29 नव॰ 2025·8 मिनट
ग्राहक फीडबैक लूप प्रबंधित करने के लिए वेब ऐप कैसे बनाएं
सीखें कि कैसे एक वेब ऐप डिजाइन और बनाएं जो ग्राहक फीडबैक को इकट्ठा, रूट, ट्रैक और क्लोज कर सके—स्पष्ट वर्कफ़्लो, भूमिकाएँ और मीट्रिक्स के साथ।
सीखें कि कैसे एक वेब ऐप डिजाइन और बनाएं जो ग्राहक फीडबैक को इकट्ठा, रूट, ट्रैक और क्लोज कर सके—स्पष्ट वर्कफ़्लो, भूमिकाएँ और मीट्रिक्स के साथ।
एक फीडबैक प्रबंधन ऐप सिर्फ "संदेशों को रखने की जगह" नहीं है। यह एक सिस्टम है जो आपकी टीम को भरोसेमंद तरीके से इनपुट → कार्रवाई → ग्राहक‑दिखने वाला फॉलो‑अप और फिर सीखने तक पहुँचने में मदद करता है।
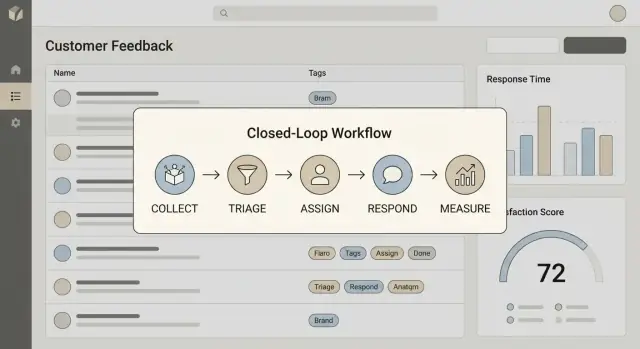
अपनी टीम के लिए एक वाक्य में परिभाषा लिखें जिसे वे दोहरा सकें। अधिकांश टीमों के लिए, लूप बंद करने में चार चरण शामिल होते हैं:
इनमें से कोई भी कदम गायब हुआ, तो आपका ऐप बैकलॉग कब्रिस्तान बन जाएगा।
आपका पहला संस्करण वास्तविक दिन‑प्रतिदिन की भूमिकाओं को सेवा दे:
"एक क्लिक पर निर्णय" के बारे में विशिष्ट रहें:
कुछ छोटे मीट्रिक्स चुनें जो गति और गुणवत्ता को दर्शाते हैं, जैसे time to first response, resolution rate, और CSAT बदलाव follow‑up के बाद। ये बाद के डिज़ाइन चुनावों के लिए आपकी नॉर्थ‑स्टार बनेंगे।
स्क्रीन डिज़ाइन या डेटाबेस चुनने से पहले, मैप करें कि फीडबैक बनते ही उससे क्या होता है जब तक आप उत्तर नहीं दे देते। एक सरल जर्नी मैप टीमों को "पूर्ण" का अर्थ समझने में संरेखित रखता है और ऐसी विशेषताएँ बनाने से रोकता है जो असली काम में फिट नहीं बैठतीं।
अपने फीडबैक स्रोतों की सूची बनाएं और नोट करें कि प्रत्येक क्या डेटा नियमित रूप से देता है:
हालाँकि इनपुट्स अलग हैं, आपका ऐप उन्हें एक सुसंगत "feedback item" आकार में सामान्यीकृत करना चाहिए ताकि टीमें सब कुछ एक ही जगह में ट्रायेज़ कर सकें।
एक व्यावहारिक पहला मॉडल आमतौर पर शामिल करता है:
शुरुआत के लिए स्टेटस: New → Triaged → Planned → In Progress → Shipped → Closed. स्टेटस के अर्थ लिखकर रखें ताकि "Planned" किसी टीम के लिए "Maybe" और किसी के लिए "Committed" न बन जाए।
डुप्लिकेट अनिवार्य हैं। नियम पहले से परिभाषित करें:
सामान्य तरीका है एक canonical feedback item रखना और अन्य को डुप्लिकेट के रूप में लिंक करना, attribution (किसने पूछा) बनाए रखते हुए ताकि काम का विखंडन न हो।
एक फीडबैक लूप ऐप की सफलता पहले दिन ही इस पर निर्भर करती है कि लोग कितनी तेज़ी से फीडबैक प्रोसेस कर पाते हैं। लक्ष्य एक ऐसा फ्लो बनाना है जो महसूस हो: “scan → decide → move on,” और अभी भी बाद के निर्णयों के लिए संदर्भ बनाए रखे।
आपका इनबॉक्स टीम की साझा कतार है। यह शक्तिशाली, कम फ़िल्टरों के सेट के माध्यम से तेज़ ट्रायज का समर्थन करना चाहिए:
जल्दी ही “Saved views” जोड़ें (भले ही बेसिक हों), क्योंकि अलग‑अलग टीमें अलग तरह से स्कैन करती हैं: Support चाहता है “urgent + paying,” Product चाहता है “feature requests + high ARR.”
जब कोई यूज़र एक आइटम खोलता है, उसे दिखना चाहिए:
लक्ष्य यह है कि कोई टैब बदलने की ज़रूरत न पड़े सिर्फ यह जानने के लिए: “यह कौन है, उन्होंने क्या कहा, और क्या हमने पहले ही जवाब दिया?”
Detail view से, ट्रायज एक क्लिक पर निर्णय होना चाहिए:
आपको दो मोड की ज़रूरत पड़ सकती है:
जो भी चुनें, “reply with context” को अंतिम कदम बनाइए—ताकि लूप बंद करना वर्कफ़्लो का हिस्सा हो, बाद का काम न बने।
फीडबैक ऐप जल्दी ही रिकॉर्ड का साझा सिस्टम बन जाता है: प्रोडक्ट थीम चाहता है, सपोर्ट तेज़ रिप्लाई चाहता है, और लीडरशिप एक्सपोर्ट्स मांगती है। अगर आप यह परिभाषित नहीं करते कि कौन क्या कर सकता है (और क्या हुआ इसकी प्रमाणिकता), तो भरोसा टूट जाता है।
अगर आप कई कंपनियों को सर्व करेंगे, तो पहले दिन से ही हर वर्कस्पेस/ऑर्ग को एक कड़ी सीमा मानें। हर कोर रिकॉर्ड (feedback item, customer, conversation, tags, reports) में workspace_id होना चाहिए, और हर क्वेरी को उसके हिसाब से स्कोप किया जाना चाहिए।
यह सिर्फ डेटाबेस का मामला नहीं है—यह URLs, इनविटेशन और analytics को प्रभावित करता है। एक सुरक्षित डिफ़ॉल्ट: उपयोगकर्ता एक या अधिक वर्कस्पेस के सदस्य हों, और उनकी परमिशन्स प्रति‑वर्कस्पेस जांची जाएँ।
पहले वर्ज़न को साधारण रखें:
फिर परमिशन्स को क्रियाओं से मैप करें, ना कि स्क्रीन से: view vs. edit feedback, merge duplicates, change status, export data, और send replies. इससे बाद में "Read‑only" रोल जोड़ना सरल रहता है।
"किसने इसे बदला?" वाद‑विवाद रोकने के लिए ऑडिट लॉग रखें। प्रमुख इवेंट्स लॉग करें actor, timestamp और before/after स्टेट के साथ जहाँ उपयोगी हो:
उचित पासवर्ड नीति लागू करें, endpoints को rate limiting से सुरक्षित रखें (विशेषकर login और ingestion), और सेशन हैंडलिंग सुरक्षित रखें।
SSO (SAML/OIDC) के साथ डिज़ाइन करें भले ही बाद में शिप करें: identity provider ID स्टोर करें और account linking की योजना रखें—यह एंटरप्राइज़ अनुरोधों को बाद में पकड़ने में मदद करेगा।
शुरुआत में सबसे बड़ा आर्किटेक्चर जोखिम "क्या यह स्केल करेगा?" नहीं बल्कि "क्या हम इसे जल्दी बदल पाएँगे बिना चीज़ें तोड़े?" है। फीडबैक ऐप तेजी से विकसित होता है क्योंकि आप सीखते हैं कि टीमें वाकई में कैसे ट्रायज, रूट और रिप्लाई करती हैं।
एक मॉड्यूलर मोनोलिथ अक्सर सबसे अच्छा पहला विकल्प है। आपको एक deployable सर्विस, एक लॉग सेट, और सरल डिबगिंग मिलती है—फिर भी कोडबेस संगठित रहे।
एक व्यवहारिक मॉड्यूल स्प्लिट:
"अलग फोल्डर्स और इंटरफ़ेसेस" को "अलग सर्विसेस" से पहले सोचें। अगर कोई सीमा बाद में दर्ददेह हो (जैसे ingestion वॉल्यूम), तो उसे कम दर्द में एक्सट्रैक्ट किया जा सकता है।
ऐसे फ्रेमवर्क और लाइब्रेरी चुनें जिन्हें आपकी टीम भरोसे के साथ शिप कर सके। एक साधारण, प्रसिद्ध स्टैक अक्सर जीतता है क्योंकि:
नवीन टूलिंग तब तक टालें जब तक असली बाध्यता न आए (उच्च ingestion rate, सख्त latency)। तब तक क्लैरिटी और steady delivery पर ऑप्टिमाइज़ करें।
अधिकांश कोर एंटिटीज़—feedback items, customers, accounts, tags, assignments—रिलेशनल डेटाबेस में अच्छी तरह फिट होती हैं। वर्कफ़्लो परिवर्तन के लिए अच्छी क्वेरीइंग, constraints और ट्रांज़ैक्शंस चाहिए।
यदि फुल‑टेक्स्ट सर्च और फिल्टर महत्वपूर्ण हो जाएं, तो बाद में समर्पित सर्च इंडेक्स जोड़ें (या पहले बिल्ट‑इन क्षमताओं का उपयोग करें)। बहुत जल्द दो स्रोतों को सच मानने से बचें।
फीडबैक सिस्टम जल्दी ही "बाद में करें" वाले काम इकट्ठा कर लेता है: ईमेल रिप्लाई भेजना, integrations सिंक करना, अटैचमेंट प्रोसेस करना, डाइजेस्ट जनरेट करना, वेबहुक फायर करना। शुरू से ही इन्हें queue/background worker में रखें।
यह UI को प्रतिक्रियाशील रखता है, टाइमआउट घटाते हैं, और फेल्योर को retryable बनाता है—बिना पहले दिन माइक्रोसर्विसेस पर जाने के।
अगर आपका लक्ष्य वर्कफ़्लो और UI जल्दी वैलिडेट करना है (inbox → triage → replies), तो Koder.ai जैसे वाइब‑कोडिंग प्लेटफ़ॉर्म का उपयोग करके संरचित चैट स्पेक से पहला वर्शन जनरेट करने पर विचार करें। यह React फ्रंट‑एंड के साथ Go + PostgreSQL बैकएंड खड़ा करने में मदद कर सकता है, "planning mode" में iterate करने में सहायक हो सकता है, और जब आप क्लासिक इंजीनियरिंग वर्कफ़्लो अपनाना चाहें तब स्रोत कोड export कर देता है।
आपकी स्टोरेज लेयर तय करती है कि आपकी फीडबैक लूप तेज़ और भरोसेमंद लगेगी—या धीमी और भ्रमित। एक ऐसा स्कीमा रखें जो दैनिक काम (triage, assignment, status) के लिए आसान क्वेरी करने लायक हो, और फिर भी पर्याप्त कच्चा विवरण ऑडिट के लिए संरक्षित करे।
MVP के लिए, आप कुछ तालिकाओं/कलेक्शंस से अधिकांश ज़रूरतें पूरा कर सकते हैं:
एक उपयोगी नियम: feedback को हल्का रखें (जिसे आप लगातार क्वेरी करते हैं) और "बाकी सब" events और चैनल‑विशिष्ट मेटाडेटा में रख दें।
जब टिकट ईमेल, चैट, या वेबहुक के माध्यम से आता है, तो प्राप्त raw incoming payload को ठीक वैसे ही स्टोर करें जैसा मिला (उदाहरण: मूल ईमेल हेडर + बॉडी, या webhook JSON)। इससे आप:
सामान्य पैटर्न: एक ingestions तालिका जिसमें source, received_at, raw_payload (JSON/text/blob), और बनाये/अपडेट किये गए feedback_id का लिंक हो।
अधिकांश स्क्रीन कुछ पूर्वानुमेय फ़िल्टर पर टिकती हैं। जल्दी ही इन पर इंडेक्स जोड़ें:
(workspace_id, status) inbox/kanban दृश्यों के लिए(workspace_id, assigned_to) “मेरे आइटम” के लिए(workspace_id, created_at) सॉर्टिंग और डेट फिल्टर के लिए(tag_id, feedback_id) या समर्पित टैग लुकअप इंडेक्सयदि आप फुल‑टेक्स्ट सर्च सपोर्ट करते हैं, तो एक अलग सर्च इंडेक्स पर विचार करें न कि प्रोडक्शन में जटिल LIKE क्वेरीज डालें।
फीडबैक में अक्सर व्यक्तिगत डेटा होता है। पहले से तय करें:
रिटेंशन को प्रति‑वर्कस्पेस पॉलिसी बनाकर लागू करें (जैसे 90/180/365 दिन) और शेड्यूल्ड जॉब के साथ उसे प्रवर्तित करें जो पहले raw ingestions समाप्त करे, फिर आवश्यक होने पर पुराने events/replies हटाये।
Ingestion वह जगह है जहाँ आपकी कस्टमर फीडबैक लूप या तो साफ़ और उपयोगी रहती है—या गन्दा ढेर बन जाती है। लक्ष्य "आसान भेजना, प्रोसेस में सुसंगत" रखें। पहले उन चैनलों से शुरू करें जो ग्राहक पहले ही इस्तेमाल करते हैं, फिर विस्तार करें।
एक व्यावहारिक पहला सेट आमतौर पर शामिल है:
पहले दिन भारी‑भरकम फिल्टरिंग की ज़रूरत नहीं है, पर बुनियादी सुरक्षा चाहिए:
हर इवेंट को एक आंतरिक फॉर्मेट में सामान्यीकृत करें जिसमें एक समान फ़ील्ड सेट हो:
दोनों raw payload और normalized record रखें ताकि आप parsing सुधारने पर पुराने डेटा को बिना खोए फिर से प्रोसेस कर सकें।
तुरंत पुष्टि भेजें (email/API/widget जहाँ संभव हो): धन्यवाद कहें, अगला क्या होगा बताएं, और वादे से बचें। उदाहरण: “हम हर संदेश की समीक्षा करते हैं। अगर हमें और जानकारी चाहिए होगी, तो हम जवाब देंगे। हम हर अनुरोध का व्यक्तिगत जवाब नहीं दे पाते, पर आपकी प्रतिक्रिया ट्रैक की जाती है।”
फीडबैक इनबॉक्स तब तक उपयोगी रहता है जब तक टीमें तीन प्रश्न जल्दी से जवाब दे सकें: यह क्या है? इसका मालिक कौन है? यह कितना जरूरी है? ट्रायज वह हिस्सा है जो कच्चे संदेशों को व्यवस्थित कार्य में बदलता है।
फ्रीफ़ॉर्म टैग लचीलापन देते हैं पर जल्द विखंडित कर देते हैं (“login”, “log-in”, “signin”). एक छोटा नियंत्रित टैक्सोनॉमी रखें जो पहले से ही आपकी प्रोडक्ट टीमों के सोच से मेल खाती हो:
उपयोगकर्ताओं को नए टैग सुझाव देने दें, पर एक मालिक (उदा., PM/Support lead) से उन्हें अनुमोदित कराना आवश्यक रखें। इससे बाद में रिपोर्टिंग अर्थपूर्ण रहेगी।
एक सरल नियम इंजन बनाएं जो अनुमानित संकेतों के आधार पर फीडबैक को ऑटोमैटिकली रूट कर सके:
नियमों को पारदर्शी रखें: दिखाएँ “Routed because: Enterprise plan + keyword ‘SSO’.” जब इंसान जांच कर सकेगा, तो वे ऑटोमेशन पर भरोसा करेंगे।
हर आइटम और हर कतार में SLA टाइमर्स जोड़ें:
लिस्ट व्यू में SLA स्टेटस दिखाएँ (“2h left”) और detail पेज पर भी, ताकि urgency पूरी टीम में साझा रहे—किसी व्यक्ति के दिमाग़ में न फँसे।
जब आइटम अटके हों तो एक स्पष्ट पाथ बनाएं: overdue queue, मालिकों को दैनिक डाइजेस्ट, और एक हल्का एस्कलेशन लैडर (Support → Team lead → On-call/Manager). उद्देश्य दबाव नहीं बल्कि महत्वपूर्ण ग्राहक फीडबैक के चुपचाप समाप्त होने को रोकना है।
लूप बंद करना वह जगह है जहाँ फीडबैक प्रबंधन सिस्टम "एक कलेक्शन बॉक्स" होना बंद होता है और भरोसा बनाने का टूल बन जाता है। लक्ष्य सरल है: हर फीडबैक काम से जुड़ा हो सके, और जिन्होंने पूछा उन्हें बताया जा सके—बिना मैन्युअल स्प्रेडशीट्स के।
शुरुआत में एक फीडबैक आइटम को एक या अधिक आंतरिक वर्क ऑब्जेक्ट (bug, task, feature request) से लिंक करने दें। अपना पूरा issue tracker मिमिक करने की कोशिश न करें—हल्के रेफ़रेंस स्टोर करें:
work_type (उदा., issue/task/feature)external_system (उदा., jira, linear, github)external_id और वैकल्पिक external_urlयह आपके डेटा मॉडल को स्थिर रखता है भले ही आप टूल बदलें। साथ ही यह "मुझे यह रिलीज़ से जुड़े सभी ग्राहक फ़ीडबैक दिखाओ" जैसी व्यूज़ सक्षम करता है बिना किसी सिस्टम को स्क्रैप किए।
जब लिंक किया गया काम Shipped (या Done/Released) हो, तो आपका ऐप संबंधित फीडबैक आइटम्स से जुड़े सभी ग्राहकों को नोटिफाई कर सके।
सुरक्षित प्लेसहोल्डर्स (name, product area, summary, release notes link) वाले टेम्पलेट संदेश का उपयोग करें। भेजने से पहले इसे संपादन योग्य रखें ताकि अजीब शब्दावली न हो। अगर आप सार्वजनिक नोट्स रखते हैं, तो उन्हें सापेक्ष पथ से लिंक करें जैसे /releases।
उन चैनलों के माध्यम से सपोर्ट रिप्लाई करें जिन्हें आप विश्वसनीय रूप से भेज सकते हैं:
जो भी चैनल चुनें, हर फीडबैक आइटम के लिए रिप्लाइज को एक ऑडिट‑फ्रेंडली टाइमलाइन में ट्रैक करें: sent_at, channel, author, template_id, और delivery status. अगर ग्राहक रिप्लाई करे, तो इनबाउंड संदेशों को timestamps के साथ स्टोर करें ताकि आपकी टीम साबित कर सके कि लूप वास्तव में बंद हुआ—सिर्फ़ "marked shipped" नहीं।
रिपोर्टिंग तभी उपयोगी है जब वह अगले कदम बदल दे। कुछ व्यूज़ के साथ शुरू करें जिन्हें लोग रोज़ देख सकें, फिर तब बढ़ाएँ जब आपको भरोसा हो कि underlying वर्कफ़्लो डेटा (status, tags, owners, timestamps) सुसंगत है।
ऑपरेशनल डैशबोर्ड से शुरू करें जो रूटिंग और फॉलो‑अप का समर्थन करें:
चार्ट सादे और क्लिक करने योग्य रखें ताकि मैनेजर स्पाइक के वास्तविक आइटम्स में ड्रिल कर सके।
एक “customer 360” पेज जोड़ें जो सपोर्ट और सक्सेस टीमों को संदर्भ के साथ जवाब देने में मदद करे:
यह व्यू डुप्लिकेट प्रश्नों को घटाता है और फॉलो‑अप को जानबूझ कर करने में मदद करता है।
टीमें जल्दी ही एक्सपोर्ट मांगेंगी। प्रदान करें:
हर जगह फ़िल्टरिंग को संगत रखें (उसी टैग नाम, तारीख परिधियाँ, स्टेटस परिभाषाएँ). यह "दो सच्चाइयों" से बचाता है।
ऐसी डैशबोर्ड्स छोड़ दें जो सिर्फ़ सक्रियता नापते हैं (tickets created, tags added). कार्रवाई और प्रतिक्रिया से जुड़े परिणाम मीट्रिक्स चुनें: time to first reply, % आइटम्स जो निर्णय तक पहुँचे, और आवर्ती मुद्दे जिन्हें वास्तव में सुलझाया गया।
फीडबैक लूप तभी काम करता है जब वह उन जगहों पर रहता है जहाँ लोग पहले से समय बिताते हैं। इंटीग्रेशन कॉपी‑पेस्ट कम करते हैं, संदर्भ को काम के पास रखते हैं, और "लूप बंद करना" आदत बनाते हैं न कि एक विशेष परियोजना।
उन सिस्टम्स को प्राथमिकता दें जिनका आपकी टीम संचार, निर्माण, और ग्राहक ट्रैक करने के लिए उपयोग करती है:
पहले वर्ज़न को साधारण रखें: वन‑वे नोटिफिकेशंस + आपके ऐप के लिए डीप‑लिंक, फिर बाद में write‑back एक्शन्स (उदा., Slack से “Assign owner”) जोड़ें।
भले ही आप कुछ नेटिव इंटीग्रेशन ही शिप करें, वेबहुक्स कस्टम कनेक्शन और अंदरूनी टूल्स के लिए रास्ता देते हैं।
छोटे, स्थिर इवेंट सेट की पेशकश करें:
feedback.createdfeedback.updatedfeedback.closedidempotency key, timestamps, tenant/workspace id, और एक न्यूनतम payload + पूर्ण विवरण लाने का URL शामिल करें। यह उपभोक्ताओं को तब तक ना तोड़ता है जब तक आप अपना डेटा मॉडल विकसित करें।
इंटीग्रेशन सामान्य कारणों से फेल होते हैं: revoked tokens, rate limits, नेटवर्क समस्याएँ, schema mismatches.
इसे पहले से डिज़ाइन करें:
यदि आप इसे एक प्रोडक्ट के रूप में पैकेज कर रहे हैं, तो इंटीग्रेशन खरीद के ट्रिगर भी होते हैं। अपने ऐप (और मार्केटिंग साइट) से /pricing और /contact पर स्पष्ट अगले कदम जोड़ें उन टीमों के लिए जो डेमो चाहती हैं या कनेक्ट करने में मदद चाहती हैं।
एक प्रभावी फीडबैक ऐप लॉन्च के बाद "पूरा" नहीं होता—वह किस तरह टीमें वाकई ट्रायज, एक्शन और रिप्लाई करती हैं, उससे आकार लेता है। आपके पहले रिलीज़ का लक्ष्य सरल है: वर्कफ़्लो प्रमाणित करें, मैन्युअल प्रयास घटाएँ, और भरोसेमंद साफ़ डेटा कैप्चर करें।
स्कोप को कड़ा रखें ताकि आप तेज़ी से शिप कर सकें और सीखें। एक व्यावहारिक MVP आमतौर पर शामिल है:
यदि कोई फ़ीचर टीम को end‑to‑end फीडबैक प्रोसेस करने में मदद नहीं कर रहा, तो वह बाद में आ सकता है।
प्रारंभिक उपयोगकर्ता फीचर्स की कमी माफ कर देंगे, पर खोया हुआ फीडबैक या गलत रूटिंग को नहीं। उन जगहों पर परीक्षण पर ध्यान दें जहाँ गलतियाँ महँगी हों:
वर्कफ़्लो पर आत्मविश्वास लक्ष्य रखें, न कि परफ़ेक्ट कवरेज।
एक MVP को भी कुछ "बोरिंग" आवश्यकताएँ चाहिए:
पायलट से शुरू करें: एक टीम, सीमित चैनल्स, और एक स्पष्ट सफलता मीट्रिक (उदा., “90% high‑priority फीडबैक को 2 दिनों में जवाब दें”). साप्ताहिक रूप से friction points जमा करें, फिर अधिक टीमों को आमंत्रित करने से पहले वर्कफ़्लो iterate करें।
उपयोग डेटा को अपने रोडमैप के रूप मेंTreat करें: लोग कहाँ क्लिक करते हैं, कहाँ छोड़ते हैं, कौन‑से टैग अप्रयुक्त हैं, और कौन‑सी वर्कअराउंड असली आवश्यकताओं का खुलासा करती है।
"लूप बंद करना" यानी आप भरोसेमंद ढंग से Collect → Act → Reply → Learn की प्रक्रिया पूरी कर पाते हैं। व्यवहार में, हर प्रतिक्रिया आइटम का एक स्पष्ट परिणाम होना चाहिए (shipped, declined, explained, या queued) और—जहाँ उपयुक्त हो—ग्राहक‑सामने प्रतिक्रिया जिसमें समयसीमा दी गई हो।
ऐसे मीट्रिक्स चुनें जो गति और गुणवत्ता दिखाते हों:
कम संख्या चुनें ताकि टीमें फालतू सक्रियता के लिए ऑप्टिमाइज़ न करें।
सभी स्रोतों को एक ही आंतरिक “feedback item” स्वरूप में सामान्यीकृत करें, साथ ही मूल डाटा रखें.
प्रायोगिक तरीका:
इससे ट्रायज़िंग सुसंगत रहता है और बाद में पार्सर सुधारने पर आप पुरानी प्रविष्टियाँ फिर से प्रोसेस कर सकते हैं।
कोर मॉडल को सरल और क्वेरी‑फ्रेंडली रखें:
एक संक्षिप्त, साझा स्थिति परिभाषा लिखें और शुरू में एक रैखिक सेट रखें:
हर स्थिति को यह बताना चाहिए कि “अगला क्या होगा?” और “अगला कदम किसका है?” अगर किसी स्थिति में अस्पष्टता हो तो उसे अलग नाम दें या विभाजित करें ताकि रिपोर्टिंग भरोसेमंद रहे।
डुप्लिकेट्स को "एक ही मूल समस्या/अनुरोध" के रूप में परिभाषित करें, न कि केवल टेक्स्ट समानता के आधार पर.
एक सामान्य वर्कफ़्लो:
यह विधि fragmented काम से बचाती है और मांग का पूरा रिकॉर्ड रखती है।
ऑटोमेशन को सरल और ऑडिटेबल रखें:
हमेशा दिखाएँ “Routed because…” ताकि इंसान इसे जाँच और सुधार सकें। पहले सुझाव/डिफ़ॉल्ट दें, कठोर ऑटो‑रूटिंग बाद में लगाएँ।
प्रत्येक वर्कस्पेस को एक कठिन सीमा मानें:
workspace_id जोड़ेंworkspace_id तक सीमित रखेंफिर roles को क्रियाओं (view/edit/merge/export/send replies) के हिसाब से परिभाषित करें—स्क्रीन के अनुसार नहीं। एक audit log जल्दी जोड़ें ताकि status changes, merges, assignments, और replies ट्रैक हो सकें।
मॉड्यूलर मोनोलिथ से शुरू करें और स्पष्ट सीमाएँ रखें (auth/orgs, feedback, workflow, messaging, analytics). ट्रांज़ैक्शनल वर्कफ़्लो डेटा के लिए relational DB का प्रयोग करें.
बैकग्राउंड जॉब्स शुरू से ही रखें—for:
यह UI को तेज़ रखता है और failures retryable बनाता है बिना तुरंत microservices में जाने के।
issue ट्रैकर की पूरी नकल करने के बजाय हल्के रेफरेंस रखें:
external_system (jira/linear/github)work_type (bug/task/feature)external_id (और वैकल्पिक external_url)जब linked work हो, तो सभी जुड़े ग्राहकों को टेम्पलेट मैसेज से नोटिफाई करने के लिए वर्कफ़्लो ट्रिगर करें और delivery को ट्रैक करें। सार्वजनिक नोट्स हों तो उन्हें सापेक्ष लिंक दें (जैसे ).
ऑडिटेबिलिटी और डायनामिक मेटाडेटा के लिए events timeline का प्रयोग करें ताकि मुख्य feedback रिकॉर्ड हल्का रहे।
/releases