07 नव॰ 2025·8 मिनट
Geoffrey Hinton के न्यूरल नेटवर्क ब्रेकथ्रूज़ — आसान भाषा में
Geoffrey Hinton के प्रमुख विचारों का सरल मार्गदर्शन—बैकप्रोप और बोल्ट्ज़मान मशीनों से लेकर डीप नेट्स और AlexNet तक—और इन्होने आधुनिक AI को कैसे आकार दिया।
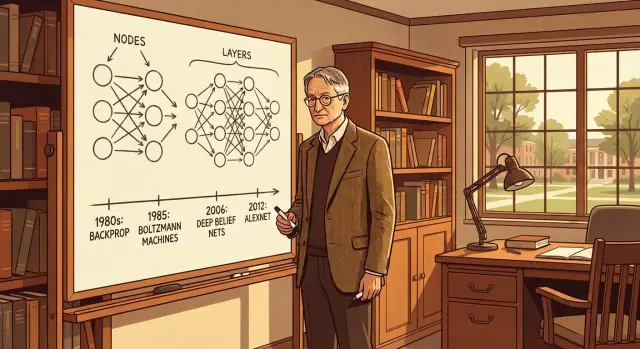
Geoffrey Hinton के प्रमुख विचारों का सरल मार्गदर्शन—बैकप्रोप और बोल्ट्ज़मान मशीनों से लेकर डीप नेट्स और AlexNet तक—और इन्होने आधुनिक AI को कैसे आकार दिया।
यह मार्गदर्शिका जिज्ञासु, गैर-तकनीकी पाठकों के लिए है जो अक्सर सुनते हैं कि “न्यूरल नेटवर्क्स ने सब कुछ बदल दिया” और वे यह साफ़, धरातलीय समझ चाहते हैं—बिना कलन या प्रोग्रामिंग की ज़रूरत के।
आपको Geoffrey Hinton द्वारा आगे बढ़ाए गए विचारों का एक सामान्य-भाषाई दौरा मिलेगा, कि वे उस समय क्यों मायने रखते थे, और वे आज के एआई उपकरणों से कैसे जुड़े हैं। इसे ऐसे समझिए जैसे कंप्यूटरों को उदाहरणों से पैटर्न—शब्द, तस्वीरें, आवाज़ें—सीखाने के बेहतर तरीकों की कहानी।
Hinton ने "AI" का आविष्कार नहीं किया, और न ही किसी एक व्यक्ति ने आधुनिक मशीन लर्निंग को पूरा बनाया। उनकी अहमियत इस बात में है कि उन्होंने बार-बार न्यूरल नेटवर्क्स को व्यवहार में काम करने योग्य बनाया जब कई शोधकर्ता उन्हें बेकार मान चुके थे। उन्होंने मुख्य अवधारणाएँ, प्रयोग और एक ऐसा शोध-संस्कृति दी जिसने प्रतिनिधित्व सीखने (उपयोगी आंतरिक फीचर्स) को केंद्रीय समस्या माना—हाथ से नियम लिखने के बजाय।
आगे के सेक्शनों में हम खोलेंगे:
इस लेख में, ब्रेकथ्रू का मतलब है वह बदलाव जिसने न्यूरल नेटवर्क्स को अधिक उपयोगी बनाया: वे विश्वसनीय रूप से ट्रेन होने लगे, बेहतर फीचर सीखने लगे, नए डेटा पर बेहतर सामान्यीकरण दिखाया, या कठिन कामों पर स्केल कर सके। यह एक चमकदार डेमो से ज़्यादा, एक विचार को भरोसेमंद विधि में बदलने का मामला है।
न्यूरल नेटवर्क्स को "प्रोग्रामर्स की जगह लेने" के लिए नहीं बनाया गया था। उनका मूल वादा अधिक विशिष्ट था: ऐसे मशीन बनाना जो गंदे वास्तविक-विश्व इनपुट—तस्वीरें, भाषण, और टेक्स्ट—से उपयोगी आंतरिक प्रतिनिधित्व सीख सकें, बिना इंजीनियर हर नियम हाथ से लिखे।
एक फोटो केवल लाखों पिक्सल मान होते हैं। एक आवाज़ रिकॉर्डिंग दबाव के मापों की एक धारा है। चुनौती इन कच्चे अंकों को उन अवधारणाओं में बदलने की है जिनकी लोगों को परवाह है: किनारे, आकार, फोनिम्स, शब्द, वस्तुएँ, इरादा।
इससे पहले कि न्यूरल नेटवर्क्स व्यवहार में आएं, कई सिस्टम हस्तनिर्मित फीचर्स पर निर्भर थे—ध्यान से डिज़ाइन किए गए माप जैसे “एज डिटेक्टर” या “टेक्सचर डिस्क्रिप्टर”। यह संकुचित सेटिंग्स में काम करता था, पर रोशनी बदलने, उच्चारण अलग होने, या जटिल वातावरण में अक्सर टूट जाता था।
न्यूरल नेटवर्क्स का लक्ष्य इसे स्वचालित करना था: डेटा से परत दर परत फीचर सीखकर। अगर सिस्टम सही मध्यवर्ती बिल्डिंग ब्लॉक्स खुद खोज ले, तो वह बेहतर सामान्यीकरण कर सकता है और नए टास्क के लिए कम मैन्युअल इंजीनियरिंग के साथ अनुकूल हो सकता है।
विचार आकर्षक था, लेकिन कई बाधाएँ थीं जो न्यूरल नेट्स को लंबे समय तक सफल होने से रोकती रहीं:
जब न्यूरल नेटवर्क्स अनफ़ैशनेबल थे—खासकर 1990s और 2000s के आरम्भिक हिस्सों में—तो Geoffrey Hinton जैसे शोधकर्ताओं ने प्रतिनिधित्व सीखने पर लगातार काम जारी रखा। उन्होंने विचार पेश किए (मध्य-1980s से) और पुराने विचारों (जैसे ऊर्जा-आधारित मॉडल) को बार-बार देखा जब तक कि हार्डवेयर, डेटा, और तरीके साथ नहीं आ गए।
उस निरंतरता ने मूल लक्ष्य—मशीनें जो सही प्रतिनिधित्व सीखती हैं—को जीवित रखा, सिर्फ़ अंतिम उत्तर नहीं।
बैकप्रोपेगेशन (अक्सर “बैकप्रॉप” कहा जाता है) वह तरीका है जिससे एक न्यूरल नेटवर्क अपनी गलतियों से सुधरता है। नेटवर्क एक भविष्यवाणी करता है, हम मापते हैं कि वह कितना गलत था, और फिर नेटवर्क के अंदरूनी "नॉब्स" (वज़न) को समायोजित करते हैं ताकि अगली बार वह थोड़ा बेहतर करे।
किसी फोटो को "बिल्ली" या "कुत्ता" लेबल करने की कोशिश करते हुए कल्पना कीजिए। नेटवर्क ने अनुमान लगाया "बिल्ली", पर सही उत्तर "कुत्ता" था। बैकप्रोप उस अंतिम त्रुटि से शुरू होता है और नेटवर्क की परतों के माध्यम से पीछे काम करते हुए यह पता लगाता है कि किस वज़न ने गलत उत्तर में कितना योगदान दिया।
व्यावहारिक दृष्टिकोण से:
ये समायोजन आमतौर पर ग्रैडिएंट डिसेंट के साथ होते हैं, जिसका अर्थ है "त्रुटि के ढलान पर छोटे कदम लेना"।
बैकप्रॉप अपनाने से पहले, मल्टी‑लेयर नेटवर्क्स को ट्रेन करना अविश्वसनीय और धीमा था। बैकप्रॉप ने कई परतों को साथ‑साथ ट्यून करने का एक व्यवस्थित, दोहराने योग्य तरीका दिया—केवल अंतिम परत को ट्वीक करने या अनुमान लगा कर समायोजन करने के बजाय।
यह बदलाव आगे के ब्रेकथ्रूज़ के लिए महत्वपूर्ण था: एक बार आप कई परतें प्रभावी रूप से ट्रेन कर सकते हैं, नेटवर्क अधिक समृद्ध फीचर सीख सकते हैं (उदा., किनारे → आकार → वस्तुएं)।
बैकप्रॉप नेटवर्क का "सोचना" या इंसान की तरह "समझना" नहीं है। यह गणित-संचालित फ़ीडबैक है: पैमानों को समायोजित करने का एक तरीका ताकि उदाहरणों के साथ बेहतर मिलान हो।
साथ ही, बैकप्रॉप कोई एक मॉडल नहीं है—यह एक प्रशिक्षण विधि है जिसे कई प्रकार के न्यूरल नेटवर्क्स पर लागू किया जा सकता है।
यदि आप नेटवर्क की संरचना पर एक मधुर गहराई चाहते हैं, तो देखें /blog/neural-networks-explained.
बोल्ट्ज़मान मशीनें Geoffrey Hinton के उन कदमों में से एक थीं जिसने न्यूरल नेटवर्क्स को उपयोगी आंतरिक प्रतिनिधित्व सीखने की दिशा दी—सिर्फ़ उत्तर देने तक सीमित न रहकर।
एक बोल्ट्ज़मान मशीन सरल यूनिट्स का नेटवर्क है जो ऑन/ऑफ़ हो सकते हैं (या आधुनिक वर्ज़न में वास्तविक मान लेते हैं)। यह सीधे आउटपुट का अनुमान लगाने के बजाय यूनिट्स के पूरे कॉन्फ़िगरेशन को एक ऊर्जा देता है। कम ऊर्जा का मतलब है "यह कॉन्फ़िगरेशन अर्थपूर्ण है।"
एक उपयोगी रूपक एक मेज़ है जिसमें छोटे गड्ढे और घाटियाँ हों। अगर आप सतह पर एक मार्बल गिराते हैं, तो वह रोल करेगा और निचले बिंदु में टिक जाएगा। बोल्ट्ज़मान मशीन कुछ ऐसा ही करती हैं: आंशिक जानकारी (कई बार डेटा द्वारा सेट कुछ विज़िबल यूनिट्स) देने पर, नेटवर्क अपने आंतरिक यूनिट्स को "हिलाता" है जब तक कि वे उन स्थितियों में न रुक जाएँ जिन्हें उसने अधिक संभाव्य माना हुआ है।
क्लासिक बोल्ट्ज़मान मशीन के प्रशिक्षण में मॉडल की मान्यताओं और डेटा के बीच के फर्क का अनुमान लगाने के लिए कई संभावित स्टेट्स को बार-बार सैम्पल करना पड़ता था। यह सैम्पलिंग बड़े नेटवर्क्स के लिए बेहद धीमा हो सकता था।
फिर भी, यह दृष्टिकोण प्रभावशाली था क्योंकि इसने:
आज अधिकांश उत्पाद फ़ीडफॉरवर्ड डीप नेटवर्क्स और बैकप्रॉप के साथ प्रशिक्षित होते हैं क्योंकि वे तेज़ और स्केल करने में आसान हैं।
बोल्ट्ज़मान मशीनों की विरासत ज़्यादातर वैचारिक है: यह विचार कि अच्छे मॉडल दुनिया की "पसंदीदा स्थितियाँ" सीखते हैं—और सीखना उन कम‑ऊर्जा घाटियों की ओर संभावना को ले जाना है।
न्यूरल नेटवर्क्स केवल कर्व फिट करने में बेहतर नहीं हुए—वे सही फीचर्स आविष्कृत करने में बेहतर हुए। यही "प्रतिनिधित्व सीखना" है: इंसान द्वारा हाथ से डिज़ाइन करने के बजाय, मॉडल ऐसे आंतरिक विवरण सीखता है जो टास्क को आसान बनाते हैं।
एक प्रतिनिधित्व मॉडल का अपना तरीका है कच्चे इनपुट को सारांशित करने का। यह अभी लेबल नहीं है जैसे "बिल्ली"; यह उपयोगी संरचना है वहाँ तक पहुँचने का—ऐसे पैटर्न जो ज़रूरत के हिसाब से मायने रखते हैं। शुरुआती परतें सरल संकेतों पर प्रतिक्रिया कर सकती हैं, जबकि बाद की परतें उन्हें अधिक सार्थक अवधारणाओं में जोड़ती हैं।
इस शिफ्ट से पहले, कई सिस्टम विशेषज्ञ-डिज़ाइन किए फीचर्स पर निर्भर थे: इमेज के लिए एज डिटेक्टर, भाषण के लिए हाथ से बनाए संकेत, या टेक्स्ट के लिए सावधानी से तैयार सांख्यिकीय फीचर। वे काम करते थे, पर बदलते हालात में अक्सर टूट जाते थे।
प्रतिनिधित्व सीखना मॉडल को खुद डेटा के अनुसार फीचर्स अनुकूलित करने देता है, जिससे सटीकता बढ़ती है और सिस्टम असली, गंदे इनपुट पर अधिक लचीला बनता है।
साझा धागा है पदानुक्रम: सरल पैटर्न मिलकर समृद्ध पैटर्न बनाते हैं।
छवि मान्यता में, एक नेटवर्क सबसे पहले किनारे-जैसे पैटर्न सीख सकता है (रोशनी‑से‑अँधेरा परिवर्तन)। फिर यह किनारों को मिलाकर कोनों और वक्रों में, उसके बाद पहियों या आँखों जैसे हिस्सों में, और अंत में "साइकिल" या "चेहरा" जैसी पूरी वस्तुओं में बदल सकता है।
Hinton के ब्रेकथ्रूज़ ने इस परत‑दर‑परत फीचर‑निर्माण को व्यवहारिक बनाया—और यही एक बड़ी वजह है कि डीप लर्निंग ने उन टास्क्स पर जीतना शुरू किया जिनकी लोगों को वाकई परवाह थी।
डीबीएन (Deep Belief Networks) उन महत्वपूर्ण स्टेप्स में से थे जिन्होंने आज हम जो गहरे न्यूरल नेटवर्क देखते हैं, उन्हें संभव बनाया। उच्च‑स्तर पर, एक DBN परतों का स्टैक है जहाँ हर परत नीचे की परत को प्रतिनिधित्व करना सीखती है—कच्चे इनपुट से शुरू करके धीरे‑धीरे अधिक सार्थक "कॉन्सेप्ट" बनाते हुए।
कल्पना कीजिए कि आप हैंडराइटिंग पहचानने की प्रणाली सिखा रहे हैं। DBN एक बार में सब कुछ सीखने की बजाय पहले सरल पैटर्न (जैसे किनारे और स्ट्रोक) सीखता है, फिर उन पैटर्नों के संयोजन (लूप्स, कोनों) सीखते हैं, और अंत में ऐसे उच्च‑स्तरीय आकृतियाँ बनती हैं जो अंकों के हिस्सों जैसी दिखती हैं।
प्रमुख विचार यह है कि हर परत बिना सही उत्तर बताए अपनी इनपुट संरचना का मॉडल बनाने की कोशिश करती है। फिर, जब स्टैक ने ये उपयोगी प्रतिनिधित्व सीख लिए, आप पूरे नेटवर्क को किसी विशेष टास्क के लिए फाइन‑ट्यून कर सकते हैं।
पहले गहरे नेटवर्क्स अक्सर यादृच्छिक इनिशियलाइज़ेशन पर अच्छे से ट्रेन नहीं होते थे। ट्रेनिंग सिग्नल कई परतों से होकर कमज़ोर या अस्थिर हो सकता था, और नेटवर्क अनउपयोगी सेटिंग्स में अटक सकता था।
लेयर‑बाय‑लेयर प्रीट्रेनिंग ने मॉडल को "वॉर्म स्टार्ट" दिया। हर परत ने डेटा की संरचना की एक समझ के साथ शुरू किया, इसलिए पूरा नेटवर्क अँधा खोज नहीं कर रहा था।
प्रीट्रेनिंग ने हर समस्या का जादू से हल नहीं किया, पर यह उस समय गहराई को व्यावहारिक बनाने में मददगार साबित हुआ जब डेटा, कम्प्यूट और ट्रेनिंग ट्रिक्स आज जितने परिष्कृत नहीं थे।
DBNs ने यह दिखाया कि कई परतों में अच्छे प्रतिनिधित्व सीखना काम कर सकता है—और कि गहराई सिर्फ़ सिद्धांत नहीं, बल्कि उपयोगी राह थी।
न्यूरल नेटवर्क्स कभी-कभी "परीक्षा की तैयारी" में अजीब तरह से माहिर होते हैं: वे ट्रेनिंग डेटा को याद कर लेते हैं बजाय कि उस में निहित पैटर्न सीखने के—इसी समस्या को ओवरफिटिंग कहा जाता है।
कल्पना कीजिए आप ड्राइविंग परीक्षा के लिए उसी सटीक मार्ग को याद कर रहे हैं जो पिछली बार प्रयोग हुआ था—हर मोड़, हर स्टॉप सिग्नल, हर गड्ढा। अगर परीक्षा वही मार्ग रखती है तो आप बढ़िया करेंगे। पर अगर मार्ग बदल जाए तो प्रदर्शन गिर जाएगा क्योंकि आपने सामान्य ड्राइविंग कौशल नहीं सीखा, एक विशेष स्क्रिप्ट सीख ली।
यही ओवरफिटिंग है: परिचित उदाहरणों पर अधिक सटीकता, नए उदाहरणों पर कमजोर परिणाम।
ड्रॉपआउट को Geoffrey Hinton और सहयोगियों ने लोकप्रिय बनाया। प्रशिक्षण के दौरान, नेटवर्क हर पास पर यादृच्छिक रूप से कुछ यूनिट्स को "बंद" (drop out) कर देता है।
यह मॉडल को किसी एक रास्ते या "पसंदीदा" फीचर सेट पर निर्भर रहने से रोकता है। इसके बजाय, इसे कई कनेक्शनों में सूचना फैलानी पड़ती है और ऐसे पैटर्न सीखने पड़ते हैं जो तब भी टिके रहें जब नेटवर्क का कुछ हिस्सा गायब हो।
एक सहायक मानसिक मॉडल: यह ऐसा है जैसे पढ़ाई करते समय कभी‑कभी आपकी नोट्स के यादृच्छिक पन्ने अनुपलब्ध हो जाएँ—तो आप किसी एक वाक्य को याद करने की बजाय अवधारणा को समझने के लिए बाध्य होते हैं।
मुख्य लाभ बेहतर सामान्यीकरण है: नेटवर्क नए, न देखे गए डेटा पर अधिक विश्वसनीय बनता है। व्यवहार में, ड्रॉपआउट ने बड़े नेटवर्क्स को ऐसा ट्रेन करने में मदद की कि वे केवल चतुर यादशीक्षा में न फंसें, और यह कई डीप लर्निंग सेटअप्स में एक मानक उपकरण बन गया।
AlexNet से पहले, "इमेज रिकग्निशन" सिर्फ़ एक दिलचस्प डेमो नहीं था—यह मापा जाने वाला प्रतिस्पर्धात्मक क्षेत्र था। ImageNet जैसे बेंचमार्क्स ने सरल सवाल पूछा: एक फोटो दीजिए, क्या आपकी व्यवस्था बता सकती है कि उसमें क्या है?
कठिनाई थी स्केल में: लाखों चित्र और हजारों श्रेणियाँ। यह आकार महत्वपूर्ण था क्योंकि इसने छोटे प्रयोगों में अच्छे दिखने वाले विचारों को उन तरीकों से अलग किया जो वास्तविक दुनिया की गड़बड़ी में टिकते थे।
प्रगति आम तौर पर धीरे-धीरे होती रही। फिर AlexNet (Alex Krizhevsky, Ilya Sutskever, और Geoffrey Hinton द्वारा निर्मित) आया और परिणामों को किसी आरामदायक चढ़ाई की तरह नहीं बल्कि एक बड़ा छलांग की तरह दिखाया।
AlexNet ने दिखाया कि एक गहरा कन्वोल्यूशनल न्यूरल नेटवर्क सर्वश्रेष्ठ पारंपरिक कंप्यूटर विज़न पाइपलाइनों को हरा सकता है जब तीन तत्व मिलते हैं:
यह केवल "बड़ा मॉडल" नहीं था। यह गहरे नेटवर्क्स को असल‑दुनिया के टास्क्स पर प्रभावी रूप से ट्रेन करने की एक व्यावहारिक विधि थी।
कल्पना कीजिए कि आप फोटो पर एक छोटा "विंडो" सरकाते हैं—जैसे टिकट‑स्टाम्प को इमेज पर घसीटना। उस विंडो के अंदर नेटवर्क किसी सरल पैटर्न की तलाश करता है: एक किनारा, एक कोना, एक पट्टी। वही पैटर्न‑चेक हर जगह दोहराया जाता है, इसलिए यह पाता है कि "किनारे‑जैसे चीज़" चाहे इमेज के किस हिस्से में हों।
इन परतों को स्टैक करिए और आपको एक पदानुक्रम मिलता है: किनारे बनते हैं बनावट, बनावट बनते हैं हिस्से (जैसे पहिये), और हिस्से बनते हैं वस्तुएँ (जैसे साइकिल)।
AlexNet ने डीप लर्निंग को भरोसेमंद और निवेशयोग्य दिखाया। अगर गहरे नेट्स एक कठिन सार्वजनिक बेंचमार्क पर हावी हो सकते हैं, तो वे उत्पादों में भी सुधार ला सकते हैं—सर्च, फोटो टैगिंग, कैमरा फीचर, पहुँच संबंधी टूल्स और बहुत कुछ।
इसने न्यूरल नेटवर्क्स को "वादा करने वाला शोध" से वास्तविक सिस्टम बनाने की निश्चित दिशा में बदल दिया।
डीप लर्निंग अचानक नहीं आई। यह तब नाटकीय दिखी जब कुछ आवश्यक तत्व साथ आ गए—कई सालों के पहले के कामों के बाद जो विचारों को आशाजनक परन्तु स्केल करने में कठिन दिखाते थे।
ज़्यादा डेटा. वेब, स्मार्टफ़ोन और बड़े लेबल्ड डेटासेट (जैसे ImageNet) ने नेटवर्क्स को लाखों उदाहरणों से सीखने के काबिल बनाया। छोटे डेटासेट्स पर बड़े मॉडल ज़्यादातर याद कर लेते थे बजाय कि सीखने के।
ज़्यादा कम्प्यूट (खासकर GPUs). एक गहरे नेटवर्क को प्रशिक्षित करना अरबों बार वही गणित करने जैसा है। GPUs ने इसे सस्ता और तेज़ बना दिया। जो पहले हफ्तों लेता था, अब दिनों या घंटों में होने लगा—इससे शोधकर्ता अधिक आर्किटेक्चर और हाइपरपैरामीटर आजमा सके।
बेहतर ट्रेनिंग ट्रिक्स. व्यावहारिक सुधारों ने "यह ट्रेन होता है… या नहीं" जैसी अनियमितता को कम किया:
इनमें से कोई भी कोर विचार नहीं बदला; बदल गया कि उन्हें भरोसेमंद तरीके से काम में कैसे लाया जाए।
एक बार कंप्यूट और डेटा ने एक सीमा पार की, सुधार एक के ऊपर एक जुड़ने लगे। बेहतर परिणामों ने अधिक निवेश आकर्षित किया, जिसने और बड़े डेटासेट और तेज़ हार्डवेयर को वित्तपोषित किया, जिसने और बेहतर परिणाम दिए। बाहर से यह छलांग जैसा दिखता है; अंदर से इसे संयोजित प्रगति कहना बेहतर है।
स्केल बढ़ाना वास्तविक लागतें लाता है: अधिक ऊर्जा उपयोग, महंगे ट्रेनिंग रन, और मॉडल को कुशलतापूर्वक तैनात करने की अधिक मेहनत। यह छोटे टीमों और पर्याप्त संसाधनों वाली लैब्स के बीच के अंतर को भी बढ़ाता है।
Hinton के प्रमुख विचार—डेटा से उपयोगी प्रतिनिधित्व सीखना, गहरे नेटवर्क्स को भरोसेमंद तरीके से ट्रेन करना, और ओवरफिटिंग रोकना—ऐसी "फीचर" नहीं हैं जिन्हें किसी ऐप में सीधे इंगित किया जा सके। ये वजहें हैं कि कई रोज़मर्रा की चीज़ें तेज़, अधिक सटीक और कम निराशाजनक महसूस होती हैं।
आधुनिक सर्च केवल कीवर्ड मैच नहीं करती। वे क्वेरी और सामग्री के प्रतिनिधित्व सीखती हैं ताकि “best noise-canceling headphones” जैसी क्वेरी उन पन्नों को ला सके जो बिल्कुल वही वाक्यांश नहीं दोहराते। यही प्रतिनिधित्व सीखना उस तरह के सिफारिश फ़ीड्स में मदद करता है जो दो आइटम्स को "समान" समझते हैं भले ही उनकी डिस्क्रिप्शन अलग हो।
मशीन अनुवाद में बड़ा सुधार तब आया जब मॉडल परतों के पैटर्न सीखने में बेहतर हुए (चर → शब्द → अर्थ)। भले ही मॉडल का प्रकार विकसित हुआ हो, प्रशिक्षण का नुस्खा—बड़े डेटासेट, सावधान ऑप्टिमाइज़ेशन, और रेगुलराइज़ेशन—आज भी विश्वसनीय भाषा फीचर बनाने के तरीके को आकार देता है।
वॉयस असिस्टेंट और डिक्टेशन उन न्यूरल नेटवर्क्स पर निर्भर करते हैं जो गंदे ऑडियो को साफ़ टेक्स्ट में बदलते हैं। बैकप्रोप यहाँ वर्कहॉर्स है, जबकि ड्रॉपआउट जैसी तकनीकें मॉडलों को किसी एक स्पीकर या माइक्रोफ़ोन की विचित्रताओं को याद करने से रोकती हैं।
फोटो ऐप्स चेहरों को पहचान सकती हैं, समान दृश्यों को समूहित कर सकती हैं, और आपको बिना मैनुअल टैगिंग के "बीच" तलाशने दे सकती हैं। यह प्रतिनिधित्व सीखने का व्यावहारिक रूप है: सिस्टम विज़ुअल फीचर्स (किनारे → बनावट → वस्तुएँ) सीखता है जो टैगिंग और रिट्रीवल को स्केल पर काम करने लायक बनाते हैं।
भले ही आप मॉडल को स्क्रैच से ट्रेन्ड न कर रहे हों, ये सिद्धांत रोज़मर्रा के उत्पाद कार्य में दिखते हैं: अक्सर प्रीट्रेंड मॉडल से शुरू करिए, ट्रेनिंग और मूल्यांकन को स्थिर करिए, और जब सिस्टम बेंचमार्क याद करने लगे तो रेगुलराइज़ेशन का उपयोग कीजिए।
यह भी कारण है कि आधुनिक "vibe-coding" टूल्स इतना सक्षम महसूस कर सकते हैं। प्लेटफ़ॉर्म जैसे Koder.ai मौजूदा पीढ़ी के LLMs और एजेंट वर्कफ़्लोज़ के ऊपर बैठकर टीमों को सामान्य भाषा के स्पेक से वेब, बैकएंड, या मोबाइल ऐप जल्दी बनाने में मदद करते हैं—अक्सर पारंपरिक पाइपलाइनों से तेज़—और फिर भी स्रोत कोड एक्सपोर्ट और परम्परागत तैनाती की अनुमति देते हैं।
यदि आप ट्रेनिंग की उच्च‑स्तरीय समझ चाहते हैं, तो देखें /blog/backpropagation-explained.
बड़े ब्रेकथ्रूज़ अक्सर सरल कहानियों में बदल दिए जाते हैं। यह याद रखना आसान बनाता है—पर साथ ही ऐसे मिथक भी बनते हैं जो असल घटनाओं और आज क्या मायने रखता है उसे छिपा देते हैं।
Hinton एक केंद्रीय आंकड़ा हैं, पर आधुनिक न्यूरल नेटवर्क कई दशकों के काम का परिणाम हैं: ऑप्टिमाइज़ेशन मेथड्स विकसित करने वाले शोधकर्ता, डेटासेट बनाने वाले लोग, ट्रेनिंग के लिए GPUs को व्यवहारिक बनाने वाले इंजीनियर, और बड़े पैमाने पर सिद्ध करने वाली टीमें।
Hinton के काम में भी उनके स्टूडेंट्स और सहयोगियों की बड़ी भूमिका रही। वास्तविक कहानी योगदानों की एक कड़ी है जो अंततः साथ आ गई।
न्यूरल नेटवर्क पर शोध मध्य‑20वीं सदी से हो रहा है, उत्तेजना और निराशा के दौरों के साथ। जो बदला वह विचारों का अस्तित्व नहीं था, बल्कि बड़े मॉडल को विश्वसनीय तरीके से ट्रेन करने और वास्तविक समस्याओं पर स्पष्ट जीत दिखाने की क्षमता थी।
"डीप लर्निंग युग" एक पुनरुत्थान है, अचानक अविष्कार नहीं।
गहरे मॉडल मदद कर सकते हैं, पर वे जादू नहीं हैं। ट्रेनिंग समय, लागत, डेटा गुणवत्ता, और घटती उपादेयता वास्तविक सीमा हैं। छोटे मॉडल कभी‑कभी बड़े मॉडलों को मात दे देते हैं क्योंकि वे ट्यून करना आसान होते हैं, शोर के प्रति कम संवेदनशील होते हैं, या टास्क के लिए बेहतर मिलते हैं।
बैकप्रोप मॉडल पैरामीटर समायोजित करने का एक व्यावहारिक तरीका है जो लेबल्ड फ़ीडबैक का उपयोग करता है। इंसान कम उदाहरणों से सीखते हैं, समृद्ध पूर्वज्ञान का उपयोग करते हैं, और उसी तरह के स्पष्ट त्रुटि‑सिग्नल पर निर्भर नहीं होते।
न्यूरल नेट्स जैविक प्रेरणा से प्रभावित हो सकते हैं, पर वे मस्तिष्क के सटीक अनुकरण नहीं हैं।
Hinton की कहानी सिर्फ़ आविष्कारों की सूची नहीं है। यह एक पैटर्न है: एक सरल सीखने का विचार रखें, उसे लगातार परखें, और आसपास की आवश्यक चीज़ों (डेटा, कम्प्यूट, ट्रेनिंग ट्रिक्स) को अपडेट करते जाएँ जब तक वह बड़े पैमाने पर काम न करे।
सबसे हस्तांतरित करने योग्य आदतें व्यावहारिक हैं:
शीर्षक पाठ से प्रेरित होकर यह सोचना आकर्षक है कि "बड़े मॉडल ही जीतते हैं।" यह अधूरा है।
बिना स्पष्ट लक्ष्यों के आकार की दौड़ अक्सर ले जाती है:
एक बेहतर डिफ़ॉल्ट है: छोटे से शुरू करें, मूल्य सिद्ध करें, फिर स्केल करें—और केवल उसी हिस्से को स्केल करें जो स्पष्ट रूप से प्रदर्शन सीमित कर रहा हो।
यदि आप इन सबक को रोज़मर्रा के अभ्यास में बदलना चाहते हैं, तो ये उपयोगी पढ़ें:
बैकप्रोप के बेसिक नियम से लेकर, अर्थ पकड़ने वाले प्रतिनिधित्वों, ड्रॉपआउट जैसे व्यावहारिक ट्रिक्स, और AlexNet जैसे ब्रेकथ्रू डेमो तक—कहानी एक समान है: डेटा से उपयोगी फीचर्स सीखिए, ट्रेनिंग को स्थिर बनाइए, और असली नतीजों से प्रगति का सत्यापन कीजिए।
यही प्लेबुक है जिसे रखना चाहिए।
Geoffrey Hinton इसलिए महत्वपूर्ण हैं क्योंकि उन्होंने बार-बार उन तरीकों को व्यावहारिक बनाया जब कई शोधकर्ता न्यूरल नेटवर्क को बुहत ही कमज़ोर रास्ता मानते थे।
“एआई का आविष्कार” करने के बजाय, उनका योगदान इस बात में है कि उन्होंने प्रतिनिधित्व सीखने (डेटा से सुविधाएँ सीखना), प्रशिक्षण विधियों में सुधार और एक ऐसी रिसर्च संस्कृति को बढ़ावा दिया जो हाथ से नियम लिखने के बजाय डेटा से फीचर सीखने पर केंद्रित थी।
यहाँ “ब्रेकथ्रू” का मतलब यह है कि न्यूरल नेटवर्क अधिक भरोसेमंद और उपयोगी बन गए: वे बेहतर तरीके से ट्रेन होते हैं, बेहतर आंतरिक फीचर सीखते हैं, नए डेटा पर बेहतर सामान्यीकरण करते हैं, या कठिन कामों पर पैमाना बढ़ा पाए।
यह किसी एक चमकदार डेमो के बारे में कम है और किसी विचार को ऐसे प्रयोगिक तरीके में बदलने के बारे में ज़्यादा है जिस पर टीमें भरोसा कर सकें।
न्यूरल नेटवर्क का लक्ष्य गन्दे कच्चे इनपुट (पिक्सल, ऑडियो वेवफॉर्म, टेक्स्ट टोकन) को उपयोगी प्रतिनिधित्व में बदलना है—आंतरिक फीचर जो मायने रखते हैं।
इंजीनियर हर फीचर हाथ से बनवाने की बजाय, मॉडल उदाहरणों से परत दर परत फीचर सीखता है, जिससे यह सामान्य परिस्थितियों में (लाइटिंग, उच्चारण, शब्दों के बदलने) अधिक मजबूत बनता है।
बैकप्रोप (backpropagation) एक प्रशिक्षण विधि है जो नेटवर्क को उसकी गलतियों से बेहतर बनाती है:
यह ग्रैडिएंट डिसेंट जैसे एल्गोरिदम के साथ काम करता है, जो त्रुटि को कम करने की दिशा में छोटे-छोटे कदम उठाता है।
बैकप्रोप ने कई परतों को एक साथ व्यवस्थित तरीके से ट्यून करने को संभव बना दिया।
यह महत्वपूर्ण इसलिए है क्योंकि गहरी नेटवर्क्स फीचर हायरेरकी (उदा., किनारे → आकार → वस्तु) बना पाते हैं। बिना भरोसेमंद तरीके के कई परतों को ट्रेन करना अक्सर असफल रहा करता था, और बैकप्रोप ने वही भरोसेमंद प्रक्रिया दी।
बोल्ट्ज़मान मशीनें ऐसे नेटवर्क थीं जो किसी भी यूनिट कॉन्फ़िगरेशन को एक ऊर्जा स्कोर देती हैं; कम ऊर्जा मतलब "यह कॉन्फ़िगरेशन अधिक संभाव्य है"।
वे महत्वपूर्ण थीं क्योंकि वे:
क्लासिक प्रशिक्षण अक्सर धीमा था, इसलिए ये आज के प्रोडक्ट्स में कम सामान्य हैं, पर वैचारिक रूप से इनका प्रभाव बड़ा रहा।
रिप्रेजेंटेशन लर्निंग का अर्थ है कि मॉडल अपने आंतरिक फीचर (प्रतिनिधित्व) सीखता है जो टास्क को आसान बनाते हैं, न कि हाथ से बनाए गए फीचर पर निर्भर रहना।
व्यावहारिक रूप से, इससे रोबस्टनेस बढ़ती है: सिखाए गए फीचर असली डेटा विविधता (शोर, अलग कैमरे, अलग स्पीकर्स) के अनुरूप ढल जाते हैं जबकि मनुष्य-निर्मित pipelines अक्सर भंगुर होते हैं।
डीप बलीफ नेटवर्क (DBN) ने परत-दर-परत प्रीट्रेनिंग का उपयोग करके गहराई को व्यावहारिक बनाया।
प्रत्येक परत पहले अपने इनपुट की संरचना बिना लेबल के सीखती है, जिससे पूरे नेटवर्क को "वॉर्म स्टार्ट" मिलता है। फिर वह पूरा स्टैक किसी विशेष टास्क (जैसे क्लासिफिकेशन) के लिए फाइन‑ट्यून किया जाता है।
ड्रॉपआउट ओवरफिटिंग से इस तरह लड़ता है कि प्रशिक्षण के दौरान नेटवर्क पर यादृच्छिक रूप से कुछ यूनिट्स "बंद" कर दिए जाते हैं।
यह नेटवर्क को किसी एक पाथ या फीचर सेट पर अत्यधिक निर्भर होने से रोकता है और इसे ऐसे फीचर सीखने के लिए मजबूर करता है जो तब भी काम करें जब मॉडल का कुछ हिस्सा गायब हो—अक्सर नए, असतत डेटा पर सामान्यीकरण में सुधार होता है।
AlexNet ने दिखाया कि गहरी convolutional नेटवर्क्स, GPUs और बड़ी लेबल्ड डाटासेट (ImageNet) के संयोजन से पारंपरिक कंप्यूटर विज़न पाइपलाइनों को हराया जा सकता है।
यह केवल "बड़ा मॉडल" नहीं था—यह एक व्यावहारिक नुस्खा था जिसने यह विश्वास दिलाया कि गहरे नेटवर्क्स असल दुनिया की समस्याओं पर स्थायी रूप से बेहतर काम कर सकते हैं, और इसी ने उद्योग का ध्यान खींचा।