05 मई 2025·8 मिनट
ग्राहक एस्कलेशन समयरेखा प्रबंधित करने के लिए वेब ऐप बनाएं
ग्राहक एस्कलेशन्स, समय-सीमाएँ, SLA, स्वामित्व और अलर्ट को ट्रैक करने वाला वेब ऐप बनाने की चरणबद्ध योजना — साथ में रिपोर्टिंग और इंटीग्रेशन।
ग्राहक एस्कलेशन्स, समय-सीमाएँ, SLA, स्वामित्व और अलर्ट को ट्रैक करने वाला वेब ऐप बनाने की चरणबद्ध योजना — साथ में रिपोर्टिंग और इंटीग्रेशन।
स्क्रीन डिज़ाइन या टेक स्टैक चुनने से पहले, यह साफ़ करें कि आपकी संस्था में “एस्कलेशन” का क्या मतलब है। क्या यह एक सपोर्ट केस है जो उम्र बढ़ रहा है, कोई इंसिडेंट जो अपटाइम को खतरे में डालता है, किसी प्रमुख खाते की शिकायत, या कोई भी अनुरोध जो गंभीरता सीमा पार कर गया है? अगर अलग- अलग टीमें इस शब्द का अलग मतलब निकालती हैं, तो आपकी ऐप भ्रम को एन्कोड कर देगी।
एक वाक्य में परिभाषा लिखें जिस पर पूरी टीम सहमत हो सके, और कुछ उदाहरण जोड़ें। उदाहरण के लिए: “एक एस्कलेशन वह कोई भी ग्राहक समस्या है जिसे उच्च समर्थन स्तर या प्रबंधन की भागीदारी चाहिए, और जिस पर समय-सीमित प्रतिबद्धता हो।”
साथ ही यह भी परिभाषित करें कि क्या गिना नहीं जाएगा (उदा., रूटीन टिकट, आंतरिक कार्य) ताकि v1 फालतू फीचर से न भर जाए।
सफलता के मानदंड वही होने चाहिए जो आप सुधारना चाहते हैं — सिर्फ़ जो आप बनाना चाहते हैं नहीं। सामान्य मुख्य परिणामों में शामिल हैं:
दिन एक से 2–4 ऐसे मैट्रिक्स चुनें जिन्हें आप ट्रैक कर सकें (उदा., ब्रिच रेट, प्रत्येक एस्कलेशन स्टेज में समय, रीअसाइनमेंट काउंट)।
प्राथमिक उपयोगकर्ताओं (एजेंट, टीम लीड, मैनेजर) और सेकेंडरी स्टेकहोल्डर्स (एकाउंट मैनेजर, इंजीनियरिंग ऑन-कॉल) की सूची बनाएं। हर एक के लिए नोट करें कि उन्हें जल्दी क्या करना है: ओनरशिप लेना, वजह के साथ डेडलाइन बढ़ाना, अगला क्या है देखना, या ग्राहक के लिए स्टेटस संक्षेप करना।
वर्तमान फेलियर मोड्स को ठोस कहानियों के साथ कैप्चर करें: टियरों के बीच मिस्ड हैंडऑफ़, रीअसाइनमेंट के बाद अस्पष्ट ड्यू टाइम, “किसने एक्सटेंशन को अप्रूव किया?” जैसी बहसें।
इन कहानियों का उपयोग करके मस्ट-हैव्स (टाइमलाइन + ओनरशिप + ऑडिटेबिलिटी) और बाद की चीज़ों (एडवांस्ड डैशबोर्ड, जटिल ऑटोमेशन) को अलग करें।
लक्ष्य स्पष्ट होने पर लिखें कि एक एस्कलेशन आपकी टीम के माध्यम से कैसे चलता है। एक साझा वर्कफ़्लो “स्पेशल केस” को असमान हैंडलिंग और मिस्ड SLA में बदलने से रोकता है।
साधारण स्टेज और अनुमत ट्रांज़िशन से शुरू करें:
डॉक्यूमेंट करें कि हर स्टेज का मतलब क्या है (एंट्री क्राइटेरिया) और उससे निकलने के लिए क्या सत्य होना चाहिए (एक्ज़िट क्राइटेरिया). यह “Resolved पर भी ग्राहक का इंतज़ार” जैसी अस्पष्टता से बचाता है।
एस्कलेशन उन नियमों से बनाए जाने चाहिए जिन्हें आप एक वाक्य में समझा सकें। सामान्य ट्रिगर्स में शामिल हैं:
निर्णय लें कि ट्रिगर्स ऑटोमेटिकली एस्कलेशन बनाएँ, एजेंट को सुझाव दें, या अप्रूवल की ज़रूरत हो।
आपकी टाइमलाइन उतनी ही अच्छी है जितने आपके घटनाएँ। न्यूनतम के तौर पर कैप्चर करें:
ओनरशिप चेंज के नियम लिखें: कौन रीअसाइन कर सकता है, कब अप्रूवल ज़रूरी है (उदा., क्रॉस-टीम या वेंडर हैंडऑफ़), और अगर ओनर शिफ्ट पर नहीं है तो क्या होता है।
अंत में, उन डिपेंडेंसियों को मैप करें जो टाइमिंग प्रभावित करती हैं: on-call शेड्यूल, टियर लेवल (T1/T2/T3), और बाहरी वेंडर (उनकी रिस्पॉन्स विंडो सहित)। यह बाद में आपकी टाइमलाइन कैलकुलेशन्स और एस्कलेशन मैट्रिक्स को ड्राइव करेगा।
एक भरोसेमंद एस्कलेशन ऐप ज़्यादातर डेटा समस्या है। अगर टाइमलाइंस, SLA और हिस्ट्री स्पष्ट रूप से मॉडल नहीं होंगे, तो UI और नोटिफिकेशन्स हमेशा "ऑफ" महसूस करेंगे। कोर एंटिटीज़ और उनके रिश्तों को नाम देकर शुरू करें।
न्यूनतम के लिए योजना बनाएं:
हर मिलेस्टोन को एक टाइमर की तरह ट्रीट करें जिसमें:
start_at (जब क्लॉक शुरू होता है)due_at (कम्प्यूटेड डेडलाइन)paused_at / pause_reason (वैकल्पिक)completed_at (जब पूरा हुआ)क्यों एक डेडलाइन मौजूद है (रूल) स्टोर करें, सिर्फ़ कम्प्यूटेड टाइमस्टैम्प नहीं। इससे बाद की डिस्प्यूट्स सुलझाना आसान होगा।
SLA शायद ही कभी “हमेशा” का मतलब रखते हैं। हर SLA पॉलिसी के लिए एक कैलेंडर मॉडल करें: बिज़नेस आवर्स बनाम 24/7, छुट्टियाँ, और क्षेत्र-विशिष्ट शेड्यूल।
डेडलाइन्स सर्वर टाइम (UTC) में कम्प्यूट करें, लेकिन हमेशा केस टाइम ज़ोन (या कस्टमर टाइम ज़ोन) स्टोर करें ताकि UI पर डेडलाइन्स सही दिख सकें और उपयोगकर्ता उन पर सही तरीके से सोच सकें।
शुरू में निर्णय लें:
CASE_CREATED, STATUS_CHANGED, MILESTONE_PAUSED), याकम्प्लायंस और जवाबदेही के लिए इवेंट लॉग को प्राथमिकता दें (भले ही प्रदर्शन के लिए आप "करंट स्टेट" कॉलम रखें)। हर चेंज में रिकॉर्ड होना चाहिए कि किसने, क्या बदला, कब, और स्रोत (UI, API, ऑटोमेशन), साथ में एक कोरिलेशन ID ट्रेसिंग के लिए।
परमिशन वही जगह है जहाँ एस्कलेशन टूल भरोसा जीतते हैं—या साइड स्प्रैडशीट्स के साथ बाईपास हो जाते हैं। जल्दी तय करें कि कौन क्या कर सकता है, और फिर उसे UI, API, और एक्सपोर्ट्स में लगातार लागू करें।
v1 को सरल रखें और रोल्स को हकीकत से मेल कराएँ:
प्रोडक्ट में रोल चेक्स स्पष्ट रखें: कंट्रोल्स को डिसेबल करें बजाय यूज़र्स को एरर पर क्लिक करने देने के।
एस्कलेशन्स अक्सर कई समूहों में फैलते हैं (Tier 1, Tier 2, CSM, incident response)। मल्टी-टीम सपोर्ट के लिए विज़िबिलिटी स्कोपिंग इन डायमेंशन्स से करें:
अच्छा डिफ़ॉल्ट: उपयोगकर्ता उन मामलों तक पहुँच सकें जहाँ वे असाइनी, वॉचर, या ओनिंग टीम के सदस्य हों—प्लस कोई अकाउंट्स जो स्पष्ट रूप से उनके रोल के साथ शेयर किए गए हों।
सभी डेटा हर किसी को दिखाना ठीक नहीं। आम संवेदनशील फ़ील्ड्स: कस्टमर PII, कॉन्ट्रैक्ट डिटेल्स, और इंटरनल नोट्स। फील्ड-लेवल परमिशन इम्प्लीमेंट करें जैसे:
v1 के लिए ईमेल/पासवर्ड और MFA पर्याप्त होते हैं। यूज़र मॉडल ऐसा डिज़ाइन करें कि बाद में SSO (SAML/OIDC) जोड़ना बिना परमिशन री-राइट के संभव हो: रोल/टीम अंदर स्टोर करें और लॉगिन पर SSO ग्रुप्स को मैप करें।
परमिशन चेंज को ऑडिटेबल एक्शन मानें। इवेंट्स रिकॉर्ड करें जैसे रोल अपडेट, टीम रीअसाइनमेंट, एक्सपोर्ट डाउनलोड और कॉन्फ़िग एडिट—किसने किया, कब, और क्या बदला। यह incidents के दौरान रक्षा करता है और एक्सेस रिव्यूज़ आसान बनाता है।
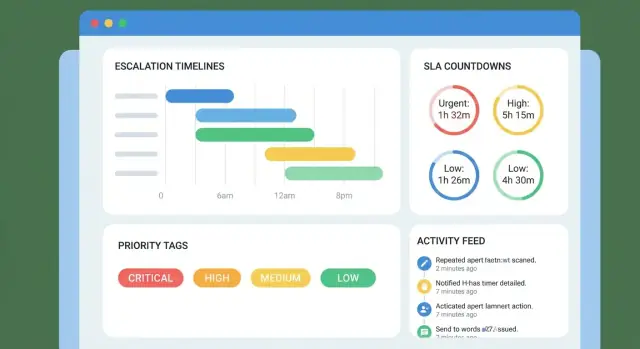
आपकी एस्कलेशन ऐप रोज़मर्रा की स्क्रीन पर ही जीती या हारी जाएगी: सपोर्ट लीड क्या पहली बार देखता है, क्या वे तेज़ी से केस समझ पाते हैं, और क्या अगला डेडलाइन मिस होना असंभव लगती है।
छोटे पेज सेट से शुरू करें जो 90% काम को कवर करें:
नेविगेशन को प्रेडिक्टेबल रखें: लेफ्ट साइडबार या टॉप टैब्स के साथ “Queue”, “My Cases”, “Reports”。क्यू को डिफ़ॉल्ट लैंडिंग पृष्ठ बनाएं।
केस लिस्ट में केवल वे फ़ील्ड दिखाएँ जो किसी को निर्णय लेने में मदद करें। एक अच्छा डिफ़ॉल्ट रो शामिल करता है: कस्टमर, प्राथमिकता, करंट ओनर, स्थिति, नेक्स्ट ड्यू डेट, और एक वार्निंग इंडिकेटर (उदा., “Due in 2h” या “Overdue by 1d”)।
तेज़, व्यावहारिक फ़िल्टर और सर्च जोड़ें:
स्कैनिंग के लिए डिजाइन करें: सुसंगत कॉलम चौड़ियाँ, स्पष्ट स्टेटस चिप्स, और एक हाइलाइट रंग जो केवल urgency के लिए उपयोग हो।
केस व्यू को तुरंत जवाब देना चाहिए:
फास्ट एक्शन्स ऊपर रखें (मेन्यू में छिपाएँ नहीं): Reassign, Escalate, Add milestone, Add note, Set next deadline. हर एक्शन को जो बदला गया उसकी पुष्टि करनी चाहिए और टाइमलाइन को तुरंत अपडेट करना चाहिए।
टाइमलाइन को स्पष्ट अनुक्रम की तरह पढ़नी चाहिए। शामिल करें:
प्रोग्रेसिव डिस्क्लोज़र का उपयोग करें: लेटेस्ट इवेंट्स पहले दिखाएँ, पुराने हिस्ट्री को एक्सपैंड करने का विकल्प दें। अगर आपके पास ऑडिट ट्रेल है, तो टाइमलाइन से लिंक करें (उदा., “View change log”)।
रीडेबल कलर कॉन्ट्रास्ट का उपयोग करें, रंग के साथ टेक्स्ट भी जोड़ें (“Overdue”), सभी एक्शन्स कीबोर्ड से पहुंच योग्य हों, और ऐसे लेबल लिखें जो उपयोगकर्ता भाषा से मेल खाएं (“Set next customer update deadline”, न कि “Update SLA”). ऐसा करने से हाई-प्रेशर स्थितियों में मिस-क्लिक्स कम होंगे।
अलर्ट टाइमलाइन का “हार्टबीट” हैं: ये मामलों को चलाते रहते हैं बिना किसी को डैशबोर्ड घूरने के मजबूर किए। लक्ष्य सरल है—सही व्यक्ति को, सही समय पर, कम से कम नॉइज़ के साथ सूचित करना।
ऐसी छोटी घटनाओं से शुरू करें जो सीधे एक्शन से जुड़ी हों:
v1 के लिए ऐसे चैनल चुनें जिन्हें आप भरोसे के साथ डिलीवर कर सकें और माप सकें:
SMS या चैट बाद में जोड़ें जब नियम और वॉल्यूम स्थिर हो जाएं।
एस्कलेशन को टाइम-बेस्ड थ्रेशहोल्ड के रूप में प्रतिनिधित्व करें जो केस की टाइमलाइन से जुड़ा हो:
मैट्रिक्स को प्राथमिकता/क्यू के अनुसार कॉन्फ़िगरेबल रखें ताकि “P1 incidents” और “billing questions” एक ही पैटर्न न फॉलो करें।
डेडुप्लिकेट (“एक ही अलर्ट दो बार न भेजें”), बैचिंग (समान अलर्ट का डाइजेस्ट), और क्वाइट आवर्स जो नॉन-क्रिटिकल रिमाइंडर्स को डिले कर दें मगर उन्हें लॉग करें—इम्प्लीमेंट करें।
हर अलर्ट को सपोर्ट करें:
इन एक्शन्स को अपने ऑडिट ट्रेल में स्टोर करें ताकि रिपोर्टिंग यह अलग कर सके कि “किसी ने देखा ही नहीं” बनाम “किसी ने देखा और टाल दिया।”
ज्यादातर एस्कलेशन टाइमलाइन ऐप तब फेल होते हैं जब वे लोगों से वही डेटा दोबारा टाइप कराना चाहते हैं जो किसी और जगह पहले से है। v1 के लिए केवल वही इंटीग्रेशन जोड़ें जो टाइमलाइनों को सटीक और नोटिफिकेशन्स को समय पर रखे।
निर्णय लें कि कौन से चैनल एस्कलेशन केस बना/अपडेट कर सकते हैं:
इनबाउंड पेलोड छोटे रखें: case ID, customer ID, current status, priority, timestamps, और शॉर्ट समरी।
आपकी ऐप अन्य सिस्टम्स को नोटिफ़ाई करनी चाहिए जब कुछ महत्वपूर्ण हो:
वेबहुक्स के साथ साइन किए गए रिक्वेस्ट और इवेंट ID का उपयोग करें डेडुप्लिकेशन के लिए।
अगर आप दोनों दिशाओं में सिंक करते हैं, तो प्रत्येक फील्ड के लिए सोर्स ऑफ़ ट्रुथ घोषित करें (उदा., टिकटिंग टूल स्टेटस का मालिक है; आपकी ऐप SLA टाइमर्स की मालिक है)। कॉन्फ्लिक्ट नियम परिभाषित करें ("last write wins" अक्सर सही नहीं) और बैकऑफ के साथ रिट्राई लॉजिक + डेड-लेट्टर क्यू रखें।
v1 के लिए, कस्टमर्स और कॉन्टैक्ट्स को स्टेबल एक्सटर्नल IDs और न्यूनतम स्कीमा के साथ इंपोर्ट करें: अकाउंट नाम, टियर, की कॉन्टैक्ट्स, और एस्कलेशन प्रेफरेंसेज़। डीप CRM मिररिंग से बचें।
एक छोटी चेकलिस्ट डॉक्यूमेंट करें (auth मेथड, आवश्यक फ़ील्ड्स, रेट लिमिट्स, रिट्राई, टेस्ट एनवायरनमेंट)। एक मिनिमल API कॉन्ट्रैक्ट प्रकाशित करें (यहाँ तक कि एक-पेज स्पेस) और इसे वर्शन करें ताकि इंटीग्रेशन अचानक टूटें नहीं।
आपका बैकएंड दो चीज़ें अच्छी तरह से करना चाहिए: एस्कलेशन टाइमिंग को सटीक रखना, और केस वॉल्यूम बढ़ने पर भी तेज़ रहना।
उस सरल आर्किटेक्चर का चयन करें जिसे आपकी टीम मेंटेन कर सके। एक क्लासिक MVC ऐप REST API के साथ v1 के लिए अक्सर काफी है। अगर आप पहले से GraphQL अच्छी तरह इस्तेमाल कर रहे हैं, तो वह भी काम कर सकता है—पर केवल इसलिए जोड़े नहीं कि यह नया है। इसे एक मैनेज्ड डेटाबेस (उदा., Postgres) के साथ पेयर करें ताकि आप डेटाबेस ऑप्स पर नहीं बल्कि एस्कलेशन लॉजिक पर समय खर्च करें।
अगर आप वर्कफ़्लो को एंड-टू-एंड वेलिडेट करना चाहते हैं इससे पहले कि आप हफ्तों की इंजीनियरिंग में जुटें, एक प्रोटोटाइप प्लेटफ़ॉर्म जैसे Koder.ai आपकी मदद कर सकता है मूल लूप (queue → case detail → timeline → notifications) को जल्दी प्रोटोटाइप करने में, और जब आप तैयार हों तो सोर्स कोड एक्सपोर्ट कर दे। इसका डिफ़ॉल्ट स्टैक (React वेब पर, Go + PostgreSQL बैकएंड) ऐसे ऑडिट-हेवी ऐप के लिए व्यावहारिक है।
एस्कलेशन्स शेड्यूल्ड वर्क पर निर्भर करते हैं, इसलिए आपको बैकग्राउंड प्रोसेसिंग चाहिए:
जॉब्स को idempotent और retryable बनाएं। केस/टाइमलाइन पर "last evaluated at" टाइमस्टैम्प स्टोर करें ताकि डुप्लिकेट एक्शन्स से बचा जा सके।
सभी टाइमस्टैम्प UTC में स्टोर करें। UI/API बाउंड्री पर ही यूज़र के टाइम ज़ोन में कन्वर्ट करें। एज-केस टेस्ट लिखें: DST, लीप दिवस, और "paused" क्लॉक्स जैसी स्थितियाँ।
क्यूज़ और ऑडिट ट्रेल व्यूज़ के लिए पेजिनेशन का उपयोग करें। अपने फ़िल्टर्स और सॉर्ट के अनुरूप इंडेक्स जोड़ें—आमतौर से (due_at), (status), (owner_id), और कंपोज़िट्स जैसे (status, due_at)।
फ़ाइल स्टोरेज को DB से अलग रखें: साइज/टाइप लिमिट लागू करें, अपलोड स्कैन करें (या प्रोवайडर इंटीग्रेशन का उपयोग करें), और रिटेंशन नियम सेट करें (उदा., 12 महीने बाद डिलीट जब तक लीगल होल न हो)। केस मैनेजमेंट टेबल्स में मैटाडेटा रखें; फ़ाइल ऑब्जेक्ट स्टोरेज में रखें।
रिपोर्टिंग वह जगह है जहाँ आपकी ऐप साधारण साझा इनबॉक्स से मैनेजमेंट टूल बन जाती है। v1 के लिए, एक सिंगल रिपोर्टिंग पेज लक्ष्य रखें जो दो सवालों का जवाब दे: “क्या हम SLAs पूरा कर रहे हैं?” और “एस्कलेशन्स कहाँ फंस रहे हैं?” इसे सरल, तेज और सभी की परिभाषाओं पर आधारित रखें।
रिपोर्ट तभी भरोसेमंद है जब नीचे की परिभाषाएँ भरोसेमंद हों। इन्हें सरल भाषा में लिखें और अपने डेटा मॉडल में मिरर करें:
यह भी तय करें कि आप कौन सा SLA क्लॉक रिपोर्ट कर रहे हैं: first response, next update, या resolution (या तीनों)।
आपका डैशबोर्ड हल्का पर एक्शन योग्य हो सकता है:
डे-टू-डे लोड बैलेंसिंग के लिए ऑपरेशनल व्यू जोड़ें:
CSV एक्सपोर्ट आमतौर पर v1 के लिए पर्याप्त है। एक्सपोर्ट को परमिशन्स से बाँधें (टीम-आधारित एक्सेस, रोल चेक्स) और हर एक्सपोर्ट के लिए एक ऑडिट लॉग एंट्री बनाएं (किसने, कब, फ़िल्टर्स क्या थे, कितनी रोज़)। यह “मिस्ट्री स्प्रैडशीट्स” को रोकता है और कम्प्लायंस सपोर्ट करता है।
पहला रिपोर्टिंग पेज जल्दी शिप करें, फिर सपोर्ट लीड्स के साथ वीकली एक महीना रिव्यू करें। गायब फ़िल्टर्स, भ्रमित परिभाषाएँ, और “मैं X का जवाब नहीं दे सकता” क्षणों पर फ़ीडबैक लें—ये ही v2 के सर्वश्रेष्ठ इनपुट हैं।
एस्कलेशन-टाइमलाइन ऐप का परीक्षण सिर्फ़ “क्या यह काम करता है?” नहीं है—बल्कि यह है “कठोर परिस्थितियों में यह वैसा व्यवहार करता है जैसा समर्थन टीमें अपेक्षित हैं?” वास्तविक परिदृश्यों पर ध्यान दें जो आपकी टाइमलाइन नियमों, नोटिफिकेशन्स, और केस हैंडऑफ़्स को तनाव दें।
अपना अधिकतर टेस्ट प्रयास टाइमलाइन कैलकुलेशन्स पर लगाएँ, क्योंकि यहाँ छोटी गलती बड़ी SLA विवाद बना देती है।
बिज़नेस-ऑवर्स काउंटिंग, छुट्टियाँ, और टाइम ज़ोन्स जैसे मामलों को कवर करें। pauses (ग्राहक प्रतीक्षा, इंजीनियरिंग पेंडिंग), प्रायोरिटी बदलाव बीच में, और ऐसे एस्कलेशन टेस्ट करें जो टार्गेट रिस्पॉन्स/रिज़ॉल्व टाइम बदल दें। एज केस के लिए टेस्ट जोड़ें: क्लोज़िंग से ठीक पहले बनाया गया केस, या pause जो ठीक SLA बॉउंडरी पर शुरू हो।
नोटिफिकेशन्स अक्सर सिस्टम्स के बीच के गैप में फेल होते हैं। इंटीग्रेशन टेस्ट लिखें जो सत्यापित करें:
अगर आप ईमेल, चैट, या वेबहुक का उपयोग करते हैं, तो केवल यह न जांचें कि “कुछ भेजा गया” — पेलोड और टाइमिंग का भी सत्यापन करें।
रीअलिस्टिक सैंपल डेटा बनाएं जो UX प्रॉब्लम्स को जल्दी दिखाए: VIP ग्राहकों, लंबे चलने वाले केस, बार-बार रीअसाइनमेंट, रीओपन्ड इंसिडेंट्स, और “हॉट” पीरियड्स में क्यू स्पाइक्स। इससे आप वेरिफाई कर पाएँगे कि क्यूज़, केस व्यू और टाइमलाइन बिना स्पष्टीकरण के पढ़ने योग्य हैं।
1–2 हफ्तों के लिए एक टीम के साथ पायलट चलाएँ। रोज़ाना इश्यूज़ कलेक्ट करें: गायब फ़ील्ड्स, भ्रमित लेबल्स, नोटिफिकेशन नॉइज़, और आपकी टाइमलाइन नियमों के अपवाद।
उन्हें ट्रैक करें जो यूज़र्स ऐप के बाहर करते हैं (स्प्रैडशीट्स, साइड चैनल्स) ताकि गैप्स दिखें।
लॉन्च से पहले लिखें कि “किया हुआ” क्या मायने रखता है: प्रमुख SLA मैट्रिक्स उम्मीद के मुताबिक मेल खाते हों, क्रिटिकल नोटिफिकेशन्स भरोसेमंद हों, ऑडिट ट्रेल्स पूरे हों, और पायलट टीम बिना वर्कअराउंड के एस्कलेशन्स एन्ड-टू-एंड चला सके।
पहली वर्जन शिप करना अंत रेखा नहीं है। एस्कलेशन टाइमलाइन ऐप तब "रियल" बनता है जब यह रोज़मर्रा की फेल्योर-सिचुएशन्स में टिक सके: मिस्ड जॉब्स, स्लो क्वेरीज, गलत कॉन्फ़िगर्ड नोटिफिकेशन्स, और SLA नियमों में inevitable बदलाव। डिप्लॉयमेंट और ऑपरेशन्स को प्रोडक्ट का हिस्सा समझें।
रिलीज़ प्रोसेस को नीरस और रिपीटेबल रखें। न्यूनतम के तौर पर डॉक्यूमेंट और ऑटोमेट करें:
अगर आपके पास स्टेजिंग है, तो उसे रियलिस्टिक (सैनिटाइज़्ड) डेटा से सीड करें ताकि टाइमलाइन बिहेवियर और नोटिफिकेशन्स प्रोडक्शन से पहले वेरिफ़ाई हो सकें।
पारंपरिक अपटाइम चेक्स सबसे बुरी समस्याओं को पकड़ते नहीं। उन जगहों पर मॉनिटरिंग जोड़ें जहाँ एस्कलेशन्स चुपचाप टूट सकती हैं:
एक छोटा ऑन-कॉल प्लेबुक बनाएं: “अगर एस्कलेशन रिमाइंडर्स नहीं भेज रहे, तो A → B → C चेक करें।” इससे हाई-प्रेशर घटनाओं में डाउनटाइम कम होगा।
एस्कलेशन डेटा में अक्सर कस्टमर नेम्स, ईमेल्स, और संवेदनशील नोट्स होते हैं। नीतियाँ पहले तय करें:
रिटेंशन को कॉन्फ़िगरेबल रखें ताकि पॉलिसी अपडेट करने के लिए कोड बदलने की ज़रूरत न पड़े।
v1 में भी एडमिन्स को सिस्टम हेल्दी रखने के तरीके चाहिए:
छोटे, टास्क-आधारित डॉक्स लिखें: “एक एस्कलेशन बनाएं”, “टाइमलाइन पॉज़ करें”, “SLA ओवरराइड करें”, “किसने क्या बदला इसका ऑडिट देखें।”
इन-ऐप एक लाइटवेट ऑनबोर्डिंग फ्लो जोड़ें जो यूज़र्स को क्यूज़, केस व्यू, और टाइमलाइन एक्शन्स तक गाइड करे, साथ में /help पेज का लिंक दें।
v1 कोर लूप साबित करना चाहिए: एक केस की स्पष्ट टाइमलाइन हो, SLA क्लॉक voorspelbaar चले, और सही लोग नोटिफ़ाई हों। v2 तब पावर जोड़ सकता है बिना v1 को एक जटिल “सब कुछ” सिस्टम में बदल दिए। ट्रिक यह है कि एक छोटा, स्पष्ट बॅकलॉग रखें और केवल वास्तविक उपयोग पैटर्न देखने के बाद ही चीज़ें जोड़ें।
एक अच्छा v2 आइटम वह होना चाहिए जो (a) बड़े पैमाने पर मैन्युअल काम घटाए, या (b) महंगे गलतियों को रोके। अगर यह मुख्यतः कॉन्फ़िगरेशन विकल्प जोड़ता है, तो तब तक पार्क करें जब तक कई टीमें वाकई में उसकी ज़रूरत न देखें।
ग्राहक-वार SLA कैलेंडर्स अक्सर पहली सार्थक विस्तृतता होते हैं: अलग बिज़नेस आवर्स, छुट्टियाँ, या कॉन्ट्रैक्चुअल रिस्पॉन्स टाइम।
अगला, प्लेबुक्स और टेम्पलेट्स जोड़ें: प्री-बिल्ट एस्कलेशन स्टेप्स, सुझाए गए स्टेकहोल्डर्स, और संदेश ड्राफ्ट जो रिस्पॉन्स को सुसंगत बनाएं।
जब असाइनमेंट बोतल-नेक बन जाए, तो स्किल-बेस्ड राउटिंग और ऑन-कॉल शेड्यूल पर विचार करें। पहले संस्करण में इसे सरल रखें: सीमित स्किल सेट, डिफ़ॉल्ट फॉलबैक ओनर, और स्पष्ट ओवरराइड कंट्रोल्स।
ऑटो-एस्कलेशन कुछ सिग्नलों पर ट्रिगर हो सकती है (severity changes, keywords, sentiment, repeat contacts)। पहले “सुझावित एस्कलेशन” (प्रॉम्प्ट) से शुरू करें बजाय “ऑटोमैटिक एस्कलेशन” के, और हर ट्रिगर कारण को लॉग करें ताकि विश्वास और ऑडिटेबिलिटी बनी रहे।
एस्कलेशन से पहले आवश्यक फ़ील्ड्स जोड़ें (इम्पैक्ट, severity, customer tier) और हाई-सीवेरिटी एस्कलेशन्स के लिए अप्रूवल स्टेप्स रखें। इससे नॉइज़ कम होगी और रिपोर्टिंग सटीक रहेगी।
अगर आप ऑटोमेशन पैटर्न एक्सप्लोर करना चाहते हैं उससे पहले कि आप उन्हें बनाएं, देखें /blog/workflow-automation-basics। अगर आप पैकेजिंग को अलाइन कर रहे हैं, तो यह जाँचें कि फीचर्स कैसे टियर्स से मैप होते हैं: /pricing।
Start with a one-sentence definition everyone agrees on (plus a few examples). Include explicit non-examples (routine tickets, internal tasks) so v1 doesn’t turn into a general ticketing system.
Then write 2–4 success metrics you can measure immediately, like SLA breach rate, time in each stage, or reassignment count.
Pick outcomes that reflect operational improvement, not feature completion. Practical v1 metrics include:
Choose a small set you can compute from day-one timestamps.
Use a small shared set of stages with clear entry/exit criteria, such as:
Write what must be true to enter and to leave each stage. This prevents ambiguity like “Resolved but still waiting on customer.”
Capture the minimum events needed to reconstruct the timeline and defend SLA decisions:
If you can’t explain how a timestamp is used, don’t collect it in v1.
Model each milestone as a timer with:
start_atdue_at (computed)paused_at and pause_reason (optional)completed_atAlso store the rule that produced (policy + calendar + reason). That makes audits and disputes far easier than storing only the final deadline.
Store timestamps in UTC, but keep a case/customer time zone for display and user reasoning. Model SLA calendars explicitly (24/7 vs business hours, holidays, region schedules).
Test edge cases like daylight saving changes, cases created near business close, and “pause starts exactly at the boundary.”
Keep v1 roles simple and aligned with real workflows:
Add scoping rules (team/region/account) and field-level controls for sensitive data like internal notes and PII.
Design the “everyday” screens first:
Optimize for scanning and reduce context switching—fast actions should not be buried in menus.
Start with a small set of high-signal notifications:
Pick 1–2 channels for v1 (usually in-app + email), then add an escalation matrix with clear thresholds (T–2h, T–0h, T+1h). Prevent fatigue with dedupe, batching, and quiet hours, and make acknowledge/snooze auditable.
Integrate only what keeps timelines accurate:
If you do two-way sync, define a source of truth per field and conflict rules (avoid “last write wins”). Publish a minimal versioned API contract so integrations don’t break. For more on automation patterns, see /blog/workflow-automation-basics; for packaging considerations, see /pricing.
due_at