14 अक्टू॰ 2025·8 मिनट
GraphQL क्या है? APIs और डेटा फ़ेचिंग के लिए स्पष्ट मार्गदर्शिका
जानें कि GraphQL क्या है, क्वेरीज, म्यूटेशन्स और स्कीमा कैसे काम करते हैं, और कब REST की जगह GraphQL का उपयोग करें—साथ में व्यावहारिक फायदे, नुकसान और उदाहरण।
जानें कि GraphQL क्या है, क्वेरीज, म्यूटेशन्स और स्कीमा कैसे काम करते हैं, और कब REST की जगह GraphQL का उपयोग करें—साथ में व्यावहारिक फायदे, नुकसान और उदाहरण।
User या Post) और फ़ील्ड्स (जैसे name या title) से मिलकर बनी होती है। फ़ील्ड्स दूसरे टाइप्स की ओर इशारा कर सकते हैं, और इस तरह GraphQL रिलेशनशिप्स मॉडल करता है।\n\nयहाँ Schema Definition Language (SDL) में एक सरल उदाहरण है (कोड ब्लॉक को जैसा है वैसा ही रखा गया है):\n\ngraphql\ntype User {\n id: ID!\n name: String!\n posts: [Post!]!\n}\n\ntype Post {\n id: ID!\n title: String!\n body: String\n author: User!\n comments: [Comment!]!\n}\n\ntype Comment {\n id: ID!\n text: String!\n author: User!\n post: Post!\n}\n\n\n### स्ट्रॉन्ग टाइपिंग = एक्ज़ीक्यूशन से पहले वैलिडेशन\n\nक्योंकि स्कीमा स्ट्रॉन्गली टाइप्ड है, GraphQL एक अनुरोध को चलाने से पहले सत्यापित कर सकता है। यदि क्लाइंट किसी ऐसे फ़ील्ड के लिए पूछता है जो मौजूद नहीं है (उदा., Post.publishDate जब स्कीमा में ऐसी फ़ील्ड न हो), तो सर्वर स्पष्ट एरर के साथ अनुरोध अस्वीकार कर सकता है—बिना अस्पष्ट “शायद काम करेगा” व्यवहार के।\n\n### समय के साथ सुरक्षित रूप से विकसित होना\n\nस्कीमा को बढ़ाने के लिए डिज़ाइन किया गया है। आप आमतौर पर नए फ़ील्ड जोड़ सकते हैं (जैसे User.bio) बिना मौजूदा क्लाइंट्स को तोड़े—क्योंकि क्लाइंट केवल वही पाते हैं जो वे माँगते हैं। फ़ील्ड्स को हटाना या बदलना अधिक संवेदनशील है, इसलिए टीमें अक्सर पहले फ़ील्ड्स को deprecate करती हैं और क्लाइंट्स को धीरे-धीरे माइग्रेट कराती हैं।\n\n## क्वेरीज: जिसकी आपको ठीक-ठीक ज़रूरत है वही माँगे\n\nएक GraphQL API आमतौर पर एक सिंगल एंडपॉइंट (उदाहरण के लिए, /graphql) के माध्यम से एक्सपोज़ होती है। कई अलग URLs (जैसे /users, /users/123, /users/123/posts) की बजाय आप एक क्वेरी भेजते हैं और बताते हैं कि वापस कौन-सा डेटा चाहिए।\n\n### फ़ील्ड्स चुनना (नेस्टेड डेटा सहित)\n\nएक क्वेरी मूल रूप से फ़ील्ड्स की एक "शॉपिंग लिस्ट" है। आप सिम्पल फ़ील्ड्स (जैसे id और name) और नेस्टेड डेटा (जैसे किसी यूज़र के हालिया पोस्ट) दोनों एक ही अनुरोध में माँग सकते हैं—बिना अनावश्यक फ़ील्ड्स डाउनलोड किए।\n\nयहाँ एक छोटा उदाहरण है:\n\ngraphql\nquery GetUserWithPosts {\n user(id: \"123\") {\n id\n name\n posts(limit: 2) {\n id\n title\n }\n }\n}\n\n\n### एक पूर्वानुमेय प्रतिक्रिया संरचना\n\nGraphQL प्रतिक्रियाएँ पूर्वानुमेय होती हैं: जो JSON आपको मिलता है वह आपकी क्वेरी की संरचना को दर्शाता है। इससे फ्रंटेंड पर काम करना आसान हो जाता है, क्योंकि आपको यह अनुमान लगाने की ज़रूरत नहीं होती कि डेटा कहाँ मिलेगा या अलग-अलग प्रतिक्रिया फ़ॉर्मैट्स को पार्स करना होगा।\n\nसरलीकृत प्रतिक्रिया कुछ इस तरह दिख सकती है:\n\njson\n{\n \"data\": {\n \"user\": {\n \"id\": \"123\",\n \"name\": \"Sam\",\n \"posts\": [\n { \"id\": \"p1\", \"title\": \"Hello GraphQL\" },\n { \"id\": \"p2\", \"title\": \"Queries in Practice\" }\n ]\n }\n }\n}\n\n\nयदि आप किसी फ़ील्ड के लिए नहीं पूछते, तो वह शामिल नहीं होगा। यदि आप पूछते हैं, तो आप उम्मीद कर सकते हैं कि वह मैचिंग जगह पर मिलेगा—जिससे GraphQL क्वेरीज प्रत्येक स्क्रीन या फीचर को ठीक वैसा डेटा लेने का साफ़ तरीका देती हैं जिसकी उसे ज़रूरत है।\n\n## म्यूटेशन्स: डेटा को सुरक्षित रूप से लिखना\n\nक्वेरीज पढ़ने के लिए हैं; म्यूटेशन्स GraphQL API में डेटा बदलने का तरीका हैं—रिकॉर्ड्स बनाना, अपडेट करना, या हटाना।\n\n### सामान्य म्यूटेशन फ़्लो\n\nअधिकांश म्यूटेशन्स इसी पैटर्न का पालन करती हैं:\n\n1. इनपुट्स: क्लाइंट एक संरचित इनपुट भेजता है (अक्सर एक input ऑब्जेक्ट) जैसे जिन फ़ील्ड्स को अपडेट करना है।\n2. वैलिडेशन & ऑथोराइज़ेशन: सर्वर चेक करता है कि आवश्यक फ़ील्ड्स हैं, फॉर्मैट सही हैं, यूनिकनेस मान्य है, और यूज़र को यह कार्रवाई करने का अधिकार है या नहीं।\n3. राइट: सर्वर डाटाबेस परिवर्तन करता है (या किसी अन्य सर्विस को कॉल करता है)।\n4. पेलोड/रिटर्न टाइप: सर्वर एक पूर्वानुमेय परिणाम संरचना लौटाता है ताकि UI अपडेट कर सके।\n\n### म्यूटेशन्स डेटा क्यों लौटाती हैं\n\nGraphQL म्यूटेशन्स आम तौर पर जानबूझकर डेटा लौटाती हैं, सिर्फ़ “success: true” नहीं। अपडेटेड ऑब्जेक्ट (या कम से कम उसका id और की फ़ील्ड्स) लौटाने से UI को मदद मिलती है:\n\n- बिना अतिरिक्त राउंड-ट्रिप के स्क्रीन तुरंत अपडेट कर सकें\n- कैश्ड डेटा सुरक्षित रूप से रिफ्रेश कर सकें (उदा., Apollo Client के साथ)\n- फ़ील्ड-स्तरीय एरर्स संदर्भ में दिखा सकें\n\nएक सामान्य डिज़ाइन “पेलोड” टाइप का उपयोग करता है जिसमें अपडेटेड एंटिटी और किसी भी एरर्स दोनों होते हैं।\n\n### एक बुनियादी म्यूटेशन उदाहरण\n\ngraphql\nmutation UpdateEmail($input: UpdateUserEmailInput!) {\n updateUserEmail(input: $input) {\n user {\n id\n email\n }\n errors {\n field\n message\n }\n }\n}\n\n\nUI-ड्रिवन APIs के लिए एक अच्छा नियम है: वह लौटाएँ जो आपको अगले स्टेट को रेंडर करने के लिए चाहिए (उदा., अपडेटेड user और कोई errors)। इससे क्लाइंट सरल रहता है, यह अनुमान लगाने से बचता है कि क्या बदला, और विफलताओं को सौम्य तरीके से हैंडल करना आसान होता है।\n\n## रिज़ॉल्वर: GraphQL कैसे परिणाम पैदा करता है\n\nएक GraphQL स्कीमा यह बताती है कि क्या माँगा जा सकता है। रिज़ॉल्वर यह बताते हैं कि वास्तव में इसे कैसे प्राप्त करें। रिज़ॉल्वर आपके स्कीमा के किसी विशेष फ़ील्ड से जुड़े फ़ंक्शन होते हैं। जब क्लाइंट उस फ़ील्ड की आवश्यकता करता है, तो GraphQL उस फ़ील्ड का रिज़ॉल्वर कॉल करता है।\n\n### रिज़ॉल्वर "फ़ील्ड-स्तरीय" फ़ंक्शन्स होते हैं\n\nGraphQL एक क्वेरी को उसके अनुरोधित आकार के अनुसार निष्पादित करता है। हर फ़ील्ड के लिए यह संबंधित रिज़ॉल्वर ढूँढता और चलाता है। कुछ रिज़ॉल्वर सीधे किसी ऑब्जेक्ट की इन-मेमोरी प्रॉपर्टी लौटाते हैं; अन्य डेटाबेस कॉल करते हैं, किसी सर्विस को कॉल करते हैं, या कई स्रोतों को मिलाते हैं।\n\nउदाहरण के लिए, अगर आपके स्कीमा में User.posts है, तो posts रिज़ॉल्वर userId द्वारा posts तालिका क्वेरी कर सकता है, या किसी अलग Posts सर्विस को कॉल कर सकता है।\n\n### स्कीमा फ़ील्ड्स को डेटा स्रोतों से मैप करना\n\nरिज़ॉल्वर स्कीमा और आपके वास्तविक सिस्टम्स के बीच गोंद होते हैं:\n\n- डेटाबेस: SQL/NoSQL क्वेरीज, स्टोर्ड प्रोसीजर, ORM कॉल्स\n- सर्विसेज़: REST/gRPC कॉल्स, इन्टरनल माइक्रोसर्विसेज़, थर्ड-पार्टी APIs\n- कम्प्यूटेड फ़ील्ड्स: टोटल्स, फॉर्मैटिंग, व्युत्पन्न मान\n\nयह मैपिंग लचीली है: आप बैकएंड इम्प्लिमेंटेशन बदल सकते हैं बिना क्लाइंट क्वेरी के आकार को बदले—जब तक स्कीมา कंसिस्टेंट रहे।\n\n### परफ़ॉर्मेंस: धीमे रिज़ॉल्वर चेन से बचना (N+1)\n\nक्योंकि रिज़ॉल्वर प्रति फ़ील्ड और लिस्ट के हर आइटम के लिए चल सकते हैं, यह आसानी से कई छोटे कॉल्स ट्रिगर कर सकता है (उदा., 100 यूज़र्स के लिए पोस्ट्स 100 अलग क्वेरीज)। यह “N+1” पैटर्न प्रतिक्रियाओं को धीमा कर सकता है।\n\nसामान्य सुधारों में बैचिंग और कैशिंग शामिल हैं (उदा., IDs इकट्ठा कर के एक ही क्वेरी में फ़ेच करना) और उन नेस्टेड फ़ील्ड्स के बारे में जानबूझकर निर्णय लेना जिन्हें आप क्लाइंट्स से प्रोत्साहित करते हैं।\n\n### ऑथोराइज़ेशन और वैलिडेशन कहाँ होते हैं\n\nआम तौर पर ऑथोराइज़ेशन रिज़ॉल्वर (या साझा मिडलवेयर) में लागू किया जाता है क्योंकि रिज़ॉल्वर जानते हैं कि कौन मांग रहा है (context के माध्यम से) और कौन सा डेटा एक्सेस कर रहे हैं। वैलिडेशन दो स्तरों पर होती है: GraphQL प्रकार/आकार वैलिडेशन स्वचालित रूप से संभालता है, जबकि रिज़ॉल्वर बिज़नेस नियम लागू करते हैं (जैसे “केवल एडमिन यह फ़ील्ड सेट कर सकते हैं”)।\n\n## एरर्स और आंशिक परिणाम\n\nGraphQL में एक चीज़ जो नए लोगों को अचरज कर देती है वह यह है कि एक अनुरोध "सफल" हो सकता है और फिर भी एरर शामिल हो सकते हैं। इसका कारण है कि GraphQL फ़ील्ड-उन्मुख है: यदि कुछ फ़ील्ड रेज़ॉल्व हो पाती हैं और कुछ नहीं, तो आपको आंशिक डेटा मिल सकता है।\n\n### एरर्स कैसी दिखती हैं\n\nएक सामान्य GraphQL प्रतिक्रिया में data और एक errors ऐरे दोनों हो सकते हैं:\n\njson\n{\n \"data\": {\n \"user\": {\n \"id\": \"123\",\n \"email\": null\n }\n },\n \"errors\": [\n {\n \"message\": \"Not authorized to read email\",\n \"path\": [\"user\", \"email\"],\n \"extensions\": { \"code\": \"FORBIDDEN\" }\n }\n ]\n}\n\n\nयह उपयोगी है: क्लाइंट अभी भी जो मौजूद है उसे रेंडर कर सकता है (उदा., यूज़र प्रोफ़ाइल) जबकि वह गायब फ़ील्ड को हैंडल करे।\n\n### फ़ील्ड-स्तरीय एरर्स बनाम रिक्वेस्ट-लेवल विफलताएँ\n\n- फ़ील्ड-स्तरीय एरर्स निष्पादन के दौरान होते हैं (एक रिज़ॉल्वर थ्रो करता है, अनुमति चेक फेल हो जाता है, डाउनस्ट्रीम सर्विस टाइमआउट हो जाती है)। अन्य फ़ील्ड्स अभी भी रेज़ॉल्व हो सकती हैं।\n- रिक्वेस्ट-लेवल फेल्यर निष्पादन को रोक देते हैं (invalid JSON, malformed query, स्कीमा के विरुद्ध वैलिडेशन एरर)। इन मामलों में data अक्सर null होता है।\n\n### डिटेल्स लीक किए बिना उपयोगकर्ता-मित्र एरर मेसेज\n\nएरर मेसेज अंत-उपयोगकर्ता के लिए लिखें, डिबगिंग के लिए नहीं। स्टैक ट्रेसेस, डाटाबेस नाम, या आंतरिक IDs उजागर करने से बचें। एक अच्छा पैटर्न है:\n\n- एक छोटा, सुरक्षित message\n- एक स्थिर मशीन-रीडेबल extensions.code\n- वैकल्पिक सुरक्षित मेटाडेटा (उदा., retryable: true)\n\nविस्तृत एरर सर्वर-साइड पर request ID के साथ लॉग करें ताकि आप बिना आंतरिक जानकारी उजागर किए जाँच कर सकें।\n\n### क्लाइंट्स में सुसंगत हैंडलिंग के टिप्स\n\nवेब और मोबाइल ऐप्स के बीच एक छोटा एरर “कॉन्ट्रैक्ट” पर सहमति करें: सामान्य extensions.code मान (जैसे UNAUTHENTICATED, FORBIDDEN, BAD_USER_INPUT), कब टोस्ट दिखाना है बनाम इनलाइन फ़ील्ड एरर्स, और आंशिक डेटा को कैसे हैंडल करना है। इससे हर क्लाइंट का अपना अलग नियम बनाने से बचा जा सकेगा।\n\n## सब्सक्रिप्शन्स: रियल-टाइम अपडेट्स\n\nसब्सक्रिप्शन्स GraphQL का तरीका हैं ताकि सर्वर डेटा बदलते ही क्लाइंट्स को पुश कर सके, बजाय इसके कि क्लाइंट बार-बार पूछे। वे आम तौर पर एक स्थायी कनेक्शन (अधिकतर WebSockets) के ऊपर डिलीवर होते हैं, ताकि सर्वर किसी घटना के होने पर तुरंत ईवेंट भेज सके।\n\n### सब्सक्रिप्शन्स क्या हैं (और कैसे काम करते हैं)\n\nएक सब्सक्रिप्शन काफी हद तक एक क्वेरी की तरह दिखती है, पर परिणाम एक ही उत्तर नहीं होता। यह परिणामों का स्ट्रीम होता है—हर एक एक ईवेंट का प्रतिनिधित्व करता है।\n\nअधः-तल में, एक क्लाइंट किसी टॉपिक (उदा., चैट ऐप में messageAdded) को "सब्सक्राइब" करता है। जब सर्वर कोई ईवेंट पब्लिश करता है, तो जुड़े सब्सक्राइबर्स को उस सब्सक्रिप्शन के चयन सेट के अनुरूप पेलोड मिलता है।\n\n### सामान्य उपयोग केस\n\nसब्सक्रिप्शन्स तब चमकते हैं जब उपयोगकर्ताओं को बदलाव तुरंत चाहिए:\n\n- चैट संदेश बिना रिफ्रेश के रूम में दिखना\n- नोटिफिकेशन्स (mentions, order status changes, alerts)\n- लाइव डैशबोर्ड (सिस्टम हेल्थ, लॉजिस्टिक्स, ट्रेडिंग, स्पोर्ट्स स्कोर)\n\n### सब्सक्रिप्शन्स बनाम पोलिंग\n\nपोलिंग में क्लाइंट हर N सेकंड पर पूछता है "कुछ नया है?"। यह सरल है, पर जब कुछ बदलता नहीं तब भी यह अनुरोध बर्बाद कर सकता है और फिर भी देरी महसूस होती है।\n\nसब्सक्रिप्शन्स में सर्वर तुरंत कहता है "यह रहा अपडेट"। इससे अनावश्यक ट्रैफ़िक घट सकता है और महसूस होने वाली गति बेहतर हो सकती है—पर इसके लिए कनेक्शन्स खुले रखने और रियल-टाइम इंफ्रास्ट्रक्चर संभालने का अतिरिक्त ओवरहेड होता है।\n\n### कब सब्सक्रिप्शन्स अनावश्यक जटिलता हैं\n\nसब्सक्रिप्शन्स हमेशा जरूरी नहीं होते। अगर अपडेट कम आते हैं, समय-संवेदी नहीं हैं, या बैच करना आसान है, तो पोलिंग (या यूज़र एक्शन के बाद रिफ्रेश) अक्सर पर्याप्त है। यह ऑपरेशनल ओवरहेड भी जोड़ सकते हैं: कनेक्शन स्केलिंग, लॉन्ग-लिव्ड सेशन्स पर ऑथ, retries, और मॉनिटरिंग। एक अच्छा नियम: सब्सक्रिप्शन्स तभी प्रयोग करें जब रियल-टाइम प्रोडक्ट आवश्यकता हो, सिर्फ "अच्छा होगा" के कारण नहीं।\n\n## फायदे, नुकसान, और व्यावहारिक ट्रेडऑफ़\n\nGraphQL को अक्सर "क्लाइंट को शक्ति" देने वाले रूप में बताया जाता है, पर इस शक्ति की भी लागत होती है। शुरुआत में ट्रेडऑफ़्स जानना मददगार है ताकि आप तय कर सकें कब GraphQL अच्छा फिट है—और कब यह ज़रूरत से ज्यादा जटिल हो सकता है।\n\n### जहाँ GraphQL ज़्यादा उपयोगी है\n\nसबसे बड़ा फायदा है लचीला डेटा फ़ेचिंग: क्लाइंट ठीक वही फ़ील्ड्स माँग सकता है जो उसे चाहिए, जिससे ओवर-फेचिंग घट सकती है और UI बदलाव तेज़ हो सकते हैं।\n\nएक और बड़ा लाभ है स्कीमा द्वारा दिया जाने वाला स्ट्रॉन्ग कॉन्ट्रैक्ट। स्कीमा प्रकारों और उपलब्ध ऑपरेशन्स के लिए एक सिंगल सोर्स ऑफ़ ट्रुथ बन जाता है, जो सहयोग और टूलिंग को बेहतर बनाता है।\n\nटीमें अक्सर बेहतर क्लाइंट प्रोडक्टिविटी देखती हैं क्योंकि फ्रंट-एंड डेवलपर्स नए एंडपॉइंट्स के इंतज़ार के बिना iterate कर पाते हैं, और Apollo Client जैसे टूल्स टाइप जनरेशन और डेटा फ़ेचिंग को आसान बनाते हैं।\n\n### आम नकारात्मक पहलू जिन्हें योजना बनानी चाहिए\n\nGraphQL से कैशिंग अधिक जटिल हो सकती है। REST में अक्सर कैशिंग "प्रति URL" होती है। GraphQL में कई क्वेरीज एक ही एंडपॉइंट साझा करती हैं, इसलिए कैशिंग क्वेरी आकारों, नार्मलाइज़्ड कैशेस, और सावधान सर्वर/क्लाइंट कॉन्फ़िगरेशन पर निर्भर करती है।\n\nसर्वर साइड पर परफॉर्मेंस पिटफॉल्स भी हैं। एक छोटा सा क्वेरी भी कई बैकएंड कॉल ट्रिगर कर सकता है जब तक आप रिज़ॉल्वर को सावधानी से डिज़ाइन नहीं करते (बैचिंग, N+1 से बचना, महँगे फ़ील्ड्स को नियंत्रित करना)।\n\nसाथ ही सीखने की कर्व भी है: स्कीमा, रिज़ॉल्वर, और क्लाइंट पैटर्न उन टीमों के लिए अपरिचित हो सकते हैं जो एंडपॉइंट-आधारित APIs के आदी हैं।\n\n### सुरक्षा और ऑपरेशंस\n\nक्योंकि क्लाइंट बहुत कुछ माँग सकता है, GraphQL APIs को क्वेरी डेप्थ और कॉम्प्लेक्सिटी लिमिट्स लागू करनी चाहिए ताकि दुर्व्यवहार या आकस्मिक "बहुत बड़ा" अनुरोध रोका जा सके।\n\nऑथेंटिकेशन और ऑथोराइज़ेशन को फील्ड-स्तर पर लागू करें, न कि केवल रूट-लेवल पर, क्योंकि विभिन्न फ़ील्ड्स के अलग एक्सेस नियम हो सकते हैं।\n\nऑपरेशनल रूप से, ऐसे लॉगिंग, ट्रेसिंग, और मॉनिटरिंग में निवेश करें जो GraphQL को समझते हों: ऑपरेशन नाम, वेरिएबल्स (ध्यान से), रिज़ॉल्वर टाइमिंग, और एरर रेट्स ट्रैक करें ताकि आप धीमी क्वेरीज और रिग्रेशन जल्दी पकड़ सकें।\n\n## GraphQL बनाम REST: वे कैसे अलग हैं\n\nGraphQL और REST दोनों एप्स और सर्वर्स के बीच बातचीत में मदद करते हैं, पर वे उस बातचीत को बहुत अलग ढंग से संरचित करते हैं।\n\n### REST आमतौर पर कैसे काम करता है\n\nREST रेसॉर्स-आधारित है। आप कई एंडपॉइंट्स (URLs) को कॉल करके डेटा लेते हैं जो "चीज़ों" का प्रतिनिधित्व करते हैं जैसे /users/123 या /orders?userId=123। हर एंडपॉइंट एक फिक्स्ड डेटा आकार लौटाता है जिसे सर्वर ने तय किया होता है।\n\nREST HTTP सिमेंटिक्स पर भी निर्भर करता है: GET/POST/PUT/DELETE जैसे मेथड, स्टेटस कोड्स, और कैशिंग नियम। जब आप ब्राउज़र/प्रॉक्सी कैश का भरपूर उपयोग करना चाहते हैं तो REST सहज महसूस कर सकता है।\n\n### GraphQL कैसे काम करता है\n\nGraphQL स्कीमा-आधारित है। कई एंडपॉइंट्स की बजाय आप आम तौर पर एक एंडपॉइंट रखते हैं, और क्लाइंट एक क्वेरी भेजकर ठीक बताता है कि उसे कौन-सा फ़ील्ड्स चाहिए। सर्वर उस क्वेरी को स्कीमा के विरुद्ध वैलिडेट करता है और क्वेरी के आकार के अनुरूप प्रतिक्रिया लौटाता है।\n\nयह "क्लाइंट-ड्रिवन सिलेक्शन" है जो GraphQL को ओवर-फेचिंग और अंडर-फेचिंग घटाने में मदद करता है, खासकर उन UI स्क्रीन के लिए जिन्हें कई रिलेटेड मॉडल्स का डेटा चाहिए।\n\n### कब REST सरल हो सकता है\n\nREST अक्सर बेहतर फिट होता है जब:\n\n- आप फाइल डाउनलोड/अपलोड कर रहे हों (स्ट्रीमिंग, कंटेंट-टाइप्स, रेंज अनुरोध)।\n- आपकी API ज्यादातर साधारण CRUD है जिसका_payload_ पूर्वानुमेय है।\n- आप HTTP कैशिंग पर बहुत भरोसा करते हैं और मौजूदा टूलिंग के साथ अधिकतम संगतता चाहते हैं।\n\n### हाइब्रिड अप्रोच सामान्य हैं\n\nकई टीमें दोनों का मिश्रण अपनाती हैं:\n\n- UI-केंद्रित डेटा फ़ेचिंग के लिए GraphQL का उपयोग करें (वेब/मॉबाइल स्क्रीन)।\n- विशिष्ट सेवाओं के लिए REST रखें जैसे auth callbacks, webhooks, फाइल हैंडलिंग, या इन्टरनल माइक्रोसर्विस एंडपॉइंट्स।\n\nव्यावहारिक सवाल यह नहीं है कि "कौन सा बेहतर है?" बल्कि यह कि "कौन सा इस उपयोग केस के लिए कम से कम जटिलता के साथ फिट बैठता है?"\n\n## GraphQL API डिज़ाइन करने का तरीका (शुरुआत करने वालों के लिए चेकलिस्ट)\n\nGraphQL API डिज़ाइन करना आसान होता है जब आप इसे स्क्रीन बनाने वाले लोगों के लिए एक प्रोडक्ट के रूप में ट्रीट करते हैं, न कि अपने डेटाबेस का आईना। छोटा शुरू करें, असली उपयोग मामलों के साथ वेरिफाई करें, और ज़रूरत के अनुसार विस्तार करें।\n\n### 1) UI स्क्रीन से शुरू करें (तालिकाओं से नहीं)\n\nअपनी प्रमुख स्क्रीन सूचीबद्ध करें (उदा., “Product list”, “Product details”, “Checkout”)। हर स्क्रीन के लिए ठीक-ठीक फ़ील्ड्स और इंटरैक्शन्स लिखें।\n\nयह आपको "गॉड क्वेरीज" से बचाएगा, ओवर-फेचिंग घटाएगा, और स्पष्ट करेगा कि कहाँ फ़िल्टरिंग, सॉर्टिंग, और पेजिनेशन की ज़रूरत होगी।\n\n### 2) डोमेन टाइप्स मॉडल करें, फिर ऑपरेशन्स धीरे-धीरे जोड़ें\n\nपहले अपने कोर टाइप्स परिभाषित करें (उदा., User, Product, Order) और उनके रिश्ते। फिर जोड़ें:\n\n- एक छोटा सेट क्वेरीज जो असली स्क्रीन से मेल खाती हों\n- एक छोटा सेट म्यूटेशन्स जो असली यूज़र क्रियाओं से मेल खाती हों ("addToCart", "placeOrder")\n\nबिज़नेस-लैंग्वेज नामकरण को प्राथमिकता दें बजाय डेटाबेस नामकरण के। “placeOrder” createOrderRecord से उद्देश्य बेहतर बताता है।\n\n### 3) नामकरण और पेजिनेशन बेसिक्स\n\nनामकरण सुसंगत रखें: आइटम्स के लिए सिंगुलर (product), कलेक्शन्स के लिए प्लुरल (products)। पेजिनेशन के लिए आमतौर पर एक चुनें:\n\n- करसर-आधारित: बदलती सूचियों और "इनफिनिटी स्क्रोल" के लिए बेहतर (ज़्यादा स्थिर)\n- ऑफ़सेट-आधारित: सरल, पर डेटा बदलने पर आइटम स्किप/डुप्लिकेट हो सकते हैं\n\nशुरुआत में ही निर्णय लें क्योंकि यह आपके API की प्रतिक्रिया संरचना को आकार देता है।\n\n### 4) बनाते समय दस्तावेज़ बनाएं\n\nGraphQL स्कीमा सीधे वर्णनात्मक सहायता देता है—फील्ड्स, आर्ग्यूमेंट्स, और एज केस के लिए उनका उपयोग करें। फिर अपनी डॉक्स में कुछ कॉपी-पेस्ट उदाहरण जोड़ें (पेजिनेशन और सामान्य एरर परिदृश्यों सहित)। एक अच्छी तरह से वर्णित स्कीमा इंट्रोस्पेक्शन और API एक्सप्लोरर्स को बहुत अधिक उपयोगी बनाती है।\n\n## शुरू करने के लिए: टूल्स, परीक्षण, और अगले कदम\n\nGraphQL के साथ शुरुआत मुख्यतः कुछ अच्छे सपोर्टेड टूल्स चुनने और एक भरोसेमंद वर्कफ़्लो सेट करने के बारे में है। आपको एक साथ सब कुछ अपनाने की ज़रूरत नहीं—एक क्वेरी को एंड-टू-एंड काम करता हुआ बनाइए, फिर विस्तार कीजिए।\n\n### एक सर्वर फ्रेमवर्क चुनें\n\nअपने स्टैक और आप कितनी "बैकरीज़-इनक्लूडेड" चाहते हैं उस आधार पर सर्वर चुनें:\n\n- Apollo Server: एक लोकप्रिय विकल्प बड़े इकोसिस्टम और अच्छी डॉक्स के साथ।\n- GraphQL Yoga: हल्का, आधुनिक डिफ़ॉल्ट्स, बढ़िया डेवलपर अनुभव।\n- NestJS: अगर आप पहले से Nest का उपयोग करते हैं और चाहते हैं कि GraphQL उसके मॉड्यूल्स, DI, और पैटर्न्स के साथ इंटीग्रेट हो।\n\nएक व्यावहारिक पहला कदम: एक छोटा स्कीमा परिभाषित करें (कुछ टाइप्स + एक क्वेरी), रिज़ॉल्वर इम्प्लीमेंट करें, और एक वास्तविक डेटा स्रोत से कनेक्ट करें (भले ही वह इन-मेमोरी स्टब हो)।\n\nअगर आप "आइडिया" से काम करने तक तेज़ी से पहुँचना चाहते हैं, तो Koder.ai जैसे प्लेटफ़ॉर्म से आप छोटा फुल‑स्टैक ऐप (React फ्रंटेंड, Go + PostgreSQL बैकएंड) स्कैफ़ोल्ड कर सकते हैं और चैट के जरिए स्कीमा/रिज़ॉल्वर पर iterate कर सकते हैं—फिर जब तैयार हों तो सोर्स कोड एक्सपोर्ट कर लें।\n\n### क्लाइंट अप्रोच चुनें\n\nफ्रंटेंड पर, आपका चुनाव आमतौर पर इस पर निर्भर करेगा कि आप कितना opinionated कन्वेंशन चाहते हैं या कितनी लचीलापन:\n- Apollo Client: व्यापक रूप से उपयोग होता है, मजबूत कैशिंग और devtools।\n- Relay: कड़े पैटर्न, बड़े ऐप्स में स्थिरता चाहने वालों के लिए अक्सर उपयोगी।\n- urql: छोटा, कंपोज़ेबल, उन टीमों के लिए अच्छा जो नियंत्रण चाहते हैं।\n\nअगर आप REST से माइग्रेट कर रहे हैं, तो एक स्क्रीन या फीचर के लिए GraphQL उपयोग करके शुरू करें, और बाकी के लिए REST रखें जब तक यह दृष्टिकोण साबित न हो जाए।\n\n### परीक्षण: स्कीमा + रिज़ॉल्वर + इंटीग्रेशन\n\nअपनी स्कीमा को API कॉन्ट्रैक्ट की तरह ट्रीट करें। उपयोगी टेस्टिंग लेयर्स में शामिल हैं:\n\n- स्कीमा वैलिडेशन (CI में स्कीमा बनाएं; invalid types पर फेल कर दें)\n- रिज़ॉल्वर यूनिट टेस्ट्स (डेटा स्रोतों को मॉक करें और एज केस व ऑथ नियम सत्यापित करें)\n- (टेस्ट सर्वर और डेटाबेस के खिलाफ असली GraphQL ऑपरेशन्स चलाएँ) \n### अगले कदम\n\nअपनी समझ बढ़ाने के लिए आगे बढ़ें:\n\n- /blog/graphql-vs-rest\n- /blog/graphql-schema-design
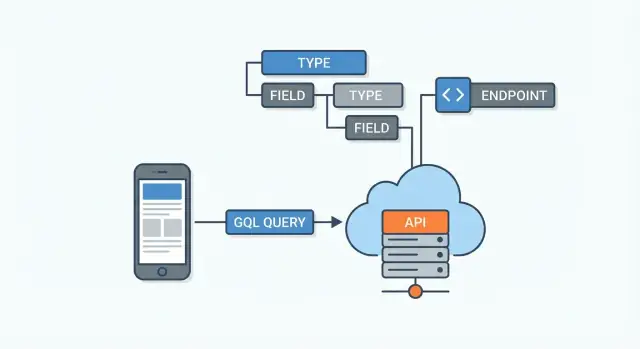
GraphQL एक क्वेरी भाषा और रनटाइम फॉर APIs है। क्लाइंट एक क्वेरी भेजता है जो बताती है कि किन-किन फ़ील्ड्स की ज़रूरत है, और सर्वर उसी संरचना के अनुरूप JSON प्रतिक्रिया लौटाता है।
इसे क्लाइंट और एक या अधिक डाटा स्रोतों (डेटाबेस, REST सर्विसेज़, थर्ड-पार्टी APIs, माइक्रोसर्विसेज़) के बीच एक लेयर के रूप में सोचा जाना चाहिए।
GraphQL मुख्यतः इन समस्याओं का समाधान करता है:
क्लाइंट केवल वह फ़ील्ड्स माँग सकता है जो उसे चाहिए (नेस्टेड फ़ील्ड्स सहित), जिससे अनावश्यक ट्रांसफ़र घटता है और क्लाइंट कोड सरल रहता है।
GraphQL यह नहीं है:
इसे एक API कॉन्ट्रैक्ट + एक्ज़ीक्यूशन इंजन की तरह देखें, स्टोरेज या परफ़ॉर्मेंस का जादू नहीं।
ज़्यादातर GraphQL APIs एक सिंगल एंडपॉइंट (अक्सर /graphql) एक्सपोज़ करते हैं। अलग-अलग URLs की बजाय आप उसी एंडपॉइंट पर भिन्न-भिन्न ऑपरेशन्स (queries/mutations) भेजते हैं।
व्यावहारिक निहितार्थ: कैशिंग और ऑब्ज़रवेबिलिटी अक्सर operation name + variables पर आधारित होते हैं, न कि URL पर।
स्कीमा API का कॉन्ट्रैक्ट है। यह परिभाषित करता है:
User, Post)\n- उन टाइप्स के फ़ील्ड्स (जैसे User.name)\n- रिलेशनशिप्स (जैसे User.posts)क्योंकि यह स्ट्रॉन्गली टाइप्ड है, सर्वर एक क्वेरी को execute करने से पहले validate कर सकता है और स्पष्ट एरर दे सकता है जब कोई फ़ील्ड मौजूद न हो।
GraphQL क्वेरीज रीड ऑपरेशन्स हैं। आप जिन फ़ील्ड्स की ज़रूरत बताते हैं, सर्वर उसी संरचना में JSON लौटाता है।
टिप्स:
query GetUserWithPosts) ताकि डिबगिंग और मॉनिटरिंग बेहतर हो।posts(limit: 2))।म्यूटेशन्स वे ऑपरेशन्स हैं जो डेटा बदलते हैं (create/update/delete)। सामान्य पैटर्न:
input ऑब्जेक्ट भेजेंडेटा लौटाने का कारण: UI तुरंत अपडेट कर सके और कैश कंसिस्टेंसी बनी रहे।
रिज़ॉल्वर वे फ़ील्ड-लेवल फ़ंक्शंस हैं जो बताते हैं कि किसी फ़ील्ड का मान कैसे प्राप्त या कैल्कुलेट किया जाए।
रिज़ॉल्वर आमतौर पर:
ऑथ और बिज़नेस नियम अक्सर रिज़ॉल्वर या साझा मिडलवेयर में लागू होते हैं क्योंकि वहीं यह पता होता है कि कौन क्या माँग रहा है।
अनायास N+1 पैटर्न बनना आसान है (उदा., 100 यूज़र्स के लिए हर यूज़र के पोस्ट अलग-अलग लाना)।
सामान्य समाधान:
रिज़ॉल्वर टाइमिंग मापें और एक ही रिक्वेस्ट में कई डाउनस्ट्रीम कॉल्स को देखें।
GraphQL आंशिक डेटा के साथ errors एरे भी लौटा सकता है—क्योंकि कुछ फ़ील्ड सफलतापूर्वक रेज़ॉल्व हो सकते हैं और कुछ फेल।
अच्छी प्रथाएँ:
messageextensions.code मान (उदा., FORBIDDEN, BAD_USER_INPUT) रखेंक्लाइंट तय करे कि कब आंशिक डेटा रेंडर करना है और कब ऑपरेशन को पूरी तरह विफल मानना है।