07 अग॰ 2025·8 मिनट
GPT-1 से GPT-4 तक: OpenAI के GPT मॉडल का इतिहास
OpenAI के GPT मॉडलों का इतिहास जानें—GPT-1 से लेकर GPT-4o तक—और देखिए कैसे हर पीढ़ी ने भाषा की समझ, उपयोगिता और सुरक्षा में प्रगति की।
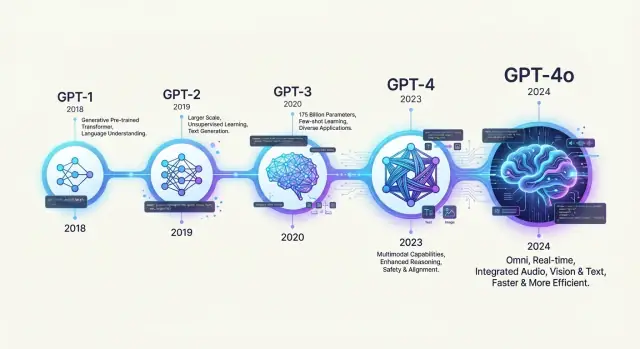
OpenAI के GPT मॉडलों का इतिहास जानें—GPT-1 से लेकर GPT-4o तक—और देखिए कैसे हर पीढ़ी ने भाषा की समझ, उपयोगिता और सुरक्षा में प्रगति की।
GPT मॉडल शब्द अनुक्रम में अगला शब्द अनुमान लगाने के लिए बनाए गए बड़े भाषा मॉडल का परिवार हैं। ये विशाल टेक्स्ट पढ़ते हैं, भाषा के उपयोग के पैटर्न सीखते हैं, और फिर उन पैटर्न का उपयोग नया टेक्स्ट जनरेट करने, प्रश्नों का उत्तर देने, कोड लिखने, दस्तावेज़ों का सार देने और बहुत कुछ करने के लिए करते हैं।
यह संक्षेप में बताता है कि मॉडल क्या करते हैं:
इन मॉडलों के विकास को समझना यह स्पष्ट करता है कि वे क्या कर सकते हैं और क्या नहीं, और क्यों हर पीढ़ी में क्षमताओं में इतना बड़ा छलांग लगती है। हर संस्करण तकनीकी चुनावों और ट्रेड‑ऑफ का प्रतिबिंब है—मॉडल आकार, प्रशिक्षण डेटा, उद्देश्य और सुरक्षा के संदर्भ में।
यह लेख एक कालानुक्रमिक, उच्च‑स्तरीय अवलोकन देता है: प्रारंभिक भाषा मॉडलों और GPT-1 से लेकर GPT-2, GPT-3, इंस्ट्रक्शन ट्यूनिंग और ChatGPT, और अंततः GPT-3.5, GPT-4 और GPT-4o परिवार तक। साथ ही हम मुख्य तकनीकी प्रवृत्तियों, उपयोग पैटर्न में बदलाव और ये बदलाव भविष्य के बारे में क्या संकेत देते हैं, देखेंगे।
GPT से पहले भी भाषा मॉडल NLP शोध का एक केंद्रबिंदु थे। शुरुआती सिस्टम n‑gram मॉडल थे, जो पिछले कुछ शब्दों की फिक्स्ड विंडो से अगला शब्द गिनती पर आधारित अनुमान लगाते थे। वे स्पेलिंग करेक्शन और बुनियादी ऑटोकम्पलीट चला पाते थे पर लंबी सीमा के संदर्भ और डेटा विरलता से संघर्ष करते थे।
अगला बड़ा कदम था न्यूरल भाषा मॉडल। फ़ीड‑फ़ॉरवर्ड नेटवर्क और बाद में RNNs, खासकर LSTMs और GRUs, वितरित शब्द प्रतिनिधित्व सीखने लगे और सिद्धांततः लंबे अनुक्रम संभाल सकते थे। उसी दौरान word2vec और GloVe जैसे मॉडल ने वर्ड एम्बेडिंग्स लोकप्रिय कीं, जो दिखाते थे कि रॉ टेक्स्ट से अनसुपरवाइज़्ड लर्निंग समृद्ध अर्थ संरचना पकड़ सकती है।
फिर भी, RNNs ट्रेन करने में धीरे और पैरेललाइज़ करने में कठिन थे, और बहुत लंबे संदर्भों में संघर्ष कर रहे थे। 2017 के पेपर 'Attention Is All You Need' ने ट्रांसफॉर्मर आर्किटेक्चर पेश करके यह समस्या हल की। ट्रांसफॉर्मर्स ने रीकरेन्स को बदलकर सेल्फ‑अटेन्शन का उपयोग किया, जिससे अनुक्रम में किसी भी दो स्थितियों को सीधे जोड़ा जा सकता है और प्रशिक्षण अत्यधिक पैरेलल हो गया।
इसने भाषा मॉडलों को RNNs से कहीं आगे स्केल करने का मार्ग खोला। शोधकर्ताओं ने देखा कि एक बड़ा ट्रांसफॉर्मर, जो इंटरनेट‑स्केल कॉर्पा पर अगला टोकन भविष्यवाणी के लिए प्रशिक्षित हो, बिना टास्क‑विशिष्ट सुपरविजन के भी सिंटैक्स, सैमान्टिक्स और कुछ हद तक तर्क कौशल सीख सकता है।
OpenAI का मुख्य विचार इसे 'जनरेटिव प्री‑ट्रेनिंग' के रूप में औपचारिक करना था: पहले एक बड़ा decoder‑only transformer व्यापक डेटा पर ट्रेन करें ताकि वह टेक्स्ट मॉडल कर सके, फिर उसी मॉडल को न्यूनतम अतिरिक्त प्रशिक्षण के साथ डाउनस्ट्रीम कार्यों के लिए अनुकूलित करें। यह एकल सामान्य‑उद्देश्य मॉडल का वादा करता था, कई संकुचित मॉडलों के बजाय।
यह वैचारिक बदलाव—छोटे, टास्क‑विशिष्ट सिस्टम से बड़े, जनरेटिवली प्री‑ट्रेंड ट्रांसफॉर्मर की ओर—पहले GPT मॉडल और उसके बाद आने वाली श्रृंखला की नींव रखता है।
GPT-1 OpenAI की पहली ऐसी कोशिश थी जिसने बाद के GPT परिवार की राह दिखाई। 2018 में जारी, इसमें 117 मिलियन पैरामीटर थे और यह 2017 के ट्रांसफॉर्मर आर्किटेक्चर पर आधारित था। हालांकि बाद के मानकों से यह छोटा था, पर इसने वह मूल विधि स्पष्ट कर दी जिसे बाद के सभी GPT मॉडल अपनाते हैं।
GPT-1 एक सरल परन्तु शक्तिशाली विचार से प्रशिक्षित किया गया:
प्री‑ट्रेनिंग के लिए GPT-1 ने BooksCorpus और विकिपीडिया‑शैली स्रोतों से निकले टेक्स्ट पर अगला टोकन अनुमान लगाना सीखा। यह उद्देश्य किसी इंसानी लेबलिंग की जरूरत नहीं देता था, जिससे मॉडल भाषा, शैली और तथ्यों के बारे में व्यापक ज्ञान吸収 कर सकता था।
प्री‑ट्रेनिंग के बाद, वही मॉडल बड़े NLP बेंचमार्क्स पर सुपरवाइज़्ड लर्निंग के साथ फाइन‑ट्यून किया गया: सेंटिमेंट एनालिसिस, प्रश्नोत्तर, टेक्स्चुअल इंटेलमेंट और अन्य। एक छोटा क्लासिफ़ायर हेड ऊपर जोड़ा गया और पूरा मॉडल (या उसका अधिकांश भाग) प्रत्येक लेबल्ड डेटासेट पर एंड‑टू‑एंड प्रशिक्षित किया गया।
मुख्य विधिक बिंदु यह था कि वही प्री‑ट्रेंड मॉडल कई कार्यों के लिए हल्का अनुकूलन लेकर प्रयोग किया जा सकता है, बजाय हर कार्य के लिए अलग‑अलग मॉडल स्क्रैच से ट्रेन करने के।
अपनी अपेक्षाकृत छोटी परिमाण के बावजूद, GPT-1 ने कई प्रभावशाली निष्कर्ष दिए:
GPT-1 में पहले से ही कुछ शून्य‑शॉट और फ्यू‑शॉट सामान्यीकरण के लक्षण थे, हालाँकि तब तक अधिकतर मूल्यांकन अलग‑अलग टास्क के लिए फाइन‑ट्यूनिंग पर निर्भर था।
GPT-1 कभी भी उपभोक्ता परिनियोजन या व्यापक डेवलपर API के लिए लक्षित नहीं था। कई कारणों से यह शोध‑क्षेत्र तक सीमित रहा:
फिर भी, GPT-1 ने टेम्पलेट स्थापित किया: बड़े टेक्स्ट कॉर्पस पर जनरेटिव प्री‑ट्रेनिंग, फिर सरल टास्क‑विशिष्ट फाइन‑ट्यूनिंग। बाद के सभी GPT मॉडल इस पहले ट्रांसफॉर्मर के स्केल, परिष्करण और बढ़ी हुई क्षमता वाले वंशज हैं।
GPT-2, 2019 में जारी, पहला ऐसा GPT मॉडल था जिसने वैश्विक ध्यान आकर्षित किया। इसने GPT-1 आर्किटेक्चर को 117M से 1.5B पैरामीटर तक स्केल किया और दिखाया कि ट्रांसफॉर्मर भाषा मॉडल का सरल स्केलिंग कितना आगे तक जा सकता है।
आर्किटेक्चरल रूप से GPT-2 GPT-1 जैसा ही था: एक डिकोडर‑ओनली ट्रांसफॉर्मर जो बड़े वेब कॉर्पस पर अगला‑टोकन अनुमान के साथ प्रशिक्षित था। प्रमुख अंतर था स्केल:
यह उछाल प्रवाहिता, लंबे अनुच्छेदों में समेकन और बिना टास्क‑विशिष्ट प्रशिक्षण के प्रॉम्प्ट का पालन करने की क्षमता में नाटकीय सुधार लाया।
GPT-2 ने कई शोधकर्ताओं की सोच बदल दी कि केवल अगला‑टोकन अनुमान क्या कर सकता है।
बिना किसी फाइन‑ट्यूनिंग के GPT-2 कई जीरो‑शॉट कार्य कर सकता था, जैसे:
प्रॉम्प्ट में कुछ उदाहरण देने पर (few‑shot) प्रदर्शन और बेहतर हो गया। यह संकेत था कि बड़े भाषा मॉडल इन‑कॉन्टेक्स्ट उदाहरणों को अस्थायी प्रशिक्षण सेट की तरह उपयोग करके कई कार्य आंतरिक रूप से प्रतिनिधित्व कर सकते हैं।
उत्कृष्ट जनरेशन गुणवत्ता ने बड़े भाषा मॉडलों के आसपास पहली बड़ी सार्वजनिक बहसें शुरू कर दीं। OpenAI ने शुरू में पूरा 1.5B मॉडल मामूली दुरुपयोग की चिंताओं के कारण रोका, जैसे:
इसके बजाय OpenAI ने चरणबद्ध रिलीज़ अपनाई:
यह क्रमिक दृष्टिकोण जोखिम मूल्यांकन और मॉनिटरिंग पर आधारित प्रारंभिक AI परिनियोजन नीति का एक शुरुआती उदाहरण था।
यहाँ तक कि छोटे GPT-2 चेकपॉइंट्स पर भी खुले स्रोत परियोजनाओं की लहर आई। डेवलपर्स ने रचनात्मक लेखन, कोड ऑटोकम्प्लीशन और प्रयोगात्मक चैटबॉट्स के लिए मॉडल फाइन‑ट्यून किए। शोधकर्ताओं ने पक्षपात, तथ्यात्मक त्रुटियाँ और विफलता मोड का परीक्षण किया।
इन प्रयोगों ने बड़े भाषा मॉडलों को रिसर्च आर्टिफैक्ट से सामान्य‑उद्देश्य टेक्स्ट इंजन की ओर बदलते हुए देखा। GPT-2 का प्रभाव GPT-3, ChatGPT और बाद के GPT‑4‑क्लास मॉडलों की स्वागत की अपेक्षाओं और चिंता‑बिंदुओं का निर्माण करने में महत्वपूर्ण रहा।
GPT-3 2020 में 175 बिलियन पैरामीटर के साथ आया, जो GPT-2 से 100× से अधिक बड़ा था। यह संख्या ध्यान खींचने लायक थी: यह केवल मेमोरी क्षमता नहीं बताती थी, बल्कि बड़ी स्केलिंग ने कुछ व्यवहारों को उजागर कर दिया जो पहले नहीं दिखे थे।
GPT-3 की प्रमुख खोज थी इन‑कॉन्टेक्स्ट लर्निंग। मॉडल को नए कार्यों पर फाइन‑ट्यून करने के बजाय, आप प्रॉम्प्ट में कुछ उदाहरण चिपका सकते थे:
मॉडल वज़न अपडेट नहीं कर रहा था; प्रॉम्प्ट अस्थायी प्रशिक्षण सेट की तरह काम कर रहा था। इससे शून्य‑शॉट, एक‑शॉट और फ्यू‑शॉट प्रॉम्प्टिंग के विचार उभरे और पहली लहर की प्रॉम्प्ट इंजीनियरिंग शुरू हुई: बिना मॉडल को छुए बेहतर व्यवहार प्राप्त करने के लिए निर्देशों, उदाहरणों और फॉर्मेटिंग को सावधानी से तैयार करना।
GPT-2 के डाउनलोडेबल वेट्स के विपरीत, GPT-3 मुख्यतः एक वाणिज्यिक API के माध्यम से उपलब्ध कराया गया। OpenAI ने 2020 में OpenAI API का प्राइवेट बीटा लॉन्च किया, जिससे GPT-3 को HTTP कॉल करके डेवलपर्स उपयोग कर सकें।
इसने बड़े भाषा मॉडलों को शोध आर्टिफैक्ट से एक व्यापक प्लेटफ़ॉर्म में बदल दिया। अपने मॉडल ट्रेन करने की बजाय स्टार्टअप और उद्यम एक API‑कुंजी के साथ प्रोटोटाइप बना सकते थे और प्रति‑टोकन भुगतान कर सकते थे।
प्रारंभिक अपनाने वालों ने तब से सामान्य पैटर्न खोज लिए जो अब मानक लगते हैं:
GPT-3 ने प्रमाणित किया कि एक सामान्य मॉडल—API के माध्यम से पहुंच योग्य—विविध अनुप्रयोगों को शक्ति दे सकता है और ChatGPT तथा बाद के GPT‑3.5 और GPT‑4 सिस्टम के लिए मंच तैयार किया।
बेस GPT-3 केवल इंटरनेट‑स्केल टेक्स्ट पर अगला‑टोकन अनुमान के लिए प्रशिक्षित था। यह पैटर्न जारी करने में अच्छा था, पर जरूरी नहीं कि वह वही करे जो उपयोगकर्ता चाहता था। उपयोगकर्ताओं को अक्सर प्रॉम्प्ट सावधानी से तैयार करने पड़ते थे, और मॉडल:
शोधकर्ताओं ने इस अंतर को संरेखण समस्या कहा: मॉडल का व्यवहार हमेशा मानव इरादों, मूल्यों या सुरक्षा अपेक्षाओं के अनुरूप नहीं था।
OpenAI का InstructGPT (2021–2022) एक मोड़ था। केवल कच्चे टेक्स्ट पर प्रशिक्षण के अलावा, उन्होंने GPT-3 के ऊपर दो प्रमुख चरण जोड़े:
इससे मॉडल ऐसे बने जो:
यूज़र स्टडीज़ में छोटे InstructGPT मॉडल अक्सर बड़े बेस GPT-3 मॉडल से बेहतर माने गए, यह दिखाते हुए कि संरेखण और इंटरफ़ेस गुणवत्ता कच्चे स्केल से अधिक मायने रख सकती है।
ChatGPT (देर 2022) ने InstructGPT के दृष्टिकोण को मल्टी‑टर्न वार्तालाप तक बढ़ाया। यह मूलतः एक GPT-3.5‑क्लास मॉडल था, जिसे SFT और RLHF के साथ संवादात्मक डेटा पर फाइन‑ट्यून किया गया।
API या डेवलपर्स के लिए प्लेग्राउंड की जगह OpenAI ने एक सरल चैट इंटरफ़ेस लॉन्च किया:
इसने गैर‑टेक्निकल उपयोगकर्ताओं के लिए बाधा घटा दी। कोई प्रॉम्प्ट इंजीनियरिंग की आवश्यकता नहीं—सिर्फ टाइप करें और उत्तर पायें।
परिणाम एक जनसंहार‑उपलब्धि थी: वर्षों के ट्रांसफॉर्मर शोध और संरेखण कार्य पर आधारित तकनीक अचानक किसी भी ब्राउज़र उपयोगकर्ता के लिए सुलभ हो गई। इंस्ट्रक्शन ट्यूनिंग और RLHF ने सिस्टम को पर्याप्त रूप से सहयोगी और सुरक्षित बनाया ताकि व्यापक रिलीज़ संभव हो, और चैट इंटरफ़ेस ने शोध मॉडल को एक वैश्विक उत्पाद और रोज़मर्रा के उपकरण में बदल दिया।
GPT-3.5 वह क्षण था जब बड़े भाषा मॉडल प्रमुखतः शोध जिज्ञासा से हटकर रोज़मर्रा की उपयोगिताएँ बन गए। यह GPT-3 और GPT-4 के बीच बसता था, पर इसकी वास्तविक महत्ता यह थी कि यह कितना सुलभ और व्यावहारिक हुआ।
तकनीकी रूप से, GPT-3.5 ने मूल GPT-3 आर्किटेक्चर को बेहतर प्रशिक्षण डेटा, अनुकूलन और व्यापक इंस्ट्रक्शन ट्यूनिंग के साथ परिष्कृत किया। इस श्रृंखला के मॉडलों—including text-davinci-003 और बाद में gpt-3.5-turbo—को प्राकृतिक भाषा निर्देशों का पालन अधिक विश्वसनीय रूप से करने, सुरक्षित रूप से प्रतिक्रिया देने और संगठित मल्टी‑टर्न संवाद बनाए रखने के लिए प्रशिक्षित किया गया।
इसने GPT-3.5 को GPT-4 के लिए एक स्वाभाविक कदम बना दिया। इसने रोज़मर्रा के कार्यों पर मजबूत तर्क क्षमता, लंबे प्रॉम्प्ट हैंडल करने की बेहतर क्षमता और स्थिर संवाद व्यवहार का पूर्वावलोकन दिया, वह भी बिना GPT-4 से जुड़ी उच्च जटिलता और लागत के।
देर 2022 में ChatGPT का पहला सार्वजनिक रिलीज़ GPT-3.5‑क्लास मॉडल द्वारा संचालित था, जिसे RLHF से फाइन‑ट्यून किया गया था। इसने काफी बेहतर बनाया कि मॉडल कैसे:
अनेकों के लिए ChatGPT पहला व्यावहारिक अनुभव था और इसने तय कर दिया कि "AI चैट" कैसा महसूस होना चाहिए।
gpt-3.5-turbo और क्यों यह डिफ़ॉल्ट बनाजब OpenAI ने API के माध्यम से gpt-3.5-turbo जारी किया, तो उसने मूल्य, गति और क्षमता का संतुलन पेश किया। यह पुराने GPT-3 मॉडलों की तुलना में सस्ता और तेज़ था, फिर भी बेहतर इंस्ट्रक्शन फॉलोइंग और संवाद गुणवत्ता देता था।
इस संतुलन ने gpt-3.5-turbo को कई अनुप्रयोगों के लिए डिफ़ॉल्ट विकल्प बना दिया:
GPT-3.5 ने इसलिए एक निर्णायक संक्रमण भूमिका निभाई: पर्याप्त शक्तिशाली, आर्थिक रूप से व्यावहारिक और इंस्ट्रक्शन्स के साथ मिलकर उपयोगी रोज़मर्रा के वर्कफ़्लोज़ खोलने वाला।
GPT-4, 2023 में जारी, "बड़े टेक्स्ट मॉडल" से एक सामान्य‑उद्देश्य सहायक की ओर एक बदलाव था, जिसमें तर्क क्षमता बेहतर हुई और मल्टीमॉडल इनपुट निहित थे।
GPT-3 और GPT-3.5 की तुलना में, GPT-4 ने कम ध्यान केवल पैरामीटर काउंट पर दिया और ज़्यादा ध्यान दिया:
फ्लैगशिप परिवार में gpt-4 और बाद के gpt-4-turbo शामिल थे, जो समान या बेहतर गुणवत्ता कम लागत और कम लेटेंसी पर देने का उद्देश्य रखते थे।
GPT-4 की एक हेडलाइन विशेषता इसकी मल्टीमॉडल क्षमता थी: टेक्स्ट के अलावा यह इमेज इनपुट भी स्वीकार कर सकता था। उपयोगकर्ता कर सकते थे:
इससे GPT-4 टेक्स्ट‑केवल मॉडल की तुलना में एक सामान्य‑तर्क इंजन जैसा महसूस होने लगा, जो भाषा के माध्यम से संवाद करता है।
GPT-4 को सुरक्षा और संरेखण पर अधिक जोर देकर प्रशिक्षण और ट्यून किया गया:
इन मॉडलों को—जैसे gpt-4 और gpt-4-turbo—गंभीर उत्पादन उपयोगों (कस्टमर सपोर्ट, कोडिंग असिस्टेंट, शिक्षा, ज्ञान‑खोज) के लिए डिफ़ॉल्ट विकल्प माना जाने लगा। GPT-4 ने बाद के वेरिएंट्स जैसे GPT-4o और GPT-4o mini के लिए ज़मीनी आधार तैयार किया, जिन्होंने दक्षता और वास्तविक‑समय इंटरैक्शन पर और काम किया।
GPT-4o ("omni") "किसी भी मूल्य पर सर्वाधिक सक्षम" से हटकर "तेज़, सस्ता और हमेशा‑ऑन" की दिशा में एक बदलाव दर्शाता है। यह GPT-4‑स्तरीय गुणवत्ता देते हुए काफी सस्ता और लाइव इंटरैक्शन के लिए तेज़ होने के लिए डिजाइन किया गया है।
GPT-4o टेक्स्ट, विज़न और ऑडियो को एकल मॉडल में एकीकृत करता है। अलग‑अलग घटकों को जोड़ने के बजाय यह नेटिव रूप से संभालता है:
यह एकीकरण विलंब और जटिलता घटाता है। GPT-4o अमूमन निकट‑रियल‑टाइम प्रतिक्रिया दे सकता है, स्ट्रीमिंग उत्तर दे सकता है और एक ही संवाद के भीतर मॉडालिटी बदल सकता है।
GPT-4o का एक प्रमुख लक्ष्य दक्षता है: प्रति‑डॉलर बेहतर प्रदर्शन और प्रति‑अनुरोध कम विलंब। इससे OpenAI और डेवलपर्स कर सकते हैं:
परिणाम यह है कि पहले सीमित, महंगे APIs पर उपलब्ध क्षमताएँ अब छात्रों, हॉबीस्ट्स, छोटे स्टार्टअप्स और AI आज़माने वाली टीमों के लिए सुलभ हो गई हैं।
GPT-4o mini और अधिक पहुँच बढ़ाता है—कुछ चरम क्षमता की कीमत पर गति और बेहद कम लागत देता है। यह उपयुक्त है:
चूँकि 4o mini किफायती है, डेवलपर्स इसे कई और स्थानों—ऐप्स, कस्टमर पोर्टल्स, आंतरिक टूल्स—में एम्बेड कर सकते हैं बिना बड़ी उपयोग लागत की चिंता के।
साथ में, GPT-4o और GPT-4o mini उन्नत GPT सुविधाओं को वास्तविक‑समय, संवादात्मक और मल्टी‑मॉडल मामलों में विस्तारित करते हैं, और उन लोगों की संख्या बढ़ाते हैं जो व्यावहारिक रूप से इन मॉडलों के साथ बना और लाभ उठा सकते हैं।
हर GPT पीढ़ी के दौरान कुछ तकनीकी धारणाएँ बार‑बार दिखती हैं: स्केल, फ़ीडबैक, सुरक्षा और विशेषज्ञीकरण। ये बताते हैं कि क्यों हर नया रिलीज़ मात्र बड़ा नहीं दिखता बल्कि गुणात्मक रूप से अलग होता है।
GPT प्रगति के पीछे एक प्रमुख खोज है स्केलिंग लॉज़: जब आप संतुलित तरीके से मॉडल पैरामीटर, डेटासेट आकार और कम्प्यूट बढ़ाते हैं तो प्रदर्शन कई कार्यों पर सुचारू और पूर्वानुमेय रूप से सुधरता है।
प्रारंभिक मॉडलों ने दिखाया कि:
इसने व्यवस्थित विधि दी:
कच्चे GPT मॉडल शक्तिशाली पर उपयोगकर्ता अपेक्षाओं के प्रति उदासीन होते हैं। RLHF उन्हें सहायक असिस्टेंट में बदल देता है:
समय के साथ यह विकास इंस्ट्रक्शन ट्यूनिंग + RLHF में बदल गया: पहले कई इंस्ट्रक्शन‑रिस्पॉन्स जोड़ों पर फाइन‑ट्यून, फिर RLHF से व्यवहार को परिष्कृत करना। यह संयोजन ChatGPT‑शैली इंटरैक्शंस की नींव है।
क्षमताएँ बढ़ने के साथ, व्यवस्थित सुरक्षा मूल्यांकन और नीति प्रवर्तन की आवश्यकता भी बढ़ी।
तकनीकी पैटर्न में शामिल हैं:
ये तंत्र बार‑बार परिष्कृत होते हैं: नई जाँच विफलता मोड खोजती है, जो प्रशिक्षण डेटा, रिवॉर्ड मॉडल और फिल्टर्स में फ़ीडबैक के रूप में जाती हैं।
पहले रिलीज़ एक फ्लैगशिप मॉडल के इर्द‑गिर्द केंद्रित थे। समय के साथ रुझान बदला—विभिन्न लक्ष्यों और उपयोग मामलों के लिए मॉडल परिवार की ओर:
अंदर से यह परिपक्व स्टैक को दर्शाता है: साझा बेस आर्किटेक्चर और प्रशिक्षण पाइपलाइन्स, फिर लक्षित फाइन‑ट्यूनिंग और सुरक्षा परतें ताकि एक एकल मॉनोलिथ के बजाय पोर्टफोलियो तैयार किया जा सके। यह बहु‑मॉडल रणनीति GPT विकास की एक प्रमुख तकनीकी और उत्पाद प्रवृत्ति बन चुकी है।
GPT मॉडलों ने भाषा‑आधारित AI को शोध औजार से उस इंफ्रास्ट्रक्चर में बदल दिया है जिस पर कई लोग और संगठन अब बनाते हैं।
डेवलपर्स के लिए GPT मॉडल एक लचीला "भाषा इंजन" की तरह व्यवहार करते हैं। नियम‑आधारित कोड लिखने के बजाय, वे प्राकृतिक‑भाषा प्रॉम्प्ट भेजते हैं और टेक्स्ट, कोड या संरचित आउटपुट पाते हैं।
इसने सॉफ़्टवेयर डिज़ाइन बदल दिया है:
नतीजा यह है कि कई उत्पाद अब GPT को एक कोर कंपोनेंट मानते हैं बजाय कि एक अतिरिक्त सुविधा के।
कंपनियाँ GPT मॉडल्स का उपयोग अंदरूनी और ग्राहक‑सामना दोनों जगह करती हैं।
आंतरिक रूप से टीमें सपोर्ट ट्रायाज, ईमेल और रिपोर्ट ड्राफ्टिंग, प्रोग्रामिंग और QA में मदद, और दस्तावेज़ों एवं लॉग्स का विश्लेषण स्वचालित करती हैं। बाहरी रूप से GPT चैटबॉट्स, प्रोडक्टिविटी सूट के AI कोपायलट्स, कोडिंग असिस्टेंट, कंटेंट और मार्केटिंग टूल्स, और वित्त, कानून, हेल्थकेयर जैसे डोमेन‑विशेष कोपायलट्स को शक्ति देता है।
API और होस्टेड उत्पादों ने उन्नत भाषा सुविधाएँ जोड़ना संभव बनाया बिना इंफ्रास्ट्रक्चर या मॉडल ट्रेनिंग की ज़रूरत के, जिससे छोटे और मध्यम संगठनों के लिए बाधा कम हुई है।
शोधकर्ता GPT का उपयोग विचार‑उत्पन्न करने, प्रयोगों के लिए कोड जनरेट करने, पेपर के ड्राफ्ट बनाने और प्राकृतिक भाषा में विचारों का परीक्षण करने के लिए करते हैं। शिक्षकों और छात्रों का सहारा GPT से स्पष्टीकरण, अभ्यास प्रश्न, ट्यूटरिंग और भाषा सहायता के लिए बढ़ा है।
लेखक, डिज़ाइनर और क्रिएटर्स GPT का उपयोग आउटलाइनिंग, आइडिएशन, वर्ल्ड‑बिल्डिंग और ड्राफ्टिंग को तेज़ करने के लिए करते हैं। मॉडल प्रतिस्थापन नहीं बल्कि सहयोगी के रूप में काम करता है जो खोज को तेज करता है।
GPT मॉडलों के प्रसार ने गंभीर चिंताएँ भी उठाईं। ऑटोमेशन कुछ नौकरियों को शिफ्ट या विस्थापित कर सकता है जबकि दूसरों की मांग बढ़ा सकता है, जिससे कामगारों को नए कौशल की ओर धकेलना पड़ सकता है।
क्योंकि GPT मानव डेटा पर प्रशिक्षित है, यह बिना सावधानी के सामाजिक पक्षपात को प्रतिबिंबित और बढ़ा सकता है। यह यथार्थपरक परन्तु गलत जानकारी भी बना सकता है, या स्पैम, пропगैंडा और भ्रामक कंटेंट बड़े पैमाने पर पैदा करने में दुरुपयोग हो सकता है।
इन जोखिमों ने संरेखण तकनीकों, उपयोग नीतियों, निगरानी और पता लगाने व प्रामाणिकता उपकरणों पर काम को प्रेरित किया है। शक्तिशाली अनुप्रयोगों और सुरक्षा, निष्पक्षता व विश्वास के बीच संतुलन बनाना एक खुली चुनौती बनी हुई है।
जैसे‑जैसे GPT मॉडल अधिक सक्षम होते जा रहे हैं, मूल प्रश्न बदलकर बन गए हैं—अब यह नहीं कि क्या हम इन्हें बना सकते हैं, बल्कि कि हमें इन्हें कैसे बनाना, परिनियोजित और शासित करना चाहिए।
दक्षता और पहुंच। GPT-4o और GPT-4o mini से संकेत मिलता है कि भविष्य में उच्च‑गुणवत्ता मॉडल सस्ते और छोटे सर्वरों पर या व्यक्तिगत उपकरणों पर चल सकेंगे। प्रमुख प्रश्न:
पर्सनलाइज़ेशन बिना ओवरफ़िटिंग। उपयोगकर्ता चाहते हैं कि मॉडल उनकी प्राथमिकताएँ, शैली और वर्कफ़्लोज़ याद रखें बिना डेटा लीक या पक्षपाती बनने के। खुले प्रश्न:
विश्वसनीयता और तर्क। शीर्ष मॉडलों में अभी भी हॉलूसिनेशन होते हैं, वे शांतिपूर्वक विफल हो सकते हैं या वितरण शिफ्ट में अनपेक्षित व्यवहार कर सकते हैं। शोध यह जांच रहा है:
स्केल पर सुरक्षा और संरेखण। जैसे‑जैसे मॉडलों को ऑटोमेशन और टूल्स के माध्यम से अधिक एजेंसी मिलती है, उन्हें मानव मूल्यों के अनुरूप संरेखित करना और निरंतर अपडेट के दौरान संरेखण बनाए रखना चुनौती बना रहता है। इसमें सांस्कृतिक वैविध्य भी शामिल है: किन मूल्यों और मानदंडों को एन्कोड किया जा रहा है, और मतभेद कैसे संभाले जाते हैं?
नियमन और मानक। सरकारें और उद्योग समूह पारदर्शिता, डेटा उपयोग, वॉटरमार्किंग और घटना रिपोर्टिंग के नियम बना रहे हैं। खुले प्रश्न:
भविष्य के GPT सिस्टम संभवतः और अधिक कुशल, और अधिक व्यक्तिगत तथा उपकरणों और संगठनों में और अधिक घुल‑मिलकर होंगे। नई क्षमताओं के साथ, और अधिक औपचारिक सुरक्षा अभ्यास, स्वतंत्र मूल्यांकन और स्पष्ट उपयोगकर्ता कंट्रोल की उम्मीद रखें। GPT-1 से GPT-4 तक का इतिहास दिखाता है कि निरंतर प्रगति संभव है, पर तकनीकी उन्नति को शासन, सामाजिक इनपुट और वास्तविक‑विश्व प्रभाव के सावधान मापन के साथ आगे बढ़ाना होगा।
GPT (Generative Pre-trained Transformer) मॉडल बड़े न्यूरल नेटवर्क होते हैं जिन्हें किसी वाक्य में अगला शब्द अनुमान लगाने के लिए प्रशिक्षित किया जाता है। बड़े टेक्स्ट कॉर्पस पर यह प्रशिक्षण करने से ये मॉडल व्याकरण, शैली, तथ्य और तर्क के पैटर्न सीख लेते हैं। प्रशिक्षित होने के बाद ये कर सकते हैं:
इतिहास जानने से स्पष्ट होता है:
यह वास्तविक अपेक्षाएँ तय करने में मदद करता है: GPT पैटर्न सीखने में शक्तिशाली हैं, पर सर्वज्ञ या त्रुटिहीन नहीं।
मुख्य माइलस्टोन्स:
इंस्ट्रक्शन ट्यूनिंग और RLHF मॉडल के व्यवहार को मानव अपेक्षाओं के अनुरूप बनाते हैं।
एक साथ ये मॉडल को अधिक सहायक, स्पष्ट और खतरनाक अनुरोधों को ठुकराने में बेहतर बनाते हैं—ऐसा कि छोटे, एलाइंड मॉडल अक्सर बड़े अनअलाइंड मॉडल से बेहतर दिखते हैं।
GPT-4 पहले के मॉडलों से कई मायनों में अलग है:
ये बदलाव GPT-4 को केवल टेक्स्ट जनरेटर से एक सामान्य‑उपयोग सहायक की ओर ले जाते हैं।
GPT-4o और GPT-4o mini को अधिकतर गति, लागत और वास्तविक‑समय उपयोग के लिए अनुकूलित किया गया है:
दोनों उन्नत GPT सुविधाओं को व्यापक और आर्थिक रूप से व्यावहारिक बनाते हैं।
डेवलपर्स सामान्यतः GPT मॉडल का उपयोग करके:
API के माध्यम से पहुँच होने से टीमें बिना अपने बड़े मॉडल ट्रेन/होस्ट किए इन क्षमताओं को जोड़ सकती हैं।
आज के GPT मॉडलों की सीमाएँ और जोखिम:
महत्वपूर्ण उपयोगों में आउटपुट की सत्यापन, पुनरुद्धार-आधारित जाँच, और मानव निगरानी आवश्यक हैं।
लेख कुछ प्रमुख रुझानों की ओर संकेत करता है:
दिशा अधिक सक्षम, नियंत्रित और जवाबदेह सिस्टमों की ओर है।
कुछ व्यावहारिक मार्गदर्शक सिद्धांत:
GPT का सुरक्षित और प्रभावी उपयोग उनकी ताकतों को गारंटी और अच्छे उत्पाद डिज़ाइन के साथ जोड़कर होता है।