09 अप्रैल 2025·8 मिनट
फीचर अपनाने और उपयोग व्यवहार को ट्रैक करने के लिए वेब ऐप कैसे बनाएं
फीचर अपनाने और उपयोगकर्ता व्यवहार को ट्रैक करने वाली वेब ऐप बनाने के लिए व्यावहारिक मार्गदर्शिका, इवेंट डिजाइन से लेकर डैशबोर्ड, गोपनीयता और रोलआउट तक।
फीचर अपनाने और उपयोगकर्ता व्यवहार को ट्रैक करने वाली वेब ऐप बनाने के लिए व्यावहारिक मार्गदर्शिका, इवेंट डिजाइन से लेकर डैशबोर्ड, गोपनीयता और रोलआउट तक।
कुछ भी ट्रैक करने से पहले तय करें कि “फीचर अपनाना” आपके प्रोडक्ट के लिए असल में क्या मतलब रखता है। अगर आप यह स्टेप स्किप कर देंगे, तो आप बहुत सारा डेटा इकट्ठा कर लेंगे—और फिर भी मीटिंग्स में इसके अर्थ पर बहस करेंगे।
अपनाना अक्सर एक अकेला क्षण नहीं होता। उन परिभाषाओं में से एक या अधिक चुनें जो वैल्यू डिलीवरी से मेल खाते हैं:
उदाहरण: “Saved Searches” के लिए अपनाना हो सकता है एक सेव्ड सर्च बनाई (use), 14 दिनों में 3+ बार चलाया (repeat), और अलर्ट मिला और उस पर क्लिक किया (value achieved)।
आपकी ट्रैकिंग उन सवालों का जवाब देनी चाहिए जो कार्रवाई की ओर ले जाएँ, जैसे:
इनको निर्णय बयान के रूप में लिखें (उदा., “यदि रिलीज़ X के बाद activation गिरता है, तो हम onboarding बदलाव rollback करेंगे.”)।
विभिन्न टीमें अलग दृश्य चाहती हैं:
सप्ताह में समीक्षा के लिए एक छोटा सेट मैट्रिक्स चुनें, और हर डिप्लॉयमेंट के बाद एक हल्का release check रखें। थ्रेसहोल्ड्स परिभाषित करें (उदा., “30 दिनों में सक्रिय उपयोगकर्ताओं में अपनाने की दर ≥ 25%”) ताकि रिपोर्टिंग बहस नहीं, निर्णय चलाए।
इंस्ट्रूमेंट करने से पहले तय करें कि आपके एनालिटिक्स सिस्टम किन “चीजों” का वर्णन करेगा। यदि आप ये एंटिटीज़ सही रखें, तो आपके रिपोर्ट्स उत्पाद बदलने पर भी समझने योग्य बने रहेंगे।
प्रत्येक एंटिटी को सरल भाषा में परिभाषित करें, फिर उसे उन IDs में अनुवाद करें जिन्हें आप स्टोर कर सकते हैं:
project_created, invite_sent)।प्रत्येक इवेंट के लिए न्यूनतम प्रॉपर्टीज़ लिखें: user_id (या anonymous ID), account_id, timestamp, और कुछ प्रासंगिक attributes (plan, role, device, feature flag आदि)। “बस किसी भी चीज़” का ढेर जमा करने से बचें।
रिपोर्टिंग के कोण चुनें जो आपके प्रोडक्ट लक्ष्यों से मेल खाते हैं:
आपकी इवेंट डिज़ाइन इन कम्प्यूटेशंस को सीधे-साधा बनानी चाहिए।
स्कोप स्पष्ट करें: पहले केवल web या day-one से web + mobile। क्रॉस-प्लैटफ़ॉर्म ट्रैकिंग सबसे आसान है अगर आप जल्दी ही इवेंट नाम और प्रॉपर्टीज़ स्टैंडर्डाइज़ कर लें।
अंत में, गैर-वारंट करना लक्ष्य सेट करें: स्वीकार्य पेज परफ़ॉर्मेंस इम्पैक्ट, इंजेस्टशन लैटेंसी (डैशबोर्ड कितने ताज़ा होने चाहिए), और डैशबोर्ड लोड टाइम। ये प्रतिबंध बाद के ट्रैकिंग, स्टोरेज, और क्वेरी विकल्पों का मार्गदर्शन करेंगे।
अच्छा ट्रैकिंग स्कीमा “सब कुछ ट्रैक करने” के बारे में नहीं बल्कि इवेंट्स को भविष्यनिष्ठ बनाना है। यदि इवेंट नाम और प्रॉपर्टीज़ ड्रिफ्ट करते हैं, तो डैशबोर्ड टूटते हैं, एनालिस्ट डेटा पर भरोसा करना बंद कर देते हैं, और इंजीनियर नई फीचर्स इंस्ट्रूमेंट करने से हिचकते हैं।
एक सरल, पुनरावर्ती पैटर्न चुनें और उस पर टिके रहें। एक सामान्य विकल्प है verb_noun:
viewed_pricing_pagestarted_trialenabled_featureexported_reportएक ही टेंस लगातार उपयोग करें (past या present), और पर्यायवाची शब्दों (clicked, pressed, tapped) से बचें जब तक कि वे वास्तव में अलग अर्थ न रखें।
हर इवेंट छोटे सेट की required प्रॉपर्टीज़ लेकर आए ताकि आप बाद में reliably segment, filter और join कर सकें। कम से कम परिभाषित करें:
user_id (anonymous users के लिए nullable, पर जब ज्ञात हो तो मौजूद)account_id (यदि आपका प्रोडक्ट B2B/multi-seat है)timestamp (सर्वर-जनरेटेड जहां संभव हो)feature_key (स्थिर पहचान जैसे "bulk_upload")plan (उदा., free, pro, enterprise)ये प्रॉपर्टीज़ फीचर अपनाने और उपयोगकर्ता व्यवहार एनालिटिक्स को आसान बनाती हैं क्योंकि आपको हर इवेंट में क्या गायब है अनुमान नहीं लगाना पड़ता।
ऑप्शनल फ़ील्ड्स संदर्भ जोड़ते हैं, पर आसानी से अधिक हो सकते हैं। सामान्य ऑप्शनल प्रॉपर्टीज़ शामिल हैं:
device, os, browserpage, referrerexperiment_variant (या ab_variant)ऑप्शनल प्रॉपर्टीज़ को इवेंट्स में सुसंगत रखें (एक ही key names, एक ही value formats), और जहां संभव हो "allowed values" दस्तावेज़ करें।
मान लें कि आपका स्कीमा विकसित होगा। एक event_version जोड़ें (उदा., 1, 2) और जब आप अर्थ या required फ़ील्ड बदलें तो उसे अपडेट करें।
अंत में, एक इंस्ट्रूमेंटेशन स्पेस लिखें जो हर इवेंट, कब वह फ़ायर होता है, required/optional प्रॉपर्टीज़, और उदाहरणों की सूची दे। उस डॉक को अपने ऐप के सोर्स कंट्रोल में रखें ताकि स्कीमा बदलाव कोड की तरह review हो।
यदि आपकी आइडेंटिटी मॉडल कमजोर है, तो आपके अपनाने के मैट्रिक्स शोर से भरे होंगे: फनल्स मेल नहीं खाएंगे, रिटेंशन खराब दिखेगा, और “सक्रिय उपयोगकर्ता” डुप्लिकेटों से inflated होंगे। लक्ष्य है तीन दृश्य एक साथ सपोर्ट करना: anonymous visitors, logged-in users, और account/workspace activity।
हर डिवाइस/सेशन को एक anonymous_id (cookie/localStorage) से शुरू करें। जिस पल उपयोगकर्ता authenticate करता है, उस anonymous history को एक identified user_id से लिंक करें।
पहचान लिंक तभी करें जब उपयोगकर्ता ने अकाउंट का स्वामित्व प्रमाणित कर दिया हो (सफल लॉगिन, magic link वेरिफिकेशन, SSO)। कमजोर सिग्नल (फॉर्म में टाइप किया गया ईमेल) पर लिंक करने से बचें जब तक कि आप इसे स्पष्ट रूप से “pre-auth” के रूप में अलग न रखें।
ऑथ ट्रांज़िशंस को इवेंट्स की तरह ट्रीट करें:
login_success (includes user_id, account_id, और वर्तमान anonymous_id)logoutaccount_switched (from account_id → account_id)महत्वपूर्ण: logout पर anonymous cookie बदलें नहीं। अगर आप उसे rotate करेंगे तो सेशन्स fragment होंगे और unique users inflate होंगे। इसके बजाय, stable anonymous_id रखें, पर logout के बाद user_id attach करना बंद कर दें।
मर्ज नियम स्पष्ट रूप से परिभाषित करें:
user_id को प्राथमिकता दें। यदि ईमेल द्वारा मर्ज करना अनिवार्य है, तो उसे सर्वर-साइड करें और केवल verified ईमेल्स के लिए करें। एक audit trail रखें।account_id/workspace_id उपयोग करें, न कि बदलने योग्य नाम।मर्ज करते समय एक mapping table (old → new) लिखें और उसे query time पर या backfill job के माध्यम से लगातार लागू करें। इससे cohorts में “दो उपयोगकर्ता” दिखने से बचा जा सकता है।
स्टोर और भेजें:
anonymous_id (प्रति ब्राउज़र/डिवाइस स्थिर)user_id (प्रति व्यक्ति स्थिर)account_id (प्रति वर्कस्पेस स्थिर)इन तीनों कुंजियों के साथ आप प्री-लॉगिन व्यवहार, प्रति-उपयोगकर्ता अपनाना, और अकाउंट-स्तरीय अपनाना बिना डबल-काउंट किए माप सकते हैं।
जहाँ आप इवेंट्स ट्रैक करते हैं वह बदल देता है कि आप किस पर भरोसा कर सकते हैं। ब्राउज़र इवेंट्स बताते हैं कि लोग क्या करने का प्रयास कर रहे थे; सर्वर इवेंट्स बताते हैं कि वास्तव में क्या हुआ।
UI इंटरैक्शन और वह संदर्भ जो केवल ब्राउज़र में मिलता है उसके लिए क्लाइंट-साइड ट्रैकिंग इस्तेमाल करें। सामान्य उदाहरण:
नेटवर्क चॅटर कम करने के लिए इवेंट्स बैच करें: मेमोरी में queue रखें, हर N सेकंड या N इवेंट्स पर flush करें, और visibilitychange/page hide पर भी flush करें।
किसी भी इवेंट के लिए सर्वर-साइड ट्रैकिंग उपयोग करें जो पूर्ण हुए आउटकम या बिलिंग/सिक्योरिटी-सेंसेटिव एक्शन्स को दर्शाता है:
सर्वर-साइड ट्रैकिंग आम तौर पर अधिक सटीक होती है क्योंकि यह ad blockers, पेज रीलोड्स, या flaky कनेक्टिविटी से ब्लॉक नहीं होती।
एक व्यावहारिक पैटर्न है: क्लाइंट में intent ट्रैक करें और सर्वर पर success।
उदाहरण के लिए, feature_x_clicked_enable (client) और feature_x_enabled (server) इमिट करें। फिर सर्वर इवेंट्स को client context से समृद्ध करने के लिए ब्राउज़र से API पर हल्का context_id (या request ID) पास करें।
जहाँ इवेंट्स सबसे अधिक ड्रॉप होने की संभावना हो वहां resiliency जोड़ें:
localStorage/IndexedDB में रखें, exponential backoff के साथ retry करें, retries को cap करें, और event_id से dedupe करें।यह मिश्रण आपको समृद्ध बिहेवियरल डिटेल देता है बिना भरोसेमंद अपनाने के मैट्रिक्स खोए।
एक फीचर-अपनाने एनालिटिक्स ऐप मुख्यतः एक पाइपलाइन है: इवेंट्स को भरोसेमंद तरीके से कैप्चर करें, उन्हें सस्ते में स्टोर करें, और तेज़ी से क्वेरी करें ताकि लोग परिणामों पर भरोसा करें और उनका उपयोग करें।
साधारण, अलग करने योग्य सर्विसेज़ के सेट से शुरू करें:
यदि आप जल्दी एक प्रोटोटाइप आंतरिक एनालिटिक्स वेब ऐप लाना चाहते हैं, तो एक vibe-coding प्लेटफ़ॉर्म जैसे Koder.ai आपकी मदद कर सकता है ताकि आप chat-driven spec से डैशबोर्ड UI (React) और backend (Go + PostgreSQL) जल्दी खड़ा कर सकें—यह पाइपलाइन को हार्डन करने से पहले एक प्रारंभिक "working slice" पाने के लिए उपयोगी है।
दो लेयर का उपयोग करें:
अपनी टीम को वास्तव में कितनी freshness चाहिए यह चुनें:
कई टीमें दोनों करती हैं: “अब क्या हो रहा है” के लिए रीयल-टाइम काउंटर और canonical metrics को nightly jobs द्वारा recompute।
विकास के लिए जल्दी से डिजाइन करें:
रिटेंशन योजना भी बनाएं (उदा., 13 महीने raw, aggregates लंबा) और एक replay path रखें ताकि आप बग्स फिक्स करने के लिए इवेंट्स को reprocess कर सकें बजाय डैशबोर्ड्स पैच करने के।
अच्छी एनालिटिक्स एक ऐसे मॉडल से शुरू होती है जो सामान्य सवालों (funnels, retention, feature usage) का जल्दी जवाब दे सके बिना हर क्वेरी को कस्टम इंजीनियरिंग प्रोजेक्ट बनाए।
कई टीमें दो स्टोर्स के साथ सबसे अच्छा प्रदर्शन करती हैं:
यह विभाजन आपके प्रोडक्ट DB को हल्का रखता है और एनालिटिक्स क्वेरीज को सस्ता और तेज़ बनाता है।
एक व्यावहारिक बेसलाइन इस प्रकार दिखती है:
warehouse में denormalize करें जिन्हें आप अक्सर क्वेरी करते हैं (उदा., account_id को events पर कॉपी करें) ताकि महँगी joins से बचा जा सके।
raw_events को time (daily सामान्य) और वैकल्पिक रूप से workspace/app द्वारा partition करें। इवेंट प्रकार के अनुसार retention लागू करें:
यह "अनंत वृद्धि" को आपके सबसे बड़े एनालिटिक्स समस्या बनने से रोकता है।
क्वालिटी चेक्स को modeling का हिस्सा बनाएं, बाद की सफाई नहीं:
validation परिणामों को संग्रहित करें (या rejected-events तालिका) ताकि आप इंस्ट्रूमेंटेशन हेल्थ मॉनिटर कर सकें और डैशबोर्ड्स ड्रिफ्ट होने से पहले मुद्दे ठीक कर सकें।
एक बार आपके इवेंट्स फ्लो करने लगें, अगला कदम कच्चे क्लिक को मैट्रिक्स में बदलना है जो यह बताएं: “क्या यह फीचर वास्तव में अपनाया जा रहा है, और किसके द्वारा?” चार व्यूज़ पर ध्यान दें जो एक साथ काम करते हैं: funnels, cohorts, retention, और paths।
हर फीचर के लिए एक फनल परिभाषित करें ताकि आप देख सकें उपयोगकर्ता कहाँ ड्रॉप करते हैं। एक व्यावहारिक पैटर्न:
feature_used)फनल स्टेप्स को भरोसेमंद इवेंट्स से जोड़े रखें और नज़दीकी नामकरण उपयोग करें। यदि “first use” कई तरीकों से हो सकता है, तो उस स्टेप को OR conditions (उदा., import_started OR integration_connected) के साथ ट्रीट करें।
Cohorts आपको समय के साथ सुधार मापने में मदद करते हैं बिना पुराने और नए उपयोगकर्ताओं को मिलाये। सामान्य cohorts:
प्रत्येक cohort के भीतर अपनाने की दर ट्रैक करें ताकि आप देखें कि हालिया onboarding या UI बदलाव मदद कर रहे हैं या नहीं।
रिटेंशन सबसे उपयोगी तब होती है जब इसे किसी फीचर से जोड़ा जाता है, न कि केवल "ऐप ओपन" से। इसे परिभाषित करें जैसे कि फीचर के मुख्य इवेंट (या value action) को Day 7/30 पर दोहराना। "दूसरी बार उपयोग का समय" भी ट्रैक करें—यह अक्सर कच्चे रिटेंशन से अधिक संवेदनशील होता है।
मैट्रिक्स को उन डाइमेंशंस से तोड़ें जो व्यवहार को समझाती हैं: plan, role, industry, device, और acquisition channel। सेगमेंट अक्सर यह दिखाते हैं कि अपनाना एक समूह के लिए मजबूत है और दूसरे के लिए लगभग нल है।
पाथ विश्लेषण जोड़ें ताकि आप खोज सकें कि अपनाने से पहले और बाद आम अनुक्रम क्या होते हैं (उदा., जो उपयोगकर्ता अपनाते हैं वे अक्सर pricing, फिर docs, फिर integration कनेक्ट करते हैं)। इसे onboarding prompts को सुधारने और dead ends हटाने के लिए उपयोग करें।
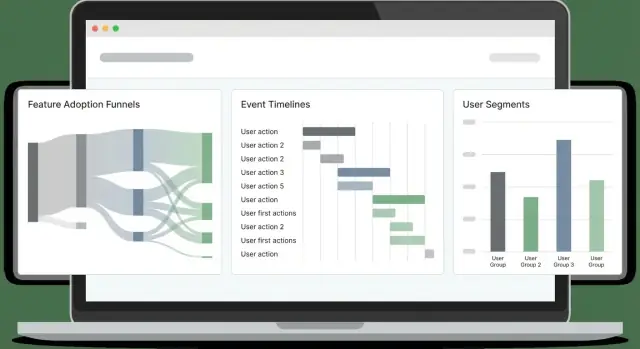
डैशबोर्ड तब फेल होते हैं जब वे सभी के लिए एक "मास्टर व्यू" बनने की कोशिश करते हैं। इसके बजाय, कुछ केंद्रित पेज डिज़ाइन करें जो अलग-अलग लोगों के निर्णयों के तरीके से मेल खाते हों, और हर पेज एक स्पष्ट प्रश्न का जवाब दे।
एक एग्जीक्यूटिव ओवरव्यू तेज़ हेल्थ चेक होना चाहिए: अपनाने का ट्रेंड, सक्रिय उपयोगकर्ता, टॉप फीचर्स, और पिछले रिलेज़ के बाद उल्लेखनीय परिवर्तन। एक फीचर डीप-डाइव PMs और इंजीनियर्स के लिए बनाइए: उपयोगकर्ता कहाँ शुरू होते हैं, कहाँ ड्रॉप ऑफ होते हैं, और कौन से सेगमेंट अलग व्यवहार करते हैं।
एक सरल संरचना जो अच्छी तरह काम करती है:
"क्या" के लिए ट्रेंड चार्ट, "कौन" के लिए सेगमेंटेड ब्रेकडाउन, और "क्यों" के लिए ड्रिल-डाउन शामिल करें। ड्रिल-डाउन को अनुमति दें कि कोई बार/पॉइंट क्लिक करके उदाहरण उपयोगकर्ता या वर्कस्पेस देख सके (उचित permissions के साथ), ताकि टीमें पैटर्न मान्य कर सकें और असली सेशन्स जांच सकें।
फिल्टर्स पेजों में सुसंगत रखें ताकि उपयोगकर्ताओं को कंट्रोल्स बार-बार सीखने न पड़े। फीचर अपनाने ट्रैकिंग के लिए सबसे उपयोगी फिल्टर्स हैं:
डैशबोर्ड तब वर्कफ़्लो का हिस्सा बनते हैं जब लोग ठीक वही शेयर कर सकें जो वे देख रहे हैं। जोड़ें:
यदि आप इसे एक प्रोडक्ट एनालिटिक्स वेब ऐप में बना रहे हैं, तो एक /dashboards पेज पर “Pinned” saved views पर विचार करें ताकि स्टेकहोल्डर्स हमेशा उन कुछ रिपोर्ट्स पर उतरें जो मायने रखती हैं।
डैशबोर्ड्स एक्सप्लोरेशन के लिए अच्छे हैं, पर टीमें आमतौर पर समस्या तब नोटिस करती हैं जब ग्राहक शिकायत करता है। अलर्ट्स इसे पलट देते हैं: आप मिनटों के भीतर किसी ब्रेकेज़ के बारे में जान जाते हैं, और उसे क्या बदला गया से जोड़ सकते हैं।
कुछ उच्च-सिग्नल अलर्ट्स से शुरू करें जो आपके कोर अपनाने फ्लो की रक्षा करें:
feature_failed इवेंट्स)। absolute thresholds और rate-based thresholds (errors per 1,000 sessions) दोनों शामिल करें।अलर्ट परिभाषाओं को पढ़ने योग्य और version-controlled रखें (यहां तक कि एक सरल YAML फ़ाइल भी) ताकि वे tribal knowledge न बनें।
बेसिक अनोमली डिटेक्शन बहुत प्रभावी हो सकती है बिना fancy ML के:
चार्ट्स में सीधे एक रिलीज़ मार्कर स्ट्रीम जोड़ें: deploys, feature flag rollouts, pricing changes, onboarding tweaks। हर मार्कर में timestamp, owner, और छोटा नोट होना चाहिए। जब मैट्रिक्स शिफ्ट होते हैं, तो आप संभावित कारण तुरंत देख पाएँगे।
अलर्ट्स को email और Slack-जैसे चैनलों पर भेजें, पर quiet hours और उन्नयन (warn → page) का समर्थन करें गंभीर मुद्दों के लिए। हर अलर्ट का एक owner और runbook लिंक होना चाहिए (यहां तक कि छोटा /docs/alerts पेज) जिसमें पहली जाँच क्या करनी है वह बताया गया हो।
एनालिटिक्स डेटा जल्दी व्यक्तिगत डेटा बन सकता है अगर आप सावधान नहीं हैं। प्राइवेसी को कानूनी बाद की बात न बनाएं: यह जोखिम कम करता है, विश्वास बनाता है, और दर्दनाक रीवर्क से बचाता है।
सहमति आवश्यकताओं का सम्मान करें और उपयोगकर्ताओं को जहाँ ज़रूरी हो opt-out करने दें। व्यवहारिक रूप से इसका मतलब है कि आपकी ट्रैकिंग परत एक consent flag जाँचे इससे पहले कि इवेंट भेजे जाएँ, और यदि उपयोगकर्ता सत्र के बीच में अपनी मंशा बदल दे तो ट्रैकिंग रोक दी जाए।
सख्त नियम वाले क्षेत्रों के लिए “consent-gated” फीचर्स पर विचार करें:
संवेदनशील डेटा कम से कम रखें: इवेंट्स में raw ईमेल से बचें; hashed/opaque IDs का उपयोग करें। इवेंट payloads को व्यवहार बताने तक सीमित रखें (क्या हुआ), न कि पहचान बताने तक (कौन है)। यदि आपको इवेंट्स को किसी अकाउंट से जोड़ना है, तो एक internal user_id/account_id भेजें और मैपिंग अपने डेटाबेस में रखें जिसके लिए उचित सुरक्षा नियंत्रण हों।
साथ ही संग्रह न करें:
क्या और क्यों आप ट्रैक करते हैं उसका दस्तावेज़ बनाएं; एक स्पष्ट प्राइवेसी पेज का लिंक दें। एक हल्का “tracking dictionary” बनाएं जो हर इवेंट, उसका उद्देश्य, और retention अवधि समझाए। अपने प्रोडक्ट UI में /privacy का लिंक दें और उसे पठनीय रखें: आप क्या ट्रैक करते हैं, क्या नहीं, और कैसे opt out करें।
Role-based access लागू करें ताकि केवल अधिकृत टीमें ही user-level डेटा देख सकें। अधिकांश लोगों को केवल aggregated dashboards की आवश्यकता होती है; raw event views एक छोटे समूह (जैसे data/product ops) के लिए रखें। एक्सपोर्ट्स और यूजर लुकअप्स के लिए audit logs जोड़ें, और पुराने डेटा के लिए ऑटोमेटिक एक्सपायर नियम रखें।
अच्छी तरह से किया गया प्राइवेसी नियंत्रण विश्लेषण धीमा नहीं करेगा—यह आपके एनालिटिक्स सिस्टम को सुरक्षित, स्पष्ट, और बनाए रखने में आसान बना देगा।
एनालिटिक्स शिप करना एक फीचर शिप करने जैसा है: आप एक छोटा, सत्यापनीय पहला रिलीज़ चाहते हैं, फिर लगातार सुधार। ट्रैकिंग वर्क को प्रोडक्शन कोड की तरह व्यवहार करें—owners, reviews, और tests के साथ।
किसी एक फीचर एरिया के लिए एक तंग सेट golden events से शुरू करें (उदा., Feature Viewed, Feature Started, Feature Completed, Feature Error)। ये सीधे उन सवालों से मैप होने चाहिए जो टीम साप्ताहिक पूछेगी।
परियोजना संकुचित रखने का उद्देश्य स्पष्ट है: कम इवेंट्स का मतलब आप जल्दी गुणवत्ता सत्यापित कर सकें, और आप यह सीखेंगे कि वास्तव में किन प्रॉपर्टीज़ की ज़रूरत है (plan, role, source, feature variant) जब आप आगे बढ़ेंगे।
Tracking को "done" कहने से पहले चेकलिस्ट का उपयोग करें:
स्टेजिंग और प्रोडक्शन दोनों में चलाने के लिए नमूना क्वेरीज़ जोड़ें। उदाहरण:
feature_name के लिए टॉप 20 प्रॉपर्टी वैल्यूज़” (टाइपो पकड़ें जैसे Search बनाम search)इंस्ट्रूमेंटेशन को आपके रिलीज़ प्रोसेस का हिस्सा बनाएं:
बदलाव के लिए योजना बनाएं: इवेंट्स को हटाने की बजाय deprecated करें, जब अर्थ बदलता है तो प्रॉपर्टीज़ का संस्करण बढ़ाएँ, और समय-समय पर audits शेड्यूल करें।
जब आप नया required प्रॉपर्टी जोड़ते हैं या बग ठीक करते हैं, तो तय करें कि क्या आपको backfill चाहिए (और उस समय सीमा को दस्तावेज़ करें जहाँ डेटा आंशिक होगा)।
अंत में, अपने डॉक्स में एक हल्का ट्रैकिंग गाइड रखें और इसे डैशबोर्ड्स और PR टेम्प्लेट्स से लिंक करें। एक अच्छा आरंभिक बिंदु एक छोटा चेकलिस्ट है जैसे /blog/event-tracking-checklist।
पहले लिखें कि आपके प्रोडक्ट के लिए “अपनाना” का क्या मतलब है:
फिर उन परिभाषाओं में से वे चुनें जो आपके फीचर के मूल्य से मेल खाती हैं और उन्हें मापने योग्य इवेंट्स में बदल दें।
छोटा सेट चुनें जिसे आप साप्ताहिक समीक्षा कर सकें और हर रिलीज़ के बाद एक हल्के पोस्ट-रिलीज़ चेक रखें। सामान्य मैट्रिक्स में शामिल हैं:
साफ थ्रेसहोल्ड्स जोड़ें (उदा., “30 दिनों में ≥ 25% अपनाने”) ताकि परिणाम बहस नहीं, निर्णय चलाएँ।
शुरू करने से पहले कोर एंटिटीज़ परिभाषित करें ताकि रिपोर्टें उत्पाद के विकास के साथ भी समझने योग्य रहें:
एक सुसंगत कन्वेंशन जैसे verb_noun अपनाएँ और पूरे प्रोडक्ट में एक ही टेंस (past या present) का पालन करें।
प्रैक्टिकल नियम:
एक न्यूनतम “इवेंट कॉन्ट्रैक्ट” बनाएं ताकि हर इवेंट बाद में सेगमेंट और जोइन के लिए काम आए। सामान्य बेसलाइन:
user_id (nullable यदि anonymous)ब्राउज़र में intent ट्रैक करें और सर्वर पर success:
हाइब्रिड अप्रोच डेटा लॉस (ad blockers/reloads) को कम करती है और अपनाने के मैट्रिक्स को भरोसेमंद बनाती है। कॉन्टेक्स कनेक्ट करने के लिए context_id (request ID) पास करें client → API और उसे सर्वर इवेंट्स में अटैच करें।
तीन स्थिर कुंजियाँ उपयोग करें:
anonymous_id (प्रति ब्राउज़र/डिवाइस)user_id (प्रति व्यक्ति)account_id (प्रति वर्कस्पेस)anonymous → identified तभी लिंक करें जब मजबूत प्रमाण हो (सफल लॉगिन, सत्यापित magic link, SSO)। ऑथ ट्रांज़िशंस को इवेंट के रूप में ट्रैक करें (, , ) और logout पर anonymous cookie rotate न करें ताकि सेशन्स टुकड़े-टुकड़े न हों और unique users inflate न हों।
अधिसंख्य क्लिक को मैट्रिक्स में बदलने के लिए इन चार व्यूज़ पर ध्यान दें: funnels, cohorts, retention, और paths।
फनल के लिए एक प्रैक्टिकल पैटर्न:
feature_used)यदि “first use” कई तरीकों से हो सकता है, तो उस स्टेप को के साथ परिभाषित करें (उदा., OR ) और भरोसेमंद इवेंट्स पर टिके रहें (आम तौर पर सर्वर-साइड)।
कुछ केंद्रित पेज बनाएं जो निर्णय लेने के तरीकों से मेल खाते हैं:
फिल्टर्स सुसंगत रखें (date range, plan, account attributes, region, app version)। सेव्ड व्यूज़ और CSV एक्सपोर्ट जोड़ें ताकि स्टेकहोल्डर वही दिखा सकें जो वे देख रहे हैं।
पाइपलाइन और प्रक्रिया में सुरक्षा जोड़ें:
event_version जोड़ें और delete की बजाय deprecate करेंहर इवेंट के लिए कम से कम कैप्चर करें: user_id (या anonymous_id), account_id (यदि लागू हो), timestamp, और कुछ प्रासंगिक प्रॉपर्टीज़ (plan/role/device/flag)।
clicked vs pressed)report_exported)feature_key (उदा., bulk_upload) रखें, डिस्प्ले नेम पर निर्भर न होंइवेंट नामों और फ़ायर कंडीशंस को कोड के साथ रखी गई इंस्ट्रूमेंटेशन स्पेसिफिकेशन में दस्तावेज़ करें।
anonymous_idaccount_id (B2B/multi-seat के लिए)timestamp (सर्वर-जनरेटेड जहां संभव हो)feature_keyplan (या tier)ऑप्शनल प्रॉपर्टीज़ सीमित और सुसंगत रखें (एक ही कुंजी और वैल्यू फॉर्मेट प्रत्येक इवेंट में)।
login_successlogoutaccount_switchedimport_startedintegration_connectedगोपनीयता को डिज़ाइन का हिस्सा बनाएं: consent gating, कच्चे ईमेल/फ्री-टेक्स्ट इवेंट्स में न रखें, और यूजर-लेवल डेटा तक पहुँच पर role-based restrictions और audit logs रखें।