क्यों जो बेडा के शुरुआती Kubernetes निर्णय अभी भी मायने रखते हैं
जो बेडा Kubernetes के शुरुआती डिज़ाइन में प्रमुख लोगों में से थे—उनके साथ अन्य संस्थापकों ने भी Google के आंतरिक सिस्टम से सीखे सबक एक ओपन प्लेटफ़ॉर्म में लाए। उनकी प्रभावशीलता ट्रेंडी फीचर पीछा करने में नहीं थी; बल्कि साधारण प्रिमिटिव चुनने में थी जो असली प्रोडक्शन के хаос में टिक सकें और रोज़मर्रा की टीमों के लिए समझने में आसान रहें।
उसी कारण से Kubernetes सिर्फ "एक कंटेनर टूल" से बढ़कर आधुनिक एप्लिकेशन प्लेटफ़ॉर्म का reusable कर्नेल बन गया।
साधारण शब्दों में कंटेनर ऑर्केस्ट्रेशन
"Container orchestration" उन नियमों और ऑटोमेशन का समूह है जो आपकी ऐप को तब भी चलाए रखते हैं जब मशीनें फेल हों, ट्रैफ़िक spike करे, या आप नया वर्शन डिप्लॉय करें। इंसान सर्वरों की बेबीसिटिंग करने के बजाय, सिस्टम कंटेनरों को कंप्यूटर्स पर शेड्यूल करता है, क्रैश होने पर उन्हें रीस्टार्ट करता है, रिसीलिएंस के लिए उन्हें फैला देता है, और नेटवर्किंग जोड़ता है ताकि यूज़र्स तक पहुँचा जा सके।
Kubernetes से पहले का अव्यवस्थित दौर
Kubernetes सामान्य न होने से पहले टीमें अक्सर बेसिक सवालों के जवाब के लिए स्क्रिप्ट्स और कस्टम टूल्स जोड़ती थीं:
- यह कंटेनर अभी कहाँ चलेगा?
- अगर 2 बजे सुबह नोड मर जाए तो क्या होगा?
- हम बिना डाउनटाइम के कैसे सुरक्षित डिप्लॉय करें?
- IPs लगातार बदलते हैं तो सेवाएँ एक-दूसरे को कैसे खोजें?
वे DIY सिस्टम काम करते थे—जब तक कि वे न करें। हर नया ऐप या टीम और एक-ऑफ लॉजिक जोड़ती, और ऑपरेशनल सुसंगतता मुश्किल से हासिल होती।
यह पोस्ट क्या कवर करती है
यह लेख शुरुआती Kubernetes डिज़ाइन चुनौतियों (Kubernetes की “आकृति”) के माध्यम से चलता है और समझाता है कि वे आधुनिक प्लेटफ़ॉर्म को कैसे प्रभावित करते हैं: डिक्लेरेटिव मॉडल, कंट्रोलर/कंट्रोल लूप्स, Pods, लेबल्स, Services, मज़बूत API, सुसंगत क्लस्टर स्टेट, प्लग-इन शेड्यूलिंग, और एक्स्टेंसिबिलिटी। भले ही आप सीधे Kubernetes चलाने न भी कर रहे हों, संभवतः आप ऐसे प्लेटफ़ॉर्म का उपयोग कर रहे हैं जो इन विचारों पर बना है—या उन्हीं समस्याओं से जूझ रहे हैं।
Kubernetes ने किस समस्या को हल करने की ठानी
Kubernetes से पहले, “कंटेनर चलाना” आमतौर पर कुछ कंटेनर चलाने जैसा था। टीमें bash स्क्रिप्ट्स, cron jobs, golden images, और कुछ ad-hoc टूल्स जोड़कर डिप्लॉय करती थीं। कुछ टूटे तो फिक्स अक्सर किसी के सिर में रहता—या README में जो किसी पर भरोसा नहीं होता। ऑपरेशन्स एक-एक करके हस्तक्षेपों की धारा थे: प्रोसेसेस रीस्टार्ट करना, लोड बैलेंसर रीपॉइंट करना, डिस्क क्लीन करना, और अनुमान लगाना कौन सा मशीन सुरक्षित है छूने के लिए।
बड़े पैमाने पर कंटेनरों ने नई फेलियर मोड पैदा किए
कंटेनरों ने पैकेजिंग आसान की, पर प्रोडक्शन की गड्डमड्ड चीजें नहीं हटाईं। बड़े पैमाने पर सिस्टम अधिक तरीकों से और अधिक बार फेल होता है: नोड्स गायब होते हैं, नेटवर्क पार्टिशन होते हैं, इमेज असंगत तरीके से रोलआउट होते हैं, और वर्कलोड्स उस चीज़ से परे चलने लगते हैं जो आप सोचते हैं कि चल रहा है। एक “साधारण” डिप्लॉय cascade में बदल सकता है—कुछ इंस्टेंसेज़ अपडेट हुए, कुछ नहीं, कुछ फंसे हुए, कुछ हेल्दी पर पहुँच से बाहर।
असल मुद्दा कंटेनर स्टार्ट करना नहीं था। असली चुनौती यह थी कि सही कंटेनर सही रूप में चलते रहें, निरंतर बदलाव के बावजूद।
इन्फ्रास्ट्रक्चर में एक सुसंगत मॉडल
टीमें अलग-अलग वातावरणों को भी मैनेज कर रही थीं: ऑन‑प्रेम हार्डवेयर, VMs, शुरुआती क्लाउड प्रोवाइडर, और विभिन्न नेटवर्क/स्टोरेज सेटअप। हर प्लेटफ़ॉर्म की अपनी शब्दावली और फेलियर पैटर्न होते थे। साझा मॉडल न होने पर हर माइग्रेशन ऑपरेशनल टूलिंग दोबारा लिखने और लोगों को रीट्रेन करने जैसा हो जाता था।
Kubernetes ने यह प्रस्ताव रखा कि ऐप्स और उनकी ऑपरेशनल ज़रूरतों को एक ही, सुसंगत तरीके से वर्णित किया जा सके—चाहे मशीनें कहीं भी हों।
प्लेटफ़ॉर्म से अपेक्षाएँ कैसी दिखती थीं
डेवलपर्स स्व-सर्विस चाहते थे: टिकट बिना डिप्लॉय करें, कैपेसिटी के लिए भीख नहीं माँगना, और रोलबैक बिना ड्रामे करें। ऑप्स टीमें पूर्वानुमेयता चाहती थीं: स्टैंडर्ड हेल्थ चेक, रिपीटेबल डिप्लॉयमेंट, और क्या चलना चाहिए उसका स्पष्ट स्रोत।
Kubernetes कोई fancy scheduler बनने की कोशिश नहीं कर रहा था। इसका लक्ष्य एक भरोसेमंद एप्लिकेशन प्लेटफ़ॉर्म का आधार बनना था—एक ऐसा सिस्टम जो गंदी वास्तविकता को उस तरह व्यवस्थित करे कि आप उस पर तर्क कर सकें।
निर्णय 1: डिक्लेरेटिव, Desired-State मॉडल
एक सबसे प्रभावशाली शुरुआती चुनाव Kubernetes को डिक्लेरेटिव बनाना था: आप जो चाहते हैं उसे बयान करते हैं, और सिस्टम वास्तविकता को उस बयान से मिलाने की कोशिश करता है।
thermostat की तरह समझाएँ desired state
एक थर्मोस्टैट रोज़मर्रा का उपयोगी उदाहरण है। आप हर कुछ मिनट में हीटर को मैन्युअली ऑन/ऑफ नहीं करते। आप एक लक्षित तापमान सेट करते हैं—मान लीजिये 21°C—और थर्मोस्टैट लगातार कमरे को चेक करके हीटर को उसी लक्ष्य के करीब बनाए रखता है।
Kubernetes भी वैसा ही काम करता है। क्लस्टर को स्टेप-बाय-स्टेप निर्देश देने की बजाय—"यह कंटेनर उस मशीन पर स्टार्ट करो, फिर फेल होने पर इसे रीस्टार्ट करो"—आप परिणाम घोषित करते हैं: "मैं चाहता हूँ कि इस ऐप की 3 कॉपीज़ चल रही हों।" Kubernetes लगातार यह देखता है कि असल में क्या चल रहा है और ड्रिफ्ट को सही करता है।
कम मैन्युअल स्टेप्स, कम आश्चर्य
डिक्लेरेटिव कॉन्फ़िगरेशन उस छिपे हुए "ऑप्स चेकलिस्ट" को घटाता है जो अक्सर किसी के सिर में या आधे-अपडेटेड रनबुक में रहता है। आप कॉन्फ़िग लागू करते हैं, और Kubernetes प्लेसमेंट, रीस्टार्ट, और परिवर्तनों को reconcile करने का मैकेनिक्स संभालता है।
यह परिवर्तन समीक्षा को भी आसान बनाता है। एक बदलाव कॉन्फ़िग के diff के रूप में दिखाई देता है, न कि एड-हॉक कमांड्स की एक श्रृंखला के रूप में।
पर्यावरणों में दोहराव योग्यपन
क्योंकि desired state लिखी होती है, आप वही दृष्टिकोण dev, staging, और prod में reuse कर सकते हैं। वातावरण भिन्न हो सकता है, पर इरादा सुसंगत रहता है, जिससे डिप्लॉयमेंट अधिक पूर्वानुमेय और ऑडिट करने में आसान होते हैं।
ट्रेडऑफ़
डिक्लेरेटिव सिस्टम सीखने की अवस्था मांगते हैं: आपको "अब मुझे क्या करना है" की बजाय "क्या सच होना चाहिए" में सोचना पड़ता है। वे अच्छे डिफ़ॉल्ट्स और स्पष्ट कन्वेंशन्स पर भी बहुत निर्भर करते हैं—बिना उनके, टीमें ऐसी कॉन्फ़िग बना सकती हैं जो तकनीकी रूप से चले पर समझने और मेंटेन करने में कठिन हों।
निर्णय 2: कंट्रोल लूप्स (कंट्रोलर) को इंजन बनाना
Kubernetes केवल एक बार कंटेनर चलाने की वजह से सफल नहीं हुआ—यह इसलिए सफल हुआ क्योंकि यह समय के साथ उन्हें सही तरीके से चलाए रख सकता था। बड़ा डिज़ाइन कदम यह था कि सिस्टम का मुख्य इंजन "control loops" (कंट्रोलर) हों।
कंट्रोलर क्या होता है
कंट्रोलर एक सरल लूप है:
- वर्तमान स्थिति देखो (क्या वास्तव में चल रहा है)
- उसे desired state से तुलना करो (आपने क्या माँगा था)
- दोनों तब तक मेल खाते रहें तब तक कार्रवाई करो
यह एक बार का टास्क नहीं बल्कि ऑटोपायलट जैसा है। आप वर्कलोड्स की बेबीसिटिंग नहीं करते; आप जो चाहते हैं उसे घोषित करते हैं, और कंट्रोलर क्लस्टर को उस परिणाम की ओर लगातार मोड़ते रहते हैं।
क्रैश, नोड लॉस और ड्रिफ्ट को सँभालना
यही पैटर्न Kubernetes को रियल-वर्ल्ड समस्याओं में लचीलापन देता है:
- कंटेनर क्रैश: कंट्रोलर देखता है कि रनिंग इंस्टेंसेज़ अपेक्षित से कम हैं और रिप्लेसमेंट शुरू कर देता है।
- नोड लॉस: जब कोई नोड गायब होता है, कंट्रोलर pods को कहीं और reschedule करके वांछित गणना बहाल कर देता है।
- कॉन्फ़िग ड्रिफ्ट: कोई रिसोर्स बदलता या डिलीट कर देता है तो कंट्रोलर अंतर को reconcile कर के ठीक कर देता है।
फेलियर को विशेष मामलों के रूप में देखने की बजाय, कंट्रोलर उन्हें नियमित "स्टेट मिसमैच" मानते हैं और हर बार एक ही तरीके से ठीक करते हैं।
स्क्रिप्ट्स से बेहतर स्केल क्यों करता है
पारंपरिक ऑटोमेशन स्क्रिप्ट्स अक्सर एक स्थिर वातावरण मानती हैं: स्टेप A, फिर B, फिर C। वितरित सिस्टम में वे मान्यताएँ लगातार टूटती रहती हैं। कंट्रोलर बेहतर स्केल करते हैं क्योंकि वे idempotent होते हैं (बार-बार चलाने पर सुरक्षित) और eventually consistent होते हैं (वे तब तक कोशिश करते रहते हैं जब तक लक्ष्य नहीं पहुँच जाता)।
रोज़मर्रा के उदाहरण: Deployments और ReplicaSets
यदि आपने कभी Deployment का उपयोग किया है, तो आप कंट्रोल लूप्स पर भरोसा कर चुके हैं। अंडर-द-हूड, Kubernetes एक ReplicaSet कंट्रोलर का उपयोग करता है यह सुनिश्चित करने के लिए कि अनुरोधित संख्या में pods मौजूद हों—और एक Deployment कंट्रोलर रोलिंग अपडेट्स और रोलबैक को पूर्वानुमेय तरीके से संभालता है।
निर्णय 3: Pods को एटॉमिक शेड्यूलिंग यूनिट बनाना
Kubernetes सिर्फ "containers" शेड्यूल कर सकता था, पर जो बेडा की टीम ने Pods को क्लस्टर पर मशीन पर रखने योग्य सबसे छोटी डिप्लॉयबल यूनिट के रूप में पेश किया। मुख्य विचार: कई वास्तविक ऐप एक ही प्रक्रिया नहीं होते—वे एक छोटे समूह होते हैं जिनको कड़ाई से साथ रहना पड़ता है।
व्यक्तिगत कंटेनरों के बजाय Pods क्यों?
एक Pod एक या अधिक कंटेनरों का रैपर है जो एक ही किस्म की किस्मत साझा करते हैं: वे एक साथ शुरू होते हैं, एक ही नोड पर चलते हैं, और एक साथ स्केल करते हैं। इससे sidecars जैसे पैटर्न प्राकृतिक बनते हैं—लॉग शिपर, प्रॉक्सी, कॉन्फ़िग रीलोडर, या सिक्योरिटी एजेंट जो हमेशा मुख्य ऐप के साथ होना चाहिए।
हर ऐप को उन हेल्पर्स के साथ एकीकृत करना सिखाने के बजाय, Kubernetes आपको उन्हें अलग कंटेनरों के रूप में पैकेज करने देता है जो फिर भी एक यूनिट की तरह व्यवहार करते हैं।
Pods ने नेटवर्किंग और स्टोरेज के लिए क्या संभव बनाया
Pods ने दो महत्वपूर्ण व्यवहार को व्यावहारिक बनाया:
- नेटवर्किंग: Pod के अंदर के कंटेनर एक नेटवर्क पहचान साझा करते हैं (एक IP और पोर्ट स्पेस)। मुख्य ऐप
localhost पर साइडकार से बात कर सकता है, जो सरल और तेज़ है।
- स्टोरेज: Pods के अंदर कंटेनर वॉल्यूम साझा कर सकते हैं। एक हेल्पर फाइल लिख सकता है जिसे मुख्य ऐप पढ़ता है, बिना बाहरी hops के।
इन निर्णयों ने कस्टम ग्लू कोड की आवश्यकता घटा दी, जबकि प्रक्रियात्मक स्तर पर कंटेनरों को अलग रखा गया।
नए उपयोगकर्ताओं के लिए Pods कहां भ्रम पैदा करते हैं
नए उपयोगकर्ता अक्सर उम्मीद करते हैं "एक कंटेनर = एक ऐप," और फिर Pod-स्तरीय अवधारणाओं—रीस्टार्ट्स, IPs, और स्केलिंग—से उलझ जाते हैं। कई प्लेटफ़ॉर्म इसे सुलभ बनाते हैं ऑपिनियनटेड टेम्पलेट्स दे कर (उदा., “web service”, “worker”, या “job”) जो पर्दे के पीछे Pods जनरेट करते हैं—ताकि टीमें रोज़ाना Pod मैकेनिक्स के बारे में सोचे बिना sidecars और साझा रिसोर्स का लाभ उठा सकें।
निर्णय 4: Loose Coupling के लिए Labels और Selectors
अपने बिल्ड बजट का अधिकतम उपयोग करें
Koder.ai पर आपने जो बनाया उसे शेयर करने या टीममेट्स को रेफर करने पर क्रेडिट कमाएँ।
Kubernetes में एक शांत शक्तिशाली शुरुआती चुनाव यह था कि labels को फ़र्स्ट-क्लास मेटाडेटा और selectors को चीज़ों को "खोजने" का प्राथमिक तरीका माना गया। "इन खास तीन मशीनों" जैसी हार्ड-वाईर्ड रिलेशनशिप के बजाय Kubernetes आपको साझा गुणों के द्वारा समूह वर्णन करने के लिए प्रेरित करता है।
Labels: सब चीज़ों पर लचीले टैग
लेबल एक सरल key/value जोड़ी है जिसे आप रिसोर्सेज़ (Pods, Deployments, Nodes, Namespaces, आदि) पर जोड़ते हैं। वे स्थिर, क्वेरीयोग्य "टैग" की तरह काम करते हैं:
app=checkoutenv=prodtier=frontend
क्योंकि लेबल हल्के और उपयोगकर्ता-परिभाषित होते हैं, आप अपनी संगठनात्मक वास्तविकता मॉडल कर सकते हैं: टीमें, कॉस्ट सेंटर्स, कंप्लायंस जोन, रिलीज चैनल, या जो भी ऑपरेशन के लिए मायने रखता हो।
Selectors: कसकर निर्भरता के बिना रिश्ते
Selectors लेबल्स पर क्वेरी हैं (उदा., “सभी Pods जहाँ app=checkout और env=prod”)। यह फिक्स्ड होस्ट लिस्ट्स से बेहतर है क्योंकि सिस्टम Pods के reschedule, scale up/down, या रोलआउट के दौरान समूह को अपडेट कर सकता है। आपकी कॉन्फ़िग तब भी स्थिर रहती है जब underlying instances लगातार बदलते हों।
बड़े पैमाने पर डायनामिक ग्रुपिंग
यह डिज़ाइन ऑपरेशनल रूप से स्केल करता है: आप हजारों इंस्टेंस पहचान नहीं मैनेज करते—आप कुछ अर्थपूर्ण लेबल सेट मैनेज करते हैं। यही लूज़ कपलिंग का सार है: कम्पोनेंट्स ऐसे समूहों से जुड़ते हैं जिनकी सदस्यता सुरक्षित तरीके से बदल सकती है।
लेबल्स सिर्फ ग्रुपिंग ही नहीं पावर करते
एक बार लेबल्स मौजूद हों, वे प्लेटफ़ॉर्म भर में साझा शब्दावली बन जाते हैं। वे ट्रैफ़िक रूटिंग (Services), पॉलिसी सीमाओं (NetworkPolicy), ऑब्ज़र्वेबिलिटी फ़िल्टर्स (metrics/logs), और यहाँ तक कि कॉस्ट ट्रैकिंग और चार्जबैक के लिए उपयोग किए जाते हैं। एक साधारण विचार—कंसिस्टेंट टैगिंग—काफी ऑटोमेशन के दरवाज़े खोल देता है।
निर्णय 5: स्थिर नेटवर्किंग के लिए Services
Kubernetes को नेटवर्किंग को_predictable_ बनाना था भले Pods कुछ भी हों। Pods बदलते हैं, reschedule होते हैं, और स्केल होते हैं—इसलिए उनके IPs और जिस मशीन पर वे चलते हैं बदल जाएंगे। Service का मूल विचार सरल था: बदलते Pods के सेट के लिए एक स्थिर "फ्रंट डोर" प्रदान करो।
बदलते Pods तक स्थिर पहुंच
Service आपको एक सुसंगत वर्चुअल IP और DNS नाम देती है (जैसे payments)। उस नाम के पीछे, Kubernetes लगातार ट्रैक करता है कि कौन से Pods Service के selector से मेल खाते हैं और ट्रैफ़िक को उसी के अनुरूप रूट करता है। यदि कोई Pod मर जाए और नया आ जाए, Service फिर भी सही जगह की ओर इंगित करती है बिना आपकी एप्लिकेशन सेटिंग्स को छुए।
कॉन्फ़िगरेशन सरल करने वाली सर्विस डिस्कवरी
इसने बहुत मैनुअल वायरिंग हटाई। IPs को कॉन्फ़िग फाइलों में हार्ड-कोड करने के बजाय, एप्स नामों पर निर्भर कर सकती हैं। आप ऐप डिप्लॉय करते हैं, Service डिप्लॉय करते हैं, और अन्य कम्पोनेंट्स DNS के जरिए उसे खोज लेते हैं—कोई कस्टम रजिस्ट्री नहीं चाहिए, कोई हार्ड‑कोडेड endpoints नहीं।
भरोसेमंदता के लिए इन-बिल्ट लोड बैलेंसिंग
Services ने हैल्थी endpoints पर डिफ़ॉल्ट लोड-बलेंसिंग का व्यवहार भी पेश किया। इसका मतलब था कि टीमों को हर आंतरिक माइक्रो‑सर्विस के लिए अपना लोड बैलेंसर बनाना नहीं पड़ता। ट्रैफ़िक फैलने से एक Pod फेल होने का blast radius कम होता है और रोलिंग अपडेट्स कम जोखिम भरे होते हैं।
सीमाएँ—और Ingress/Gateway का विस्तार
Service L4 (TCP/UDP) ट्रैफ़िक के लिए बढ़िया है, पर यह HTTP रूटिंग नियम, TLS termination, या एज नीति मॉडल नहीं करता। वहीं Ingress और बढ़ते हुए Gateway API आते हैं: वे Services के ऊपर बनते हैं ताकि hostnames, paths और एक्सटर्नल एंट्री‑पॉइंट्स को साफ़ तरीके से संभाला जा सके।
निर्णय 6: API को प्रोडक्ट सरफेस बनाना
एक शांत तरीके से क्रांतिकारी शुरुआती फैसला था Kubernetes को एक API के रूप में पेश करना—ना कि एक मोनोलीथिक टूल के रूप में जिसे आप सिर्फ़ "यूज़" करें। API‑फर्स्ट रुख ने Kubernetes को ऐसा महसूस कराया जैसे यह एक ऐसा प्लेटफ़ॉर्म हो जिस पर आप एक्स्टेंड, स्क्रिप्ट और गवर्न कर सकें।
API‑फर्स्ट ने प्लेटफ़ॉर्म बिल्डिंग कैसे बदला
जब API ही सतह होती है, प्लेटफ़ॉर्म टीमें मानकीकृत कर सकती हैं कि एप्लिकेशन्स को कैसे वर्णित और मैनेज किया जाए, चाहे कौन-सा UI, पाइपलाइन, या आंतरिक पोर्टल ऊपर बैठा हो। "ऐप डिप्लॉय करना" बन जाता है "API ऑब्जेक्ट्स सबमिट और अपडेट करना" (जैसे Deployments, Services, ConfigMaps), जो एप टीमों और प्लेटफ़ॉर्म के बीच एक साफ़ कॉन्ट्रैक्ट है।
टूलिंग, UIs और ऑटोमेशन बिना खास एक्सेस के
क्योंकि सब कुछ एक ही API के जरिए होता है, नए टूलिंग को किसी विशेष बैकडोर की ज़रूरत नहीं होती। डैशबोर्ड, GitOps कंट्रोलर्स, पॉलिसी इंजन, और CI/CD सिस्टम सभी सामान्य API क्लाइंट के रूप में काम कर सकते हैं और उचित स्कोप वाली permissions के साथ काम कर सकते हैं।
यह समानता महत्वपूर्ण है: वही नियम, auth, auditing, और admission controls लागू होते हैं चाहे request इंसान से आई हो, स्क्रिप्ट से आई हो, या आंतरिक प्लेटफ़ॉर्म UI से।
वर्शनिंग और दीर्घायु क्लस्टर्स के लिए कम्पैटिबिलिटी
API वर्शनिंग ने Kubernetes को बिना हर क्लस्टर या हर टूल को एक ही रात में तोड़े हुए विकसित होने की गुंजाइश दी।Deprecated चीज़ें staged की जा सकती हैं; कम्पैटिबिलिटी टेस्ट की जा सकती है; upgrades नियोजित किए जा सकते हैं। वर्षों तक क्लस्टर्स चलाने वाली संस्थाओं के लिए यही फर्क "हम अपग्रेड कर सकते हैं" और "हम अटक गए हैं" के बीच बनाता है।
kubectl असल में क्या दर्शाता है
kubectl Kubernetes नहीं है—यह एक क्लाइंट है। यह मानसिक मॉडल टीमों को API वर्कफ़्लोज़ के बारे में सोचने के लिए प्रेरित करता है: आप kubectl को ऑटोमेशन, वेब UI, या कस्टम पोर्टल से बदल सकते हैं, और सिस्टम सुसंगत रहता है क्योंकि कॉन्ट्रैक्ट API स्वयं है।
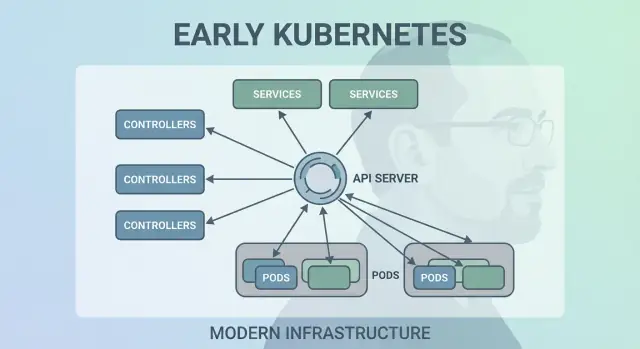
निर्णय 7: केंद्रीकृत क्लस्टर स्टेट (etcd) और सुसंगतता
वेब और API स्टैक शुरू करें
साधारण चैट से एक React वेब ऐप और Go व PostgreSQL बैकएंड बनाएं।
Kubernetes को एक single "source of truth" चाहिए था कि क्लस्टर अभी कैसा दिखना चाहिए: कौन से Pods मौजूद हैं, कौन से नोड हेल्दी हैं, Services किसकी ओर इशारा कर रहीं हैं, और कौन से ऑब्जेक्ट अपडेट हो रहे हैं। यही काम etcd करता है।
साधारण शब्दों में etcd क्या करता है
etcd कंट्रोल प्लेन के लिए डेटाबेस है। जब आप Deployment बनाते हैं, ReplicaSet स्केल करते हैं, या Service अपडेट करते हैं, वांछित कॉन्फ़िग etcd में लिखा जाता है। कंट्रोलर और अन्य कंट्रोल‑प्लेन कंपोनेंट्स उस स्टोर किए गए स्टेट को वॉच करते हैं और वास्तविकता को मिलाने की कोशिश करते हैं।
सब कुछ एक साथ काम कर रहा हो तो सुसंगतता क्यों मायने रखती है
एक Kubernetes क्लस्टर कई चलती हुई चीज़ों से भरा होता है: schedulers, controllers, kubelets, autoscalers, और admission checks सभी एक साथ प्रतिक्रिया कर सकते हैं। अगर वे "सत्य" के अलग-अलग वर्शन पढ़ रहे हों, तो रेसेस होते हैं—जैसे दो कंपोनेंट्स एक ही Pod के बारे में टकराव करने वाले निर्णय लें।
etcd की मजबूत सुसंगतता यह सुनिश्चित करती है कि जब कंट्रोल प्लेन कहता है "यह वर्तमान स्टेट है," तो सबलोग उसी से जुड़ें। वही एलाइन्मेंट कंट्रोल लूप्स को भविष्यवाणी योग्य बनाता है, न कि कैओटिक।
बैकअप, अपग्रेड, और डिजास्टर रिकवरी पर प्रभाव
क्योंकि etcd क्लस्टर की कॉन्फ़िग और परिवर्तन इतिहास रखता है, यह उन स्थितियों में भी संरक्षित करना आवश्यक होता है:
- बैकअप्स: बिना etcd स्नैपशॉट के आप क्लस्टर ऑब्जेक्ट्स को भरोसेमंद तरीके से रिस्टोर नहीं कर सकते।
- अपग्रेड्स: सावधान etcd हेल्थ और स्नैपशॉटिंग अपग्रेड रिस्क कम करता है।
- डिजास्टर रिकवरी: etcd को रिस्टोर करना अक्सर कंट्रोल प्लेन को उसी इरादे के साथ वापस पाने का सबसे तेज़ रास्ता होता है।
व्यावहारिक मार्गदर्शन
कंट्रोल-प्लेन स्टेट को क्रिटिकल डेटा की तरह ट्रीट करें। नियमित etcd स्नैपशॉट्स लें, रिस्टोर्स टेस्ट करें, और बैकअप्स क्लस्टर से बाहर स्टोर रखें। यदि आप managed Kubernetes चलाते हैं, तो अपने प्रोवाइडर से जानें कि वे क्या बैकअप करते हैं—और किन चीज़ों का बैकअप आपको खुद लेना है (उदा., परसिस्टेंट वॉल्यूम और ऐप‑लेवल डेटा)।
निर्णय 8: प्लग‑इन योग्य शेड्यूलिंग और रिसोर्स अवेयरनेस
Kubernetes ने "कहाँ वर्कलोड चले" को अनदेखा नहीं किया। शुरुआती ही Scheduler को एक अलग कंपोनेंट के रूप में रखा गया जो काम करता है: Pods को उन नोड्स से मैच करना जो वास्तव में उन्हें चला सकते हैं, क्लस्टर की वर्तमान स्थिति और Pod की माँगों के आधार पर।
शेड्यूलर कैसे वर्कलोड्स को नोड्स से मैच करता है
ऊपर के स्तर पर, शेड्यूलिंग दो‑स्टेप निर्णय है:
- Filter: उन नोड्स को हटा दें जो हार्ड कॉन्स्ट्रेंट्स पूरा नहीं करते (CPU/memory कम, जरूरी लेबल्स गायब, taints incompatible, पोर्ट्स पहले से ले लिए गए, आदि)।
- Score: बचे हुए नोड्स को प्राथमिकताएँ दें (ज़ोन के बीच फैलाओ, दक्षता के लिए पैक करो, noisy neighbors से बचो, affinity नियमों का सम्मान करो)।
यह संरचना शेड्यूलिंग को बिना सब कुछ फिर से लिखे विकसित करने योग्य बनाती है।
कन्सर्न्स को अलग रखना: scheduler vs runtime vs networking
एक प्रमुख डिज़ाइन निर्णय जिम्मेदारियों को साफ़ रखना था:
- scheduler प्लेसमेंट तय करता है।
- container runtime (और kubelet) चुने गए नोड पर निष्पादन करते हैं।
- networking layer एक बार चीज़ें चलने पर connectivity प्रदान करता है।
इन कन्सर्न्स को अलग रखने से किसी एक क्षेत्र में सुधार दूसरे को नया शेड्यूलिंग मॉडल लागू करने के लिये मजबूर नहीं करता।
कंस्ट्रेंट्स और प्राथमिकताएँ स्वाभाविक रूप से बढ़ीं
रिसोर्स अवेयरनेस ने शुरु में requests और limits के साथ meaningful संकेत दिए, न कि अनुमान पर आधारित। वहाँ से Kubernetes ने और नियंत्रण जोड़े—node affinity/anti-affinity, pod affinity, priorities and preemption, taints and tolerations, और topology-aware spreading—एक ही नींव पर बने हुए।
आधुनिक प्रभाव: मल्टी‑टेनेट और लागत‑कुशल प्लेसमेंट
यह अप्रोच आज के साझा क्लस्टर्स को सक्षम करती है: टीमें प्राथमिकताओं और taints के साथ महत्वपूर्ण सेवाओं को अलग कर सकती हैं, जबकि सब ऊंची उपयोगिता से लाभ उठाते हैं। बेहतर bin-packing और topology controls के साथ प्लेटफ़ॉर्म वर्कलोड्स को लागत‑कुशल तरीके से रख सकते हैं बिना भरोसेमंदता खोए।
निर्णय 9: "एक ही बिल्ट‑इन तरीका" से अधिक एक्स्टेंसिबिलिटी
इरादे से चलती ऐप बनाएं
चैट से असली ऐप बनाएं और देखें कि Koder.ai के साथ आप कितनी तेज़ी से सुधार कर सकते हैं।
Kubernetes एक पूरा, opinionated प्लेटफ़ॉर्म अनुभव (buildpacks, app routing rules, background jobs, config conventions, आदि) बनाकर भेज सकता था। लेकिन जो बेडा और शुरुआती टीम ने कोर को एक छोटे वादे पर केंद्रित रखा: वर्कलोड्स को भरोसेमंद तरीके से चलाना और heal करना, उन्हें एक्सपोज़ करना, और ऑटोमेशन के लिए एक सुसंगत API देना।
Kubernetes पूरा PaaS क्यों नहीं बनने की कोशिश किया
एक "पूर्ण PaaS" हर किसी पर एक workflow और trade-offs थोप देता। Kubernetes ने व्यापक आधार लक्ष्य रखा ताकि कई तरह के प्लेटफ़ॉर्म‑स्टाइल—Heroku-जैसी डेवलपर सादगी, एंटरप्राइज़ गवर्नेंस, बैच + ML पाइपलाइंस, या बुनियादी इन्फ्रास्ट्रक्चर कंट्रोल—का समर्थन कर सके बिना किसी एक उत्पाद दर्शन में लॉक किए।
एक्स्टेंशन कैसे सुरक्षित रूप से फीचर्स जोड़ने देते हैं
Kubernetes की extensibility मैकेनिज्म ने क्षमाशील तरीके दिए:
- CRDs नए API प्रकार जोड़ने देते हैं (उदा.,
Certificate या Database) जो मूल की तरह लगते हैं।
- Controllers/operators उन नए रिसोर्सेस को उसी desired-state पैटर्न से reconcile करते हैं जैसा बिल्ट‑इन कम्पोनेंट्स करते हैं।
- Admission controllers/webhooks API सीमा पर नीति लागू करने और डिफ़ॉल्ट्स mutate करने की सुविधा देते हैं।
इसका मतलब है कि आंतरिक प्लेटफ़ॉर्म टीमें और विक्रेता add-on के रूप में फीचर्स भेज सकते हैं, जबकि Kubernetes प्रिमिटिव्स जैसे RBAC, namespaces, और audit logs का उपयोग कर सकते हैं।
लाभ—और मुख्य जोखिम
विक्रेताओं के लिए यह बिना Kubernetes fork किए विभेदित उत्पाद सक्षम करता है। आंतरिक टीमों के लिए यह संगठनात्मक जरूरतों के अनुसार "Kubernetes पर प्लेटफ़ॉर्म" बनाने की अनुमति देता है।
ट्रेड‑ऑफ है इकोसिस्टम स्प्रॉल: बहुत सारे CRDs, ओवरलैपिंग टूल्स, और असंगत कन्वेंशन्स। गवर्नेंस—मानक, मालिकाना, वर्शनिंग, और डिप्रिकेशन नीतियाँ—प्लेटफ़ॉर्म काम का हिस्सा बन जाती हैं।
इन निर्णयों का आधुनिक एप्लिकेशन प्लेटफ़ॉर्म्स पर प्रभाव
Kubernetes के शुरुआती चुनावों ने सिर्फ एक कंटेनर शेड्यूलर नहीं बनाया—उन्होंने एक reusable प्लेटफ़ॉर्म कर्नेल बनाया। इसलिए कई आधुनिक आंतरिक डेवलपर प्लेटफ़ॉर्म (IDPs) मूल रूप से "Kubernetes प्लस opinionated वर्कफ़्लोज़" हैं। डिक्लेरेटिव मॉडल, कंट्रोलर, और सुसंगत API ने उच्च‑स्तरीय उत्पादों का निर्माण संभव किया—हर बार deployment, reconciliation, और service discovery को दोबारा नहीं बनाते हुए।
Kubernetes एक साझा कंट्रोल प्लेन के रूप में
क्योंकि API ही प्रोडक्ट सरफेस है, विक्रेता और प्लेटफ़ॉर्म टीमें एक कंट्रोल प्लेन पर मानकीकरण कर सकती हैं और ऊपर अलग‑अलग अनुभव बना सकती हैं: GitOps, multi-cluster management, policy, service catalogs, और deployment ऑटोमेशन। यह एक बड़ा कारण है कि Kubernetes क्लाउड‑नेटिव प्लेटफ़ॉर्म्स के लिए सामान्य हरफनमौल बन गया: एकीकरण API को लक्षित करते हैं, किसी विशिष्ट UI को नहीं।
क्या रहा कठिन (Day‑2 वास्तविकता)
साफ़ एब्स्ट्रैक्शन्स के बावजूद, सबसे कठिन काम अभी भी ऑपरेशनल है:
- सिक्योरिटी: पहचान, नेटवर्क नीति, secrets, और सप्लाई‑चेन ट्रस्ट
- अपग्रेड्स: Kubernetes वर्शन, CRDs, और add-ons अलग‑अलग गति से आगे बढ़ते हैं
- विश्वसनीयता: कंट्रोलर्स, मिसकॉनफिगरेशन, और noisy neighbors का डिबगिंग
Kubernetes‑आधारित प्लेटफ़ॉर्म का मूल्यांकन कैसे करें
ऐसे प्रश्न पूछें जो ऑपरेशनल मैच्योरिटी को उजागर करें:
- अपग्रेड्स कैसे हैं, और रोलबैक कहानी क्या है?
- कौन‑से हिस्से standard Kubernetes हैं और कौन‑से प्रॉप्रायरेटरी एक्सटेंशन्स?
- किन गार्डरेल्स (policy, defaults, templates) से फुट‑गन्स रोके जाते हैं?
- सिस्टम कितना observable है (इवेंट्स, लॉग्स, ऑडिट ट्रेल्स), और incidents किसके द्वारा हैंडल होते हैं?
एक अच्छा प्लेटफ़ॉर्म cognitive load घटाता है बिना underlying कंट्रोल प्लेन को छिपाते हुए या escape hatches को दर्दनाक बना दिए।
एक व्यावहारिक नजरिया: क्या प्लेटफ़ॉर्म टीमों को "विचार → चलती सेवा" तक मदद करता है बिना हर किसी को पहले दिन ही Kubernetes एक्सपर्ट बनना जरूरी किए? "vibe-coding" श्रेणी के टूल—जैसे Koder.ai—इस बात पर जोर देते हैं कि टीमें चैट से वास्तविक एप्लिकेशन जेनरेट कर सकें (React वेब, Go बैकेंड के साथ PostgreSQL, Flutter मोबाइल) और फिर planning mode, snapshots, और rollback जैसी सुविधाओं से तेज़ी से iterate कर सकें। चाहे आप ऐसा कुछ अपनाएँ या अपना पोर्टल बनाएं, लक्ष्य वही है: Kubernetes के मज़बूत प्रिमिटिव्स बनाए रखें और उनके आसपास के वर्कफ़्लो ओवरहेड को घटाएँ।
मुख्य निष्कर्ष और व्यावहारिक सबक
Kubernetes जटिल महसूस कर सकता है, पर इसका अधिकांश "अजीबपन" जानबूझकर है: यह कई छोटे प्रिमिटिव्स का सेट है जो कई तरह के प्लेटफ़ॉर्म में कंपोज़ करने के लिए डिज़ाइन किए गए हैं।
दो सामान्य भ्रांतियाँ साफ़ करें
पहला: "Kubernetes सिर्फ Docker orchestration है।" Kubernetes का मुख्य उद्देश्य कंटेनर शुरू करना नहीं है। यह desired state (आप क्या चलाना चाहते हैं) और actual state (वास्तव में क्या चल रहा है) के बीच लगातार reconciliation के बारे में है, फेलियर्स, रोलआउट्स, और बदलती मांग के पार।
दूसरा: "अगर हम Kubernetes इस्तेमाल करते हैं तो सब कुछ microservices बन जाएगा।" Kubernetes माइक्रोसर्विसेज़ का समर्थन करता है, पर यह monoliths, batch jobs, और आंतरिक प्लेटफ़ॉर्म्स का भी समर्थन करता है। यूनिट्स (Pods, Services, labels, controllers, और API) न्यूट्रल हैं; आपकी आर्किटेक्चर‑चॉइस टूल से निर्धारित नहीं होती।
जटिलता असल में कहाँ से आती है
कठिन हिस्से अक्सर YAML या Pods नहीं होते—वे हैं नेटवर्किंग, सिक्योरिटी, और बहु‑टीम उपयोग: पहचान और एक्सेस, secrets मैनेजमेंट, नीतियाँ, ingress, ऑब्ज़र्वेबिलिटी, सप्लाई‑चेन कंट्रोल्स, और गार्डरेल्स बनाना ताकि टीमें सुरक्षित तरीके से शिप कर सकें बिना एक‑दूसरे पर कदम रखे।
निर्णय‑स्तरीय सबक जिन्हें आप उपयोग कर सकते हैं
योजना बनाते समय मूल डिज़ाइन बेट्स के संदर्भ में सोचें:
- डिक्लेरेटिव वर्कफ़्लोज़ और ऐसे ऑटोमेशन पसंद करें जो ड्रिफ्ट reconcile कर सकें।
- टीमों और घटकों के बीच कपलिंग कम रखने के लिए labels/selectors का उपयोग करें।
- API को एक प्रोडक्ट की तरह ट्रीट करें: वर्शनिंग, कन्वेंशन्स, और स्पष्ट ओनरशिप मायने रखती है।
एक व्यावहारिक अगला कदम
अपनी असली आवश्यकताओं को Kubernetes प्रिमिटिव्स और प्लेटफ़ॉर्म लेयर्स के साथ मैप करें:
-
Workloads → Pods/Deployments/Jobs
-
Connectivity → Services/Ingress
-
Operations → controllers, policies, और observability
अगर आप मूल्यांकन या मानकीकरण कर रहे हैं, यह मैप लिखें और स्टेकहोल्डर्स के साथ रिव्यू करें—फिर अपने प्लेटफ़ॉर्म को ट्रेंड्स के आस‑पास नहीं बल्कि गैप्स के चारों ओर क्रमिक रूप से बनाएँ।
यदि आप बिल्ड साइड (न कि सिर्फ रन साइड) को तेज़ करना चाहते हैं, तो सोचें कि आपकी delivery workflow किस तरह इरादा को deployable सर्विसेज़ में बदलती है। कुछ टीमों के लिए यह curated टेम्पलेट्स का सेट है; दूसरों के लिए यह AI-सहायता प्राप्त वर्कफ़्लो जैसा कुछ है (जैसे Koder.ai) जो एक शुरुआती काम करने वाली सर्विस जल्दी तैयार कर सकता है और फिर स्रोत कोड को गहरे कस्टमाइज़ेशन के लिए एक्सपोर्ट कर सकता है—जबकि आपका प्लेटफ़ॉर्म अभी भी Kubernetes के मूल डिज़ाइन निर्णयों से लाभ उठाता है।