10 अग॰ 2025·8 मिनट
LLM कैसे व्यावसायिक नियम और वर्कफ़्लो तर्क को संभालते हैं
जानें कि LLM व्यावसायिक नियमों को कैसे समझते और लागू करते हैं, वर्कफ़्लो स्टेट को कैसे ट्रैक करते हैं, और प्रॉम्प्ट्स, टूल्स, टेस्ट व मानव समीक्षा के जरिए निर्णयों को कैसे सत्यापित किया जाता है—केवल कोड नहीं।
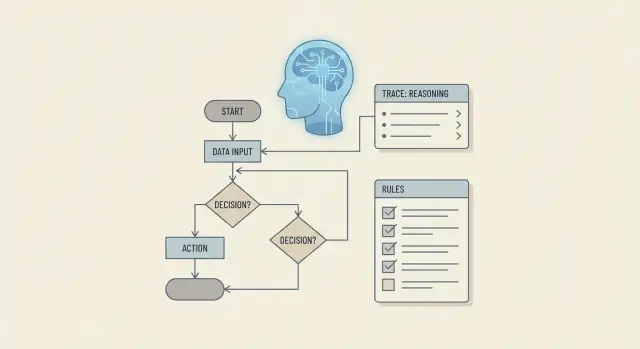
क्यों व्यावसायिक-नियम तर्क केवल कोड जनरेशन से अधिक है
जब लोग पूछते हैं कि क्या एक LLM “व्यावसायिक नियमों के बारे में तर्क कर सकता है”, तो वे आमतौर पर "क्या यह if/else लिख सकता है" से कहीं अधिक मांग रहे होते हैं। व्यावसायिक-नियम तर्क का मतलब है नीतियों को लगातार लागू करना, निर्णयों को समझाना, अपवादों को संभालना, और यह सुनिश्चित करना कि निर्णय वर्तमान वर्कफ़्लो चरण के अनुरूप हों—खासकर जब इनपुट अधूरे, गंदे, या बदल रहे हों।
तर्क बनाम कोड उत्पन्न करना
कोड जनरेशन मुख्य रूप से लक्षित भाषा में वैध सिंटैक्स बनाने के बारे में है। नियम तर्क का मकसद इरादा संरक्षित करना है।
एक मॉडल बिल्कुल वैध कोड उत्पन्न कर सकता है जो फिर भी गलत व्यावसायिक परिणाम देता है क्योंकि:
- नीति पाठ अस्पष्ट है ("हाल का ग्राहक", "उच्च जोखिम", "स्वीकृत दस्तावेज़").
- नियमों में टकराव हैं, और प्राथमिकता स्पष्ट नहीं है।
- एज केस बताए नहीं गए हैं (आंशिक रिफंड, डुप्लिकेट, सप्ताहांत/छुट्टियाँ)।
- वर्कफ़्लो की स्थिति यह बदल देती है कि अगला कदम क्या होना चाहिए (intake बनाम review बनाम final approval)।
दूसरे शब्दों में, सही होने का अर्थ केवल "क्या यह कंपाइल होता है?" नहीं है। यह है "क्या यह हर बार उस निर्णय से मेल खाता है जो व्यवसाय लेगा, और क्या हम इसे प्रमाणित कर सकते हैं?"
LLM से क्या उम्मीद रखें
LLM नीतियों को संरचित नियमों में ट्रांसलेट करने, निर्णय पथ सुझाने, और मनुष्यों के लिए स्पष्टीकरण ड्राफ्ट करने में मदद कर सकते हैं। लेकिन वे स्वचालित रूप से यह नहीं जानते कि कौन-सा नियम प्राधिकृत है, कौन-सा डेटा स्रोत भरोसेमंद है, या मामला किस चरण में है। बिना प्रतिबंधों के, वे भरोसेमंद-लगने वाला एक उपयुक्त उत्तर चुन सकते हैं बजाय कि नियंत्रित उत्तर के।
इसलिए लक्ष्य "मॉडल को निर्णय लेने देना" नहीं है, बल्कि उसे संरचना और जाँच देना है ताकि यह विश्वसनीय रूप से सहायता कर सके।
इस पोस्ट के बाकी हिस्से में क्या होगा
एक व्यावहारिक दृष्टिकोण एक पाइपलाइन जैसा दिखता है:
- नीति पाठ को उपयोगी नियम प्रतिनिधित्वों में बदलें।
- वर्कफ़्लो स्थिति को ट्रैक करें ताकि निर्णय चरणों में सुसंगत रहें।
- प्राथमिकताओं, अपवादों और स्पष्टीकरणों को लागू करने के लिए प्रॉम्प्ट पैटर्न का उपयोग करें।
- अनुमोदित डेटा का उपयोग करके उपकरणों और रिट्रीवल से निर्णयों को ग्राउंड करें।
- अस्पष्टता कम करने के लिए स्कीमाओं के साथ आउटपुट को सीमित करें।
- मान्य करें, परीक्षण करें, और निगरानी करें ताकि रिलीज़ से पहले गलतियाँ पकड़ी जा सकें।
यही फर्क है एक चालाक कोड स्निपेट और एक ऐसे सिस्टम के बीच जो वास्तविक व्यावसायिक निर्णयों का समर्थन कर सके।
व्यावसायिक नियम और वर्कफ़्लो: एक त्वरित, सामान्य-भाषा रिफ्रेशर
"तर्क करने" की क्षमता पर बात करने से पहले यह अलग कर लेना मददगार है कि टीमें अक्सर किन दो चीज़ों को एक साथ मिलाती हैं: व्यावसायिक नियम और वर्कफ़्लो।
व्यावसायिक नियम क्या हैं?
व्यावसायिक नियम वे निर्णय कथन हैं जिन्हें आपकी संस्था लगातार लागू करना चाहती है। वे नीतियों और लॉजिक के रूप में प्रकट होते हैं जैसे:
- पात्रता: कौन किसी लाभ, प्लान, या फीचर के लिए योग्य है?
- प्राइसिंग: कौन-सा डिस्काउंट किस समय लागू होता है?
- अनुमोदन: कब मैनेजर की समीक्षा आवश्यक है?
- अनुपालन: क्या लॉग किया जाना चाहिए, रिडैक्ट किया जाना चाहिए, या ब्लॉक किया जाना चाहिए?
नियम सामान्यतः "यदि X, तो Y" के रूप में व्यक्त होते हैं (कभी-कभी अपवादों के साथ), और इन्हें स्पष्ट परिणाम देना चाहिए: approve/deny, price A/price B, अधिक जानकारी का अनुरोध, आदि।
वर्कफ़्लो क्या है?
एक वर्कफ़्लो वह प्रक्रिया है जो काम को शुरुआत से समाप्ति तक आगे बढ़ाती है। यह यह तय करने से ज़्यादा है कि क्या अनुमति है और यह ज़्यादा है कि अगला क्या होना चाहिए। वर्कफ़्लो अक्सर शामिल करते हैं:
- स्थिति (States): submitted → under review → approved/denied → completed
- कदम और हैंडऑफ़: customer support → finance → customer
- समय-आधारित घटनाएँ: reminders, SLAs, 14 दिनों के बाद auto-cancel
- आर्टिफैक्ट्स: फॉर्म, अटैचमेंट, रीज़न कोड, ऑडिट नोट्स
एक छोटा उदाहरण: रिफंड अनुरोध
एक रिफंड अनुरोध की कल्पना करें।
नियम स्निपेट: “रिफंड खरीद के 30 दिनों के भीतर की अनुमति है। अपवाद: डिजिटल डाउनलोड एक बार एक्सेस होने के बाद नॉन-रिफंडेबल है। अपवाद: चार्जबैक को एस्केलेट करना चाहिए।”
वर्कफ़्लो स्निपेट:
- ग्राहक अनुरोध सबमिट करता है (स्थिति: submitted)।
- सिस्टम खरीद तारीख और उत्पाद प्रकार की जाँच करता है (स्थिति: under review)।
- यदि पात्र है, तो रिफंड जारी करें और ग्राहक को सूचित करें (स्थिति: completed)।
- यदि चार्जबैक है, तो फाइनेंस को जाँच के लिए भेजें (स्थिति: escalated)।
नियम अपेक्षाकृत कठिन क्यों हैं
जब नियम टकराते हैं (“VIP ग्राहकों को हमेशा रिफंड मिलता है” बनाम “डिजिटल डाउनलोड कभी नहीं”), संदर्भ लापता होता है (क्या डाउनलोड एक्सेस हुआ था?), या एज केस छिपे होते हैं (बंडल्स, आंशिक रिफंड, क्षेत्रीय कानून), तो नियम जटिल हो जाते हैं। वर्कफ़्लो एक और परत जोड़ता है: निर्णयों को वर्तमान स्थिति, पिछले कार्यों, और समय-सीमाओं के साथ सुसंगत रहना चाहिए।
LLM कैसे "तर्क" करते हैं: संरचित पैटर्न मिलान
LLM उस तरह से व्यावसायिक नियमों को "समझ" नहींते जैसे इंसान समझता है। वे बड़े मात्रा के टेक्स्ट से सीखे गए पैटर्न के आधार पर अगला सबसे संभावित शब्द जेनरेट करते हैं। इसलिए एक LLM बिना पर्याप्त जानकारी के भी आत्मविश्वास से प्रवण लग सकता है—या वह चुपचाप उन विवरणों को भर सकता है जो प्रदान नहीं किए गए।
यह सीमा वर्कफ़्लो और निर्णय लॉजिक के लिए महत्वपूर्ण है। एक मॉडल ऐसा नियम लागू कर सकता है जो "सही" सुनाई देता है ("कर्मचारियों को हमेशा मैनेजर की स्वीकृति चाहिए") भले ही वास्तविक नीति में अपवाद हों ("केवल $500 से ऊपर" या "केवल ठेकेदारों के लिए")। यह एक सामान्य फेलियर मोड है: आत्मविश्वासी लेकिन गलत नियम लागू करना।
वे फिर भी व्यावसायिक नियमों के लिए उपयोगी क्यों हैं
सच्ची "समझ" के बिना भी, LLM तब उपयोगी हो सकते हैं जब आप उन्हें एक संरचित सहायक के रूप में ट्रीट करें:
- लंबी नीतियों को समीक्षा के लिए स्पष्ट भाषा में सारांशित करना
- गंदे पाठ को सुसंगत फ़ील्ड्स में मैप करना (who, what, threshold, exception, effective date)
- प्रस्तावित निर्णय की प्रविष्टियों के खिलाफ जाँच करना ("कौन-सा क्लॉज़ इसे सपोर्ट करता है?")
कुंजी यह है कि मॉडल को ऐसी स्थिति में रखें जहाँ वह आसानी से इम्प्रोवाइज न कर सके।
मॉडल को भटकने से रोकना
अस्पष्टता कम करने का एक व्यावहारिक तरीका है सीमित आउटपुट: LLM से अपेक्षा करें कि वह एक निश्चित स्कीमा या टेम्पलेट में उत्तर दे (उदाहरण के लिए, JSON में विशिष्ट फ़ील्ड्स, या आवश्यक कॉलम के साथ एक टेबल)। जब मॉडल को rule_id, conditions, exceptions, और decision भरना होता है, तो गैप्स देखना और स्वचालित रूप से वैलिडेट करना आसान हो जाता है।
सीमित फॉर्मेट यह भी स्पष्ट करता है जब मॉडल कुछ नहीं जानता। यदि एक आवश्यक फ़ील्ड गायब है, तो आप एक फॉलो-अप प्रश्न बाध्य कर सकते हैं बजाय कि एक कमज़ोर उत्तर स्वीकार करने के।
निष्कर्ष: LLM "तर्क" को पैटर्न-आधारित जनरेशन के रूप में देखें जिसे संरचना द्वारा निर्देशित किया गया है—नियमों को व्यवस्थित करने और क्रॉस-चेक करने में उपयोगी, परंतु यदि आप इसे एक अटल निर्णयकर्ता मानते हैं तो जोखिम है।
गंदे नीति पाठ को उपयोगी नियम प्रतिनिधित्व में बदलना
नीति दस्तावेज़ मनुष्यों के लिए लिखे जाते हैं: वे लक्ष्यों, अपवादों, और "कॉमन सेंस" को एक ही पैरा में मिलाते हैं। एक LLM उस पाठ का सारांश कर सकता है, लेकिन जब आप नीति को स्पष्ट, टेस्ट करने योग्य इनपुट में बदलते हैं तो यह अधिक भरोसेमंद तरीके से नियमों का पालन करेगा।
"उपयोगी" नियम कैसा दिखता है
अच्छे नियम प्रतिनिधित्व की दो विशेषताएँ होती हैं: वे अस्पष्टता रहित होते हैं और वे जांचे जा सकते हैं।
टेस्ट करने योग्य कथनों के रूप में नियम लिखें:
- IF/THEN निर्णयों के लिए (पात्रता, रूटिंग, अनुमोदन)
- MUST / MUST NOT हार्ड कंस्ट्रेंट्स के लिए
- MAY अनुमत विकल्पों के लिए (अक्सर टाई-ब्रेकर चाहिए)
नियम मॉडल को कई रूपों में दिए जा सकते हैं:
- सादा-भाषा बुलेट्स (सबसे तेज़, फिर भी संरचित)
- एक टेबल (थ्रेशहोल्ड-आधारित नीतियों के लिए बेहतरीन)
- YAML/JSON (जब आप सीमित आउटपुट और स्वचालित वैलिडेशन भी चाहते हैं तो श्रेष्ठ)
टकराव और प्राथमिकता को संभालना
वास्तविक नीतियाँ टकराती हैं। जब दो नियम असहमति करते हैं, मॉडल को स्पष्ट प्राथमिकता स्कीम चाहिए। सामान्य दृष्टिकोण:
- विशेष सामान्य से बेहतर (अपवाद डिफ़ॉल्ट को ओवरराइड करता है)
- ऊँचे प्राधिकार का नियम जीतता है (legal/compliance टीम की प्राथमिकता टीम पसंद पर भारी)
- नवीनतम चलता है (नए संस्करण पुराने को ओवरराइड करते हैं)
- स्पष्ट प्राथमिकता संख्या (सबसे भरोसेमंद)
टकराव नियम को सीधे बताएं, या इसे एन्कोड करें (उदाहरण: priority: 100)। अन्यथा, LLM नियमों का "औसत" निकाल सकता है।
उदाहरण: एक पैराग्राफ को नियम सूची में बदलना
मूल नीति पाठ:
“Refunds are available within 30 days for annual plans. Monthly plans are non-refundable after 7 days. If the account shows fraud or excessive chargebacks, do not issue a refund. Enterprise customers need Finance approval for refunds over $5,000.”
Structured rules (YAML):
rules:
- id: R1
statement: "IF plan_type = annual AND days_since_purchase <= 30 THEN refund MAY be issued"
priority: 10
- id: R2
statement: "IF plan_type = monthly AND days_since_purchase > 7 THEN refund MUST NOT be issued"
priority: 20
- id: R3
statement: "IF fraud_flag = true OR chargeback_rate = excessive THEN refund MUST NOT be issued"
priority: 100
- id: R4
statement: "IF customer_tier = enterprise AND refund_amount > 5000 THEN finance_approval MUST be obtained"
priority: 50
conflict_resolution: "Higher priority wins; MUST NOT overrides MAY"
अब मॉडल यह अनुमान नहीं लगा रहा कि क्या महत्वपूर्ण है—यह एक नियम सेट लागू कर रहा है जिसे आप समीक्षा, परीक्षण और संस्करण नियंत्रित कर सकते हैं।
वर्कफ़्लो स्टेट को ट्रैक करना ताकि मॉडल सुसंगत रहे
वर्कफ़्लो केवल नियमों का सेट नहीं है; यह घटनाओं का एक अनुक्रम है जहाँ पहले के कदम यह बदल देते हैं कि आगे क्या होना चाहिए। वह "मेमोरी" ही स्टेट है: केस के बारे में वर्तमान तथ्य (किसने क्या सबमिट किया, क्या पहले से अनुमोदित है, क्या प्रतीक्षा में है, और कौन-सी समय-सीमाएँ लागू हैं)। यदि आप स्टेट को स्पष्ट रूप से ट्रैक नहीं करते, तो वर्कफ़्लो निश्चित तरीकों से टूटता है—डुप्लिकेट अनुमोदन, आवश्यक जाँचों को स्किप करना, निर्णय उलट जाना, या गलत नीति लागू होना क्योंकि मॉडल यह भरोसेमंद तरीके से नहीं समझ पाया कि पहले क्या हुआ।
सामान्य भाषा में "स्टेट" का क्या मतलब है
स्टेट को वर्कफ़्लो का स्कोरबोर्ड समझें। यह जवाब देता है: हम अब कहाँ हैं? क्या हो चुका है? अगला क्या करने की अनुमति है? LLM के लिए, एक स्पष्ट स्टेट सारांश होने से वह पिछली प्रक्रियाओं को फिर से बहस करने या अनुमान लगाने से बचता है।
मॉडल को स्टेट कैसे पास करें
जब आप मॉडल को कॉल करें, तो यूज़र अनुरोध के साथ एक संक्षिप्त स्टेट पेलोड शामिल करें। उपयोगी फ़ील्ड्स हैं:
- Step name and status (उदा.,
manager_review: approved,finance_review: pending) - Stable IDs (request ID, employee ID) ताकि मॉडल मामलों को मिक्स न करे
- Timestamps (submitted at, last updated) ताकि "latest wins" स्थितियाँ सुलझ सकें
- Flags (policy exceptions, missing documents, escalation required)
हर ऐतिहासिक संदेश को डंप करने से बचें। इसके बजाय वर्तमान स्टेट और प्रमुख ट्रांज़िशन का छोटा ऑडिट ट्रेल दें।
एकल सत्य स्रोत रखें
वर्कफ़्लो इंजन (डेटाबेस, टिकट सिस्टम, या ऑर्केस्ट्रेटर) को सिंगल सोर्स ऑफ़ ट्रुथ मानें। LLM को उस सिस्टम से स्टेट पढ़नी चाहिए और अगला कदम प्रस्तावित करना चाहिए, पर उस सिस्टम को ट्रांज़िशन रिकॉर्ड करने का अधिकार होना चाहिए। इससे "स्टेट ड्रिफ्ट" घटेगा, जहाँ मॉडल की कथा वास्तविकता से अलग हो जाती है।
उदाहरण: अप्रूवल-फ्लो स्टेट स्नैपशॉट
{
"request_id": "TRV-10482",
"workflow": "travel_reimbursement_v3",
"current_step": "finance_review",
"step_status": {
"submission": "complete",
"manager_review": "approved",
"finance_review": "pending",
"payment": "not_started"
},
"actors": {
"employee_id": "E-2291",
"manager_id": "M-104",
"finance_queue": "FIN-AP"
},
"amount": 842.15,
"currency": "USD",
"submitted_at": "2025-12-12T14:03:22Z",
"last_state_update": "2025-12-13T09:18:05Z",
"flags": {
"receipt_missing": false,
"policy_exception_requested": true,
"needs_escalation": false
}
}
ऐसी स्नैपशॉट के साथ, मॉडल सुसंगत रह सकता है: यह फिर से मैनेजर की मंजूरी नहीं मांगेगा, यह फाइनेंस जाँचों पर ध्यान देगा, और वर्तमान फ़्लैग्स और स्टेप के संदर्भ में निर्णय समझा पाएगा।
प्रॉम्प्ट पैटर्न जो नियम-अनुपालन और निर्णयों में सुधार करते हैं
फुल-स्टैक तेज़ी से तैयार करें
एक ही बातचीत से React ऐप, Go बैकएंड और PostgreSQL जनरेट करें।
एक अच्छा प्रॉम्प्ट केवल उत्तर नहीं माँगता—यह इस बात की उम्मीद भी सेट करता है कि मॉडल कैसे आपके नियम लागू करे और कैसे परिणाम रिपोर्ट करे। लक्ष्य दोहराव योग्य निर्णय हैं, न कि शानदार निबंध।
1) रोल प्रॉम्प्टिंग: वाइब नहीं, नौकरी सौंपें
मॉडल को आपके प्रोसेस से जुड़ा एक ठोस रोल दें। तीन भूमिकाएँ अच्छी तरह काम करती हैं:
- Policy analyst: नियम पाठ की व्याख्या करता है और उसे वर्तमान केस पर मानचित्रित करता है।
- Validator: निर्णय की आवश्यकताओं के मुताबिक़ जाँच करता है और गायब इनपुट फ़्लैग करता है।
- Agent: अगला वर्कफ़्लो एक्शन लेता है (टिकट बनाएँ, ईमेल ड्राफ्ट करें, स्थिति सेट करें)।
आप इन्हें क्रमिक रूप से चला सकते हैं ("analyst → validator → agent") या एक संरचित उत्तर में तीनों आउटपुट माँग सकते हैं।
2) चरण-दर-चरण निर्देश (छिपे हुए तर्क के लिए नहीं)
"चेन-ऑफ-थॉट" माँगने के बजाय, दृश्यमान चरण और आर्टिफैक्ट निर्दिष्ट करें:
- प्रासंगिक नियम पहचानें।
- केस से आवश्यक इनपुट निकालें।
- प्राथमिकता क्रम में नियम लागू करें।
- एक निर्णय और अगला कदम उत्पन्न करें।
यह मॉडल को संगठित रखने के साथ-साथ डिलिवरेबल्स पर ध्यान बनाए रखता है: कौन-से नियम उपयोग हुए और परिणाम क्या हुआ।
3) संरचित तर्क माँगें: rule IDs + evidence
फ्री-फॉर्म स्पष्टीकरण भटके रहते हैं। एक संक्षिप्त तर्क माँगें जो स्रोतों की ओर संकेत करे:
- Rule IDs used (उदा., R-12, R-18)
- Evidence (नीति पाठ से उद्धृत स्निपेट और विशिष्ट केस फ़ील्ड्स)
- Assumptions (केवल यदि इनपुट गायब हो)
यह समीक्षा तेज़ बनाता है और वाद-विवादों को डीबग करने में मदद करता है।
4) चेकलिस्ट प्रॉम्प्ट पैटर्न: इनपुट्स, निर्णय, अपवाद, अगला कदम
हर बार एक फिक्स्ड टेम्पलेट का उपयोग करें:
- Inputs received: …
- Inputs missing: …
- Decision: approve/deny/needs-review
- Rule references: [R-…]
- Exceptions considered: …
- Next workflow step: update status / request info / escalate
टेम्पलेट अस्पष्टता कम करता है और मॉडल को कमिट करने से पहले गैप्स सतह पर लाने के लिए प्रेरित करता है।
उपकरणों और रिट्रीवल का उपयोग कर निर्णयों को वास्तविक डेटा से ज़मीन पर लाना
एक LLM प्रेरक उत्तर दे सकता है भले ही वह महत्वपूर्ण तथ्यों के बिना हो। ड्राफ्टिंग के लिए यह उपयोगी है, पर व्यावसायिक-नियम निर्णयों के लिए जोखिम भरा। यदि मॉडल को किसी खाते की स्थिति, ग्राहक की टियर, क्षेत्रीय कर दर, या यह कि क्या सीमा पहले ही पहुंच चुकी है—इन सब का अनुमान लगाना पड़े, तो आपको आत्मविश्वासी-लगने वाली गलतियाँ मिलेंगी।
उपकरण इस समस्या को दो-चरण प्रक्रिया में बदल देते हैं: पहले प्रमाण लाओ, फिर निर्णय लो।
मॉडल को ईमानदार रखने वाले सामान्य उपकरण
नियम और वर्कफ़्लो-भारी सिस्टम में, कुछ सरल उपकरण अधिकांश काम करते हैं:
- डेटाबेस लुकअप (कस्टमर प्रोफ़ाइल, खाता स्थिति, entitlements, उपयोग टोटल)
- पॉलिसी/रूल स्टोर (अनुमोदित नियम पाठ, संस्करणित प्रक्रियाएँ, अपवाद सूचियाँ)
- कैल्कुलेटर (फीस, प्रोरेशन, टैक्स, टाइम विंडो, थ्रेशहोल्ड)
- टिकेटिंग / वर्कफ़्लो API (खुले केस, SLA टाइमर, अनुमोदन, स्टेप कंप्लीशन)
कुंजी यह है कि मॉडल ऑपरेशनल फैक्ट्स "बना" नहीं रहा—यह उन्हें अनुरोध कर रहा है।
रिट्रीवल: केवल वही नियम लाएँ जो मायने रखते हैं
यदि आप सारी नीतियाँ सेंट्रल स्टोर में रखते हैं, तब भी आप शायद पूरे दस्तावेज़ को प्रॉम्प्ट में पेस्ट नहीं करना चाहेंगे। रिट्रीवल उस हिस्से को चुनने में मदद करता है जो वर्तमान केस के लिए सबसे प्रासंगिक है—उदाहरण:
- उस ग्राहक के प्लान की कैंसलेशन नीति
- देश/राज्य के आधार पर क्षेत्रीय अनुपालन क्लॉज़
- चार्जबैक पेंडिंग होने पर लागू अपवाद नियम
इससे विरोधाभास कम होता है और मॉडल पुराने नियम का पालन इसलिए नहीं करेगा क्योंकि वह संदर्भ में पहले दिखाई दिया।
उपकरण आउटपुट को निर्णय साक्ष्य में बदलना
एक विश्वसनीय पैटर्न यह है कि टूल परिणामों को सबूत की तरह ट्रीट किया जाए जिन्हें मॉडल अपने निर्णय में उद्धृत करे। उदाहरण:
- Tool:
get_account(account_id)→status="past_due",plan="Business",usage_this_month=12000 - Tool:
retrieve_policies(query="overage fee Business plan")→ returns rule: “Overage fee applies above 10,000 units at $0.02/unit.” - Tool:
calculate_overage(usage=12000, threshold=10000, rate=0.02)→$40.00
अब निर्णय अनुमान नहीं है: यह विशिष्ट इनपुट्स पर आधारित निष्कर्ष है (“past_due”, “12,000 units”, “$0.02/unit”)। बाद में यदि आप नतीजा ऑडिट करें, तो आप देख पाएंगे कि किस तथ्य और किस नियम-वर्ज़न का उपयोग हुआ—और जब कुछ बदले तो सही हिस्से को ठीक कर सकेंगे।
सीमित आउटपुट: अस्पष्टता घटाने वाली स्कीमाएँ
तेज़ी से तैनात करें और सुधार करें
एक ही जगह तैनाती और होस्टिंग के साथ अपना वर्कफ़्लो असिस्टेंट तैनात करें।
फ्री-फॉर्म टेक्स्ट लचीला होता है, पर यह वर्कफ़्लो टूटने का सबसे आसान तरीका भी है। एक मॉडल "तर्क" देने में सक्षम हो सकता है पर वह ऐसा उत्तर दे सकता है जिसे ऑटोमेट करना मुश्किल हो ("यह ठीक लगता है") या चरणों के बीच असंगतता हो सकती है ("approve" बनाम "approved")। सीमित आउटपुट यह समस्या हल करता है क्योंकि वह हर निर्णय को एक अपेक्षित आकार में बाध्य करता है।
निर्णय JSON के रूप में लौटाएँ
एक व्यावहारिक पैटर्न यह है कि मॉडल से एक ही JSON ऑब्जेक्ट जवाब में माँगा जाए जिसे आपकी सिस्टम पार्स कर सके और रूट कर सके:
{
"decision": "needs_review",
"reasons": [
"Applicant provided proof of income, but the document is expired"
],
"next_action": "request_updated_document",
"missing_info": [
"Income statement dated within the last 90 days"
],
"assumptions": [
"Applicant name matches across documents"
]
}
यह संरचना आउटपुट को उपयोगी बनाती है भले ही मॉडल पूरा निर्णय न कर पाए। missing_info और assumptions अनिश्चितता को कार्रवाई योग्य फॉलो-अप में बदल देते हैं, न कि छिपे हुए अनुमान में।
परिणाम सीमित करने के लिए एन्यूम्स का उपयोग
बदलाव घटाने के लिए प्रमुख फ़ील्ड्स (enums) की अनुमति वाले मान परिभाषित करें। उदाहरण:
decision:approved|denied|needs_reviewnext_action:approve_case|deny_case|request_more_info|escalate_to_human
एन्यूम्स के साथ, डाउनस्ट्रीम सिस्टम को पर्यायवाची शब्दों या टोन की व्याख्या नहीं करनी होती—वे केवल ज्ञात मानों पर शाखा लगा सकते हैं।
स्कीमा वर्कफ़्लो को सुरक्षित क्यों बनाते हैं
स्कीमा गार्डरेल की तरह काम करते हैं। वे:
- आवश्यक फ़ील्ड माँग कर "आंशिक उत्तर" को रोकते हैं।
reasonsके माध्यम से दिखाते हैं कि निर्णय क्यों हुआ, जिससे ऑडिट आसान होता है।- विश्वसनीय ऑटोमेशन सक्षम करते हैं: क्यूज़, नोटिफ़िकेशन, और टास्क क्रिएशन सीधे
decisionऔरnext_actionसे ट्रिगर हो सकते हैं। - वैलिडेशन का समर्थन करते हैं: आप ऐसे आउटपुट रिजेक्ट कर सकते हैं जो स्कीमा से मेल नहीं खाते और मॉडल से पुनः प्रयास मांग सकते हैं।
परिणाम: कम अस्पष्टता, कम एज-कैस विफलताएँ, और निर्णय जो सुसंगत रूप से वर्कफ़्लो से होकर आगे बढ़ सकते हैं।
मान्यकरण की रणनीतियाँ: रिलीज़ से पहले त्रुटियाँ पकड़ना
एक अच्छी तरह से प्रॉम्प्टेड मॉडल भी "सही" सुन सकता है पर चुप्पी से नियम का उल्लंघन कर सकता है, आवश्यक कदम छोड़ सकता है, या कोई मान बना सकता है। मान्यकरण वह सुरक्षा जाल है जो संभावित उत्तर को भरोसेमंद निर्णय बनाता है।
प्री-चेक: तर्क से पहले इनपुट मान्य करें
शुरू में सुनिश्चित करें कि नियम लागू करने के लिए न्यूनतम जानकारी मौजूद है। प्री-चेक्स मॉडल के किसी भी निर्णय से पहले चलने चाहिए।
सामान्य प्री-चेक्स में आवश्यक फ़ील्ड्स (उदा., customer type, order total, region), बेसिक फॉर्मैट (तिथियाँ, IDs, मुद्रा), और अनुमत रेंजेस (निगेटिव न हों, प्रतिशत 100 पर कैप) शामिल हैं। यदि कुछ विफल होता है, तो एक स्पष्ट, कार्रवाई योग्य त्रुटि लौटाएँ ("Missing 'region'; cannot choose tax rule set") बजाय कि मॉडल को अनुमान लगाने दें।
पोस्ट-चेक: नियमों के खिलाफ निर्णय को वैलिडेट करें
मॉडल ने आउटपुट बना दिया—अब जाँच करें कि वह आपके नियम सेट के अनुरूप है।
ध्यान दें:
- Rule coverage: क्या निर्णय ने लागू नियमों का हवाला दिया या किसी अनिवार्य नीति को छोड़ दिया?
- Contradiction checks: क्या आउटपुट इनपुट्स के साथ विरोध कर रहा है (उदा., एक हार्ड-ब्लॉक स्थिति होने पर "approved"?)
- Boundary cases: थ्रेशहोल्ड्स का परीक्षण करें (ठीक $10,000), खाली स्थितियाँ ("no prior violations"), और "थोड़ा ऊपर" परिदृश्यों की जाँच करें।
सेकंड-पास वैलिडेशन: एक इरादतन समीक्षा कदम
पहले उत्तर को पुनः-अकलन करने के लिए एक "दूसरा पास" जोड़ें। यह दूसरी मॉडल कॉल हो सकती है या वही मॉडल एक वैलिडेटर-स्टाइल प्रॉम्प्ट के साथ जो केवल अनुपालन जांचता है, रचनात्मकता नहीं।
एक सरल पैटर्न: पहला पास निर्णय + तर्क देता है; दूसरा पास valid लौटाता है या असफलताओं की संरचित सूची (गायब फ़ील्ड्स, उल्लंघन किए गए कंस्ट्रेंट्स, अस्पष्ट नियम व्याख्या) देता है।
लॉगिंग: निर्णयों को ऑडिटेबल बनाएं
हर निर्णय के लिए, उपयोग किए गए इनपुट्स, नियम/नीति वर्ज़न, और वैलिडेशन परिणाम (दूसरे पास की खोज सहित) लॉग करें। जब कुछ गलत हो, तो यह आपको सटीक परिस्थितियाँ फिर से उत्पन्न करने, नियम मैपिंग को ठीक करने, और सुधार की पुष्टि करने देता है—बिना यह अनुमान लगाए कि मॉडल "क्या कहना चाहता था"।
नियम और वर्कफ़्लो विश्वसनीयता के लिए परीक्षण और निगरानी
LLM-आधारित नियम और वर्कफ़्लो सुविधाओं का परीक्षण यह नहीं है कि "क्या उसने कुछ उत्पन्न किया?" बल्कि यह है कि "क्या उसने वही निर्णय लिया जो एक सतर्क इंसान हर बार सही कारण के लिए लेता?" अच्छी बात यह है कि आप इसे पारंपरिक निर्णय लॉजिक जितनी अनुशासनात्मकता से टेस्ट कर सकते हैं।
व्यावसायिक नियमों के लिए यूनिट टेस्ट (छोटे, पूर्वानुमान योग्य चेक)
हर नियम को एक फ़ंक्शन की तरह ट्रीट करें: दिए गए इनपुट पर इसका आउटपुट ऐसा होना चाहिए जिसका आप अनुमान लगा सकें।
उदाहरण के लिए, यदि आपके पास रिफंड नियम है "अन-ओपन किए गए आइटम के लिए 30 दिनों के भीतर रिफंड की अनुमति है", तो फोकस्ड केस लिखें:
- Order age = 10 days, unopened = true → approve
- Order age = 10 days, unopened = false → deny
- Order age = 45 days, unopened = true → deny
- एज केस: ठीक 30 दिन, "unopened" फ़ील्ड गायब, विरोधाभास संकेत
ये यूनिट टेस्ट ऑफ-बाय-वन गलतियाँ, गायब फ़ील्ड्स, और "मददगार" मॉडल बिहेवियर जहाँ वह अज्ञात भरने की कोशिश करता है, पकड़ लेते हैं।
वर्कफ़्लो के लिए परिदृश्य टेस्ट (मल्टी-स्टेप, समय-सम्वेदनशील मार्ग)
वर्कफ़्लो तब विफल होते हैं जब स्टेट चरणों के बीच असंगत हो जाता है। परिदृश्य टेस्ट वास्तविक यात्राओं का अनुकरण करते हैं:
- पाथ टेस्ट: submit claim → request documents → documents received → decision
- समय-आधारित एज: "यदि 7 दिनों में कोई उत्तर नहीं, तो reminder भेजें", "यदि 30 दिन गुजर गए, तो केस बंद करें"
- ब्रांचिंग: ग्राहक एस्केलेट करता है, नीति अपवाद अनुरोध किया जाता है, डुप्लिकेट केस का पता चलता है
लक्ष्य यह सुनिश्चित करना है कि मॉडल वर्तमान स्टेट का सम्मान करे और केवल अनुमत ट्रांज़िशन ही ले।
"गोल्ड सेट" बनाना
वास्तविक, अनामिकृत उदाहरणों का एक क्यूरेटेड डेटासेट बनाएं जिनके साथ सहमत परिणाम (और संक्षिप्त तर्क) हों। इसे संस्करण नियंत्रित रखें और नीति बदलने पर समीक्षा करें। एक छोटा गोल्ड सेट (100–500 केस भी) शक्तिशाली होता है क्योंकि यह गंदे वास्तविकता—गायब डेटा, असामान्य वर्डिंग, बॉर्डरलाइन निर्णय—को दर्शाता है।
प्रोडक्शन में निगरानी (ग्राहकों से पहले ड्रिफ्ट पकड़ें)
समय के साथ निर्णय वितरण और गुणवत्ता संकेतों को ट्रैक करें:
- ड्रिफ्ट: बिना नीति अपडेट के अप्रत्याशित रूप से बदलती approval/denial दरें
- needs_review या मानव हस्तक्षेप में उछाल (अक्सर प्रॉम्प्ट, रिट्रीवल, या अपस्ट्रीम डेटा समस्या)
- उत्पाद, क्षेत्र, या नीति श्रेणी के अनुसार त्रुटि क्लस्टर
निगरानी को सेफ रोलबैक के साथ जोड़ें: पिछला प्रॉम्प्ट/नियम पैक रखें, नई वर्ज़न पर फ़ीचर फ्लैग रखें, और मेट्रिक्स गिरने पर जल्दी वापस करने के लिए तैयार रहें। ऑपरेशनल प्लेबुक और रिलीज़ गेटिंग के लिए देखें /blog/validation-strategies।
इस पाइपलाइन में Koder.ai की भूमिका
अपने डोमेन पर लाइव जाएँ
जब आप साझा करने के लिए तैयार हों तो अपने कस्टम डोमेन पर लॉन्च करें।
यदि आप ऊपर बताए गए पैटर्न लागू कर रहे हैं, तो आमतौर पर आप मॉडल के चारों ओर एक छोटा सिस्टम बनाएँगे: स्टेट स्टोरेज, टूल कॉल्स, रिट्रीवल, स्कीमा वेलिडेशन, और एक वर्कफ़्लो ऑर्केस्ट्रेटर। Koder.ai उस तरह के वर्कफ़्लो-बैक्ड असिस्टेंट को तेज़ी से प्रोटोटाइप और शिप करने का एक व्यावहारिक तरीका है: आप चैट में वर्कफ़्लो का वर्णन कर सकते हैं, एक कार्यशील वेब ऐप (React) और बैकएंड सर्विसेज (Go with PostgreSQL) जेनरेट कर सकते हैं, और स्नैपशॉट्स और रोलबैक का उपयोग करके सुरक्षित रूप से इटरेट कर सकते हैं।
यह व्यावसायिक-नियम तर्क के लिए मायने रखता है क्योंकि "गार्डरेल" अक्सर एप्लिकेशन में रहते हैं, न कि केवल प्रॉम्प्ट में:
- Planning mode आपको फ्लो (स्टेट्स, अनुमत ट्रांज़िशन, एस्केलेशन पाथ) को निष्पादन से पहले डिजाइन करने में मदद करता है।
- Schema-constrained responses API बाउंडरी पर लागू किए जा सकते हैं, ताकि आप केवल पार्स करने योग्य निर्णय स्वीकार करें।
- Tooling hooks (DB reads, policy retrieval, calculators, ticket updates) स्पष्ट एंडपॉइंट्स के रूप में लागू किए जा सकते हैं, जिससे "पहले प्रमाण लाओ, फिर निर्णय लो" डिफ़ॉल्ट बन जाता है।
- Source code export आपको लॉक-इन से बचाता है जब प्रोटोटाइप प्रोडक्शन-क्रिटिकल बन जाए।
सीमाएँ, सुरक्षित उपयोग, और कब मानव को शामिल रखें
LLM रोज़मर्रा की नीतियों पर आश्चर्यजनक रूप से अच्छा प्रदर्शन कर सकते हैं, पर वे एक निर्धारक नियम इंजन के बराबर नहीं हैं। उन्हें ऐसे निर्णय सहायक के रूप में ट्रीट करें जिन्हें गार्डरेल की आवश्यकता है—न कि अंतिम प्राधिकरण के रूप में।
LLM कहाँ संघर्ष करते हैं
नियम-भारी वर्कफ़्लो में तीन फेलियर मोड बार-बार आते हैं:
- दुर्लभ अपवाद और एज केस: यदि कोई अपवाद साल में एक बार ही होता है, तो वह प्रशिक्षण डेटा में कम प्रतिनिधित्व वाला हो सकता है और प्रॉम्प्ट या पॉलिसी डॉक्यूमेंट से स्पष्ट रूप से प्रदान न होने पर आसानी से छूट सकता है।
- लंबा संदर्भ और "दफ़न" बाध्यताएँ: जब प्रमुख विवरण कई पृष्ठों या संदेशों में बँटे हों, मॉडल ताज़ा या जीवंत टेक्स्ट पर अधिक वजन कर सकता है और पहले के बाध्यताओं को कम आंका जा सकता है।
- सांख्यिकीय सटीकता और कड़े कैलकुलेशन: टोटल्स, प्रोरेशन, थ्रेशहोल्ड और राउंडिंग नियम भटक सकते हैं। गणित के लिए उपकरणों का उपयोग करें और मॉडल से वे सटीक संख्याएँ उद्धृत करने को कहें जिनका उसने उपयोग किया।
कब मानव समीक्षा ज़रूरी रखें
मैंडेटरी रिव्यू जोड़ें जब:
- परिणाम उच्च जोखिम वाला हो (पैसे का लेन-देन, अनुपालन, सुरक्षा, कानूनी प्रतिबद्धताएँ, ग्राहक क्रेडिट/पात्रता)।
- मॉडल कम आत्मविश्वास संकेत दे (यह गायब इनपुट्स को अनुमान लगाने का प्रस्ताव करे, नीति आधार न मिल पाए, या विरोधाभासी तर्क दे)।
- केस नवीन हो (नया उत्पाद, नया क्षेत्र, नीति हाल ही में बदली हुई) या असामान्य संवेदनशील हो।
एस्केलेशन पाथ जो चीज़ों को आगे बढ़ाते हैं
मॉडल को "कुछ बना देने" देने की बजाय, स्पष्ट अगले कदम परिभाषित करें:
- स्पष्ट करने वाले प्रश्न पूछें (गायब तिथियाँ, ग्राहक टियर, क्षेत्राधिकार, अनुमोदन स्थिति)।
- एक एजेंट को रूट करें जिनके पास निकाले गए तथ्य, प्रस्तावित निर्णय, और उद्धरण हों।
- टिकिट बनाएं जब नीति अस्पष्ट या विरोधाभासी हो, ताकि इसे स्रोत पर सुधारा जा सके (और बाद में स्वतः प्राप्त किया जा सके)।
एक सरल अपनाने का फ्रेमवर्क
नीति-भारी वर्कफ़्लो में LLM का उपयोग तब करें जब आप अधिकतर सवालों का "हाँ" कह सकें:
- क्या हम निर्णयों को अनुमोदित नीति पाठ या सिस्टम डेटा में ग्राउंड कर सकते हैं?
- क्या हम आउटपुट को सीमित कर सकते हैं (स्कीमा, अनुमत क्रियाएँ, आवश्यक उद्धरण)?
- क्या हम निष्पादन से पहले वैलिडेट कर सकते हैं (चेक्स, थ्रेशहोल्ड, यूनिट टेस्ट, सैंप्लिंग)?
- क्या हमारे पास जोखिमपूर्ण या अनिश्चित मामलों के लिए मानव एस्केलेशन पाथ है?
यदि नहीं, तो उन नियंत्रणों के बने बिना LLM को ड्राफ्ट/सहायक भूमिका में रखें।