11 अक्टू॰ 2025·8 मिनट
Kafka इवेंट स्ट्रीमिंग: कब एक क्यू काम करता है और कब लॉग बेहतर है
Kafka इवेंट स्ट्रीमिंग ने घटनाओं को एक ऑर्डर्ड लॉग मानकर सिस्टम डिज़ाइन बदल दिया। जानें कब एक साधारण क्यू पर्याप्त है और कब लॉग फायदेमंद होता है।
Kafka इवेंट स्ट्रीमिंग ने घटनाओं को एक ऑर्डर्ड लॉग मानकर सिस्टम डिज़ाइन बदल दिया। जानें कब एक साधारण क्यू पर्याप्त है और कब लॉग फायदेमंद होता है।
अधिकांश प्रोडक्ट्स साधारण पॉइंट-टू-पॉइंट इंटीग्रेशंस से शुरू होते हैं: सिस्टम A सिस्टम B को कॉल करता है, या एक छोटा स्क्रिप्ट डेटा एक जगह से दूसरी जगह कॉपी कर देता है। यह तब तक काम करता है जब तक प्रोडक्ट बढ़ता नहीं, टीमें विभाजित नहीं होतीं और कनेक्शनों की संख्या गुणा नहीं हो जाती। जल्द ही हर बदलाव के लिए कई सर्विसेज़ में समन्वय चाहिए होता है, क्योंकि एक छोटा फ़ील्ड या स्टेटस अपडेट निर्भरताओं की चैन में असर डाल सकता है।
स्पीड अक्सर पहली चीज़ है जो टूटती है। नया फीचर जोड़ने का मतलब कई इंटीग्रेशंस अपडेट करना, कई सर्विसेज़ को री-डिप्लॉय करना और उम्मीद रखना कि किसी ने पुराने व्यवहार पर निर्भर नहीं किया होगा।
फिर डिबगिंग पीड़ा बन जाती है। जब UI में कुछ गलत दिखे, तो बुनियादी सवालों का जवाब देना मुश्किल होता है: क्या हुआ, किस क्रम में हुआ, और किस सिस्टम ने जो वैल्यू आप देख रहे हैं वो लिखी?
अक्सर कमी एक ऑडिट ट्रेल की होती है। यदि डेटा सीधे एक डेटाबेस से दूसरे में धकेला जा रहा है (या रास्ते में ट्रांसफॉर्म हुआ है), तो आप इतिहास खो देते हैं। आपको अंतिम स्थिति दिख सकती है, पर उस तक पहुँचने वाली घटनाओं की श्रृंखला नहीं। इंसीडेंट रिव्यू और कस्टमर सपोर्ट दोनों तब प्रभावित होते हैं क्योंकि आप यह पुष्टि करने के लिए अतीत को री-प्ले नहीं कर सकते कि क्या बदला और क्यों।
यह वही जगह है जहाँ “किसका सच है” वाला तर्क शुरू होता है। एक टीम कहती है, “बिलिंग सर्विस सोर्स ऑफ ट्रूथ है।” दूसरी कहती है, “ऑर्डर सर्विस है।” असल में, हर सिस्टम का आंशिक दृश्य होता है, और पॉइंट-टू-पॉइंट इंटीग्रेशंस इस असहमति को रोज़मर्रा की रगड़ में बदल देते हैं।
एक सरल उदाहरण: एक ऑर्डर बनाया गया, फिर भुगतान हुआ, फिर रिफंड हुआ। अगर तीन सिस्टम सीधे एक दूसरे को अपडेट करते हैं, तो retries, timeouts या मैनुअल फिक्सेस होने पर हर किसी के पास अलग कहानी रह सकती है।
यही Kafka इवेंट स्ट्रीमिंग के पीछे का मुख्य डिज़ाइन सवाल बन जाता है: क्या आपको बस काम एक जगह से दूसरी जगह भेजना है (एक क्यू), या क्या आपको एक साझा, Durable रिकॉर्ड चाहिए कि क्या हुआ जिसे कई सिस्टम पढ़ सकें, रीवाइंड कर सकें और भरोसा कर सकें (एक लॉग)? जवाब तय करता है कि आप सिस्टम कैसे बनाते, डिबग करते और बढ़ाते हैं।
Jay Kreps ने Kafka को आकार देने में मदद की और उससे भी ज़्यादा महत्वपूर्ण — कई टीमों के डेटा मूवमेंट के बारे में सोचने का तरीका बदला। उपयोगी परिवर्तन माइंडसेट है: मैसेज को एक बार का डिलीवरी समझना बंद करें, और सिस्टम गतिविधि को एक रिकॉर्ड के रूप में देखना शुरू करें।
मूल विचार सरल है। महत्वपूर्ण बदलावों को अपरिवर्तनीय तथ्यों की स्ट्रीम के रूप में मॉडल करें:
हर इवेंट एक ऐसा तथ्य है जिसे बाद में एडिट नहीं करना चाहिए। अगर बाद में कुछ बदले तो आप एक नया इवेंट जोड़ते हैं जो नई सच्चाई बताता है। समय के साथ, ये तथ्यों का लॉग बन जाता है: आपके सिस्टम का एपनड-ओनली इतिहास।
यहीं Kafka इवेंट स्ट्रीमिंग कई बुनियादी मैसेजिंग सेटअप्स से अलग दिखती है। बहुत सी क्यूज़ “भेजो, प्रोसेस करो, डिलीट करो” के इर्द-गिर्द बनी होती हैं। वह ठीक है जब काम सिर्फ हैंडऑफ हो। लॉग का नजरिया कहता है, “इतिहास रखें ताकि कई कंज्यूमर अब और भविष्य में इसका उपयोग कर सकें।”
री-प्ले करना व्यावहारिक सुपरपावर है।
अगर कोई रिपोर्ट गलत है, आप उसी इवेंट हिस्ट्री को एक फिक्स्ड एनालिटिक्स जॉब के साथ फिर से चला सकते हैं और देख सकते हैं कि संख्याएँ कहाँ बदलती हैं। अगर किसी बग ने गलत ईमेल भेज दिए, तो आप इवेंट्स को टेस्ट एनवायरनमेंट में रीप्ले करके वही टाइमलाइन दोहरा सकते हैं। अगर नए फीचर को पुराने डेटा की ज़रूरत है, तो आप एक नया कंज्यूमर बना सकते हैं जो शुरू से पढ़ना शुरू करे और अपनी गति से पकड़ बनाए।
यहाँ एक ठोस उदाहरण है। कल्पना करें कि आपने फ़्रॉड चेक बाद में जोड़े जबकि आपने महीनों के पेमेंट पहले ही प्रोसेस किए थे। पेमेंट और अकाउंट इवेंट्स का लॉग होने पर आप अतीत को रीप्ले कर सकते हैं, असली सीक्वेंस पर नियम ट्रेन/कैलिब्रेट कर सकते हैं, पुराने ट्रांज़ैक्शंस के लिए रिस्क स्कोर निकाल सकते हैं, और बिना डेटाबेस री-राइट किए "fraud_review_requested" इवेंट बैकफिल कर सकते हैं।
यह ध्यान देने योग्य है कि यह आपको क्या करने के लिए मजबूर करता है। लॉग-आधारित अप्रोच आपको इवेंट्स को स्पष्ट नाम देने, उन्हें स्थिर रखने और स्वीकार करने के लिए प्रेरित करता है कि कई टीमें और सर्विसेज़ उन पर निर्भर होंगी। यह उपयोगी सवाल भी बुलवाता है: ट्रूथ का स्रोत क्या है? यह इवेंट लंबी अवधि में क्या मतलब रखता है? गलती होने पर हम क्या करते हैं?
मूल्य उस विशेष व्यक्ति का नहीं है जो यह कहता है। इसका अर्थ है कि एक साझा लॉग आपके सिस्टम की मेमोरी बन सकता है, और मेमोरी ही वह चीज़ है जो सिस्टम को बढ़ने देती है बिना हर बार थोड़ी सी नई कंज्यूमर जोड़ने पर टूटे।
एक मैसेज क्यू आपके सॉफ़्टवेयर के लिए टू-डू लाइन जैसा है। प्रोड्यूसर काम लाइन में डालते हैं, कंज्यूमर अगला आइटम लेते हैं, काम करते हैं, और आइटम गायब हो जाता है। सिस्टम मुख्यतः इस बारे में है कि हर टास्क को जितनी जल्दी हो सके एक बार हैंडल किया जाए।
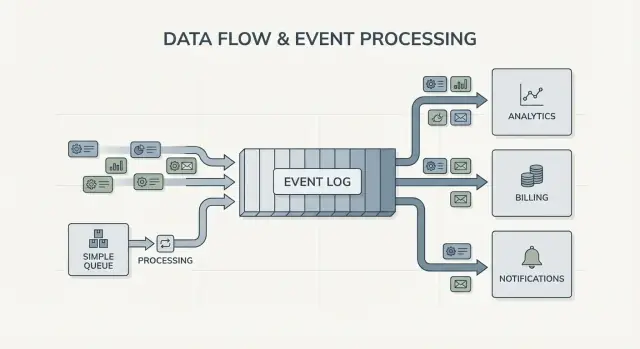
एक लॉग अलग है। यह उन घटनाओं का ऑर्डर्ड रिकॉर्ड है जो हुईं, एक Durable सिक्वेंस में रखी जाती हैं। कंज्यूमर इवेंट्स को "ले" कर नहीं हटाते; वे अपने-अपने गति से लॉग पढ़ते हैं और बाद में फिर से पढ़ भी सकते हैं। Kafka इवेंट स्ट्रीमिंग में यह लॉग मुख्य विचार है।
याद रखने का एक व्यावहारिक तरीका:
रिटेंशन डिज़ाइन बदल देता है। क्यू में, अगर बाद में किसी फीचर को पुराने मैसेजेज़ पर निर्भर होना पड़े (एनालिटिक्स, फ्रॉड चेक, बग के बाद रीप्ले), तो अक्सर आपको अलग डेटाबेस जोड़ना पड़ता है या कहीं और कॉपियाँ पकड़नी पड़ती हैं। लॉग के साथ, री-प्ले सामान्य है: आप शुरुआत से (या एक ज्ञात चेकपॉइंट से) पढ़कर एक डेराइव्ड व्यू फिर से बना सकते हैं।
फैन-आउट भी बड़ा अंतर है। कल्पना करें कि एक चेकआउट सर्विस "OrderPlaced" इमिट करती है। क्यू के साथ, आप आम तौर पर इसे प्रोसेस करने के लिए एक वर्कर ग्रुप चुनते हैं, या कई क्यूज़ में काम की नकल करते हैं। लॉग के साथ, billing, email, inventory, search indexing और analytics सभी उसी इवेंट स्ट्रीम को स्वतंत्र रूप से पढ़ सकते हैं। हर टीम अपनी गति से बढ़ सकती है, और नया कंज्यूमर बाद में जोड़ना प्रोड्यूसर बदलने की ज़रूरत नहीं रखता।
तो मानसिक मॉडल सीधा है: जब आप टास्क मूव कर रहे हों तो क्यू का उपयोग करें; जब आप ऐसे इवेंट्स रिकॉर्ड कर रहे हों जिनको कंपनी के कई हिस्से अब या बाद में पढ़ना चाहते हैं तो लॉग का उपयोग करें।
इवेंट स्ट्रीमिंग डिफ़ॉल्ट सवाल पलट देती है। "मैं किसे यह मैसेज भेजूँ?" पूछने की बजाय आप "अभी क्या हुआ?" रिकॉर्ड करना शुरू करते हैं। यह छोटा सा बदलाव है, पर यह आपके सिस्टम को मॉडल करने का तरीका बदल देता है।
आप OrderPlaced या PaymentFailed जैसे फैक्ट्स प्रकाशित करते हैं, और सिस्टम के अन्य भाग तय करते हैं कि वे कब और कैसे प्रतिक्रिया देंगे।
Kafka इवेंट स्ट्रीमिंग के साथ, प्रोड्यूसरों को डायरेक्ट इंटीग्रेशन की लिस्ट की ज़रूरत नहीं रहती। एक चेकआउट सर्विस एक इवेंट प्रकाशित कर सकती है, और उसे नहीं जानना होता कि analytics, email, fraud checks या भविष्य की recommendation सर्विस इसका उपयोग करेगी या नहीं। नए कंज्यूमर बाद में आ सकते हैं, पुराने को रोक दिया जा सकता है, और प्रोड्यूसर का व्यवहार वैसा ही रहता है।
यह गलती से उबरने के तरीके को भी बदलता है। सिर्फ़ मैसेजिंग दुनिया में, एक कंज्यूमर कुछ मिस कर दे या बग कर दे तो डेटा अक्सर "गाया" होता है जब तक आपने कस्टम बैकअप नहीं बनाए। लॉग के साथ, आप कोड ठीक कर सकते हैं और इतिहास को रीप्ले करके सही स्टेट फिर से बना सकते हैं। अक्सर यह मैनुअल डेटाबेस एडिट्स या एक-ऑफ स्क्रिप्ट्स से बेहतर होता है जिनपर किसी का भरोसा नहीं होता।
व्यवहार में, यह परिवर्तन कुछ ठोस तरीकों में दिखता है: आप इवेंट्स को Durable रिकॉर्ड मानते हैं, आप फ़ीचर्स जोड़ते समय प्रोड्यूसर बदलने के बजाय सब्सक्राइब करते हैं, आप रीड मॉडल (सर्च इंडेक्स, डैशबोर्ड) को शुरुआत से पढ़कर फिर से बना सकते हैं, और आपको सेवाओं के बीच क्या हुआ इसकी स्पष्ट टाइमलाइन मिलती है।
ऑब्ज़रविबिलिटी बेहतर होती है क्योंकि इवेंट लॉग एक साझा संदर्भ बन जाता है। जब कुछ गलत होता है, आप एक बिजनेस सीक्वेंस को फॉलो कर सकते हैं: ऑर्डर बनाया गया, इन्वेंटरी रिज़र्व हुई, पेमेंट फिर से ट्राय हुआ, शिपमेंट शेड्यूल हुआ। यह टाइमलाइन अक्सर बिखरे एप्लिकेशन लॉग्स से समझने में आसान होती है क्योंकि यह बिजनेस फैक्ट्स पर केन्द्रित होती है।
एक ठोस उदाहरण: यदि किसी डिस्काउंट बग ने दो घंटे के लिए गलत प्राइस लगा दिया, तो आप फिक्स शिप कर सकते हैं और प्रभावित इवेंट्स को रीप्ले करके टोटल्स फिर से गणना कर सकते हैं, इनवॉइस अपडेट कर सकते हैं और एनालिटिक्स रिफ्रेश कर सकते हैं। आप आउटपुट्स को फिर से व्युत्पन्न करके सुधार रहे हैं, बजाय यह अनुमान लगाने के कि किस टेबल को मैन्युअल पैच करना चाहिए।
साधारण क्यू सही टूल है जब आप काम को मूव कर रहे हों, न कि लंबे समय का रिकॉर्ड बना रहे हों। लक्ष्य एक वर्कर को टास्क सौंपना, उसे चलाना और फिर भूल जाना होता है। अगर किसी को अतीत री-प्ले करने, पुराने इवेंट्स जांचने, या बाद में नए कंज्यूमर्स जोड़ने की ज़रूरत नहीं है, तो क्यू चीज़ों को सरल रखता है।
क्यूज़ बैकग्राउंड जॉब्स के लिए बेहतरीन हैं: साइनअप ईमेल भेजना, अपलोड के बाद इमेज रिसाइज़ करना, रात में रिपोर्ट जनरेट करना, या किसी धीमी बाहरी API को कॉल करना। इन मामलों में मैसेज बस एक वर्क टिकट है। एक बार वर्कर जॉब समाप्त कर दे तो टिकट ने भी अपना काम कर दिया।
क्यू सामान्य रूप से उस ओनरशिप मॉडल में फिट बैठता है जहाँ एक कंज्यूमर ग्रुप काम के लिए जिम्मेदार होता है और अन्य सर्विसेज़ उसी मैसेज को स्वतंत्र रूप से पढ़ने की उम्मीद नहीं रखतीं।
क्यू आम तौर पर पर्याप्त होता है जब इनमें से अधिकांश सच हों:
उदाहरण: एक प्रोडक्ट उपयोगकर्ता की फ़ोटो अपलोड करता है। ऐप एक "resize image" टास्क क्यू में लिखता है। वर्कर A इसे उठाता है, थंबनेल बनाता है, स्टोर करता है और टास्क को पूरा कर मार्क करता है। अगर टास्क दो बार चले तो आउटपुट समान रहेगा (आइडेमपोटेंट), इसलिए at-least-once डिलीवरी ठीक है। किसी अन्य सर्विस को बाद में उस टास्क को पढ़ने की ज़रूरत नहीं है।
अगर आपकी ज़रूरतें साझा तथ्यों (कई कंज्यूमर्स), री-प्ले, ऑडिट, या “सिस्टम ने पिछले सप्ताह क्या माना था?” की ओर बढ़ने लगती हैं, तो वहाँ Kafka इवेंट स्ट्रीमिंग और लॉग-आधारित अप्रोच फायदेमंद होना शुरू करते हैं।
लॉग-आधारित सिस्टम तब फायेदेमंद होता है जब इवेंट्स एक बार के मैसेज से निकलकर साझा इतिहास बन जाते हैं। "भेजो और भूल जाओ" के बजाय आप एक ऑर्डर्ड रिकॉर्ड रखते हैं जिसे कई टीमें अपनी गति से पढ़ सकें और बाद में री-प्ले कर सकें।
सबसे स्पष्ट संकेत कई कंज्यूमर्स हैं। एक इवेंट जैसे OrderPlaced बिलिंग, ईमेल, फ्रॉड चेक, सर्च इंडेक्सिंग और एनालिटिक्स को फीड कर सकता है। लॉग के साथ हर कंज्यूमर उसी स्ट्रीम को स्वतंत्र रूप से पढ़ता है। आपको कस्टम फैन-आउट पाइपलाइन बनाने या यह तय करने की ज़रूरत नहीं कि मैसेज किसे पहले मिले।
एक और लाभ यह जानने की क्षमता है कि "तब हमें क्या मालूम था?" अगर ग्राहक चार्ज पर विवाद करे, या कोई सिफारिश गलत लगे, तो एक एपेंड-ओनली इतिहास के साथ आप घटनाओं को उसी क्रम में री-प्ले कर सकते हैं जैसा वे आए थे। ऐसी ऑडिट ट्रेल बाद में कड़ी लगाकर जोड़ना मुश्किल होता है।
आपको यह भी एक व्यावहारिक तरीका देता है पुराने फीचर्स जोड़ने का बिना पुराने वर्किंग को फिर से लिखे। अगर आप महीनों बाद एक नया "shipping status" पेज जोड़ते हैं, तो एक नया सर्विस सब्सक्राइब कर के मौजूद इतिहास से बैकफिल कर सकता है, बजाय हर अपस्ट्रीम सिस्टम से एक्सपोर्ट माँगने के।
लॉग-आधारित अप्रोच अक्सर तब सार्थक होता है जब आप इनमें से कोई ज़रूरत पहचानते हैं:
एक सामान्य पैटर्न यह है कि प्रोडक्ट ऑर्डर और ईमेल के साथ शुरू होता है। बाद में, फाइनेंस राजस्व रिपोर्ट चाहता है, प्रोडक्ट फनल चाहता है, और ऑप्स लाइव डैशबोर्ड चाहता है। अगर हर नई ज़रूरत आपको डेटा को नई पाइपलाइन से कॉपी करने पर मजबूर करे, तो लागत जल्दी बढ़ जाती है। एक साझा इवेंट लॉग टीमों को एक ही सोर्स ऑफ ट्रूथ पर बनाने देता है, भले ही सिस्टम बढ़े और इवेंट आकार बदलें।
एक साधारण क्यू और लॉग-आधारित अप्रोच के बीच चुनना तब आसान होता है जब आप इसे एक प्रोडक्ट निर्णय की तरह देखें। एक साल बाद आपको क्या सच चाहिए, इस दृष्टि से शुरू करें, न कि सिर्फ़ इस हफ्ते क्या काम करता है।
प्रकाशकों और रीडर्स का नक्शा बनाएं। लिखें कि आज कौन इवेंट बनाता है और कौन पढ़ता है, फिर संभावित भविष्य के कंज्यूमर जोड़ें (analytics, search indexing, fraud checks, customer notifications)। अगर आप उम्मीद करते हैं कि कई टीमें स्वतंत्र रूप से वही इवेंट पढ़ेंगी, तो एक लॉग समझ में आने लगता है।
पूछें कि क्या आपको इतिहास को फिर से पढ़ने की ज़रूरत पड़ेगी। स्पष्ट कारण बताएं: बग के बाद रीप्ले, बैकफिल्स, या अलग-अलग गति से पढ़ने वाले कंज्यूमर। क्यू एक बार का हैंडऑफ करने के लिए बढ़िया है। लॉग उन मामलों में बेहतर है जहाँ आप फिर से पढ़ने योग्य रिकॉर्ड चाहते हैं।
परिभाषित करें कि “हो गया” का क्या मतलब है। कुछ वर्कफ्लो के लिए हो गया मतलब है “जॉब चल गया” (ईमेल भेजा, इमेज रिसाइज़)। दूसरों के लिए हो गया मतलब है “इवेंट एक Durable फैक्ट है” (एक ऑर्डर रखा गया, एक भुगतान अधिकृत हुआ)। Durable फैक्ट्स आपको लॉग की तरफ़ धकेलते हैं।
डिलीवरी अपेक्षाएँ चुनें और तय करें कि डुप्लिकेट्स को कैसे हैंडल करेंगे। at-least-once डिलीवरी सामान्य है, जिसका मतलब है कि डुप्लिकेट्स हो सकते हैं। अगर डुप्लिकेट हानिकारक हो सकता है (कार्ड का डबल-चार्ज), तो आइडेमपोटेंसी की योजना बनाएं: प्रोसेस किए गए इवेंट ID स्टोर करें, अनूठे संकुलन उपयोग करें, या अपडेट्स को दोहराने पर सुरक्षित बनाएं।
एक पतला स्लाइस से शुरू करें। एक इवेंट स्ट्रीम चुनें जो समझने में आसान हो और वहाँ से बढ़ें। अगर आप Kafka इवेंट स्ट्रीमिंग चुनते हैं, तो पहला टॉपिक केंद्रित रखें, इवेंट्स को स्पष्ट नाम दें और असंबंधित इवेंट प्रकारों को मिलाने से बचें।
एक ठोस उदाहरण: अगर OrderPlaced बाद में shipping, invoicing, support, और analytics को फीड करेगा, तो एक लॉग हर टीम को अपनी गति से पढ़ने और गलतियों के बाद रीप्ले करने की अनुमति देता है। अगर आपको सिर्फ़ एक बैकग्राउंड वर्कर चाहिए जो रसीद भेजे, तो एक साधारण क्यू अक्सर काफी है।
एक छोटा ऑनलाइन स्टोर कल्पना करें। शुरू में उसे सिर्फ़ ऑर्डर लेना, कार्ड चार्ज करना और शिपिंग रिक्वेस्ट बनानी होती है। सबसे आसान वर्शन एक बैकग्राउंड जॉब है जो चेकआउट के बाद चलता है: “process order.” यह पेमेंट API से बात करता है, ऑर्डर रो अपडेट करता है, फिर शिपिंग को कॉल करता है।
वह क्यू स्टाइल तब अच्छा चलता है जब एक स्पष्ट वर्कफ़्लो हो, एक ही कंज्यूमर चाहिए और retries व डेड लेटर्स अधिकांश फेल्यर केस कवर करते हैं।
जैसे-जैसे स्टोर बढ़ता है, दर्द शुरू होता है। सपोर्ट ऑटोमैटिक "where is my order?" अपडेट चाहता है। फाइनेंस डेली राजस्व नंबर चाहता है। प्रोडक्ट टीम कस्टमर ईमेल चाहती है। फ्रॉड चेक शिपिंग से पहले होना चाहिए। एक सिंगल "process order" जॉब के साथ आप बार-बार वही वर्कर एडिट करते रहेंगे, ब्रांच जोड़ते रहेंगे, और कोर फ्लो में नए बग का जोखिम बढ़ेगा।
लॉग-आधारित अप्रोच में, चेकआउट छोटी फैक्ट्स के रूप में इवेंट्स उत्पन्न करता है और हर टीम उन पर बिल्ड कर सकती है। सामान्य इवेंट्स ऐसे दिख सकते हैं:
OrderPlacedPaymentConfirmedItemShippedRefundIssuedमुख्य बदलाव ओनरशिप में है। चेकआउट सर्विस OrderPlaced की ओनर है। पेमेंट्स सर्विस PaymentConfirmed की। शिपिंग ItemShipped की। बाद में नए कंज्यूमर बिना प्रोड्यूसर बदले आ सकते हैं: एक फ्रॉड सर्विस OrderPlaced और PaymentConfirmed पढ़कर रिस्क स्कोर कर सकती है, एक ईमेल सर्विस रसीद भेज सकती है, analytics फनल बना सकता है, और सपोर्ट टूल्स टाइमलाइन रख सकते हैं।
यहीं Kafka इवेंट स्ट्रीमिंग का लाभ दिखता है: लॉग इतिहास रखता है, इसलिए नए कंज्यूमर वापस जाकर शुरुआत से (या किसी ज्ञात पॉइंट से) पकड़ बना सकते हैं बजाय हर अपस्ट्रीम टीम से नया वेबहुक मांगने के।
लॉग आपके डेटाबेस की जगह नहीं लेता। आपको अभी भी करंट स्टेट के लिए डेटाबेस चाहिए: नवीनतम ऑर्डर स्टेटस, कस्टमर रिकॉर्ड, इन्वेंटरी काउंट और ट्रांज़ैक्शनल नियम (जैसे “payment confirmed होने पर ही शिप करें”)। लॉग को परिवर्तन का रिकॉर्ड समझें और डेटाबेस वह जगह जहां आप “अब क्या सच है” पूछते हैं।
इवेंट स्ट्रीमिंग सिस्टम को साफ़ महसूस करा सकता है, पर कुछ आम गलतियाँ लाभ को जल्दी मिटा सकती हैं। इनमें से ज़्यादातर तब होती हैं जब आप इवेंट लॉग को रिमोट कंट्रोल की तरह ट्रीट करते हैं बजाय रिकॉर्ड के।
एक बार-बार आने वाली गलती है इवेंट्स को कमाण्ड की तरह लिखना, जैसे "SendWelcomeEmail" या "ChargeCardNow." इससे कंज्यूमर्स आपके इरादे से सख्ती से जुड़े रहते हैं। इवेंट्स तथ्यों के रूप में बेहतर काम करते हैं: "UserSignedUp" या "PaymentAuthorized." तथ्य समय के साथ अच्छे रहते हैं। नई टीमें बाद में उन्हें बिना अनुमान लगाए फिर से उपयोग कर सकती हैं।
डुप्लिकेट्स और रिट्राइज अगली बड़ी तकलीफ हैं। वास्तविक सिस्टम में, प्रोड्यूसर रिट्राय करते हैं और कंज्यूमर्स फिर से प्रोसेस करते हैं। अगर आपने इसके लिए योजना नहीं बनाई तो डबल चार्ज, डबल ईमेल और गुस्से भरे सपोर्ट टिकट मिलेंगे। समाधान जटिल नहीं है, पर वह इरादतन होना चाहिए: आइडेमपोटेंट हैंडलर्स, स्थिर इवेंट IDs, और बिजनेस नियम जो “पहले लागू हो चुका” पहचान सकें।
आम pitfalls:
स्कीमा और वर्ज़निंग विशेष ध्यान मांगते हैं। भले ही आप JSON से शुरू करते हों, आपको एक स्पष्ट कॉन्ट्रैक्ट चाहिए: आवश्यक फील्ड, वैकल्पिक फील्ड, और बदलाव कैसे रोलआउट होंगे। एक छोटा बदलाव जैसे फील्ड का नाम बदलना एनालिटिक्स, बिलिंग, या मोबाइल ऐप्स को चुपके से तोड़ सकता है जो धीमे अपडेट होते हैं।
एक और जाल ओवर-स्प्लिटिंग है। टीमें अक्सर हर फीचर के लिए नई स्ट्रीम बना देती हैं। एक महीने बाद कोई यह जवाब नहीं दे पाता कि “एक ऑर्डर की वर्तमान स्थिति क्या है?” क्योंकि कथा बहुत सी जगह फैली हुई है।
इवेंट स्ट्रीमिंग अच्छे डेटा मॉडल की आवश्यकता नहीं हटाती। आपको अभी भी एक डेटाबेस चाहिए जो वर्तमान सच्चाई का प्रतिनिधित्व करे। लॉग इतिहास है, आपका पूरा एप्लिकेशन नहीं।
अगर आप क्यू और Kafka इवेंट स्ट्रीमिंग के बीच फंस गए हैं, तो कुछ तेज चेक से पता लग जाता है कि आपको साधारण हैंडऑफ़ चाहिए या एक लॉग जो वर्षों तक फिर से उपयोग हो सके।
अगर आपके उत्तर “नहीं” हैं: री-प्ले नहीं, केवल एक कंज्यूमर, और संदेश अल्पकालिक हैं — तो एक बेसिक क्यू आम तौर पर काफी है। अगर आपने “हाँ” कहा री-प्ले, कई कंज्यूमर, या लंबी रिटेंशन के लिए, तो लॉग-आधारित अप्रोच अक्सर फायदेमंद रहती है क्योंकि यह तथ्यों की एक स्ट्रीम को एक साझा सोर्स ऑफ ट्रूथ में बदल देती है जिस पर अन्य सिस्टम बिल्ड कर सकते हैं।
उत्तरों को एक छोटे, टेस्टेबल प्लान में बदलें।
यदि आप प्रोटोटाइप तेज़ी से कर रहे हैं, तो आप Koder.ai की प्लैनिंग मोड में इवेंट फ्लो स्केچ कर सकते हैं और डिज़ाइन पर इतरेट कर सकते हैं इससे पहले कि आप इवेंट नाम और रिट्राय नियम फाइनल करें। चूंकि Koder.ai सोर्स कोड एक्सपोर्ट, स्नैपशॉट्स और रोलबैक सपोर्ट करता है, यह एक छोटा प्रोड्यूसर-कंज्यूमर स्लाइस टेस्ट करने और शुरुआती एक्सपेरिमेंट्स को प्रोडक्शन डेट पर डालने से पहले एडजस्ट करने का व्यावहारिक तरीका है।
एक क्यू उन वर्क टिकट्स के लिए सबसे अच्छा है जिन्हें आप हैंडल कराना चाहते हैं और फिर भूल जाना चाहते हैं (ईमेल भेजना, इमेज रिसाइज़ करना, कोई जॉब चलाना)। एक लॉग उन फैक्ट्स के लिए बेहतर है जिन्हें आप रखना चाहते हैं और जिन्हें कई सिस्टम बाद में पढ़कर री-प्ले कर सकें (order placed, payment authorized, refund issued).
ऐसा तब महसूस होगा जब हर नए फीचर के लिए आपको कई इंटिग्रेशन छूने पड़ें, और डिबग करना इस तरह हो जाए: “किसने यह वैल्यू लिखा?” बिना किसी स्पष्ट टाइमलाइन के। एक लॉग मदद करता है क्योंकि यह एक साझा रिकॉर्ड बन जाता है जिसे आप निरीक्षण और री-प्ले कर सकते हैं, बजाय बिखरे हुए डेटाबेस स्टेट्स से अनुमान लगाने के।
जब आपको ऑडिट ट्रेल और री-प्ले की ज़रूरत हो: बग ठीक करने के लिए हिस्ट्री को फिर से प्रोसेस करना, पुराने डेटा से कोई नया फीचर बैकफिल करना, यह जांचना कि “उस समय हमारे पास क्या जानकारी थी?”, या कई कंज्यूमर्स (billing, analytics, support, fraud) को सपोर्ट करना बिना प्रोड्यूसर को बार-बार बदलने के।
क्योंकि सिस्टम जटिल तरीकों से फेल होते हैं: रिट्राइज, टाइमआउट, अंशिक आउटेज, और मैनुअल फिक्सेस। अगर हर सर्विस सीधे दूसरों को अपडेट करती है तो वे अलग-अलग कहानी बता सकती हैं। एक एपेंड-ओनली इवेंट हिस्ट्री आपको एक ऑर्डर्ड क्रम देती है जिससे आप समझ सकें कि क्या हुआ, भले ही कुछ कंज्यूमर्स डाउन रहे और बाद में कैच अप करें।
इवेंट्स को अपरिवर्तनीय फैक्ट्स के रूप में मॉडल करें (भूतकाल) जो कुछ पहले हुआ बताएं:
OrderPlaced, न कि ProcessOrderPaymentAuthorized, न कि ChargeCardNowयह मानकर चलें कि डुप्लिकेट होंगे (अकसर at-least-once डिलीवरी होती है)। हर कंज्यूमर को रीट्राई से सुरक्षित बनाएं:
डिफ़ॉल्ट नियम: पहले करेक्शन, फिर स्पीड।
आमतौर पर एडिटिव बदलाव करें: पुराने फील्ड रखें, नए वैकल्पिक फील्ड जोड़ें, और फील्ड का नाम बदलने/हटाने से बचें जिन पर मौजूदा कंज्यूमर्स निर्भर हैं। अगर ब्रेकिंग चेंज ज़रूरी हो तो इवेंट (या टॉपिक) वर्ज़निंग करें और कंज्यूमर को इरादतन माइग्रेट करें बजाय बस JSON अपडेट करने के।
एक पतला, एंड-टू-एंड स्लाइस से शुरू करें:
OrderPlaced → ईमेल रसीद)।orderId या userId)।नहीं। वर्तमान स्टेट और ट्रांज़ैक्शन के लिए एक डेटाबेस रखें (“अब क्या सच है”)। इवेंट लॉग हिस्ट्री और डेराइव्ड व्यू (एनालिटिक्स टेबल्स, सर्च इंडेक्स) को री-बिल्ड करने के लिए है। व्यावहारिक रूप से: DB पढ़ने/लिखने के लिए, लॉग वितरण, री-प्ले और ऑडिट के लिए।
प्लैनिंग मोड पब्लिशर्स/कंज्यूमर्स मैप करने, इवेंट नाम परिभाषित करने, और आइडेमपोटेंसी व रिटेंशन तय करने में उपयोगी है ताकि आप प्रोडक्शन कोड लिखने से पहले डिज़ाइन पर सहमत हों। फिर आप एक छोटा प्रोड्यूसर-कंज्यूमर स्लाइस लागू कर सकते हैं, स्नैपशॉट लें और जल्दी रोलबैक करें जब तक इवेंट शेप्स स्थिर न हों। स्थिर होने पर सोर्स कोड एक्सपोर्ट करके इसे किसी भी सर्विस की तरह तैनात करें।
UserEmailChanged, न कि UpdateEmailअगर कुछ बदलता है तो पुरानी एंट्री एडिट करने की बजाय नया इवेंट प्रकाशित करें जो नया ट्रूथ बताता हो।
लूप काम करता है यह साबित कर लें फिर और इवेंट्स और टीमों में बढ़ाएँ।