10 जुल॰ 2025·8 मिनट
ईमेल और वेबहुक के लिए सरल बैकग्राउंड जॉब क्यू पैटर्न
रिट्राई, बैकऑफ और डेड-लेट्टर हैंडलिंग के साथ ईमेल भेजने, रिपोर्ट चलाने और वेबहुक डिलीवरी के लिए सरल बैकग्राउंड जॉब क्यू पैटर्न सीखें—बिना भारी टूल्स के।
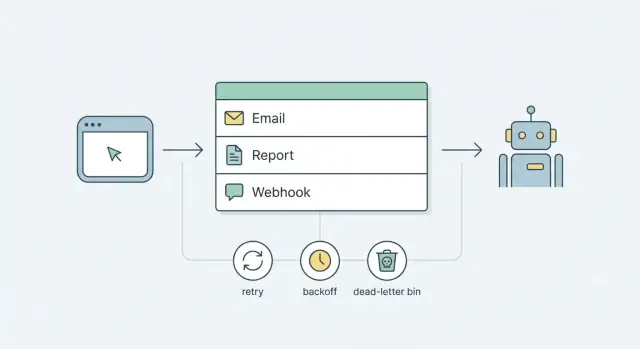
रिट्राई, बैकऑफ और डेड-लेट्टर हैंडलिंग के साथ ईमेल भेजने, रिपोर्ट चलाने और वेबहुक डिलीवरी के लिए सरल बैकग्राउंड जॉब क्यू पैटर्न सीखें—बिना भारी टूल्स के।
कोई भी काम जो एक या दो सेकंड से ज्यादा ले सकता है, उसे यूज़र रिक्वेस्ट के अंदर नहीं चलाना चाहिए। ईमेल भेजना, रिपोर्ट बनाना और वेबहुक डिलिवरी नेटवर्क, थर्ड-पार्टी सर्विसेस या धीली क्वेरीज़ पर निर्भर करते हैं। कभी-कभी वे रुक जाते हैं, फेल होते हैं, या उम्मीद से ज्यादा समय लेते हैं।
अगर आप यह काम यूज़र के इंतज़ार के दौरान करते हैं तो लोग तुरंत ध्यान देते हैं। पेज हैंग होते हैं, "Save" बटन घूर्णन करता है, और रिक्वेस्ट्स टाइमआउट हो जाती हैं। रिट्राईज़ गलत जगह भी हो सकती हैं। यूज़र रिफ्रेश करता है, आपका लोड बैलेंसर फिर से भेजता है, या फ्रंटेंड दुबारा सबमिट कर देता है, और आप डुप्लिकेट ईमेल, डुप्लिकेट वेबहुक कॉल, या दो रिपोर्ट रन के साथ टकराव पाते हैं।
बैकग्राउण्ड जॉब्स इस समस्या को सुलझाते हैं: रिक्वेस्ट्स को छोटा और अनुमानित रखें: काम स्वीकार करें, बाद में करने के लिए जॉब रिकॉर्ड करें, और तेजी से रिस्पॉन्ड करें। जॉब रिक्वेस्ट के बाहर चलता है, और नियम आपके नियंत्रण में होते हैं।
कठिन हिस्सा विश्वसनीयता है। काम जब रिक्वेस्ट पाथ से बाहर चला जाता है, तब भी आपको इन सवालों के जवाब देने होते हैं:
बहुत सी टीमें "भारी इंफ्रास्ट्रक्चर" जोड़ कर जवाब देती हैं: मैसेज ब्रोकर्स, अलग वर्कर फ़्लीट, डैशबोर्ड, अलर्टिंग और प्लेबुक्स। ये टूल्स तब उपयोगी हैं जब वाकई ज़रूरत हो, पर ये नए मूविंग पार्ट्स और नए फेल्योर मोड भी जोड़ते हैं।
बेहतर शुरुआती लक्ष्य सरलता है: पहले से मौजूद हिस्सों का उपयोग करके भरोसेमंद जॉब्स। अधिकांश प्रोडक्ट्स के लिए इसका मतलब है डाटाबेस-बैक्ड क्यू और एक छोटा वर्कर प्रोसेस। एक स्पष्ट रिट्राई और बैकऑफ रणनीति जोड़ें, और उन जॉब्स के लिए डेड-लेट्टर पैटर्न जिनकी बार-बार विफलता हो रही हो। आप जटिल प्लेटफ़ॉर्म पर पहले दिन कम समझौता करके अनुमानित व्यवहार पा लेते हैं।
यहाँ तक कि अगर आप तेजी से Koder.ai जैसे चैट-ड्रिवन टूल से बना रहे हैं, तब भी यह अलगाव मायने रखता है। उपयोगकर्ता को अभी तेज़ जवाब मिलना चाहिए, और आपका सिस्टम धीमे, विफलता-प्रवण काम को सुरक्षित रूप से बैकग्राउंड में पूरा करे।
क्यू काम के लिए एक प्रतीक्षा पंक्ति है। धीमे या अस्थिर टास्क को यूज़र रिक्वेस्ट के दौरान करने की बजाय (ईमेल भेजना, रिपोर्ट बनाना, वेबहुक कॉल करना), आप एक छोटा रिकॉर्ड क्यू में डालते हैं और तुरंत वापस आ जाते हैं। बाद में, एक अलग प्रोसेस वह रिकॉर्ड उठाकर काम करता है।
कुछ शब्द जो आप अक्सर देखेंगे:
सबसे सरल फ्लो इस तरह दिखता है:
Enqueue: आपका ऐप एक जॉब रिकॉर्ड (type, payload, run time) सेव करता है।
Claim: एक वर्कर अगला उपलब्ध जॉब ढूंढता है और उसे "लॉक" कर लेता है ताकि सिर्फ़ एक वर्कर ही उसे चला सके।
Run: वर्कर टास्क करता है (भेजना, जनरेट करना, डिलिवर करना)।
Finish: उसे पूरा मार्क करें, या विफलता रिकॉर्ड करें और अगली रन टाइम सेट करें।
अगर आपका जॉब वॉल्यूम मामूली है और आपके पास पहले से एक डेटाबेस है, तो डाटाबेस-बैक्ड क्यू अक्सर काफी होता है। इसे समझना आसान है, डिबग करना आसान है, और यह ईमेल जॉब प्रोसेसिंग और वेबहुक डिलीवरी जैसी सामान्य ज़रूरतों को पूरा करता है।
स्ट्रीमिंग प्लेटफ़ॉर्म तब समझ में आते हैं जब आपको बहुत उच्च थ्रूपुट, कई स्वतंत्र कंस्यूमर्स, या कई सिस्टम्स में बड़े इवेंट हिस्ट्री को रीप्ले करने की ज़रूरत हो। अगर आप दर्जनों सर्विस चला रहे हैं और लाखों इवेंट्स प्रति घंटे हैं तो Kafka जैसे टूल मदद कर सकते हैं। तब तक, एक डेटाबेस टेबल और एक वर्कर लूप बहुत से रीयल-वर्ल्ड क्यू को कवर करते हैं।
एक डेटाबेस क्यू तब तक व्यवस्थित रहता है जब हर जॉब रिकॉर्ड तीन सवालों का तेज़ी से उत्तर दे: क्या करना है, अगली बार कब आज़माना है, और पिछली बार क्या हुआ। इसे सही करें और ऑपरेशंस उबाऊ हो जाएंगे (यही लक्ष्य है)।
काम करने के लिए जरूरी सबसे छोटा इनपुट रखें, पूरा रेंडर्ड आउटपुट नहीं। अच्छे payloads IDs और कुछ पैरामीटर्स होते हैं, जैसे { "user_id": 42, "template": "welcome" }।
बड़े ब्लॉब्स (पूरा HTML ईमेल, बड़ी रिपोर्ट डेटा, विशाल वेबहुक बॉडी) स्टोर करने से बचें। इससे आपका डेटाबेस तेज़ी से बढ़ेगा और डिबगिंग मुश्किल होगी। अगर जॉब को कोई बड़ी डाक्यूमेंट चाहिए, तो उसकी जगह एक रेफरेंस स्टोर करें: report_id, export_id, या एक फ़ाइल key। वर्कर रन के समय पूरा डेटा फ़ेच कर सकता है।
कम से कम, जगह बनाएं:
job_type हैंडलर चुनता है (send_email, generate_report, deliver_webhook). payload छोटे इनपुट्स जैसे IDs और ऑप्शन्स रखता है.queued, running, succeeded, failed, dead).attempt_count और max_attempts ताकि आप रिट्राई रोक सकें जब यह स्पष्ट हो कि काम नहीं होगा।created_at और next_run_at (कब eligible होगा). started_at और finished_at जोड़ें अगर आप धीमे जॉब्स की बेहतर visibility चाहते हैं।idempotency_key, और last_error ताकि बिना ढेर सारे लॉग्स खोले यह पता चल सके कि क्यों फेल हुआ।Idempotency शब्द जटिल लग सकता है, पर विचार सरल है: अगर वही जॉब दो बार चले तो दूसरी बार उसे ऐसा कुछ नहीं करना चाहिए जो खतरनाक हो। उदाहरण के लिए, एक वेबहुक delivery जॉब webhook:order:123:event:paid जैसा idempotency key इस्तेमाल कर सकता है ताकि अगर retry timeout के साथ overlap करे तो वही इवेंट दो बार न भेजा जाए।
कुछ बुनियादी संख्याएँ जल्दी पकड़ लें। बड़े डैशबोर्ड की ज़रूरत नहीं — बस क्वेरीज़ जो बताएँ: कितने जॉब्स कतार में हैं, कितने फेल हो रहे हैं, और सबसे पुराने कतारबद्ध जॉब की उम्र क्या है।
अगर आपके पास पहले से एक डेटाबेस है, तो आप नया इंफ्रास्ट्रक्चर जोड़े बिना बैकग्राउण्ड क्यू शुरू कर सकते हैं। जॉब्स पंक्तियाँ हैं, और वर्कर एक प्रोसेस है जो due पंक्तियाँ उठाता और काम करता है।
तालिका को छोटा और साधारण रखें। आपको बाद में जॉब्स चलाने, रिट्राई करने और डिबग करने के लिए पर्याप्त फ़ील्ड चाहिए।
CREATE TABLE jobs (
id bigserial PRIMARY KEY,
job_type text NOT NULL,
payload jsonb NOT NULL,
status text NOT NULL DEFAULT 'queued', -- queued, running, done, failed
attempts int NOT NULL DEFAULT 0,
next_run_at timestamptz NOT NULL DEFAULT now(),
locked_at timestamptz,
locked_by text,
last_error text,
created_at timestamptz NOT NULL DEFAULT now(),
updated_at timestamptz NOT NULL DEFAULT now()
);
CREATE INDEX jobs_due_idx ON jobs (status, next_run_at);
अगर आप Postgres पर बना रहे हैं (Go बैकएंड के साथ सामान्य), jsonb जॉब डेटा स्टोर करने का व्यवहारिक तरीका है जैसे { "user_id":123,"template":"welcome" }।
जब कोई यूज़र एक्शन जॉब ट्रिगर करे (ईमेल भेजना, वेबहुक फायर करना), तो संभव हो तो मुख्य परिवर्तन के साथ ही उसी डेटाबेस ट्रांज़ैक्शन में जॉब रो लिखें। इससे यह रोका जाता है कि अगर क्रैश हो तो "यूज़र बना पर जॉब गायब" जैसी समस्या हो।
उदाहरण: जब कोई यूज़र साइन अप करे, तो user रो और send_welcome_email जॉब एक ही ट्रांज़ैक्शन में डालें।
एक वर्कर बार-बार यही चक्र दोहराता है: एक due जॉब ढूंढो, उसे क्लेम करो ताकि कोई दूसरा न ले, प्रोसेस करो, फिर उसे पूरा मार्क करो या अगले प्रयास के लिए शेड्यूल करें।
वास्तव में, इसका मतलब है:
status='queued' और next_run_at <= now() वाली एक जॉब चुनें।SELECT ... FOR UPDATE SKIP LOCKED आम तरीका है)।status='running', locked_at=now(), locked_by='worker-1' सेट करें।done/succeeded), या last_error रिकॉर्ड करें और अगला प्रयास शेड्यूल करें।एक से ज़्यादा वर्कर एक साथ चल सकते हैं। क्लेम स्टेप डबल-पिकिंग को रोकता है।
शटडाउन पर, नई जॉब्स लेना बंद करें, वर्तमान जॉब पूरा करें, फिर exit करें। अगर कोई प्रोसेस बीच में क्रैश कर जाए, तो एक सरल नियम अपनाएँ: running में फँसी जॉब्स जो टाइमआउट से पुराने हैं उन्हें पिरियॉडिक "reaper" टास्क द्वारा फिर से कतारबद्ध माना जाए।
अगर आप Koder.ai पर बना रहे हैं, तो यह डेटाबेस-क्यू पैटर्न ईमेल, रिपोर्ट और वेबहुक्स के लिए एक ठोस डिफ़ॉल्ट है इससे पहले कि आप विशेष क्यू सर्विस जोड़ें।
रिट्राइज़ वह तरीका है जिससे क्यू असली दुनिया की गड़बड़ी में शांत रहती है। स्पष्ट नियमों के बिना, रिट्राइज़ शोरगुल में बदल जाते हैं जो उपयोगकर्ताओं को स्पैम करते हैं, APIs को हरा देते हैं, और असली बग को छुपाते हैं।
शुरू में तय करें क्या रिट्राई होना चाहिए और क्या फेल फास्ट होना चाहिए।
अस्थायी समस्याओं पर रिट्राई करें: नेटवर्क टाइमआउट, 502/503 त्रुटियाँ, rate limits, या छोटा डेटाबेस कनेक्शन ब्लिप।
जिन मामलों में जॉब सफल नहीं होगा, वहां तुरंत फेल करें: मिसिंग ईमेल पता, वेबहुक का 400 रिस्पॉन्स क्योंकि पेलोड अमान्य है, या किसी हटाए गए अकाउंट के लिए रिपोर्ट रिक्वेस्ट।
बैकऑफ प्रयासों के बीच की देरी है। लिनियर बैकऑफ (5s, 10s, 15s) सरल है, पर यह फिर भी ट्रैफ़िक की लहरें बना सकता है। Exponential backoff (5s, 10s, 20s, 40s) लोड को बेहतर फैलाता है और आम तौर पर वेबहुक्स और थर्ड-पार्टी प्रोवाइडर्स के लिए सुरक्षित होता है। थोड़ी सी jitter (रैंडम अतिरिक्त देरी) जोड़ें ताकि हजारों जॉब्स एक ही सेकंड में नहीं दोबारा कोशिश करें।
प्रोडक्शन में व्यवहार करने वाले नियम:
Max attempts नुकसान सीमित करने के बारे में है। कई टीमों के लिए 5 से 8 प्रयास पर्याप्त होते हैं। उसके बाद, रिट्राई रोको और जॉब को समीक्षा के लिए पार्क करो (dead-letter flow) बजाय उसके लगातार घूमने के।
Timeouts "zombie" जॉब्स को रोकते हैं। ईमेल के लिए प्रति प्रयास 10–20 सेकंड का टाइमआउट ठीक हो सकता है। वेबहुक्स के लिए अक्सर 5–10 सेकंड छोटा लिमिट चाहिए, क्योंकि रिसीवर डाउन हो सकता है और आप आगे बढ़ना चाहेंगे। रिपोर्ट जनरेशन मिनट ले सकती है, पर उसे भी एक हार्ड कटऑफ होना चाहिए।
यदि आप यह Koder.ai में बना रहे हैं, तो should_retry, next_run_at, और idempotency key को प्राथमिक फ़ील्ड मानें। ये छोटे विवरण सिस्टम को शांत रखने में मदद करते हैं जब कुछ गलत होता है।
डेड-लेट्टर स्थिति उन जॉब्स के लिए है जो आगे रिट्राई करना सुरक्षित या उपयोगी नहीं है। यह मौन विफलता को कुछ ऐसा बनाता है जिसे आप देख सकते हैं, खोज सकते हैं और उस पर कार्रवाई कर सकते हैं।
इतना रखें कि क्या हुआ यह समझ में आए और बिना अनुमान के जॉब को फिर से चलाया जा सके, पर सीक्रेट्स के बारे में सावधान रहें।
रखें:
यदि payload में टोकन या पर्सनल डेटा है, तो स्टोर करने से पहले redaction या encryption करें।
जब जॉब डेड-लेट्टर पर पहुँचता है, तो जल्दी निर्णय लें: retry करें, ठीक करें, या अनदेखा करें।
Retry बाहरी आउटेज और टाइमआउट के लिए है। Fix खराब डेटा (missing email, गलत वेबहुक URL) या आपके कोड में बग के लिए है। Ignore कम ही होना चाहिए, पर तभी वैध है जब जॉब अब अप्रासंगिक हो (उदा. कस्टमर ने अपना अकाउंट डिलीट कर दिया)। अगर आप ignore करते हैं, तो कारण रिकॉर्ड करें ताकि जॉब गायब न लगे।
कहानचाल requeue सबसे सुरक्षित तब है जब वह एक नई जॉब बनाता है और पुरानी जॉब अपरिवर्तनीय रहती है। डेड-लेट्टर जॉब पर लिखें किसने उसे फिर से कतारबद्ध किया, कब और क्यों, फिर एक नई कॉपी नई ID के साथ enqueue करें।
अलर्टिंग के लिए उन संकेतों पर नज़र रखें जो आमतौर पर असली दर्द बताते हैं: डेड-लेट्टर की गिनती तेजी से बढ़ रही है, एक ही त्रुटि कई जॉब्स में बार-बार दिख रही है, और पुराने कतारबद्ध जॉब्स जिन्हें कोई क्लेम नहीं कर रहा।
यदि आप Koder.ai उपयोग कर रहे हैं, तो स्नैपशॉट्स और रोलबैक मदद कर सकते हैं जब कोई खराब रिलीज अचानक फेल्योर spike करे — इससे आप जल्दी पीछे हट सकते हैं और जांच कर सकते हैं।
अंत में, वेंडर आउटेज के लिए सुरक्षा वाल्व जोड़ें। प्रदाता के प्रति भेजे जाने वाले संदेशों की दर सीमित करें, और सर्किट ब्रेकर का उपयोग करें: अगर किसी वेबहुक एंडपॉइंट पर लगातार विफलता आ रही है, तो उनकी सर्वर (और अपने) को बाढ़ से बचाने के लिए कुछ समय के लिए नए प्रयास रोक दें।
क्यू तब सबसे अच्छा काम करता है जब हर जॉब प्रकार के स्पष्ट नियम हों: सफल क्या माना जाएगा, क्या रिट्राई होगा, और क्या कभी दो बार नहीं होना चाहिए।
ईमेल। अधिकांश ईमेल फेल्योर अस्थायी होते हैं: प्रोवाइडर टाइमआउट, रेट लिमिट्स, या छोटे आउटेज। इन्हें रिट्राई योग्य मानें, बैकऑफ के साथ। डुप्लिकेट भेजने का बड़ा जोखिम होता है, इसलिए ईमेल जॉब्स को idempotent बनाएं। स्थिर डेडुप कीज़ स्टोर करें जैसे user_id + template + event_id और अगर वह की पहले से भेजी गई दिखे तो भेजना न करें।
यह भी उपयोगी है कि टेम्पलेट नाम और वर्शन (या रेंडर्ड subject/body का हैश) स्टोर करें। अगर आपको कभी जॉब्स पुन:चलाने पड़ें, तो आप चुन सकते हैं कि वही कंटेंट दोबारा भेजना है या नवीनतम टेम्पलेट से रेंडर करना है। अगर प्रोवाइडर एक message ID लौटाता है तो उसे सेव करें ताकि सपोर्ट ट्रेस कर सके क्या हुआ।
रिपोर्ट्स। रिपोर्ट्स अलग तरह से फेल होती हैं। ये मिनट्स ले सकती हैं, pagination लिमिट्स से टकरा सकती हैं, या अगर सब कुछ एक साथ किया जाए तो मेमोरी खत्म कर सकती हैं। काम को छोटे हिस्सों में बांटें। एक आम पैटर्न: एक "report request" जॉब कई "page" (या "chunk") जॉब्स बनाता है, हर एक डाटा का एक स्लाइस प्रोसेस करता है।
यूज़र को इंतज़ार न करवाकर परिणाम डाउनलोड के लिए स्टोर करें। यह एक डेटाबेस टेबल हो सकती है जिसे report_run_id से की गया हो, या एक फ़ाइल रेफरेंस साथ में मेटाडेटा (status, row count, created_at)। प्रोग्रेस फ़ील्ड जोड़ें ताकि UI "processing" बनाम "ready" बिना अनुमान लगाए दिखा सके।
वेबहुक्स। वेबहुक्स डिलीवरी विश्वसनीयता के बारे में हैं, न कि स्पीड के। हर रिक्वेस्ट पर सिग्नेचर जोड़ें (उदा. HMAC shared secret के साथ) और उनकी रोकथाम के लिए टाइमस्टैम्प शामिल करें। केवल तब रिट्राई करें जब रिसीवर बाद में सफल हो सके।
सरल नियम सेट:
ऑर्डरिंग और प्रायोरिटी। अधिकांश जॉब्स को क़ठोर ऑर्डरिंग की जरूरत नहीं होती। जब ऑर्डर मायने रखता है, तो सामान्यतः वह per-key (प्रति-यूज़र, प्रति-इन्क्वॉयस, प्रति-वेबहुक एंडपॉइंट) होता है। group_key जोड़ें और प्रति key केवल एक इन-फ्लाइट जॉब चलाएँ।
प्रायोरिटी के लिए, जरूरी काम को धीमे काम से अलग रखें। एक बड़ा रिपोर्ट बैकलॉग पासवर्ड रीसेट ईमेल्स को देरी नहीं कर सकता।
उदाहरण: खरीद के बाद आप एन्क्यू करते हैं (1) ऑर्डर कन्फर्मेशन ईमेल, (2) पार्टनर वेबहुक, और (3) रिपोर्ट अपडेट जॉब। ईमेल जल्दी रिट्राई कर सकता है, वेबहुक लंबा बैकऑफ लेता है, और रिपोर्ट बाद में कम प्रायोरिटी पर चलती है।
उपयोगकर्ता आपके ऐप के लिए साइन अप करता है। तीन चीजें होनी चाहिए, पर कोई भी साइनअप पेज को धीमा न करे: welcome email भेजना, आपके CRM को वेबहुक से सूचित करना, और उपयोगकर्ता को नाइटली एक्टिविटी रिपोर्ट में शामिल करना।
यूज़र रिकॉर्ड बनाने के ठीक बाद, अपनी डेटाबेस क्यू में तीन जॉब पंक्तियाँ लिखें। हर पंक्ति में एक प्रकार, एक payload (जैसे user_id), एक स्थिति, एक attempt count, और next_run_at timestamp होता है।
एक सामान्य लाइफसाइकिल कुछ इस तरह दिखता है:
queued: बनाई गई और वेट कर रही हैrunning: किसी वर्कर ने इसे क्लेम किया हैsucceeded: पूरा हो गया, और आगे काम नहीं हैfailed: विफल हुआ, बाद में शेड्यूल या retries खत्म हो गएdead: बहुत बार फेल हुआ और इंसान की जांच चाहिएवेलकम ईमेल जॉब में welcome_email:user:123 जैसा idempotency key शामिल होगा। भेजने से पहले, वर्कर कम्पलीट idempotency keys की टेबल चेक करता है (या यूनिक कंस्ट्रेंट लागू करता है)। अगर जॉब दो बार चलता है क्योंकि क्रैश हुआ, दूसरी बार की में key दिखेगी और भेजना स्किप कर दिया जाएगा। कोई डबल वेलकम ईमेल नहीं।
अब CRM वेबहुक एंडपॉइंट डाउन है। वेबहुक जॉब टाइमआउट के साथ फेल हो जाता है। आपका वर्कर बैकऑफ के साथ रिट्राई शेड्यूल करता है (उदा.: 1 मिनट, 5 मिनट, 30 मिनट, 2 घंटे) और थोड़ा jitter ताकि कई जॉब्स एक ही सेकंड में रिट्राई न करें।
मैक्स अटेम्प्ट्स के बाद, जॉब dead बन जाता है। उपयोगकर्ता अभी भी साइन अप हो चुका है, वेलकम ईमेल मिल गया है, और नाइटली रिपोर्ट जॉब सामान्य रूप से चल सकती है। केवल CRM नोटिफिकेशन अटका हुआ है और यह दिखाई देता है।
अगली सुबह, सपोर्ट (या ऑन-कॉल) उसे बिना घंटों लॉग्स खोदे हैंडल कर सकता है:
webhook.crm).यदि आप Koder.ai जैसे प्लेटफ़ॉर्म पर ऐप बनाते हैं, तो वही पैटर्न लागू होता है: यूज़र फ्लो तेज रखें, साइड-इफेक्ट्स को जॉब्स में धकेलें, और फेल्योर को आसान तरीके से निरीक्षण और दोबारा चलाने योग्य बनाएं।
क्यू को तोड़ने का सबसे तेज़ तरीका इसे वैकल्पिक मानना है। टीमें अक्सर शुरू में कहती हैं "इस एक बार के लिए रिक्वेस्ट में ईमेल भेज देते हैं" क्योंकि यह सरल लगता है। फिर यह फैल जाता है: पासवर्ड रीसेट्स, रसीदें, वेबहुक्स, रिपोर्ट एक्सपोर्ट। जल्दी ही ऐप धीमा लगने लगता है, टाइमआउट बढ़ते हैं, और कोई भी थर्ड-पार्टी हिचकी आपकी आउटेज बन जाती है।
एक और आम जाल idempotency को छोड़ना है। अगर जॉब दो बार चल सकता है, तो उसे दो परिणाम नहीं बनाना चाहिए। बिना idempotency के, retries डुप्लिकेट ईमेल, बार-बार वेबहुक इवेंट्स या उससे भी बदतर समस्याएँ पैदा कर सकते हैं।
तीसरी समस्या विज़िबिलिटी की कमी है। अगर आप केवल सपोर्ट टिकट से फेल्यर्स के बारे में पता लगाते हैं, तो क्यू पहले ही उपयोगकर्ताओं को नुकसान पहुँचा रही होती है। भले ही एक बेसिक इंटरनल व्यू जो जॉब काउंट्स बाय स्टेटस और searchable last_error दिखाए, वह बहुत समय बचा देता है।
कुछ समस्याएँ जल्दी दिखती हैं, यहां तक कि साधारण क्यू में भी:
बैकऑफ खुद-निर्मित आउटेज को रोकता है। यहां तक कि एक बुनियादी शेड्यूल जैसे 1 मिनट, 5 मिनट, 30 मिनट, 2 घंटे विफलता को सुरक्षित बनाता है। साथ में max attempts सेट करें ताकि एक टूटी हुई जॉब रुक जाए और दिखाई दे।
अगर आप Koder.ai पर बना रहे हैं, तो इन बुनियादियों को फीचर के साथ ही शिप करना मददगार होता है, न कि कुछ हफ्तों बाद सफाई परियोजना के रूप में।
नए टूल्स जोड़ने से पहले, सुनिश्चित करें कि बुनियादी बातें मजबूत हैं। एक डाटाबेस-बैक्ड क्यू तब अच्छा काम करता है जब हर जॉब को क्लेम करना आसान हो, रिट्राई करना आसान हो, और निरीक्षण करना आसान हो।
एक त्वरित भरोसेमंदी चेकलिस्ट:
अगला कदम: अपने पहले तीन जॉब प्रकार चुनें और उनके नियम लिखें। उदाहरण के लिए: पासवर्ड रीसेट ईमेल (तेज़ रिट्राइज़, छोटा max), नाइटली रिपोर्ट (कम रिट्राइज़, लंबे टाइमआउट), वेबहुक डिलीवरी (अधिक रिट्राइज़, लंबा बैकऑफ, स्थायी 4xx पर रोक)।
अगर आपको संदेह है कि कब डेटाबेस क्यू पर्याप्त नहीं है, तो इन संकेतों पर नजर रखें: कई वर्कर्स से row-level contention, बहुत सख्त ordering ज़रूरतें कई जॉब प्रकारों में, बड़े फैन-आउट (एक इवेंट हजारों जॉब्स trigger करता है), या क्रॉस-सर्विस कंजम्पशन जहाँ अलग टीमें अलग वर्कर्स की जिम्मेदारी लेती हैं।
अगर आप एक तेज़ प्रोटोटाइप चाहते हैं, तो आप Koder.ai (koder.ai) में Planning mode में फ्लो स्केच कर सकते हैं, jobs तालिका और वर्कर लूप जनरेट कर सकते हैं, और स्नैपशॉट्स और रोलबैक के साथ deploy से पहले iterate कर सकते हैं।
यदि कोई टास्क एक या दो सेकंड से अधिक ले सकता है, या वह किसी नेटवर्क कॉल (ईमेल प्रदाता, वेबहुक एंडपॉइंट, धीली क्वेरी) पर निर्भर करता है, तो उसे बैकग्राउंड जॉब में डालें.
यूज़र रिक्वेस्ट को इनपुट वैलिडेट करने, मुख्य डेटा परिवर्तन लिखने, जॉब enqueue करने और तेज़ प्रतिक्रिया देने पर केंद्रित रखें।
डाटाबेस-बैक्ड क्यू से शुरू करें जब:
बहुत उच्च थ्रूपुट, कई स्वतंत्र कंस्यूमर्स, या क्रॉस-सर्विस इवेंट रीप्ले की ज़रूरत होने पर ही आप ब्रोकर्स/स्ट्रीमिंग टूल जोड़ें।
ऐसी फ़ील्ड जो ये सवाल जल्दी उत्तर दें: क्या करना है, अगली बार कब आज़माना है, और पिछली बार क्या हुआ।
प्रैक्टिकल न्यूनतम:
इनपुट्स स्टोर करें, बड़े आउटपुट्स नहीं।
अच्छे payloads:
user_id, template, report_id)बचें:
कुंजी है एक एटॉमिक “क्लेम” स्टेप ताकि दो workers एक ही जॉब न ले लें.
Postgres में सामान्य तरीका:
FOR UPDATE SKIP LOCKED)running मार्क करें और locked_at/locked_by सेट करेंइस तरह workers हॉरिज़ॉन्टली स्केल कर सकते हैं बिना डबल-प्रोसेसिंग के।
मान लें कि जॉब कभी-कभी दो बार चल सकता है (क्रैश, टाइमआउट, रिट्राई)। साइड-इफेक्ट को सुरक्षित बनाएं.
सरल पैटर्न:
idempotency_key जोड़ें जैसे welcome_email:user:123यह विशेष रूप से ईमेल और वेबहुक्स के लिए जरूरी है ताकि डुप्लिकेट से बचा जा सके।
एक साफ़ डिफॉल्ट पॉलिसी अपनाएँ:
स्थायी त्रुटियों (जैसे missing email, invalid payload, अधिकांश 4xx) पर फ़ेल फास्ट करें।
Dead-letter का मतलब है “रिट्राई बंद करो और इसे दिखाई देने लायक बनाओ।” इसका उपयोग तब करें जब:
max_attempts पार हो गया होकौन-कौन सी चीज़ें रखें:
दो नियम अपनाएँ:
running जॉब्स को जो threshold से पुराने हैं, फिर से enqueue करे (या failed मार्क करे)इससे worker क्रैश के बाद सिस्टम अपने आप recover कर सकता है बिना मैनुअल क्लीनअप के।
धीमी वर्क को तेज़ काम को ब्लॉक न करने दें:
जब order matter करे, अक्सर वह per-key होता है (प्रति-ग्रह/यूज़र)। group_key जोड़ें और एक ही key पर सिर्फ़ एक इन-फ्लाइट जॉब चलाने का नियम रखें।
job_type, payloadstatus (queued, running, succeeded, failed, dead)attempts, max_attemptsnext_run_at, साथ में created_atlocked_at, locked_bylast_erroridempotency_key (या कोई अन्य डिडुप मेकेनिज्म)अगर जॉब को बड़ा डेटा चाहिए तो एक रेफरेंस स्टोर करें (report_run_id या फ़ाइल key) और worker रन के समय वास्तविक कंटेंट फेच करें।
last_error और वेबहुक के लिए अंतिम status codeरीप्ले करते समय नई जॉब बनाना सुरक्षित रहता है और पुरानी जॉब अपरिवर्तनीय रखें।