03 अक्टू॰ 2025·8 मिनट
क्लाउड में ऐप्स को भरोसेमंद रूप से चलाने के लिए Docker क्यों महत्वपूर्ण है
जानिए कैसे Docker आपकी एप को लैपटॉप से क्लाउड तक एक जैसा चलाने, डिप्लॉयमेंट सरल करने, पोर्टेबिलिटी बढ़ाने और एनवायरनमेंट समस्याएँ घटाने में मदद करता है।
जानिए कैसे Docker आपकी एप को लैपटॉप से क्लाउड तक एक जैसा चलाने, डिप्लॉयमेंट सरल करने, पोर्टेबिलिटी बढ़ाने और एनवायरनमेंट समस्याएँ घटाने में मदद करता है।
अधिकांश क्लाउड डिप्लॉयमेंट दर्द एक परिचित आश्चर्य से शुरू होता है: ऐप लैपटॉप पर ठीक चलता है, लेकिन क्लाउड सर्वर पर पहुँचते ही फेल हो जाता है। हो सकता है कि सर्वर पर Python या Node का अलग वर्ज़न हो, कोई सिस्टम लाइब्रेरी गायब हो, कोई कॉन्फ़िग फ़ाइल थोड़ी भिन्न हो, या कोई बैकग्राउंड सर्विस न चल रही हो। ये छोटे-छोटे अंतर मिलकर बड़ी समस्याएँ बना लेते हैं, और टीमें वातावरण डिबग करते-करते प्रोडक्ट में सुधार करने की बजाय फंस जाती हैं।
Docker मदद करता है आपकी एप को उस रनटाइम और निर्भरताओं के साथ पैकेज करके जो उसे चलाने के लिए चाहिए। "वर्ज़न X इंस्टॉल करो, फिर लाइब्रेरी Y जोड़ो, फिर यह कॉन्फ़िग सेट करो" जैसी स्टेप-लिस्ट भेजने की बजाय आप एक कंटेनर इमेज भेजते हैं जिसमें ये चीज़ें पहले से मौजूद होती हैं।
उपयोगी मानसिक मॉडल है:
जब आप वही इमेज क्लाउड में चलाते हैं जिसे आपने लोकल पर टेस्ट किया था, तो "लेकिन मेरे सर्वर में अलग है" वाली समस्याएँ नाटकीय रूप से घट जाती हैं।
Docker अलग-अलग भूमिकाओं को अलग कारणों से मदद करता है:
Docker बेहद मददगार है, लेकिन यह अकेला पूरा समाधान नहीं है। आपको अभी भी कॉन्फ़िगरेशन, सीक्रेट्स, डेटा स्टोरेज, नेटवर्किंग, मॉनिटरिंग, और स्केलिंग प्रबंधित करनी होगी। कई टीमों के लिए Docker एक बिल्डिंग ब्लॉक है जो लोकल वर्कफ़्लोज के लिए Docker Compose और प्रोडक्शन में आर्केस्ट्रेशन प्लेटफ़ॉर्म के साथ काम करता है।
Docker को अपने ऐप के लिए शिपिंग कंटेनर समझें: यह डिलीवरी को पूर्वानुमेय बनाता है। पोर्ट (क्लाउड सेटअप और रनटाइम) पर क्या होता है वह अभी भी मायने रखता है—लेकिन जब हर शिपमेंट एक जैसा पैक हो तो काम बहुत आसान हो जाता है।
Docker में बहुत सारी नई शब्दावली लग सकती है, लेकिन मूल विचार सीधा है: अपनी ऐप को इस तरह पैकेज करें कि वह कहीं भी एक जैसा चले।
एक वर्चुअल मशीन एक पूरा गेस्ट ऑपरेटिंग सिस्टम और आपकी ऐप दोनों को बंडल करती है। यह लचीला है, लेकिन चलाने में भारी और शुरू होने में धीमा होता है।
एक कंटेनर आपकी ऐप और उसकी निर्भरताओं को बंडल करता है, पर होस्ट मशीन के OS कर्नेल को साझा करता है बजाय कि पूरा OS भेजने के। इस वजह से कंटेनर हल्के होते हैं, सेकंड्स में स्टार्ट होते हैं, और आप एक ही सर्वर पर अधिक कंटेनर चला सकते हैं।
इमेज: आपकी ऐप के लिए एक read-only टेम्पलेट। इसे एक पैकेज्ड आर्टिफैक्ट समझें जिसमें कोड, रनटाइम, सिस्टम लाइब्रेरी और डिफ़ॉल्ट सेटिंग्स शामिल हैं।
कंटेनर: इमेज का चलता हुआ इंस्टेंस। अगर इमेज ब्लूप्रिंट है तो कंटेनर वह घर है जिसमें आप रह रहे हैं।
Dockerfile: स्टेप-बाय-स्टेप निर्देश जिनसे Docker इमेज बनाता है (निर्भरताएँ इंस्टॉल करना, फाइलें कॉपी करना, स्टार्टअप कमांड सेट करना)।
रजिस्ट्री: इमेज स्टोर और डिस्ट्रीब्यूशन सर्विस। आप इमेज को रजिस्ट्री में "push" करते हैं और बाद में सर्वर से "pull" करते हैं (पब्लिक रजिस्ट्री या प्राइवेट)।
एक बार जब आपकी ऐप को Dockerfile से बनाई गई इमेज के रूप में परिभाषित कर दिया जाता है, तो आपको एक मानकीकृत डिलीवरी यूनिट मिलती है। यह मानकीकरण रिलीज़ को रिपीटेबल बनाता है: वही इमेज जिसे आपने टेस्ट किया, वही डिप्लॉय होती है।
यह हैंडऑफ़ को भी आसान बनाता है। "मेरे मशीन पर चलता है" कहने की बजाय आप किसी खास इमेज वर्ज़न की ओर इशारा कर सकते हैं और कह सकते हैं: इस कंटेनर को इन environment variables के साथ इस पोर्ट पर चलाइए। यही विकास और प्रोडक्शन वातावरण की सुसंगति का आधार है।
Docker का सबसे बड़ा कारण क्लाउड डिप्लॉयमेंट्स में कंसिस्टेंसी है। किसी भी मशीन पर जो कुछ इंस्टॉल है उस पर भरोसा करने की बजाय आप एक बार वातावरण को परिभाषित करते हैं (Dockerfile में) और उसी को विभिन्न चरणों में पुनः उपयोग करते हैं।
व्यवहार में, कंसिस्टेंसी कुछ इस तरह दिखती है:
यह कंसिस्टेंसी जल्दी लाभ देती है। प्रोड में आया हुआ बग उसी इमेज टैग को लोकल में चलाकर दोहराया जा सकता है। अगर डिप्लॉय किसी गायब लाइब्रेरी के कारण फेल होता है तो यह कम संभावित है क्योंकि वही लाइब्रेरी टेस्ट कंटेनर में भी गायब होती।
टीमें अक्सर सेटअप डॉक या स्क्रिप्ट से मानकीकरण करने की कोशिश करती हैं। समस्या ड्रिफ्ट है: मशीनें समय के साथ बदलती हैं जैसे पैच और पैकेज अपडेट आते हैं, और अंतर धीरे-धीरे जमा हो जाते हैं।
Docker में, वातावरण को एक आर्टिफैक्ट माना जाता है। अगर आपको इसे अपडेट करना है, तो आप नई इमेज बनाते हैं और उसे डिप्लॉय करते हैं—जिससे बदलाव स्पष्ट और रिव्यू योग्य होते हैं। अगर अपडेट से समस्या आती है, तो रोलबैक अक्सर पिछले ज्ञात-सही टैग को डिप्लॉय करना जितना सरल होता है।
Docker की दूसरी बड़ी जीत पोर्टेबिलिटी है। एक कंटेनर इमेज आपकी एप्लिकेशन को एक पोर्टेबल आर्टिफैक्ट में बदल देती है: एक बार बनाइए, फिर जहाँ भी संगत कंटेनर रनटाइम हो वहाँ चलाइए।
Docker इमेज आपकी ऐप कोड और उसके रनटाइम निर्भरताएँ (उदा. Node.js, Python पैकेज, सिस्टम लाइब्रेरी) बंडल करती है। इसका अर्थ है कि आपकी मशीन पर बनी इमेज यह भी चला सकती है:
यह रनटाइम स्तर पर vendor lock-in को घटाता है। आप फिर भी क्लाउड-नेटीव सेवाएँ (DB, 큐, स्टोरेज) उपयोग कर सकते हैं, पर आपकी कोर ऐप को फिर से बनाना नहीं पड़ेगा केवल इसलिए कि होस्ट बदल गया।
पोर्टेबिलिटी तब सबसे अच्छी होती है जब इमेजेज़ रजिस्ट्री में संग्रहीत और versioned हों—पब्लिक या प्राइवेट। एक सामान्य वर्कफ़्लो:
myapp:1.4.2).रजिस्ट्री यह भी आसान बनाती है कि आप डिप्लॉयमेंट्स को पुनरुत्पादित और ऑडिट कर सकें: अगर प्रोड में 1.4.2 चल रहा है, तो आप बाद में वही आर्टिफैक्ट pull कर के बिल्कुल वही बिट्स वापस पा सकते हैं।
होस्ट माइग्रेट करना: अगर आप एक VM प्रदाता से दूसरे पर जाते हैं, तो स्टैक को फिर से इंस्टॉल नहीं करना पड़ता। आप नए सर्वर को रजिस्ट्री की ओर इशारा करते हैं, इमेज pull करते हैं, और वही कॉन्फ़िग के साथ कंटेनर स्टार्ट करते हैं।
स्केल आउट करना: अधिक क्षमता चाहिए? उसी इमेज से और कंटेनर शुरू करें। क्योंकि प्रत्येक इंस्टेंस समान है, स्केलिंग एक दोहराने योग्य ऑपरेशन बन जाता है बजाय मैन्युअल सेटअप के।
एक अच्छी Docker इमेज सिर्फ "चलने वाली चीज़" नहीं होती। यह एक पैकेज्ड, versioned आर्टिफैक्ट होती है जिसे आप बाद में फिर से बना कर भरोसा कर सकते हैं। यही क्लाउड डिप्लॉयमेंट्स को पूर्वानुमेय बनाती है।
एक Dockerfile यह बताता है कि आपकी ऐप इमेज को चरण दर चरण कैसे असेंबल किया जाए—ठीक उस तरह जैसे एक रेसिपी जिसमें सटीक सामग्री और निर्देश होते हैं। हर लाइन एक लेयर बनाती है, और साथ में वे परिभाषित करते हैं:
इस फ़ाइल को साफ़ और इरादतन बनाकर रखना इमेज डिबग, रिव्यू और मेंटेन करने में आसान बनाता है।
छोटी इमेज तेज़ी से pull होती हैं, तेजी से शुरू होती हैं, और कम "अनावश्यक चीज़ें" रखती हैं जो टूट सकती हैं या कमजोरियाँ ला सकती हैं।
alpine या slim वेरिएंट) जहां संभव हो।कई ऐप्स को कंपाइल करने के लिए बिल्ड टूल्स चाहिए लेकिन रनटाइम पर नहीं। मल्टी-स्टेज बिल्ड आपको एक स्टेज में बिल्ड करने और दूसरे, मिनिमल स्टेज में प्रोडक्शन के लिए पैकेज करने देता है।
# build stage
FROM node:20 AS build
WORKDIR /app
COPY package*.json ./
RUN npm ci
COPY . .
RUN npm run build
# runtime stage
FROM nginx:1.27-alpine
COPY --from=build /app/dist /usr/share/nginx/html
परिणाम एक छोटी प्रोडक्शन इमेज है जिसमें कम निर्भरताएँ होती हैं जिन्हें पै치 करना होता है।
टैग्स बताते हैं कि आपने बिलकुल क्या डिप्लॉय किया है।
latest पर भरोसा न करें प्रोडक्शन में; यह अस्पष्ट है।1.4.2)।1.4.2-<sha> या बस <sha>) ताकि आप हमेशा इमेज को उसके निर्माण वाले कोड से ट्रेस कर सकें।यह क्लीन रोलबैक और स्पष्ट ऑडिट को समर्थन देता है जब क्लाउड में कुछ बदलता है।
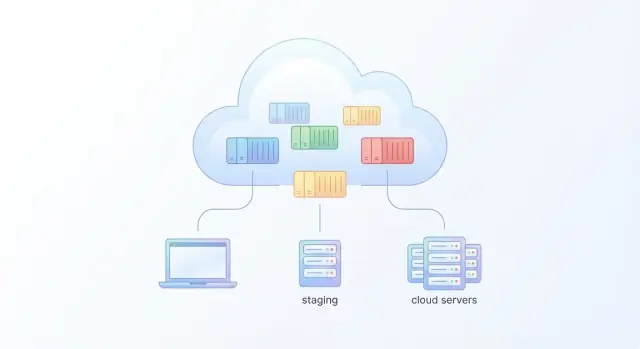
एक "असली" क्लाउड ऐप आमतौर पर एक ही प्रोसेस नहीं होता। यह एक छोटा सिस्टम होता है: वेब फ्रंटएंड, एक API, शायद बैकग्राउंड वर्कर, और एक डेटाबेस या कैश। Docker सरल और मल्टी-सर्विस सेटअप दोनों का समर्थन करता है—आपको बस यह समझना होगा कि कंटेनर कैसे एक-दूसरे से बात करते हैं, कॉन्फ़िग कहाँ रहती है, और डेटा रीस्टार्ट के बाद कैसे जीवित रहता है।
सिंगल-कंटेनर ऐप एक स्टेटिक साइट या एक ऐसा API हो सकता है जो किसी और चीज़ पर निर्भर नहीं है। आप एक पोर्ट एक्सपोज़ करते हैं (उदा. 8080) और चलाते हैं।
मल्टी-सर्विस ऐप्स ज़्यादा सामान्य हैं: web -> api, api -> db, और worker जॉब्स खाता है। IP एड्रेस हार्ड-कोड करने की बजाय, कंटेनर सामान्यतः सर्विस नाम से साझा नेटवर्क पर बात करते हैं (उदा. db:5432)।
Docker Compose लोकल डेवलपमेंट और स्टेजिंग के लिए व्यावहारिक विकल्प है क्योंकि यह आपको एक कमांड से पूरा स्टैक स्टार्ट करने देता है। यह आपकी ऐप की "शेप" (सर्विसेस, पोर्ट्स, निर्भरताएँ) को एक फ़ाइल में दस्तावेज़ करता है जिसे पूरी टीम साझा कर सकती है।
सामान्य प्रगति इस तरह होती है:
इमेज को पुनः उपयोग योग्य और सुरक्षित रखना चाहिए। इमेज के बाहर रखें:
इन्हें environment variables, .env फ़ाइल (सावधान: commit न करें), या आपके क्लाउड के सिक्रेट्स मैनेजर के जरिए पास करें।
कंटेनर डिस्पोज़ेबल होते हैं; आपका डेटा नहीं होना चाहिए। किसी भी चीज़ के लिए जो रीस्टार्ट पर जिये रहना चाहिए वॉल्यूम्स का उपयोग करें:
क्लाउड डिप्लॉयमेंट्स में समकक्षता प्रबंधित स्टोरेज (managed DBs, network disks, object storage) है। मुख्य विचार वही है: कंटेनर ऐप चलाते हैं; पर्सिस्टेंट स्टोरेज स्टेट रखता है।
एक स्वस्थ Docker डिप्लॉयमेंट वर्कफ़्लो जानबूझकर सरल होता है: एक बार इमेज बनाएं, फिर वही इमेज हर जगह चलाएँ। फाइलों को सर्वर पर कॉपी करने या इंस्टॉलर फिर से चलाने की बजाय आप डिप्लॉयमेंट को एक दोहराने योग्य रूटीन में बदल देते हैं: इमेज pull करो, कंटेनर चलाओ।
अधिकांश टीमें इस तरह का पाइपलाइन फॉलो करती हैं:
myapp:1.8.3).आखिरी स्टेप ही Docker को "बोरिंग" महसूस कराता है लेकिन अच्छा अर्थ में:
# build locally or in CI
docker build -t registry.example.com/myapp:1.8.3 .
docker push registry.example.com/myapp:1.8.3
# on the server / cloud runner
docker pull registry.example.com/myapp:1.8.3
docker run -d --name myapp -p 80:8080 registry.example.com/myapp:1.8.3
दो आम तरीके Dockerized एप्स को क्लाउड में चलाने के:
रिलीज़ के दौरान आउटेज कम करने के लिए प्रोडक्शन डिप्लॉयमेंट आमतौर पर तीन चीज़ें जोड़ते हैं:
रजिस्ट्री केवल स्टोरेज नहीं है—यह तरीका है जिससे आप एनवायरनमेंट्स को सुसंगत रखते हैं। एक आम अभ्यास है वही इमेज dev → staging → prod तक प्रमोट करना (अक्सर re-tag करके), बजाय हर बार rebuild करने के। इस तरह प्रोडक्शन वही आर्टिफैक्ट चलाती है जिसे आपने टेस्ट किया था, जिससे "स्टेजिंग में चलता था" वाले आश्चर्य घट जाते हैं।
CI/CD (Continuous Integration और Continuous Delivery) मूलतः सॉफ्टवेयर शिपिंग की असेंबली लाइन है। Docker उस असेंबली लाइन को अधिक पूर्वानुमेय बनाता है क्योंकि हर स्टेप एक ज्ञात वातावरण के खिलाफ चलता है।
एक Docker-फ्रेंडली पाइपलाइन आमतौर पर तीन चरणों में रहती है:
myapp:1.8.3).यह फ्लो गैर-टेक स्टेकहोल्डर्स के लिए भी समझाने में आसान है: "हम एक सीलबंद बॉक्स बनाते हैं, बॉक्स का टेस्ट करते हैं, फिर उसी बॉक्स को हर वातावरण में भेजते हैं।"
टेस्ट अक्सर लोकल पर पास होते हैं और प्रोड पर फेल क्योंकि रनटाइम मेल नहीं खाते, सिस्टम लाइब्रेरी गायब होती हैं, या environment variables अलग होते हैं। कंटेनरों में टेस्ट चलाने से ये गैप छोटे होते हैं। आपके CI रनर को एक खास मशीन की ज़रूरत नहीं—सिर्फ Docker चाहिए।
Docker "promote, don’t rebuild" का समर्थन करता है। बजाय प्रत्येक वातावरण के लिए रीबिल्ड करने के, आप:
myapp:1.8.3 बनाइए और टेस्ट कीजिए।केवल कॉन्फ़िग एनवायरनमेंट्स के बीच बदलती है (URLs या credentials जैसे), एप्लिकेशन आर्टिफैक्ट नहीं। इससे रिलीज़-डे अनिश्चितता घटती है और रोलबैक सरल बनता है: पिछला इमेज टैग फिर से डिप्लॉय करें।
अगर आप तेज़ी से आगे बढ़ रहे हैं और Docker के फायदे बिना ढेर सारा स्कैफ़ोल्डिंग किए चाहते हैं, तो Koder.ai चैट-ड्रिवन वर्कफ़्लो से प्रोडक्शन-शेप्ड ऐप जनरेट कर के और उसे साफ़-सुथरे ढंग से कंटेनराइज़ करके मदद कर सकता है।
टीमें अक्सर Koder.ai का उपयोग करती हैं ताकि:
Dockerfile और docker-compose.yml जोड़ना (ताकि dev और prod व्यवहार संरेखित रहें),मुख्य लाभ यह है कि Docker डिप्लॉयमेंट प्रिमिटिव बने रहता है, जबकि Koder.ai आइडिया से कंटेनर-रेडी कोडबेस तक का रास्ता तेज़ करता है।
Docker एक सेवा को एक मशीन पर पैकेज और चलाना आसान बनाता है। लेकिन जब आपके पास कई सर्विसेस, प्रत्येक की कई कॉपियाँ, और कई सर्वर होते हैं, तो आपको एक सिस्टम चाहिए जो सब कुछ समन्वित रखे। यही ऑर्केस्ट्रेशन है: सॉफ्टवेयर जो तय करता है कि कंटेनर कहाँ चलेंगे, उन्हें हेल्दी रखेगा और मांग बदलने पर क्षमता समायोजित करेगा।
कुछ कंटेनरों के साथ आप उन्हें मैन्युअली स्टार्ट और रिस्टार्ट कर सकते हैं। बड़े पैमाने पर यह जल्दी असफल हो जाता है:
Kubernetes (अक्सर “K8s”) सबसे आम ऑर्केस्ट्रेटर है। सरल मानसिक मॉडल:
Kubernetes कंटेनर नहीं बनाता; वह उन्हें चलाता है। आप अभी भी Docker इमेज बनाते हैं, उसे रजिस्ट्री पर push करते हैं, फिर Kubernetes उस इमेज को नोड्स पर pull करके कंटेनर स्टार्ट करता है। आपकी इमेज वही पोर्टेबल, versioned ऐप आर्टिफैक्ट बनी रहती है जो हर जगह उपयोग होती है।
यदि आप एक सर्वर पर कुछ सेवाओं के साथ हैं, तो Docker Compose पर्याप्त हो सकता है। ऑर्केस्ट्रेशन तब उपयोगी होना शुरू होता है जब आपको हाई अवेलेबिलिटी, बार-बार डिप्लॉयमेंट, ऑटो-स्केलिंग, या क्षमता और रेजिलिएंस के लिए कई सर्वर चाहिए हों।
कंटेनर अपने आप ऐप को सुरक्षित नहीं बनाते—वे मुख्यतः सुरक्षा के काम को मानकीकृत और ऑटोमेट करने के लिए साफ़ पॉइंट देते हैं जो ऑडिटर और सुरक्षा टीमें चाहती हैं। अच्छा पहलू यह है कि Docker आपको स्पष्ट, दोहराने योग्य बिंदु देता है जिनमें नियंत्रण जोड़े जा सकते हैं।
कंटेनर इमेज आपकी ऐप और उसकी निर्भरताओं का बंडल है, इसलिए कमजोरियाँ अक्सर बेस इमेज या सिस्टम पैकेज से आती हैं जिन्हें आपने लिखा नहीं है। इमेज स्कैनिंग तैनाती से पहले ज्ञात CVE के लिए जांच करती है।
इसे अपनी पाइपलाइन में एक गेट बनाइए: अगर किसी क्रिटिकल वल्नरेबिलिटी की पहचान हो तो बिल्ड फेल कर दीजिए और पैच्ड बेस इमेज के साथ फिर से बनाइए। स्कैन रिपोर्ट्स को आर्टिफैक्ट के रूप में रखें ताकि आप दिखा सकें कि आपने क्या शिप किया था (compliance के लिए)।
जहाँ संभव हो नॉन-रूट यूज़र के रूप में चलाएँ। कई हमले रुट एक्सेस पर निर्भर होते हैं ताकि कंटेनर से बाहर निकल कर फाइलसिस्टम छेड़छाड़ की जा सके।
साथ ही कंटेनर के लिए पढ़ने-केवल फाइलसिस्टम और केवल विशिष्ट writable paths माउंट करने पर विचार करें (लॉग्स या अपलोड्स के लिए)। इससे अगर किसी ने अंदर घुसपैठ कर ली तो बदला जा सकने वाला सतह छोटा रहता है।
API कीज़, पासवर्ड, या प्राइवेट सर्टिफिकेट्स को Docker इमेज में कभी न कॉपी करें और Git में न कमिट करें। इमेज कैश होती हैं, शेयर की जाती हैं और रजिस्ट्री पर पुश होती हैं—सीक्रेट्स व्यापक रूप से लीक हो सकते हैं।
इसके बजाय रनटाइम पर प्लेटफ़ॉर्म के सिक्रेट स्टोर (Kubernetes Secrets या क्लाउड सिक्रेट मैनेजर) का उपयोग करें, और केवल उन सर्विसेस को एक्सेस दें जिन्हें इसकी आवश्यकता है।
परंपरागत सर्वरों की तरह कंटेनर अपने आप रन करते समय खुद को पैच नहीं करते। मानक तरीका यह है: निर्भरताओं के साथ इमेज रीबिल्ड करें, फिर redeploy करें।
एक कैडेंस सेट करें (साप्ताहिक या मासिक) ताकि आप इमेज रीबिल्ड करें भले ही ऐप कोड न बदला हो, और उच्च-गंभीरता वाले CVE मिलने पर तुरंत रीबिल्ड करें। यह आदत आपकी डिप्लॉयमेंट्स को ऑडिट योग्य और कम जोखिम वाली बनाती है।
यहाँ वे गलतियाँ हैं जो सबसे अधिक दर्द देती हैं—और उन्हें रोकर उपाय।
आम एंटी-पैटर्न है “सर्वर में SSH करके कुछ बदल दो,” या चल रहे कंटेनर में exec करके हॉट-फिक्स करना। यह एक बार काम कर जाता है, फिर बाद में टूट जाता है क्योंकि कोई भी सटीक स्थिति दोहराने लायक नहीं होती।
इसके बजाय कंटेनरों को गाय/भैंसे की तरह समझें: डिस्पोज़ेबल और रिप्लेसबल। हर बदलाव इमेज बिल्ड और डिप्लॉयमेंट पाइपलाइन के जरिए करें। अगर डिबग करना है, तो अस्थायी वातावरण में करें और फिर फिक्स को Dockerfile, कॉन्फ़िग या इंफ्रास्ट्रक्चर सेटिंग्स में कोडाइज़ करें।
बड़ी इमेज CI/CD धीमी कर देती हैं, स्टोरेज लागत बढ़ाती हैं, और सुरक्षा सतह बढ़ाती हैं।
इसे टाला जा सकता है:
.dockerignore जोड़ें ताकि node_modules, बिल्ड आर्टिफैक्ट या लोकल सीक्रेट्स भेजे न जाएँ।लक्ष्य एक ऐसा बिल्ड है जो क्लीन मशीन पर भी रिपीटेबल और तेज़ हो।
कंटेनर ऐप के व्यवहार को समझने की ज़रूरत नहीं हटती। बिना लॉग्स, मीट्रिक्स और ट्रेसेस के आप केवल तब समस्याएँ नोटिस करेंगे जब उपयोगकर्ता शिकायत करें।
कम से कम, सुनिश्चित करें कि आपकी ऐप stdout/stderr पर लॉग लिखे (लोकल फाइल पर नहीं), बुनियादी हेल्थ एंडपॉइंट्स हों, और कुछ महत्वपूर्ण मीट्रिक्स दें (error rate, latency, queue depth)। फिर इन संकेतों को आपके क्लाउड स्टैक के मॉनिटरिंग से कनेक्ट करें।
स्टेटलेस कंटेनर बदलना आसान है; स्टेटफुल डेटा नहीं। टीमें अक्सर बहुत बाद में पाती हैं कि कंटेनर में चल रहा डेटाबेस "ठीक था" जब तक कि रीस्टार्ट पर डेटा हट न जाए।
जल्दी फैसला करें कि स्टेट कहाँ रहेगा:
Docker ऐप पैकेज करने में शानदार है—लेकिन विश्वसनीयता इस बात से आती है कि आप जानबूझ कर कंटेनरों को कैसे बनाते, अवलोकन करते, और पर्सिस्टेंट डेटा से जोड़ते हैं।
यदि आप Docker में नए हैं, तो सबसे तेज़ तरीका है एक वास्तविक सर्विस को end-to-end कंटेनराइज़ करना: बिल्ड करें, लोकल चलाएँ, रजिस्ट्री में push करें, और डिप्लॉय करें। इस चेकलिस्ट का उपयोग कर के स्कोप छोटा रखें और परिणाम उपयोगी रखें।
एक स्टेटलेस सर्विस चुनें (API, worker, या सादे वेब ऐप)। परिभाषित करें कि उसे स्टार्ट होने के लिए क्या चाहिए: किस पोर्ट पर सुनता है, कौन से environment variables जरूरी हैं, और कोई बाहरी निर्भरता (जैसे डेटाबेस) जिसे आप अलग से चला सकते हैं।
लक्ष्य स्पष्ट रखें: "मैं एक ही इमेज से लोकल और क्लाउड दोनों पर वही ऐप चला सकूँ।"
सबसे छोटे Dockerfile को लिखिए जो विश्वसनीय रूप से आपकी ऐप बना और चला सके। प्राथमिकता दें:
फिर लोकल विकास के लिए docker-compose.yml जोड़ें जो environment variables और निर्भरताओं (जैसे DB) को वायर करे बिना आपके लैपटॉप पर कुछ इंस्टॉल किए।
अगर आप बाद में गहरा लोकल सेटअप चाहते हैं तो विस्तार कर सकते हैं—पहले साधारण रखें।
निर्धारित करें कि इमेज कहाँ रहेंगी (Docker Hub, GHCR, ECR, GCR, आदि)। फिर ऐसे टैग अपनाइए जो डिप्लॉयमेंट्स को पूर्वानुमेय बनाएं:
:dev लोकल टेस्ट के लिए (वैकल्पिक):git-sha (अपरिवर्तनीय, डिप्लॉयमेंट के लिए सबसे अच्छा):v1.2.3 रिलीज़ के लिएप्रोडक्शन में :latest पर भरोसा न करें।
CI सेट करें ताकि आपकी मुख्य ब्रांच में हर मर्ज पर इमेज बन जाए और रजिस्ट्री में push हो। आपका पाइपलाइन यह करे:
एक बार यह काम करने लगे, आप प्रकाशित इमेज को अपने क्लाउड डिप्लॉय स्टेप से जोड़ सकते हैं और वहां से इटर्रेट कर सकते हैं।
Docker आपकी एप को उसके रनटाइम और निर्भरताओं के साथ एक इमेज में पैकेज करके “माई मशीन पर चलता था” वाली समस्याओं को कम करता है। आप वही इमेज लोकल, CI और क्लाउड में चलाते हैं, जिससे OS पैकेज, भाषा वर्ज़न और लाइब्रेरी के अंतर छुपकर व्यवहार नहीं बदलते।
आप आमतौर पर एक बार इमेज बनाते हैं (उदा. myapp:1.8.3) और कई कंटेनर उसी से अलग- अलग वातावरणों में चलाते हैं।
VM में एक पूरा गेस्ट ऑपरेटिंग सिस्टम शामिल होता है, इसलिए वह भारी और धीमा शुरू होता है। कंटेनर होस्ट के कर्नेल को साझा करते हैं और केवल ऐप के लिए आवश्यक रनटाइम और लाइब्रेरी भेजते हैं, इसलिए सामान्यतः:
रजिस्ट्रि वह जगह है जहाँ इमेज स्टोर और versioned रहती हैं ताकि अन्य मशीनें उन्हें pull कर सकें.
साधारण वर्कफ़्लो:
docker build -t myapp:1.8.3 .docker push <registry>/myapp:1.8.3इससे रोलबैक आसान होता है: बस पिछला टैग फिर से डिप्लॉय करें।
उचित टैगिंग कीजिए ताकि आप हमेशा जान सकें कि क्या चल रहा है.
प्रैक्टिकल तरीका:
:1.8.3:<git-sha>:latest पर भरोसा न करें (यह अस्पष्ट है)यह क्लीन रोलबैक और ऑडिट में मदद करता है।
इमेज के अंदर environment-specific सेटिंग्स नहीं रखनी चाहिए। Dockerfile में API कीज़, पासवर्ड या प्राइवेट सर्टिफिकेट्स न डालें।
इसके बजाय:
.env फ़ाइल को Git में commit न करेंइससे इमेज पुनः उपयोग योग्य रहती है और रिस्क कम होता है।
कंटेनर अस्थायी होते हैं; उनका फाइलसिस्टम रीस्टार्ट पर बदल सकता है।
नियम: ऐप कंटेनरों में चलाएँ; स्टेट-purpose-built स्टोरेज में रखें।
Compose स्थानीय विकास और एक होस्ट के लिए अच्छा है:
db:5432)अगर आपको मल्टी-सर्वर प्रोडक्शन, हाई अवेलेबिलिटी और ऑटो-स्केलिंग चाहिए तो ऑर्केस्ट्रेटर (अक्सर Kubernetes) जोड़ें।
एक व्यावहारिक पाइपलाइन: build → test → publish → deploy
यह “promote, don’t rebuild” सिद्धांत रखता है ताकि आर्टिफैक्ट अनन्य बना रहे।
अक्सर कारण:
-p 80:8080).डिबग करने के लिए प्रोडक्शन टैग को लोकल पर चलाएँ और पहले कॉन्फ़िग की तुलना करें।