21 जुल॰ 2025·8 मिनट
घटना प्रभाव विश्लेषण के लिए वेब ऐप बनाना — चरण-दर-चरण
सेवा निर्भरताओं, रीयल-टाइम सिग्नल और स्पष्ट डैशबोर्ड का उपयोग करके घटना (इन्सिडेंट) के प्रभाव की गणना करने वाला वेब ऐप कैसे डिज़ाइन और बनाया जाए, सीखें।
सेवा निर्भरताओं, रीयल-टाइम सिग्नल और स्पष्ट डैशबोर्ड का उपयोग करके घटना (इन्सिडेंट) के प्रभाव की गणना करने वाला वेब ऐप कैसे डिज़ाइन और बनाया जाए, सीखें।
कैलकुलेशन या डैशबोर्ड बनाने से पहले तय करें कि आपकी संस्था में “प्रभाव” का वास्तविक मतलब क्या है। यदि आप यह चरण छोड़ते हैं, तो आपको एक ऐसा स्कोर मिलेगा जो वैज्ञानिक दिखता है पर किसी के काम का नहीं।
प्रभाव किसी घटना का उस चीज़ पर मापनीय परिणाम है जो व्यापार के लिए मायने रखती है। सामान्य आयामों में शामिल हैं:
2–4 प्राथमिक आयाम चुनें और उन्हें स्पष्ट रूप से परिभाषित करें। उदाहरण: “Impact = प्रभावित भुगतान करने वाले ग्राहक + SLA मिनट जोखिम में,” न कि “Impact = ग्राफ़ पर कुछ भी जो बुरा दिखता है।”
विभिन्न भूमिकाएँ अलग निर्णय लेती हैं:
“इम्पैक्ट” आउटपुट इस तरह डिज़ाइन करें कि हर दर्शक अपनी मुख्य प्रश्न का उत्तर बिना मेट्रिक्स ट्रांसलेट किए दे सके।
क्या लेटेंसी स्वीकार्य है यह तय करें। “रियल-टाइम” महँगा होता है और अक्सर आवश्यक नहीं होता; नियर-रियल-टाइम (उदा., 1–5 मिनट) निर्णय लेने के लिए अक्सर काफी होता है।
इसे एक प्रोडक्ट आवश्यकता के रूप में लिखें क्योंकि यह इनगेशन, कैशिंग और UI को प्रभावित करता है।
आपका MVP सीधे उन कार्रवाइयों का समर्थन करना चाहिए जैसे:
यदि कोई मीट्रिक किसी निर्णय को नहीं बदलता, तो संभवतः वह “प्रभाव” नहीं—बस टेलीमेट्री है।
स्क्रीन डिज़ाइन या डेटाबेस चुनने से पहले लिखें कि वास्तविक घटना के दौरान “इम्पैक्ट एनालिसिस” को किन प्रश्नों का उत्तर देना चाहिए। लक्ष्य दिन एक पर पूर्ण सटीकता नहीं है—बल्कि लगातार, समझाने योग्य नतीजे हैं जिन पर रेस्पॉन्डर भरोसा कर सकें।
शुरू में जिन डाटाओं को आप इन्गेस्ट या संदर्भित करेंगे ताकि इम्पैक्ट की गणना हो सके:
बहुत सी टीमों के पास दिन एक पर परफेक्ट डिपेंडेंसी या ग्राहक मैपिंग नहीं होती। तय करें आप किन चीजों को मैन्युअल एंट्री की अनुमति देंगे ताकि ऐप फिर भी उपयोगी रहे:
इनको स्पष्ट फ़ील्ड्स के रूप में डिज़ाइन करें (ad-hoc नोट्स नहीं) ताकि ये बाद में क्वेरी करने योग्य हों।
आपका पहला रिलीज़ विश्वसनीय रूप से उत्पन्न करे:
इम्पैक्ट एनालिसिस एक निर्णय उपकरण है, इसलिए प्रतिबंध मायने रखते हैं:
इन आवश्यकताओं को टेस्टेबल स्टेटमेंट्स के रूप में लिखें। यदि आप इसे सत्यापित नहीं कर सकते, तो आप आउटेज के दौरान उस पर भरोसा नहीं कर पाएँगे।
आपका डेटा मॉडल इनगेशन, कैलकुलेशन और UI के बीच कॉन्ट्रैक्ट है। यदि इसे सही बनाते हैं, तो आप टूलिंग स्रोत बदल सकते हैं, स्कोरिंग सुधार सकते हैं, और फिर भी वही प्रश्नों के उत्तर दे पाएँगे: “क्या टूटा?”, “कौन प्रभावित है?”, और “कितनी देर?”
न्यूनतम, इन्हें फ़र्स्ट-क्लास रिकॉर्ड के रूप में मॉडल करें:
service A → service B मेटाडेटा के साथ (type, criticality)।IDs स्थिर और स्रोतों के बीच सुसंगत रखें। अगर आपके पास पहले से सर्विस कैटलॉग है, तो उसे सत्यता-स्रोत मानें और बाहरी टूल आइडेंटिफायर्स को उसमें मैप करें।
रिपोर्टिंग और विश्लेषण के समर्थन के लिए इंसिडेंट पर कई टाइमस्टैम्प स्टोर करें:
इम्पैक्ट स्कोरिंग के लिए कैल्क्युलेटेड टाइम विंडोज़ भी स्टोर करें (उदा., 5-मिनट बकेट)। इससे रिप्ले और तुलना सरल होती है।
दो मुख्य ग्राफ़ मॉडल करें:
एक सरल पैटर्न है customer_service_usage(customer_id, service_id, weight, last_seen_at) ताकि आप यह रैंक कर सकें कि “किस ग्राहक का उस पर कितना निर्भरता है।”
डिपेंडेंसीज़ विकसित होती हैं, और इम्पैक्ट कैलकुलेशन को उस समय की सच्चाई दिखानी चाहिए। एजेज़ पर effective dating जोड़ें:
dependency(valid_from, valid_to)ग्राहक सब्सक्रिप्शन्स और उपयोग स्नैपशॉट्स के लिए भी यही करें। हिस्टोरिकल वर्ज़न्स के साथ आप पिछले इन्सिडेंट्स को सटीक रूप से फिर से चला सकते हैं और लगातार SLA रिपोर्टिंग कर सकते हैं।
आपका इम्पैक्ट एनालिसिस केवल उतना ही अच्छा है जितने अच्छे इनपुट होते हैं। लक्ष्य सरल है: जिन टूल्स का आप पहले से इस्तेमाल करते हैं उनसे सिग्नल खींचें, फिर उन्हें एक सुसंगत ईवेंट स्ट्रीम में कन्वर्ट करें जिसे आपका ऐप समझ सके।
एक छोटे स्रोतों की सूची से शुरू करें जो विश्वसनीय रूप से बताते हैं कि “कुछ बदल गया”:
एक बार में सब कुछ इन्गेस्ट करने की कोशिश न करें। ऐसे स्रोत चुनें जो डिटेक्शन, एस्केलेशन और पुष्टि को कवर करते हों।
विभिन्न टूल्स अलग- अलग इंटीग्रेशन पैटर्न सपोर्ट करते हैं:
एक व्यवहारिक तरीका: क्रिटिकल सिग्नल्स के लिए वेबहुक और गैप भरने के लिए बैच इम्पोर्ट।
प्रत्येक इनकमिंग आइटम को एक ही “ईवेंट” शेप में सामान्यीकृत करें, चाहे स्रोत उसे अलर्ट, इंसिडेंट या एनोटेशन कहे। न्यूनतम रूप से स्टैंडर्डाइज़ करें:
अशुद्ध डेटा की उम्मीद रखें। डुप्लीकेशन रोकने के लिए idempotency keys (source + external_id) का उपयोग करें, arrival time के बजाय occurred_at पर सॉर्ट करके आर्डर से बाहर ईवेंट्स सहन करें, और मिसिंग फील्ड्स के लिए सुरक्षित डिफ़ॉल्ट लागू करें (उन्हें समीक्षा के लिए फ्लैग करते हुए)।
UI में एक छोटा “unmatched service” क्वे्यू निश्चिच करें ताकि चुपके से त्रुटियाँ ना हों और आपके इम्पैक्ट परिणाम भरोसेमंद रहें।
अगर आपका डिपेंडेंसी मैप गलत है, तो आपका ब्लास्ट-रेडियस भी गलत होगा—भले ही आपके सिग्नल और स्कोरिंग परफेक्ट हों। लक्ष्य एक ऐसा डिपेंडेंसी ग्राफ़ बनाना है जिस पर आप इन्सिडेंट के दौरान और बाद में भरोसा कर सकें।
एजेज़ मैप करने से पहले नोड्स परिभाषित करें। हर सिस्टम के लिए एक सर्विस कैटलॉग एंट्री बनाएं जिसे आप इन्सिडेंट में संदर्भित कर सकते हैं: APIs, बैकग्राउंड वर्कर्स, डेटा स्टोर्स, थर्ड-पार्टी वेंडर्स, और अन्य क्रिटिकल शेयरड कंपोनेंट्स।
हर सर्विस में कम-से-कम शामिल होना चाहिए: owner/team, tier/criticality (उदा., ग्राहक-सामने वाला बनाम आंतरिक), SLA/SLO टार्गेट, और runbooks/on-call docs के लिंक (उदा., /runbooks/payments-timeouts)।
दो परस्पर पूरक स्रोत उपयोग करें:
इनको अलग एज टाइप्स के रूप में रखें ताकि लोग भरोसा समझ सकें: “टीम द्वारा घोषित” बनाम “पिछले 7 दिनों में ऑब्ज़र्व्ड।”
डिपेंडेंसीज़ को दिशानिर्देशित होना चाहिए: Checkout → Payments और Payments → Checkout एक जैसे नहीं हैं। दिशा कारण-निरुपण को चलाती है (“यदि Payments खराब है, तो कौन से upstreams फेल हो सकते हैं?”)।
साथ ही हार्ड vs सॉफ्ट डिपेंडेंसीज़ मॉडल करें:
यह भ्रामक प्रभाव को रोकता है और रेस्पॉन्डर्स को प्राथमिकता देने में मदद करता है।
आपकी आर्किटेक्चर साप्ताहिक बदलती है। यदि आप स्नैपशॉट स्टोर नहीं करते, तो आप दो महीने पहले की घटना का सही विश्लेषण नहीं कर पाएँगे।
डिपेंडेंसी ग्राफ़ वर्ज़न्स को समय पर सहेजें (रोज़ाना, प्रति डिप्लॉय, या परिवर्तन पर)। जब ब्लास्ट-रेडियस की गणना करें, तो इन्सिडेंट टाइमस्टैम्प को सबसे नज़दीकी ग्राफ स्नैपशॉट पर रेसॉल्व करें, ताकि “कौन प्रभावित था” उस पल की वास्तविकता को दर्शाए — न कि आज की आर्किटेक्चर।
एक बार जब आप सिग्नल (अलर्ट्स, SLO बर्न, सिंथेटिक चेक्स, कस्टमर टिकट्स) इनजेस्ट कर लेते हैं, तो ऐप को एक सुसंगत तरीका चाहिए जिससे गंदे इनपुट्स को साफ़ बयान में बदला जाए: क्या टूटा है, कितना बुरा है, और कौन प्रभावित है?
MVP के लिए आप इन पैटर्न्स में से किसी से काम चला सकते हैं:
जो भी तरीका चुनें, मध्यम मान (threshold hit, weights, tier) सहेजें ताकि लोग समझ सकें क्यों स्कोर हुआ।
सब कुछ एक नंबर में जल्दी समेटने से बचें। कुछ आयाम अलग-अलग ट्रैक करें, फिर कुल गंभीरता निकाले:
यह मदद करता है रेस्पॉन्डर्स को स्पष्ट रूप से संचार करने में (उदा., “उपलब्ध है पर धीमा” बनाम “गलत परिणाम दे रहा है”)।
इम्पैक्ट सिर्फ सर्विस हेल्थ नहीं है—यह यह भी है कि किसने इसे महसूस किया।
यूसेज मैपिंग (tenant → service, customer plan → features, user traffic → endpoint) का उपयोग करें और इम्पैक्ट टाइम-विंडो के भीतर प्रभावित ग्राहकों की गणना करें (start time, mitigation time, और कोई भी बैकफिल अवधि)।
अनुमानों के बारे में स्पष्ट रहें: सैंपल्ड लॉग्स, अनुमानित ट्रैफ़िक, या आंशिक टेलीमेट्री।
ऑपरेटरों को ओवरराइड करने की आवश्यकता होगी: false-positive अलर्ट, पार्टियल रोलआउट, ज्ञात उपसमूह।
Severity, आयाम, और प्रभावित ग्राहकों में मैन्युअल एडिट्स की अनुमति दें, पर आवश्यक हों:
यह ऑडिट ट्रेल डैशबोर्ड पर भरोसा बनाता है और पोस्ट-इन्सिडेंट रिव्यू को तेज़ बनाता है।
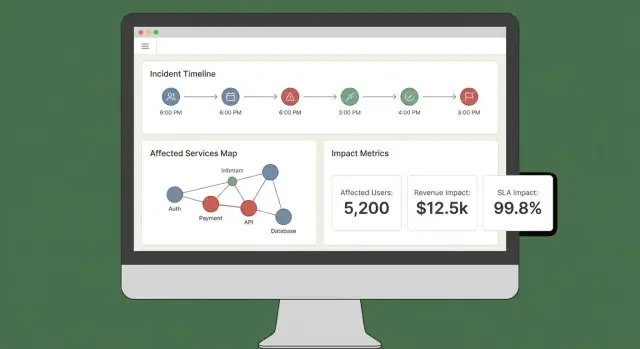
एक अच्छा इम्पैक्ट डैशबोर्ड तीन सवालों का तेज़ उत्तर देता है: क्या प्रभावित है? कौन प्रभावित है? और हम कितना सुनिश्चित हैं? अगर उपयोगकर्ताओं को पाँच टैब खोलने पड़ें तो भरोसा नहीं होगा — या कार्रवाई नहीं होगी।
छोटे सेट से शुरू करें जो वास्तविक इंसिडेंट वर्कफ़्लोज़ से मेल खाते हैं:
बिना व्याख्या के इम्पैक्ट स्कोर्स मनमाने लगते हैं। हर स्कोर को इनपुट्स और नियमों तक ट्रेसएबल होना चाहिए:
एक सरल “Explain impact” ड्रॉअर या पैनल मुख्य व्यू को अव्यवस्थित किए बिना यह काम कर सकता है।
इम्पैक्ट को सर्विस, क्षेत्र, कस्टमर टीयर, और समय सीमा के अनुसार आसानी से स्लाइस करना चाहिए। उपयोगकर्ताओं को किसी भी चार्ट पॉइंट या रो पर क्लिक करके रॉ सबूत (ठीक वही मॉनिटर्स, लॉग्स, या ईवेंट्स जिन्होंने चेंज डाला) तक ड्रिल करने दें।
एक सक्रिय घटना के दौरान लोगों को पोर्टेबल अपडेट चाहिए। शामिल करें:
यदि आपके पास पहले से स्टेटस पेज है, तो इसे relative route जैसे /status के माध्यम से लिंक करें ताकि कम्युनिकेशन टीम जल्दी क्रॉस-रेफर कर सके।
इम्पैक्ट एनालिसिस केवल तभी उपयोगी है जब लोग उस पर भरोसा करें—जिसका मतलब है कि किसे क्या देखने की अनुमति है और परिवर्तन का स्पष्ट रिकॉर्ड रखना।
छोटे सेट की भूमिकाएँ परिभाषित करें जो घटना के तरीके से मेल खाती हों:
परमिशन्स को एक्शन के अनुसार संरेखित रखें, न कि सिर्फ नौकरी के शीर्षक के अनुसार। उदा., “can export customer impact report” एक परमिशन है जिसे आप कमांडर और कुछ एडमिन को दे सकते हैं।
इम्पैक्ट एनालिसिस अक्सर ग्राहक आइडेंटिफायर्स, कॉन्ट्रैक्ट टीयर्स, और कभी-कभी संपर्क विवरण छूता है। डिफ़ॉल्ट रूप से least privilege लागू करें:
की-एक्शन्स को पर्याप्त संदर्भ के साथ लॉग करें ताकि रिव्यू संभव हो:
ऑडिट लॉग्स append-only रखें, timestamps और actor identity के साथ। इन्हें प्रति-इंसिडेंट searchable रखें ताकि पोस्ट-इन्सिडेंट रिव्यू में उपयोगी हों।
दस्तावेज़ करें कि आप अभी क्या सपोर्ट कर सकते हैं—रिटेंशन पीरियड, एक्सेस कंट्रोल, एन्क्रिप्शन, और ऑडिट कवरेज—और क्या रोडमैप पर है।
ऐप में एक छोटा “Security & Audit” पेज (/security) अपेक्षाएँ तय करने में मदद करेगा और क्रिटिकल घटनाओं के दौरान अनियोजित सवालों को कम करेगा।
इम्पैक्ट एनालिसिस तभी मायने रखती है जब यह अगले कदम को प्रेरित करे। आपका ऐप इंसीडेंट चैनल के लिए एक “को-पायलट” की तरह व्यवहार करे: यह इनकमिंग सिग्नल्स को संक्षेप में अपडेट में बदलता है और जब इम्पैक्ट महत्वपूर्ण रूप से बदलता है तो लोगों को चपकाता है।
पहले उस जगह से इंटीग्रेट करें जहाँ रेस्पॉन्डर्स पहले से काम करते हैं (अक्सर Slack, Microsoft Teams, या समर्पित इंसिडेंट टूल)। लक्ष्य चैनल को बदलना नहीं है—बल्कि संदर्भ-समझदार अपडेट पोस्ट करना और साझा रिकॉर्ड रखना है।
व्यावहारिक पैटर्न: इंसीडेंट चैनल को इनपुट और आउटपुट दोनों के रूप में ट्रीट करें:
यदि आप तेजी से प्रोटोटाइप कर रहे हैं, तो पहले एंड-टू-एंड वर्कफ़्लो बनाएं (incident view → summarize → notify) फिर स्कोरिंग फाइन-ट्यून करें। प्लेटफ़ॉर्म जैसे Koder.ai यहां उपयोगी हो सकते हैं: आप React डैशबोर्ड और Go/PostgreSQL बैकएंड के साथ चैट-ड्रिवन वर्कफ़्लो पर जल्दी iterate कर सकते हैं और फिर स्रोत कोड एक्सपोर्ट कर सकते हैं जब टीम UX को स्वीकार कर ले।
इम्पैक्ट को केवल स्पष्ट थ्रेशोल्ड्स पार करने पर ही नोटिफाई करें ताकि अलर्ट स्पैम से बचा जा सके। सामान्य ट्रिगर्स:
जब थ्रेशोल्ड पार हो, तो ऐसा संदेश भेजें जो बताये क्यों (क्या बदला), कौन कार्रवाई करे, और क्या करना है।
हर नोटिफिकेशन में "अगला कदम" लिंक शामिल होने चाहिए ताकि रेस्पॉन्डर्स तेजी से आगे बढ़ सकें:
इन लिंक्स को स्थिर और रिलेटिव रखें ताकि ये विभिन्न एन्वायरनमेंट्स में काम करें।
एक ही डेटा से दो सार-फॉर्मेट बनाएं:
अनुसूचित सारांश (उदा., हर 15–30 मिनट) और ऑन-डिमांड “generate update” कार्य का समर्थन करें, बाहरी भेजने से पहले अप्रूवल स्टेप के साथ।
इम्पैक्ट एनालिसिस तभी उपयोगी है जब लोग उस पर घटना के दौरान और बाद में भरोसा करें। वैलिडेशन को दो बातें साबित करनी चाहिए: (1) सिस्टम स्थिर, समझाने योग्य परिणाम देता है, और (2) ये परिणाम बाद में संगठन के निष्कर्षों से मेल खाते हैं।
सबसे पहले उन दो क्षेत्रों के लिए ऑटोमेटेड टेस्ट रखें जिनमें सबसे अधिक त्रुटियाँ होती हैं: स्कोरिंग लॉजिक और डेटा इनगेशन।
टेस्ट फ़िक्स्चर्स पठनीय रखें: जब कोई नियम बदलता है, तो किसी को यह समझ में आना चाहिए कि स्कोर क्यों बदला।
रिप्ले मोड विश्वास बढ़ाने का तेज़ रास्ता है। ऐतिहासिक इंसिडेंट्स को ऐप में चला कर तुलना करें कि सिस्टम "उस समय" क्या दिखाता बनाम बाद में रेस्पॉन्डरों ने क्या निष्कर्ष निकाला।
व्यावहारिक टिप्स:
वास्तविक इन्सिडेंट्स अक्सर साफ़ आउटेज नहीं होते। आपकी वैलिडेशन सूट में इन परिदृश्यों को शामिल करें:
प्रत्येक के लिए, न केवल स्कोर पर असर्ट करें, बल्कि व्याख्या पर भी: किस सिग्नल्स और किस डिपेंडेंसीज़/ग्राहकों ने परिणाम चलाया।
संचालनीय शब्दों में सटीकता परिभाषित करें और उसे ट्रैक करें।
कम्प्यूटेड इम्पैक्ट की तुलना पोस्ट-इन्सिडेंट रिव्यू के परिणामों से करें: प्रभावित सेवाएँ, अवधि, ग्राहक गणना, SLA उल्लंघन, और गंभीरता। विसंगतियों को वैलिडेशन इश्यू के रूप में लॉग करें और उन्हें एक श्रेणी दें (मिसिंग डेटा, गलत डिपेंडेंसी, खराब थ्रेशोल्ड, देरी सिग्नल)।
समय के साथ लक्ष्य पूर्णता नहीं है—लक्ष्य कम आश्चर्यजनक घटनाएँ और घटनाओं के दौरान तेज़ सहमति है।
इन्सिडेंट इम्पैक्ट एनालिसिस का MVP शिप करना ज्यादातर भरोसेमंदता और फ़ीडबैक लूप्स के बारे में है। आपकी पहली डिप्लॉयमेंट पसंद तेजी से बदली जाने वाली होनी चाहिए, न कि भविष्य के सैद्धांतिक स्केल के लिए।
एक मॉड्यूलर मोनोलिथ से शुरुआत करें जब तक कि आपके पास मजबूत प्लेटफ़ॉर्म टीम और स्पष्ट सर्विस बाउंडरीज न हों। एक डिप्लॉयेबल यूनिट माइग्रेशन, डिबगिंग, और एंड-टू-एंड टेस्टिंग को सरल बनाती है।
सर्विसेस तब विभाजित करें जब असली दर्द महसूस हो:
एक व्यावहारिक बीच का रास्ता है एक ऐप + बैकग्राउंड वर्कर्स (queues) + अलग इनगेशन edge अगर ज़रूरत हो।
अगर आप बड़े bespoke प्लेटफ़ॉर्म पर तुरंत निवेश नहीं करना चाहते, तो Koder.ai जैसे टूल MVP तेज़ी से बनवाने में मदद कर सकते हैं: यह चैट-ड्रिवन “vibe-coding” वर्कफ़्लो React UI, Go API, और PostgreSQL डेटा मॉडल बनाने में सहायक है, साथ में स्कोरिंग नियमों और वर्कफ़्लो बदलने पर स्नैपशॉट/रोलबैक की सुविधा।
कोर एंटिटीज़ के लिए relational storage (Postgres/MySQL) उपयोग करें: incidents, services, customers, ownership, और कैल्क्युलेटेड इम्पैक्ट स्नैपशॉट्स। यह क्वेरी करना, ऑडिट करना, और विकसित करना आसान बनाता है।
हाई-वॉल्यूम सिग्नल्स (मेट्रिक्स, लॉग से निकले ईवेंट्स) के लिए, जब कच्चा सिग्नल रिटेंशन और रोलअप्स SQL में महंगा हो जाए तो एक टाइम-सीरीज़ स्टोर (या कॉलम्नर) जोड़ें।
यदि डिपेंडेंसी क्वेरीज़ बॉटलनेक बन जाएँ या आपका डिपेंडेंसी मॉडल बहुत डायनेमिक हो जाए तो ग्राफ डेटाबेस पर विचार करें। कई टीमें adjacency टेबल्स + कैशिंग के साथ काफी दूर जा सकती हैं।
आपका इम्पैक्ट एनालिसिस ऐप भी अपने आप में इंसिडेंट टूलचेन का हिस्सा बन जाता है, इसलिए इसे प्रोडक्शन सॉफ़्टवेयर की तरह इंस्ट्रूमेंट करें:
UI में एक “health + freshness” व्यू एक्स्पोज़ करें ताकि रेस्पॉन्डर्स संख्याओं पर भरोसा कर (या सवाल उठा) सकें।
MVP स्कोप को कड़ा रखें: छोटे टूल सेट जो इनजेस्ट करे, एक स्पष्ट इम्पैक्ट स्कोर, और डैशबोर्ड जो “कौन प्रभावित और कितना” का उत्तर दे। फिर इटेरेट करें:
मॉडल को एक प्रोडक्ट की तरह ट्रीट करें: इसे वर्ज़न करें, सेफ़ली माईग्रेट करें, और पोस्ट-इंसिडेंट रिव्यू के लिए परिवर्तनों का दस्तावेज़ तैयार रखें।
प्रभाव वह है जो किसी घटना का व्यवसाय-निजी परिणामों पर मापनीय परिणाम होता है।
एक व्यावहारिक परिभाषा में 2–4 प्राथमिक आयाम स्पष्ट रूप से नामित होते हैं (उदा., प्रभावित भुगतान करने वाले ग्राहकों की संख्या + SLA जोखिम में मिनट) और यह स्पष्ट रूप से "ग्राफ़्स पर खराब दिखने वाली हर चीज" को बाहर रखती है। इससे आउटपुट निर्णयों से जुड़ा रहता है, सिर्फ़ टेलीमेट्री से नहीं।
वे आयाम चुनें जो पहले 10 मिनट में आपकी टीमों के निर्णयों से सीधे जुड़ें।
साझा, MVP-अनुकूल आयाम:
इसे 2–4 तक सीमित रखें ताकि स्कोर व्याख्यायोग्य रहे।
आउटपुट इस तरह डिज़ाइन करें कि हर भूमिका अपना मुख्य प्रश्न बिना मेट्रिक अनुवाद किए जवाब दे सके:
अगर कोई मेट्रिक इन में से किसी का उपयोग नहीं कर पा रही, तो वह संभवतः "प्रभाव" नहीं है।
“रियल-टाइम” महँगा होता है; कई टीमों के लिए नियर-रियल-टाइम (1–5 मिनट) पर्याप्त होता है।
एक लेटेंसी लक्ष्य एक आवश्यकता के रूप में लिखें क्योंकि इससे प्रभावित होते हैं:
UI में भी उम्मीदें दिखाएँ (उदा., “डेटा 2 मिनट पहले तक ताज़ा है”)।
पहले उन निर्णयों की सूची बनाकर शुरू करें जो रेस्पॉन्डर को लेना होते हैं, फिर सुनिश्चित करें कि हर आउटपुट किसी एक निर्णय का समर्थन करता है:
यदि कोई मेट्रिक निर्णय नहीं बदलता, तो उसे टेलीमेट्री के रूप में रखें, न कि प्रभाव के रूप में।
सामान्यत: आवश्यक इनपुट:
डेटा गायब या गलत होने पर स्पष्ट, क्वेरीयेबल मैनुअल फ़ील्ड्स की अनुमति दें ताकि ऐप उपयोगी रहे:
बदलावों के लिए कौन/कब/क्यों आवश्यक रखें ताकि समय के साथ भरोसा कम न हो।
विश्वसनीय MVP आउटपुट:
वैकल्पिक: लागत का अनुमान (SLA क्रेडिट, सपोर्ट लोड, राजस्व जोखिम) और कॉन्फिडेंस रेंज।
सभी स्रोतों को एक सामान्य ईवेंट स्कीमा में सामान्यीकृत करें ताकि गणनाएँ सुसंगत रहें।
कम से कम स्टैंडर्डाइज़ करें:
occurred_at, detected_at, सरल और समझाने योग्य से शुरू करें:
मध्यवर्ती मान (थ्रेशोल्ड हिट, वेट्स, टीयर, कॉन्फिडेंस) सहेजें ताकि उपयोगकर्ता देख सकें क्यों स्कोर बदला। इम्पैक्ट को एक संख्या में समेटने से पहले आवश्यक आयाम (availability/latency/errors/data correctness/security) ट्रैक करें।
यह सेट "क्या टूटा", "कौन प्रभावित है", और "कितनी देर" निकालने के लिए पर्याप्त होना चाहिए।
resolved_atservice_id (टूल टैग/नाम से मैप किया हुआ)source + मूल रॉ पेलोड (ऑडिट/डिबग के लिए)बेव्यवस्था को idempotency keys (source + external_id) और occurred_at के आधार पर आउट-ऑफ-ऑर्डर सहनशीलता से हैंडल करें।