Kafka सरल भाषा में
Apache Kafka एक वितरित इवेंट स्ट्रीमिंग प्लेटफ़ॉर्म है। सरल शब्दों में, यह एक साझा, टिकाऊ “पाइप” है जो कई सिस्टमों को यह अनुमति देता है कि वे क्या हुआ इसकी जानकारी प्रकाशित करें और अन्य सिस्टम उन तथ्यों को पढ़ सकें—तेज़, स्केल पर, और क्रम में।
टीमें Kafka का उपयोग तब करती हैं जब डेटा को विश्वसनीय रूप से सिस्टमों के बीच स्थानांतरित करने की आवश्यकता हो बिना कड़ी जोड़े जाने के। एक एप्लिकेशन सीधे दूसरे को कॉल करने की बजाय (और तब विफल होने पर या धीमा होने पर टूटने की जगह), प्रोड्यूसर इवेंट्स को Kafka में लिखते हैं। कंज्यूमर उन्हें तब पढ़ते हैं जब वे तैयार होते हैं। Kafka घटनाओं को एक कॉन्फ़िगर किए जाने योग्य अवधि के लिए संग्रहीत करता है, इसलिए सिस्टम आउटेज से ठीक हो सकते हैं और इतिहास को फिर से प्रोसेस भी कर सकते हैं।
कुछ शब्द जो आप देखेंगे
- इवेंट / संदेश: कुछ हुआ उस घटना का रिकॉर्ड (उदाहरण के लिए “OrderPlaced” या “PaymentFailed”)। Kafka उपयोगकर्ता अक्सर “message” कहते हैं, लेकिन “event” इस बात पर ज़ोर देता है कि यह वास्तविक-विश्व परिवर्तन का प्रतिनिधित्व करता है।
- स्ट्रीम: समय के साथ घटनाओं का लगातार बहाव।
- लॉग: Kafka घटनाओं को append-only लॉग के रूप में व्यवस्थित करता है—नयी घटनाएँ अंत में जोड़ी जाती हैं, और रीडर्स अपनी गति से आगे बढ़ते हैं।
यह गाइड किसके लिए है (और आप क्या सीखेंगे)
यह गाइड प्रोडक्ट-मनिड इंजीनियर्स, डेटा लोगों, और तकनीकी नेताओं के लिए है जो Kafka का एक व्यावहारिक मानसिक मॉडल चाहते हैं।
आपको मूल बिल्डिंग ब्लॉक्स (प्रोड्यूसर, कंज्यूमर, टॉपिक्स, ब्रोकर्स), कैसे Kafka पार्टिशन्स के साथ स्केल करता है, यह कैसे घटनाओं को स्टोर और रीप्ले करता है, और इवेंट-ड्रिवन आर्किटेक्चर में इसकी जगह मिलेगी। हम सामान्य उपयोग मामलों, डिलीवरी गारंटी, सुरक्षा की मूल बातें, संचालन योजना, और कब Kafka सही (या गलत) विकल्प है—इनपर भी चर्चा करेंगे।
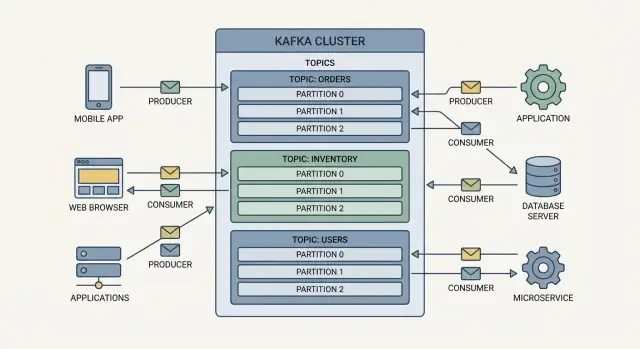
कोर कॉन्सेप्ट्स: प्रोड्यूसर, कंज्यूमर, टॉपिक्स, ब्रोकर्स
Kafka को समझना सबसे आसान है एक साझा इवेंट लॉग के रूप में: एप्लिकेशन इसमें इवेंट्स लिखते हैं, और अन्य एप्लिकेशन बाद में उन इवेंट्स को पढ़ते हैं—अक्सर रियल-टाइम में, कभी-कभी घंटे या दिन बाद भी।
प्रोड्यूसर और कंज्यूमर
प्रोड्यूसर वे लेखक होते हैं। एक प्रोड्यूसर ऐसा इवेंट प्रकाशित कर सकता है जैसे “order placed,” “payment confirmed,” या “temperature reading.” प्रोड्यूसर इवेंट्स को सीधे किसी विशिष्ट ऐप में भेजते नहीं—वे उन्हें Kafka में भेजते हैं।
कंज्यूमर वे पठन करने वाले होते हैं। एक कंज्यूमर एक डैशबोर्ड को पावर दे सकता है, शिपमेंट वर्कफ़्लो ट्रिगर कर सकता है, या एनालिटिक्स में डेटा लोड कर सकता है। कंज्यूमर तय करते हैं कि इवेंट्स के साथ क्या करना है, और वे अपनी गति से पढ़ सकते हैं।
टॉपिक्स: घटनाओं का संगठन
Kafka में घटनाएँ टॉपिक्स में समूहीकृत होती हैं, जो मूलतः नामित श्रेणियाँ हैं। उदाहरण के लिए:
orders ऑर्डर-संबंधी घटनाओं के लिएpayments भुगतान घटनाओं के लिएinventory स्टॉक परिवर्तनों के लिए
एक टॉपिक उस प्रकार की घटना के लिए “स्रोत-सत्य” स्ट्रीम बन जाता है, जो कई टीमों के लिए एक ही डेटा को बिना अलग-थलग एक-ऑफ इंटीग्रेशन बनाए पुन: उपयोग करना आसान बनाता है।
ब्रोकर्स और क्लस्टर
एक ब्रॉकर एक Kafka सर्वर है जो घटनाओं को स्टोर करता है और उन्हें कंज्यूमरों को परोसता है। व्यवहार में, Kafka एक क्लस्टर (कई ब्रोकर्स एक साथ काम करते हैं) के रूप में चलता है ताकि यह अधिक ट्रैफ़िक संभाल सके और एक मशीन फेल होने पर भी चल रहा रहे।
कंज्यूमर ग्रुप: बिना डुप्लिकेट काम के रीडर्स को स्केल करना
कंज्यूमर अक्सर एक कंज्यूमर ग्रुप में चलते हैं। Kafka समूह के बीच पढ़ने का काम फैलाता है, ताकि आप प्रोसेसिंग को स्केल करने के लिए और कंज्यूमर इंस्टेंसेस जोड़ सकें—बिना हर इंस्टेंस को वही काम करने दिए।
कैसे टॉपिक्स और पार्टिशन्स Kafka को स्केल बनाते हैं
Kafka स्केल करता है यह काम को टॉपिक्स (संबंधित घटनाओं की स्ट्रीम) में विभाजित करके और फिर प्रत्येक टॉपिक को पार्टिशन्स (उस स्ट्रीम के छोटे, स्वतंत्र हिस्से) में बाँटकर।
पार्टिशन्स = समानांतरता और थ्रूपुट
एक एक पार्टिशन वाला टॉपिक एक समय में एक ही कंज्यूमर द्वारा ही पढ़ा जा सकता है (एक कंज्यूमर ग्रुप के भीतर)। और पार्टिशन्स बढ़ाने पर आप घटनाओं को समानांतर में प्रोसेस करने के लिए और कंज्यूमर जोड़ सकते हैं। यही तरीका है जिससे Kafka उच्च-वॉल्यूम इवेंट स्ट्रीमिंग और रियल-टाइम डेटा पाइपलाइन्स का समर्थन करता है बिना हर सिस्टम को बोतल-गर्दन बनाए।
पार्टिशन्स ब्रोकर्स के बीच लोड फैलाने में भी मदद करते हैं। एक मशीन के बजाय कई ब्रोकर्स अलग-अलग पार्टिशन्स होस्ट कर सकते हैं और ट्रैफ़िक साझा कर सकते हैं।
ऑर्डरिंग: Kafka क्या गारंटी देता है (और क्या नहीं)
Kafka एक ही पार्टिशन के भीतर ऑर्डरिंग की गारंटी देता है। यदि घटनाएँ A, B, और C उसी पार्टिशन में उसी क्रम में लिखी गईं हैं, तो कंज्यूमर उन्हें A → B → C पढ़ेंगे।
पार्टिशन्स के पार ऑर्डरिंग गारंटीकृत नहीं है। यदि आपको किसी विशिष्ट एंटिटी (जैसे कस्टमर या ऑर्डर) के लिए कड़ा ऑर्डर चाहिए, तो आमतौर पर आप सुनिश्चित करते हैं कि उस एंटिटी के सभी इवेंट्स एक ही पार्टिशन में जाएं।
कीज़ तय करते हैं कि घटनाएँ कहाँ जाती हैं
जब प्रोड्यूसर एक इवेंट भेजते हैं, तो वे एक key (उदाहरण के लिए order_id) शामिल कर सकते हैं। Kafka उस key का उपयोग संबंधित इवेंट्स को हमेशा एक ही पार्टिशन पर रूट करने के लिए करता है। इससे उस key के लिए प्रत्याशित ऑर्डरिंग मिलती है जबकि कुल टॉपिक कई पार्टिशन्स पर स्केल कर सकता है।
रेप्लिकास डेटा उपलब्ध रखने में मदद करते हैं
प्रत्येक पार्टिशन को अन्य ब्रोकर्स पर रेप्लिकेट किया जा सकता है। यदि एक ब्रॉकर फेल हो जाता है, तो किसी अन्य ब्रॉकर पर मौजूद रेप्लिका takeover कर सकता है। रेप्लिकेशन Kafka को मिशन-क्रिटिकल pub-sub messaging और इवेंट-ड्रिवन सिस्टम्स के लिए भरोसेमंद बनाता है: यह उपलब्धता में सुधार करता है और फॉल्ट टॉलरेंस देता है बिना हर एप्लिकेशन को अपना फेलओवर लॉजिक बनाने के।
स्टोरेज, रिटेंशन, और इवेंट्स को रीप्ले करना
Apache Kafka का एक महत्वपूर्ण विचार यह है कि इवेंट्स केवल पारित नहीं होते—उन्हें डिस्क पर एक क्रमबद्ध लॉग में लिखा जाता है, इसलिए कंज्यूमर उन्हें अब पढ़ सकते हैं—या बाद में। इससे Kafka केवल डेटा मूव करने के लिए ही नहीं, बल्कि जो हुआ उसका टिकाऊ इतिहास रखने के लिए भी उपयोगी बनता है।
इवेंट्स अस्थायी नहीं, बल्कि स्थायी होते हैं
जब एक प्रोड्यूसर किसी टॉपिक पर इवेंट भेजता है, Kafka उसे ब्रॉकर पर स्टोरेज में जोड़ देता है। कंज्यूमर फिर उस स्टोर्ड लॉग से अपनी गति से पढ़ते हैं। यदि कोई कंज्यूमर एक घंटा डाउन रहा, तो घटनाएँ अभी भी मौजूद रहेंगी और वह ठीक होने पर पकड़ सकता है।
रिटेंशन: Kafka डेटा कितनी देर रखता है
Kafka टॉपिक्स के लिए रिटेंशन नीतियों के अनुसार घटनाएँ रखता है:
- समय-आधारित रिटेंशन: घटनाओं को एक सेट अवधि (उदाहरण के लिए 7 दिन) के लिए रखें।
- आकार-आधारित रिटेंशन: लॉग तब तक रखें जब तक वह एक कॉन्फ़िगर की गई साइज तक नहीं पहुँचता, फिर सबसे पुराने डेटा को हटा दें।
रिटेंशन टॉपिक-वार कॉन्फ़िगर की जाती है, जिससे आप “ऑडिट ट्रेल” टॉपिक्स को उच्च-वॉल्यूम telemetry टॉपिक्स से अलग रख सकते हैं।
कम्पैक्शन: प्रति-की सबसे हाल का मान रखना
कुछ टॉपिक्स ऐतिहासिक अभिलेख की तरह नहीं, बल्कि चेंजलॉग की तरह होते हैं—उदाहरण के लिए “कस्टमर की करेंट सेटिंग्स।” लॉग कम्पैक्शन प्रत्येक key के लिए कम-से-कम सबसे हाल का इवेंट रखता है, जबकि पुराने ओवरराइट किए गए रिकॉर्ड हटाए जा सकते हैं। आप फिर भी नवीनतम स्थिति के लिए टिकाऊ स्रोत पाते हैं, बिना अनबाउंड वृद्धि के।
इवेंट्स को रीप्ले करना: स्टेट पुनर्निर्माण और बग से रिकवरी
क्योंकि इवेंट्स स्टोर रहते हैं, आप उन्हें रीप्ले कर सकते हैं ताकि स्टेट को पुनर्निर्मित किया जा सके:
- किसी सर्च इंडेक्स या मटेरियलाइज्ड व्यू को स्क्रैच से बनाना
- एक खराब डिप्लॉयमेंट के बाद सेवा को रिकवर करने के लिए पहले के पॉइंट से पुनःप्रोसेस करना
- एक नए कंज्यूमर को ऑनबोर्ड करना और इसे ऐतिहासिक डेटा पढ़ने देना
व्यवहार में, रीप्ले इस बात से नियंत्रित होता है कि कंज्यूमर “कहाँ से पढ़ना शुरू करता है” (उसका ऑफसेट), जो टीम्स को सिस्टम्स के विकसित होने पर एक शक्तिशाली सेफ़्टी नेट देता है।
भरोसेमंदता और फॉल्ट टॉलरेंस की बुनियादी बातें
Kafka इस तरह बनाया गया है कि सिस्टम के कुछ हिस्से फेल होने पर भी डेटा प्रवाह बना रहे। यह रेप्लिकेशन, प्रत्येक पार्टिशन के लिए स्पष्ट नियमों के साथ कि कौन “लीडर” है, और कॉन्फ़िगर करने योग्य write acknowledgments से यह करता है।
रेप्लिकेशन: लीडर और फॉलोअर्स (ऊपर स्तर)
प्रत्येक टॉपिक पार्टिशन का एक लीडर ब्रॉकर और एक या अधिक फॉलोअर रेप्लिकास अन्य ब्रोकर्स पर होता है। प्रोड्यूसर और कंज्यूमर उस पार्टिशन के लीडर से बात करते हैं।
फॉलोअर्स लगातार लीडर के डेटा की नकल करते हैं। यदि लीडर डाउन हो जाता है, Kafka एक अप-टू-डेट फॉलोअर को नया लीडर बना सकता है, ताकि पार्टिशन उपलब्ध बना रहे।
ब्रॉकर फेल होने पर क्या होता है (संक्षेप में)
यदि एक ब्रॉकर फेल हो जाता है, तो जिन पार्टिशन्स का वह लीडर था वे थोड़े समय के लिए अनुपलब्ध हो सकते हैं। Kafka का कंट्रोलर (आंतरिक समन्वय) विफलता का पता लगाता है और उन पार्टिशन्स के लिए लीडर चुनाव ट्रिगर करता है।
यदि कम-से-कम एक फॉलोअर रेप्लिका पर्याप्त रूप से caught up है, तो वह लीडर बनकर क्लाइंट्स को फिर से प्रोड्यूस/कंज्यूम करने दे सकती है। यदि कोई इन-सिंक रेप्लिका उपलब्ध नहीं है, तो Kafka लिखावटों को रोक भी सकता है (आपकी सेटिंग्स पर निर्भर करते हुए) ताकि सत्यापित किए गए डेटा को खोने से बचा जा सके।
टिकाऊपन: acknowledgments और replication factor
दो मुख्य नॉब्स टिकाऊपन को आकार देते हैं:
- Replication factor: प्रत्येक पार्टिशन की कितनी प्रतियां हैं (उदाहरण के लिए, 3 प्रतियाँ तीन ब्रोकर्स पर)।
- Acknowledgments (acks): प्रोड्यूसर किस स्थिति में एक write को सफल मानता है।
सैद्धांतिक रूप से:
- acks=0: प्रोड्यूसर इंतज़ार नहीं करता—तेज़, लेकिन आप संदेश खो सकते हैं।
- acks=1: लीडर write की पुष्टि करता है—बेहतर, पर यदि लीडर फ़ॉलोअर्स को डेटा कॉपी करने से पहले फेल हो जाए तो हाल की लिखी गई संदेशें खो सकती हैं।
- acks=all (या -1): लीडर उन रेप्लिकाओं का इंतज़ार करता है जो “इन-सिंक” हैं—यह ज़्यादा सुरक्षित है, आमतौर पर थोड़ा धीमा होता है।
रिट्राई के दौरान डुप्लिकेट्स को कम करने के लिए, टीमें अक्सर सुरक्षित acks के साथ idempotent प्रोड्यूसर्स और ठोस कंज्यूमर हैंडलिंग का संयोजन करती हैं (बाद में कवर किया गया)।
लेटेंसी बनाम सुरक्षा का ट्रेड-ऑफ
ऊँची सुरक्षा आमतौर पर अधिक पुष्टियों का इंतज़ार करने और अधिक रेप्लिकाओं को सिंक में रखने का मतलब है, जो लेटेंसी बढ़ा सकता है और पीक थ्रूपुट घटा सकता है।
कम लेटेंसी सेटिंग्स उन मामलों के लिए ठीक हो सकती हैं जहाँ कभी-कभार नुकसान स्वीकार्य है (जैसे telemetry या clickstream), लेकिन भुगतान, इन्वेंटरी, और ऑडिट लॉग आमतौर पर अतिरिक्त सुरक्षा को न्यायसंगत ठहराते हैं।
इवेंट-ड्रिवन आर्किटेक्चर में Kafka की भूमिका
प्रोड्यूसर और कंज्यूमर का स्कैफ़ोल्ड बनाएं
Koder.ai से अपने Kafka टॉपिक्स के आसपास सर्विस का स्कैफ़ोल्ड बनवाएँ, फिर डिटेल्स पर इटरेट करें।
इवेंट-ड्रिवन आर्किटेक्चर (EDA) एक प्रणाली बनाने का तरीका है जहाँ बिज़नेस में जो कुछ होता है—एक ऑर्डर रखा गया, भुगतान की पुष्टि, एक पैकेज भेजा गया—उन्हें ऐसे इवेंट्स के रूप में प्रस्तुत किया जाता है जिन पर सिस्टम के अन्य हिस्से प्रतिक्रिया कर सकते हैं।
इवेंट प्रकाशित करें, कंज्यूमर से प्रतिक्रिया लें
Kafka अक्सर EDA के केंद्र में एक साझा “इवेंट स्ट्रीम” के रूप में बैठता है। सेवा A सीधे सेवा B को कॉल करने की बजाय एक इवेंट (उदाहरण के लिए OrderCreated) एक Kafka टॉपिक पर प्रकाशित करती है। कोई भी संख्या में अन्य सेवाएँ उस इवेंट को कंज्यूम कर सकती हैं और कार्रवाई कर सकती हैं—ईमेल भेजना, इन्वेंटरी रिज़र्व करना, फ्रॉड चेक शुरू करना—बिना सेवा A को यह जानने की ज़रूरत कि वे मौजूद हैं।
लूज़ कपलिंग (कम डायरेक्ट डिपेंडेंसी)
क्योंकि सेवाएँ इवेंट्स के जरिए संवाद करती हैं, उन्हें प्रत्येक इंटरैक्शन के लिए request/response APIs का समन्वय नहीं करना पड़ता। इससे टीमों के बीच कड़ी निर्भरता कम होती है और नई विशेषताओं को जोड़ना आसान होता है: आप किसी मौजूदा इवेंट के लिए एक नया कंज्यूमर जोड़कर नई क्षमता ला सकते हैं बिना प्रोड्यूसर को बदलने के।
असिंक्रोनस वर्कफ़्लो और स्पाइक रेसिस्टेंस
EDA स्वाभाविक रूप से असिंक्रोनस है: प्रोड्यूसर तेज़ी से इवेंट्स लिखते हैं, और कंज्यूमर उन्हें अपनी गति से प्रोसेस करते हैं। ट्रैफ़िक स्पाइक्स के दौरान, Kafka उस सर्ज को बफ़र करने में मदद करता है ताकि डाउनस्ट्रीम सिस्टम तुरंत क्रैश न करें। कंज्यूमर स्केल आउट कर के पकड़ सकते हैं, और यदि कोई कंज्यूमर अस्थायी रूप से डाउन हो जाता है तो वह वहीं से फिर से शुरू कर सकता है जहाँ उसने छोड़ा था।
व्यावहारिक मानसिक मॉडल
Kafka को सिस्टम के “एक्टिविटी फीड” की तरह सोचें। प्रोड्यूसर तथ्य प्रकाशित करते हैं; कंज्यूमर उन तथ्यों को सब्स्क्राइब करते हैं जिनमें वे दिलचस्पी रखते हैं। यह पैटर्न रियल-टाइम डेटा पाइपलाइन्स और इवेंट-ड्रिवन वर्कफ़्लोज़ को सक्षम बनाता है जबकि सेवाओं को साधारण और स्वतंत्र रखता है।
आधुनिक प्रणालियों में सामान्य Kafka उपयोग मामले
Kafka अक्सर उन्हीं जगहों पर दिखाई देता है जहाँ टीमों को कई छोटे “घटे हुए तथ्यों” (इवेंट्स) को सिस्टमों के बीच तेज़ी से, विश्वसनीय रूप से और इस तरह से स्थानांतरित करने की आवश्यकता होती है कि कई कंज्यूमर एक ही डेटा को पुन: उपयोग कर सकें।
गतिविधि ट्रैकिंग और ऑडिट लॉग
एप्लिकेशन अक्सर एक append-only इतिहास की ज़रूरत होती है: यूज़र साइन-इन्स, परमिशन परिवर्तन, रिकॉर्ड अपडेट्स, या एडमिन एक्शन्स। Kafka इन घटनाओं का एक केंद्रीय स्ट्रीम बनाकर अच्छा काम करता है, इसलिए सुरक्षा टूल्स, रिपोर्टिंग, और अनुपालन एक्सपोर्ट्स सभी एक ही स्रोत पढ़ सकते हैं बिना प्रोडक्शन डेटाबेस पर लोड बढ़ाए। क्योंकि घटनाएँ एक अवधि के लिए रिटेन होती हैं, आप बग या स्कीमा परिवर्तन के बाद एक ऑडिट व्यू को रीबिल्ड करने के लिए उन्हें रीप्ले भी कर सकते हैं।
माइक्रोसर्विसेस संचार इवेंट्स के जरिए
सेवाएँ सीधे एक-दूसरे को कॉल करने की बजाय “order created” या “payment received” जैसी घटनाएँ प्रकाशित कर सकती हैं। अन्य सेवाएँ उन घटनाओं को सब्स्क्राइब कर के अपने समय पर प्रतिक्रिया देती हैं। इससे टाइट कपलिंग घटती है, आंशिक आउटेज के दौरान सिस्टम काम करते रहते हैं, और नए फीचर्स जोड़ना आसान होता है (उदाहरण के लिए, फ्रॉड चेक) बस मौजूदा इवेंट स्ट्रीम को कंज्यूम करके।
एनालिटिक्स और वेयरहाउस के लिए डेटा पाइपलाइन्स
Kafka अक्सर ऑपरेशनल सिस्टम्स से एनालिटिक्स प्लेटफॉर्मों तक डेटा ले जाने के लिए रीढ़ के रूप में उपयोग किया जाता है। टीमें एप्लिकेशन डेटाबेस से परिवर्तन स्ट्रीम कर सकती हैं और कम विलंबता के साथ उन्हें वेयरहाउस या लेक में पहुंचा सकती हैं, जबकि प्रोडक्शन ऐप को भारी एनालिटिकल क्वेरीज़ से अलग रखते हैं।
IoT और बर्स्टी ट्रैफ़िक वाला टेलीमेट्री
सेंसर, डिवाइसेस, और ऐप टेलीमेट्री अक्सर स्पाइक्स में आती हैं। Kafka इन बर्स्ट्स को स्वीकार कर सकता है, सुरक्षित रूप से बफ़र कर सकता है, और डाउनस्ट्रीम प्रोसेसिंग को पकड़ने दे सकता है—जो मॉनिटरिंग, अलर्टिंग, और दीर्घकालिक विश्लेषण के लिए उपयोगी है।
Kafka इकोसिस्टम: Connect, Streams, और टूलिंग
Kafka केवल ब्रोकर्स और टॉपिक्स से अधिक है। अधिकांश टीमें ऐसे साथी उपकरणों पर भरोसा करती हैं जो रोज़मर्रा के डेटा मूवमेंट, स्ट्रीम प्रोसेसिंग, और ऑपरेशंस को व्यावहारिक बनाते हैं।
Kafka Connect: बिना कस्टम कोड के डेटा मूव करना
Kafka Connect Kafka का इंटीग्रेशन फ्रेमवर्क है जो डेटा Kafka में (सोर्स) और Kafka से बाहर (सिंक) ले जाने के लिए कनेक्टर्स का उपयोग करता है। कस्टम पाइपलाइन्स बनाने और मेंटेन करने के बजाय आप Connect चलाते हैं और कनेक्टर्स को कॉन्फ़िगर करते हैं।
सामान्य उदाहरणों में डेटाबेस से बदलाव खींचना, SaaS इवेंट्स इनजेस्ट करना, या Kafka डेटा को डेटा वेयरहाउस या ऑब्जेक्ट स्टोरेज में डिलीवर करना शामिल है। Connect retries, offsets, और parallelism जैसे ऑपरेशनल विचारों को भी स्टैंडर्डाइज़ करता है।
Kafka Streams: आपकी एप्स के अंदर रियल-टाइम प्रोसेसिंग
यदि Connect इंटीग्रेशन के लिए है, तो Kafka Streams गणना के लिए है। यह एक लाइब्रेरी है जिसे आप अपनी एप्लिकेशन में जोड़ते हैं ताकि स्ट्रीम्स को रियल-टाइम में ट्रांसफ़ॉर्म किया जा सके—इवेंट्स को फ़िल्टर करना, एनरिच करना, स्ट्रीम्स को जॉइन करना, और एग्रीगेट्स बनाना (जैसे “orders per minute”)।
क्योंकि Streams ऐप्स टॉपिक्स से पढ़ते हैं और टॉपिक्स में लिखते हैं, वे इवेंट-ड्रिवन सिस्टम्स में स्वाभाविक रूप से फिट होते हैं और अधिक इंस्टेंसेस जोड़कर स्केल कर सकते हैं।
स्कीमा प्रबंधन: इवेंट्स को सुसंगत रखना
जैसे-जैसे कई टीमें इवेंट्स प्रकाशित करती हैं, सुसंगतता महत्वपूर्ण हो जाती है। स्कीमा प्रबंधन (अक्सर स्कीमा रजिस्ट्री के माध्यम से) यह परिभाषित करता है कि किसी इवेंट में क्या फील्ड होने चाहिए और वे समय के साथ कैसे विकसित होंगे। इससे ब्रेकेज़ जैसे प्रोड्यूसर द्वारा फील्ड का नाम बदलना जिसे कंज्यूमर पर निर्भर है, रोका जा सकता है।
टूलिंग: जिन चीज़ों की निगरानी ज़रूरी है
Kafka ऑपरेशनल रूप से संवेदनशील है, इसलिए बेसिक मॉनिटरिंग आवश्यक है:
- कंज्यूमर लैग: क्या कंज्यूमर पीछे पड़ रहे हैं?
- थ्रूपुट: कितने इवेंट्स प्रति सेकंड फ्लो कर रहे हैं?
- एरर्स: failed fetches, produce errors, connector task failures
अधिकांश टीमें प्रबंधन UIs और डिप्लॉयमेंट, टॉपिक कॉन्फ़िगरेशन, और एक्सेस कंट्रोल नीतियों के लिए ऑटोमेशन भी उपयोग करती हैं (देखें /blog/kafka-security-governance)।
डिलीवरी गारंटी और प्रोसेसिंग पैटर्न
तेज़ी से Kafka डेमो बनाएं
एक चैट‑ड्रिवन बिल्ड में अपने Kafka के मानसिक मॉडल को काम करने वाले प्रोड्यूसर और कंज्यूमर ऐप में बदलें।
Kafka को अक्सर “ड्यूरेबल लॉग + कंज्यूमर” के रूप में वर्णित किया जाता है, लेकिन ज्यादातर टीमें वास्तव में यह जानना चाहती हैं: क्या मैं हर इवेंट को एक बार प्रोसेस करूँगा, और कुछ फेल होने पर क्या होगा? Kafka आपको निर्माण ब्लॉक्स देता है, और आप ट्रेड-ऑफ़ चुनते हैं।
डिलीवरी गारंटीज (ऊपर स्तर)
At-most-once का मतलब है कि आप इवेंट्स खो सकते हैं, लेकिन डुप्लिकेट्स नहीं होंगे। यह तब हो सकता है जब कंज्यूमर अपनी पोजिशन पहले कमिट कर दे और फिर काम खत्म करने से पहले क्रैश कर जाए।
At-least-once का मतलब है कि आप इवेंट्स खोएँगे नहीं, पर डुप्लिकेट्स संभव हैं (उदाहरण के लिए, कंज्यूमर एक इवेंट प्रोसेस करता है, क्रैश हो जाता है, और फिर रिस्टार्ट पर उसे फिर से प्रोसेस कर देता है)। यह सबसे आम डिफ़ॉल्ट है।
Exactly-once दोनों नुकसान और डुप्लिकेट्स से बचने का लक्ष्य रखता है end-to-end। Kafka में, यह आमतौर पर transactional प्रोड्यूसर्स और अनुकूल प्रोसेसिंग (अक्सर Kafka Streams के माध्यम से) की आवश्यकता रखता है। यह शक्तिशाली है, लेकिन अधिक सीमित है और सावधानीपूर्वक सेटअप की मांग करता है।
आइडेम्पोटेंसी और डेडुप्लीकेशन
व्यवहार में, कई सिस्टम at-least-once को अपनाते हैं और सुरक्षा की परतें जोड़ते हैं:
- Idempotent writes: “इवेंट लागू करें” चरण को दोहराने के लिए सुरक्षित बनाएं (जैसे upserts, conditional updates, unique keys)।
- Deduplication: एक इवेंट id (या बिज़नेस की) स्टोर करें और विंडो के भीतर रिपीट्स को अनदेखा करें।
कंज्यूमर ऑफसेट्स: आपका "बुकमार्क"
एक कंज्यूमर ऑफसेट किसी पार्टिशन में आख़िरी प्रोसेस किए गए रिकॉर्ड की स्थिति है। जब आप ऑफसेट्स कमिट करते हैं, तो आप कह रहे होते हैं, “मैं यहाँ तक कर चुका हूँ।” बहुत जल्दी कमिट करें और आप क्रैश पर काम खो देंगे; बहुत देर से कमिट करें और आप फेलियर के बाद डुप्लिकेट्स बढ़ाएंगे।
रिट्राईज़ और पॉयजन संदेश
रिट्राईज़ को सीमित और दिखाई देने योग्य होना चाहिए। एक सामान्य पैटर्न है:
- ट्रांज़िएंट एरर्स के लिए बैकऑफ़ के साथ रिट्राई करें,
- फिर विफल रिकॉर्ड को निरीक्षण और रीप्ले के लिए एक dead-letter topic में भेज दें।
यह एक “poison message” को पूरे कंज्यूमर ग्रुप को ब्लॉक करने से रोकता है और साथ ही बाद में फिक्स के लिए डेटा को संरक्षित करता है।
सुरक्षा और गवर्नेंस पर विचार
Kafka अक्सर व्यवसाय-सम्बंधी महत्वपूर्ण घटनाएँ (ऑर्डर, पेमेंट, उपयोगकर्ता गतिविधि) ढोता है। इसलिए सुरक्षा और गवर्नेंस डिज़ाइन का हिस्सा होना चाहिए, न कि बाद की सोचा-समझ।
प्रमाणीकरण और अधिकरण
प्रमाणीकरण पूछता है "आप कौन हैं?" और अधिकरण पूछता है "आप क्या कर सकते हैं?" Kafka में प्रमाणीकरण आमतौर पर SASL (जैसे SCRAM या Kerberos) के साथ किया जाता है, जबकि अधिकरण को ACLs (एक्सेस कंट्रोल लिस्ट्स) के साथ टॉपिक, कंज्यूमर ग्रुप, और क्लस्टर स्तर पर लागू किया जाता है।
एक व्यावहारिक पैटर्न least privilege है: प्रोड्यूसर्स केवल उन्हीं टॉपिक्स पर लिख सकें जो वे ओन करते हैं, और कंज्यूमर केवल उन्हीं टॉपिक्स को पढ़ सकें जिनकी उन्हें ज़रूरत है। इससे आकस्मिक डेटा एक्सपोज़र घटता है और यदि क्रेडेंशियल्स लीक हो जाएँ तो blast radius सीमित रहता है।
ट्रांज़िट में एन्क्रिप्शन (TLS)
TLS एप्लिकेशन, ब्रोकर्स, और टूलिंग के बीच डेटा के संचरण को एन्क्रिप्ट करता है। इसके बिना, आंतरिक नेटवर्क पर भी इवेंट्स इंटरसेप्ट किए जा सकते हैं, न कि सिर्फ़ सार्वजनिक इंटरनेट पर। TLS ब्रॉकर की पहचान मान्य करके “मैन-इन-द-मिडिल” हमलों को भी रोकने में मदद करता है।
मल्टी-टेनेंट Kafka और नामकरण कन्वेंशंस
जब कई टीमें एक क्लस्टर साझा करती हैं, तो गार्डरैइल्स आवश्यक होते हैं। स्पष्ट टॉपिक नामकरण कन्वेंशंस (उदाहरण: \u003cteam\u003e.\u003cdomain\u003e.\u003cevent\u003e.\u003cversion\u003e) मालिकाना दिखाने में मदद करते हैं और टूलिंग को नीतियाँ लागू करने में आसान बनाते हैं।
नामकरण को कोटा और ACL टेम्पलेट्स के साथ जोड़ों ताकि एक शोर करने वाला वर्कलोड दूसरों का गला न घोंटे, और नए सर्विसेस सुरक्षित डिफ़ॉल्ट्स के साथ शुरू हों।
डेटा गवर्नेंस: PII, रिटेंशन, और संरेखण
Kafka को केवल तभी रिकॉर्ड सिस्टम मानें जब आप इवेंट इतिहास के लिए ऐसा इरादा रखते हों। यदि इवेंट्स में PII है, तो डेटा को न्यूनतम रखें (पूर्ण प्रोफाइल के बजाय IDs भेजें), फ़ील्ड-लेवल एन्क्रिप्शन पर विचार करें, और दस्तावेज़ बनाएं कि कौन से टॉपिक्स संवेदनशील हैं।
रिटेंशन सेटिंग्स को कानूनी और व्यवसायिक आवश्यकताओं से मेल खाना चाहिए। यदि नीति कहती है “30 दिनों के बाद हटाएँ,” तो 6 महीने का डेटा “बस सोचिए” के लिए न रखें। नियमित समीक्षा और ऑडिट्स कॉन्फ़िगरेशनों को सिस्टम्स के विकसित होने के साथ संरेखित रखते हैं।
Kafka को ऑपरेट करना: टीमों को किसकी योजना बनानी चाहिए
एक EDA सर्विस का प्रोटोटाइप तैयार करें
Koder.ai में React UI, Go.backend और PostgreSQL के साथ एक इवेंट‑ड्रिवन सर्विस का प्रोटोटाइप तैयार करें।
Apache Kafka को चलाना केवल "इंस्टॉल और भूल जाओ" नहीं है। यह एक साझा यूटिलिटी की तरह व्यवहार करता है: कई टीमें इस पर निर्भर होती हैं, और छोटी गलतियाँ डाउनस्ट्रीम ऐप्स तक फैल सकती हैं।
क्षमता योजना की बुनियादी बातें
Kafka क्षमता ज्यादातर एक गणित की समस्या है जिसे आप नियमित रूप से फिर से देखते हैं। सबसे बड़े लीवर हैं पार्टिशन्स (समानांतरता), थ्रूपुट (MB/s इन और आउट), और स्टोरेज वृद्धि (आप कितनी देर तक डेटा रखें)।
यदि ट्रैफ़िक दोगुना हो जाता है, तो आपको लोड फैलाने के लिए अधिक पार्टिशन्स, रिटेंशन रखने के लिए अधिक डिस्क, और रेप्लिकेशन के लिए नेटवर्क headroom की आवश्यकता पड़ सकती है। एक व्यावहारिक आदत है पीक write rate का अनुमान लगाना और रिटेंशन से गुणा कर के डिस्क वृद्धि का अनुमान लगाना, फिर रेप्लिकेशन और "अनपेक्षित सफलता" के लिए बफ़र जोड़ना।
रोज़मर्रा के ऑपरेशनल कार्य
सर्वरों को चालू रखने से परे नियमित काम की उम्मीद करें:
- अपग्रेड्स: रोलिंग अपग्रेड्स की योजना बनाएं, क्लाइंट कम्पैटिबिलिटी टेस्ट करें, और बदलाव तभी शेड्यूल करें जब ट्रैफ़िक कम हो।
- रीबैलेंसिंग: कंज्यूमर ग्रुप रीबैलेंस कुछ क्षणों के लिए पाज़ करवा सकता है; सुरक्षित डिप्लॉयमेंट पैटर्न और स्पष्ट ओनरशिप रखें।
- इनसिडेंट रिस्पॉन्स: ब्रॉकर फेल्योर, डिस्क-फुल घटनाएँ, और गलत कॉन्फ़िगर किए गए प्रोड्यूसर्स जो किसी टॉपिक को फ्लड कर रहे हों—इनके लिए प्लेबुक्स रखें।
लागत ड्राइवर और डिप्लॉयमेंट विकल्प
लागतें मुख्यतः डिस्क, नेटवर्क एग्रस्स, और ब्रोकर्स की संख्या/आकार से आती हैं। मैनेज्ड Kafka स्टाफिंग ओवरहेड कम कर सकता है और अपग्रेड्स को सरल बना سکتا है, जबकि स्वयं होस्ट करना स्केल पर सस्ता हो सकता है यदि आपके पास अनुभवी ऑपरेटर हैं। व्यापार-बंदा अंतर है रिकवरी का समय और ऑन-कॉल बोझ।
किन चीज़ों को मापें (ताकि आप अनुमान न लगाएँ)
टीमें आमतौर पर निगरानी करती हैं:
- एंड-टू-एंड लेटेंसी (produce से consume तक)
- कंज्यूमर लैग (कितना पीछे हैं कंज्यूमर)
- ब्रॉकर हेल्थ (डिस्क उपयोग, under-replicated partitions, request error rates)
अच्छे डैशबोर्ड और अलर्ट Kafka को एक “रहस्यमय बॉक्स” से एक समझने योग्य सेवा में बदल देते हैं।
कब Kafka उपयोग करें (और कब नहीं)
Kafka एक मजबूत विकल्प है जब आपको बहुत सारे इवेंट्स को विश्वसनीय रूप से मूव करने, उन्हें कुछ समय के लिए रखने, और कई सिस्टमों को उस डेटा स्ट्रीम पर अपनी गति से प्रतिक्रिया देने की आवश्यकता हो। यह विशेष रूप से उपयोगी है जब डेटा को रीप्ले करने की जरुरत हो (बैकफिल, ऑडिट, या नई सर्विस निर्माण के लिए) और जब आप उम्मीद करते हैं कि समय के साथ अधिक प्रोड्यूसर/कंज्यूमर जुड़ेंगे।
Kafka चुनने के अच्छे समय
Kafka तब चमकता है जब आपके पास हो:
- हाई-थ्रूपुट इवेंट स्ट्रीम्स (क्लिक्स, ऑर्डर्स, सेंसर डेटा)
- कई कंज्यूमर जिन्हें वही इवेंट्स चाहिए (एनालिटिक्स, मॉनिटरिंग, फ्रॉड, नोटिफिकेशन्स)
- रीप्ले और दीर्घकालिक हिस्ट्री की आवश्यकता
- टीमों और सेवाओं को डिकपल करने की ज़रूरत
कब Kafka बहुत भारी पड़ सकता है
यदि आपकी ज़रूरतें सरल हैं तो Kafka ओवरकिल हो सकता है:
- दो सेवाओं के बीच एक सिंगल लो-वॉल्यूम क्यू
- शॉर्ट-लाइव्ड टास्क (बैकग्राउंड जॉब्स) जहाँ रीप्ले का लाभ न के बराबर हो
- ऐसी टीमें जिनके पास वितरित सिस्टम को ऑपरेट और मॉनिटर करने का समय न हो
इन मामलों में, क्लस्टर साइजिंग, अपग्रेड्स, मॉनिटरिंग, ऑन-कॉल—यह ऑपरेशनल ओवरहेड लाभों से अधिक हो सकता है।
विकल्प और पूरक
- RabbitMQ: क्लासिक वर्क क्यूज़ और राउटिंग पैटर्न के लिए बेहतरीन।
- NATS: लो लेटेंसी के साथ हल्का मैसेजिंग।
- क्लाउड pub/sub: जब आप मैनेज्ड इंफ्रास्ट्रक्चर और सरल ऑप्स चाहते हैं तब अच्छा विकल्प।
Kafka डेटाबेस (सिस्टम ऑफ़ रिकॉर्ड), कैशेस (तेज़ रीड्स), और बैच ETL टूल्स (बड़े पीरियॉडिक ट्रांसफ़ॉर्मेशंस) के साथ पूरक है—न कि उनका रिप्लेसमेंट।
त्वरित निर्णय चेकलिस्ट
पूछें:
- क्या हमें कई कंज्यूमर और रीप्ले की ज़रूरत है?
- क्या थ्रूपुट काफी बढ़ने की संभावना है?
- क्या हमें इवेंट इतिहास/रिटेंशन एक फीचर के रूप में चाहिए?
- क्या हम ऑपरेशनल ओनरशिप संभाल सकते हैं (या मैनेज्ड Kafka उपयोग करेंगे)?
- क्या हम इवेंट्स स्ट्रीम कर रहे हैं, केवल कमांड/टास्क नहीं भेज रहे?
यदि आप इन में से ज़्यादातर का उत्तर “हां” देते हैं, तो Kafka आमतौर पर एक समझदारी विकल्प होता है।
शुरूआत: सरल अपनाने का मार्ग
Kafka सबसे अच्छा तब फिट बैठता है जब आपको रियल-टाइम इवेंट स्ट्रीम्स के लिए एक साझा “स्रोत-सत्य” चाहिए: कई सिस्टम तथ्य पैदा करते हैं (ऑर्डर बनाए गए, भुगतान अधिकृत, इन्वेंटरी बदली) और कई सिस्टम उन तथ्यों को पाइपलाइन्स, एनालिटिक्स, और रिएक्टिव फीचर्स को पावर करने के लिए कंज्यूम करते हैं।
चरण 1: एक ठोस उपयोग मामला चुनें
एक संकुचित, उच्च-मूल्य फ्लो से शुरू करें—जैसे "OrderPlaced" इवेंट प्रकाशित करना डाउनस्ट्रीम सेवाओं (ईमेल, फ्रॉड चेक, fulfillment) के लिए। पहले दिन Kafka को catch-all क्यू बनाने से बचें।
चरण 2: अपनी इवेंट्स और टॉपिक्स परिभाषित करें
लिख लें:
- इवेंट्स: सरल बिज़नेस शब्दों में क्या हुआ
- टॉपिक्स: वे इवेंट्स कहाँ रहते हैं (आम तौर पर प्रत्येक इवेंट प्रकार या डोमेन के लिए एक टॉपिक)
- कंज्यूमर: किन टीमों/सेवाओं को इवेंट्स चाहिए, और क्यों
प्रारंभिक स्कीमाओं को सरल और सुसंगत रखें (timestamps, IDs, और स्पष्ट इवेंट नाम)। तय करें कि क्या आप स्कीमा को पहले से लागू करेंगे या समय के साथ सावधानी से विकसित करेंगे।
चरण 3: ओनरशिप और ऑपरेटिंग बेसिक्स स्थापित करें
Kafka तभी सफल होता है जब कोई जिम्मेदार हो:
- टॉपिक निर्माण और नामकरण नीतियाँ
- रिटेंशन और एक्सेस नीतियाँ
- ऑन-कॉल ज़िम्मेदारियाँ और रनबुक्स
तुरंत मॉनिटरिंग जोड़ें (कंज्यूमर लैग, ब्रॉकर हेल्थ, थ्रूपुट, एरर रेट)। यदि आपके पास प्लेटफ़ॉर्म टीम नहीं है, तो मैनेज्ड ऑफ़रिंग से शुरू करें और स्पष्ट सीमाएँ रखें।
चरण 4: "पतला" पहला पाइपलाइन बनाएं
एक सिस्टम से इवेंट्स पैदा करें, उन्हें एक जगह पर कंज्यूम करें, और लूप को end-to-end सबूत करें। तभी और कंज्यूमर, पार्टिशन्स, और इंटीग्रेशन बढ़ाएँ।
यदि आप विचार से काम कर के जल्दी काम करने की ओर बढ़ना चाहते हैं, तो टूल्स जैसे Koder.ai आपको आसपास की एप्लिकेशन तेजी से प्रोटोटाइप करने में मदद कर सकते हैं (React वेब UI, Go बैकएंड, PostgreSQL) और चैट-ड्रिवन वर्कफ़्लो के माध्यम से Kafka प्रोड्यूसर्स/कंज्यूमर्स को क्रमशः जोड़ना आसान बनाते हैं। यह विशेष रूप से उन आंतरिक डैशबोर्ड्स और हल्के सेवाओं के लिए उपयोगी है जो टॉपिक्स को कंज्यूम करती हैं, planning mode, source code export, deployment/hosting, और snapshots के साथ rollback जैसी सुविधाओं के साथ।
यदि आप इसे इवेंट-ड्रिवन दृष्टिकोण में मैप कर रहे हैं, तो देखें /blog/event-driven-architecture। लागत और एन्वायरनमेंट प्लानिंग के लिए देखें /pricing।