09 जुल॰ 2025·8 मिनट
जो आर्मस्ट्रांग और एर्लैंग: भरोसेमंद प्लेटफ़ॉर्म के लिए "लेट इट क्रैश"
जानिए कि जो आर्मस्ट्रांग ने कैसे एर्लैंग के समवर्तीपन, निगरानी और 'लेट इट क्रैश' सोच को आकार दिया — ऐसे विचार जो आज भी भरोसेमंद रियल‑टाइम सेवाएँ बनाने में काम आते हैं।
यह पोस्ट क्या कवर करती है (और क्यों यह आज भी मायने रखता है)
जो आर्मस्ट्रांग ने सिर्फ़ एर्लैंग बनाया ही नहीं—वह इसे सबसे स्पष्ट और प्रभावी तरीके से समझाने वाले थे। टॉक्स, पेपर्स, और एक व्यवहारिक दृष्टिकोण के ज़रिये उन्होंने एक सरल बात लोकप्रिय की: अगर आप ऐसा सॉफ़्टवेयर चाहते हैं जो लगातार चलना जारी रखे, तो आप असफलता के लिए डिज़ाइन करें बजाय यह मानने के कि आप उसे टाल लेंगे।
यह पोस्ट एर्लैंग के माइंडसेट का मार्गदर्शक दौरा है और बताती है कि जब आप भरोसेमंद रियल‑टाइम प्लेटफ़ॉर्म बनाते हैं—जैसे चैट सिस्टम, कॉल रूटिंग, लाइव नोटिफिकेशन, मल्टीप्लेयर समन्वय, और ऐसी इंफ्रास्ट्रक्चर जो जल्दी और सुसंगत प्रतिक्रिया देनी चाहिए—तो ये विचार क्यों आज भी उपयोगी हैं।
"रियल‑टाइम" सरल शब्दों में
रियल‑टाइम का मतलब हमेशा “माइक्रोसेकंड” या “हार्ड डेडलाइन” नहीं होता। कई प्रोडक्ट्स में इसका मतलब होता है:
- उपयोगकर्ता महसूस कर सकें ऐसी तेज़ प्रतिक्रियाएँ (कोई अजीब ठहराव न हो)
- लोड में भी पूर्वानुमान योग्य व्यवहार (धीम तो हो सकता है, पर बिगड़ना नहीं चाहिए)
- आंशिक विफलताओं में भी सेवा जारी रहे (एक खराब कंपोनेंट सब कुछ नीचे न खींचे)
एर्लैंग टेलीकॉम सिस्टम्स के लिए बनाया गया था जहाँ ये अपेक्षाएँ गैर‑मोल्यवान थीं—और उसी दबाव ने इसके सबसे प्रभावशाली विचारों को आकार दिया।
वे तीन स्तम्भ जिन पर हम ध्यान देंगे
सिन्टैक्स में गोता लगाने की बजाय, हम उन कॉन्सेप्ट्स पर ध्यान देंगे जिन्होंने एर्लैंग को चर्चित बनाया और जो आधुनिक सिस्टम डिजाइन में बार‑बार लौटकर आते हैं:
- डिफ़ॉल्ट रूप से समवर्तीता: बड़े, सर्व-समर्थ कार्यक्रमों की बजाय छोटे, अलग नौकरी करने वाले वर्करों से सिस्टम बनाइए।
- डिज़ाइन लक्ष्य के रूप में फॉल्ट टॉलरेंस: मान लीजिए कि बग, टाइमआउट और क्रैश होंगे—और तय करिए कि फिर क्या होना चाहिए।
- “लेट इट क्रैश”: हर लाइन को अत्यधिक रक्षा न करें; फेल तेज़ी से होने दें और संरचना (हीरोइक्स नहीं) से साफ़‑सुथरा रिकवरी करें।
रास्ते में हम इन विचारों को अभिनेता मॉडल और मैसेज पासिंग से जोड़ेंगे, सुपरविजन ट्रीज़ और OTP को आसान शब्दों में समझाएँगे, और दिखाएँगे कि BEAM VM कैसे पूरे दृष्टिकोण को व्यावहारिक बनाता है।
चाहे आप एर्लैंग इस्तेमाल कर रहे हों या नहीं, आर्मस्ट्रांग की रूपरेखा आपको ऐसे सिस्टम बनाने के लिए एक शक्तिशाली चेकलिस्ट देती है जो असल दुनिया में गड़बड़ी के बावजूद उत्तरदायी और उपलब्ध रहते हैं।
जो आर्मस्ट्रांग की प्रेरणा: ऐसे सिस्टम बनाना जो चलते रहें
टेलीकॉम स्विच और कॉल‑रूटिंग प्लेटफ़ॉर्म "मेंटेनेंस के लिए डाउन" नहीं हो सकते जिस तरह कई वेबसाइट्स हो सकती हैं। उन्हें कॉल हैंडल करना, बिलिंग इवेंट्स और सिग्नलिंग ट्रैफ़िक चक्कर में रखने की उम्मीद रहती है—अक्सर सख़्त उपलब्धता और पूर्वानुमान‑योग्य प्रतिक्रिया समय की मांग के साथ।
एर्लैंग 1980s के अंत में Ericsson के अंदर इन यथार्थों को सॉफ्टवेयर के जरिए पूरा करने की कोशिश थी, सिर्फ़ विशेष हार्डवेयर नहीं। जो आर्मस्ट्रांग और उनके सहयोगी शानदारता के पीछे नहीं भाग रहे थे; वे ऐसे सिस्टम बनाना चाहते थे जिनपर ऑपरेटर लगातार लोड, आंशिक विफलताओं और वास्तविक दुनिया की गड़बड़ियों के दौरान भरोसा कर सकें।
व्यवहार में “भरोसेमंद” का मतलब
सोच में एक प्रमुख बदलाव यह है कि भरोसेमंद होना "कभी न फेल होना" बराबर नहीं है। बड़े, लंबे समय चलने वाले सिस्टम्स में कुछ न कुछ फेल होगा: एक प्रोसेस अनपेक्षित इनपुट पर फँस सकता है, कोई नोड रीबूट हो सकता है, नेटवर्क लिंक झटके खा सकता है, या कोई निर्भरता अटक सकती है।
तो लक्ष्य बनता है:
- उपयोगकर्ताओं को सेवा देते रहना जब कुछ हिस्से गड़बड़ करें
- विफलताओं का जल्दी पता लगाना
- न्यूनतम मानव हस्तक्षेप के साथ स्वचालित तौर पर रिकवर करना
- दोषों को अलग रखना ताकि एक बग सब कुछ नीचे न खींचे
यही माइंडसेट बाद में सुपरविजन ट्रीज़ और "लेट इट क्रैश" जैसे विचारों को तर्कसंगत बनाता है: आप विफलता को एक सामान्य घटना के रूप में डिज़ाइन करते हैं, न कि एक असाधारण आपदा के रूप में।
कम मिथक, अधिक समस्या‑समाधान
कहानी को एक अकेले विज़नरी की सफलता के रूप में बताना आकर्षक है। पर उपयोगी दृष्टि ज्यादा सरल है: टेलीकॉम की सीमाओं ने अलग‑तरह के ट्रेड‑ऑफ़ थोपे। एर्लैंग ने समवर्तीता, पृथक्करण, और रिकवरी को प्राथमिकता दी क्योंकि वे वही व्यावहारिक उपकरण थे जिनसे सेवाएँ तब भी चलती रह सकें जब दुनिया बदलती रहती।
यह समस्या‑पहले वाला फ्रेम भी इसलिए आज के समय में ठीक बैठता है—जहाँ भी अपटाइम और तेज़ रिकवरी परफ़ेक्ट प्रिवेंशन से ज़्यादा महत्वपूर्ण हो।
डिफ़ॉल्ट के रूप में समवर्तीता: कई छोटे वर्कर
एर्लैंग का मूल विचार यह है कि “एक साथ कई काम करना” कोई अतिरिक्त फ़ीचर नहीं है जिसे बाद में जोड़ा जाए—यह वह सामान्य तरीका है जिससे आप सिस्टम को संरचित करते हैं।
हल्के‑वज़न प्रोसेसेस, सरल शब्दों में
एर्लैंग में काम को बहुत से छोटे “प्रोसेसेस” में बाँटा जाता है। इन्हें छोटे वर्करों की तरह सोचिए, हर एक एक काम के लिए जिम्मेदार: एक फोन कॉल संभालना, एक चैट सत्र ट्रैक करना, एक डिवाइस मॉनिटर करना, पेमेंट को रीट्राय करना, या एक क्यू देखना।
ये हल्के‑वज़न होते हैं, मतलब आप इन्हें बहुत बड़ी संख्या में चला सकते हैं बिना भारी हार्डवेयर की ज़रूरत के। एक बड़े, भारी वर्कर के बजाय जो सब कुछ संभालने की कोशिश करे, आपके पास कई केन्द्रित वर्कर होते हैं जो जल्दी शुरू होते हैं, जल्दी बंद होते हैं, और जल्दी बदले जा सकते हैं।
"एक बड़ा प्रोग्राम" अलग तरह से क्यों टूटता है
कई सिस्टम एक बड़े प्रोग्राम की तरह डिज़ाइन होते हैं जिनके कई हिस्से काफ़ी जुड़े होते हैं। जब ऐसा सिस्टम किसी गंभीर बग, मेमोरी समस्या, या ब्लॉकिंग ऑपरेशन से टकराता है, तो विफलता चारों ओर फैल सकती है—जैसे एक ब्रेकर ट्रिप करके पूरा भवन अँधेरा कर दे।
एर्लैंग इसके विपरीत धक्का देता है: जिम्मेदारियों को अलग करें। अगर एक छोटा वर्कर गलत व्यवहार करे, आप उस वर्कर को गिराकर बदल सकते हैं बिना असंबंधित काम को नीचे किए।
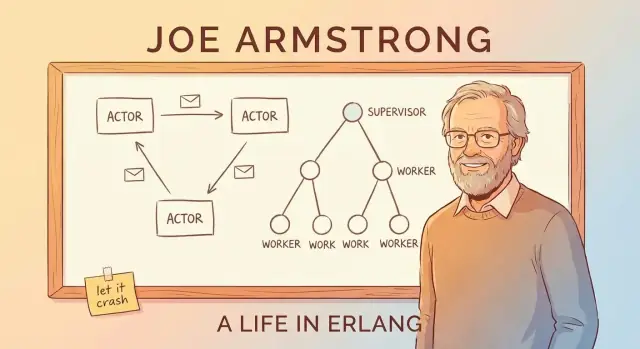
मैसेज पासिंग को “नोट भेजना” समझिए
इन वर्करों का समन्वय कैसे होता है? वे एक दूसरे की भीतरी स्थिति में हाथ नहीं डालते। वे संदेश भेजते हैं—ज्यादा तरह से नोट पास करने जैसे, बजाय एक गंदे वाइटबोर्ड को साझा करने के।
एक वर्कर कह सकता है, “यहाँ एक नया अनुरोध है,” “यह यूज़र डिस्कनेक्ट हो गया,” या “5 सेकंड में फिर कोशिश करो।” रिसीविंग वर्कर नोट पढ़ता है और फैसला करता है कि क्या करना है।
मुख्य लाभ है कंटेनमेंट: क्योंकि वर्कर अलग‑अलग हैं और संदेशों से बात करते हैं, विफलताएँ पूरे सिस्टम में फैलने की संभावना कम हो जाती है।
मैसेज पासिंग और अभिनेता मॉडल (ज्यादा जार्गन के बिना)
एर्लैंग के "अभिनेताओं" के मॉडल को समझने का सरल तरीका है: एक सिस्टम की कल्पना करें जो बहुत सारे छोटे, स्वतंत्र वर्करों से बना है।
अभिनेता: छोटे वर्कर जो केवल संदेश भेजकर बात करते हैं
एक actor एक आत्म‑निहित यूनिट है जिसकी अपनी निजी स्थिति और एक मेलबॉक्स होता है। यह तीन बुनियादी चीजें करता है:
- मेलबॉक्स से (एक‑एक करके) संदेश प्राप्त करता है
- अपनी आंतरिक स्थिति अपडेट करता है
- अन्य अभिनेताओं को संदेश भेजता है
बस इतना ही। कोई छिपा साझा वैरिएबल नहीं, कोई दूसरे वर्कर की मेमोरी में हाथ नहीं। अगर एक अभिनेता को दूसरे से कुछ चाहिए, तो वह संदेश भेजकर माँगता है।
साझा स्टेट से बचने से किस तरह के बग दूर होते हैं
जब कई थ्रेड एक ही डेटा शेयर करते हैं, तो रेस कंडीशन्स हो सकती हैं: दो अलग घटनाएँ लगभग एक साथ वही वैल्यू बदलती हैं और परिणाम टाइमिंग पर निर्भर करता है। यही बग्स इंटरमिटेंट और रीप्रोड्यूस करने में मुश्किल होते हैं।
मैसेज पासिंग के साथ, हर अभिनेता अपना डेटा मालिक होता है। दूसरे सीधे उसमें म्युटेट नहीं कर सकते। इससे समवर्ती एक्सेस से होने वाली समस्याएँ काफी हद तक घट जाती हैं।
बैक‑प्रेशर, एक कॉफी शॉप की कतार की तरह
संदेश “मुफ़्त” नहीं आते। अगर कोई अभिनेता उसे मिलने वाले संदेशों को प्रोसेस करने से तेज़ी से संदेश पा रहा है, तो उसका मेलबॉक्स बढ़ेगा। यही बैक‑प्रेशर है: सिस्टम अप्रत्यक्ष रूप से कह रहा है, “यह हिस्सा ओवरलोड है।”
व्यवहार में, आप मेलबॉक्स साइज़ मॉनिटर करते हैं और सीमाएँ बनाते हैं: लोड घटाना, बैच करना, सैम्पल करना, या काम को और वर्करों में बाँटना बजाय की क्यू को अनंत तक बढ़ने देना।
एक ठोस उदाहरण: चैट नोटिफिकेशन्स
एक चैट ऐप की कल्पना करें। प्रत्येक यूज़र के लिए एक अभिनेता हो सकता है जो नोटिफिकेशन डिलीवर करने के लिए जिम्मेदार हो। जब यूज़र ऑफ़लाइन हो जाता है, तो संदेश आते रहते हैं—तो मेलबॉक्स बढ़ जाता है। एक अच्छे डिज़ाइन वाला सिस्टम क्यू को कैप कर सकता है, नॉन‑क्रिटिकल नोटिफिकेशन ड्रॉप कर सकता है, या डाइजेस्ट मोड में स्विच कर सकता है, बजाय कि एक धीमे यूज़र की वजह से पूरी सेवा को घटित होने दे।
“लेट इट क्रैश” समझाया गया: फेल फ़ास्ट, और तेज़ रिकवरी
“लेट इट क्रैश” ढीले इंजीनियरिंग का नारा नहीं है। यह एक विश्वसनीयता रणनीति है: जब कोई कंपोनेंट बुरी या अनपेक्षित स्थिति में पहुँचता है, तो उसे धीमे चलने की बजाय तेज़ और जोरदार तरीके से बंद होना चाहिए।
असल में इसका क्या मतलब है
एक ही प्रोसेस के अंदर हर संभव किनारे‑केस को संभालने की बजाय, एर्लैंग प्रोत्साहित करता है कि हर वर्कर छोटा और केंद्रित रहे। अगर वह वर्कर किसी ऐसी चीज़ से टकराता है जिसे वह संभाल ही नहीं सकता (करप्ट स्टेट, टूटे हुए अनुमानों, अनपेक्षित इनपुट), तो वह exit कर देता है। सिस्टम का दूसरा हिस्सा उसे वापस लाने का ज़िम्मा उठाता है।
यह मुख्य सवाल को बदल देता है: “हम विफलता को कैसे रोकें?” से “विफलता होने पर हम साफ़‑सुथरे तरीके से कैसे रिकवर करें?” पर।
ट्रेड‑ऑफ: कम रक्षात्मक चेक्स, स्पष्ट लॉजिक
हर जगह रक्षात्मक प्रोग्रामिंग सरल फ्लोज़ को शर्तों, रिट्राइज़, और आंशिक स्टेट के भूलभुलैया में बदल सकती है। “लेट इट क्रैश” कुछ इन‑प्रोसेस जटिलताओं का व्यापार करती है:
- सरल, पठनीय कोड पाथ
- टूटे हुए अनुमानों का तेज़ पता लगना
- रिकवरी जो केंद्रीकृत और सुसंगत हो (क्योंकि नियम वहीँ पर हैं)
बड़ा विचार यह है कि रिकवरी को पहले से तय और दोहराने योग्य होना चाहिए, न कि हर फ़ंक्शन में अचानक improvisation।
कब यह फिट बैठता है—और कब नहीं
यह तब सबसे अच्छा बैठता है जब विफलताएँ रिकवरेबल और पृथक हों: अस्थायी नेटवर्क समस्या, खराब अनुरोध, अटकी हुई वर्कर, या थर्ड‑पार्टी टाइमआउट।
यह उन मामलों में खराब फिट है जहाँ क्रैश अपरिवर्तनीय नुकसान कर सकता है, जैसे:
- बिना किसी दृढ़ स्रोत के डेटा लॉस
- सेफ़्टी‑क्रिटिकल ऑपरेशन्स जहाँ "फिर कोशिश करो" स्वीकार्य नहीं है
तेज़ रीस्टार्ट और ज्ञात‑अच्छी स्थिति
क्रैश तब ही मददगार होता है जब वापस आना तेज़ और सुरक्षित हो। व्यवहार में, इसका मतलब है वर्करों को एक ज्ञात‑अच्छी स्थिति में रीस्टार्ट करना—अक्सर कॉन्फ़िगरेशन पुनःलोड करना, इन‑मेमरी कैशेस को दृढ़ स्टोरेज से फिर से बनाना, और बिना यह दिखावा किए काम फिर से शुरू करना कि टूटे हुए स्थिति कभी थी ही नहीं।
सुपरविजन ट्रीज़: जानबूझकर विफलता के लिए डिज़ाइन
रीयल-टाइम प्रोटोटाइप बनाएं
Koder.ai में चैट प्रॉम्प्ट से बनाकर भरोसेमंद विचारों को कामकाजी ऐप में बदलें।
एर्लैंग का “लेट इट क्रैश” तब ही काम करता है जब क्रैश को छोड़ दिया न जाए। मुख्य पैटर्न है सुपरविजन ट्री: एक हायरेरकी जहाँ सुपरवाइज़र मैनेजर की तरह होते हैं और वर्कर असल काम करते हैं (कॉल हैंडल करना, सत्र ट्रैक करना, क्यू उपभोग करना, आदि)। जब कोई वर्कर गड़बड़ करता है, मैनेजर नोटिस करता है और उसे रीस्टार्ट कर देता है।
वर्करों को रीस्टार्ट करने वाले मैनेजर
एक सुपरवाइज़र टूटी हुई चीज़ को जगह में “ठीक” करने की कोशिश नहीं करता। बल्कि वह एक सरल, सुसंगत नियम अपनाता है: अगर वर्कर मर गया, तो एक नया शुरू कर दो। इससे रिकवरी पथ पूर्वानुमान‑योग्य हो जाता है और कोड में बिखरी हुई एड‑हॉक एरर हैंडलिंग की ज़रूरत कम होती है।
इतना ही नहीं, सुपरवाइज़र यह भी तय कर सकते हैं कि कब रीस्टार्ट न करना चाहिए—अगर कुछ बार जल्दी‑जल्दी क्रैश हो रहा है, तो बार‑बार रीस्टार्ट करना स्थिति को और खराब कर सकता है।
रीस्टार्ट रणनीतियाँ (उच्च‑स्तर)
सुपरविजन एक‑साइज़‑फिट‑ऑल नहीं है। आम रणनीतियाँ हैं:
- One‑for‑one: सिर्फ़ फेल हुए वर्कर को रीस्टार्ट किया जाता है। यह स्वतंत्र कार्यों के लिए फिट बैठता है जहाँ एक विफलता दूसरों को प्रभावित न करे।
- Group restarts: अगर एक वर्कर फेल करे, तो संबंधित सेट को साथ में रीस्टार्ट किया जाता है। यह कड़े‑तौर पर जुड़े घटकों के लिए अच्छा है जो सिंक में रहना ज़रूरी है।
निर्भरताएँ: वह हिस्से जिनपर सोचना ज़रूरी है
अच्छा सुपरविजन डिज़ाइन निर्भरता मानचित्र से शुरू होता है: कौन‑कौन से कंपोनेंट किन पर निर्भर हैं, और उनके लिए "ताज़ा शुरू" का असल अर्थ क्या है।
अगर एक सेशन हैंडलर किसी कैश प्रोसेस पर निर्भर है, तो सिर्फ़ हैंडलर को रीस्टार्ट करने से वह एक खराब स्टेट से जुड़ा रह सकता है। उन्हें सही सुपरवाइज़र के अधीन समूहबद्ध करना (या उन्हें साथ में रीस्टार्ट करना) गंदे विफलता‑मोड्स को सुसंगत, दोहराने योग्य रिकवरी व्यवहार में बदल देता है।
OTP: भरोसेमंद सेवाओं के लिए पुन:प्रयोगी पार्ट्स
यदि एर्लैंग भाषा है, तो OTP (Open Telecom Platform) वह किट है जो "लेट इट क्रैश" को वर्षों तक प्रोडक्शन में चलाने योग्य बनाता है।
OTP को एक टूलबॉक्स के रूप में देखें
OTP कोई एक लाइब्रेरी नहीं है—यह कन्वेंशन्स और तैयार‑मौजूद घटकों (जिसे behaviours कहा जाता है) का सेट है जो सेवाएँ बनाते समय उबाऊ पर महत्वपूर्ण समस्याओं का हल देता है:
gen_serverउन लंबे समय चलने वाले वर्करों के लिए जो एक समय में अनुरोध संभालते हुए स्टेट रखते हैंsupervisorस्वचालित रूप से फेल हुए वर्करों को स्पष्ट नियमों के अनुसार रीस्टार्ट करता हैapplicationयह परिभाषित करता है कि एक पूरी सर्विस कैसे शुरू और बंद होती है और एक रिलीज़ में कैसे फिट बैठती है
ये "जादू" नहीं हैं, बल्कि टेम्पलेट हैं जिनके निश्चित कॉलबैक्स होते हैं, ताकि आपका कोड हर प्रोजेक्ट में नया आकार गढ़ने की बजाय एक ज्ञात आकार में फिट हो जाए।
क्यूँ स्टैण्डर्ड पैटर्न कस्टम फ्रेमवर्क से बेहतर हैं
टीमें अक्सर एड‑हॉक बैकग्राउंड वर्कर, होमग्रोन मॉनिटरिंग हुक, और वन‑ऑफ रीस्टार्ट लॉजिक बनाती हैं। यह काम करता है—जब तक नहीं करता। OTP जोखिम को कम करता है क्योंकि यह सभी को एक ही शब्दावली और लाइफसायकल की ओर धकेलता है। जब नई इंजीनियर टीम में आती है, उन्हें आपके कस्टम फ्रेमवर्क को सीखने की बजाय साझा पैटर्न पर भरोसा करने का मौका मिलता है जो एर्लैंग पारिस्थितिकी में व्यापक रूप से समझे जाते हैं।
OTP रोज़मर्रा की वास्तुकला में किस तरह मार्गदर्शन करता है
OTP आपको प्रोसेस रोल्स और ज़िम्मेदारियों के संदर्भ में सोचने के लिए प्रेरित करता है: क्या वर्कर है, क्या कोऑर्डिनेटर है, क्या किसे रीस्टार्ट करना चाहिए, और क्या कभी ऑटोमैटिकली रीस्टार्ट नहीं होना चाहिए।
यह साफ़ नामकरण, स्पष्ट स्टार्टअप ऑर्डर, पूर्वानुमान‑योग्य शटडाउन, और इन‑बिल्ट मॉनिटरिंग सिग्नल जैसे अच्छे हाइजीन को भी प्रोत्साहित करता है। नतीजा ऐसा सॉफ़्टवेयर है जो लगातार चलने के लिए डिज़ाइन किया गया है—ऐसी सेवाएँ जो दोषों से रिकवर कर सकती हैं, समय के साथ विकसित हो सकती हैं, और बार‑बार इंसानी देखरेख की ज़रूरत के बिना अपना काम करती रहें।
BEAM VM: वह रनटाइम जो मॉडल को व्यावहारिक बनाता है
एक्टर-स्टाइल दृष्टिकोण का परीक्षण करें
चैट या नोटिफिकेशन सर्विस का प्रोटोटाइप बनाएं और बिना बोइलरप्लेट हाथ से लिखे तेज़ी से इटरेट करें।
एर्लैंग के बड़े विचार—छोटे प्रोसेसेस, मैसेज पासिंग, और "लेट इट क्रैश"—प्रोडक्शन में उपयोग करना BEAM वर्चुअल मशीन के बिना बहुत मुश्किल होता। BEAM वह रनटाइम है जो इन पैटर्न्स को नाजुक नहीं बल्कि स्वाभाविक बनाता है।
शेड्यूलिंग: "एक बड़े थ्रेड" की बजाय निष्पक्षता
BEAM बड़े पैमाने पर हल्के‑वज़न प्रोसेसेस चलाने के लिए बना है। ऑपरेटिंग सिस्टम के कुछ थ्रेड्स पर निर्भर होने और एप्लिकेशन के सही व्यवहार की उम्मीद करने के बजाय, BEAM स्वयं एर्लैंग प्रोसेसेस का शेड्यूलिंग करता है।
व्यवहारिक लाभ है लोड के दौरान उत्तरदायित्व: काम को छोटे टुकड़ों में काटकर निष्पादित किया जाता है और निष्पक्ष रूप से घुमाया जाता है, ताकि कोई भी व्यस्त वर्कर लंबे समय तक सिस्टम पर हावी न हो। यह कई स्वतंत्र कार्यों से बने सर्विस के साथ बिल्कुल मेल खाता है—हर एक थोड़ा काम करता है, फिर yielding करता है।
पृथक्करण और "प्रति‑प्रोसेस" मेमोरी क्लीनअप
प्रत्येक एर्लैंग प्रोसेस की अपनी ही हीप और अपनी ही गार्बेज कलेक्शन होती है। यह एक की प्रमुख बात है: एक प्रोसेस में मेमोरी साफ़ करने के लिए पूरे प्रोग्राम को रोकना आवश्यक नहीं है।
इतना ही महत्वपूर्ण, प्रोसेसेस अलग‑अलग हैं। अगर एक क्रैश हो जाए, तो वह दूसरों की मेमोरी को करप्ट नहीं कर सकता, और VM जीवित रहता है। यह पृथक्करण वह नींव है जो सुपरविजन ट्रीज़ को व्यावहारिक बनाती है: विफलता को कंटेन किया जाता है, फिर असफल हिस्से को रीस्टार्ट करके संभाला जाता है बजाय पूरे सिस्टम को नीचे करने के।
डिस्ट्रिब्यूशन: कई नोड्स, एक सिस्टम
BEAM वितरण का समर्थन भी सीधा‑सा तरीका देता है: आप कई एर्लैंग नोड्स (अलग VM इंस्टेंसेज़) चला सकते हैं और उन्हें संदेश भेजकर बातचीत करने दे सकते हैं। अगर आपने समझा है कि "प्रोसेसेस मैसेज भेजते हैं", तो वितरण उसी विचार का विस्तारा है—कुछ प्रोसेसेस बस किसी दूसरे नोड पर रहते हैं।
BEAM कच्ची स्पीड का वादा करने के बजाय इस बात पर ज़ोर देता है कि समवर्तीता, फॉल्ट कंटेनमेंट, और रिकवरी डिफ़ॉल्ट हों, ताकि भरोसेमंदता की कहानी सैद्धांतिक नहीं बल्कि व्यावहारिक हो।
सिस्टम रोके बिना अपग्रेड (हॉट कोड, सावधानी से)
एर्लैंग का एक चर्चित तरीका है हॉट कोड स्वैपिंग: रनिंग सिस्टम के हिस्सों को न्यूनतम डाउनटाइम के साथ अपडेट करना (जहाँ रनटाइम और टूलिंग इसका समर्थन करे)। व्यावहारिक वादा यह नहीं है कि "कभी भी रीस्टार्ट न करना", बल्कि यह कि "फिक्सेस भेजिए बिना लंबी डाउनटाइम के"।
"हॉट कोड" असल में क्या है
एर्लैंग/OTP में, रनटाइम एक समय में दो मॉड्यूल वर्शन रख सकता है। मौजूदा प्रोसेसेस पुराने वर्शन का उपयोग करते हुए काम पूरा कर सकते हैं जबकि नए कॉल नए वर्शन का उपयोग कर सकते हैं। इससे आप बिना सभी को लॉग‑आउट किए बग पैच, फीचर रोलआउट या व्यवहार समायोजन कर सकते हैं।
अगर अच्छी तरह किया जाए, यह प्रत्यक्ष रूप से भरोसेमंदता के लक्ष्यों का समर्थन करता है: कम पूर्ण रीस्टार्ट, छोटे मेंटेनेंस विंडोज़, और उत्पादन में कुछ ग़लत होने पर तेज़ रिकवरी।
वे सीमाएँ जिनको अनदेखा नहीं करना चाहिए
हर बदलाव को लाइव स्वैप करना सुरक्षित नहीं होता। कुछ उदाहरण जिनके लिए अतिरिक्त सावधानी (या रीस्टार्ट) चाहिए:
- स्टेट के स्वरूप में बदलाव (एक प्रोसेस एक फ़ॉर्मैट उम्मीद करता है, नया कोड दूसरे की)
- प्रोटोकॉल या संदेश‑फॉर्मैट के बदलाव जो सर्विसेज़ के बीच मेल खाएं होना चाहिए
- स्कीमा माइग्रेशंस जो समय लेती हैं या समन्वय की ज़रूरत होती है
एर्लैंग नियंत्रित संक्रमण के मैकेनिज़्म देता है, पर आपको अपग्रेड पथ डिजाइन करना ही होगा।
माइंडसेट: अपग्रेड और रोलबैक सामान्य ऑपरेशन हों
हॉट अपग्रेड सबसे अच्छी तरह तब काम करते हैं जब अपग्रेड और रोलबैक को सामान्य संचालन की तरह माना जाए, न कि दुर्लभ आपात‑स्थिति। इसका मतलब है वर्ज़निंग, कम्पैटिबिलिटी, और शुरुआत से एक स्पष्ट "पूर्ववत" पाथ की योजना बनाना। व्यवहार में टीमें लाइव‑अपग्रेड तकनीक को चरणबद्ध रोलआउट, हेल्थ चेक और सुपरविजन‑आधारित रिकवरी के साथ जोड़ती हैं।
भले ही आप कभी एर्लैंग न इस्तेमाल करें, सबक ट्रांसफर होता है: सिस्टम को ऐसा डिजाइन कीजिए कि उन्हें सुरक्षित तरीके से बदलना पहली कक्षा की मांग हो, न कि विचार के बाद की चीज़।
रियल‑टाइम प्लेटफ़ॉर्म्स में जहाँ एर्लैंग के विचार चमकते हैं
रियल‑टाइम प्लेटफ़ॉर्म्स का मतलब परफेक्ट टाइमिंग नहीं बल्कि यह है कि सिस्टम प्रतिसाददेही बना रहे जबकि चीज़ें लगातार गलत होती रहती हैं: नेटवर्क हिलता‑डुलता है, निर्भरता धीमी हो जाती है, और यूज़र ट्रैफ़िक स्पाइक कर देता है। जो आर्मस्ट्रांग द्वारा बढ़ावा दी गई एर्लैंग की डिज़ाइन यही वास्तविकता मानती है और समवर्तीता को सामान्य मानती है, न कि अपवाद।
सामान्य “रियल‑टाइम” उपयोग‑मामले
जहाँ भी बहुत सारी स्वतंत्र गतिविधियाँ एक साथ हो रही हों, वहाँ एर्लैंग‑स्टाइल सोच काम आती है:
- मैसेजिंग और चैट: लाखों छोटी बातचीतें, हर एक की अपनी स्टेट और रिट्राइज़ हैं।
- रियल‑टाइम कम्युनिकेशन: वॉइस/वीडियो सिग्नलिंग, प्रेज़ेंस अपडेट, और सेशन समन्वय।
- IoT समन्वय: उपकरणों की फ्लीट जो कभी‑कभार चेक‑इन करती है, गायब होती है, और फिर दिख जाती है।
- पेमेंट वर्कफ़्लोज़: बहु‑कदम प्रक्रियाएँ जहाँ कुछ कदम धीमे, अनुपलब्ध, या कंपेन्सेटिंग एक्शंस की ज़रूरत हो सकती हैं।
“सॉफ्ट रियल‑टाइम” का सामान्य अर्थ
ज्यादातर उत्पादों को हार्ड गारंटी की ज़रूरत नहीं होती जैसे “हर क्रिया 10 ms में पूरी होनी चाहिए।” उन्हें चाहिए सॉफ़्ट रियल‑टाइम: सामान्य अनुरोधों के लिए लगातार कम लेटेंसी, हिस्सों के फेल होने पर तेज़ रिकवरी, और उच्च उपलब्धता ताकि उपयोगकर्ता मुश्किल से ही घटनाओं को महसूस करें।
विफलता सामान्य है: इसके लिए डिज़ाइन करें
वास्तविक सिस्टम निम्न जैसी समस्याओं का सामना करते हैं:
- ड्रॉप्ड कनेक्शंस (मोबाइल नेटवर्क, Wi‑Fi हैंडऑफ़)
- टाइमआउट्स जब डाउनस्ट्रीम सर्विस धीमी हो
- आंशिक आउटेज जहाँ किसी एक क्षेत्र या निर्भरता का प्रदर्शन गिरता है
एर्लैंग का मॉडल प्रत्येक गतिविधि (यूज़र सत्र, डिवाइस, पेमेंट प्रयास) को अलग करने की प्रोत्साहना करता है ताकि एक विफलता फैल न सके। एक बड़े “सब कुछ संभालने” घटक बनाने के बजाय टीमें छोटे यूनिट्स में सोच सकती हैं: हर वर्कर एक काम करता है, संदेशों से बात करता है, और अगर टूटे तो साफ़‑सुथरे तरीके से रीस्टार्ट किया जाता है।
यह बदलाव—“हर विफलता रोकने” से “विफलताओं को जल्दी कंटेन और रिकवर करने” की ओर—अक्सर वही चीज़ है जो रियल‑टाइम प्लेटफ़ॉर्म्स को दबाव में स्थिर बनाती है।
सामान्य गलतफहमियाँ और वास्तविक सीमाएँ
जो आप बनाते हैं उस पर मालिकाना रखें
जब चाहें तो स्रोत कोड निर्यात करके पूरा नियंत्रण रखें ताकि आप इसे कहीं और चलाएँ या बढ़ाएँ।
एर्लैंग की साख कभी‑कभी इस वादे जैसी सुनाई देती है: सिस्टम कभी नहीं डगमगाएँगे क्योंकि वे बस रीस्टार्ट कर लेते हैं। वास्तविकता ज़्यादा व्यावहारिक और उपयोगी है। “लेट इट क्रैश” भरोसेमंद सेवाएँ बनाने का एक टूल है, न कि कठिन समस्याओं की उपेक्षा करने का लाइसेंस।
रीस्टार्ट बैंड‑एड नहीं हैं
एक आम गलती सुपरविजन को गहरे बग्स छुपाने का तरीका समझना है। अगर एक प्रोसेस स्टार्ट होते ही तुरंत क्रैश कर रहा है, तो सुपरवाइज़र उसे बार‑बार रीस्टार्ट कर सकता है और आप CPU जलाते हुए, लॉग स्पैम करते हुए, और शायद मूल बग से बड़ा आउटेज पैदा कर देते हैं—क्रैश‑लूप।
अच्छे सिस्टम बैकऑफ़, रीस्टार्ट‑इंटेंसिटी लिमिट्स, और "हार मानो और एस्केलेट करो" व्यवहार जोड़ते हैं। रीस्टार्ट स्वस्थ ऑपरेशन को बहाल करना चाहिए, टूटी हुई अनिवार्यता को छुपाना नहीं।
स्टेट सबसे कठिन हिस्सा है
एक प्रोसेस को रीस्टार्ट करना अक्सर आसान होता है; सही स्टेट को रिकवर करना कठिन है। अगर स्टेट केवल मेमोरी में है, तो आपको तय करना होगा क्रैश के बाद "सही" क्या होगा:
- क्या आप दृढ़ स्टोरेज से फिर से बनाएँगे?
- क्या आप इवेंट्स को रीप्ले कर सकते हैं (idempotency के साथ)?
- इन‑फ्लाइट वर्क या आंशिक अपडेट्स का क्या होगा?
फॉल्ट टॉलरेंस सावधानीपूर्वक डेटा डिज़ाइन की जगह नहीं लेता; यह इसे स्पष्ट रूप से माँगता है।
आपको अभी भी अवलोकनीयता चाहिए
क्रैश तभी सहायक होते हैं जब आप उन्हें जल्दी देख सकें और समझ सकें। इसका मतलब है लॉगिंग, मेट्रिक्स, और ट्रेसिंग में निवेश—केवल यह मत समझिए कि "यह रीस्टार्ट हो गया, तो सब ठीक है।" आपको बढ़ती रीस्टार्ट दरें, बढ़ती कतारें, और धीमी निर्भरताओं को उपयोगकर्ता महसूस करने से पहले देखना होगा।
वास्तविक संचालन सीमाएँ मौजूद हैं
BEAM की ताकतों के बावजूद, सिस्टम बहुत आम तरीकों से फेल कर सकते हैं:
- मेमोरी ग्रोथ लीक, कैशेस, या बड़े हीप्स की वजह से
- मेलबॉक्स बैकलॉग जब प्रोड्यूसर कंज्यूमर से तेज़ हो (लेटेंसी स्पाइक और टाइमआउट्स)
- निर्भरता विफलताएँ (डेटाबेस, थर्ड‑पार्टी APIs, DNS) जहाँ सिर्फ़ आपके कोड का रीस्टार्ट मूल कारण ठीक नहीं करेगा
एर्लैंग का मॉडल आपको विफलताओं को कंटेन और रिकवर करने में मदद करता है—पर यह उन्हें मिटा नहीं सकता।
आज लागू करने के लिए तरीका (भले ही आप एर्लैंग न इस्तेमाल करें)
एर्लैंग का सबसे बड़ा उपहार सिंटैक्स नहीं है—यह आदतों का एक सेट है जो ऐसी सेवाएँ बनाता है जो हिस्सों के असफल होने पर भी चलती रहती हैं। आप इन आदतों को लगभग किसी भी स्टैक में लागू कर सकते हैं।
विचारों को ठोस कदमों में बदलना
शुरू में विफलता सीमाओं को स्पष्ट कीजिए। अपने सिस्टम को उन घटकों में तोड़िए जो स्वतंत्र रूप से फेल कर सकते हैं, और सुनिश्चित करें कि हर एक का एक स्पष्ट कॉन्ट्रैक्ट हो (इनपुट, आउटपुट, और "खराब" क्या दिखता है)।
फिर रिकवरी को स्वचालित बनाइए बजाय हर त्रुटि को रोकने की कोशिश करने के:
- घटक अलग करें: रिस्की वर्क को अलग प्रोसेसेस/कंटेनरों/थ्रेड्स में चलाएँ ताकि एक क्रैश बाकी सबको ज़हरीला न करे।
- सीमाएँ तय करें: टाइमआउट्स, बैकऑफ़ के साथ रिट्राई, सर्किट‑ब्रेकर्स, और बुल्कहेड्स ताकि कैस्केडिंग विफलताएँ रुकीं रहें।
- रिकवरी को नियमित बनाइए: हेल्थ चेक्स, ऑटो‑रीस्टार्ट, और सुरक्षित डिफॉल्ट ताकि सिस्टम जल्दी से ज्ञात‑अच्छी स्थिति में लौट आए।
इन आदतों को "सच" बनाने का एक व्यावहारिक तरीका है टूलिंग और लाइफसायकल में इन्हें बेक करना, सिर्फ़ कोड में नहीं। उदाहरण के लिए, जब टीमें Koder.ai जैसी टूलिंग के साथ चैट के ज़रिये वेब, बैकएंड, या मोबाइल ऐप्स को गति से बनाती हैं, तो वर्कफ़्लो स्वाभाविक रूप से स्पष्ट प्लानिंग (Planning Mode), दोहराने योग्य तैनातियाँ, और स्नैपशॉट/रोलबैक जैसी सुरक्षित पुनरावृत्ति को बढ़ावा देता है—वही ऑपरेशनल माइंडसेट जिसे एर्लैंग ने लोकप्रिय किया: परिवर्तन और विफलता को मानकर चलना, और रिकवरी को नीरस बनाना।
एर्लैंग के बाहर शुरू करने के बिंदु
आप शायद जिन टूल्स का उपयोग करते हैं उनसे "सुपरविजन" पैटर्न की नकल कर सकते हैं:
- सुपरवाइज़र: systemd, Kubernetes Deployments, या कोई प्रोसेस मैनेजर (restart‑on‑failure, readiness probes)
- प्रोसेस पृथक्करण: CPU‑भारी या अनट्रस्टेड कार्यों के लिए अलग वर्कर सर्विसेज़
- मैसेज पासिंग: क्यूज़/स्ट्रीम (RabbitMQ, SQS, Kafka) प्रोड्यूसर और कंज्यूमर को अलग करने और स्पाइक्स को स्मूद करने के लिए
एक त्वरित निर्णय चेकलिस्ट
पैटर्न कॉपी करने से पहले तय कर लीजिए कि आपको वास्तव में क्या चाहिए:
- अपेक्षित विफलता‑मोड्स: ओवरलोड, आंशिक आउटेज, धीमे निर्भरता, खराब इनपुट, मेमोरी लीक
- लेटेंसी जरूरतें: क्या आपको रियल‑टाइम प्रतिक्रियाएँ चाहिए, या बाद में प्रोसेस करना ठीक है?
- रिकवरी उद्देश्य: तेज़ रीस्टार्ट, ग्रेसफ़ुल डिग्रेडेशन, या मैन्युअल हस्तक्षेप?
- टीम कौशल और टूलिंग: ऑन‑कॉल, अवलोकनीयता, और घटना‑प्रतिक्रिया का मालिक कौन होगा?
अगर आप व्यावहारिक अगले कदम चाहते हैं, तो /blog में और गाइड देखें, या /docs में इम्प्लीमेंटेशन विवरण ब्राउज़ करें (और उपकरण का मूल्यांकन कर रहे हैं तो /pricing देखें)।
अक्सर पूछे जाने वाले प्रश्न
जो आर्मस्ट्रांग की एर्लैंग सोच आज भी क्यों प्रासंगिक है?
एर्लैंग ने व्यावहारिक भरोसेमंद सोच को लोकप्रिय बनाया: मान लें कि सिस्टम के कुछ हिस्से असफल होंगे और फिर तय करें कि अगला कदम क्या होगा।
हर क्रैश रोकने की कोशिश करने के बजाय यह त्रुटि पृथक्करण, तेज़ पता लगाना, और स्वचालित पुनर्प्राप्ति पर जोर देता है — जो चैट, कॉल रूटिंग, नोटिफिकेशन और समन्वय जैसी रियल‑टाइम सेवाओं के लिए मेल खाता है।
पोस्ट में “रियल‑टाइम” का सामान्य अर्थ क्या है?
यहाँ “रियल‑टाइम” का सादे शब्दों में अर्थ है सॉफ्ट रियल‑टाइम:
- प्रतिक्रियाएँ तेज़ और सुसंगत महसूस हों
- लोड के दौरान व्यवहार पूर्वानुमान योग्य रहे
- आंशिक विफलताओं के बावजूद सिस्टम काम करता रहे
यह माइक्रोसेकंड की गारंटी की बात नहीं है, बल्कि ठहराव, स्पाइरल और कैस्केडिंग आउटेज से बचने की बात है।
एर्लैंग‑स्टाइल डिजाइन में “डिफ़ॉल्ट रूप से समवर्तीता” का क्या मतलब है?
“डिफ़ॉल्ट के रूप में समवर्तीता” का मतलब है सिस्टम को कई छोटे, अलग‑अलग वर्करों के रूप में बनाना बजाय कुछ बड़े, टाइटली कपल्ड घटकों के।
हर वर्कर एक संकरी जिम्मेदारी संभाले (एक session, device, call, retry loop), जिससे स्केलिंग और फ़ेलियर कंटेनमेंट आसान होता है।
एर्लैंग के “लाइटवेट प्रोसेसेस” क्या हैं और वे क्यों महत्वपूर्ण हैं?
Lightweight processes छोटे, स्वतंत्र वर्कर होते हैं जिन्हें बड़े पैमाने पर बनाया जा सकता है।
व्यवहारिक रूप से इनका लाभ है:
- आप प्रति “वस्तु” (यूज़र/session/device) एक प्रोसेस मॉडल कर सकते हैं
- विफलताएँ एकल वर्कर तक सीमित रहती हैं
- मोनोलिथ को रीबूट करने की तुलना में वर्क को रीस्टार्ट करना सस्ता है
एर्लैंग क्यों साझा स्टेट की बजाय मैसेज पासिंग को प्राथमिकता देता है?
मैसेज पासिंग समन्वय है — संदेश भेजकर — बजाय साझा म्यूटेबल स्टेट के।
इससे रेस कंडीशन्स जैसे समवर्ती बग की श्रेणियाँ कम हो जाती हैं क्योंकि हर वर्कर अपना आंतरिक स्टेट मालिक होता है; अन्य केवल संदेश के जरिए बदलाव का अनुरोध कर सकते हैं।
एक अभिनेता/मैसेज सिस्टम में बैक‑प्रेशर क्या है, और इसे कैसे हैंडल करें?
बैक‑प्रेशर तब होता है जब कोई वर्कर अपने संसाधनों से अधिक संदेश प्राप्त करता है और उसका मेलबॉक्स बढ़ने लगता है।
वास्तविक समाधान में शामिल हैं:
- मेलबॉक्स/क्यू साइज़ की निगरानी
- सीमाएँ लगाना (ड्रॉप, सैम्पल, या कैप)
- लोड को कई वर्करों पर फैलाना
- अनिवार्य नहीं तो ग्रेसफ़ुल डिग्रेडेशन (उदा., नॉन‑क्रिटिकल नोटिफिकेशन के लिए डाइजेस्ट मोड)
“लेट इट क्रैश” का असल मतलब क्या है (और क्या नहीं)?
“लेट इट क्रैश” का अर्थ है: यदि कोई वर्कर किसी असमान्य या अमान्य स्थिति में पहुँच जाए, तो वह फेल फ़ास्ट होना चाहिए बजाय धीमे‑धीमे चलने के।
पुनर्प्राप्ति संरचनात्मक रूप से (सुपरविजन के ज़रिए) संभाली जाती है, जिससे कोड पाथ सरल और पुनर्प्राप्ति पूर्वानुमान‑योग्य बनती है—बशर्ते कि रीस्टार्ट सुरक्षित और तेज़ हो।
सुपरविजन ट्री क्या हैं, और वे फॉल्ट टॉलरेंस में क्यों केंद्रीय हैं?
सुपरविजन ट्री एक हायरेरकी है जहाँ सुपरवाइज़र वर्करों पर नजर रखते हैं और तय नियमों के अनुसार उन्हें रीस्टार्ट करते हैं।
इससे आप एड‑हॉक रिकवरी छँटाई के बजाय केंद्रीकृत रूप से निर्णय लेते हैं:
- क्या जब फेल हो तो क्या रीस्टार्ट होगा
- क्रैश‑लूप रोकने के लिए लिमिट्स/बैकऑफ़
- जब घटकों को सिंक में रहना ज़रूरी हो तो उन्हें साथ में रीस्टार्ट करना
OTP क्या है, और यह भरोसेमंद सेवाएँ बनाने में कैसे मदद करता है?
OTP पैटर्न और कन्वेंशन्स का सेट है जो "लेट इट क्रैश" को लंबे समय तक प्रोडक्शन में चलाने लायक बनाता है।
आम बिल्डिंग ब्लॉक्स में हैं:
gen_server— स्टेटफुल लंबे समय चलने वाला वर्करsupervisor— फेल होने पर स्वचालित रीस्टार्ट नीतिapplication— सर्विस का क्लीन स्टार्ट/स्टॉप और रिलीज़ प्रबंधन
लाभ यह है कि टीमों को हर बार कस्टम फ्रेमवर्क बनाने की बजाय साझा समझी जाने वाली लाइफसायकल मिलती है।
मैं एर्लैंग का इस्तेमाल किए बिना भी एर्लैंग के सबक कैसे लागू कर सकता/सकती हूँ?
यदि आप एर्लैंग नहीं भी इस्तेमाल कर रहे, तब भी आप इन सिद्धांतों को लागू कर सकते हैं: विफलता और पुनर्प्राप्ति को प्राथमिकता बनाइए।
कदमों में शामिल हैं:
- जोखिम‑भरे काम को अलग प्रक्रियाओं/कंटेनरों/सर्विसेस में चलाएँ
- टाइमआउट, बैकऑफ़ के साथ रिट्राई, सर्किट‑ब्रेकर्स और बुल्कहेड जोड़ें
- रिकवरी को स्वचालित बनाइए (हेल्थ चेक्स + रीस्टार्ट‑ऑन‑फेल्योर)
- क्यू/स्ट्रीम (RabbitMQ, SQS, Kafka) का उपयोग कर प्रोड्यूसर‑कंज्यूमर को अलग रखें
अधिक मार्गदर्शन के लिए पोस्ट में सुझाव दिए गए हैं: /blog और तैनाती/विवरण के लिए /docs तथा योजनाओं के लिए /pricing।