"ACID" का रोज़मर्रा के लेनदेन के लिए क्या मतलब है
जब आप किराने का भुगतान करते हैं, फ्लाइट बुक करते हैं, या खातों के बीच पैसा स्थानांतरित करते हैं, तो आप परिणाम को स्पष्ट उम्मीद करते हैं: या तो यह सफल हुआ, या नहीं। डेटाबेस भी वही सुनिश्चित करने की कोशिश करते हैं—भले ही बहुत से लोग सिस्टम एक साथ इस्तेमाल कर रहे हों, सर्वर क्रैश हों, या नेटवर्क हिचकियाँ हो।
साधारण शब्दों में एक ट्रांज़ैक्शन
एक ट्रांज़ैक्शन एक एकल कार्य-इकाई होती है जिसे डेटाबेस एक "पैकेज" की तरह मानता है। इसमें कई चरण हो सकते हैं—इन्वेंट्री घटाना, ऑर्डर रिकॉर्ड बनाना, कार्ड चार्ज करना, और रसीद लिखना—लेकिन इसे एक सुसंगत क्रिया की तरह व्यवहार करना चाहिए।
अगर कोई भी चरण फेल हो, तो सिस्टम को आधे-अधूरे हालात छोड़ने के बजाय सुरक्षित बिंदु पर वापस जाने की जरूरत है।
आंशिक अपडेट असल बिजनेस समस्याएँ क्यों बनाते हैं
आंशिक अपडेट सिर्फ तकनीकी गड़बड़ियाँ नहीं हैं; वे कस्टमर सपोर्ट टिकट और वित्तीय जोखिम बन जाते हैं। उदाहरण:
- पेमेंट कैप्चर हो गया, पर ऑर्डर नहीं बना—ग्राहक से पैसे कटे पर कोई पुष्टि नहीं।
- ऑर्डर बना लिया गया, पर इन्वेंटरी घटाई नहीं गई—आपकी साइट ओवरसेल कर देती है और बाद में रद्द करती है।
- बैंक ट्रांसफ़र ने एक खाते से डेबिट किया पर दूसरे को क्रेडिट नहीं किया—बैलेंस का अर्थ बिगड़ जाता है।
ये फ़ेल्योर डिबग करना मुश्किल होते हैं क्योंकि सब कुछ "ज्यादातर सही" दिखता है, फिर भी संख्याएँ मेल नहीं खातीं।
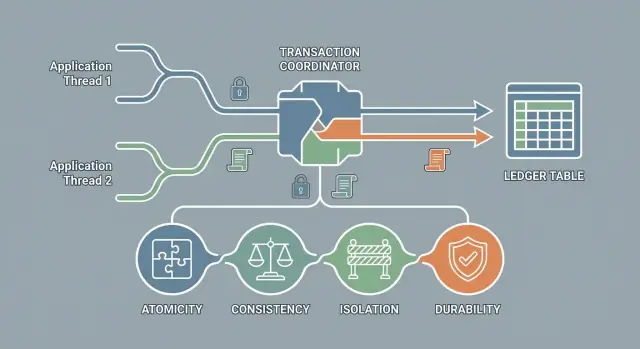
ACID एक गारंटी-सेट है (कोई प्रोडक्ट नहीं)
ACID चार गारंटी का संक्षेप है जो कई डेटाबेस ट्रांज़ैक्शन्स के लिए दे सकते हैं:
- Atomicity: सब-या-कुछ नहीं निष्पादन
- Consistency: डेटा वैध नियमों के भीतर रहे
- Isolation: समकालीय ट्रांज़ैक्शन असुरक्षित तरीके से हस्तक्षेप न करें
- Durability: एक बार commit होने के बाद बदलाव टिके रहें
यह कोई निश्चित डेटाबेस ब्रांड या एक फीचर नहीं है जिसे आप बस ऑन कर दें; यह व्यवहार के बारे में एक वादा है।
लाभ—और जिन लागतों की उम्मीद रखें
मजबूत गारंटियाँ आमतौर पर डेटाबेस को अधिक काम करवाती हैं: अतिरिक्त समन्वय, लॉक के लिए प्रतीक्षा, वर्ज़न ट्रैकिंग, और लॉग पर लिखना। इससे भारी लोड पर थ्रूपुट कम या लेटेंसी बढ़ सकती है। लक्ष्य यह नहीं है कि "हर समय अधिकतम ACID" मिले, बल्कि ऐसी गारंटी चुनना है जो आपके वास्तविक बिजनेस जोखिमों से मेल खाएं।
Atomicity: सब-या-कुछ नहीं अपडेट
Atomicity का मतलब है कि एक ट्रांज़ैक्शन को एक एकल कार्य-इकाई की तरह माना जाए: या तो यह पूरी तरह पूरा होता है या इसका कोई प्रभाव नहीं होता। डेटाबेस में कभी भी "आधा अपडेट" दिखाई नहीं देता।
एक साधारण बैंक ट्रांसफ़र उदाहरण
मान लीजिए ऐलिस से बॉब को $50 ट्रांसफ़र कर रहे हैं। अन्दरुनी तौर पर, यह आमतौर पर कम से कम दो बदलाव करता है:
- ऐलिस के बैलेंस से $50 घटाना
- बॉब के बैलेंस में $50 जोड़ना
Atomicity के साथ, ये दोनों बदलाव साथ में सफल होंगे या साथ में विफल। अगर सिस्टम दोनों सुरक्षित रूप से नहीं कर सकता, तो उसे दोनों नहीं करना चाहिए। इससे वह दुःस्वप्न टेली-आउटकम रोका जाता है जहाँ ऐलिस से चार्ज हुआ पर बॉब को पैसे नहीं मिले (या बॉब को मिला पर ऐलिस से चार्ज नहीं हुआ)।
Commit बनाम rollback (साधारण भाषा)
डेटाबेस ट्रांज़ैक्शन्स को दो निकास देते हैं:
- Commit: "सभी चरण सफल हुए; परिणाम आधिकारिक बनाओ।"
- Rollback: "कुछ गड़बड़ हुई; इस ट्रांज़ैक्शन के सभी बदलाव वापस ले लो।"
एक उपयोगी मानसिक मॉडल है "ड्राफ्ट बनाम पब्लिश"। जब तक ट्रांज़ैक्शन चल रहा होता है, बदलाव अस्थायी होते हैं। केवल एक commit उन्हें प्रकाशित करता है।
ट्रांज़ैक्शन के बीच क्या गलत हो सकता है?
Atomicity मायने रखती है क्योंकि फेल्योर सामान्य हैं:
- एप क्रैश: आपकी सर्विस एक टेबल अपडेट करने के बाद रुक सकती है पर अगला अपडेट नहीं हुआ।
- नेटवर्क ड्रॉप: एप DB तक नहीं पहुँच पाता, या क्लाइंट को "सफलता" रिस्पॉन्स नहीं मिलता।
- पावर लॉस: डाटाबेस सर्वर अचानक बंद हो जाता है।
अगर इनमें से कोई भी commit से पहले होता है, तो atomicity यह सुनिश्चित करती है कि डेटाबेस rollback कर सके ताकि आंशिक काम स्थायी स्थिति में न आ जाए।
Atomicity के साथ idempotency और retries
Atomicity डेटाबेस स्थिति की रक्षा करता है, पर आपका एप अभी भी अनिश्चितता को संभालना चाहिए—विशेषकर जब नेटवर्क ड्रॉप से पता न चले कि commit हुआ या नहीं।
दो प्रायोगिक पूरक:
- Retries: जब आपको प्रतिक्रिया न मिले तो अनुरोध दोहराएँ।
- Idempotency: एक ही अनुरोध को दोहराना सुरक्षित बनाएं (उदा. idempotency key का उपयोग ताकि "transfer #123" कम से कम एक बार ही लागू हो)।
साथ मिलकर, atomic ट्रांज़ैक्शन और idempotent retries आपको आंशिक अपडेट और आकस्मिक डबल-चार्ज से बचने में मदद करते हैं।
Consistency: डेटा को वैध नियमों के भीतर रखना
ACID में consistency का अर्थ यह नहीं है कि "डेटा ठीक दिखता है" या "सभी रेप्लिका मेल खाते हैं"। इसका मतलब है कि हर ट्रांज़ैक्शन डेटाबेस को आपके द्वारा परिभाषित नियमों के अनुसार एक वैध स्थिति से दूसरी वैध स्थिति में ले जाए।
Consistency उन नियमों से परिभाषित होती है जिन्हें आप चुनते हैं
डेटाबेस केवल उन्हीं constraints, triggers और invariants के सापेक्ष सुसंगत रख सकता है जो आपने परिभाषित किए हैं—ACID ये नियम नहीं बनाता; यह उन्हें ट्रांज़ैक्शन के दौरान लागू करता है।
सामान्य उदाहरण:
- Foreign keys: हर
order.customer_id मौजूदा ग्राहक की ओर पॉइंट करे।
- Unique constraints: दो उपयोगकर्ता एक ही ईमेल शेयर न करें।
- Check constraints / invariants: एक खाते का बैलेंस शून्य से नीचे न हो, या आइटम की मात्रा नकारात्मक न हो।
अगर ये नियम मौजूद हैं, तो डेटाबेस किसी भी ऐसे ट्रांज़ैक्शन को अस्वीकार कर देगा जो उन्हें तोड़ता हो—इसलिए आपको "आधा-वैध" डेटा नहीं मिलेगा।
एप्लिकेशन वैलिडेशन बनाम डेटाबेस constraints
ऐप-स्तरीय वैलिडेशन महत्वपूर्ण है, पर केवल वही पर्याप्त नहीं है।
- एप वैलिडेशन UX को बेहतर बनाता है (स्पष्ट त्रुटि संदेश, जल्दी फीडबैक) और जटिल बिजनेस नियम लागू कर सकता है।
- डेटाबेस constraints अंतिम दरवाज़ा होते हैं—खासकर जब कई सर्विसेज, बैकग्राउंड जॉब्स, इम्पोर्ट्स, या एडमिन टूल्स एक ही टेबल लिखते हैं।
एक क्लासिक विफलता मोड है: ऐप में चेक करना ("ईमेल उपलब्ध है") और फिर रो शामिल करना। समकालिकता के अंतर्गत, दो रिक्वेस्ट एक ही समय पर चेक पास कर सकती हैं। डेटाबेस में unique constraint ही गारंटी देती है कि केवल एक insert सफल होगा।
व्यवहार में consistency कैसा दिखता है
अगर आप "नो नेगेटिव बैलेंस" को constraint के रूप में एनकोड करते हैं (या इसे एक ही ट्रांज़ैक्शन में विश्वसनीय रूप से लागू करते हैं), तो कोई भी ऐसा ट्रांज़ैक्शन जो खाते को ओवरड्रॉ करेगा, पूरे रूप में विफल होना चाहिए। अगर आपने उस नियम को कहीं परिभाषित नहीं किया है, तो ACID उसे नहीं बचा पाएगा—क्योंकि लागू करने के लिए कुछ भी नहीं है।
Consistency अंततः स्पष्ट होने का मामला है: नियम परिभाषित करें, फिर ट्रांज़ैक्शन सुनिश्चित करें कि वे कभी न टूटें।
Isolation: समकालीयता के नीचे सुरक्षित काम करना
Isolation सुनिश्चित करती है कि ट्रांज़ैक्शन्स एक दूसरे पर कदम न रखें। जब एक ट्रांज़ैक्शन चल रहा हो, तो अन्य ट्रांज़ैक्शन्स आधे-निष्पन्न काम को न देखें या आकस्मिक रूप से उसे ओवरराइट न करें। लक्ष्य सरल है: हर ट्रांज़ैक्शन को ऐसा व्यवहार करना चाहिए मानो वह अकेले चल रहा हो, भले ही कई उपयोगकर्ता एक साथ सक्रिय हों।
समकालिकता इसे कठिन क्यों बनाती है
असली सिस्टम व्यस्त होते हैं: ग्राहक ऑर्डर देते हैं, सपोर्ट एजेंट प्रोफाइल अपडेट करते हैं, बैकग्राउंड जॉब्स पेमेंट reconcile करते हैं—सब एक साथ। ये क्रियाएँ समय में ओवरलैप करती हैं, और अक्सर एक ही पंक्तियों को छूती हैं (खाता बैलेंस, इन्वेंटरी काउंट, या बुकिंग स्लॉट)।
Isolation के बिना, टाइमिंग आपकी बिजनेस लॉजिक का हिस्सा बन जाती है। "स्टॉक घटाओ" अपडेट किसी दूसरे चेकआउट के साथ रेस कर सकता है, या रिपोर्ट मध्यान्तर में डेटा पढ़कर ऐसी संख्याएँ दिखा सकती है जो कभी स्थिर स्थिति में मौजूद ही नहीं थीं।
Isolation आमतौर पर कॉन्फ़िगरेबल है
पूरी "अकेले चलो" जैसी isolation महँगी हो सकती है। यह थ्रूपुट कम कर सकती है, प्रतीक्षा (लॉक्स) बढ़ा सकती है, या ट्रांज़ैक्शन retries का कारण बन सकती है। वहीं, कई वर्कफ़्लो सबसे सख्त सुरक्षा की आवश्यकता नहीं रखते—उदा. कल के analytics पढ़ना मामूली असंगतियों को सहन कर सकता है।
इसीलिए डेटाबेस कॉन्फ़िगरेबल isolation levels देते हैं: आप चुनते हैं कि आप प्रदर्शन और संघर्ष में किस हद तक जोखिम स्वीकार करेंगे।
एक त्वरित पूर्वावलोकन: अनोमलियाँ जो isolation रोकता/अनुमत करता है
जब isolation आपके वर्कलोड के लिए बहुत कमजोर होता है, तो आप क्लासिक अनोमलियों से मिलेंगे:
- Dirty reads: किसी दूसरे ट्रांज़ैक्शन के लिखे हुए पर अभी commit नहीं हुए बदलाव पढ़ना।
- Lost updates: दो ट्रांज़ैक्शन एक-दूसरे को ओवरराइट कर देते हैं और एक सेट बदल जाता है।
- Phantom reads: एक क्वेरी दो बार चलाने पर अलग-पंक्तियाँ मिलना क्योंकि किसी ने बीच में मिलती-जुलती पंक्तियाँ डाली/हटा दीं।
इन फेल्योर मोड्स को समझने से सही isolation level चुनना आसान होता है जो आपके प्रोडक्ट के वादों से मेल खाए।
सामान्य अनोमलियाँ जो Isolation रोकती/अनुमत करती है
वास्तविक डेटाबेस प्रतिबंध जोड़ें
ऐसे प्रतिबंधों के साथ Go + PostgreSQL बैकएंड बनाएं जो आपके मुख्य व्यवसायिक नियमों की सुरक्षा करें।
Isolation निर्धारित करती है कि जब आपका ट्रांज़ैक्शन चल रहा हो तो आप किन दूसरों को देख सकते हैं। कमजोर isolation होने पर आप अनोमलियाँ देख सकते हैं—तकनीकी रूप से संभव पर उपयोगकर्ताओं के लिए चौंकाने वाली व्यवहार:
पढ़ने की अनोमलियाँ
Dirty read तब होता है जब आप किसी ऐसे डेटा को पढ़ते हैं जिसे दूसरे ट्रांज़ैक्शन ने लिखा है पर commit नहीं किया।
परिदृश्य: अलेक्स $500 ट्रांसफ़र करता है, बैलेंस अस्थायी रूप से $200 हो जाता है, और आप वह $200 पढ़ लेते हैं इससे पहले कि अलेक्स का ट्रांसफ़र बाद में फेल हो और rollback हो जाए।
उपयोगकर्ता परिणाम: ग्राहक गलत कम बैलेंस देखता है, फ्रॉड रूल गलत तरीके से ट्रिगर हो सकता है, या सपोर्ट एजेंट गलत जवाब देता है।
Non-repeatable read तब होता है जब आप एक ही पंक्ति दो बार पढ़ते हैं और बीच में किसी अन्य ट्रांज़ैक्शन ने commit कर दिया, इसलिए मान बदल जाता है।
परिदृश्य: आप एक ऑर्डर टोटल ($49.00) लोड करते हैं, फिर तुरंत रीफ़्रेश करते हैं और $54.00 देखते हैं क्योंकि किसी ने डिस्काउंट लाइन हटा दी।
उपयोगकर्ता परिणाम: "मेरी कुल राशि चेकआउट के दौरान बदल गई", जिससे अविश्वास या कार्ट छोड़ना हो सकता है।
Phantom read non-repeatable read जैसा है, पर पंक्तियों के सेट के साथ: दूसरी बार क्वेरी चलाने पर नया या गायब मिलती पंक्ति क्योंकि किसी ने मैचिंग रिकॉर्ड डाला/हटा दिया।
परिदृश्य: होटल सर्च "3 कमरे उपलब्ध" दिखाता है, फिर बुकिंग के दौरान सिस्टम फिर से चेक करता है और पाता है कि अब कोई नहीं है क्योंकि नई reservations जोड़ दी गईं।
उपयोगकर्ता परिणाम: डबल बुकिंग प्रयास, inconsistent availability स्क्रीन, या ओवरसेलिंग।
लिखने की अनोमलियाँ (सामान्य असली दुनिया की बग्स)
Lost update तब होता है जब दो ट्रांज़ैक्शन एक ही मान पढ़ते हैं और दोनों अपडेट लिखते हैं, और बाद वाला पिछले वाले को ओवरराइट कर देता है।
परिदृश्य: दो एडमिन एक ही प्रोडक्ट प्राइस एडिट करते हैं। दोनों $10 से शुरू करते हैं; एक $12 सेव करता है, दूसरा $11 बाद में सेव करता है।
उपयोगकर्ता परिणाम: किसी का परिवर्तन गायब हो जाता है; टोटल्स और रिपोर्ट गलत हो जाती हैं।
Write skew तब होता है जब दो ट्रांज़ैक्शन प्रत्येक अलग-अलग वैध परिवर्तन करते हैं, पर मिलकर कोई नियम तोड़ देते हैं।
परिदृश्य: नियम: "कम से कम एक ऑन-कॉल डॉक्टर शेड्यूल में होना चाहिए." दो डॉक्टर स्वतंत्र रूप से खुद को ऑफ-कॉल मार्क कर देते हैं यह देखकर कि दूसरा अभी भी ऑन-कॉल है।
उपयोगकर्ता परिणाम: आपके पास शेड्यूल में शून्य कवरेज बचता है, भले ही हर ट्रांज़ैक्शन ने अपने चेक पास कर लिए हों।
हमेशा सबसे सख्त isolation क्यूँ नहीं?
ज़्यादा मजबूत isolation अनोमलियाँ कम करती है पर प्रतीक्षा, retries और लागत बढ़ा सकती है उच्च समकालिकता में। बहुत से सिस्टम पढ़-भारी analytics के लिए कमजोर isolation चुनते हैं, जबकि पैसा-हिलाने, बुकिंग, और अन्य correctness-critical फ्लोज के लिए सख्त सेटिंग्स का उपयोग करते हैं।
Isolation स्तर: सही सुरक्षा सेटिंग चुनना
Isolation इस बारे में है कि आपका ट्रांज़ैक्शन दूसरों के चलने के दौरान क्या "देख" सकता है। डेटाबेस इसे isolation levels के रूप में एक्सपोज़ करते हैं: ऊँचे स्तर आश्चर्यजनक व्यवहार को कम करते हैं, पर थ्रूपुट या प्रतीक्षा बढ़ा सकते हैं।
सामान्य isolation स्तर
- Read Uncommitted: आप ऐसे बदलाव पढ़ सकते हैं जिन्हें दूसरे ट्रांज़ैक्शन ने commit भी नहीं किया है ("dirty reads"). लगभग कुछ भी रोका नहीं जाता।
- Read Committed: आप केवल committed डेटा पढ़ते हैं, इसलिए dirty reads रोके जाते हैं। पर अगर आप वही क्वेरी दो बार चलाते हैं तो बीच में किसी ने commit किया हो सकता है और आपको अलग परिणाम मिल सकता है ("non-repeatable reads").
- Repeatable Read: आपने जो पढ़ा है वह ट्रांज़ैक्शन के दौरान स्थिर रहता है, इसलिए non-repeatable reads सामान्यतः रोके जाते हैं। इंजन पर निर्भर करते हुए, आपको फिर भी "phantoms" देखने मिल सकते हैं या नहीं।
- Serializable: ट्रांज़ैक्शन्स ऐसे व्यवहार करते हैं मानो वे एक-एक करके चले हों। यह सबसे सख्त सेटिंग है, आमतौर पर dirty reads, non-repeatable reads, और phantoms को रोकती है और कई सूक्ष्म लिखने की अनोमलियों को कम करती है।
स्तर चुनना: थ्रूपुट बनाम correctness
टीमें अक्सर Read Committed को यूजर-फेसिंग ऐप्स के लिए डिफ़ॉल्ट चुनती हैं: अच्छा प्रदर्शन, और "कोई dirty reads नहीं" अधिकांश अपेक्षाओं से मेल खाता है।
जब आपको ट्रांज़ैक्शन के अंदर स्थिर परिणाम चाहिए (उदा. लाइन आइटम्स से invoice बनाना) और आप कुछ overhead सहन कर सकते हैं तो Repeatable Read लें।
जब correctness concurrency पर सबसे अधिक मायने रखता है (उदा. oversell रोकना) और आप जटिल रेस कंडीशनों को एप कोड में संभाल नहीं सकते, तब Serializable का उपयोग करें।
Read Uncommitted OLTP सिस्टम में दुर्लभ है; कभी-कभी निगरानी या अनुमानित रिपोर्टिंग के लिए उपयोग होता है जहाँ कभी-कभी गलत पढ़ना सहनीय है।
महत्वपूर्ण चेतावनी: व्यवहार भिन्न हो सकता है
नाम सामान्यीकृत हैं, पर ठीक गारंटियाँ DB इंजन के अनुसार अलग-अलग हो सकती हैं (और कभी-कभी कॉन्फ़िगरेशन पर भी)। अपने डेटाबेस डॉक्यूमेंटेशन की पुष्टि करें और उन अनोमलियों का परीक्षण करें जो आपके बिजनेस के लिए मायने रखती हैं।
Durability: commits को टिकाना
Durability का मतलब है कि एक बार ट्रांज़ैक्शन committed होने पर उसके परिणाम किसी क्रैश—पावर लॉस, प्रोसेस रीस्टार्ट, या अचानक मशीन रीबूट—के बाद भी बरकरार रहने चाहिए। अगर आपकी ऐप कस्टमर को बताती है "पेमेंट सफल हुआ", तो durability का वादा है कि डेटाबेस अगली फेल्योर के बाद उस तथ्य को "भूल" नहीं सकता।
डेटाबेस commits को क्रैश के बाद कैसे बचाते हैं
अधिकांश रिलेशनल डेटाबेस write-ahead logging (WAL) के साथ durability हासिल करते हैं। उच्च स्तर पर, डेटाबेस commit मानने से पहले बदलावों की एक क्रमिक "रसीद" लॉग पर डिस्क पर लिख देता है। अगर डेटाबेस क्रैश कर जाता है, तो startup पर यह लॉग replay करके committed बदलावों को बहाल कर सकता है।
रिकवरी समय को सीमित रखने के लिए, डेटाबेस checkpoints भी बनाता है। एक checkpoint वह क्षण होता है जब डेटाबेस सुनिश्चित करता है कि हाल के काफी बदलाव मुख्य डेटा फाइलों में लिखे जा चुके हैं, ताकि रिकवरी अनंत लॉग इतिहास replay न करे।
Durability स्टोरेज और कॉन्फ़िगरेशन पर निर्भर करती है
Durability कोई बाइनरी ऑन/ऑफ स्विच नहीं है; यह इस बात पर निर्भर करती है कि डेटाबेस कितना आक्रामक रूप से डेटा को स्थायी स्टोरेज तक पुश करता है।
- Synchronous सेटिंग्स में डेटाबेस अक्सर लॉग फ्लश होने (अक्सर OS-level
fsync) का इंतज़ार करता है पहले कि commit की पुष्टि करे। यह सुरक्षित है पर लेटेंसी बढ़ सकती है।
- Asynchronous सेटिंग्स में डेटाबेस commit से पहले लॉग को पूरी तरह durable स्टोरेज पर न लिखकर acknowledgement दे सकता है। प्रदर्शन बेहतर हो सकता है, पर क्रैश पर हाल की "committed" ट्रांज़ैक्शन्स खो सकती हैं।
मूलभूत हार्डवेयर भी मायने रखता है: SSDs, RAID कंट्रोलर्स जिनमें write caches हों, और क्लाउड वॉल्यूम फेल्योर के दौरान अलग व्यवहार कर सकते हैं।
बैकअप और रेप्लिकेशन संबंधित पर अलग चीज़ें हैं
बैकअप और रेप्लिकेशन आपको recover करने या downtime घटाने में मदद करते हैं, पर वे durability की वही गारंटी नहीं हैं। कोई ट्रांज़ैक्शन प्राइमरी पर durable हो सकता है भले ही वह replica पर न पहुँचा हो, और बैकअप सामान्यतः प्वाइंट-इन-टाइम स्नैपशॉट होते हैं न कि commit-लागत-by-लागत गारंटी।
डेटाबेस ACID को अंदर से कैसे लागू करते हैं
अपने डिज़ाइन को प्रोडक्शन में लागू करें
जब आप वास्तविक ट्रैफ़िक में concurrency परखने के लिए तैयार हों, तब अपना ऐप डिप्लॉय और होस्ट करें।
जब आप BEGIN करते हैं और बाद में COMMIT, डेटाबेस कई मूविंग पार्ट्स का समन्वय करता है: कौन किस पंक्ति को पढ़ सकता है, कौन उसे अपडेट कर सकता है, और अगर दो लोग एक ही रिकॉर्ड बदलना चाह रहे हों तो क्या होगा।
Pessimistic बनाम optimistic concurrency control
एक प्रमुख "भीतर का" चुनाव यह है कि conflicts को कैसे संभाला जाए:
- Pessimistic locking: मानते हैं कि conflicts संभव हैं। जब एक ट्रांज़ैक्शन किसी पंक्ति को अपडेट करता है, डेटाबेस उसे लॉक कर देता है ताकि अन्य ट्रांज़ैक्शन्स को इंतज़ार करना पड़े। यह कई अनोमलियाँ रोकता है पर blocking पैदा कर सकता है।
- Optimistic approaches: मानते हैं कि conflicts दुर्लभ हैं। ट्रांज़ैक्शन्स कम blocking के साथ आगे बढ़ते हैं, और डेटाबेस commit समय पर conflicts detect कर सकता है और किसी ट्रांज़ैक्शन को reject कर सकता है ताकि उसे retry किया जा सके।
कई सिस्टम वर्कलोड और isolation level के अनुसार दोनों विचारों को मिलाते हैं।
MVCC: readers writers को ब्लॉक नहीं करते
आधुनिक डेटाबेस अक्सर MVCC (Multi-Version Concurrency Control) का उपयोग करते हैं: एक पंक्ति की केवल एक प्रति रखने के बजाय, डेटाबेस कई वर्शन रखता है।
- पाठक एक सुसंगत स्नैपशॉट (एक पुराना संस्करण) देख सकते हैं बिना इंतज़ार किए।
- लेखक एक नई वर्शन बना सकते हैं जबकि पढ़ने वाले चालू रहते हैं।
यह एक बड़ा कारण है कि कुछ डेटाबेस बहुत सारे पढ़/लिख ऑप्स को कम blocking के साथ संभालते हैं—हालांकि write/write conflicts का समाधान अभी भी जरूरी होता है।
Deadlocks: जब प्रतीक्षा लूप बना लेती है
लॉक्स deadlocks पैदा कर सकते हैं: ट्रांज़ैक्शन A उस लॉक का इंतज़ार करता है जो B के पास है, जबकि B उसी लॉक का इंतज़ार करती है जो A के पास है।
डेटाबेस आमतौर पर इस चक्र का पता लगा कर और एक ट्रांज़ैक्शन को abort कर के (deadlock victim) इसे सुलझाते हैं, ताकि एप्लिकेशन retry कर सके।
व्यवहारिक संकेत कि कुछ गलत है
अगर ACID प्रवर्तन घर्षण पैदा कर रहा है, तो आप प्रायः यह देखेंगे:
- पीक उपयोग के दौरान लॉक वेट्स बढ़ना
- Timeouts (बहुत अधिक इंतज़ार के बाद क्वेरी फेल होना)
- Contention hotspots (कुछ पंक्तियाँ/टेबल लगातार अपडेट हो रही हों, जैसे काउंटर या "last seen" फ़ील्ड)
ये लक्षण अक्सर बताते हैं कि ट्रांज़ैक्शन साइज, इंडेक्सिंग, या कौन सा isolation/locking रणनीति वर्कलोड के अनुरूप है, इसे फिर से देखना चाहिए।
ACID एप्लिकेशन डिज़ाइन निर्णय कैसे आकार देता है
ACID गारंटियाँ सिर्फ डेटाबेस थीगरी नहीं हैं—वे इस बारे में प्रभावित करती हैं कि आप API, बैकग्राउंड जॉब्स, और यहां तक कि UI फ्लो कैसे डिज़ाइन करते हैं। मूल विचार सरल है: तय करें कौन से स्टेप्स साथ में सफल होने चाहिए, फिर केवल उन्हीं स्टेप्स को ट्रांज़ैक्शन में रखें।
"एक बिजनेस परिवर्तन" के आसपास API डिजाइन करना
एक अच्छा ट्रांज़ैक्शनल API आमतौर पर एक ही बिजनेस एक्शन से मेल खाता है, भले ही यह कई तालिकाओं को छुए। उदाहरण के लिए, /checkout ऑपरेशन ऑर्डर बनाए, इन्वेंटरी रिज़र्व करे, और पेमेंट इंटेंट रिकॉर्ड करे—उन डेटाबेस राइट्स को आमतौर पर एक ही ट्रांज़ैक्शन में होना चाहिए ताकि वे साथ में commit हों (या साथ में rollback)।
एक सामान्य पैटर्न:
- ट्रांज़ैक्शन खोलने से पहले इनपुट वैलिडेशन करें।
- ट्रांज़ैक्शन खोलें।
- न्यूनतम आवश्यक पढ़/लिख करें।
- Commit करें।
यह atomicity और consistency बनाये रखता है जबकि धीमे, नाजुक ट्रांज़ैक्शन्स से बचाता है।
रिक्वेस्ट्स, सर्विसेज़, और जॉब्स में ट्रांज़ैक्शन सीमाएँ
ट्रांज़ैक्शन सीमाएँ इस बात पर निर्भर करती हैं कि "एक यूनिट ऑफ वर्क" का क्या मतलब है:
- यूजर रिक्वेस्ट्स: ट्रांज़ैक्शन्स को छोटा रखें—आदर्श रूप से कुछ ही क्वेरीज। रेंडरिंग व्यूज़ या डाउनस्ट्रीम रिस्पॉन्स का इंतज़ार करते हुए लॉक न रखें।
- बैकग्राउंड जॉब्स: हर जॉब प्रयास को एक यूनिट ऑफ वर्क मानें। अगर जॉब 10,000 रिकॉर्ड प्रोसेस करता है तो बैच में commit करें ताकि आप सुरक्षित रूप से restart कर सकें।
- सर्विस बॉउंड्रीज: आमतौर पर एक ट्रांज़ैक्शन एक सर्विस के डेटाबेस के भीतर रखें। सर्विस पार करना आमतः अलग दृष्टिकोण (जैसे outbox) माँगता है क्योंकि एक ACID ट्रांज़ैक्शन कई डेटाबेस पर आसान नहीं होता।
त्रुटि हैंडलिंग: rollback, retries और सुरक्षित replays
ACID मदद करता है, पर आपका एप अभी भी फेल्योर सही तरीके से संभाले:
- Error पर rollback: अगर कोई भी चरण फेल हो, तो ट्रांज़ैक्शन abort करें ताकि आंशिक अपडेट लीक न हों।
- Transient errors पर retry: serialization failures और deadlocks समकालिकता के तहत सामान्य हैं। पूरे ट्रांज़ैक्शन को retry करना अक्सर सही समाधान है।
- ऑपरेशन्स को idempotent बनाएं: यदि रिक्वेस्ट retry हो (क्लाइंट द्वारा या आपका जॉब रनर), तो उसे बिना डबल-चार्ज या डबल-शिपिंग के सुरक्षित रूप से replay किया जा सके—idempotency keys और unique constraints का उपयोग करें।
सामान्य एंटी-पैटर्न्स
बचे रहें: लंबे ट्रांज़ैक्शन्स, ट्रांज़ैक्शन के अंदर बाहरी API कॉल करना, और ट्रांज़ैक्शन में यूज़र थिंक टाइम (उदा. "कार्ट रो लॉक करें, फिर यूज़र से कन्फ़र्मेशन का इंतज़ार करें"). ये contention बढ़ाते हैं और isolation conflicts की संभावना बढ़ाते हैं।
कहाँ टूल मदद कर सकते हैं (बुनियादी बातें बदले बिना)
अगर आप तेज़ी से transactional system बना रहे हैं, तो सबसे बड़ा जोखिम अक्सर "ACID न जानना" नहीं—बल्कि एक बिजनेस एक्शन को कई endpoints, जॉब्स, या टेबल्स में बिखेर देना है बिना स्पष्ट ट्रांज़ैक्शन सीमा के।
ऐसे प्लेटफ़ॉर्म जैसे Koder.ai आपको तेज़ी से बनाते समय मदद कर सकते हैं: आप एक वर्कफ़्लो (उदा. "इन्वेंटरी रिज़र्वेशन और पेमेंट इंटेंट के साथ चेकआउट") योजना-प्रथम चैट में वर्णन कर सकते हैं, React UI और Go + PostgreSQL बैकएंड जेनरेट कर सकते हैं, और schema/transaction सीमा बदलने पर snapshots/rollback के साथ iterate कर सकते हैं। डेटाबेस अभी भी गारंटियाँ लागू करता है; मूल्य सही डिज़ाइन से काम करने वाले इम्प्लीमेंटेशन तक पहुँचने की गति में है।
वितरित और मल्टी-सर्विस सिस्टम में ACID
समानकालिकता को जल्दी परखें
डेडलॉक्स, रीट्राइज़ और छोटे ट्रांज़ैक्शन्स को जल्दी मॉडल करें — एक चलने वाले प्रोजेक्ट में जिसे आप चला सकें।
एक ही डेटाबेस आमतौर पर एक ट्रांज़ैक्शन सीमा के भीतर ACID गारंटियाँ दे सकता है। जब आप काम कई सर्विसेज़ (और अक्सर कई डेटाबेस) में फैलाते हैं, तो वही गारंटियाँ रखना कठिन और महंगा हो जाता है।
Consistency बनाम availability: प्रोडक्शन में महसूस होने वाला trade-off
कठोर consistency का मतलब है हर पढ़ने पर "लेटेस्ट committed सच" दिखाई दे। उच्च availability का मतलब है सिस्टम उत्तर देता रहे भले ही कुछ हिस्से धीमे या अनपहुंचयोग्य हों।
मल्टी-सर्विस सेटअप में, अस्थायी नेटवर्क समस्या आपको चुनाव पर मजबूर कर सकती है: हर प्रतिभागी के सहमति तक अनुरोध ब्लॉक/फेल करें (ज़्यादा consistent, कम available), या स्वीकार करें कि सर्विसेज़ थोड़ी देर के लिए असंगत रह सकती हैं (ज़्यादा available, कम consistent)। कोई विकल्प हमेशा सही नहीं है—यह निर्भर करता है कि आपके बिजनेस किस त्रुटि को सहन कर सकता है।
वितरित ट्रांज़ैक्शन्स कठिन क्यों हैं
वितरित ट्रांज़ैक्शन्स उन सीमाओं के पार समन्वय मांगती हैं जिन पर आपके पास पूरा नियंत्रण नहीं होता: नेटवर्क देरी, retries, टाइमआउट, सर्विस क्रैश, और आंशिक फेल्योर।
भले ही हर सर्विस सही हो, नेटवर्क ambiguity पैदा कर सकता है: क्या पेमेंट सर्विस commit कर गया पर ऑर्डर सर्विस ने acknowledge नहीं पाया? ऐसे मामलों को सुरक्षित रूप से सुलझाने के लिए सिस्टम समन्वय प्रोटोकॉल (जैसे two-phase commit) इस्तेमाल करते हैं, जो धीमे, फेल्योर के दौरान उपलब्धता घटा सकते हैं और संचालन जटिलता बढ़ा सकते हैं।
"एक बड़ा ट्रांज़ैक्शन" को बदलने वाले व्यावहारिक पैटर्न
Sagas वर्कफ़्लो को स्टेप्स में तोड़ते हैं; हर स्टेप लोकल रूप से commit होता है। अगर बाद का स्टेप फेल हो, तो पहले किये गए स्टेप्स को compensating actions (उदा. चार्ज रिफंड करना) से undo किया जाता है।
Outbox/inbox पैटर्न ईवेंट पब्लिशिंग और उपभोक्ता भरोसेमंद बनाते हैं। एक सर्विस एक ही लोकल ट्रांज़ैक्शन में बिजनेस डेटा और "पब्लिश करने हेतु ईवेंट" रिकॉर्ड (outbox) लिखती है। उपभोक्ता प्रोसेस्ड मैसेज IDs (inbox) रिकॉर्ड करते हैं ताकि retries बिना डुप्लिकेट प्रभावों के संभाले जा सकें।
Eventual consistency अल्प विंडो को स्वीकार करती है जहाँ सर्विसेज़ के बीच डेटा भिन्न हो सकता है, और reconciliation का स्पष्ट प्लान होता है।
गारंटियाँ कब ढीली करें—और जोखिम कैसे नियंत्रित करें
ग্যারंटी तब ढीली करें जब:
- आप अस्थायी मेल न खाने को सहन कर सकते हैं (शिपिंग स्टेटस ऑर्डर क्रिएशन से पीछे रहे)
- आप compensations से त्रुटियाँ ठीक कर सकते हैं (रिफंड, कैंसलेशन)
- लेटेंसी और uptime तत्काल वैश्विक सत्यता से ज्यादा मायने रखते हों
जोखिम नियंत्रित करें: invariants परिभाषित कर के (क्या कभी नहीं टूटना चाहिए), idempotent ऑपरेशन्स डिज़ाइन करके, टाइमआउट और retries के साथ backoff उपयोग करके, और drift की निगरानी कर के (stuck sagas, repeated compensations, बढ़ती outbox टेबल)। सच में क्रिटिकल invariants के लिए (उदा. "कभी खाते से ज़्यादा न निकलें"), उन्हें एक ही सर्विस और एक ही डेटाबेस ट्रांज़ैक्शन के भीतर रखें।
प्रैक्टिकल चेकलिस्ट: ACID प्रणालियाँ डिज़ाइन, परीक्षण, और मॉनिटर करना
एक ट्रांज़ैक्शन यूनिट टेस्ट में "सही" लग सकता है और फिर भी असल ट्रैफ़िक, रीस्टार्ट, और समकालिकता में फेल हो सकता है। इस चेकलिस्ट का उपयोग करें ताकि ACID गारंटियाँ आपके प्रोडक्शन व्यवहार के साथ संरेखित रहें।
1) Design: invariants और ट्रांज़ैक्शन सीमा परिभाषित करें
सबसे पहले लिखिए कि क्या हमेशा सच होना चाहिए (आपके डेटा invariants)। उदाहरण: "खाता बैलेंस कभी नेगेटिव न हो", "ऑर्डर टोटल लाइन आइटम्स के योग के बराबर हो", "इन्वेंटरी शून्य से नीचे न जाए", "एक पेमेंट ठीक एक ऑर्डर से जुड़ा हो"। इन्हें प्रोडक्ट नियम मानें, न कि केवल डेटाबेस ट्रिविया।
फिर तय करिए क्या एक ट्रांज़ैक्शन में होना चाहिए और क्या बाद में किया जा सकता है।
- Data invariants: तालिकाएँ/पंक्तियाँ और ठोस नियम सूचीबद्ध करें।
- Failure scenarios: प्रोसेस क्रैश बीच में, commit के बाद नेटवर्क टाइमआउट, retry से duplicates, replica failover, डिस्क पूर्ण होना इत्यादि।
- Concurrency profile: किन ऑपरेशन्स का समानांतर चलना उम्मीद है, contention hotspots, और क्या पढ़ने को "तुरंत अब" चाहिए या थोड़ी सी stale चल सकती है।
ट्रांज़ैक्शन्स को छोटा रखें: कम पंक्तियाँ छुएँ, कम काम करें (कोई बाहरी API कॉल्स नहीं), और जल्दी commit करें।
2) Test: रेस और फॉल्ट के तहत व्यवहार साबित करें
समकालिकता को टेस्ट का पहला दर्जा बनाइए।
- Race-condition tests: एक ही क्रिटिकल ऑपरेशन को समकालिक रूप से चलाएँ (उदा. दो चेकआउट्स आखिरी आइटम के लिए) और सुनिश्चित करें कि invariants कभी न टूटें।
- Fault injection: एप प्रोसेस को ट्रांज़ैक्शन बीच में मारें; टाइमआउट इंजेक्ट करें; retries बाधित करें; DB restart फ़ोर्स करें; परिणाम जाँचें कि या तो commit एक बार हुआ हो या सुरक्षित रूप से rollback हुआ हो।
- Load tests with correctness checks: पीक थ्रूपुट पर न सिर्फ लेटेंसी बल्कि टोटल्स, काउंट्स, और "कोई duplicates नहीं" constraints भी वैलिडेट करें।
अगर आप retries सपोर्ट करते हैं, तो एक स्पष्ट idempotency key जोड़ें और "सफलता के बाद अनुरोध दोहराया गया" पर भी परीक्षण करें।
3) Monitor: उपयोगकर्ताओं से पहले ACID दर्द पकड़ें
उन संकेतकों को मॉनिटर करें जो बताते हैं कि आपकी गारंटियाँ महंगी या नाज़ुक हो रही हैं:
- Lock waits और queue time (बढ़ती contention)
- Deadlocks (आवृत्ति, victim queries)
- Long-running transactions (अक्सर मूल कारण)
- Replication lag (stale reads और delayed failover)
- Commit/fsync times (storage दबाव; durability लागत)
ट्रेन्ड्स पर अलर्ट सेट करें, सिर्फ स्पाइक्स पर नहीं, और इन्हें उन endpoints या जॉब्स से जोड़ें जो कारण हैं।
नियम-मूल बातें: isolation और ट्रांज़ैक्शन स्कोप
आपके invariants को बचाने वाली सबसे कमजोर isolation का उपयोग करें; डिफ़ॉल्ट रूप से उसे "max कर देना" मत कीजिए। जब आपको छोटे क्रिटिकल सेक्शन के लिए सख्त correctness चाहिए (पैसा स्थानांतरित करना, इन्वेंटरी घटाना), तो ट्रांज़ैक्शन को सिर्फ उसी सेक्शन तक सीमित रखें और बाकी सब बाहर रखें।