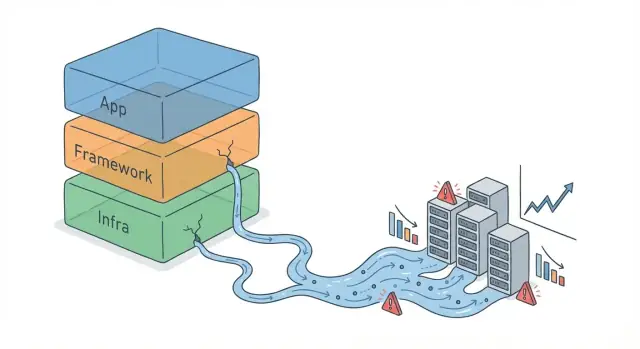
स्केल पर “एब्स्ट्रैक्शन लीक” का क्या मतलब है
एक एब्स्ट्रैक्शन एक सरलीकरण की परत है: एक फ्रेमवर्क API, एक ORM, एक मैसेज क्यू क्लाइंट, या एक "एक-लाइन" कैशिंग हेल्पर। यह आपको उच्च-स्तरीय अवधारणाओं ("यह ऑब्जेक्ट सेव करो", "यह इवेंट भेजो") में सोचने देता है बिना निचले-स्तरीय मैकेनिक्स को बार-बार संभाले।
एक एब्स्ट्रैक्शन लीक तब होता है जब वे छिपे हुए विवरण फिर भी असली परिणामों को प्रभावित करने लगते हैं—तो आपको उसी चीज़ को समझकर और मैनेज करना पड़ता है जिसे एब्स्ट्रैक्शन छिपाने की कोशिश कर रहा था। कोड अभी भी “काम” करता है, लेकिन सरलीकृत मॉडल अब वास्तविक व्यवहार की भविष्यवाणी नहीं कर पाता।
शुरुआती चरण में लीक क्यों दिखाई नहीं देते
शुरुआती वृद्धि सहनशील होती है। कम ट्रैफ़िक और छोटे datasets के साथ, अक्षमताएँ खाली CPU, गर्म कैश और तेज़ क्वेरीज के पीछे छिप जाती हैं। लेटेंसी स्पाइक्स दुर्लभ होते हैं, retries जमते नहीं, और थोड़ा-सा फालतू लॉग लाइन मायने नहीं रखती।
जैसे वॉल्यूम बढ़ता है, वही शॉर्टकट बढ़ते हैं:
- अधिक रिक्वेस्ट छोटे ओवरहेड को एक स्थायी बोतल-नेक में बदल देते हैं।
- बड़ी तालिकाएँ “सुविधाजनक” क्वेरीज को महँगा बना देती हैं।
- अधिक सेवाएँ टाइमआउट, retries और आंशिक विफलताओं के चेन बनने की संभावना बढ़ा देती हैं।
लीक केवल गति का मामला नहीं है
लीकी एब्स्ट्रैक्शन्स आम तौर पर तीन क्षेत्रों में दिखाई देते हैं:
- प्रदर्शन: धीमी क्वेरीज, थ्रेड exhaustion, अत्यधिक serialization, अप्रत्याशित N+1 कॉल्स।
- विश्वसनीयता: retry storms, क्यू बिल्डअप, टाइमआउट जो cascading failures ट्रिगर करते हैं।
- लागत: चैटी सर्विसेज, ओवर-लॉगिंग, अक्षम कैशिंग और अनावश्यक स्टोरेज/नेटवर्क उपयोग से बढ़ी क्लाउड लागत।
इस गाइड में क्या उम्मीद करें
आगे हम उन व्यावहारिक संकेतों पर ध्यान देंगे जो बताते हैं कि एब्स्ट्रैक्शन लीक कर रहा है, अंतर्निहित कारण को कैसे डायग्नोज़ करें (सिर्फ लक्षणों को नहीं), और माइटीगेशन विकल्प—कन्फ़िगरेशन ट्वीक से लेकर जब एब्स्ट्रैक्शन आपके स्केल से मेल नहीं खाती तब जानबूझकर "एक स्तर नीचे उतरने" तक।
क्यों स्केल नियम बदल देता है
काफी सॉफ़्टवेयर एक ही चाप का अनुसरण करता है: प्रोटोटाइप विचार साबित करता है, प्रोडक्ट शिप होता है, फिर उपयोग मूल आर्किटेक्चर से तेज़ी से बढ़ता है। शुरुआती चरण में फ्रेमवर्क जादुई लगते हैं क्योंकि उनके डिफ़ॉल्ट आपको जल्दी आगे बढ़ने देते हैं—राउटिंग, DB एक्सेस, लॉगिंग, retries, और बैकग्राउंड जॉब्स “मुफ्त” मिल जाते हैं।
स्केल पर भी आप उन फायदों को चाहते हैं—लेकिन डिफ़ॉल्ट और convenience APIs मान्यताएँ बनना शुरू कर देते हैं।
डिफ़ॉल्ट “नॉर्मल” वर्कलोड के लिए ट्यून होते हैं
फ्रेमवर्क डिफ़ॉल्ट आमतौर पर मानते हैं:
- मामूली डेटा साइज
- स्थिर ट्रैफ़िक
- सीमित concurrency
- अनुमानित निष्पादन समय
ये मान्यताएँ शुरुआत में सही रहती हैं, इसलिए एब्स्ट्रैक्शन साफ़ दिखती है। लेकिन स्केल यह बदल देता है कि “नॉर्मल” का क्या मतलब है। 10,000 पंक्तियों पर ठीक चलने वाली क्वेरी 100 मिलियन पर धीमी हो सकती है। एक सिंक्रोनस हैंडलर जो सरल लगता था, ट्रैफिक स्पाइक होने पर टाइमआउट करने लगता है। एक retry नीति जो कभी-कभार की विफलताओं को स्मूद कर देती थी, हजारों क्लाइंट्स के एक साथ retry करने पर आउटेज बढ़ा सकती है।
वॉल्यूम, बर्स्ट्स और concurrency छिपे हुए खर्च उजागर करते हैं
स्केल केवल “ज़्यादा यूज़र्स” नहीं है। यह उच्च डेटा वॉल्यूम, बर्स्टी ट्रैफ़िक, और अधिक समवर्ती काम है। ये उन हिस्सों पर दबाव डालते हैं जिन्हें एब्स्ट्रैक्शन्स छिपाते हैं: कनेक्शन पूल्स, थ्रेड शेड्यूलिंग, क्यू डेप्थ, मेमोरी प्रेशर, I/O लिमिट्स, और निर्भरताओं से मिलने वाले रेट लिमिट्स।
फ्रेमवर्क अक्सर सुरक्षित, सामान्य सेटिंग्स चुनते हैं (पूल साइज़, टाइमआउट, बैचिंग व्यवहार)। लोड पर, वे सेटिंग्स contention, लॉन्ग-टेल लेटेंसी और cascading failures में बदल सकती हैं—समस्याएँ जो तब दिखाई नहीं देतीं जब सब कुछ मार्जिन के अंदर आराम से फिट होता है।
प्रोडक्शन स्टेजिंग नहीं है सिर्फ अतिरिक्त ट्रैफिक के साथ
स्टेजिंग एन्वायरनमेंट्स आमतौर पर प्रोडक्शन की नकल नहीं करते: छोटी datasets, कम सर्विसेज़, अलग कैशिंग व्यवहार, और कम "मैसी" यूज़र एक्टिविटी। प्रोडक्शन में आपके पास असली नेटवर्क वैरिएबिलिटी, noisy neighbors, रोलिंग डिप्लॉय्स, और आंशिक विफलताएँ भी होती हैं। इसलिए वही एब्स्ट्रैक्शन जो टेस्ट में एयरटाइट लगे, रियल-वर्ल्ड कंडीशन्स दबाव डालने पर लीक कर सकती है।
सामान्य संकेत कि कोई एब्स्ट्रैक्शन लीक कर रहा है
जब कोई फ्रेमवर्क एब्स्ट्रैक्शन लीक करता है, लक्षण शायद सीधे एरर मैसेज के रूप में नहीं आते। इसके बजाय आप पैटर्न देखते हैं: कम ट्रैफ़िक पर जो ठीक था, उच्च वॉल्यूम पर अनप्रेडिक्टेबल या महँगा दिखने लगता है।
टाइपिकल प्रदर्शन लक्षण
एक लीकिंग एब्स्ट्रैक्शन अक्सर यूज़र-देखने योग्य लेटेंसी के माध्यम से खुद का इशारा देता है:
- एंडपॉइंट्स जो गैर-रेखीय तरीके से धीमे होते हैं (p95/p99 फटते हैं जबकि औसत “ठीक” दिखता है)
- पीक लोड पर ही टाइमआउट्स दिखने लगते हैं
- क्यू बिल्डअप (बैकग्राउंड जॉब्स, मैसेज कंस्यूमर, थ्रेड पूल) जहाँ काम आने की दर प्रोसेस होने की दर से तेज़ हो
- अचानक थ्रूपुट की छतें: आप इंस्टेंस जोड़ते हैं, पर requests per second में मामूली ही सुधार दिखता है
ये क्लासिक संकेत हैं कि एब्स्ट्रैक्शन किसी बोतल-नेक को छिपा रहा है जिसे आप बिना एक स्तर नीचे उतरकर (जैसे असल क्वेरीज, कनेक्शन उपयोग, या I/O व्यवहार को निरीक्षण करके) हल नहीं कर पाएँगे।
लागत के लक्षण जो “रहस्यमयी बिल” जैसे दिखते हैं
कुछ लीक सबसे पहले इनवॉइस में दिखते हैं न कि डैशबोर्ड पर:
- DB CPU स्पाइक्स या बढ़ती IOPS बिना किसी स्पष्ट फीचर लॉन्च के
- कैश थ्रैश: हिट रेट झूलता है, evictions बढ़ते हैं, या hot keys हावी होते हैं
- ईग्रीस फीस में छलांग क्योंकि एक “सुविधाजनक” मिडलवेयर या प्रॉक्सी पाथ अनपेक्षित cross-zone/region ट्रैफ़िक पैदा करता है
- वही लोड बनाए रखने के लिए अधिक नोड्स की आवश्यकता, क्योंकि ओवरहेड (serialization, logging, retries) वॉल्यूम के साथ बढ़ता है
अगर इंफ्रास्ट्रक्चर बढ़ाने से प्रदर्शन समानुपाती रूप से वापस नहीं आता, तो अक्सर यह कच्ची क्षमता नहीं—यह ओवरहेड है जिसका आप भुगतान कर रहे थे और जिसे आपने महसूस नहीं किया।
विश्वसनीयता के लक्षण (सबसे डरावने)
लीक्स तब विश्वसनीयता समस्याएँ बन जाते हैं जब वे retries और dependency chains के साथ इंटरैक्ट करते हैं:
- Cascading failures: एक धीमी डिपेंडेंसी अपस्ट्रीम में टाइमआउट ट्रिगर करती है, जो कहीं और अधिक लोड ट्रिगर करता है
- Retries बढ़ाते हैं लोड: एक टाइमआउट क्लाइंट/वर्कर को retry करने के लिए मजबूर करता है, कमजोर घटक पर दबाव दोगुना या तिगुना कर देता है
- Circuit breakers और rate limits “बेतरतीब” ट्रिगर होते हैं क्योंकि लेटेंसी वेरिएंस बढ़ जाती है
- incidents जो "बस धीमा था" से शुरू होकर पार्टियल आउटेज में बदल जाते हैं
त्वरित चेकलिस्ट: लीक या underprovisioning?
इसे गंभीरता से जांचने के लिए उपयोग करें, इससे पहले कि आप और क्षमता खरीद लें:
- क्या प्रदर्शन लगभग रेखीय सुधार करता है जब आप संसाधन दोगुने करते हैं? अगर नहीं, तो लीक का शक रखें।
- क्या p95/p99 लेटेंसी और एरर रेट बिगड़ रहे हैं जबकि ऐप सर्वर का CPU मध्यम बना रहता है? अक्सर यह छिपी हुई डिपेंडेंसी बोतल-नेक है।
- क्या DB/cache/network वृद्धि असममित है अनुरोध वॉल्यूम के सापेक्ष? संभावना है कि एब्स्ट्रैक्शन अतिरिक्त काम जेनरेट कर रहा है।
- क्या retries/queues spikes के साथ कोरिलेट करते हैं (लोड और अधिक लोड बनाता है)? यह आमतौर पर लीक और failure handling का इंटरैक्शन होता है।
अगर लक्षण किसी एक डिपेंडेंसी (DB, cache, network) में केंद्रित हैं और "ज़्यादा सर्वर" पर प्रेडिक्टेबल रूप से प्रतिक्रिया नहीं करते, तो यह मजबूत संकेत है कि आपको एब्स्ट्रैक्शन के नीचे देखना चाहिए।
डेटाबेस एब्स्ट्रैक्शन्स: ORMs, क्वेरीज और छिपे हुए खर्च
ORMs बॉइलरप्लेट हटाने में शानदार हैं, लेकिन वे यह भी आसान बनाते हैं कि आप भूल जाएँ कि हर ऑब्जेक्ट अंततः एक SQL क्वेरी बनता है। छोटे स्केल पर यह तकरार अदृश्य लगता है। उच्च वॉल्यूम पर, डेटाबेस अक्सर पहला स्थान होता है जहाँ "साफ" एब्स्ट्रैक्शन ब्याज लेना शुरू कर देता है।
N+1 क्वेरीज का अचानक प्रकट होना
N+1 तब होता है जब आप parent रिकॉर्ड्स की सूची लोड करते हैं (1 क्वेरी) और फिर लूप के भीतर हर parent के लिए related रिकॉर्ड्स लोड करते हैं (N और क्वेरीज)। लोकल टेस्टिंग में यह ठीक दिखता है—शायद N 20 है। प्रोडक्शन में N 2,000 बन जाता है, और आपकी ऐप चुपचाप एक रिक्वेस्ट को हज़ारों राउंड-ट्रिप्स में बदल देती है।
मुस्किल बात यह है कि कुछ भी तुरंत "टूटता" नहीं; लेटेंसी धीरे-धीरे बढ़ती है, कनेक्शन पूल भरते हैं, और retries लोड को गुणा करते हैं।
ओवर-फेचिंग, मिसिंग इंडेक्स और महंगे joins
एब्स्ट्रैक्शन्स अक्सर डिफ़ॉल्ट रूप से पूरे ऑब्जेक्ट फ़ेच करने को प्रोत्साहित करते हैं, भले ही आपको सिर्फ दो फ़ील्ड चाहिए हों। इससे I/O, मेमोरी और नेटवर्क ट्रांसफर बढ़ता है।
साथ ही, ORMs ऐसे क्वेरीज जेनरेट कर सकते हैं जो उन इंडेक्सों का उपयोग छोड़ देते हैं जिनके आप उपयोग होने की उम्मीद करते थे (या जो मौजूद ही नहीं थे)। एक ही मिसिंग इंडेक्स एक चयनात्मक lookup को टेबल स्कैन में बदल सकता है।
Joins भी एक छिपा हुआ खर्च हैं: जो "बस रिलेशन शामिल करें" जैसा दिखता है वह बड़े मध्यवर्ती परिणामों वाले मल्टी-join क्वेरी बन सकता है।
कनेक्शन पूल्स और ट्रांज़ैक्शन contention
लोड पर डेटाबेस कनेक्शन्स एक scarce resource होते हैं। अगर हर रिक्वेस्ट कई क्वेरीज में फैलती है, तो पूल जल्दी सीमा तक पहुँच जाता है और आपकी ऐप कतार लगने लगती है।
लॉन्ग ट्रांज़ैक्शन्स (कभी-कभी आकस्मिक) भी contention बढ़ा सकते हैं—लॉक्स लंबे समय तक रहते हैं, और concurrency घटती है।
वो माइटीगेशन जो बेहतर स्केल करते हैं
- ज्ञात रिलेशनशिप के लिए eager loading का उपयोग करें, पर सावधानी से: केवल वही फ़ेच करें जो चाहिए।
- क्वेरीज को आकृति दें: विशिष्ट कॉलम चुनें, pagination जोड़ें, और अनबाउंड "सभी लोड करें" पैटर्न से बचें।
- जहां संभव हो बैच ऑपरेशन्स (bulk inserts/updates) का उपयोग करें ताकि प्रति-रो ओवरहेड घटे।
- पढ़ाई-भारी सिस्टम के लिए read replicas लाएँ और सुरक्षित क्वेरीज उन्हें रूट करें।
- ORM-जनरेटेड SQL को
EXPLAIN से वैध करें, और इंडेक्स को एप्लिकेशन डिज़ाइन का हिस्सा समझें—DBA के बाद का विचार नहीं।
concurrency मॉडल और backpressure
Concurrency वह जगह है जहाँ एब्स्ट्रैक्शन्स dev में “सुरक्षित” लगते हैं और फिर लोड पर ज़ोर से फेल हो जाते हैं। फ्रेमवर्क का डिफ़ॉल्ट मॉडल अक्सर असली constraint छिपा देता है: आप सिर्फ रिक्वेस्ट सर्व नहीं कर रहे—आप CPU, थ्रेड्स, सॉकेट्स, और डाउनस्ट्रीम क्षमता के लिए contention भी मैनेज कर रहे हैं।
थ्रेड-प्रति-रिक्वेस्ट बनाम async: अलग विफलता के आकार
Thread-per-request (क्लासिक वेब स्टैक्स में आम) सरल है: हर रिक्वेस्ट को एक वर्कर थ्रेड मिलता है। यह तब टूटता है जब धीमे I/O (DB, API कॉल) थ्रेड्स को इकठ्ठा कर देता है। एक बार थ्रेड पूल खत्म होने पर, नई रिक्वेस्ट कतार लगती हैं, लेटेंसी बढ़ती है, और अंततः टाइमआउट आ जाते हैं—जबकि सर्वर बस इंतजार कर रहा होता है।
Async/event-loop मॉडल कम थ्रेड्स के साथ बहुत सारे इन-फ्लाइट रिक्वेस्ट संभालते हैं, इसलिए वे हाई concurrency पर बढ़िया होते हैं। वे अलग तरीके से टूटते हैं: एक blocking कॉल (एक सिंक लाइब्रेरी, धीमा JSON पार्सिंग, भारी लॉगिंग) event loop को अटकाकर "एक धीमा रिक्वेस्ट" को "सब कुछ धीमा" बना सकता है। Async से यह भी आसान हो जाता है कि आप बहुत अधिक concurrency क्रिएट कर दें, और एक dependency को थ्रॉटल कर दें जिसकी तुलना थ्रेड सीमाएँ नहीं कर पातीं।
Backpressure: गायब अनुबंध
Backpressure वह सिस्टम है जो कॉलर्स से कहता है, "धीरे करो; मैं और सुरक्षित रूप से और काम नहीं ले सकता।" इसके बिना, एक धीमी डिपेंडेंसी सिर्फ प्रतिक्रियाओं को धीमा नहीं करती—यह इन-फ्लाइट काम, मेमोरी उपयोग, और क्यू लंबाई बढ़ाती है। यह अतिरिक्त काम डिपेंडेंसी को और धीमा कर देता है, एक फ़ीडबैक लूप बनता है।
टाइमआउट और retry storms
टाइमआउट स्पष्ट और लेयर्ड होने चाहिए: client, service, और dependency। अगर टाइमआउट बहुत लंबे हैं, तो क्यूज़ बढ़ती हैं और रिकवरी देर से होती है। अगर retries ऑटोमैटिक और आक्रामक हैं, तो आप एक retry storm ट्रिगर कर सकते हैं: एक डिपेंडेंसी धीमी होती है, कॉल्स टाइमआउट होते हैं, कॉलर्स retry करते हैं, लोड गुणा हो जाता है, और डिपेंडेंसी गिर जाती है।
स्केल पर काम करने वाले माइटीगेशन
- Bulkheads का उपयोग करें ताकि संसाधन पृथक रहें (प्रति डिपेंडेंसी अलग थ्रेड पूल/कनेक्शन पूल), ताकि एक धीमा घटक सब कुछ consume न कर सके।
- Circuit breakers जोड़ें ताकि फेल हो रही डिपेंडेंसी को कॉल करना रोका जा सके और उसे recover करने का समय मिले।
- Request shedding लागू करें (क्यूज़ सुरक्षित सीमाएँ पार कर जाएँ तो फेल फास्ट करें)—किसी समय कुछ ट्रैफ़िक छोड़ना बेहतर है बजाय इसके कि सारी ट्रैफ़िक अनपेक्षित रूप से टाइमआउट हो।
नेटवर्किंग और मिडलवेयर ओवरहेड
लीक को जल्दी दोहराएँ
पुनर्लेखन से पहले यह सुनिश्चित करने के लिए एक न्यूनतम repro ऐप चलाएँ कि क्या लीक हो रहा है।
फ्रेमवर्क नेटवर्किंग को "सिर्फ एक एंडपॉइंट कॉल करना" जैसा महसूस कराते हैं। लोड पर, यह एब्स्ट्रैक्शन अक्सर मिडलवेयर स्टैक्स, serialization, और payload हैंडलिंग द्वारा किए गए अदृश्य कामों के माध्यम से लीक करता है।
“सिंपल” मिडलवेयर का प्रति-हॉप टैक्स
हर लेयर—API गेटवे, auth मिडलवेयर, rate limiting, request validation, observability hooks, retries—थोड़ा समय जोड़ती है। एक अतिरिक्त मिलीसेकण्ड डेवलपमेंट में शायद मायने न रखे; स्केल पर, कुछ मिडलवेयर हॉप्स 20 ms की रिक्वेस्ट को 60–100 ms में बदल सकते हैं, खासकर जब क्यूज़ बनती हैं।
मुख्य बात यह है कि लेटेंसी केवल जोड़ती नहीं—यह गुणा करती है। छोटे विलम्ब अधिक concurrency बढ़ाते हैं (अधिक इन-फ्लाइट रिक्वेस्ट), जो contention बढ़ाते हैं (थ्रेड पूल, कनेक्शन पूल), जो फिर विलम्ब बढ़ाते हैं।
serialization खर्च और payload आकार की आश्चर्यजनक बातें
JSON सुविधाजनक है, पर बड़े payloads का एनकोड/डिकोड CPU हावी कर सकता है। लीक उस तरह दिखती है जैसे "नेटवर्क" धीमा है पर वास्तव में यह एप्लिकेशन CPU का काम है, साथ ही buffers से मेमोरी चर्न भी बढ़ती है।
बड़े payloads भी सब कुछ धीमा करते हैं:
- ट्रांज़िट में अधिक समय और buffers के बीच अधिक कॉपीिंग
- मैनेज्ड रनटाइम्स में ज्यादा GC प्रेशर
- कुछ बड़े रिस्पॉन्सेस shared resources को ब्लॉक कर के tail latencies बढ़ाते हैं
हेडर, कम्प्रेशन, और स्ट्रीमिंग बनाम बफ़रिंग
हेडर चुपके से रिक्वेस्ट को फुल कर सकते हैं (कुकीज़, auth टोकन्स, tracing headers)। यह हर कॉल और हर हॉप पर गुणा हो जाता है।
कम्प्रेशन एक और ट्रेडऑफ़ है। यह bandwidth बचा सकता है, पर CPU लागत और अतिरिक्त लेटेंसी जोड़ता है—खासकर जब आप छोटे payloads compress करते हैं या proxies के ज़रिये कई बार compress होता है।
अंत में, स्ट्रीमिंग बनाम बफ़रिंग मायने रखता है। कई फ्रेमवर्क डिफ़ॉल्ट रूप से पूरे request/response बॉडीज़ को बफ़र करते हैं (retries, logging, या content-length कैलकुलेशन सक्षम करने के लिए)। यह सुविधाजनक है, पर उच्च वॉल्यूम पर यह मेमोरी उपयोग बढ़ाता है और head-of-line blocking बनाता है। स्ट्रीमिंग मेमोरी को पूर्वानुमानिय बनाये रखती है और time-to-first-byte घटाती है, पर इसके लिए अधिक सावधानीपूर्ण error handling की ज़रूरत होती है।
व्यावहारिक माइटीगेशन
payload size और middleware depth को बजट की तरह मानें, न कि बाद में सोचे जाने वाली चीज़:
- payload और header बजट सेट करें; उन्हें लिमिट्स और चेतावनियों के साथ लागू करें।
- "सब कुछ लौटाओ" endpoints की बजाय pagination और partial responses पसंद करें।
- बड़े अपलोड/डाउनलोड स्ट्रीम करें; पूरे बॉडी को लॉग करने से बचें।
- जहाँ लेटेंसी/CPU महत्वपूर्ण हो वहां बाइनरी फॉर्मैट (जैसे Protobuf) पर विचार करें।
- कम्प्रेशन सलेक्टिव रखें (साइज़ थ्रेशोल्ड्स, चैन में केवल एक जगह)।
जब स्केल नेटवर्किंग ओवरहेड को उजागर करता है, तो फिक्स अक्सर "नेटवर्क को optimize करो" नहीं होता बल्कि "हर रिक्वेस्ट पर छिपा काम बंद करो" होता है।
कैशिंग: जब “आसान” फिक्स नए फेल्यर मोड बनाते हैं
कैशिंग अक्सर एक सरल स्विच की तरह माना जाता है: Redis (या CDN) जोड़ें, लेटेंसी घटेगी, और चलते रहें। वास्तविक लोड में, कैशिंग एक एब्स्ट्रैक्शन है जो बुरी तरह लीक कर सकती है—क्योंकि यह बदल देता है कि काम कहाँ होता है, कब होता है, और विफलताएँ कैसे फैलती हैं।
कैशिंग मुफ्त स्पीड बूस्ट नहीं है
एक कैश अतिरिक्त नेटवर्क हॉप्स, serialization, और ऑपरेशनल जटिलता जोड़ता है। यह दूसरा “सोर्स ऑफ ट्रुथ” भी जोड़ता है जो stale, आंशिक रूप से भरा या अनुपलब्ध हो सकता है। जब चीज़ें गलत होती हैं, सिस्टम सिर्फ धीमा नहीं होता—यह अलग व्यवहार कर सकता है (पुराना डेटा सर्व करना, retries को बढ़ाना, या डेटाबेस को ओवरलोड करना)।
सामान्य फेल्यर मोड: स्टैम्पीड्स, कीज़, और इनवैलिडेशन
Cache stampedes तब होते हैं जब कई रिक्वेस्ट एक साथ cache miss करते हैं (अक्सर expiry के बाद) और सभी एक ही वैल्यू को rebuild करने के लिए दौड़ पड़ते हैं। स्केल पर, यह छोटे miss rate को DB स्पाइक में बदल सकता है।
खराब की डिज़ाइन एक और चुप समस्या है। अगर कीज़ बहुत broad हैं (जैसे user:feed बिना पैरामीटर्स के), आप गलत डेटा सर्व कर सकते हैं। अगर कीज़ बहुत specific हैं (टाइमस्टैम्प, रैंडम IDs, unordered क्वेरी params शामिल करते हैं), तो हिट रेट लगभग ज़ीरो हो सकता है और आप बिना लाभ के ओवरहेड चुकाएँगे।
Invalidation क्लासिक जाल है: DB अपडेट आसान है; हर संबंधित cached view को ताज़ा करना नहीं। आंशिक इनवैलिडेशन भ्रमित करने वाले "मेरे लिए ठीक है" बग और inconsistent reads पैदा करती है।
Hot keys और असमान ट्रैफ़िक
वास्तविक ट्रैफ़िक बराबर नहीं होता। एक सेलिब्रिटी प्रोफ़ाइल, लोकप्रिय प्रोडक्ट, या shared config endpoint एक hot key बन सकता है, जो लोड को एक ही cache एंट्री और उसके बैकिंग स्टोर पर केंद्रित कर देता है। भले ही औसत प्रदर्शन ठीक लगे, tail latency और नोड-स्तरीय दबाव फट सकते हैं।
व्यवहारिक माइटीगेशन
- TTL jitter का उपयोग करें ताकि expiry एक साथ न हो।
- Request coalescing (single-flight) जोड़ें ताकि सिर्फ एक रिक्वेस्ट missing key को rebuild करे जबकि अन्य इंतजार करें।
- Tiered caches (in-process LRU + shared cache) पर विचार करें ताकि नेटवर्क ओवरहेड घटे और Redis सुरक्षित रहे।
- cache-miss पाथ के चारों ओर rate limits और circuit breakers लागू करें ताकि एक cache घटना तुरंत DB घटना न बन जाए।
मेमोरी, गारबेज कलेक्शन, और रिसोर्स लीक
समस्या को दिखाएँ
वास्तविक अनुरोध पैटर्न ट्रिगर करने और ट्रेस कैप्चर करने के लिए एक छोटा React UI बनाएं।
फ्रेमवर्क अक्सर मेमोरी को “मैनेज्ड” महसूस कराते हैं, जो सुखद है—जब तक ट्रैफ़िक बढ़ता है और लेटेंसी ऐसी तरकीब से स्पाइक करने लगती है जो CPU ग्राफ़ से मेल नहीं खाती। कई डिफ़ॉल्ट developer convenience के लिए ट्यून होते हैं, न कि लंबे समय तक चलने वाले प्रोसेसेज़ के लिए सतत लोड पर।
डिफ़ॉल्ट मेमोरी वृद्धि और GC pauses छिपाते हैं कैसे
हाई-लेवल फ्रेमवर्क अक्सर प्रति रिक्वेस्ट छोटे-जीवित ऑब्जेक्ट्स allocate करते हैं: request/response wrappers, middleware context objects, JSON पेड़, regex matchers, और अस्थायी strings। व्यक्तिगत रूप से ये छोटे होते हैं। स्केल पर, वे लगातार allocation प्रेशर बनाते हैं, रनटाइम को गारबेज कलेक्शन (GC) अधिक बार चलाने के लिए मजबूर करते हैं।
GC pauses छोटे पर अक्सर दिखाई देने योग्य लेटेंसी स्पाइक्स बन सकते हैं। जैसे-जैसे heap बड़े होते हैं, pauses अक्सर लंबे होते जाते हैं—ज़रूरी नहीं कि आप leak कर रहे हों, पर रनटाइम को मेमोरी स्कैन और compact करने में अधिक समय चाहिए होता है।
allocation पैटर्न, बड़े heaps, और fragmentation
लोड पर, एक सर्विस कुछ ऑब्जेक्ट्स को older generation (या समकक्ष long-lived region) में promote कर सकती है सिर्फ इसलिए क्योंकि वे कुछ GC साइकिल्स से बच गए—अपेक्षित रूप से कतारों, बफ़र्स, कनेक्शन पूल्स, या इन-फ्लाइट रिक्वेस्ट्स में रहते हुए। इससे heap फूल सकता है भले ही एप्लिकेशन “सही” हो।
Fragmentation एक और छिपा हुआ खर्च है: मेमोरी फ्री हो सकती है लेकिन उस साइज के लिए पुन:उपयोग योग्य नहीं, इसलिए प्रोसेस OS से और मेमोरी माँगता रहता है।
लीक बनाम हाई-पर-स्टेबल मेमोरी
एक असली लीक अनबाउंड ग्रोथ है: मेमोरी बढ़ती रहती है, वापस नहीं आती, और अंततः OOM kills या चरम GC thrash ट्रिगर होता है।
High-but-stable usage अलग है: मेमोरी warm-up के बाद एक प्लेटो पर चढ़ती है, फिर लगभग फ्लैट रहती है।
ऐसे माइटीगेशन जो बैकफ़ायर न करें
प्रोफाइलिंग (heap snapshots, allocation flame graphs) से शुरू करें ताकि allocation hot paths और retained objects मिल सकें।
पूलिंग के साथ सतर्क रहें: यह allocations घटा सकता है, पर गलत आकार का पूल मेमोरी पिन कर सकता है और fragmentation बिगाड़ सकता है। पहले allocations घटाने पर ध्यान दें (स्ट्रीमिंग बनाम बफ़रिंग, अनावश्यक object निर्माण से बचना, प्रति-रिक्वेस्ट कैशिंग सीमित करना), फिर तभी पूलिंग जोड़ें जब मापन स्पष्ट लाभ दिखाएँ।
ऑब्ज़र्वेबिलिटी लीक: लोड पर लॉगिंग, मेट्रिक्स और ट्रेसिंग
ऑब्ज़र्वेबिलिटी टूल्स अक्सर “मुफ्त” महसूस होते हैं क्योंकि फ्रेमवर्क आपको सुविधाजनक डिफ़ॉल्ट देता है: रिक्वेस्ट लॉग्स, ऑटो-इंस्ट्रुमेंटेड मेट्रिक्स, और एक-लाइन ट्रेसिंग। असली ट्रैफ़िक पर, वे डिफ़ॉल्ट वही वर्कलोड बन सकते हैं जिसे आप देखना चाह रहे हैं।
जब ऑब्ज़र्वेबिलिटी बाधा बन जाती है
Per-request logging क्लासिक उदाहरण है। प्रति रिक्वेस्ट एक लाइन ठीक लगती है—जब तक आप सैकड़ों/हज़ारों रिक्वेस्ट प्रति सेकंड पर नहीं पहुँच जाते। तब आप string formatting, JSON encoding, डिस्क या नेटवर्क लेखन, और डाउनस्ट्रीम ingestion का भुगतान करते हैं। लीक CPU की अधिकता, tail latency, log pipelines का पिछड़ना, और कभी-कभी synchronous log flushing से रिक्वेस्ट टाइमआउट के रूप में दिखता है।
Metrics शांत तरीके से सिस्टम को ओवरलोड कर सकती हैं। काउंटर और हिस्टोग्राम तब सस्ते होते हैं जब समय श्रृंखलाओं की संख्या कम हो। पर फ्रेमवर्क अक्सर user_id, email, path, या order_id जैसी tags/labels जोड़ने को बढ़ावा देते हैं। इससे cardinality विस्फोट होता है: एक मेट्रिक की बजाय लाखों यूनिक सीरीज़ बन जाती हैं। परिणाम: क्लाइंट और बैकएंड में बढ़ी हुई मेमोरी, डैशबोर्ड पर धीमे क्वेरीज, ड्रॉप्ड सैम्पल्स, और आश्चर्यजनक बिल।
ट्रेसिंग: दृश्यता की एक कीमत
डिस्ट्रीब्यूटेड ट्रेसिंग स्टोरेज और compute ओवरहेड जोड़ती है जो ट्रैफ़िक और प्रति रिक्वेस्ट स्पैन संख्या के साथ बढ़ती है। अगर आप हर चीज़ को डिफ़ॉल्ट रूप से trace करते हैं, तो आप दो बार भुगतान कर सकते हैं: एक बार ऐप ओवरहेड (स्पैन बनाना, context propagate करना) में और दूसरा बार ट्रेसिंग बैकएंड में (ingestion, indexing, retention)।
सैंपलिंग वह तरीका है जिससे टीमें नियंत्रण वापस पाती हैं—पर इसे गलत करना आसान है। बहुत आक्रामक सैंपलिंग दुर्लभ विफलताओं को छुपा देती है; बहुत कम सैंपलिंग ट्रेसिंग को महँगा बना देती है। व्यावहारिक तरीका यह है कि errors और high-latency रिक्वेस्ट्स के लिए अधिक सैंपल करें, और हेल्दी फास्ट पाथ्स के लिए कम।
यदि आप एक बेसलाइन चाहते हैं कि क्या इकट्ठा करना है (और क्या नहीं), तो देखें /blog/observability-basics.
लीक दिखने पर क्या करें
ऑब्ज़र्वेबिलिटी को प्रोडक्शन ट्रैफ़िक की तरह मानें: बजट सेट करें (log वॉल्यूम, metric series count, trace ingestion), टैग्स की cardinality रिस्क की समीक्षा करें, और instrumentation को चालू करके load-test करें। लक्ष्य "कम ऑब्ज़र्वेबिलिटी" नहीं है—बल्कि ऐसी ऑब्ज़र्वेबिलिटी है जो तब भी काम करे जब आपकी प्रणाली दबाव में हो।
वितरित सिस्टम: जहाँ “सरल” जुड़ाव बन जाता है
फ्रेमवर्क अक्सर किसी और सर्विस को कॉल करना लोकल फ़ंक्शन कॉल जैसा महसूस कराते हैं: userService.getUser(id) जल्दी लौटता है, एरर सिर्फ "एक्सेप्शन" हैं, और retries harmless लगते हैं। छोटे स्केल पर यह भ्रम काम करता है। बड़े स्केल पर, एब्स्ट्रैक्शन इसलिए लीक करता है क्योंकि हर "सरल" कॉल छुपा हुआ coupling लाती है: लेटेंसी, क्षमता सीमाएँ, आंशिक विफलताएँ, और वर्शन mismatch।
सर्विसेज़ के बीच छुपा coupling
एक रिमोट कॉल दो टीमों के release cycles, डेटा मॉडल्स, और uptime को जोड़ देता है। अगर सर्विस A मान लेती है कि सर्विस B हमेशा उपलब्ध और तेज़ है, तो A का व्यवहार अब उसके अपने कोड से परिभाषित नहीं होता—यह B के सबसे खराब दिन से परिभाषित होता है। इस तरह सिस्टम कड़े जुड़े हुए हो जाते हैं भले ही कोड मॉड्यूलर दिखे।
ट्रांज़ैक्शन्स, consistency, और idempotency
डिस्ट्रीब्यूटेड ट्रांज़ैक्शन्स एक आम जाल हैं: जो दिखता था "यूज़र सेव करो, फिर कार्ड चार्ज करो" वह कई स्टेप्स में फैल जाता है डेटाबेस और सर्विसेज़ के पार। two-phase commit अक्सर प्रोडक्शन में सरल नहीं रहता, इसलिए कई सिस्टम eventual consistency पर स्विच करते हैं (जैसे, "पेमेंट थोड़ी देर में कन्फ़र्म हो जाएगा")। यह आपको retries, duplicates, और out-of-order events के लिए डिज़ाइन करने के लिए मजबूर करता है।
Idempotency अपरिहार्य बन जाती है: अगर रिक्वेस्ट किसी टाइमआउट के कारण retry होती है, तो उसे दूसरा चार्ज या दूसरा शिपमेंट नहीं बनाना चाहिए। फ्रेमवर्क-लेवल retry हेल्पर समस्याओं को बढ़ा सकते हैं जब तक कि आपके endpoints स्पष्ट रूप से repeat-safe न हों।
फेल्यर प्रोपेगेशन
एक धीमा डिपेंडेंसी थ्रेड पूल्स, कनेक्शन पूल्स, या क्यूज़ को ख़त्म कर सकता है, एक ripple effect बन जाता है: टाइमआउट retries ट्रिगर करते हैं, retries लोड बढ़ाते हैं, और जल्द ही असंबंधित एंडपॉइंट्स degrade हो जाते हैं। "बस और instances जोड़ो" अक्सर तूफ़ान को और खराब कर सकता है अगर सब लोग एक साथ retries करें।
जोड़ेपन को स्पष्ट रखने वाले माइटीगेशन
स्पष्ट कॉन्ट्रैक्ट परिभाषित करें (schemas, error codes, और versioning), हर कॉल के लिए टाइमआउट और बजट सेट करें, और जहां उपयुक्त हो fallbacks (cached reads, degraded responses) लागू करें।
अंत में, हर डिपेंडेंसी के लिए SLOs सेट करें और उन्हें लागू करें: अगर सर्विस B अपना SLO पूरा नहीं कर सकती, तो सर्विस A को फेल फास्ट या gracefully degrade करना चाहिए बजाय इसके कि वह चुपचाप पूरे सिस्टम को नीचे खींचे।
बिना अटकलों के लीक डायग्नोज़ कैसे करें
जांच की योजना बनाएं
प्लैनिंग मोड का उपयोग करके अनुमान, मेट्रिक्स और रोलबैक चरण एक ही स्थान पर दस्तावेज़ करें।
जब कोई एब्स्ट्रैक्शन स्केल पर लीक करता है, यह अक्सर एक अस्पष्ट लक्षण (timeouts, CPU स्पाइक्स, धीमी क्वेरीज) के रूप में दिखता है जो टीमों को जल्दबाज़ी में री-राइट्स की ओर ले जाता है। बेहतर तरीका है हंच को साक्ष्य में बदलना।
एक व्यावहारिक, चरण-दर-चरण वर्कफ़्लो
1) Reproduce (इसे मांग पर फेल कराएँ).
उस सबसे छोटे сценарियो को कैप्चर करें जो समस्या ट्रिगर करता है: एंडपॉइंट, बैकग्राउंड जॉब, या यूज़र फ्लो। प्रोडक्शन-जैसी कॉन्फ़िगरेशन के साथ लोकल या स्टेजिंग में इसे reproduce करें (feature flags, timeouts, connection pools)।
2) Measure (दो या तीन संकेत चुनें).
ऐसे कुछ मेट्रिक्स चुनें जो बताएं कि समय और संसाधन कहाँ जाते हैं: p95/p99 latency, error rate, CPU, memory, GC time, DB query time, queue depth। इन्सिडेंट के दौरान दर्जनों नए ग्राफ़ जोड़ने से बचें।
3) Isolate (संदिग्ध घटक को संकुचित करें).
टूलिंग का उपयोग करें ताकि “फ्रेमवर्क ओवरहेड” को “आपके कोड” से अलग किया जा सके:
- Profilers (CPU, memory, allocation) ताकि hot paths और churn मिले
- Tracing (OpenTelemetry, vendor APM) ताकि हर हॉप और कॉल depth में समय दिखे
- DB query planner / EXPLAIN ताकि ORM-जनरेटेड SQL और इंडेक्स उपयोग सत्यापित हों
- Load tests (k6, Gatling, Locust) ताकि नियंत्रित दबाव में reproduce कर सकें
4) Confirm (cause और effect साबित करें).
एक बार में एक वेरिएबल बदलें: एक क्वेरी के लिए ORM बाईपास करें, एक मिडलवेयर डिसेबल करें, लॉग वॉल्यूम घटाएँ, concurrency कैप करें, या पूल साइज़ बदलें। अगर लक्षण परिप्रेक्ष्य में प्रेडिक्टेबल रूप से बदलता है, तो आपने लीक खोज लिया है।
प्रोडक्शन जैसा स्ट्रेस टेस्ट करें, डेमो जैसा नहीं
वास्तविक डेटा साइज (row counts, payload sizes) और वास्तविक concurrency (burs ts, long tails, slow clients) का उपयोग करें। कई लीक तभी ही दिखाई देते हैं जब कैश ठंडी हो, तालिकाएँ बड़ी हों, या retries लोड को बढ़ा रहे हों।
“पुनर्लेखन से पहले” चेकलिस्ट
- क्या आप इसे एक load test के साथ reproduce कर सकते हैं और एक trace कैप्चर कर सकते हैं?
- क्या आपके पास profiler snapshot है जो शीर्ष उपभोक्ताओं को दिखाता है?
- क्या आपने worst queries को query planner से देखा है?
- क्या आपने उस लेयर को अलग करने वाला एक छोटा, reversible परिवर्तन आजमाया है?
- क्या आप fix के बाद सुधार को माप (p95/p99, लागत, error rate) कर सकते हैं?
माइटीगेशन रणनीतियाँ और कब एक स्तर नीचे उतरें
एब्स्ट्रैक्शन लीक फ्रेमवर्क की नैतिक विफलता नहीं है—यह एक संकेत है कि आपकी प्रणाली की जरूरतें "डिफ़ॉल्ट पाथ" से बाहर निकल चुकी हैं। लक्ष्य फ्रेमवर्क को छोड़ना नहीं है, बल्कि यह जानबूझकर निर्णय लेना है कि कब उन्हें ट्यून करना है और कब बायपास करना है।
पहले फ्रेमवर्क को ट्यून करें (जब यह अभी भी सही काम कर रहा हो)
फ्रेमवर्क के भीतर रहें जब समस्या कन्फ़िगरेशन या उपयोग का मामला हो बजाय मौलिक mismatch के। अच्छे उम्मीदवार:
- एक धीमा एंडपॉइंट जो बेहतर इंडेक्सेस, क्वेरी शेपिंग, और कनेक्शन पूल सेटिंग्स से सुधरता है
- अत्यधिक लॉगिंग जिसे sampling, log levels, और structured fields से ठीक किया जा सकता है
- थ्रेड/वर्कर starvation जो concurrency limits और timeouts से ठीक होता है
अगर आप उसे सेटिंग्स और गार्डरेल्स जोड़कर ठीक कर सकते हैं, तो आप अपग्रेड्स को आसान रखते हैं और "special cases" कम बनाते हैं।
escape hatches का उपयोग करें (जब आपको precision चाहिए)
अधिकांश परिपक्व फ्रेमवर्क ऐसे तरीके देते हैं जिससे आप पूरी तरह rewrite किए बिना abstraction के बाहर जा सकें। सामान्य पैटर्न:
- Escape hatches: एक hot query के लिए raw SQL, सीधे HTTP client सेटिंग्स, एक payload के लिए custom serialization
- Thin adapters: फ्रेमवर्क कंपोनेंट के चारों ओर छोटा wrapper ताकि आप बाद में implementation बदल सकें
- Boundary layers: फ्रेमवर्क को किनारों पर रखें (routing, auth), पर कोर बिज़नेस लॉजिक को साफ़ इंटरफेस के पीछे अलग करें
यह फ्रेमवर्क को एक टूल बनाये रखता है, न कि ऐसा निर्भरता जो आर्किटेक्चर को निर्धारित करे।
ऑपरेशनल प्रैक्टिसेज़ जो “फिक्स” को रिस्क न बन जाने दें
मिटिगेशन उतना ही ऑपरेशनल है जितना कि कोड:
- Capacity planning: बजट परिभाषित करें (p95 latency, CPU, DB time) और उन्हें प्रति रिलीज़ ट्रैक करें
- Canaries और safe rollouts: पहले एक छोटे स्लाइस पर रोल आउट करें, error rates/latency की तुलना करें, फिर बढ़ाएँ
- Load testing जो वास्तविकता से मेल खाता है: पीक पैटर्न्स, retries, और डाउनस्ट्रीम स्लोनस शामिल करें
संबंधित rollout प्रैक्टिस के लिए देखें /blog/canary-releases.
एक सरल निर्णय फ्रेमवर्क
एक स्तर नीचे तब उतरें जब (1) मुद्दा critical path को प्रभावित करे, (2) आप जीत को माप सकें, और (3) परिवर्तन दीर्घकालिक मेंटेनेंस टैक्स नहीं बनाए जिससे आपकी टीम नहीं निपट सके। अगर केवल एक व्यक्ति ही बाईपास समझता है, तो यह "fix" नहीं—यह नाज़ुकता है।
Koder.ai किस तरह फिट बैठता है (बिना और एब्स्ट्रैक्शन्स जो आप नहीं देख सकते जोड़ने के)
जब आप लीक hunt कर रहे हों, स्पीड मायने रखती है—पर परिवर्तन reversible होना भी मायने रखता है। टीमें अक्सर Koder.ai का उपयोग छोटी, अलग reproducible प्रोडक्शन इश्यूज़ (एक मिनिमल React UI, एक Go सर्विस, एक PostgreSQL schema, और एक load-test harness) जल्दी से बनाने के लिए करती हैं बिना स्कैफ़ोल्डिंग पर दिन बर्बाद किए। इसकी planning mode मदद करती है जो आप क्या बदल रहे हैं और क्यों, दस्तावेज़ करने में, जबकि snapshots और rollback “एक स्तर नीचे उतरने” प्रयोग (जैसे एक ORM क्वेरी को raw SQL से बदलना) को सुरक्षित बनाते हैं ताकि यदि डेटा उसे सपोर्ट न करे तो आप आसानी से revert कर सकें।
यदि आप यह काम कई एन्वायरनमेंट्स में कर रहे हैं, तो Koder.ai का बिल्ट-इन डिप्लॉयमेंट/होस्टिंग और exportable source code निदान आर्टिफैक्ट्स (बेंचमार्क्स, repro ऐप्स, आंतरिक डैशबोर्ड) को असली सॉफ़्टवेयर की तरह रखने में मदद कर सकता है—versioned, shareable, और किसी के लोकल फोल्डर में फंसा नहीं।