आधुनिक डेटा वर्कफ़्लो में Ullman का महत्त्व
ज्यादातर लोग जो SQL लिखते हैं, डैशबोर्ड बनाते हैं, या धीमी क्वेरी को ट्यून करते हैं, वे Jeffrey Ullman के काम से लाभान्वित हुए हैं—चाहे उन्होंने कभी उनका नाम न सुना हो। Ullman एक कंप्यूटर वैज्ञानिक और शिक्षक हैं जिनके शोध और पाठ्यपुस्तकें इस बात को परिभाषित करने में मदद करती हैं कि डेटाबेस डेटा का कैसे वर्णन करते हैं, क्वेरीज के बारे में कैसे सोचा जाता है, और उन्हें कुशलता से कैसे चलाया जाता है।
रोज़मर्रा के उपकरणों के पीछे शांत प्रभाव
जब कोई डेटाबेस इंजन आपका SQL लेकर उसे तेज़ी से चलाने योग्य बनाता है, तो वह उन विचारों पर निर्भर करता है जो सटीक और अनुकूलनीय दोनों होने चाहिए। Ullman ने क्वेरी के अर्थ को औपचारिक किया (ताकि सिस्टम उसे सुरक्षित रूप से फिर से लिख सके), और डेटाबेस सोच को कंपाइलर सोच से जोड़ने में मदद की (ताकि क्वेरी पार्स, ऑप्टिमाइज़ और executable steps में बदली जा सके)।
यह प्रभाव शांत है क्योंकि यह आपके BI टूल में बटन के रूप में या क्लाउड कंसोल में स्पष्ट फीचर के रूप में नहीं दिखता। यह इस तरह दिखता है:
- आप इंडेक्स जोड़ने या
JOIN फिर से लिखने के बाद क्वेरीज जो तेज़ी से चलती हैं
- ऑप्टिमाइज़र जो डेटा बढ़ने पर अलग योजनाएँ चुनते हैं
- सिस्टम जो स्केल करते समय आपके क्वेरी के परिणाम नहीं बदलते
इस लेख में आप क्या सीखेंगे (बिना भारी गणित के)
यह पोस्ट Ullman के मूल विचारों को ले कर डेटाबेस इंटर्नल का एक गाइडेड टूर देती है: SQL के नीचे रिलेशनल बीजगणित कैसे बैठता है, क्वेरी री-राइट्स अर्थ कैसे बचाते हैं, लागत-आधारित ऑप्टिमाइज़र क्यों वही चुनाव करते हैं जो करते हैं, और जॉइन एल्गोरिदम अक्सर यह तय करते हैं कि कोई काम सेकंड में खत्म होगा या घंटों में।
हम कुछ कंपाइलर-जैसे कांसेप्ट भी जोड़ेंगे—पार्सिंग, री-राइटिंग, और प्लानिंग—क्योंकि डेटाबेस इंजन अक्सर कई लोगों की अपेक्षा से अधिक परिष्कृत कंपाइलरों जैसे व्यवहार करते हैं।
एक छोटा वादा: हम चर्चा सटीक रखेंगे, पर गणित-भरे प्रमाणों से बचेंगे। उद्देश्य यह है कि आपको ऐसे मानसिक मॉडल मिलें जिन्हें आप अपने काम में अगले प्रदर्शन, स्केलिंग या भ्रमित करने वाले क्वेरी व्यवहार पर लागू कर सकें।
वह डेटाबेस बुनियादी बातें जिनको Ullman ने मजबूत किया
अगर आपने कभी SQL लिखकर उम्मीद की कि यह “सिर्फ़ एक ही मतलब” रखता है, तो आप उन विचारों पर भरोसा कर रहे हैं जिनको Jeffrey Ullman ने लोकप्रिय और औपचारिक किया: डेटा के लिए एक साफ़ मॉडल और ये बताने के सटीक तरीके कि क्वेरी क्या मांगती है।
सरल शब्दों में रिलेशनल मॉडल
मूलतः, रिलेशनल मॉडल डेटा को टेबल्स (relations) के रूप में देखता है। हर टेबल में रोज़ (tuples) और कॉलम (attributes) होते हैं। अब यह स्पष्ट लग सकता है, पर महत्वपूर्ण हिस्सा वह अनुशासन है जो यह बनाता है:
- कीज़ पंक्तियों की पहचान करती हैं। एक primary key प्रत्येक रिकॉर्ड के लिए “नाम टैग” है।
- रिलेशनशिप्स तालिकाओं को foreign keys के माध्यम से जोड़ते हैं, ताकि आप तथ्यों को एक जगह रख सकें और उन्हें अन्य जगह संदर्भित कर सकें।
यह फ्रेमवर्क बिना अटकलें लगाए सटीकता और प्रदर्शन के बारे में तर्क करने की अनुमति देता है। जब आप जानते हैं कि एक टेबल क्या दर्शाती है और पंक्तियाँ कैसे पहचानी जाती हैं, तो आप अनुमान लगा सकते हैं कि joins क्या करेंगे, duplicates का क्या मतलब है, और किन फ़िल्टर्स से परिणाम बदलते हैं।
रिलेशनल बीजगणित: क्वेरी के लिए एक कैलकुलेटर
Ullman अक्सर रिलेशनल बीजगणित को एक तरह का क्वेरी कैलकुलेटर के रूप में पढ़ाते हैं: ऑपरेशनों (select, project, join, union, difference) का एक छोटा सेट जिसे जोड़कर आप अपनी आवश्यकता व्यक्त कर सकते हैं।
SQL के साथ काम करने के लिए यह इसलिए मायने रखता है: डेटाबेस SQL को अल्जेब्राईक रूप में बदलते हैं और फिर उसे दूसरे समकक्ष रूप में री-राइट करते हैं। दो क्वेरीज जो अलग दिखती हैं, अल्जेब्रिक रूप से समान हो सकती हैं—इसीलिए ऑप्टिमाइज़र joins का क्रम बदल सकते हैं, फ़िल्टर्स को आगे धकेल सकते हैं, या अनावश्यक काम हटा सकते हैं और फिर भी अर्थ को सुरक्षित रख सकते हैं।
अल्जेब्रा बनाम कैलकुलस (सतही स्तर)
- रिलेशनल बीजगणित अधिक “कैसे” है: परिणाम निकालने का एक अनुक्रम।
- रिलेशनल कैलकुलस अधिक “क्या” है: वह विवरण कि आप क्या चाहते हैं।
SQL ज्यादातर “क्या” है, पर इंजन अक्सर अल्जेब्राईक “कैसे” का उपयोग करके ऑप्टिमाइज़ करते हैं।
फ़ाउंडेशन किसी डायलेक्ट को memorize करने से बेहतर
SQL डायलेक्ट अलग होते हैं (Postgres बनाम Snowflake बनाम MySQL), पर मूल बातें नहीं बदलतीं। कीज़, रिलेशनशिप और अल्जेब्राईक समकक्षता को समझना आपको बताता है कि कब क्वेरी तर्कतः गलत है, कब यह केवल धीमी है, और किन बदलावों से प्लेटफ़ॉर्म बदलने पर भी अर्थ बना रहेगा।
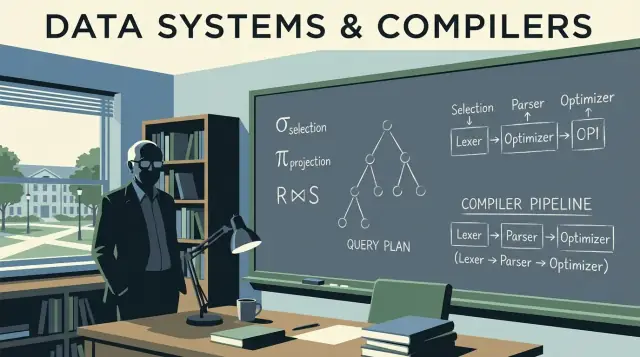
रिलेशनल बीजगणित: SQL के नीचे छिपी भाषा
रिलेशनल बीजगणित SQL के "माथे के नीचे की गणित" है: कुछ ऑपरेटर जो बतलाते हैं कि आप क्या परिणाम चाहते हैं। Jeffrey Ullman के काम ने इस ऑपरेटर-व्यू को स्पष्ट और पढ़ने योग्य बनाया—और यही वह मानसिक मॉडल है जिसे अधिकतर ऑप्टिमाइज़र आज भी इस्तेमाल करते हैं।
मुख्य ऑपरेटर (और उनका अर्थ)
एक डेटाबेस क्वेरी को कुछ बिल्डिंग ब्लॉक्स की पाइपलाइन के रूप में व्यक्त किया जा सकता है:
- Select (σ): पंक्तियों को फ़िल्टर करना (SQL का
WHERE)
- Project (π): कुछ विशिष्ट कॉलम रखना (SQL का
SELECT col1, col2)
- Join (⋈): शर्त के आधार पर टेबल को जोड़ना (
JOIN ... ON ...)
- Union (∪): समान आकार के परिणामों को ऊपर-ऊपर जोड़ना (
UNION)
- Difference (−): A में पर B में नहीं (कई SQL डायलेक्ट में
EXCEPT जैसी)
क्योंकि सेट छोटा है, यह सही होने पर तर्क करना आसान बनाता है: यदि दो अल्जेब्राईक अभिव्यक्तियाँ समकक्ष हैं, तो वे किसी भी वैध डेटाबेस स्टेट के लिए वही टेबल लौटाती हैं।
SQL कैसे अल्जेब्रा से मैप होता है (वैचारिक)
एक परिचित क्वेरी लें:
SELECT c.name
FROM customers c
JOIN orders o ON o.customer_id = c.id
WHERE o.total > 100;
वैचारिक रूप से यह है:
-
customers और orders का join: customers ⋈ orders
-
केवल उन ऑर्डर्स को चुनें जिनका कुल 100 से अधिक है: σ(o.total > 100)(...)
-
आप जो कॉलम चाहते हैं उसे projection: π(c.name)(...)
यह हर इंजन द्वारा उपयोग की जाने वाली एकदम वही आंतरिक नोटेशन नहीं है, पर विचार सही है: SQL एक ऑपरेटर ट्री बन जाता है।
समकक्षता: ऑप्टिमाइज़ेशन की राह
कई अलग-अलग ट्रीज़ एक ही परिणाम दे सकते हैं। उदाहरण के लिए, फ़िल्टर अक्सर पहले लगाया जा सकता है (बड़े join से पहले σ लागू करना), और projection अक्सर बेकार कॉलम पहले हटा सकता है (पहले π लागू करना)।
ये समकक्षता नियम डेटाबेस को आपकी क्वेरी को सस्ता प्लान चुनने के लिए फिर से लिखने देते हैं बिना अर्थ बदले। एक बार जब आप क्वेरीज को अल्जेब्रा के रूप में देखते हैं, तो “ऑप्टिमाइज़ेशन” जादू नहीं रह जाता—बल्कि नियम-आधारित सुरक्षित रूप से रूपांतरण बन जाता है।
SQL से क्वेरी प्लान तक: अर्थ-संरक्षण री-राइट्स
जब आप SQL लिखते हैं, डेटाबेस उसे "जैसा लिखा है" वैसा नहीं चलाता। वह आपके स्टेटमेंट को एक क्वेरी प्लान में बदलता है: एक संरचित प्रतिनिधित्व कि किस तरह का काम करना है।
एक अच्छा मानसिक मॉडल है एक ऑपरेटर का पेड़। पत्तियाँ टेबल या इंडेक्स पढ़ती हैं; अंदर के नोड्स पंक्तियों को बदलते और जोड़ते हैं। सामान्य ऑपरेटरों में scan, filter, project, join, group/aggregate, और sort शामिल हैं।
लॉजिकल प्लान बनाम फिज़िकल प्लान (क्या बनाम कैसे)
डेटाबेस आमतौर पर प्लानिंग को दो परतों में अलग करते हैं:
- Logical plan: क्या परिणाम निकालना है, abstract ऑपरेटरों के साथ (filter, join, aggregate)।
- Physical plan: उसे असल स्टोरेज और हार्डवेयर पर कैसे चलाना है (index scan बनाम full scan, hash join बनाम nested-loop, parallel बनाम single-threaded)।
Ullman का प्रभाव इस बात पर दिखता है कि अर्थ-संरक्षण रूपांतरणों पर ज़ोर दिया जाता है: लॉजिकल प्लान को कई तरह से बदला जा सकता है बिना उत्तर बदले, फिर एक कुशल फिज़िकल रणनीति चुनी जाती है।
काम घटाने वाले नियम-आधारित री-राइट्स
अंतिम निष्पादन तरीके चुनने से पहले, ऑप्टिमाइज़र अल्जेब्राईक “सफाई” नियम लागू करते हैं। ये री-राइट्स परिणाम नहीं बदलते; ये अनावश्यक काम घटाते हैं।
सामान्य उदाहरण:
- Selection pushdown: फ़िल्टर जितना जल्दी हो सके लागू करें ताकि बाद के स्टेप्स में कम पंक्तियाँ जाएँ।
- Projection pruning: केवल ज़रूरी कॉलम रखें, I/O और मेमोरी घटेगी।
- Join reordering: पहले छोटे/intermediate परिणामों को जोड़ें (जब सुरक्षित हो), न कि SQL के सतही क्रम का पालन करें।
एक सरल री-राइट उदाहरण
मान लीजिए आप उन यूज़र्स के ऑर्डर्स चाहते हैं जो एक देश में हैं:
SELECT o.order_id, o.total
FROM users u
JOIN orders o ON o.user_id = u.id
WHERE u.country = 'CA';
एक साधारण व्याख्या सभी users को सभी orders से जोड़कर फिर Canada फ़िल्टर कर सकती है। अर्थ-संरक्षण री-राइट फ़िल्टर को नीचे धकेल देता है ताकि join कम पंक्तियों पर हो:
- users को
country = 'CA' के साथ फ़िल्टर करें
- फिर उन यूज़र्स को orders से जोड़ें
- फिर केवल
order_id और total प्रोजेक्ट करें
प्लान शब्दों में optimizer इस तरह बदलने की कोशिश करता है:
Join(Users, Orders) → Filter(country='CA') → Project(order_id,total)
के करीब कुछ इस तरह:
Filter(country='CA') on Users → Join(with Orders) → Project(order_id,total)
उसी उत्तर के साथ। कम काम।
ये री-राइट्स आप टाइप नहीं करते—फिर भी यही एक बड़ा कारण है कि वही SQL एक डेटाबेस पर तेज़ और दूसरे पर धीमा चल सकता है।
लागत-आधारित अनुकूलन (जैगरन की भाषा के बिना)
जब आप SQL चलाते हैं, डेटाबेस एक जैसे उत्तर देने वाले कई तरीकों पर विचार करता है और फिर उस रास्ते को चुनता है जिसे वह सस्ता समझता है। इस निर्णय प्रक्रिया को लागत-आधारित अनुकूलन कहते हैं—और यह रोज़मर्रा के प्रदर्शन में Ullman-जैसे सिद्धांत का एक बहुत व्यावहारिक स्थान है।
“लागत मॉडल” असल में क्या होता है
लागत मॉडल एक स्कोरिंग सिस्टम है जिसका उपयोग ऑप्टिमाइज़र विकल्पों की तुलना के लिए करता है। अधिकांश इंजन लागत का अनुमान कुछ मुख्य संसाधनों से करते हैं:
- प्रोसेस की गई पंक्तियाँ (काम सामान्यत: इससे स्केल करता है)
- I/O (डिस्क/SSD से पेज पढ़ना, कैश प्रभाव)
- CPU (फ़िल्टरिंग, हैशिंग, सॉर्टिंग, एग्रीगेट)
- मेमोरी (क्या ऑपरेशन RAM में फिट होता है या disk पर spill होता है)
मॉडल को परफेक्ट होने की ज़रूरत नहीं—बस इतना कि अक्सर सही दिशा में निर्णय करे।
कार्डिनैलिटी एस्टिमेशन, साधारण शब्दों में
कोई भी स्टेप स्कोर करने से पहले ऑप्टिमाइज़र हर स्टेप पर यह पूछता है: यह कितनी पंक्तियाँ निकालेगा? यही कार्डिनैलिटी एस्टिमेशन है।
यदि आप WHERE country = 'CA' फ़िल्टर लगाते हैं, इंजन अनुमान लगाता है कि टेबल का कितना भाग मैच करेगा। यदि आप customers को orders से जोड़ते हैं, तो वह अनुमान लगाता है कि कितने जोड़े मेल खाएँगे। ये पंक्ति-काउंट अंदाज़े यह तय करते हैं कि इंडेक्स स्कैन बेहतर है या फुल स्कैन, हैश जॉइन बेहतर है या नेस्टेड लूप, या sort छोटा है या विशाल।
स्टैटिस्टिक्स क्यों मायने रखती हैं (और बिना इनके क्या गलत होता है)
ऑप्टिमाइज़र के अनुमान स्टैटिस्टिक्स (काउंट, वैल्यू वितरण, नल दर, और कभी-कभी कॉलमों के बीच सहसंबंध) पर निर्भर करते हैं।
जब स्टैट्स पुरानी या गायब हों, इंजन पंक्ति गणनाओं का गलत अनुमान लगा सकता है। एक ऐसा प्लान जो कागज़ पर सस्ता दिखता है, वास्तविकता में महंगा बन सकता है—क्लासिक लक्षणों में डेटा वृद्धि के बाद अचानक धीरे चलना, "रैंडम" प्लान बदलाव, या जॉइन्स जो अप्रत्याशित रूप से डिस्क पर स्पिल करते हैं शामिल हैं।
अपरिहार्य ट्रेड-ऑफ: सटीकता बनाम प्लानिंग समय
बेहतर अनुमान अक्सर अधिक काम माँगते हैं: विस्तृत स्टैट्स, सैम्पलिंग, या अधिक candidate plans का परीक्षण। पर प्लानिंग खुद भी समय लेती है, खासकर जटिल क्वेरीज के लिए।
इसलिए ऑप्टिमाइज़र दो लक्ष्यों का संतुलन करते हैं:
- इंटरऐक्टिव वर्कलोड के लिए तेज़ प्लान बनाना
- ऐसा प्लान बनाना जो खराब चुनावों से बचाए
EXPLAIN आउटपुट को समझते समय यह ट्रेड-ऑफ ध्यान में रखें: ऑप्टिमाइज़र चालाक बनने की कोशिश नहीं कर रहा—यह सीमित जानकारी में पूर्वानुमाननिय रूप से सही रहने की कोशिश कर रहा है।
जॉइन एल्गोरिदम और क्वेरी प्रदर्शन का मूल
Ullman ने यह विचार लोकप्रिय किया कि SQL इतना "चलाया" नहीं जाता जितना कि उसे अनुवादित किया जाता है। यह जॉइन्स में सबसे स्पष्ट होता है। दो क्वेरीज जो वही पंक्तियाँ लौटाती हैं, उनके रनटाइम में बड़ा फर्क हो सकता है इस बात पर निर्भर करते हुए कि इंजन कौन सा जॉइन एल्गोरिदम चुना और किस ऑर्डर में जॉइन किया।
Nested loop, hash join, merge join—कब कौन सा समझदारी है
Nested loop join सरल है: बाएँ हर पंक्ति के लिए दाएँ में मैच ढूँढो। यह तब तेज़ हो सकता है जब बाएँ पक्ष छोटा हो और दाएँ पक्ष पर उपयोगी इंडेक्स हो।
Hash join एक इनपुट (अक्सर छोटा) से हैश टेबल बनाता है और दूसरे से उसे probe करता है। यह बड़े, unsorted इनपुट और बराबरी की शर्तों के लिए बढ़िया है (जैसे A.id = B.id), पर मेमोरी चाहिए; डिस्क पर स्पिल होने से फायदہ खो सकता है।
Merge join दोनों इनपुट को क्रमबद्ध होकर चलता है। यह तब अच्छा है जब दोनों पक्ष पहले से sorted हों (या आसानी से sort हो सकें), जैसे कि इंडेक्स़्स जो join-key क्रम में पंक्तियाँ दे रहे हों।
क्यों जॉइन ऑर्डर प्रदर्शन पर हावी हो सकता है
तीन या अधिक तालिकाओं के साथ, संभावित जॉइन ऑर्डर्स की संख्या बहुत बढ़ जाती है। पहले दो बड़े टेबलों को जोड़ना एक बड़ा intermediate परिणाम बना सकता है जो सबकुछ धीमा कर देगा। बेहतर क्रम अक्सर सबसे selective फ़िल्टर (सर्वन्यूनतम पंक्तियाँ) से शुरू होता है और बाहर की ओर जोड़ता है ताकि intermediate छोटे रहें।
इंडेक्स विकल्पों को बदलते हैं कि कौन से प्लान अच्छे हैं
इंडेक्स सिर्फ खोज तेज़ नहीं करते—वे कुछ जॉइन रणनीतियों को व्यवहार्य बनाते हैं। जॉइन की कुंजी पर इंडेक्स नेस्टेड लूप को हर पंक्ति के लिए तेज़ seek-पैटर्न में बदल सकता है। दूसरी ओर, गायब या अनुपयोगी इंडेक्स इंजन को हैश जॉइन या बड़े sorts की ओर धकेल सकते हैं।
व्यावहारिक चेकलिस्ट: खराब जॉइन प्लान के लक्षण
- डेटा थोडा बढ़ने पर रनटाइम नाटकीय रूप से बढ़ता है (जॉइन ऑर्डर से intermediates बढ़ रहे हैं)
- प्लान में "rows estimated vs. rows actual" में बड़े अंतर दिखते हैं (खराब कार्डिनैलिटी अनुमान)
- आप बड़े sorts या hash spills डिस्क पर देखते हैं (मेमोरी दबाव)
- छोटा filtered टेबल देर से जोड़ा जा रहा है (फ़िल्टर्स जल्दी लागू नहीं हो रहे)
- जॉइन predicate साफ़ equality और संगत प्रकारों पर नहीं है (यह हैश/मर्ज को रोकता है)
डेटाबेस इंजनों के अंदर कंपाइलर विचार
डेटाबेस सिर्फ़ SQL नहीं चलाते—वे उसे कम्पाइल करते हैं। Ullman का प्रभाव डेटाबेस सिद्धांत और कंपाइलर सोच दोनों पर है, और यह कनेक्शन बताता है कि क्वेरी इंजिन क्यों प्रोग्रामिंग भाषा टूलचेन की तरह व्यवहार करते हैं: वे अनुवाद करते, री-राइट करते, और ऑप्टिमाइज़ करते पहले कि कोई असली काम हो।
पार्सिंग और सिंटैक्टिक ट्री: SQL कैसे पढ़ा जाता है
जब आप क्वेरी भेजते हैं, पहला चरण कंपाइलर के फ्रंट-एंड जैसा दिखता है। इंजन keywords और identifiers को टोकनाइज़ करता है, व्याकरण चेक करता है, और एक parse tree बनाता है (अक्सर इसे सरल करके abstract syntax tree में बदला जाता है)। यही वह जगह है जहाँ बुनियादी त्रुटियाँ पकड़ी जाती हैं: गायब कॉमा, अस्पष्ट कॉलम नाम, अमान्य grouping नियम।
एक सहायक मानसिक मॉडल: SQL एक प्रोग्रामिंग भाषा है जिसका “प्रोग्राम” डाटा रिश्तों का वर्णन करता है बजाय लूप्स के।
parse tree से logical operators तक
कंपाइलर सिंटैक्स को एक मध्यवर्ती प्रतिनिधित्व (IR) में बदलते हैं। डेटाबेस कुछ ऐसा ही करते हैं: वे SQL सिंटैक्स को logical operators में बदलते हैं जैसे:
- Selection (फ़िल्टरिंग)
- Projection (कॉलम चुनना)
- Join (टेबल्स जोड़ना)
- Aggregation (
GROUP BY)
यह लॉजिकल रूप SQL टेक्स्ट की तुलना में रिलेशनल बीजगणित के करीब होता है, जो अर्थ और समकक्षता पर तर्क करना आसान बनाता है।
क्यों ऑप्टिमाइज़र कंपाइलर ऑप्टिमाइशनों जैसे लगते हैं
कंपाइलर ऑप्टिमाइज़ेशन प्रोग्राम परिणामों को समान रखते हुए उन्हें सस्ता बनाते हैं। डेटाबेस ऑप्टिमाइज़र यही करते हैं, नियमों के रूप में:
- फ़िल्टर पहले धकेलें (काम कम करने के लिए)
- जॉइन्स का पुन:क्रम (विभिन्न लागत, समान परिणाम)
- अनावश्यक गणनाएँ हटाएँ
यह “dead code elimination” का डेटाबेस संस्करण है: तकनीकें IDENTICAL नहीं पर दर्शन वही—संतुलन बनाए रखें और लागत कम करें।
डीबगिंग: प्लान को कंपाइल्ड कोड की तरह पढ़ना
यदि आपकी क्वेरी धीमी है, तो केवल SQL पर न टकटकी लगाएँ। EXPLAIN आउटपुट को देखें जैसे आप कंपाइलर आउटपुट पढ़ते हैं। प्लान आपको बताता है कि इंजन ने असल में क्या चुना: जॉइन ऑर्डर, इंडेक्स उपयोग, और समय कहाँ खर्च हो रहा है।
व्यावहारिक निष्कर्ष: EXPLAIN पढ़ना सीखें और इसे प्रदर्शन का “assembly listing” मानें। यह ट्यूनिंग को अंदाज़े से साक्ष्य-आधारित डीबगिंग में बदल देता है। इसके अभ्यास में मदद के लिए देखें /blog/practical-query-optimization-habits।
स्कीमा डिज़ाइन सिद्धांत जो वास्तविक प्रदर्शन को प्रभावित करते हैं
अच्छा क्वेरी प्रदर्शन अक्सर SQL लिखने से पहले ही शुरू होता है। Ullman की स्कीमा डिज़ाइन थ्योरी (खासकर normalization) इस बारे में है कि डेटा को इस तरह संरचित करें कि डेटाबेस उसे जैसे-जैसे बढ़े सही, Predictable और कुशल रख सके।
सामान्यीकरण के लक्ष्य (क्यों मौजूद है)
नॉर्मलाइज़ेशन का उद्देश्य है:
- अनॉमलीज़ घटाना (जैसे किसी ग्राहक के पते को पाँच जगह अपडेट करने पर एक छूट जाना)
- कंसिस्टेंसी सुधारना ताकि हर तथ्य एक "घर" में रहे
- कंस्ट्रेंट्स व्यक्त करना आसान बनाना (keys, foreign keys) ताकि इंजन नियम लागू कर सके न कि एप्लिकेशन को भरोसा करना पड़े
ये सहीपन लाभ बाद में प्रदर्शन लाभों में बदलते हैं: कम डुप्लिकेट फ़ील्ड, छोटे इंडेक्स, और कम महंगी अपडेट्स।
आम भाषा में नॉर्मल फॉर्म्स
सबूत याद रखने की ज़रूरत नहीं—विचार उपयोगी हैं:
- 1NF: कॉलम में एटॉमिक मान रखें (कोई comma-separated lists नहीं)। यह filtering और indexing को सरल बनाता है।
- 2NF: composite key वाली तालिकाओं में हर non-key कॉलम पूरे key पर निर्भर होना चाहिए (न कि उसका हिस्सा)। यह attributes की दोहराव से बचाता है।
- 3NF: non-key कॉलम केवल key पर निर्भर होने चाहिए, न कि अन्य non-key कॉलम पर। यह छुपी हुई duplication रोकता है।
- BCNF: 3NF का सख्त रूप जहाँ हर determinant एक candidate key हो—उपयोगी जब "लगभग यूनिक" कॉलम सूक्ष्म डुप्लिकेट बनाते हैं।
कब डीनॉर्मलाइज़ करना समझदारी है
डीनॉर्मलाइज़ेशन समझदारी हो सकती है जब:
- आप analytics-heavy तालिकाएँ बना रहे हों (wide fact tables, reporting)
- joins bottleneck बन रहे हों और आप नियंत्रित redundancy स्वीकार कर सकें
- आप पढ़ने की गति के लिए ऑप्टिमाइज़ कर रहे हों और साफ़ refresh नियम हैं (उदा., nightly rebuilds)
महत्पूर्ण बात यह है कि डीनॉर्मलाइज़ेशन इरादतन हो और duplicates को सिंक रखने की प्रक्रिया मौजूद हो।
स्कीमा चुनाव ऑप्टिमाइज़र और स्केलिंग को कैसे प्रभावित करते हैं
स्कीमा डिज़ाइन तय करती है कि ऑप्टिमाइज़र क्या कर सकता है। साफ़ keys और foreign keys बेहतर जॉइन रणनीतियाँ, सुरक्षित री-राइट्स और अधिक सटीक पंक्ति-गणना अनुमानों को सक्षम करते हैं। वहीं, अत्यधिक duplication इंडेक्स फुलता है और writes धीमी करता है, और multi-valued कॉलम कुशल predicates को रोकते हैं। डेटा बढ़ने पर ये शुरुआती मॉडलिंग निर्णय अक्सर किसी एक क्वेरी के सूक्ष्म सुधारों से ज्यादा मायने रखते हैं।
सिद्धांत बड़े सिस्टम में कैसे दिखता है
जब कोई सिस्टम "स्केल" करता है, यह दुर्लभ रूप से सिर्फ बड़ी मशीनें जोड़ने के बारे में होता है। अक्सर कठिन हिस्सा यह है कि वही क्वेरी अर्थ बनाए रखते हुए इंजन बहुत अलग फिजिकल रणनीति चुनता है ताकि रनटाइम भविष्यवाणीयोग्य रहे। Ullman का जोर औपचारिक समकक्षताओं पर ठीक वही चीज़ है जो रणनीति बदलते समय जवाब को अपरिवर्तित रखने की अनुमति देती है।
स्केल अक्सर फिज़िकल लेआउट + प्लान चुनाव है
छोटी साइज पर कई योजनाएँ "काम" कर जाती हैं। स्केल पर तालिका स्कैन, इंडेक्स उपयोग, या प्री-कम्प्यूटेड परिणाम के बीच फर्क सेकंड और घंटों का होता है। सिद्धांत पक्ष इसलिए मायने रखता है क्योंकि ऑप्टिमाइज़र को सुरक्षित री-राइट नियमों का एक सेट चाहिए (उदा., फ़िल्टर आगे धकेलना, जॉइन reorder) जो उत्तर न बदले—भले ही वे किए गए काम कोRADICALLY बदल दें।
पार्टिशनिंग वही SQL बदलती नहीं पर क्वेरी बदल देती है
पार्टिशनिंग (तिथि, ग्राहक, क्षेत्र आदि के अनुसार) एक लॉजिकल टेबल को कई भौतिक टुकड़ों में बदल देती है। इससे प्लानिंग प्रभावित होती है:
- कौन से partitions स्किप किए जा सकते हैं (partition pruning)
- क्या जॉइन्स partitions के भीतर होते हैं या नोड्स के बीच डेटा शफल चाहिए
- क्या grouping लोकली किया जा सकता है पहले फिर परिणाम combine करें
SQL टेक्स्ट अपरिवर्तित रह सकता है, पर सबसे अच्छा प्लान अब इस पर निर्भर करेगा कि पंक्तियाँ कहाँ रहती हैं।
मटेरियलाइज़्ड व्यूज़: प्री-कम्प्यूटेशन अलजेब्राईक शॉर्टकट की तरह
मटेरियलाइज़्ड व्यूज़ मूलतः "सहेजे हुए उप-अभिव्यक्तियाँ" हैं। अगर इंजन यह सिद्ध कर सकता है कि आपकी क्वेरी किसी स्टोर किए गए परिणाम से मेल खाती है (या उसी में बदली जा सकती है), तो वह महंगे काम—जैसे बार-बार joins और aggregations—को तेज़ lookup से बदल सकता है। यह प्रायोगिक रूप से रिलेशनल बीजगणित का उपयोग है: समकक्षता पहचानें और पुन: उपयोग करें।
कैशिंग मददगार है, पर गलत काम का आकार नहीं बदल सकती
कैशिंग बार-बार पढ़ने को तेज़ कर सकती है, पर वह उस क्वेरी को ठीक नहीं कर सकती जिसे बहुत सारा डेटा स्कैन करना पड़ता है, विशाल intermediate results शफल करने पड़ते हैं, या एक बड़ा जॉइन करना पड़ता है। स्केल समस्याओं के सामने अक्सर समाधान होता है: छूने वाले डेटा की मात्रा घटाएँ (layout/partitioning), बार-बार की गणना घटाएँ (materialized views), या प्लान बदलें—सिर्फ़ "कैश जोड़ें" नहीं।
Ullman से प्रेरित व्यावहारिक ऑप्टिमाइज़ेशन आदतें
Ullman का प्रभाव एक सरल मानसिकता में दिखता है: धीमी क्वेरी को उस इरादे के रूप में देखें जिसे डेटाबेस बना सकता है, फिर पुष्टि करें कि उसने वास्तव में क्या फैसला किया। आपको सिद्धांतज्ञ बनने की ज़रूरत नहीं—आप बस दोहरनीय दिनचर्या अपनाएँ।
1) EXPLAIN प्लान पढ़ें: सबसे पहले किस पर ध्यान दें
जो हिस्से आम तौर पर रनटाइम को नियंत्रित करते हैं उनके साथ शुरू करें:
- Access method: क्या इंजन पूरी तालिका स्कैन कर रहा है जब आप इंडेक्स lookup की उम्मीद करते थे?
- Row estimates vs. actuals (यदि DB यह दिखाता है): बड़े गैप अक्सर अजीब धीमापन समझाते हैं।
- Join order: कौन सा टेबल ड्राइव कर रहा है और क्या यह सबसे selective फ़िल्टर से शुरू होता है?
- Expensive operators: sorts, hash builds, बड़े nested loops—आम तौर पर यही बताते हैं कि काम कहाँ है।
अगर आप सिर्फ़ एक काम करें, तो उस पहले ऑपरेटर की पहचान करें जहाँ पंक्ति संख्या अचानक फट जाती है। वहीं अक्सर मूल कारण होता है।
2) आम एंटी-पैटर्न्स जो ऑप्टिमाइज़र को हराम करते हैं
ये लिखना आसान है पर महंगा पड़ सकता है:
- इंडेक्स्ड कॉलम पर फंक्शन्स:
WHERE LOWER(email) = ... इंडेक्स उपयोग रोक सकती है (समर्थन होने पर functional index या normalized कॉलम का उपयोग करें)।
- गायब predicates: date range या tenant फ़िल्टर भूल जाने से लक्षित क्वेरी बड़े स्कैन में बदल सकती है।
- अनजाने में cross joins: missing join condition पंक्तियाँ गुणा कर सकती है और huge intermediates बना सकती है।
3) अल्जेब्राईक सोच के साथ एक परिकल्पना बनाइए
रिलेशनल बीजगणित दो व्यावहारिक कदम बढ़ावा देती है:
- Filters को पहले धकेलें: जहां संभव हो
WHERE शर्तों को joins से पहले लागू करें ताकि inputs छोटे हों।
- कम कॉलम पहले रखें: joins से पहले केवल ज़रूरी कॉलम चुनें ताकि मेमोरी और I/O घटे।
एक अच्छी परिकल्पना कुछ ऐसी होगी: “यह जॉइन महंगा है क्योंकि हम बहुत सारी पंक्तियाँ जोड़ रहे हैं; यदि हम orders को पहले पिछले 30 दिनों तक फ़िल्टर करें तो join इनपुट घट जाएगा।”
4) इंडेक्स, री-राइट, या स्कीमा बदलें?
एक सरल निर्णय नियम इस्तेमाल करें:
- इंडेक्स जोड़ें जब क्वेरी सही, selective और बार-बार चलने वाली हो।
- क्वेरी फिर से लिखें जब
EXPLAIN दिखाए कि अवॉयडेबल काम हो रहा है (अनावश्यक joins, देर से फ़िल्टर, non-sargable predicates)।
- स्कीमा बदलें जब वर्कलोड पैटर्न स्थिर हो और आप बार-बार उसी bottleneck से जूझ रहे हों (जैसे precomputed aggregates, denormalized lookup fields, या time/tenant के आधार पर partitioning)।
लक्ष्य "बुद्धिमान SQL" नहीं है; यह predictable, छोटे intermediate results है—वही समकक्षता-संरक्षण सुधार जिनको Ullman के विचार आसानी से पहचानने में मदद करते हैं।
इन्हें असली प्रोडक्ट्स में लागू करना
ये अवधारणाएँ सिर्फ़ DBA के लिए नहीं हैं। अगर आप एक एप्लिकेशन भेज रहे हैं, तो आप डेटाबेस और क्वेरी-प्लानिंग निर्णय ले रहे होते हैं चाहे आप जान रहे हों या नहीं: स्कीमा आकार, key विकल्प, क्वेरी पैटर्न, और डेटा एक्सेस लेयर—ये सभी ऑप्टिमाइज़र को प्रभावित करते हैं।
यदि आप vibe-coding वर्कफ़्लो (उदा., chat इंटरफ़ेस से React + Go + PostgreSQL ऐप जनरेट करना Koder.ai में) उपयोग कर रहे हैं, तो Ullman-शैली के मानसिक मॉडल एक व्यावहारिक सुरक्षा नेट हैं: आप जनरेट किए गए स्कीमा की समीक्षा कर सकते हैं कि क्या clean keys और relationships हैं, अपनी ऐप की भरोसा-योग्य क्वेरीज को जांच सकते हैं, और EXPLAIN के साथ प्रदर्शन मान्य कर सकते हैं इससे पहले कि प्रोडक्शन में समस्याएँ दिखें। जितनी तेज़ आप "क्वेरी इरादा → प्लान → फिक्स" पर iterate कर पाएँगे, उतना अधिक मूल्य आप accelerated development से पाएँगे।
अधिक सीखने के स्रोत और इन्हें काम पर कैसे लागू करें
आपको सिद्धांत को अलग शौक के रूप में पढ़ने की ज़रूरत नहीं। Ullman-शैली की बुनियाद से सबसे तेज़ लाभ उठाने का तरीका यह है कि आप प्लान पढ़ना सीखें—और फिर अपने डेटाबेस पर अभ्यास करें।
शुरुआत के अनुकूल संसाधन
इन पुस्तकों और व्याख्यान विषयों की खोज करें (कोई संबद्धता नहीं—सिर्फ व्यापक रूप से उद्धृत प्रारंभिक बिंदु):
- “A First Course in Database Systems” (Ullman & Widom) — पहुँचने योग्य डेटाबेस नींव के साथ व्यावहारिक फ्रेमिंग।
- “Principles of Database and Knowledge-Base Systems” (Ullman) — यदि आप अधिक कठोरता चाहते हैं तो गहराई।
- “Compilers: Principles, Techniques, and Tools” (Aho, Lam, Sethi, Ullman) — "क्यों ऑप्टिमाइज़र कंपाइलरों से मिलते-जुलते हैं" कनेक्शन के लिए।
- व्याख्यान/सर्च विषय: relational algebra, query rewriting, join ordering, cost-based optimization, indexes and selectivity, parsing and query languages।
हल्का सीखने का रास्ता
छोटे से शुरू करें और हर कदम को कुछ ऐसे से जोड़े जिसे आप देख सकें:
- रिलेशनल बीजगणित: selection, projection, join, और समकक्षता नियम सीखें।
- प्लान: प्लान नोड्स पढ़ना सीखें (scan types, filters, joins, sorts, aggregates)।
- जॉइन्स: nested loop बनाम hash join बनाम merge join और कब कौन सा जीतता है समझें।
- कास्ट मॉडल: निर्णयों को प्रभावित करने वाले कुछ इनपुट सीखें (row counts, selectivity, I/O बनाम CPU)।
छोटे अभ्यास जो तेजी से लाभ देते हैं
2–3 वास्तविक क्वेरीज चुनें और परीक्षण करें:
- रिवाइट:
IN को EXISTS में बदलें, predicates को आगे धकेलें, अनावश्यक कॉलम हटाएँ, और परिणामों की तुलना करें।
- प्लान की तुलना: “पहले/बाद” प्लानों को कैप्चर करें और नोट करें क्या बदला (जॉइन ऑर्डर, जॉइन टाइप, स्कैन टाइप)।
- इंडेक्स बदलें: एक-एक करके इंडेक्स जोड़/हटाएँ और अनुमानित बनाम वास्तविक पंक्तियों को देखें।
टीममेट्स को कैसे बताएं
साफ़, प्लान-आधारित भाषा प्रयोग करें:
- “प्लान एक sequential scan से index scan पर गया क्योंकि फ़िल्टर selective हो गया।”
- “Row estimates 100× off थे, इसलिए optimizer ने गलत जॉइन ऑर्डर चुना।”
- “यह रिवाइट समकक्ष है (एक ही परिणाम), पर यह predicate pushdown को सक्षम करता है और join में कम पंक्तियाँ भेजता है।”
यही Ullman की नींव का व्यावहारिक लाभ है: आपको प्रदर्शन समझाने के लिए एक साझा शब्दावली मिलती है—बिना अटकलों के।