21 सित॰ 2025·8 मिनट
एरिक ब्रूअर का CAP विचार: क्यों वितरित प्रणालियाँ ट्रेड-ऑफ करती हैं
CAP थ्योरम को एक व्यावहारिक मानसिक मॉडल के रूप में समझें: कैसे Consistency, Availability और Partitions वितरित प्रणालियों के फैसलों को आकार देते हैं।
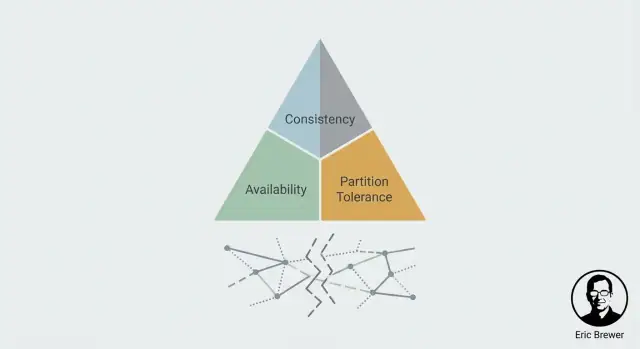
CAP थ्योरम को एक व्यावहारिक मानसिक मॉडल के रूप में समझें: कैसे Consistency, Availability और Partitions वितरित प्रणालियों के फैसलों को आकार देते हैं।
जब आप एक ही डेटा को एक से अधिक मशीनों पर स्टोर करते हैं, तो आपको गति और फॉल्ट टॉलरेंस मिलता है—लेकिन इसके साथ एक नई समस्या भी आती है: असहमति। दो सर्वर अलग अपडेट पा सकते हैं, संदेश देर से या बिल्कुल नहीं पहुँचते, और उपयोगकर्ताओं को अलग-अलग उत्तर मिल सकते हैं कि वे किस रेप्लिका से जुड़े हैं। CAP इसलिए लोकप्रिय हुआ क्योंकि यह इंजीनियरों को उस गंदली रियलिटी के बारे में बिना लंबी बात के साफ़ भाषा देता है।
एरिक ब्रूअर, कंप्यूटर वैज्ञानिक और Inktomi के सह-संस्थापक, ने 2000 में प्रतिकृत प्रणालियों में विफलता के समय के लिए मूल विचार पेश किया। यह जल्दी फैल गया क्योंकि यह उन अनुभवों से मेल खाता था जो टीमें प्रोडक्शन में पहले से देख रही थीं: वितरित प्रणालियाँ सिर्फ़ बंद होकर विफल नहीं होतीं; वे टुकड़ों में टूटती हैं।
CAP तब सबसे उपयोगी है जब चीजें गलत होती हैं—खासकर जब नेटवर्क ठीक तरह से व्यवहार नहीं करता। एक सामान्य दिन में, कई सिस्टम पर्याप्त रूप से संगत और उपलब्ध दिख सकते हैं। असली परीक्षा तब है जब मशीनें भरोसेमंद तरीके से संवाद नहीं कर पातीं और आपको तय करना होता है कि विभाजन के दौरान पढ़ने और लिखने के साथ क्या करना है।
यही फ्रेमिंग CAP को एक लोकप्रिय मानसिक मॉडल बनाती है: यह सर्वोत्तम प्रैक्टिस पर बहस नहीं करता; यह एक ठोस प्रश्न थोपता है—विभाजन के दौरान हम क्या कुर्बान करेंगे?
इस लेख के अंत तक, आप सक्षम होंगे:
CAP आज भी इसलिए प्रासंगिक है क्योंकि यह 'वितरित मुश्किल है' जैसी धुंधली बातों को एक ऐसा निर्णय बनाता है जिसे आप बना सकते हैं—और बचाव कर सकते हैं।
एक वितरित प्रणाली साधारण शब्दों में है, कई कंप्यूटर जो एक होने की तरह काम करने की कोशिश कर रहे हों। आपके पास कई सर्वर हो सकते हैं अलग-अलग रैक, रीजन, या क्लाउड ज़ोन में, लेकिन उपयोगकर्ता के लिए यह 'ऐप' या 'डाटाबेस' ही होता है।
इस साझा सिस्टम को रियल-वर्ल्ड स्केल पर काम कराने के लिए, हम आमतौर पर रिप्लिकेशन करते हैं: एक ही डेटा की कई प्रतियाँ अलग मशीनों पर रखी जाती हैं।
रिप्लिकेशन तीन व्यावहारिक कारणों से लोकप्रिय है:
अब तक, रिप्लिकेशन एक सीधा लाभ जैसा लगता है। जाल यही है कि रिप्लिकेशन एक नया काम जोड़ देता है: सभी प्रतियों को सहमत रखना।
यदि हर रेप्लिका हमेशा तुरंत एक-दूसरे से बात कर सके, तो वे अपडेट समन्वयित कर सकेंगे और संरेखित रहेंगे। लेकिन असल नेटवर्क परफेक्ट नहीं होते। संदेश देरी से आ सकते हैं, गिरे हुए हो सकते हैं, या विफलताओं के चारों ओर रूट किए जा सकते हैं।
जब संचार स्वस्थ होता है, तो रेप्लिकाएँ अक्सर अपडेट्स साझा कर समरूप हो जाती हैं। लेकिन जब संचार टूटता है (भले ही अस्थायी), तो आप दो वैध-नज़र आने वाले 'सत्य' संस्करणों के साथ फँस सकते हैं।
उदाहरण के लिए, एक उपयोगकर्ता अपना शिपिंग पता बदलता है। रेप्लिका A को अपडेट मिलता है, रेप्लिका B को नहीं। अब सिस्टम को एक साधारण सवाल का जवाब देना होगा: वर्तमान पता क्या है?
यह अंतर है:
CAP सोच यहीं से शुरू होती है: एक बार रिप्लिकेशन मौजूद है, संचार विफलता के दौरान असहमति कोई किनारा-मामला नहीं—यह केंद्रीय डिजाइन समस्या है।
CAP एक मानसिक मॉडल है जो बताता है कि जब सिस्टम कई मशीनों में फैला होता है तब उपयोगकर्ता वास्तव में क्या महसूस करते हैं। यह 'अच्छा' या 'बुरा' सिस्टम नहीं बताता—सिर्फ़ वह तनाव जिसे आपको संभालना है।
सामंजस्य का मतलब है सहमति। अगर आप कुछ अपडेट करते हैं, क्या अगली रीड (कहीं से भी) उस अपडेट को दिखाएगी?
उपयोगकर्ता के नज़रिए से, यह फर्क है 'मैंने अभी बदला और हर कोई वही नया मान देखता है' और 'कुछ लोग कुछ समय के लिए पुराना मान देखते रहते हैं' के बीच।
उपलब्धता का मतलब है कि सिस्टम अनुरोधों (रीड और राइट) का सफल परिणाम देता है। जरूरी नहीं कि 'सबसे तेज़', पर यह 'आपको सेवा देने से इंकार नहीं करता'।
समस्याओं के दौरान (सर्वर डाउन, नेटवर्क हिचकिचाहट), एक उपलब्ध सिस्टम अनुरोध लेना जारी रखेगा, भले ही उसे थोड़ी पुरानी जानकारी के साथ उत्तर देना पड़े।
एक पार्टिशन तब होता है जब नेटवर्क विभाजित हो: मशीनें चल रही होती हैं, पर उनके बीच संदेश नहीं पहुँच पाते (या उपयोगी रूप से देर से पहुँचते हैं)। वितरित प्रणालियों में आप इसे असंभव मानकर नहीं चल सकते—आपको यह परिभाषित करना होगा कि ऐसा होने पर व्यवहार क्या होगा।
सोचिए दो रीटेल शॉप्स हैं जो एक ही प्रोडक्ट बेचती हैं और '1 इन्वेंटरी काउंट' साझा करती हैं। ग्राहक Shop A से आख़िरी आइटम खरीदता है, तो Shop A लिखता है inventory = 0। उसी समय, एक नेटवर्क विभाजन Shop B को इसके बारे में सुनने से रोकता है।
अगर Shop B उपलब्ध रहता है, तो वह एक आइटम बेच सकता है जो उसके पास वास्तविक में नहीं है (विभाजन के दौरान सेल स्वीकार करना)। अगर Shop B सामंजस्य लागू करे, तो वह विभाजन तक पुष्टि करने तक बिक्री अस्वीकार कर सकता है (विभाजन के दौरान सेवा अस्वीकार करना)।
'विभाजन' सिर्फ़ 'इंटरनेट डाउन' नहीं है। यह कोई भी स्थिति है जहाँ आपके सिस्टम के हिस्से भरोसेमंद ढंग से एक-दूसरे से बात नहीं कर पाते—यहाँ तक कि हर हिस्सा ठीक चल रहा हो।
रिप्लिकेट सिस्टम में, नोड लगातार संदेशों का आदान-प्रदान करते हैं: लिखाइयाँ, स्वीकृतियाँ, हार्टबीट, लीडर चुनाव, रीड रिक्वेस्ट। एक विभाजन तब होता है जब वे संदेश पहुँचना बंद कर दें (या उपयोगी ढंग से देर से पहुँचें), जिससे वास्तविकता के बारे में असहमति पैदा होती है: 'क्या लिखाई हुई?', 'कौन लीडर है?', 'क्या नोड B ज़िंदा है?'
संचार गड़बड़ियाँ बेढंगे, आंशिक तरीकों से होती हैं:
महत्वपूर्ण बात: विभाजन अक्सर डिग्रेडेशन होते हैं, न कि साफ़ ऑन/ऑफ आउटेज। एप्लिकेशन के दृष्टिकोण से, 'काफ़ी धीमा' और 'डाउन' के बीच फर्क अक्सर न के बराबर होता है।
जैसे-जैसे आप अधिक मशीनें, नेटवर्क, रीजन और चलती चीज़ें जोड़ते हैं, संचार टूटने के अवसर बढ़ते हैं। यहां तक कि यदि व्यक्तिगत घटक भरोसेमंद हैं, कुल मिलाकर सिस्टम विफलताओं का अनुभव करता है क्योंकि उसमें अधिक निर्भरताएँ और अधिक क्रॉस-नोड समन्वय होते हैं।
आपको किसी सटीक विफलता दर माननी नहीं है यह स्वीकार करने के लिए: यदि आपका सिस्टम लंबा समय चलता है और पर्याप्त इन्फ्रास्ट्रक्चर फैलाता है, तो विभाजन होंगे।
विभाजन सहनशीलता का अर्थ है कि आपकी प्रणाली विभाजन के दौरान भी काम करना जारी रखती है—यहाँ तक कि जब नोड्स सहमत नहीं हो सकते या यह पुष्टि नहीं कर सकते कि दूसरे पक्ष ने क्या देखा है। इससे एक विकल्प ज़ोर देकर सामने आता है: या तो अनुरोध स्वीकार करते रहें (संगति का जोखिम) या कुछ अनुरोधों को रोक/अस्वीकार कर दें (संगति बनाए रखें)।
एक बार जब आपके पास रिप्लिकेशन हो, तो विभाजन बस एक संचार ब्रेक है: प्रणाली के दो हिस्से कुछ समय के लिए भरोसेमंद तरीके से बात नहीं कर पाते। रेप्लिकाएँ अभी भी चल रही हैं, उपयोगकर्ता अभी भी क्लिक कर रहे हैं, और आपकी सेवा अनुरोध प्राप्त कर रही है—पर रेप्लिकाएँ नवीनतम सत्य पर सहमत नहीं हो सकतीं।
इसी एक वाक्य में CAP तनाव है: विभाजन के दौरान, आपको Consistency (C) या Availability (A) में से किसी एक को प्राथमिकता देनी होगी। आप एक साथ दोनों नहीं पा सकते।
आप कह रहे हैं: 'मैं प्रतिक्रियाशील होने से ज्यादा सही होना पसंद करूँगा।' जब सिस्टम यह पुष्टि नहीं कर सकता कि कोई अनुरोध सभी रेप्लिकाओं को सिंक में रखेगा, तो उसे फेल या वेट करना होगा।
व्यवहारिक असर: कुछ उपयोगकर्ताओं को त्रुटियाँ, टाइमआउट, या 'पुनः प्रयास करें' संदेश दिखेंगे—खासतौर पर उन ऑपरेशनों के लिए जो डेटा बदलते हैं। यह आम है जब आप दो बार चार्ज करने का जोखिम लेने से बेहतर कुछ ट्रांज़ैक्शन अस्वीकार कर देते हैं, या किसी सीट आरक्षण में ओवरसेल से बचते हैं।
आप कह रहे हैं: 'मैं ब्लॉक होने से बेहतर तुरंत उत्तर देना पसंद करूँगा।' विभाजन के हर पक्ष पर अनुरोध स्वीकार करना जारी रहेगा, भले ही वे समन्वय न कर पाएं।
व्यवहारिक असर: उपयोगकर्ताओं को सफल उत्तर मिलेंगे, पर वे जो डेटा पढ़ते हैं वह स्टेल हो सकता है, और समकालिक अपडेट संगर्ष कर सकते हैं। आप बाद में समेकन पर भरोसा करते हैं (मर्ज नियम, अंतिम-लिखाई-विजेता, मैन्युअल समीक्षा, आदि)।
यह हमेशा एक वैश्विक सेटिंग नहीं होती। कई उत्पाद रणनीतियाँ मिलाकर चलते हैं:
मुख्य क्षण यह तय करना है—प्रति ऑपरेशन—कि अब एक उपयोगकर्ता को ब्लॉक करना खराब है, या बाद में विरोधाभास ठीक करना।
'दो चुनें' स्लोगन यादगार है, पर यह अक्सर लोगों को यह गलत सोचने पर मजबूर करता है कि CAP तीन फीचर्स की एक मेन्यू है जहाँ आप हमेशा सिर्फ़ दो रख सकते हैं। CAP इस बारे में है कि क्या होता है जब नेटवर्क सहयोग करना बंद कर दे: विभाजन के दौरान, एक वितरित प्रणाली को या तो संगत उत्तर लौटाने या हर अनुरोध के लिए उपलब्ध रहने के बीच चुनना होगा।
वास्तविक वितरित प्रणालियों में, विभाजन कोई ऐसा सेटिंग नहीं है जिसे आप डिसेबल कर दें। यदि आपका सिस्टम मशीनों, रैक्स, जोन या रीजन पर फैला है, तो संदेश देर हो सकते हैं, ड्रॉप हो सकते हैं, या अजीब तरह रूट हो सकते हैं। यह सॉफ़्टवेयर की नज़र से ही विभाजन है: नोड्स भरोसेमंद तरीके से क्या हो रहा है इसमें समन्वय नहीं कर पाते।
यहाँ तक कि भौतिक नेटवर्क ठीक भी हो, अन्य विफलताएँ वही प्रभाव पैदा कर सकती हैं—ओवरलोडेड नोड्स, GC पॉज़, noisy neighbors, DNS हिचकियाँ, फ्लेकी लोड बैलेंसर। नतीजा वही है: सिस्टम के कुछ हिस्से दूसरों के साथ समन्वय करने के लिए 'काफ़ी' संवाद नहीं कर पाते।
एप्लिकेशन विभाजन को एक साफ़, बाइनरी इवेंट के रूप में अनुभव नहीं करते। वे लेटेंसी स्पाइक्स और टाइमआउट अनुभव करते हैं। अगर एक अनुरोध 200ms के बाद टाइमआउट हो जाता है, तो यह मायने नहीं रखता कि पैकेट 201ms पर आया या कभी नहीं आया: ऐप को अगले कदम का फैसला करना होगा। एप्लिकेशन के लिए, धीमा संचार अक्सर टूटे संचार जैसा ही होता है।
कई वास्तविक सिस्टम ऑपरेटिंग कंडीशन्स और कॉन्फ़िगरेशन के आधार पर ज्यादातर संगत या ज्यादातर उपलब्ध दिखते हैं। टाइमआउट, रिट्राई पॉलिसी, क्वोरम साइज और 'रीड-योर-राइट्स' विकल्प व्यवहार को बदल सकते हैं।
सामान्य परिस्थितियों में एक डेटाबेस मजबूत सामंजस्य दिख सकता है; तनाव या क्रॉस-रीजन हिचकियों के दौरान यह अनुरोध अस्वीकार करने लगेगा (संगति को प्राथमिकता) या पुराना डेटा लौटाने लगेगा (उपलब्धता को प्राथमिकता)।
CAP का मकसद उत्पादों को लेबल करना नहीं, बल्कि यह समझना है कि जब असहमति होती है तब आप किस ट्रेड-ऑफ को बना रहे हैं—खासतौर पर जब असहमति साधारण धीमेपन से पैदा होती है।
CAP चर्चाएँ अक्सर सामंजस्य को द्विआधारी बनाती हैं: या तो 'परफेक्ट' या 'कुछ भी चलेगा'। वास्तविक सिस्टम गारंटी का एक मेन्यू देते हैं, जिनमें से प्रत्येक का विफलता के दौरान अलग उपयोगकर्ता अनुभव होता है।
मजबूत सामंजस्य (अक्सर 'linearizable' व्यवहार) का अर्थ है कि एक बार लिखाई स्वीकार कर ली गई, तो किसी भी बाद की रीड—किसी भी रेप्लिका से—उस लिखाई को लौटाएगी।
क्या लागत आती है: विभाजन या जब अल्पसंख्यक रेप्लिकाएँ पहुंच से बाहर हों, तो सिस्टम रीड/राइट विलंबित या अस्वीकार कर सकता है ताकि विरोधाभासी राज्य न दिखे। उपयोगकर्ता इसे टाइमआउट्स, 'फिर प्रयास करें', या अस्थायी रूप से केवल-पढ़ने के रूप में अनुभव कर सकते हैं।
इवेंटुअल कंसिस्टेंसी वादा करती है कि अगर नए अपडेट नहीं होते हैं, तो सभी रेप्लिकाएँ समय के साथ समरूप हो जाएँगी। यह यह वादा नहीं करती कि अभी दो उपयोगकर्ता एक साथ पढ़ते समय एक ही चीज़ देखेंगे।
उपयोगकर्ता जो नोटिस कर सकते हैं: हाल में बदला गया प्रोफ़ाइल फोटो कुछ समय के लिए 'वापस' लग सकता है, काउंटर पीछे रह सकते हैं, या अभी भेजा गया संदेश दूसरी डिवाइस पर कुछ देर के लिए नहीं दिखना।
आप अक्सर पूर्ण मजबूत सामंजस्य की मांग किए बिना बेहतर अनुभव खरीद सकते हैं:
ये गारंटियाँ उपयोगकर्ता की सोच से अच्छी तरह मेल खाती हैं ('मेरा खुद का परिवर्तन गायब न दिखे') और आंशिक विफलताओं के दौरान बनाए रखना आसान हो सकता है।
उपयोगकर्ता वादों से शुरू करें, शब्दज़ाल से नहीं:
सामंजस्य एक उत्पाद निर्णय है: यह परिभाषित करें कि उपयोगकर्ता के लिए 'गलत' कैसा दिखता है, फिर वह सबसे कम कड़ी गारंटी चुनें जो उस 'गलत' को रोक दे।
CAP में उपलब्धता एक विज़िटर-शानदार नंबर नहीं है ('पाँच नौ'); यह उपयोगकर्ताओं को दिया गया वादा है कि जब सिस्टम सुनिश्चित नहीं कर सकता तो क्या होता है।
जब रेप्लिकाएँ सहमत नहीं हो पातीं, अक्सर आप चुनते हैं:
उपयोगकर्ता इसे इस तरह महसूस करते हैं: 'ऐप काम कर रहा है' बनाम 'ऐप सही है'। कोई भी सार्वभौमिक रूप से बेहतर नहीं है; सही चुनाव इस पर निर्भर करता है कि आपके उत्पाद में 'गलत' का क्या मतलब है। थोड़ा पुराना सोशल फ़ीड परेशान करने वाला है; पुराना अकाउंट बैलेंस हानिकारक हो सकता है।
अनिश्चितता में दो सामान्य व्यवहार दिखते हैं:
यह केवल तकनीकी कॉल नहीं है; यह एक नीति निर्णय है। उत्पाद को परिभाषित करना चाहिए कि क्या दिखाना स्वीकार्य है और क्या कभी अनुमान नहीं लगाया जाना चाहिए।
उपलब्धता शायद ही कभी सब-या-कुछ होती है। विभाजन के दौरान, आप आंशिक उपलब्धता देख सकते हैं: कुछ रीजन, नेटवर्क, या उपयोगकर्ता समूह सफल होते हैं जबकि अन्य फेल। यह जानबूझकर डिज़ाइन भी हो सकता है (जहाँ लोकल रेप्लिका स्वस्थ है वहां सर्व करना) या आकस्मिक (रूटिंग असंतुलन, असमान क्वोरम पहुंच)।
एक व्यवहारिक मध्य मार्ग है डिग्रेस्ड मोड: सुरक्षित क्रियाओं को जारी रखें और जोखिम भरी क्रियाओं को सीमित करें। उदाहरण के लिए, ब्राउज़िंग और सर्च की अनुमति दें, पर 'फंड ट्रांसफर', 'पासवर्ड बदलें', जैसी क्रियाएँ अस्थायी रूप से डिसेबल कर दें जहाँ सटीकता और यूनिकनेस अहम है।
CAP तब अमूर्त लगता है जब तक आप इसे नेटवर्क स्प्लिट के दौरान उपयोगकर्ता के अनुभव से मैप नहीं करते: क्या आप चाहते हैं कि सिस्टम उत्तर देना जारी रखे, या रुके और विरोधाभासी डेटा को स्वीकार न करे?
सोचिए दो डेटा सेंटर दोनों ऑर्डर स्वीकार करते हैं जब वे बात नहीं कर रहे।
यदि आप चेकआउट को उपलब्ध रखते हैं, तो हर तरफ आखिरी आइटम बिक सकता है और आप ओवरसेल कर लेंगे। यह कम-जोखिम वस्तुओं के लिए स्वीकार्य हो सकता है (बैकऑर्डर या माफ़ी), पर सीमित इन्वेंटरी ड्रॉप के लिए यह दर्दनाक है।
यदि आप सामंजस्य-प्राथमिक व्यवहार चुनते हैं, तो आप ऐसे समय में नए ऑर्डर ब्लॉक कर सकते हैं जब आप स्टॉक को ग्लोबली सत्यापित न कर सकें। उपयोगकर्ताओं को 'बाद में प्रयास करें' दिखेगा, पर आप कुछ बेचने जैसा जोखिम नहीं लेंगे जो आप पूरा नहीं कर सकते।
पैसा वह क्लासिक डोमेन है जहाँ गलत होना महंगा है। यदि दो रेप्लिकाएँ विभाजन के दौरान स्वतंत्र रूप से निकासी स्वीकार करती हैं, तो खाता नकारात्मक हो सकता है।
सिस्टम अक्सर महत्वपूर्ण लिखाइयों के लिए सामंजस्य पसंद करते हैं: यदि वे नवीनतम बैलेंस की पुष्टि नहीं कर सकते तो कार्रवाई अस्वीकार या विलंबित कर दें। आप कुछ उपलब्धता का त्याग कर सटीकता, ऑडिटेबिलिटी और ट्रस्ट हासिल करते हैं।
चैट और सोशल फीड्स में, उपयोगकर्ता अक्सर कुछ सेकंड की असंगति सह लेते हैं: संदेश कुछ देर बाद आता है, लाइक काउंट अलग दिखता है, व्यू मेट्रिक बाद में अपडेट होती है।
यहाँ उपलब्धता-प्राथमिक डिजाइन एक अच्छा उत्पाद विकल्प हो सकता है, बशर्ते आप स्पष्ट हों कि कौन से हिस्से 'आख़िरकार ठीक' होंगे और आप अपडेट को साफ़ तरीके से मर्ज कर सकते हैं।
'सही' CAP चुनाव इस बात पर निर्भर करता है कि 'गलत' होने की लागत क्या है: रिफंड, कानूनी जोखिम, उपयोगकर्ता ट्रस्ट, या संचालनात्मक अव्यवस्था। तय कीजिए कि आप अस्थायी स्टेलनेस कहाँ स्वीकार कर सकते हैं—और कहाँ आपको फेल क्लोज़ करना चाहिए।
एक बार आपने तय कर लिया कि विभाजन के दौरान क्या करना है, आपको ऐसे मैकेनिज़्म चाहिए जो उस फैसले को वास्तविक बनायें। ये पैटर्न डेटाबेस, मैसेज सिस्टम और API में बार-बार दिखते हैं—भले ही उत्पाद कभी 'CAP' शब्द न बोले।
क्वोरम का अर्थ है कि 'अधिकांश रेप्लिकाएँ सहमत हों।' यदि आपके पास 5 कॉपी हैं, तो बहुमत 3 है।
रीड और/या राइट के लिए बहुमत की आवश्यकता निर्धारित करके आप स्टेल या कॉन्फ्लिक्ट रिटर्न की संभावना घटाते हैं। उदाहरण के लिए, अगर लिखाई को 3 रेप्लिकाओं का ACK चाहिये, तो दो अलग-थलग समूहों द्वारा दोनों तरफ अलग सत्य स्वीकार होने की संभावना कम हो जाती है।
ट्रेडऑफ है गति और पहुँच: यदि आप बहुमत तक नहीं पहुँच पाते (विभाजन या आउटेज के कारण), तो सिस्टम ऑपरेशन अस्वीकार कर सकता है—संगति का चुनाव उपलब्धता पर।
कई 'उपलब्धता' मुद्दे असल में तेज़ प्रतिसाद नहीं बल्कि धीमी प्रतिक्रियाएँ हैं। छोटी टाइमआउट सेट करना सिस्टम को सुस्त महसूस करवा सकता है, पर इसका मतलब है कि आप धीमी सफलताओं को विफल भी मान लेंगे।
रिट्राई अस्थायी चूकें ठीक कर सकता है, पर आक्रामक रिट्राई एक पहले से संघर्षरत सेवा पर और भार डाल सकता है। बैकऑफ (रिट्राई के बीच थोड़ा और इंतज़ार) और जिटर (रैंडमनेस) मदद करते हैं कि रिट्राई ट्रैफ़िक स्पाइक में बदल न जाए।
कुंजी है इन सेटिंग्स को आपके वादे के अनुरूप करना: 'हमेशा जवाब दें' सामान्यतः अधिक रिट्राई और फ़ॉलबैक्स की माँग करता है; 'कभी झूठ नहीं बोलना' का मतलब तंग सीमा और स्पष्ट त्रुटियाँ है।
यदि आप विभाजन के दौरान उपलब्ध रहना चुनते हैं, रेप्लिकाएँ अलग अपडेट्स स्वीकार कर सकती हैं और आपको बाद में मिलाना होगा। आम दृष्टिकोण शामिल हैं:
रिट्राई डुप्लिकेट बना सकती हैं: कार्ड को दो बार चार्ज करना या उसी ऑर्डर को दो बार सबमिट करना। Idempotency इसे रोकती है।
आम पैटर्न है idempotency की (रिक्वेस्ट ID) हर अनुरोध के साथ भेजना। सर्वर पहले परिणाम को स्टोर करता है और रिपीट की स्थिति में वही परिणाम लौटाता है—इस तरह रिट्राई उपलब्धता बढ़ाते हैं बिना डेटा को गड़बड़ किए।
ज्यादातर टीमें CAP स्टैंड पर बोर्ड पर चुनती हैं—फिर प्रोडक्शन में पाता चलता है कि सिस्टम तनाव में अलग व्यवहार कर रहा है। मान्यता का मतलब है जानबूझकर वे कंडीशन बनाना जहाँ CAP ट्रेडऑफ दिखाई दें, और जांचना कि आपकी प्रणाली डिज़ाइन के अनुसार प्रतिक्रिया करती है।
किसी वास्तविक केबल कट की ज़रूरत नहीं है कुछ सीखने के लिए। स्टेजिंग में नियंत्रित फॉल्ट इंजेक्शन का उपयोग करें (और सावधानी से प्रोडक्शन में) विभाजन सिमुलेट करने के लिए:
लक्ष्य है ठोस प्रश्नों का उत्तर पाना: क्या लिखाइयाँ अस्वीकार हो जाती हैं या स्वीकार? क्या रीड स्टेल सेवा करती हैं? क्या सिस्टम अपने आप रिकवरी करता है, और समेकन में कितना समय लगता है?
यदि आप जल्दी दिखावा करना चाहते हैं (बहुत पहले कि आपने सिस्टम बनाना शुरू किया हो), तो एक यथार्थवादी प्रोटोटाइप जल्दी स्पिन अप करना मददगार हो सकता है। उदाहरण के लिए, टीमें Koder.ai का उपयोग करके आमतौर पर एक छोटा सर्विस प्रोटोटाइप (आम तौर पर Go बैकएंड + PostgreSQL और React UI) बनाकर रिट्राई, idempotency कीज़, और डिग्रेस्ड मोड फ्लोज़ जैसे व्यवहार सैंडबॉक्स में आज़माती हैं।
पारंपरिक अपटाइम चेक्स 'उपलब्ध पर गलत' व्यवहार पकड़ नहीं पाएँगे। ट्रैक करें:
ऑपरेटरों को पहले से तय किए गए कदम चाहिए जब विभाजन हो: कब राइट्स फ्रीज़ करें, कब फेलओवर करें, कब फ़ीचर डिग्रेड करें, और कैसे री-मर्ज सुरक्षा को मान्य करें।
साथ ही उपयोगकर्ता-मुखी व्यवहार की योजना बनाएं। यदि आप संगति चुनते हैं, तो संदेश हो सकता है 'हम अभी आपकी अपडेट की पुष्टि नहीं कर पा रहे—कृपया पुनः प्रयास करें।' यदि आप उपलब्धता चुनते हैं, तो स्पष्ट लिखें: 'आपका अपडेट कुछ मिनट में हर जगह दिखना शुरू हो सकता है।' स्पष्ट शब्दावली सपोर्ट लोड घटाती है और ट्रस्ट बनाए रखती है।
जब आप सिस्टम निर्णय ले रहे हों, CAP सबसे उपयोगी एक त्वरित 'विभाजन के दौरान क्या टूटता है?' ऑडिट के रूप में होता है—न कि सैद्धान्तिक बहस। इस चेकलिस्ट का उपयोग करें किसी डेटाबेस फीचर, कैशिंग रणनीति, या रिप्लिकेशन मोड चुनने से पहले।
क्रम में इन प्रश्नों से पूछें:
यदि नेटवर्क विभाजन होता है, तो आप तय कर रहे हैं कि इनमें से किसकी सुरक्षा पहले करेंगे।
एक वैश्विक सेटिंग जैसे 'हम AP सिस्टम हैं' से बचें। इसके बजाय प्रति:
उदाहरण: विभाजन के दौरान आप payments पर राइट्स ब्लॉक कर सकते हैं (संगति प्राथमिक) पर product_catalog के लिए पढ़ाई कैश्ड डेटा के साथ उपलब्ध रख सकते हैं।
लिखें कि आप क्या सहन कर सकते हैं, उदाहरण के साथ:
अगर आप असंगति को साधारण उदाहरणों में नहीं बता सकते, तो आप इसे टेस्ट और इन्सिडेंट में समझाने में कठिनाई महसूस करेंगे।
अगले विषय जो इस चेकलिस्ट के साथ अच्छी तरह चलते हैं: consensus (/blog/consensus-vs-cap), consistency models (/blog/consistency-models-explained), और SLOs/error budgets (/blog/sre-slos-error-budgets).
CAP एक मानसिक मॉडल है जो संचार विफलता के दौरान प्रतिकृत प्रणालियों के लिए प्रयुक्त होता है। यह तब सबसे उपयोगी है जब नेटवर्क धीमा, पैकेट-लूसी या विभाजित हो जाता है, क्योंकि तब रेप्लिकाएँ विश्वसनीय रूप से सहमत नहीं हो पातीं और आपको निम्न में से किसी एक का चुनाव करना पड़ता है:
यह 'वितरित कठिन है' जैसी धुंधली बातों को ठोस उत्पाद और इंजीनियरिंग निर्णय में बदल देता है।
एक वास्तविक CAP परिदृश्य के लिए दोनों चाहिए:
यदि आपका सिस्टम एकल नोड है या आप राज्य को रेप्लिकेट नहीं करते, तो CAP ट्रेडऑफ प्राथमिक समस्या नहीं है।
वास्तविक प्रणालियों में विभाजन कोई ऐसी स्थिति है जहाँ सिस्टम के हिस्से अपेक्षित समयसीमा के भीतर भरोसेमंद रूप से संवाद नहीं कर पाते—यहाँ तक कि हर मशीन चल रही हो।
व्यावहारिक रूप से, 'विभाजन' अक्सर इस तरह दिखता है:
एप्लिकेशन के दृष्टिकोण से, 'बहुत धीमा' अक्सर 'डाउन' के जैसा ही होता है।
Consistency (C) का अर्थ है कि रीड्स किसी भी जगह से नवीनतम स्वीकृत लिखाई को प्रतिबिंबित करें। उपयोगकर्ता इसे अनुभव करते हैं जैसे 'मैंने बदला, और सभी वही नया मान देखते हैं।'
Availability (A) का अर्थ है कि हर अनुरोध को सफल उत्तर मिलता है (जरूरी नहीं कि सबसे नया डेटा हो)। उपयोगकर्ता इसे इस तरह महसूस करते हैं जैसे 'एप काम कर रहा है', पर संभव है कि परिणाम स्टेल हों।
विभाजन के दौरान, आमतौर पर आप दोनों की गारंटी सभी ऑपरेशनों के लिए एक साथ नहीं दे पाते।
क्योंकि यदि आप मशीनों/रैक/ज़ोनों/रीजन में रेप्लिकेट करते हैं, तो विभाजन 'वैकल्पिक' नहीं होता। संदेश विलंब, ड्रॉप, री-ऑर्डरिंग या अजीब रूटिंग कर सकते हैं—यह सब सॉफ़्टवेयर के नजरिए से विभाजन है।
इसलिए 'विभाजन सहनशीलता' का मतलब है: जब संचार टूटे, तो सिस्टम का परिभाषित व्यवहार होना चाहिए—या तो कुछ ऑपरेशन अस्वीकार/रोक दिए जाएँ (Consistency को प्राथमिकता देना) या बेहतर प्रयत्न उत्तर दिया जाए (Availability को प्राथमिकता देना)।
यदि आप consistency को प्राथमिकता देते हैं, तो आप आमतौर पर:
यह पैटर्न पैसे, इन्वेंटरी आरक्षण और अनुमति परिवर्तनों जैसी जगहों पर सामान्य है—जहाँ गलत होना अस्थायी अनुपलब्धता से बदतर है।
यदि आप availability को प्राथमिकता देते हैं, तो आप आमतौर पर:
उपयोगकर्ता कम हार्ड एरर देखते हैं, पर स्टेल डेटा, डुप्लिकेट इफेक्ट्स (यदि idempotency न हो) या क्लीनअप की ज़रूरत जैसी समस्याएँ आ सकती हैं।
हाँ। आप ऑपरेशन के हिसाब से अलग-अलग चुन सकते हैं। सामान्य मिश्रित रणनीतियाँ:
इससे एकल वैश्विक 'हम AP/CP हैं' लेबल से बचा जा सकता है जो वास्तविक जरूरतों से मेल नहीं खाता।
उपयोगी विकल्पों में शामिल हैं:
अपनों को ऐसे कंडीशनों में डालकर वेरिफाई करें जहाँ असहमति दिखाई दे:
उसी सबसे कमजोर गारंटी को चुनें जो उपयोगकर्ता-देखी 'गलती' को रोक दे जिसे आप बर्दाश्त नहीं कर सकते।
साथ ही रनबुक और उपयोगकर्ता-संचार तैयार रखें जो आपके चुने व्यवहार (फेल क्लोज़ बनाम फेल ओपन) से मेल खाएँ।