15 मई 2025·8 मिनट
ग्राहक डेटा एनरिचमेंट के लिए वेब ऐप कैसे बनाएं
सीखें कि कैसे एक वेब ऐप बनाएं जो ग्राहक रिकॉर्ड्स को एनरिच करे: आर्किटेक्चर, इंटीग्रेशन, मैचिंग, वैलिडेशन, प्राइवेसी, मॉनिटरिंग और रोलआउट टिप्स।
लक्ष्य, उपयोगकर्ता और एनरिचमेंट स्कोप पर परिभाषा रखें
टूल चुनने या आर्किटेक्चर ड्रॉ करने से पहले, यह स्पष्ट करें कि आपकी संस्था के लिए “एनरिचमेंट” का क्या मतलब है। टीमें अक्सर कई प्रकार के एनरिचमेंट को मिला देती हैं और फिर प्रगति नापने या यह तय करने में उलझ जाती हैं कि “पूरा” क्या है।
किसे एनरिचमेंट माना जाएगा?
पहले उन फ़ील्ड श्रेणियों को नाम दें जिन्हें आप सुधारना चाहते हैं और क्यों:
- फर्मोग्राफिक: कंपनी का आकार, उद्योग, मुख्यालय स्थान, फंडिंग स्टेज
- संपर्क: नौकरी का शीर्षक, सत्यापित ईमेल/फोन, सीनियोरिटी, भूमिका
- व्यवहारिक: उत्पाद उपयोग संकेत, इंटेंट, एंगेजमेंट स्कोर
- कस्टम फ़ील्ड: आंतरिक क्षेत्र, खाता टियर, ICP फिट स्कोर
लिखें कौन से फ़ील्ड आवश्यक हैं, कौन से अच्छे होंगे और किन्हें कभी एनरिच नहीं किया जाना चाहिए (उदा. संवेदनशील गुण)।
ऐप कौन इस्तेमाल करेगा — और किसलिए?
प्राथमिक उपयोगकर्ताओं और उनके मुख्य कार्यों की पहचान करें:
- Sales ops: डुप्लिकेट घटाना, अकाउंट स्टैंडर्डाइज़ेशन, बेहतर रूटिंग
- Marketing ops: सेगमेंटेशन और टार्गेटिंग के लिए लीड्स को एनरिच करना
- Support: टिकट के दौरान अकाउंट संदर्भ दिखाना
- Analysts: रिपोर्टिंग के लिए भरोसेमंद datasets
प्रत्येक उपयोगकर्ता समूह को अलग वर्कफ़्लो (बुल्क प्रोसेसिंग बनाम सिंगल-रिकॉर्ड रिव्यू) की आवश्यकता होती है, इसलिए इन आवश्यकताओं को जल्द पकड़ लें।
आउटपुट, स्कोप सीमाएँ और सफलता मीट्रिक परिभाषित करें
परिणामों को मापने योग्य शब्दों में सूचीबद्ध करें: उच्च मैच रेट, कम डुप्लिकेट, तेज़ लीड/अकाउंट रूटिंग, या बेहतर सेगमेंटेशन प्रदर्शन।
स्पष्ट सीमाएँ तय करें: कौन से सिस्टम स्कोप में हैं (CRM, बिलिंग, प्रोडक्ट एनालिटिक्स, सपोर्ट डेस्क) और कौन से नहीं — कम से कम पहले रिलीज़ तक।
अंत में, सफलता मीट्रिक्स और स्वीकार्य त्रुटि दरों (उदा. एनरिचमेंट कवरेज, सत्यापन दर, डुप्लिकेट दर, और “सुरक्षित विफलता” नियम जब एनरिचमेंट अनिश्चित हो) पर सहमति बनाएं। यह आपके बिल्ड का उत्तर तारा बनेगा।
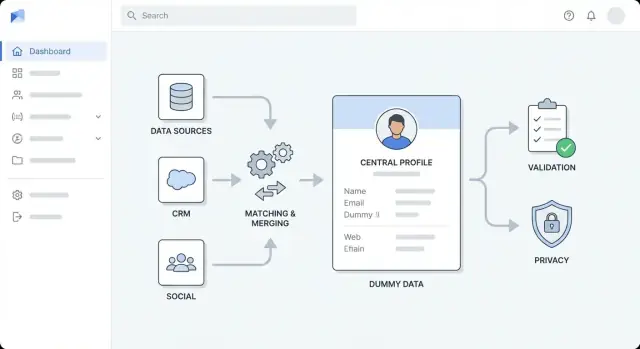
अपने ग्राहक डेटा का मॉडल बनाएं और गैप पहचानें
कुछ भी एनरिच करने से पहले, यह स्पष्ट करें कि आपके सिस्टम में “एक ग्राहक” का क्या अर्थ है — और आप पहले से उनके बारे में क्या जानते हैं। इससे आप ऐसे एनरिचमेंट के लिए भुगतान करने से बचेंगे जिन्हें आप स्टोर नहीं कर सकते और बाद में भ्रमित मर्ज से बचाव होगा।
अपने वर्तमान फ़ील्ड्स और स्रोतों की इन्वेंट्री बनाएं
सरल कैटलॉग से शुरू करें (उदा. नाम, ईमेल, कंपनी, डोमेन, फोन, पता, नौकरी का शीर्षक, उद्योग)। हर फ़ील्ड के लिए नोट करें कहाँ से यह आता है: यूज़र इनपुट, CRM इम्पोर्ट, बिलिंग सिस्टम, सपोर्ट टूल, प्रोडक्ट साइन-अप फॉर्म, या कोई एनरिचमेंट प्रदाता।
यह भी कैप्चर करें कैसे यह एकत्र किया जाता है (required vs optional) और कितनी बार बदलता है। उदाहरण के लिए, नौकरी का शीर्षक और कंपनी का आकार समय के साथ बदलते हैं, जबकि आंतरिक ग्राहक ID कभी नहीं बदलना चाहिए।
अपना पहचान मॉडल परिभाषित करें: व्यक्ति, कंपनी, अकाउंट
अधिकांश एनरिचमेंट वर्कफ़्लो में कम से कम दो एंटिटी शामिल होती हैं:
- व्यक्ति (contact/lead): एक व्यक्ति जिसके पास ईमेल, फोन, रोल होते हैं
- कंपनी (organization): एक व्यवसाय जिसके पास डोमेन, लोकेशन, फर्मोग्राफिक्स होते हैं
निर्णय लें कि क्या आपको एक Account भी चाहिए (एक वाणिज्यिक संबंध) जो कई लोगों को एक कंपनी से जोड़ सके और साथ में प्लान, कॉन्ट्रैक्ट तारीखें और स्टेटस जैसी विशेषताएँ रखे।
लिखें आप किन संबंधों का समर्थन करते हैं (उदा. कई लोग → एक कंपनी; एक व्यक्ति → समय के साथ कई कंपनियाँ)।
सामान्य डेटा समस्याओं का दस्तावेज़ीकरण करें
बार-बार दिखने वाली समस्याओं की सूची बनाएं: गायब वैल्यूज़, असंगत फॉर्मैट ("US" बनाम "United States"), इम्पोर्ट से बने डुप्लिकेट, स्टेल रिकॉर्ड, और संघर्षशील स्रोत (billing address बनाम CRM address)।
आवश्यक कुंजी चुनें और ट्रस्ट स्तर सेट करें
वो पहचानकर्ता चुनें जिनका आप मिलान और अपडेट के लिए उपयोग करेंगे — सामान्यतः email, domain, phone, और आंतरिक customer ID।
प्रत्येक को ट्रस्ट स्तर दें: कौन सी कुंजी authoritative हैं, कौन सी “best effort” हैं, और कौन सी कभी ओवरराइट नहीं करनी चाहिए।
स्वामित्व और एडिट परमिशन्स स्पष्ट करें
तय करें कि कौन किस फ़ील्ड का ओनर है (Sales ops, Support, Marketing, Customer success) और एडिट नियम: इंसान क्या बदल सकता है, ऑटोमेशन क्या बदल सकता है, और किसके लिए अप्रूवल चाहिए।
यह गवर्नेंस उन स्थितियों में समय बचाएगा जब एनरिचमेंट परिणाम मौजूदा डेटा से टकराएँ।
एनरिचमेंट स्रोत और डेटा कॉन्ट्रैक्ट चुनें
इंटीग्रेशन कोड लिखने से पहले तय करें कि एनरिचमेंट डेटा कहाँ से आएगा और आप उसके साथ क्या कर सकते हैं। इससे एक सामान्य विफलता मोड रोका जा सकता है: तकनीकी रूप से काम करने वाली फ़ीचर को शिप करना जो लागत, विश्वसनीयता या अनुपालन अपेक्षाओं को तोड़ दे।
सामान्य एनरिचमेंट स्रोत
आप आमतौर पर कई इनपुट्स को मिलाएंगे:
- आंतरिक सिस्टम: CRM, बिलिंग, सपोर्ट टिकट, प्रोडक्ट एनालिटिक्स, ईमेल प्लेटफ़ॉर्म, डेटा वेयरहाउस
- थर्ड-पार्टी APIs: कंपनी फर्मोग्राफिक्स, संपर्क सत्यापन, इंडस्ट्री कोड, टेक्नोग्राफिक्स, रिस्क सिग्नल
- अपलोडेड लिस्ट्स: CSVs, इवेंट/पार्टनर डेटा
- Webhooks: उन टूल्स से रियल-टाइम अपडेट्स जो बदलाव देखते हैं (उदा. ईमेल सत्यापन, आइडेंटिटी प्रोवाइडर्स)
स्रोतों का मूल्यांकन कैसे करें
प्रत्येक स्रोत के लिए उसे स्कोर करें: कवरेज (कितनी बार उपयोगी लौटता है), ताज़गी (कितनी जल्दी अपडेट होता है), लागत (प्रति कॉल/प्रति रिकॉर्ड), रेट लिमिट्स, और उपयोग की शर्तें (आप क्या स्टोर कर सकते हैं, कितनी देर, किस उद्देश्य के लिए)।
जांचें कि प्रदाता confidence scores और स्पष्ट provenance (किस स्रोत से फ़ील्ड आया) देता है या नहीं।
डेटा कॉन्ट्रैक्ट परिभाषित करें
हर स्रोत को एक कॉन्ट्रैक्ट मानें जो फ़ील्ड नाम और फॉर्मैट, required vs optional फ़ील्ड, अपडेट फ्रिक्वेंसी, अपेक्षित लेटेंसी, एरर कोड्स, और confidence semantics निर्दिष्ट करे।
एक स्पष्ट मैपिंग शामिल करें (“provider field → आपका canonical field”) और nulls तथा conflicting values के नियम।
फॉलबैक और स्टोरेज निर्णय
योजना बनाएं कि जब कोई स्रोत अनुपलब्ध हो या कम-कॉन्फिडेंस परिणाम दे तो क्या होगा: बैकऑफ के साथ रीट्राई, बाद के लिए क्यू में डालना, या सेकेंडरी स्रोत पर फॉलबैक।
निर्णय लें कि आप क्या स्टोर करेंगे (सर्च/रिपोर्टिंग के लिए ज़रूरी स्थिर एट्रिब्यूट) बनाम क्या आप डिमांड पर कंप्यूट करेंगे (महंगा या समय-संवेदी लुकअप)।
अंत में, संवेदनशील एट्रिब्यूट्स (उदा. व्यक्तिगत पहचानकर्ता, अनुमानित जनसांख्यिकी) को स्टोर करने पर प्रतिबंध और रिटेंशन नियम दस्तावेज़ित करें।
हाई-लेवल आर्किटेक्चर डिजाइन करें
टूल चुनने से पहले तय करें कि ऐप कैसे आकार लेगा। एक स्पष्ट हाई-लेवल आर्किटेक्चर एनरिचमेंट काम को पूर्वानुमेय रखता है, “क्विक फिक्स” को स्थायी गंदगी बनने से रोकता है, और आपकी टीम को प्रयास का अंदाज़ा देने में मदद करता है।
अपनी टीम के लिए सही आर्किटेक्चर स्टाइल चुनें
अधिकतर टीमों के लिए, एक मॉड्यूलर मोनोलिथ के साथ शुरू करें: एक डिप्लॉयेबल ऐप, अंदर स्पष्ट मॉड्यूल (ingestion, matching, enrichment, UI)। यह बनाना, टेस्ट करना और डिबग करना सरल बनाता है।
अलग सेवाओं की ओर तभी बढ़ें जब स्पष्ट कारण हो—उदा. एनरिचमेंट थ्रूपुट बहुत ज़्यादा हो, स्वतंत्र स्केलिंग चाहिए, या अलग टीमें अलग हिस्सों को हैंडल करती हों। एक सामान्य विभाजन:
- API सर्विस (sync रिक्वेस्ट्स, auth, record CRUD)
- Worker सर्विस (async एनरिचमेंट, retries)
- UI (रिव्यू, अप्रूवल्स, बुल्क एक्शन्स)
चिंताएँ परतों में अलग रखें
सीमाओं को स्पष्ट रखें ताकि बदलाव सब जगह असर न करें:
- Ingestion layer: CRM/files से इम्पोर्ट और इनपुट नॉर्मलाइज़ेशन
- Enrichment layer: विक्रेता/आंतरिक स्रोत कॉल्स और परिणाम स्टोर करना
- Validation layer: डेटा क्वालिटी नियम और अपवादों को फ्लैग करना
- Storage layer: ग्राहक प्रोफाइल्स, कच्चे स्रोत पेलोड्स, ऑडिट हिस्ट्री
- Presentation layer: UI व्यूज़, रिव्यू कतारें, अप्रूवल्स
शुरुआत से async एनरिचमेंट के लिए डिजाइन करें
एनरिचमेंट धीमा और विफलता-प्रवण है (रेट लिमिट्स, टाइमआउट्स, आंशिक डेटा)। एनरिचमेंट को जॉब्स की तरह देखें:
- API एक जॉब बनाता है और जल्दी रिटर्न करता है
- वर्कर्स जॉब्स को क्यू के जरिए प्रोसेस करते हैं (retries और backoff के साथ)
- UI जॉब स्टेटस दिखाती है और जरूरत पर री-रन की अनुमति देती है
एनवायरनमेंट और कॉन्फ़िगरेशन की योजना बनाएं
शुरू से dev/staging/prod सेट करें। वेंडर कीज़, thresholds, और feature flags को कोड में नहीं बल्कि कॉन्फ़िगरेशन में रखें, और हर एनवायरनमेंट के लिए प्रदाताओं को स्वैप करना सरल रखें।
एक-पृष्ठ का डायग्राम बनाकर सहमति लें
एक सरल डायग्राम स्केच करें: UI → API → DB, साथ में queue → workers → enrichment providers। इसे रिव्यू में उपयोग करें ताकि कार्यान्वयन से पहले सभी जिम्मेदारियों पर सहमति हो जाए।
फास्ट-पाथ प्रोटोटाइपिंग (वैकल्पिक)
यदि आपका लक्ष्य वर्कफ़्लो और रिव्यू स्क्रीन को मान्य करना है तो पूर्ण इंजीनियरिंग चक्र में निवेश करने से पहले, Koder.ai जैसे vibe-coding प्लेटफ़ॉर्म से कोर ऐप जल्दी प्रोटोटाइप किया जा सकता है: रिव्यू/अप्रूवल के लिए React-आधारित UI, एक Go API लेयर, और PostgreSQL-बैक्ड स्टोरेज।
यह जॉब मॉडल (async एनरिचमेंट with retries), ऑडिट हिस्ट्री, और रोल-आधारित एक्सेस पैटर्न साबित करने में विशेष रूप से उपयोगी हो सकता है, और जब आप प्रोडक्शनाइज़ करने के लिए तैयार हों तो सोर्स कोड एक्सपोर्ट कर सकते हैं।
स्टोरेज, क्यूज़ और सहायक सेवाएँ सेट अप करें
एनरिचमेंट प्रदाताओं को वायर करने से पहले “प्लंबिंग” सही रखें। स्टोरेज और बैकग्राउंड प्रोसेसिंग के निर्णय बाद में बदलना कठिन होते हैं, और वे विश्वसनीयता, लागत, और ऑडिटेबिलिटी को सीधे प्रभावित करते हैं।
प्राथमिक डेटाबेस: प्रोफाइल + हिस्ट्री
ग्राहक प्रोफाइल के लिए एक प्राथमिक डेटाबेस चुनें जो संरचित डेटा और सक्षम एट्रिब्यूट्स को संभाल सके। Postgres एक सामान्य विकल्प है क्योंकि यह कोर फ़ील्ड्स (नाम, डोमेन, उद्योग) के साथ semi-structured एनरिचमेंट फ़ील्ड्स (JSON) रख सकता है।
उसी तरह महत्वपूर्ण: परिवर्तन इतिहास स्टोर करें। वैल्यूज़ को चुपचाप ओवरराइट करने के बजाय, कैप्चर करें किसने/क्या बदला, कब बदला, और क्यों (उदा. “vendor_refresh”, “manual_approval”)। इससे अप्रूवल्स आसान होते हैं और रोलबैक के समय सुरक्षा मिलती है।
क्यू: एनरिचमेंट और retries
एनरिचमेंट स्वाभाविक रूप से असिंक्रोनस है: APIs रेट-लिमिट करते हैं, नेटवर्क फेल होते हैं, और कुछ विक्रेता धीरे-धीरे रिस्पॉन्स देते हैं। बैकग्राउंड वर्क के लिए जॉब क्यू जोड़ें:
- एनरिचमेंट रिक्वेस्ट्स (सिंगल रिकॉर्ड और बुल्क)
- बैकऑफ के साथ retries
- शेड्यूल्ड रिफ्रेश (उदा. हर 30/90 दिन)
- जिन जॉब्स का बार-बार फेल होना — dead-letter हैंडलिंग
यह आपकी UI को प्रतिक्रियाशील रखता है और विक्रेता की परेशानियाँ ऐप को डाउन करने से रोकता है।
कैश: तेज़ लुकअप और रेट-लिमिट ट्रैकिंग
एक छोटा कैश (अक्सर Redis) बार-बार लुकअप (उदा. “डोमेन द्वारा कंपनी”) और विक्रेता रेट-लिमिट/कूलडाउन विंडो ट्रैक करने में मदद करता है। यह idempotency keys के लिए भी उपयोगी है ताकि रिपीट इम्पोर्ट्स डुप्लिकेट एनरिचमेंट ट्रिगर न करें।
फ़ाइल स्टोरेज और रिटेंशन
CSV इम्पोर्ट/एक्सपोर्ट, एरर रिपोर्ट्स, और रिव्यू फ्लो में उपयोग होने वाली “diff” फाइल्स के लिए ऑब्जेक्ट स्टोरेज प्लान करें।
शुरू में रिटेंशन नियम परिभाषित करें: कच्चे वेंडर पेलोड्स डिबग और ऑडिट के लिए तभी रखें जब ज़रूरी हो, और लॉग्स को आपकी कंम्प्लायंस नीति के अनुरूप एक्सपायर करें।
इन्गेस्टन और नॉर्मलाइज़ेशन पाइपलाइन्स बनाएं
रिव्यू और अप्रूवल का परीक्षण करें
पूर्ण कार्यान्वयन से पहले मर्ज रिव्यू स्क्रीन और ऑडिट हिस्ट्री बनाएं।
आपका एनरिचमेंट ऐप उतना ही अच्छा है जितना आप इसमें फीड करते हैं। इन्गेस्टन वह जगह है जहाँ आप तय करते हैं कि जानकारी सिस्टम में कैसे आती है, और नॉर्मलाइज़ेशन वह जगह है जहाँ आप उस जानकारी को इतना सुसंगत बनाते हैं कि मिलान, एनरिच और रिपोर्टिंग संभव हो।
डेटा कैसे प्रवेश करेगा तय करें
अधिकांश टीमों को कई एंट्री पॉइंट्स की ज़रूरत होती है:
- API endpoints आपके प्रोडक्ट या आंतरिक टूल्स के लिए नए/अपडेटेड ग्राहक पुश करने के लिए
- Webhooks CRMs या बिलिंग सिस्टम से नियर-रियल-टाइम बदलाव के लिए
- Scheduled pulls (नाइटली सिंक्स) उन सिस्टम्स के लिए जो पुश सपोर्ट नहीं करते
- CSV imports बैकफिल्स और वन-ऑफ़ अपलोड्स के लिए
जो भी आप सपोर्ट करें, “raw ingest” स्टेप को हल्का रखें: डेटा स्वीकार करें, authenticate करें, metadata लॉग करें, और प्रोसेसिंग के लिए काम क्यू में डाल दें।
जल्द ही नॉर्मलाइज़ और स्टैंडर्डाइज़ करें
एक नॉर्मलाइज़ेशन लेयर बनाएं जो गंदे इनपुट्स को एक सुसंगत इंटरनल शेप में बदल दे:
- नाम: whitespace हटाएँ, संभव हो तो full names को split करें, केसिंग संभालें
- फोन: E.164 फॉर्मैट में कन्वर्ट करें और देशीय अनुमान स्पष्ट रखें
- पते: फील्ड्स स्टैंडर्डाइज़ करें (street, locality, region, postal code) और मूल टेक्स्ट रखें
- डोमेन्स/ईमेल: लोअरकेस करें, URL से ट्रैकिंग पैरामीटर्स हटाएँ, सिन्टैक्स वैलिडेट करें
वेरीफाई, क्वारंटीन और आइडेम्पोटेंसी बनाएँ
रिकॉर्ड प्रकार के अनुसार required फ़ील्ड्स परिभाषित करें और चेक फेल होने पर reject या quarantine करें (उदा. कंपनी मैचिंग के लिए ईमेल/डोमेन गायब)। क्वारंटीन किए गए आइटम UI में देखे और ठीक किए जाने चाहिए।
idempotency keys जोड़ें ताकि retries के दौरान डुप्लिकेट प्रोसेसिंग न हो (वेबहुक्स और अस्थिर नेटवर्क के साथ सामान्य)। एक सरल तरीका है (source_system, external_id, event_type, event_timestamp) का हैशिंग।
प्रति फ़ील्ड lineage ट्रैक करें
हर रिकॉर्ड और ideally हर फ़ील्ड के लिए provenance स्टोर करें: source, ingestion time, और transformation version। इससे बाद में सवालों के जवाब मिलते हैं: “यह फोन नंबर क्यों बदला?” और “किस इम्पोर्ट ने यह वैल्यू पैदा की?”
मिलान, डुप्लिकेशन हटाना, और मर्जिंग लागू करें
एनरिचमेंट का सही होना इस बात पर निर्भर करता है कि आप विश्वसनीय रूप से पहचान सकें कौन कौन है। आपके ऐप में स्पष्ट मिलान नियम, पूर्वानुमेय मर्ज व्यवहार, और जब सिस्टम निश्चित न हो तब एक सुरक्षा नेट होना चाहिए।
मिलान नियम परिभाषित करें (और कॉन्फिडेंस थ्रेशोल्ड्स)
डिटर्मिनिस्टिक पहचानकर्ताओं से शुरू करें:
- एक्सैक्ट कीज़: ईमेल (लोअरकेस किया हुआ), customer ID, tax/VAT ID, या सत्यापित डोमेन
फिर प्रॉबैबिलिस्टिक मिलान जोड़ें जहाँ एक्सैक्ट कीज़ गायब हों:
- फज़ी मैचेस: नाम + कंपनी डोमेन, नाम + लोकेशन, फोन समानता
एक match score असाइन करें और थ्रेशोल्ड्स सेट करें, उदाहरण:
- Auto-merge केवल उच्च थ्रेशोल्ड के ऊपर
- मैनुअल रिव्यू कतार में “शायद” रेंज
- Reject निचले थ्रेशोल्ड के नीचे
डुप्लिकेशन हटाने और मर्ज लॉजिक की योजना बनाएं
जब दो रिकॉर्ड एक ही ग्राहक को दर्शाते हैं, तय करें कि फ़ील्ड्स कैसे चुनी जाएँ:
- Field precedence: “सत्यापित ईमेल अनसत्यापित पर जीतता है”, “नया टाइमस्टैम्प जीतेगा”, “कॉन्टैक्ट ओनर के लिए CRM एनरिचमेंट को ओवरराइड न करें”
- स्रोत ट्रस्ट स्कोर: स्रोतों को रैंक करें (CRM, बिलिंग, एनरिचमेंट प्रदाता) ताकि संघर्ष सुलझाया जा सके
- संघर्ष संभालना: जहाँ संभव हो दोनों वैल्यू रखें (उदा. कई फोन नंबर) या हारने वाली वैल्यू को हिस्ट्री में स्टोर करें
ऑडिट ट्रेल और रिव्यू वर्कफ़्लो
हर मर्ज एक ऑडिट इवेंट बनाए: किसने/क्या ट्रिगर किया, पहले/बाद के वैल्यू, match score, और शामिल रिकॉर्ड IDs।
अस्पष्ट मैचेस के लिए एक रिव्यू स्क्रीन दें जिसमें साइड-बाय-साइड तुलना और “merge / don’t merge / और डेटा माँगें” विकल्प हों।
आकस्मिक मास मर्ज से बचाव के उपाय
बुल्क मर्ज के लिए अतिरिक्त कन्फर्मेशन आवश्यक रखें, जॉब प्रति मर्ज कैप लगाएँ, और “ड्राई रन” प्रीव्यू सपोर्ट करें।
ऑडिट हिस्ट्री का उपयोग कर एक undo पाथ (या मर्ज रिवर्सल) भी जोड़ें ताकी गलतियाँ स्थायी न हों।
एनरिचमेंट APIs इंटीग्रेट करें और विश्वसनीयता संभालें
एनरिचमेंट वह जगह है जहाँ आपका ऐप बाहरी दुनिया से मिलता है—कई प्रदाता, असंगत रिस्पॉन्स, और अनअपेक्षित उपलब्धता।
प्रत्येक प्रदाता को एक प्लग-इन “कनेक्टर” की तरह ट्रीट करें ताकि आप स्रोत जोड़, स्वैप, या डिसेबल कर सकें बिना बाकी पाइपलाइन को छुए।
प्रदाता कनेक्टर्स बनाएं (auth, retries, error mapping)
प्रत्येक एनरिचमेंट प्रदाता के लिए एक कनेक्टर बनाएं जिसका एक सुसंगत इंटरफ़ेस हो (उदा. enrichPerson(), enrichCompany())। कनेक्टर के अंदर प्रदाता-विशिष्ट लॉजिक रखें:
- Authentication (API keys, OAuth tokens, token refresh)
- अस्थायी विफलों के लिए standardized retries
- एरर मैपिंग (प्रदाता की त्रुटियों को आपकी केटेगरीज़ में बदलें जैसे
invalid_request,not_found,rate_limited,provider_down)
इससे डाउनस्ट्रीम वर्कफ़्लोज़ सरल होते हैं: वे आपके एरर टाइप्स को संभालते हैं, हर प्रदाता की अनियमितताओं को नहीं।
रेट-लिमिट्स को throttling और backoff से संभालें
अधिकांश एनरिचमेंट APIs कोटा लागू करते हैं। प्रदाता के अनुसार (और कभी-कभी एंडपॉइंट के अनुसार) थ्रॉटलिंग जोड़ें ताकि रिक्वेस्ट्स लिमिट के अंदर रहें।
जब आप लिमिट हिट करें, तो exponential backoff with jitter और Retry-After हेडर का सम्मान करें।
“धीमी विफलता” के लिए भी योजना बनाएं: टाइमआउट और आंशिक रिस्पॉन्स को retriable इवेंट्स माना जाना चाहिए, न कि साइलेंट ड्रॉप।
कॉन्फिडेंस और एविडेंस स्टोर करें (पॉलिसी के भीतर)
एनरिचमेंट परिणाम शायद ही कभी निश्चित होते हैं। प्रदाता confidence scores उपलब्ध कराने पर उन्हें स्टोर करें, साथ में अपना स्कोर भी रखें जो मैच क्वालिटी और फ़ील्ड कंप्लीटनेस पर आधारित हो।
जहाँ अनुबंध और प्राइवेसी पॉलिसी अनुमति दें, रॉ एविडेंस (स्रोत URLs, आइडेंटिफ़ायर्स, टाइमस्टैम्प) स्टोर करें ताकि ऑडिट और उपयोगकर्ता विश्वास संभव हो।
बहु-प्रदाता रणनीति: “बेस्ट अवेलेबल” चयन
कई प्रदाताओं का समर्थन करें और चयन नियम परिभाषित करें: सबसे सस्ता-पहले, उच्चतम-कॉन्फिडेंस, या फ़ील्ड-बाय-फ़ील्ड “बेस्ट अवेलेबल”।
यह भी रिकॉर्ड करें कि किसने कौन सी एट्रिब्यूट दी ताकि आप परिवर्तनों को समझा सकें और जरूरत पे रोलबैक कर सकें।
शेड्यूल्ड रिफ्रेश नियम
एनरिचमेंट समय के साथ स्टेल हो जाता है। रिफ्रेश नीतियाँ लागू करें जैसे “हर 90 दिन re-enrich”, “कुंजी फ़ील्ड बदलने पर रिफ्रेश”, या “केवल तभी रिफ्रेश जब कॉन्फिडेंस गिरे”।
शेड्यूल को ग्राहक और डेटा प्रकार के अनुसार कॉन्फ़िगर करने योग्य रखें ताकि लागत और शोर नियंत्रित रहें।
डेटा क्वालिटी नियम और वैलिडेशन जोड़ें
स्कीमा से UI तक जाएँ
अपने डेटा मॉडल और कॉन्ट्रैक्ट्स को कार्यशील CRUD स्क्रीन और APIs में बदलें।
जब तक नए वैल्यूज़ भरोसेमंद न हों, एनरिचमेंट मदद नहीं करता। वैलिडेशन को एक फर्स्ट-क्लास फ़ीचर मानें: यह गंदे इम्पोर्ट्स, अविश्वसनीय थर्ड-पार्टी रिस्पॉन्सेस, और मर्ज के दौरान आकस्मिक भ्रष्टाचार से उपयोगकर्ताओं की रक्षा करता है।
फ़ील्ड-स्तरीय वैलिडेशन नियम परिभाषित करें
प्रत्येक फ़ील्ड के लिए एक सरल “रूल्स कैटलॉग” से शुरू करें, जो UI फॉर्म्स, इन्गेस्टन पाइपलाइन्स, और पब्लिक APIs द्वारा साझा किया जाए।
सामान्य नियमों में फॉर्मैट चेक्स (ईमेल, फोन, पोस्टल कोड), अनुमत मान (country codes, industry lists), रेंज (employee count, revenue bands), और आवश्यक dependencies (यदि country = US तो state आवश्यक) शामिल हैं।
नियमों को वर्ज़न्ड रखें ताकि आप समय के साथ उन्हें सुरक्षित रूप से बदल सकें।
वास्तविक उपयोग को प्रतिबिंबित करने वाले क्वालिटी चेक जोड़ें
बुनियादी वैलिडेशन के परे, डेटा क्वालिटी चेक्स चलाएँ जो व्यापारिक प्रश्नों का उत्तर दें:
- Completeness: क्या हमारे पास रिकॉर्ड उपयोग के लिए न्यूनतम फ़ील्ड्स हैं?
- Uniqueness: क्या “यूनिक” पहचानकर्ता (डोमेन, टैक्स ID) डुप्लिकेट हैं?
- Consistency: क्या संबंधित फ़ील्ड्स सहमत हैं (country बनाम phone prefix)?
- Timeliness: वैल्यू पुराना है, और क्या इसे रिफ्रेश करना चाहिए?
रिकॉर्ड्स और स्रोतों को स्कोर करें
चेक्स को स्कोरकार्ड में बदलें: प्रति रिकॉर्ड (ओवरऑल हेल्थ) और प्रति स्रोत (कितनी बार यह वैध, अप-टू-डेट वैल्यू देता है)।
स्कोर का उपयोग ऑटोमेशन को गाइड करने के लिए करें — उदाहरण के लिए, केवल उच्च-थ्रेशोल्ड वाले एनरिचमेंट को ऑटो-अप्लाई करें।
विफलताओं को पूर्वानुमेय रूप से रूट करें
जब रिकॉर्ड वैलिडेशन फेल होता है, इसे ड्रॉप न करें।
इसे “data-quality” क्यू में भेजें (ट्रांज़िएंट इश्यूज़ के लिए retry) या मैन्युअल रिव्यू के लिए (खराब इनपुट)। फेल्ड पेलोड, नियम उल्लंघन, और सुझाए गए सुधार स्टोर करें।
त्रुटियों को समझने योग्य बनाएं
इम्पोर्ट्स और API क्लाइंट्स के लिए स्पष्ट, कार्रवाई योग्य संदेश लौटाएँ: कौन सा फ़ील्ड फेल हुआ, क्यों, और वैध मान का उदाहरण।
यह सपोर्ट लोड घटाता है और क्लीनअप काम तेज़ करता है।
रिव्यू, अप्रूवल्स और बुल्क वर्क के लिए UI बनाएं
आपका एनरिचमेंट पाइपलाइन तभी मूल्य लाती है जब लोग यह देख सकें कि क्या बदला, क्यों, और निश्चित होकर डाउनस्ट्रीम सिस्टम्स में अपडेट धकेल सकें।
UI को “क्या हुआ, क्यों हुआ, और अगला कदम क्या है?” स्पष्ट करना चाहिए।
डिज़ाइन करने के लिए मुख्य स्क्रीन
Customer profile होम बेस है। प्रमुख पहचानकर्ता (ईमेल, डोमेन, कंपनी नाम), वर्तमान फ़ील्ड वैल्यूज़, और एक enrichment status बैज दिखाएँ (उदा. Not enriched, In progress, Needs review, Approved, Rejected)।
एक change history टाइमलाइन जोड़ें जो अपडेट्स को स्पष्ट भाषा में बताए: “Company size 11–50 से 51–200 में अपडेट हुआ।” हर एंट्री क्लिकेबल हो ताकि डिटेल देखें।
डुप्लिकेट्स मिलने पर merge suggestions दें। कैंडिडेट रिकॉर्ड्स को साइड-बाय-साइड दिखाएँ साथ में सिफारिश किया गया “survivor” रिकॉर्ड और मर्ज का प्रीव्यू।
वास्तविक ऑपरेशंस से मेल खाते बुल्क वर्क
ज्यादातर टीमें बैच में काम करती हैं। शामिल करें:
- चुने गए रिकॉर्ड्स को एनरिच करें (या रात भर प्रोसेसिंग के लिए क्यू में डालें)
- सुझाए गए मर्जेस को अप्रूव/रिजेक्ट करें
- ऑडिट/ऑफ़लाइन रिव्यू के लिए परिणाम एक्सपोर्ट करें (CSV)
विनाशकारी क्रियाओं (merge, overwrite) के लिए स्पष्ट कन्फर्मेशन स्टेप और जहाँ संभव हो “undo” विंडो रखें।
तेज़ सर्च, फ़िल्टर्स, और फ़ील्ड-स्तरीय provenance
ग्लोबल सर्च और फ़िल्टर्स जोड़ें: email, domain, company, status, और quality score द्वारा।
उपयोगकर्ताओं को "Needs review" या "Low confidence updates" जैसे व्यू सेव करने दें।
प्रत्येक एनरिच्ड फ़ील्ड के लिए provenance दिखाएँ: स्रोत, टाइमस्टैम्प, और कॉन्फिडेंस।
एक साधारण “Why this value?” पैनल विश्वास बनाता है और बैक-एंड बातचीत कम करता है।
गैर-तकनीकी उपयोगकर्ताओं के लिए गाइडेड वर्कफ़्लोज़
निर्णयों को बाइनरी और मार्गदर्शित रखें: “Suggest किए गए वैल्यू को स्वीकार करें”, “मौजूदा रखें”, या “हाथ से एडिट करें”। यदि गहरी नियंत्रण आवश्यकता हो तो उसे “Advanced” टॉगल के पीछे रखें बजाय इसे डिफ़ॉल्ट बनाने के।
सुरक्षा, गोपनीयता, और अनुपालन के बुनियादी सिद्धांत
असिंक्रोनस जॉब मॉडल सत्यापित करें
टूल्स जोड़ने से पहले जॉब क्यू, रिट्राइ और स्टेटस स्क्रीन खड़ी करें।
ग्राहक एनरिचमेंट ऐप्स संवेदनशील पहचानकर्ताओं (ईमेल, फोन) को छूते हैं और अक्सर थर्ड-पार्टी से डेटा खींचते हैं। सुरक्षा और प्राइवेसी को कोई "बाद में" फीचर न मानें।
रोल-आधारित एक्सेस कंट्रोल (RBAC)
स्पष्ट भूमिकाओं और न्यून-विशेषाधिकार डिफ़ॉल्ट के साथ शुरू करें:
- Admin: यूज़र्स, रोल्स, कनेक्टर्स, रिटेंशन नीतियाँ प्रबंधित करें
- Ops: एनरिचमेंट जॉब्स चलाएँ, कॉन्फ्लिक्ट्स हल करें, मर्ज अप्रूव करें
- Viewer: रिपोर्टिंग और सपोर्ट के लिए केवल-पढ़ने का एक्सेस
परमिशन्स को ग्रैन्युलर रखें (उदा. “export data”, “view PII”, “approve merges”) और एनवायरनमेंट अलग रखें ताकि प्रोडक्शन डेटा dev में उपलब्ध न हो।
संवेदनशील डेटा की सुरक्षा
सभी ट्रैफ़िक के लिए TLS और डेटाबेस/ऑब्जेक्ट स्टोरेज के लिए encryption at rest का उपयोग करें।
API कीज़ को सीक्रेट्स मैनेजर में रखें (source control में env फाइलों में नहीं), उन्हें नियमित रूप से रोटेट करें, और कीज़ को एनवायरनमेंट के अनुसार स्कोप करें।
यदि आप UI में PII दिखाते हैं, तो सुरक्षित डिफ़ॉल्ट जैसे मास्क्ड फ़ील्ड (उदा. अंतिम 2–4 अंक दिखाएँ) और पूर्ण मान दिखाने के लिए स्पष्ट अनुमति आवश्यक रखें।
सहमति और डेटा-उपयोग प्रतिबंध
यदि एनरिचमेंट सहमति या विशेष अनुबंधों पर निर्भर है, उन प्रतिबंधों को वर्कफ़्लो में एन्कोड करें:
- प्रति फ़ील्ड data source, purpose, और allowed uses ट्रैक करें
- आप क्या स्टोर करते हैं और क्यों, यह दस्तावेज़ करें (एक छोटा आंतरिक पॉलिसी पेज जैसे /privacy या /docs/data-handling मददगार है)
- गैर-ज़रूरी फ़ील्ड इकट्ठा करने से बचें — कम डेटा = कम जोखिम
ऑडिटिंग, रिटेंशन, और डिलीशन
एक ऑडिट ट्रेल बनाएँ दोनों एक्सेस और परिवर्तन के लिए:
- किसने रिकॉर्ड देख/एक्सपोर्ट किया यह लॉग करें
- किसने क्या बदला और कब (पहले/बाद के वैल्यू, जॉब ID, एनरिचमेंट प्रदाता) लॉग करें
अंत में, प्राइवेसी अनुरोधों का समर्थन करने के लिए वास्तविक उपकरण दें: रिटेंशन शेड्यूल, रिकॉर्ड डिलीशन, और “भूल जाएँ” वर्कफ़्लोज़ जो लॉग्स, कैशेज़, और बैकअप्स में नकलों को भी जहाँ संभव हो हटाएँ या एक्सपायर के लिये चिह्नित करें।
मॉनिटरिंग, एनालिटिक्स, और ऑपरेशनल कंट्रोल
मॉनिटरिंग सिर्फ़ अपटाइम के लिए नहीं है—यह वह तरीका है जिससे आप बढ़ती मात्रा, प्रदाताओं, और नियमों के साथ एनरिचमेंट पर भरोसा बनाए रखते हैं।
हर एनरिचमेंट रन को एक मापनीय जॉब मानें और ऐसे संकेत रखें जिन्हें आप समय के साथ ट्रेंड कर सकें।
उपयोगी मीट्रिक्स
छोटे सेट से शुरू करें जो आउट्कम्स से जुड़े हों:
- Job throughput (records/min) और प्रति रन time-to-complete
- Success rate बनाम failure rate, failure प्रकारों (validation, matching, provider) में विभाजित
- Provider latency (p50/p95) और प्रत्येक स्रोत के लिए टाइमआउट्स
- Match rate (कितनी बार आप भरोसेमंद तरीके से एनरिच जोड़ते हैं)
- Duplicates prevented (बिना चेक के कितने गलत मर्ज होने से रोके गए)
ये संख्याएँ जल्दी बताएंगी: “क्या हम डेटा सुधार रहे हैं, या बस उसे इधर-उधर खिसका रहे हैं?”
अलर्ट्स और गार्डरेल्स
परिवर्तन पर ट्रिगर होने वाले अलर्ट जोड़ें, न कि शोर पर:
- फेल्यर या क्वारंटीन रिकॉर्ड्स में स्पाइक
- क्यू बैकलॉग या धीमे कन्ज़्यूमर्स (संकेत कि पाइपलाइन अटक गई है)
- प्रदाता एरर बर्स्ट (429/5xx), बढ़ी हुई लेटेंसी, या टाइमआउट्स
अलर्ट्स को ऐसे क्रियाओं से जोड़ें जो ठोस हों, जैसे किसी प्रदाता को पॉज़ करना, concurrency घटाना, या कैश/स्टेल डेटा की ओर स्विच करना।
ऑपरेटर्स के लिए एडमिन डैशबोर्ड
संदर्भ के लिए हाल के रन की स्थिति: स्टेटस, काउंट्स, retries, और quarantined records की सूची कारणों के साथ दें।
“रिप्ले” कंट्रोल्स और सुरक्षित बुल्क एक्शन्स (सभी provider timeouts को रीट्राय करें, केवल म्याचिंग को फिर चलाएँ) शामिल करें।
ट्रैसेबिलिटी के लिए लॉग्स
Structured logs और एक correlation ID का उपयोग करें जो एक रिकॉर्ड को end-to-end फॉलो करे (ingestion → match → enrichment → merge)।
यह कस्टमर सपोर्ट और इनसिडेंट डिबग को बहुत तेज़ बना देता है।
इनसिडेंट प्लेबुक्स और रोलबैक
छोटी प्लेबुक्स लिखें: प्रदाता degrade होने पर क्या करें, match rate गिरने पर क्या करें, या जब डुप्लिकेट्स निकल जाएँ तो क्या करें।
एक रोलबैक विकल्प रखें (उदा. एक टाइम विंडो के लिए मर्जेस को revert करना) और इसे /runbooks पर दस्तावेज़ करें।
टेस्टिंग, रोलआउट, और इटरेशन प्लान
टेस्टिंग और रोलआउट वह जगह हैं जहाँ एनरिचमेंट ऐप भरोसेमंद बनता है। लक्ष्य ‘और अधिक टेस्ट’ नहीं बल्कि यह विश्वास है कि मिलान, मर्ज, और वैलिडेशन असली दुनिया के गंदे डेटा में पूर्वानुमेय तरीके से काम करेंगे।
जोखिम भरे हिस्सों का पहले परीक्षण करें
उन लॉजिक पर टेस्ट को प्राथमिकता दें जो रिकॉर्ड्स को चुपचाप नुकसान पहुँचा सकती हैं:
- Matching rules: exact, fuzzy, और composite matches के यूनिट टेस्ट (उदा. email + company domain)। near-duplicates और swapped fields शामिल करें।
- Merge outcomes: field precedence (source priority), conflict handling, और “do not overwrite” नियमों के टेस्ट।
- Validation edge cases: malformed emails, अंतरराष्ट्रीय फोन फॉर्मैट, missing country, duplicate identifiers, और “unknown” मान।
सिंथेटिक datasets (जनरेट किए गए नाम, डोमेन्स, पते) का उपयोग करें ताकि वास्तविक ग्राहक डेटा उजागर न हो।
एक versioned “golden set” रखें जिसमें अपेक्षित match/merge आउटपुट हों ताकि regressions स्पष्ट हों।
रोलआउट को चरणबद्ध करें ताकि ब्लास्ट रेडियस घटे
छोटे से शुरू करें, फिर बढ़ाएँ:
- Pilot scope: एक टीम या एक सेगमेंट (उदा. केवल SMB leads)
- Limited actions: पहले “suggested updates” रखें जो CRM में लिखे जाने से पहले अप्रूवल मांगें
- Ramp up: रिकॉर्ड वॉल्यूम बढ़ाएं, फिर लो-रिस्क फ़ील्ड्स के लिए automated writes चालू करें
शुरू करने से पहले सफलता मीट्रिक्स परिभाषित करें (match precision, approval rate, मैन्युअल एडिट्स में कमी, और time-to-enrich)।
वर्कफ़्लोज़ और इंटीग्रेशन चेकलिस्ट दस्तावेज़ करें
उपयोगकर्ताओं और इंटीग्रेटर्स के लिए छोटे दस्तावेज़ बनाएं (अपने प्रोडक्ट एरिया या /pricing से लिंक करें यदि आप फीचर्स को गेट करते हैं)। एक इंटीग्रेशन चेकलिस्ट में शामिल करें:
- API auth method, rate limits, और retry व्यवहार
- एनरिचमेंट रिक्वेस्ट्स के लिए आवश्यक फ़ील्ड्स
- वेबहुक/इवेंट पेलोड्स (और वर्जनिंग)
- एरर कोड्स और “partial enrichment” नियम
- ऑडिट लॉग अपेक्षाएँ और डेटा रिटेंशन
सुधार के लिए एक हल्का रिव्यू कैडेंस शेड्यूल करें: फेल्ड वैलिडेशन्स, बार-बार मैन्युअल ओवरराइड्स, और mismatches का विश्लेषण करें, फिर नियम अपडेट करें और टेस्ट जोड़ें।
एक व्यावहारिक संदर्भ के लिए: /blog/data-quality-checklist।
बनाना बनाम तेज़ी लाना: व्यावहारिक नोट
यदि आप अपने टारगेट वर्कफ़्लोज़ जानते हैं पर स्पेक से वर्किंग ऐप तक का समय घटाना चाहते हैं, तो Koder.ai का उपयोग करके शुरुआती इम्प्लिमेंटेशन (React UI, Go सर्विसेज, PostgreSQL स्टोरेज) जनरेट करने पर विचार करें।
टीमें अक्सर इस दृष्टिकोण का उपयोग रिव्यू UI, जॉब प्रोसेसिंग, और ऑडिट हिस्ट्री जल्दी खड़ा करने के लिए करती हैं — फिर योजना मोड, स्नैपशॉट्स, और रोलबैक के साथ आवश्यकताओं के बदलने पर इटरेट करती हैं। जब पूर्ण नियंत्रण चाहिए, तो आप सोर्स कोड एक्सपोर्ट कर सकते हैं और अपने मौजूदा पाइपलाइन में आगे बढ़ सकते हैं। Koder.ai मुफ्त, प्रो, बिज़नेस, और एंटरप्राइज़ टियर ऑफ़र करता है, जो एक्सपेरिमेंटेशन बनाम प्रोडक्शन ज़रूरतों को मैच करने में मदद कर सकते हैं।