करते हैं।
एक प्रमुख विचार single‑writer सिद्धांत है: साझा स्थिति के किसी दिए हिस्से के लिए एक घटक को जिम्मेदार रखें (उदा., रिंग में आगे बढ़ने वाला cursor)। कम राइटर‑सर्गियों का मतलब है कम “अगला कौन?” क्षण।
बैकप्रेशर स्पष्ट होता है। जब कंज्यूमर पीछे रह जाते हैं, तो प्रोड्यूसर अंततः ऐसे स्लॉट पर पहुँचते हैं जो अभी भी उपयोग में है। उस बिंदु पर सिस्टम को इंतज़ार करना होगा, ड्रॉप करना होगा, या धीमा होना होगा, पर यह नियंत्रित और दिखाई देने वाला तरीके से होता है बजाय इस समस्या को एक बढ़ती कतार के अंदर छुपाने के।
Disruptor‑शैली डिज़ाइनों को तेज़ बनाता है यह कोई चालाक माइक्रो‑ऑप्टिमाइज़ेशन नहीं है। यह अनिश्चित विरामों को हटाना है जो सिस्टम के अपने हिस्सों के साथ लड़ने पर होते हैं: अलोकेशन्स, कैश मिस, लॉक कंटेंशन, और हॉट पाथ में मिलाया गया भारी काम।
एक उपयोगी मानसिक मॉडल असेंब्ली लाइन है। इवेंट्स एक फिक्स्ड मार्ग से साफ़ हैंडऑफ के साथ आगे बढ़ते हैं। यह साझा स्थिति को घटाता है और हर स्टेप को सरल और मापनीय रखना आसान बनाता है।
तेज़ सिस्टम्स आश्चर्यजनक अलोकेशन्स से बचते हैं। अगर आप बफ़र्स प्री‑अलोकेट करें और मैसेज ऑब्जेक्ट्स रीयूज़ करें तो आप GC, heap growth, और allocator locks की “कभी‑कभी” स्पाइक्स को घटाते हैं।
यह भी मदद करता है कि मैसेज छोटे और स्थिर हों। जब प्रति‑इवेंट आप जो डेटा छूते हैं वह CPU कैश में फिट हो, तो आप कम मेमोरी इंतज़ार करते हैं।
व्यावहारिक रूप से, सामान्य प्रथाएँ जो सबसे ज़्यादा मायने रखती हैं: इवेंट‑प्रति नया ऑब्जेक्ट बनाने के बजाय ऑब्जेक्ट रीयूज़ करना, इवेंट डेटा कॉम्पैक्ट रखना, साझा स्थिति के लिए single writer पसंद करना, और सावधानी से बैचिंग करना ताकि समन्वय लागत कम बार चुके।
रीयल‑टाइम ऐप्स को अक्सर लॉगिंग, मेट्रिक्स, retries, या DB लिखने जैसे एक्स्ट्रा चीज़ों की जरूरत होती है। Disruptor मानसिकता यह है कि इन्हें कोर लूप से अलग रखें ताकि वे उसे ब्लॉक न कर सकें।
एक लाइव प्राइसिंग फ़ीड में, हॉट पाथ सिर्फ़ एक टिक की वैलिडेशन कर सकता है और अगला प्राइस स्नैपशॉट प्रकाशित कर सकता है। जो कुछ भी स्टॉल कर सकता है (डिस्क, नेटवर्क कॉल, भारी सीरियलाइज़ेशन) उसे एक अलग कंज्यूमर या साइड चैन में ले जाया जाता है, ताकि प्रेडिक्टेबल पाथ प्रेडिक्टेबल बना रहे।
पूर्वानुमानित लेटेंसी ज्यादातर एक आर्किटेक्चर समस्या है। आपके पास तेज़ कोड हो सकता है और फिर भी स्पाइक्स आ सकते हैं अगर बहुत सारे थ्रेड्स एक ही डेटा पर लड़ते हैं, या संदेश बेवजह नेटवर्क पर उछलते हैं।
शुरू करें यह तय करके कि कितने राइटर्स और रीडर्स एक ही कतार या बफ़र को छूते हैं। एक सिंगल प्रोड्यूसर को स्मूथ रखना आसान होता है क्योंकि यह समन्वय से बचता है। मल्टी‑प्रोड्यूसर सेटअप थ्रूपुट बढ़ा सकते हैं, पर अक्सर कंटेंशन बढ़ाते हैं और वर्स्ट‑केस टाइमिंग को कम पूर्वानुमानित बनाते हैं। यदि आपको कई प्रोड्यूसर्स चाहिए, तो साझा लिखाई को कम करने के लिए ईवेंट्स को की द्वारा शार्ड करें (उदा., userId या instrumentId) ताकि हर शार्ड की अपनी हॉट पाथ हो।
कंज्यूमर पक्ष पर, जब ordering मायने रखती है तो एक सिंगल कंज्यूमर सबसे स्थिर टाइमिंग देता है क्योंकि स्टेट एक थ्रेड पर लोकल रहता है। वर्कर पूल तब मदद करते हैं जब टास्क वाकई स्वतंत्र हों, पर वे शेड्यूलिंग देरी जोड़ते हैं और काम को reorder कर सकते हैं जब तक आप सावधान न हों।
बैचिंग एक और ट्रेडऑफ है। छोटे बैच ओवरहेड घटाते हैं (कम वेकअप, कम कैश मिस), पर बैच भरने के लिए इंतज़ार करना भी प्रतीक्षा जोड़ सकता है। अगर आप रीयल‑टाइम सिस्टम में बैच करते हैं, तो इंतज़ार समय कैप करें (उदा., “अधिकतम 16 इवेंट्स या 200 माइक्रोसेकंड, जो भी पहले आए”)।
सर्विस बॉउंड्रीज़ भी मायने रखती हैं। कड़ी लेटेंसी चाहिए तो इन‑प्रोसेस मैसेजिंग आम तौर पर बेस्ट होती है। स्केलिंग के लिए नेटवर्क हॉप्स लाभकारी हो सकते हैं, पर हर हॉप कतारें, retries, और चर‑व delay जोड़ता है। अगर आपको हॉप चाहिए, तो प्रोटोकॉल सरल रखें और हॉट पाथ में fan‑out से बचें।
एक व्यावहारिक नियम सेट: जहाँ संभव हो प्रति‑शार्ड एक single‑writer पथ रखें, एक हॉट कतार साझा करने के बजाय की द्वारा शार्ड करके स्केल करें, केवल कड़े समय कैप के साथ बैच करें, केवल समानांतर और स्वतंत्र कार्यों के लिए वर्कर पूल जोड़ें, और हर नेटवर्क हॉप को एक संभावित जिटर स्रोत मानें जब तक आपने मापा न हो।
कोड तक पहुंचने से पहले एक लिखित लेटेंसी बजट के साथ शुरू करें। एक लक्ष्य चुनें ("अच्छा" कैसा महसूस होता है) और एक p99 (जिसके नीचे आपको रहना चाहिए)। उस संख्या को इनपुट, वैलिडेशन, मैचिंग, पर्सिस्टेंस, और आउटबाउंड अपडेट्स जैसे चरणों में बाँटें। अगर किसी स्टेज के पास बजट नहीं है, तो उसके पास कोई सीमा नहीं है।
अगला, पूरा डेटा फ्लो बनाएं और हर हैंडऑफ़ को मार्क करें: थ्रेड सीमाएँ, कतारें, नेटवर्क हॉप्स, और स्टोरेज कॉल। हर हैंडऑफ़ वह जगह है जहाँ जिटर छिपता है। जब आप उन्हें देख लेते हैं, तो आप उन्हें घटा सकते हैं।
एक वर्कफ़्लो जो डिज़ाइन को ईमानदार रखता है:
फिर तय करें कि क्या असिंक्रोनस किया जा सकता है बिना यूज़र अनुभव बिगाड़े। एक सरल नियम: जो कुछ भी यूज़र को “अब” दिखाना बदलता है वह क्रिटिकल पाथ पर रहे। बाकी सब बाहर चले जाए।
एनालिटिक्स, ऑडिट लॉग्स, और सेकेंडरी इंडेक्सिंग अक्सर हॉट पाथ से हटाकर सुरक्षित रखे जा सकते हैं। वैलिडेशन, ऑर्डरिंग और अगले स्टेट को उत्पन्न करने के लिए आवश्यक कदम आम तौर पर नहीं हटाए जा सकते।
तेज़ कोड तब भी धीमा महसूस हो सकता है जब रनटाइम या OS आपके काम को गलत समय पर रोक दे। लक्ष्य सिर्फ़ उच्च थ्रूपुट नहीं है। यह सबसे धीमे 1% रिक्वेस्ट में कम आश्चर्य होना है।
गैर्बेज कलेक्टेड रनटाइम्स (JVM, Go, .NET) उत्पादकता के लिए अच्छे हो सकते हैं, पर memory cleanup के समय pauses ला सकते हैं। आधुनिक कलेक्टर्स पहले से बेहतर हैं, फिर भी टेल लेटेंसी तब कूद सकती है जब आप लोड के तहत बहुत सारे शॉर्ट‑लाइव्ड ऑब्जेक्ट्स बनाते हैं। नॉन‑GC भाषाएँ (Rust, C, C++) GC pauses से बचाती हैं, पर लागत मैन्युअल ownership और अलोकेशन अनुशासन में डालती हैं। किसी भी तरह, मेमोरी व्यवहार CPU स्पीड जितना ही मायने रखता है।
व्यावहारिक आदत सरल है: जहाँ allocations होते हैं उन्हें खोजें और उन्हें नीरस बनाएं। ऑब्जेक्ट्स रीयूज़ करें, बफ़र्स प्री‑साइज़ करें, और हॉट‑पाथ डेटा को अस्थायी स्ट्रिंग्स या मैप्स में बदलने से बचें।
थ्रेडिंग विकल्प भी जिटर के रूप में दिखाई देते हैं। हर अतिरिक्त कतार, async हॉप, या थ्रेड पूल हैंडऑफ इंतज़ार जोड़ता है और वैरिएंस बढ़ाता है। कम संख्या में लंबी‑जीवित थ्रेड्स पसंद करें, प्रोड्यूसर‑कंज्यूमर बॉउंडरीज़ स्पष्ट रखें, और हॉट पाथ पर ब्लॉकिंग कॉल से बचें।
कुछ OS और कंटेनर सेटिंग्स अक्सर तय कर देती हैं कि आपकी टेल क्लीन है या स्पाइकी: CPU throttling, shared hosts पर noisy neighbors, और गलत जगह पर की गई लॉगिंग/मेट्रिक्स अचानक स्लोडाउन कर सकती हैं। अगर आप सिर्फ़ एक चीज़ बदलते हैं, तो लेटेंसी स्पाइक्स के दौरान allocation rate और context switches को मापने से शुरू करें।
कई लेटेंसी स्पाइक्स “धीमा कोड” नहीं होते। वे ऐसी प्रतीक्षाएँ होती हैं जिनकी आपने योजना नहीं बनाई: DB लॉक, retry storm, एक cross‑service कॉल जो अटक जाती है, या एक कैश मिस जो पूरा राउंड‑ट्रिप बना देता है।
क्रिटिकल पाथ को छोटा रखें। हर अतिरिक्त हॉप शेड्यूलिंग, सीरियलाइज़ेशन, नेटवर्क कतारों और ब्लॉक होने की और जगहें जोड़ता है। यदि आप एक प्रोसेस और एक डेटा स्टोर से अनुरोध का उत्तर दे सकते हैं, तो पहले वही करें। सेवाओं में विभाजन तभी करें जब हर कॉल वैकल्पिक हो या कड़ी सीमा में बंधी हो।
बाउंडेड प्रतीक्षा तेज़ औसत और पूर्वानुमानित लेटेंसी के बीच अंतर है। रिमोट कॉल्स पर हार्ड टाइमआउट लगाएँ, और जब कोई डिपेंडेंसी unhealthy हो तो जल्दी फेल करें। सर्किट‑ब्रेकर्स सिर्फ सर्वर्स बचाने के लिए नहीं हैं—वे यह सीमित करते हैं कि उपयोगकर्ता कितनी देर तक फँसा रह सकता है।
जब डेटा एक्सेस ब्लॉक करता है, तो पाथ्स को अलग करें। पढ़ने अक्सर इंडेक्स्ड, डेनॉर्मलाइज़्ड, कैश‑फ्रेंडली शेप चाहते हैं। लिखने अक्सर durability और ordering चाहते हैं। इन्हें अलग करने से कंटेंशन हट सकता है और लॉक समय घट सकता है। अगर आपकी consistency जरूरतें अनुमति देती हैं, तो append‑only रिकॉर्ड्स (एक इवेंट लॉग) अक्सर इन‑प्लेस अपडेट्स की तुलना में अधिक पूर्वानुमानित व्यवहार करते हैं जो हॉट‑रो लॉकिंग या बैकग्राउंड मेंटेनेंस ट्रिगर करते हैं।
रीयल‑टाइम ऐप्स के लिए एक सरल नियम: persistence तभी क्रिटिकल पाथ पर हो जब वह सचमुच correctness के लिए आवश्यक हो। अक्सर बेहतर रूप यह है: मेमोरी में अपडेट करें, रिस्पॉन्ड करें, फिर persistence असिंक्रोनस तरीके से करें और रिप्ले मैकेनिज़्म (आउटबॉक्स या write‑ahead log) रखें।
कई रिंग‑बफर पाइपलाइन्स में यह इस तरह होता है: इन‑मेमोरी बफर में प्रकाशित करें, स्टेट अपडेट करें, जवाब दें, फिर एक अलग कंज्यूमर PostgreSQL के लिए बैच राइट्स करे।
एक लाइव कोलैबोरेशन ऐप (या एक छोटा मल्टीप्लेयर गेम) का चित्र बनाइए जो हर 16 ms में अपडेट पुश करता है (लगभग 60 बार प्रति सेकंड)। लक्ष्य “औसतन तेज़” नहीं है। लक्ष्य है “अक्सर 16 ms से नीचे”, भले ही किसी एक यूज़र का कनेक्शन खराब हो।
एक सरल Disruptor‑स्टाइल फ्लो कुछ इस तरह दिखता है: यूज़र इनपुट एक छोटा इवेंट बनता है, वह प्री‑अलोकेटेड रिंग बफर में प्रकाशित होता है, फिर एक फिक्स्ड हैंडलर्स सेट द्वारा क्रम में प्रोसेस होता है (validate -> apply -> prepare outbound messages), और अंत में क्लाइंट्स को ब्रॉडकास्ट किया जाता है।
एज पर बैचिंग मदद कर सकती है। उदाहरण के लिए, प्रति‑क्लाइंट आउटबाउंड राइट्स को प्रति‑टिक बैच करें ताकि नेटवर्क लेयर को कम बार कॉल करें। पर हॉट पाथ के अंदर इस तरह बैच न करें कि आप "थोड़ा और इंतज़ार" करें। इंतज़ार करने से आप टिक मिस करते हैं।
जब कुछ धीमा होता है, तो उसे containment की तरह ट्रीट करें। यदि एक हैंडलर धीमा हो जाता है, तो उसे अपने बफ़र के पीछे अलग कर दें और मुख्य लूप को ब्लॉक करने के बजाय हल्का‑वज़न वर्क आइटम प्रकाशित करें। यदि एक क्लाइंट धीमा है, तो ब्रॉडकास्टर को बैक कर न होने दें; हर क्लाइंट को एक छोटा सेंड कतार दें और पुराने अपडेट्स को ड्रॉप या कोएलेस करें ताकि आप नवीनतम स्टेट रखें। यदि बफ़र की गहराई बढ़ती है, तो एज पर बैकप्रेशर लागू करें (उस टिक के लिए अतिरिक्त इनपुट स्वीकार न करें, या फीचर्स degrade करें)।
आप जानते हैं कि यह काम कर रहा है जब संख्याएँ उबाऊ रहती हैं: बैकलॉग डेप्थ शून्य के करीब रहती है, ड्रॉप/कोएलेस्ड इवेंट्स दुर्लभ और समझ में आने वाले हों, और p99 वास्तविक लोड के दौरान आपके टिक बजट के नीचे रहे।
अधिकांश लेटेंसी स्पाइक्स आत्म‑निर्मित होते हैं। कोड तेज़ हो सकता है, पर सिस्टम फिर भी रुकता है जब वह अन्य थ्रेड्स, OS, या CPU कैश के बाहर किसी चीज़ का इंतज़ार करता है।
कुछ आम गलतियाँ बार‑बार दिखती हैं:
स्पाइक्स घटाने का तेज तरीका है इंतज़ार को दिखाई देने योग्य और बाउंडेड बनाना। धीमे काम को अलग पाथ पर रखें, कतारों को कैप करें, और जब आप फ़ुल हों तो क्या होगा (ड्रॉप, शेड़, या degrade) पहले से तय करें।
पूर्वानुमानित लेटेंसी को एक उत्पाद फीचर की तरह ट्रीट करें, संयोग की तरह नहीं। कोड ट्यून करने से पहले, सुनिश्चित करें कि सिस्टम के स्पष्ट लक्ष्य और गार्डरेल हैं।
एक साधारण परीक्षण: एक बर्स्ट सिम्युलेट करें (नॉर्मल ट्रैफ़िक का 10x, 30 सेकंड के लिए)। अगर p99 फटकर बढ़ जाए, तो पूछें कि इंतज़ार कहाँ हो रहा है: बढ़ती कतारें, एक धीमा कंज्यूमर, GC pause, या साझा संसाधन।
Disruptor पैटर्न को एक लाइब्रेरी विकल्प के रूप में नहीं बल्कि एक कार्यप्रवाह के रूप में ट्रीट करें। एक पतली स्लाइस के साथ पूर्वानुमानित लेटेंसी को साबित करें इससे पहले कि आप फीचर्स जोड़ें।
एक ऐसा यूज़र एक्शन चुनें जिसे तुरंत महसूस होना चाहिए (उदा., “नया प्राइस आता है, UI अपडेट होता है”)। एंड‑टू‑एंड बजट लिखें, फिर दिन‑एक से p50, p95, और p99 मापें।
अक्सर काम करने वाली अनुक्रम:
यदि आप Koder.ai (koder.ai) पर बना रहे हैं, तो पहले Planning Mode में इवेंट फ्लो मैप करना मददगार होता है ताकि कतारें, लॉक और सर्विस बॉउंड्रीज़ आकस्मिक रूप से न उभरें। स्नैपशॉट और रोलबैक भी बार‑बार लेटेंसी प्रयोग चलाने और उन परिवर्तनों को वापस लेने में आसान बनाते हैं जो थ्रूपुट बढ़ाते हैं पर p99 को बिगाड़ देते हैं।
मापो को ईमानदार रखें। एक फिक्स्ड टेस्ट स्क्रिप्ट उपयोग करें, सिस्टम को वार्म‑अप करें, और थ्रूपुट और लेटेंसी दोनों रिकॉर्ड करें। जब लोड के साथ p99 कूदे, तो "कोड ऑप्टिमाइज़ेशन" से पहले GC, noisy neighbors, लॉगिंग बर्स्ट, थ्रेड शेड्यूलिंग, या छिपे ब्लॉकिंग कॉल्स से विराम ढूँढें।
औसत छिपाए हुए विरामों को दिखाता है। अगर अधिकतर क्रियाएँ तेज़ हों पर कुछ ही काफी लंबे हों, तो यूज़र को उन्हीं स्पाइक्स के कारण झटके या “लग” महसूस होता है, खासकर रीयल‑टाइम फ्लो में जहाँ लय मायने रखती है।
पूछे गए मापदंडों में tail latency (जैसे p95/p99) को ट्रैक करें क्योंकि वहीं पर ध्यान देने लायक विराम होते हैं।
थ्रूपुट बताता है कि आप प्रति सेकंड कितना काम पूरा कर रहे हैं। लेटेंसी बताती है कि एक एकक काम शुरू से लेकर खत्म होने तक कितना समय लेता है।
आपके पास उच्च थ्रूपुट हो सकता है और फिर भी कभी‑कभी बहुत लंबे इंतज़ार हों — वही रीयल‑टाइम ऐप्स को धीमा महसूस कराते हैं।
टेल लेटेंसी (p95/p99) सबसे धीमे अनुरोधों को मापती है, न कि सामान्य ones। p99 का अर्थ है कि 1% ऑपरेशन्स उस मान से ज़्यादा समय लेते हैं।
रियल‑टाइम ऐप्स में वही 1% अक्सर नजर आने योग्य जिटर बनकर आता है: ऑडियो पॉप्स, rubber‑banding, इंडिकेटर का टिमटिमाना, या मिस टिक्स।
अधिकांश समय असल में प्रतीक्षा में जाता है, न कि गणना में:
2 ms का हैंडलर भी कुछ जगहों पर प्रतीक्षा करके 60–80 ms end‑to‑end दे सकता है।
सामान्य जिटर स्रोतों में शामिल हैं:
डिबग के लिए, स्पाइक्स को एलोकेशन रेट, context switches और कतार गहराई के साथ सहसम्बद्ध करें।
Disruptor एक ऐसा पैटर्न है जो इवेंट्स को पाइपलाइन में छोटे और सुसंगत देरी के साथ आगे बढ़ाने के लिए उपयोग होता है। यह पारंपरिक साझा कतार के बजाय प्री‑अलोकेटेड रिंग बफर और सीक्वेंस नंबर का उपयोग करता है।
लक्ष्य यह है कि कंटेंशन, एलोकेशन और थ्रेड वेकअप जैसी अनिश्चित विरामों को कम किया जाए—ताकि लेटेंसी "बोरिंग" बनी रहे, सिर्फ औसत पर तेज़ न दिखे।
हॉट लूप में ऑब्जेक्ट्स/बफर्स को प्री‑अलोकेट और रीयूज़ करें। इससे घटता है:
साथ ही इवेंट डेटा कॉम्पैक्ट रखें ताकि CPU हर इवेंट पर कम मेमोरी छुए (बेहतर कैश व्यवहार)।
जहाँ तक संभव हो, प्रति शार्ड एक single‑writer पथ शुरू करें (कम कंटेंशन और समझने में आसान)। स्केलिंग के लिए शार्डिंग कीज (userId/instrumentId) का उपयोग करें बजाय एक ही हॉट कतार को शेयर किए।
वर्कर पूल केवल तभी इस्तेमाल करें जब काम वाकई स्वतंत्र हो; अन्यथा आप थ्रूपुट बढ़ाकर टेल लेटेंसी और डिबग मुश्किल बना सकते हैं।
बैचिंग ओवरहेड घटाती है, पर यह तब हानिकारक हो सकती है जब आप इवेंट्स को भरने के लिए रोकते हैं।
व्यावहारिक नियम है कि बैचिंग को समय और आकार दोनों से सीमा दें (उदा.: “अधिकतम N इवेंट्स या T माइक्रोसेकंड, जिसे भी पहले पहुँचें”) ताकि बैचिंग चुपचाप आपके लेटेंसी बजट को न तोड़े।
पहले लेटेंसी बजट लिखें (टारगेट और p99), फिर इसे स्टेज‑दर‑स्टेज बाँटें। हर हैंडऑफ़ (कतारें, थ्रेड बॉउंडरी, नेटवर्क हॉप, स्टोरेज कॉल) को मैप करें और प्रतीक्षा को मेट्रिक्स से दिखाई देने योग्य बनाएं (कटौती गहराई, प्रति‑स्टेज समय)।
हॉट पाथ से ब्लॉकिंग I/O हटाएँ, बाउंडेड कतारें उपयोग करें, और ओवरलोड व्यवहार (ड्रॉप, शेड़, कोएलेस) पहले से तय करें।