06 नव॰ 2025·8 मिनट
इंसिडेंट ट्रैकिंग और पोस्टमॉर्टेम के लिए वेब ऐप कैसे बनाएं?
वर्कफ़्लो, डेटा मॉडल और UX से लेकर लॉन्च तक — घटना ट्रैकिंग और पोस्टमॉर्टेम के लिए वेब ऐप डिजाइन, बिल्ड और लॉन्च करने का प्रयोगात्मक ब्लूप्रिंट।
वर्कफ़्लो, डेटा मॉडल और UX से लेकर लॉन्च तक — घटना ट्रैकिंग और पोस्टमॉर्टेम के लिए वेब ऐप डिजाइन, बिल्ड और लॉन्च करने का प्रयोगात्मक ब्लूप्रिंट।
स्क्रीन बनाना या डेटाबेस चुनने से पहले यह स्पष्ट कर लें कि आपकी टीम "घटना ट्रैकिंग वेब ऐप" से क्या उम्मीद रखती है — और "पोस्टमॉर्टेम प्रबंधन" का उद्देश्य क्या है। अक्सर टीमें एक ही शब्दों का अलग-अलग मतलब निकालती हैं: एक समूह के लिए घटना कोई भी ग्राहक-रिपोर्टेड समस्या हो सकती है; दूसरे के लिए सिर्फ़ Sev-1 आउटेज होता है जिसमें ऑन-कॉल एस्केलेशन चाहिए।
छोटी सी परिभाषा लिखें जो इन सवालों का जवाब दे:
यह परिभाषा आपके इंसिडेंट रिस्पॉन्स वर्कफ़्लो को दिशा देगी और यह रोकेगी कि ऐप या तो बहुत सख्त बने (कोई उपयोग नहीं करता) या बहुत ढीला (डेटा असंगत)।
निर्धारित्त करें कि आपकी संस्था में पोस्टमॉर्टेम क्या है: हर घटना के लिए एक हल्का सारांश, या केवल उच्च-गंभीरता घटनाओं के लिए पूर्ण RCA। स्पष्ट करें कि लक्ष्य सीखना है, अनुपालन है, रिपीट घटनाओं को घटाना है, या इन सबका संयोजन।
एक उपयोगी नियम: अगर आप उम्मीद करते हैं कि पोस्टमॉर्टेम से बदलाव होगा, तो आपका टूल एक्शन आइटम ट्रैकिंग सपोर्ट करे—केवल दस्तावेज़ स्टोरेज नहीं।
अधिकांश टीमें इस तरह के ऐप को कुछ आवर्ती समस्याएँ हल करने के लिए बनाती हैं:
इस सूची को संकुचित रखें। आप जो भी फीचर जोड़ते हैं, उसे कम से कम एक समस्या से जुड़ा होना चाहिए।
ऐसे कुछ मापदंड चुनें जिन्हें आप अपने ऐप के डेटा मॉडल से स्वचालित रूप से नाप सकते हैं:
ये आपकी ऑपरेशनल मेट्रिक्स और पहले रिलीज़ के लिए "डिफ़िनिशन ऑफ़ ड्रन" बनेंगे।
एक ही ऐप ऑन-कॉल संचालन में अलग-अलग भूमिकाएँ सर्व करता है:
यदि आप सभी के लिए एक साथ डिज़ाइन करेंगे, तो UI भरा-भरा बनेगा। इसके बजाय, v1 के लिए एक प्राथमिक उपयोगकर्ता चुनें—और बाद में tailored views, डैशबोर्ड और permissions के जरिए दूसरों की ज़रूरतें पूरी होने दें।
एक स्पष्ट वर्कफ़्लो दो सामान्य विफलता तरीकों को रोकता है: ऐसी घटनाएँ जो अटक जाती हैं क्योंकि किसी को नहीं पता "आगे क्या करना है," और ऐसी घटनाएँ जो "हो गई" दिखती हैं पर सीख नहीं देतीं। पहले अपने लाइफसाइकल को end-to-end मैप करें और फिर हर स्टेप पर भूमिकाएँ और परमिशन्स लगाएँ।
अधिकतर टीमें एक साधारण चक्र फॉलो करती हैं: detect → triage → mitigate → resolve → learn. आपका ऐप इस बात का प्रतिबिंब दे कि कदम सीमित और अनुमाननीय हों, न कि विकल्पों का अंतहीन मेन्यू।
हर स्टेज के लिए "done" का अर्थ परिभाषित करें। उदाहरण के लिए, mitigation का मतलब हो सकता है कि ग्राहक-स्तरीय प्रभाव रोका गया है, भले ही रूट कॉज़ अभी अज्ञात हो।
भूमिकाएँ स्पष्ट रखें ताकि लोग बिना मीटिंग के इंतज़ार किए कार्रवाई कर सकें:
आपका UI "करंट ओनर" को स्पष्ट रूप से दिखाए, और वर्कफ़्लो delegation (reassign, responders जोड़ना, commander रोटेट करना) को सपोर्ट करे।
आवश्यक स्टेट्स और अनुमत ट्रांज़िशन्स चुनें, जैसे Investigating → Mitigated → Resolved. गार्डरेल्स जोड़ें:
आंतरिक अपडेट्स (तेज़, टैक्टिकल, गंदे हो सकते हैं) और स्टेकहोल्डर-फेसिंग अपडेट्स (स्पष्ट, टाइम-स्टैम्प्ड, क्यूरेटेड) को अलग रखें। अलग टेम्पलेट्स, विजिबिलिटी और अनुमोदन नियमों के साथ दो अपडेट स्ट्रीम बनाएं—अक्सर कमांडर स्टेकहोल्डर अपडेट का एकमात्र पब्लिशर होता है।
एक अच्छा इंसिडेंट टूल UI में "सिंपल" लगता है क्योंकि अंडरलीइंग डेटा मॉडल सुसंगत होता है। स्क्रीन बनाने से पहले तय करें कि कौन-से ऑब्जेक्ट्स मौजूद होंगे, वे कैसे जुड़े होंगे, और क्या ऐतिहासिक रूप से सही रहना चाहिए।
छोटी पहली-श्रेणी चीज़ों से शुरू करें:
अधिकतर रिलेशनशिप एक-से-कई होते हैं:
Incidents और ईवेंट्स के लिए स्थिर आइडेंटिफ़ायर्स (UUIDs) का उपयोग करें। मनुष्यों के लिए एक फ्रेंडली की भी दें जैसे INC-2025-0042, जिसे आप एक अनुक्रम से जेनरेट कर सकते हैं।
इन्हें पहले मॉडल करें ताकि आप फ़िल्टर, सर्च और रिपोर्ट कर सकें:
इंसिडेंट डेटा संवेदनशील होता है और अक्सर बाद में देखा जाता है। एडिट्स को डेटा की तरह संभालें—ओवरराइट नहीं:
यह स्ट्रक्चर बाद की सुविधाओं — सर्च, मेट्रिक्स और परमिशन्स — को बिना रीवर्क के लागू करना आसान बनाता है।
जब कुछ टूटता है, तो ऐप का काम टाइपिंग घटाना और स्पष्टता बढ़ाना है। यह सेक्शन "राइट पाथ" को कवर करता है: लोग कैसे घटना बनाते हैं, उसे अपडेट रखते हैं, और बाद में क्या हुआ यह पुनर्निर्मित करते हैं।
इनटेक फ़ॉर्म इतना छोटा रखें कि आप ट्रबलशूटिंग के दौरान भर सकें। एक अच्छा डिफ़ॉल्ट अनिवार्य फ़ील्ड सेट:
अन्य सब चीज़ें क्रिएशन के समय वैकल्पिक रखें (इंपैक्ट, ग्राहक टिकट लिंक, संदेहित कारण)। स्मार्ट डिफ़ॉल्ट्स का प्रयोग करें: start time को "now" सेट करें, यूज़र की on-call टीम पहले से चुनें, और एक-टैप "Create & open incident room" कार्रवाई दें।
आपका अपडेट UI बार-बार छोटे edits के लिए ऑप्टिमाइज़्ड होना चाहिए। एक कॉम्पैक्ट अपडेट पैनल दें जिसमें:
अपडेट्स append-friendly हों: हर अपडेट एक टाइमस्टैम्प्ड एंट्री बने, पिछले टेक्स्ट का ओवरराइट न हो।
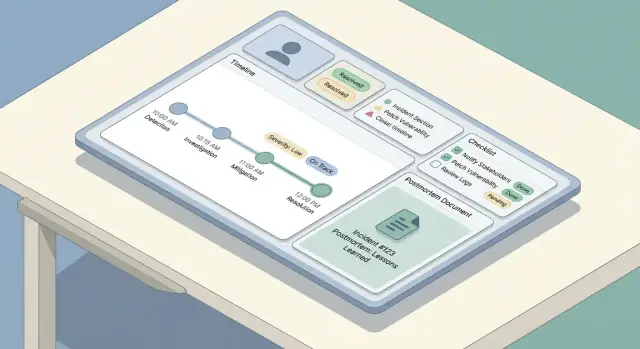
एक ऐसी टाइमलाइन बनाएं जो मिलाकर दिखाए:
यह एक भरोसेमंद नैरेटिव बनाता है बिना लोगों को हर क्लिक लॉग करने के लिए मजबूर किए।
आउटेज के दौरान कई अपडेट फोन से होते हैं। तेज़, कम-फ्रिक्शन स्क्रीन को प्राथमिकता दें: बड़े टच टार्गेट्स, एकल स्क्रॉलिंग पेज, ऑफ़लाइन-फ्रेंडली ड्राफ्ट्स, और एक-टैप क्रियाएँ जैसे "Post update" और "Copy incident link"।
Severity इंसिडेंट रिस्पॉन्स का "स्पीड डायल" है: यह बताता है कि कितनी जल्दी कार्रवाई करनी है, कितनी चौड़ी कम्युनिकेशन करनी है, और कौन-कौन से trade-offs स्वीकार्य हैं।
अस्पष्ट लेबल जैसे "high/medium/low" से बचें। हर severity लेवल को स्पष्ट ऑपरेशनल अपेक्षाओं से जोड़ें—खासकर रिस्पॉन्स समय और कम्युनिकेशन cadence।
उदाहरण:
Severity चुनने वाले UI में ये नियम दिखाई दें ताकि responders को आउटेज के दौरान बाहरी डॉक्यूमेंट्स खोजने की ज़रूरत न पड़े।
चेकलिस्ट तनाव के समय कॉग्निटिव लोड घटाते हैं। इन्हें छोटा, कारगर और भूमिकाओं से जुड़ा रखें।
एक उपयोगी पैटर्न कुछ सेक्शन में हो सकता है:
चेकलिस्ट आइटम्स टाइमस्टैम्प्ड और attributable हों, ताकि वे घटना रिकॉर्ड का हिस्सा बनें।
घटनाएँ शायद एक ही टूल में न रहें। आपका ऐप responders को लिंक संलग्न करने दे:
"Typed" लिंक पसंद करें (उदा., Runbook, Ticket) ताकि बाद में फ़िल्टर किया जा सके।
यदि आपकी संस्था विश्वसनीयता लक्ष्यों को ट्रैक करती है, तो हल्के फ़ील्ड जोड़ें जैसे SLO प्रभावित (हाँ/नहीं), अनुमानित error budget burn, और ग्राहक SLA जोखिम। इन्हें वैकल्पिक रखें—पर घटना के दौरान या ठीक बाद जल्दी भरने योग्य बनाएं।
एक अच्छा पोस्टमॉर्टेम शुरू करने में आसान, भूलने में कठिन और टीमों के बीच सुसंगत होता है। सबसे आसान तरीका एक डिफ़ॉल्ट टेम्पलेट देना है (कम से कम आवश्यक फ़ील्ड्स के साथ) और उसे घटना रिकॉर्ड से ऑटो-फिल करना, ताकि लोग सोचने में समय बिताएँ—न कि फिर से टाइप करने में।
बिल्ट-इन टेम्पलेट संरचना और लचीलापन दोनों का संतुलन रखे:
यदि आप तेज़ पब्लिशिंग चाहते हैं तो "Root cause" को शुरुआत में वैकल्पिक रखें, पर अंतिम अनुमोदन से पहले इसे आवश्यक बनाएं।
पोस्टमॉर्टेम एक अलग फ़्लोटिंग दस्तावेज़ न हो। जब पोस्टमॉर्टेम बनाया जाए, तो स्वतः संलग्न करें:
इनका उपयोग पोस्टमॉर्टेम सेक्शन्स को प्री-फिल करने में करें। उदाहरण के लिए, "Impact" ब्लॉक घटना के start/end टाइम्स और वर्तमान severity से शुरू हो सकता है, जबकि "What we did" को टाइमलाइन एंट्रीज़ से खींचा जा सकता है।
एक हल्का वर्कफ़्लो जोड़ें ताकि पोस्टमॉर्टेम अटकें नहीं:
हर स्टेप पर निर्णय नोट्स कैप्चर करें: क्या बदला, क्यों बदला, और किसने अनुमोदित किया। यह "साइलेंट एडिट्स" से बचाता है और भविष्य के ऑडिट या सीखने की समीक्षा को आसान बनाता है।
यदि आप UI सरल रखना चाहते हैं, तो रिव्यूज़ को कमेंट्स की तरह रखें जिनके स्पष्ट परिणाम हों (Approve / Request changes) और अंतिम अनुमोदन को अपरिवर्तनीय रिकॉर्ड के रूप में स्टोर करें।
जिन टीमों को इसकी ज़रूरत है, उनके लिए "Published" को आपके स्टेटस अपडेट्स वर्कफ़्लो से लिंक करें (देखें /blog/integrations-status-updates) बिना कंटेंट को हाथ से कॉपी किए।
पोस्टमॉर्टेम तभी भविष्य की घटनाओं को घटाते हैं जब फॉलो-अप वर्क वास्तव में हो। एक्शन आइटम्स को आपके ऐप में फर्स्ट-क्लास ऑब्जेक्ट समझें—किसी दस्तावेज़ के अंत में पैराग्राफ़ नहीं।
हर एक्शन आइटम में सुसंगत फ़ील्ड होने चाहिए ताकि उसे ट्रैक और माप सकें:
छोटा पर उपयोगी मेटाडेटा जोड़ें: tags (उदा., “monitoring”, “docs”), component/service, और "created from" (incident ID और postmortem ID)।
एक्शन आइटम्स को एक ही पोस्टमॉर्टेम पेज में न फँसने दें। प्रदान करें:
यह फॉलो-अप्स को बिखरे नोट्स की बजाय एक ऑपरेशनल 큐 में बदल देता है।
कुछ कार्य दोहराए जाते हैं (त्रैमासिक गेम डे, रनबुक समीक्षा)। एक recurring template सपोर्ट करें जो अनुसूची पर नए आइटम जेनरेट करे, जबकि हर occurrence स्वतंत्र रूप से ट्रैक करने योग्य रहे।
यदि टीम पहले से किसी अन्य ट्रैकर का उपयोग करती है, तो एक्शन आइटम में external reference link और external ID शामिल करने दें, जबकि आपका ऐप incident linkage और verification के लिए स्रोत बने रहे।
हल्के nudges बनाएं: मालिकों को due date के करीब नोटिफ़ाई करें, ओवरड्यू आइटम्स को टीम लीड को फ़्लैग करें, और रिपोर्ट्स में लगातार ओवरड्यू पैटर्न सर्फेस करें। नियम कॉन्फ़िगरेबल रखें ताकि टीमें अपने ऑन-कॉल संचालन और वर्कलोड से मिल सकें।
घटनाएँ और पोस्टमॉर्टेम अक्सर संवेदनशील विवरण रखते हैं—ग्राहक पहचान, आंतरिक IPs, सुरक्षा निष्कर्ष, या विक्रेता समस्याएँ। स्पष्ट एक्सेस नियम सहयोग के लिए टूल को उपयोगी रखते हैं बिना इसे डेटा लीक का स्रोत बनाए।
छोटे, समझने योग्य रोल्स से शुरू करें:
यदि कई टीमें हैं, तो सेवाओं/टीम द्वारा रोल्स को scope करने पर विचार करें (उदा., “Payments Editors”) बजाय व्यापक ग्लोबल एक्सेस देने के।
कंटेंट को पहले वर्गीकृत करें, ताकि लोग आदत बनाकर संवेदनशील जानकारी गलती से साझा न करें:
एक व्यावहारिक पैटर्न सेक्शन्स को Internal या Shareable के रूप में मार्क करना है और एक्सपोर्ट्स तथा स्टेटस पेज में enforcement करना है। सुरक्षा घटनाओं के लिए अलग incident type और कड़े defaults बनाना चाहिए।
हर परिवर्तन के लिए रिकॉर्ड रखें: किसने बदला, क्या बदला, और कब। severity, टाइमस्टैम्प्स, इम्पैक्ट और अंतिम अनुमोदनों जैसी चीज़ों के एडिट्स शामिल करें। ऑडिट लॉग्स सर्चेबल और नॉन-एडिटेबल होने चाहिए।
आउट-ऑफ-द-बॉक्स मजबूत auth सपोर्ट करें: ईमेल + MFA या मैजिक लिंक, और यदि उपयोगकर्ता अपेक्षा रखते हैं तो SSO (SAML/OIDC) जोड़ें। शॉर्ट-लाइव्ड सेशन्स, सिक्योर कूकीज़, CSRF सुरक्षा, और रोल चेंज पर ऑटोमैटिक सेशन रिवोकेशन लागू करें। रोलआउट विचारों के लिए देखें /blog/testing-rollout-continuous-improvement।
जब कोई घटना सक्रिय हो, लोग स्कैन करते हैं— पढ़ते नहीं। आपका UX कुछ सेकंड में वर्तमान स्थिति स्पष्ट कर दे, और फिर responders को विवरणों में खोए बिना ड्रिल-डाउन करने दे।
तीन स्क्रीन से शुरू करें जो ज़्यादातर वर्कफ़्लोज़ कवर करती हैं:
एक सरल नियम: incident detail पेज के टॉप पर "अभी क्या हो रहा है?" का जवाब होना चाहिए, और नीचे "यहाँ तक कैसे पहुंचे?"।
इंसिडेंट्स तेज़ी से बढ़ते हैं, इसलिए खोज तेज और सहनशील बनाएं:
सहेजे हुए व्यूज़ जैसे My open incidents या Sev-1 this week दें ताकि ऑन-कॉल इंजीनियर हर शिफ्ट में फ़िल्टर ना बनाएँ।
ऐप में लगातार, कलर-सेफ़ बैज्स का प्रयोग करें (तनाव में असफल होने वाली सूक्ष्म छायाओं से बचें)। वही स्टेटस शब्दावली हर जगह रखें: लिस्ट, डिटेल हेडर, और टाइमलाइन इवेंट्स में।
एक नज़र में responders को दिखना चाहिए:
स्कैनबिलिटी को प्राथमिकता दें:
डिज़ाइन सबसे खराब पल के लिए करें: यदि कोई नींद-हीन है और फोन से पेज कर रहा है, तो UI अभी भी उसे तेज़ी से सही कार्रवाई तक गाइड करे।
इंटीग्रेशन्स वही चीज़ें हैं जो एक इंसिडेंट ट्रैकर को "नोट्स रखने की जगह" से उस सिस्टम में बदल देती हैं जिसमें आपकी टीम वास्तव में घटनाएँ चलाती है। पहले सूची बनाएं कि किन सिस्टम्स से कनेक्ट करना अनिवार्य है: मॉनिटरिंग/ऑब्ज़रवेबिलिटी (PagerDuty/Opsgenie, Datadog, CloudWatch), चैट (Slack/Teams), ईमेल, टिकटिंग (Jira/ServiceNow), और स्टेटस पेज।
अधिकांश टीमें मिश्रण के साथ काम करती हैं:
अलर्ट्स शोर वाले, retry किए हुए और अक्सर आउट-ऑर्डर होते हैं। हर प्रोवाइडर ईवेंट के लिए स्थिर idempotency key परिभाषित करें (उदाहरण: provider + alert_id + occurrence_id) और इसे यूनिक constraint के साथ स्टोर करें। डेडप्लिकेशन के लिए नियम तय करें जैसे "same service + same signature within 15 minutes" मौजूदा घटना में append करे बजाय नया बनाने के।
स्पष्ट करें कि आपका ऐप क्या मालिक है और क्या सोर्स टूल में रहता है:
जब इंटीग्रेशन फेल करे, तो gracefully degrade करें: retries queue करें, घटना पर चेतावनी दिखाएँ ("Slack posting delayed"), और ऑपरेटरों को मैन्युअल जारी रखने की अनुमति दें।
स्टेटस अपडेट्स को फर्स्ट-क्लास आउटपुट मानें: UI में एक संरचित "Update" कार्रवाई चैट में पब्लिश कर सके, घटना टाइमलाइन में जोड़ सके, और वैकल्पिक रूप से स्टेटस पेज के साथ सिंक कर सके—बिना responder से वही संदेश तीन बार लिखवाए।
आपका इंसिडेंट टूल "आउटेज के दौरान" चलने वाला सिस्टम है, इसलिए सरलता और विश्वसनीयता को ताजगी पर प्राथमिकता दें। सबसे अच्छा स्टैक अक्सर वही है जिसे आपकी टीम बिल्ड, डिबग और 2am पर operate कर सके।
जो चीज़ें आपकी इंजीनियर्स पहले से प्रोडक्शन में भेजते हैं, वही शुरूआत के लिए बेहतर होती हैं। एक मेनस्ट्रीम वेब फ्रेमवर्क (Rails, Django, Laravel, Spring, Express/Nest, ASP.NET) आम तौर पर बेहतर है बजाए किसी नए फ्रेमवर्क के जिसे सिर्फ़ एक व्यक्ति समझता हो।
डेटा स्टोरेज के लिए रिलेशनल DB (PostgreSQL/MySQL) incidents के लिए उपयुक्त है: incidents, updates, participants, action items, और postmortems सभी ट्रांज़ैक्शन्स और स्पष्ट रिलेशनशिप से लाभान्वित होते हैं। Redis तब जोड़ें जब सच में caching, queues, या ephemeral locks की ज़रूरत हो।
होस्टिंग मैनेज्ड प्लेटफ़ॉर्म (Render/Fly/Heroku-जैसे) या आपके मौजूदा क्लाउड (AWS/GCP/Azure) से हो सकती है। managed databases और managed backups को प्राथमिकता दें।
सक्रिय घटनाओं में रियल-टाइम अपडेट बेहतर होते हैं, पर शुरुआत में हमेशा websockets जरूरी नहीं:
एक व्यवहारिक तरीका: API/इवेंट्स को ऐसा डिज़ाइन करें कि आप polling से शुरू कर सकें और बाद में websockets पर अपग्रेड कर सकें बिना UI को री-राइट किए।
यदि यह ऐप किसी घटना के दौरान फेल हो जाए, तो यह खुद घटना का हिस्सा बन जाएगा। शामिल करें:
इसे एक प्रोडक्शन सिस्टम की तरह ट्रीट करें:
यदि आप वर्कफ़्लो और स्क्रीन वैलिडेट करना चाहते हैं बिना पूरा बिल्ड किए, तो एक प्रोटोटाइप अच्छा विकल्प है: Koder.ai जैसे टूल का उपयोग करके विस्तृत चैट स्पेसिफिकेशन से एक काम करने वाला प्रोटोटाइप जेनरेट करें, फिर tabletop exercises के दौरान responders के साथ iterate करें। क्योंकि Koder.ai वास्तविक React फ्रंटेंड के साथ Go + PostgreSQL बैकएंड जेनरेट कर सकता है (और सोर्स कोड एक्सपोर्ट सपोर्ट करता है), आप शुरुआती वर्ज़न को "थ्रोअवे प्रोटोटाइप" या हार्डन करने के लिए स्टार्टिंग पॉइंट दोनों के रूप में इस्तेमाल कर सकते हैं—बिना उन सीखों को खोए जो असली परीक्षणों से मिली हों।
एक इंसिडेंट ट्रैकिंग ऐप बिना अभ्यास के शिप करना एक जुआ है। सबसे अच्छी टीमें इसे किसी अन्य ऑपरेशनल सिस्टम की तरह behandelen: critical paths टेस्ट करें, वास्तविक drills चलाएँ, धीरे-धीरे रोलआउट करें, और वास्तविक उपयोग के आधार पर ट्यून करते रहें।
पहले उन फ्लोज़ पर फोकस करें जिन पर लोग हाई-स्ट्रेस में निर्भर रहेंगे:
रेग्रेशन टेस्ट जोड़ें जो ये साबित करें कि क्या नहीं टूटना चाहिए: टाइमस्टैम्प्स, टाइमज़ोन्स, और इवेंट ऑर्डरिंग। घटनाएँ नैरेटिव होती हैं—यदि टाइमलाइन गलत है, तो भरोसा चला जाएगा।
परमिशन बग्स ऑपरेशनल और सिक्यूरिटी जोखिम हैं। ऐसे टेस्ट लिखें जो साबित करें:
"नियर मिसेज" भी टेस्ट करें, जैसे किसी उपयोगकर्ता का घटना के बीच में एक्सेस खो देना या टीम रिऑर्ग के कारण समूह सदस्यता बदलना।
ब्रोड रोलआउट से पहले आपका ऐप स्रोत-ऑफ-ट्रुथ के रूप में प्रयोग करते हुए tabletop simulations चलाएँ। अपनी संस्था के लिए परिचित परिदृश्य चुनें (उदा., पार्टिअल आउटेज, डेटा डिले, थर्ड-पार्टी फेलियर)। घर्षण देखें: भ्रमित फ़ील्ड्स, गायब संदर्भ, बहुत अधिक क्लिक, अस्पष्ट ओनरशिप।
तुरंत फ़ीडबैक कैप्चर करें और उसे छोटे, तेज़ सुधारों में बदलें।
एक पायलट टीम और कुछ प्री-बिल्ट टेम्पलेट्स (इंसिडेंट टाइप, चेकलिस्ट, पोस्टमॉर्टेम फॉर्मैट) के साथ शुरू करें। छोटा ट्रेनिंग और एक पेज "कैसे हम घटनाएँ चलाते हैं" गाइड दें जो ऐप से लिंक हो (उदा., /docs/incident-process)।
अपनाने के मेट्रिक्स ट्रैक करें और friction पॉइंट्स पर iterate करें: time-to-create, % incidents with updates, postmortem completion rate, और action-item closure time। इन्हें प्रोडक्ट मेट्रिक्स की तरह ट्रीट करें—न कि सिर्फ़ अनुपालन—और हर रिलीज़ में सुधार करते रहें।
शुरुआत एक स्पष्ट, संगठित परिभाषा से करें:
यह परिभाषा सीधे आपके वर्कफ़्लो स्टेट्स और आवश्यक फ़ील्ड्स से जुड़नी चाहिए, ताकि डेटा भारित न हो और संसाधन बिना बोझ के लगातार रखें।
पोस्टमॉर्टेम को सिर्फ़ दस्तावेज़ न मानकर एक वर्कफ़्लो समझें:
यदि आप सच में बदलाव चाहते हैं तो आपको सिर्फ़ स्टोरेज नहीं, बल्कि रिमाइंडर और एक्शन-आइटम ट्रैकिंग चाहिए।
एक व्यावहारिक v1 सेट:
उन्नत ऑटोमेशन को तब तक टालें जब तक ये फ्लोज़ दबाव में सुचारू रूप से न चलें।
टीम के वास्तविक काम के अनुरूप एक सीमित, अनुमाननीय स्टेज रखें:
हर स्टेज के लिए “किसे पूरा माना जाएगा” स्पष्ट करें और गार्डरेल जोड़ें:
यह व्यवहार में अटके हुए घटनाओं और बाद की गुणवत्ता समस्याओं को रोकता है।
कुछ स्पष्ट रोल मॉडल करें और उन्हें परमीशन्स से बाँधें:
UI में current owner/commander साफ़ दिखे और delegation (reassign, rotate commander) संभव हो।
छोटा पर संरचित डेटा मॉडल रखें:
स्टीबल आइडेंटिफ़ायर्स (UUID) का उपयोग करें और मानव-पठनीय की (उदा. INC-2025-0042) भी दें। सभी एडिट्स को history की तरह रखें (created_at/created_by) और परिवर्तन के लिए audit log रखें।
दो स्ट्रीम अलग रखें और नियम लागू करें:
दोनों को घटना रिकॉर्ड में स्टोर करें ताकि निर्णय बाद में पुनर्निर्मित किए जा सकें बिना संवेदनशील जानकारी लीक किए।
गंभीरता स्तरों को स्पष्ट अपेक्षाओं (रिस्पॉन्स urgency और कम्युनिकेशन cadence) के साथ परिभाषित करें। उदाहरण:
Severity चुनते समय UI में नियम दिखाएँ ताकि responders को बाहर के डॉक्स की ज़रूरत न पड़े।
एक्शन आइटम्स को संरचित रिकॉर्ड बनाकर उपचार सुनिश्चित करें:
फिर global views (overdue, due soon, by owner/service) और हल्के रिमाइंडर/एस्केलेशन दें ताकि फॉलो-अप मीटिंग के बाद गायब न हो।
प्रोवाइडर-विशिष्ट idempotency keys और डेडुप नियमों का प्रयोग करें:
provider + alert_id + occurrence_id जैसा यूनिक की स्टोर करेंजब APIs फेल हों तो मैनुअल लिंकिंग हमेशा fallback के रूप में रखें।