21 मई 2025·8 मिनट
क्लाइंट SLA रिपोर्टिंग के लिए केंद्रीकृत वेब ऐप बनाएं
सीखें कि कैसे एक मल्टी‑क्लाइंट वेब ऐप की योजना बनाएं, बनाएं और लॉन्च करें जो SLA डेटा इकट्ठा करे, मैट्रिक्स सामान्यीकृत करे, और डैशबोर्ड, अलर्ट और एक्सपोर्टेबल रिपोर्ट्स दे।
सीखें कि कैसे एक मल्टी‑क्लाइंट वेब ऐप की योजना बनाएं, बनाएं और लॉन्च करें जो SLA डेटा इकट्ठा करे, मैट्रिक्स सामान्यीकृत करे, और डैशबोर्ड, अलर्ट और एक्सपोर्टेबल रिपोर्ट्स दे।
कंद्रीकृत SLA रिपोर्टिंग इसलिए जरूरी है क्योंकि SLA के प्रमाण अक्सर एक ही जगह नहीं होते। अपटाइम मॉनिटरिंग टूल में हो सकता है, incidents स्टेटस पेज पर हों, टिकट्स helpdesk में हों, और एस्केलेशन नोट्स ईमेल या चैट में रहें। जब हर क्लाइंट का स्टैक (या नामकरण) थोड़ा अलग हो, तो मासिक रिपोर्टिंग मैन्युअल स्प्रेडशीट काम बन जाती है—और “वास्तव में क्या हुआ” पर विवाद आम हो जाते हैं।
एक अच्छा SLA रिपोर्टिंग वेब ऐप अलग‑अलग लक्ष्यों वाले कई दर्शकों की सेवा करता है:
ऐप को भूमिका के आधार पर अलग‑अलग विस्तार स्तर पर वही underlying सत्य दिखाना चाहिए।
केंद्रीकृत SLA डैशबोर्ड को प्रदान करना चाहिए:
व्यवहार में, हर SLA संख्या को कच्चे ईवेंट्स (अलर्ट्स, टिकट, incident timelines) के टाइमस्टैम्प्स और ownership के साथ ट्रेस किया जा सके।
कुछ भी बनाने से पहले यह तय करें कि क्या in scope है और क्या out of scope। उदाहरण:
स्पष्ट सीमाएँ बाद में बहस रोकती हैं और रिपोर्टिंग को क्लाइंट्स में समान रखती हैं।
न्यूनतम रूप से, केंद्रीकृत SLA रिपोर्टिंग को पाँच वर्कफ़्लो सपोर्ट करने चाहिए:
इन वर्कफ़्लो के चारों ओर डिज़ाइन करें ताकि सिस्टम के बाकी हिस्से (डेटा मॉडल, इंटीग्रेशन, UX) वास्तविक रिपोर्टिंग आवश्यकताओं से मेल खाएँ।
स्क्रीन या पाइपलाइन्स बनाने से पहले तय करें कि आपका ऐप क्या मापेगा और उन संख्याओं की व्याख्या कैसे होगी। लक्ष्य है स्थिरता: एक ही रिपोर्ट पढ़ रहे दो लोग एक ही निष्कर्ष पर पहुँचें।
शुरू में छोटे सेट से शुरू करें जिसे अधिकांश क्लाइंट पहचानते हैं:
स्पष्ट रूप से बताएं कि हर मैट्रिक क्या मापता है और क्या नहीं करता। UI में एक छोटा definitions पैनल (और /help/sla-definitions का लिंक) बाद की गलतफहमियों को रोकता है।
नियम वहीं पर टूटते हैं जहाँ SLA रिपोर्टिंग अक्सर फेल होती है। उन्हें ऐसे वाक्यों में दस्तावेज़ करें जिन्हें आपका क्लाइंट मान्य कर सके, फिर उन्हें लॉजिक में अनुवाद करें।
ज़रूरी बातें कवर करें:
डिफ़ॉल्ट पीरियड्स (मासिक और त्रैमासिक आम हैं) चुनें और तय करें कि क्या आप कस्टम रेंज सपोर्ट करेंगे। कटऑफ़ के लिए उपयोग होने वाले टाइमज़ोन को स्पष्ट करें।
ब्रीच के लिए परिभाषाएँ:
प्रत्येक मैट्रिक के लिए आवश्यक इनपुट (मॉनिटरिंग ईवेंट्स, incident रिकॉर्ड्स, टिकट टाइमस्टैम्प, मेंटेनेंस विंडो) सूचीबद्ध करें। यह आपके इंटीग्रेशन और डेटा क्वालिटी चेक्स के लिए ब्लूप्रिंट बन जाता है।
डैशबोर्ड या KPIs डिज़ाइन करने से पहले स्पष्ट करें कि SLA प्रमाण वास्तव में कहाँ रहता है। अधिकांश टीमें पाती हैं कि उनका “SLA डेटा” टूल्स में विभाजित है, अलग‑अलग समूहों के स्वामित्व में है, और थोड़े अलग अर्थों के साथ रिकॉर्ड किया गया है।
प्रति क्लाइंट (और प्रति सेवा) एक सरल सूची से शुरू करें:
प्रत्येक सिस्टम के लिए मालिक, retention अवधि, API सीमाएँ, समय रिज़ोल्यूशन (सेकंड बनाम मिनट), और क्या डेटा क्लाइंट‑स्कोप्ड है या साझा, नोट करें।
अधिकांश SLA रिपोर्टिंग ऐप मिश्रण का उपयोग करते हैं:
व्यावहारिक नियम: जहाँ ताज़गी मायने रखती है वहाँ webhooks, जहाँ पूर्णता मायने रखती है वहाँ API pulls।
भिन्न टूल समान चीज़ों का भिन्न वर्णन करते हैं। सामान्यीकृत करने के लिए एक छोटा सेट ईवेंट्स बनाएं जिनपर आपका ऐप भरोसा कर सके, जैसे:
incident_opened / incident_closeddowntime_started / downtime_endedticket_created / first_response / resolvedसंगत फ़ील्ड शामिल करें: client_id, service_id, source_system, external_id, severity, और timestamps।
सभी टाइमस्टैम्प्स UTC में स्टोर करें, और डिस्प्ले पर क्लाइंट की पसंदीदा टाइम ज़ोन के अनुसार कन्वर्ट करें (विशेषकर मासिक रिपोर्टिंग कटऑफ़ के लिए)।
गैप्स के लिए भी योजना बनाएं: कुछ क्लाइंट्स के पास स्टेटस पेज नहीं होगा, कुछ सेवाएँ 24/7 मॉनिटर नहीं होंगी, और कुछ टूल्स ईवेंट्स खो सकते हैं। रिपोर्ट्स में “आंशिक कवरैज” दिखाएँ (उदा. “3 घंटे के लिए मॉनिटरिंग डेटा अनुपलब्ध”) ताकि SLA परिणाम भ्रामक न हों।
यदि आपका ऐप कई कस्टमर्स के SLA रिपोर्ट करता है, तो आर्किटेक्चर निर्णय यह तय करते हैं कि आप सुरक्षित रूप से स्केल कर पाएँगे या नहीं बिना क्लाइंट‑डेटा लीक के।
पहले उन परतों को नाम दें जिन्हें आपको सपोर्ट करना है। एक “क्लाइंट” हो सकता है:
इन्हें जल्दी लिख दें, क्योंकि ये permissions, filters, और configuration स्टोर करने के तरीके को प्रभावित करते हैं।
अधिकांश SLA रिपोर्टिंग ऐप इनमें से एक चुनते हैं:
tenant_id टैग। लागत‑प्रभावी और संचालन में सरल पर सख्त क्वेरी अनुशासन की जरूरत होती है।कौमन समझौता: अधिकांश टेनेंट्स के लिए shared DB और "एंटरप्राइज़" ग्राहकों के लिए dedicated DBs।
隔離 को बनाए रखें:
tenant_id शामिल हो ताकि गलत टेनेंट पर परिणाम न लिखेंGuardrails जैसे row-level security, अनिवार्य क्वेरी स्कोप और tenant boundary के लिए automated tests उपयोग करें।
अलग क्लाइंट्स के लक्ष्य और परिभाषाएँ अलग होंगी। प्रति‑टेनेंट सेटिंग्स की योजना बनाएं जैसे:
आंतरिक उपयोगकर्ता अक्सर क्लाइंट व्यू को "impersonate" करना चाहते हैं। एक जानबूझकर स्विच लागू करें (फ्री‑फॉर्म फ़िल्टर नहीं), सक्रिय टेनेंट स्पष्ट रूप से दिखाएँ, स्विच को ऑडिट के लिए लॉग करें, और ऐसे लिंक रोकें जो tenant checks बायपास कर सकें।
केंद्रीकृत SLA रिपोर्टिंग वेब ऐप की सफलता उसके डेटा मॉडल पर निर्भर करती है। अगर आप केवल “प्रतिमाह SLA %” मॉडल करेंगे, तो आप परिणाम समझाने, विवाद संभालने, या बाद में गणनाओं को अपडेट करने में मुश्किल आएगी। अगर आप सिर्फ कच्चे ईवेंट्स मॉडल करेंगे, रिपोर्टिंग धीमी और महँगी हो जाएगी। लक्ष्य दोनों का समर्थन करना है: ट्रेस करने योग्य कच्चा प्रमाण और तेज़, क्लाइंट‑रेडी रोल‑अप्स।
"किस पर रिपोर्ट की जा रही है", "क्या मापा जा रहा है", और "कैसे गणना हो रही है" के बीच साफ़ अलगाव रखें:
टेबल्स/कलेक्शन्स डिज़ाइन करें:
SLA लॉजिक बदलता रहता है: बिजनेस ऑवर्स अपडेट होते हैं, बहिष्करण स्पष्ट होते हैं, राउंडिंग नियम विकसित होते हैं। हर किए गए परिणाम में calculation_version (और बेहतर है तो एक rule set reference) जोड़ें ताकि पुराने रिपोर्ट्स ठीक वैसे ही पुनरुत्पादन हो सकें।
जहाँ जरूरी हो audit फ़ील्ड्स जोड़ें:
क्लाइंट अक्सर पूछते हैं “मुझे क्यों दिखाओ।” इसके लिए schema योजना बनाएं:
यह स्ट्रक्चर ऐप को समझने योग्य, पुनरुत्पादन योग्य और तेज़ रखता है—बिना आधारभूत प्रमाण खोए।
यदि आपके इनपुट गन्दे हैं, तो आपका SLA डैशबोर्ड भी गन्दा होगा। एक विश्वसनीय पाइपलाइन कई टूल्स से incident और टिकट डेटा को सुसंगत, ऑडिटेबल SLA परिणामों में बदलती है—बिना डबल‑काउंटिंग, गैप्स, या चुपचाप फेल होने के।
ingestion, normalization, और rollups को अलग चरणों के रूप में रखें। इन्हें बैकग्राउंड जॉब्स के रूप में चलाएँ ताकि UI तेज़ रहे और आप सुरक्षित रूप से retries कर सकें।
यह विभाजन तब भी मदद करता है जब किसी क्लाइंट के स्रोत डाउन हों: ingestion फेल हो सकता है बिना मौजूदा गणनाओं को भ्रष्ट किए।
एक्सटर्नल APIs टाइमआउट करते हैं। वेबहुक्स दो बार डिलीवर हो सकते हैं। आपकी पाइपलाइन idempotent होनी चाहिए: एक ही इनपुट को बार‑बार प्रोसेस करने से परिणाम नहीं बदलना चाहिए।
सामान्य दृष्टिकोण:
क्लाइंट्स और टूल्स में “P1”, “Critical”, और “Urgent” एक ही अर्थ दे सकते हैं—या नहीं। एक normalization लेयर बनाएं जो स्टैन्डर्डाइज़ करे:
ट्रेसबिलिटी के लिए मूल मान और सामान्यीकृत मान दोनों स्टोर करें।
validation नियम जोड़ें (missing timestamps, negative durations, असंभव स्टेटस ट्रांज़िशन्स)। खराब डेटा को चुपचाप ड्रॉप न करें—इसे कारण के साथ एक quarantine queue में भेजें और "fix or map" वर्कफ़्लो प्रदान करें।
प्रत्येक क्लाइंट और स्रोत के लिए “last successful sync”, “oldest unprocessed event”, और “rollup up-to date through” कैलकुलेट करें। इसे एक साधारण डेटा फ्रेशनेस संकेतक के रूप में दिखाएँ ताकि क्लाइंट्स संख्याओं पर भरोसा करें और आपकी टीम जल्दी समस्याएँ पकड़ सके।
यदि क्लाइंट्स आपके पोर्टल का उपयोग अपने SLA प्रदर्शन की समीक्षा के लिए करेंगे, तो authentication और permissions उतने ही सावधानी से डिज़ाइन करने होंगे जितना SLA गणित। लक्ष्य सरल है: हर यूज़र वही देखे जिसकी उसे अनुमति है—और आप बाद में इसे सिद्ध कर सकें।
छोटे, स्पष्ट रोल सेट से शुरू करें और केवल जब सख्त कारण हों तब ही बढ़ाएँ:
न्यू अकाउंट्स के लिए least privilege डिफ़ॉल्ट रखें: नए खाते सामान्यतः viewer मोड में आएँ जब तक स्पष्ट रूप से प्रमोट न किया जाए।
आंतरिक टीम्स के लिए SSO अकाउंट स्प्रॉल और ऑफबोर्डिंग जोखिम घटाता है। OIDC (Google Workspace/Azure AD/Okta) और जहाँ आवश्यक हो SAML सपोर्ट करें।
क्लाइंट्स के लिए SSO को एक अपग्रेड विकल्प के रूप में दें, पर छोटे संगठनों के लिए ईमेल/पासवर्ड + MFA भी रखें।
हर परत पर टेनेंट बॉउन्ड्री लागू करें:
संवेदनशील पृष्ठों और डाउनलोड्स तक पहुँच को लॉग करें: किसने क्या, कब, और कहाँ से एक्सेस किया। यह अनुपालन और क्लाइंट भरोसे में मदद करता है।
एक ऑनबोर्डिंग फ़्लो बनाएं जहाँ admins या client editors यूज़र्स को आमंत्रित कर सकें, रोल्स सेट कर सकें, ईमेल सत्यापन आवश्यक कर सकें, और किसी के जाने पर पहुँच तुरंत रद्द कर सकें।
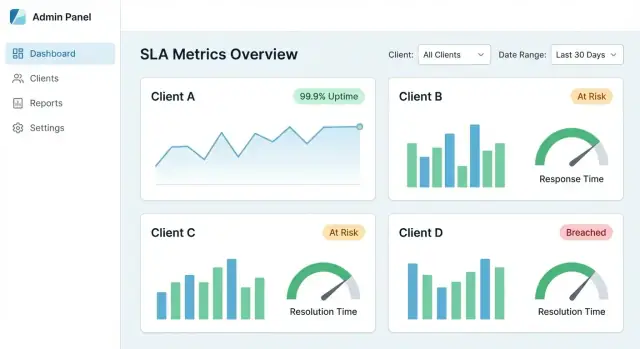
केंद्रीकृत SLA डैशबोर्ड तब सफल होता है जब क्लाइंट एक मिनट के अंदर तीन सवालों के जवाब पा लें: क्या हम SLA पूरा कर रहे हैं? क्या बदला? किस वजह से कमी आई? आपका UX उन्हें हाई‑लेवल व्यू से प्रमाण तक गाइड करे—बिना यह मजबूर किए कि वे आपके आंतरिक डेटा मॉडल को सीखें।
छोटे सेट के टाइल्स और चार्ट से शुरू करें जो सामान्य SLA चर्चाओं से मेल खाते हों:
हर कार्ड को क्लिक‑योग्य बनाएं ताकि वह विवरण का द्वार बने, न कि एक dead end।
फ़िल्टर्स सभी पृष्ठों में सुसंगत होने चाहिए और उपयोगकर्ता के नेविगेशन के साथ “stick” करने चाहिए।
सिफारिश किए गए डिफ़ॉल्ट्स:
ऊपर सक्रिय फ़िल्टर चिप्स दिखाएँ ताकि उपयोगकर्ता हमेशा समझें वे क्या देख रहे हैं।
हर मैट्रिक का एक “क्यों” पथ होना चाहिए। एक मजबूत ड्रिल‑डाउन फ्लो:
अगर कोई संख्या प्रमाण से समझाई न जा सके, तो वह प्रश्न उठेगी—खासकर QBRs के दौरान।
प्रत्येक KPI के लिए टूलटिप्स या “info” पैनल जोड़ें: इसे कैसे गणना किया जाता है, बहिष्करण, टाइमज़ोन, और डेटा ताज़गी। उदाहरण शामिल करें जैसे “Maintenance windows excluded” या “Uptime measured at the API gateway.”
फ़िल्टर्ड व्यूज़ को स्थिर URLs के माध्यम से शेयरेबल बनाएं (उदा. /reports/sla?client=acme&service=api&range=30d)। यह आपके केंद्रीकृत SLA डैशबोर्ड को क्लाइंट‑रेडी रिपोर्टिंग पोर्टल बनाता है जो recurring check‑ins और ऑडिट ट्रेल्स का समर्थन करता है।
केंद्रीकृत SLA डैशबोर्ड दिन‑प्रतिदिन उपयोगी है, पर क्लाइंट्स अक्सर ऐसी चीज़ें चाहते हैं जिन्हें वे आंतरिक रूप से फॉरवर्ड कर सकें: नेतृत्व के लिए PDF, विश्लेषकों के लिए CSV, और बुकमार्क करने लायक लिंक।
एक ही underlying SLA परिणाम से तीन आउटपुट सपोर्ट करें:
लिंक‑आधारित रिपोर्ट्स के लिए फ़िल्टर्स स्पष्ट रखें (डेट रेंज, सेवा, गंभीरता) ताकि क्लाइंट जानें कि संख्याएँ किसका प्रतिनिधित्व करती हैं।
प्रत्येक क्लाइंट के लिए शेड्यूलिंग जोड़ें ताकि वे रिपोर्ट्स ऑटोमेटिकली प्राप्त कर सकें—साप्ताहिक, मासिक, त्रैमासिक—क्लाइंट‑विशिष्ट सूची या साझा इनबॉक्स पर। शेड्यूल्स tenant‑scoped और auditable होने चाहिए (किसने बनाया, आख़िरी बार भेजा गया, अगला रन)।
सरल शुरुआत के लिए /reports से “monthly summary” और एक‑क्लिक डाउनलोड के साथ लॉन्च करें।
ऐसे टेम्पलेट बनाएं जो QBR/MBR स्लाइड्स की तरह पढ़ें:
वास्तविक SLAs में अपवाद होते हैं (maintenance windows, थर्ड‑पार्टी आउटेज)। उपयोगकर्ताओं को compliance notes जोड़ने दें और ऐसे अपवादों को approval के लिए फ़्लैग करने का विकल्प दें, साथ में approval trail।
एक्सपोर्ट्स को टेनेंट अलगाव और रोल परमिशन का सम्मान करना चाहिए। किसी उपयोगकर्ता को केवल उन्हीं क्लाइंट्स, सेवाओं, और अवधियों को एक्सपोर्ट करने दें जिन्हें वह देख सकता है—और एक्सपोर्ट पोर्टल व्यू से बिल्कुल मेल खाना चाहिए (कोई छुपा डेटा न लीक हो)।
अलर्ट्स वही जगह हैं जहाँ SLA रिपोर्टिंग वेब ऐप “रोचक डैशबोर्ड” से एक कार्यात्मक उपकरण बनता है। लक्ष्य ज़्यादा संदेश भेजना नहीं है—बल्कि सही लोगों को समय पर प्रतिक्रिया करने, जो हुआ उसे दस्तावेज़ करने, और क्लाइंट्स को सूचित रखने में मदद करना है।
तीन श्रेणियों से शुरू करें:
हर अलर्ट को स्पष्ट परिभाषा (मैट्रिक, टाइम विंडो, थ्रेशोल्ड, क्लाइंट स्कोप) से बाँधें ताकि प्राप्तकर्ता उस पर भरोसा कर सकें।
कई डिलीवरी विकल्प दें ताकि टीमें उन चैनलों में मिलें जहाँ वे पहले से काम करती हैं:
मल्टी‑क्लाइंट रिपोर्टिंग के लिए नोटिफिकेशन को tenant नियमों के अनुसार रूट करें (उदा. “Client A के ब्रीच Channel A पर जाएँ; internal breaches ऑन‑कॉल पर जाएँ”)। साझा चैनलों में क्लाइंट‑विशेष विवरण भेजने से बचें।
अलर्ट थकावट अपनाने को समाप्त कर देगी। लागू करें:
हर अलर्ट में होना चाहिए:
यह एक हल्का‑सा ऑडिट ट्रेल बनाता है जिसे आप क्लाइंट‑रेडी सारों में reuse कर सकते हैं।
प्रति‑क्लाइंट थ्रेशोल्ड्स और रूटिंग के लिए एक बेसिक नियम संपादक प्रदान करें (बिना जटिल क्यूरी लॉजिक दिखाए)। गार्डरिल्स मदद करते हैं: डिफ़ॉल्ट्स, वैलिडेशन, और प्रीव्यू (“यह नियम पिछले महीने 3 बार ट्रिगर होता”)।
केंद्रीकृत SLA रिपोर्टिंग वेब ऐप जल्दी ही मिशन‑क्रिटिकल बन जाता है क्योंकि क्लाइंट्स इसे सेवा गुणवत्ता पर आँकने के लिए उपयोग करते हैं। इसलिए स्पीड, सेफ्टी, और ऑडिट साक्ष्य चार्ट्स जितने ही महत्वपूर्ण हैं।
बड़े क्लाइंट्स लाखों टिकट्स, incidents, और मॉनिटरिंग ईवेंट्स जनरेट कर सकते हैं। पेजेस को प्रतिक्रियाशील रखने के लिए:
कच्चे ईवेंट्स जांच के लिए मूल्यवान हैं, पर सब कुछ हमेशा के लिए रखना लागत और जोखिम बढ़ाता है। स्पष्ट नियम सेट करें:
किसी भी क्लाइंट रिपोर्टिंग पोर्टल के लिए संवेदनशील सामग्री की उम्मीद करें: ग्राहक नाम, टाइमस्टैम्प्स, टिकट नोट्स, और कभी‑कभी PII।
हालांकि आप किसी विशेष मानक को लक्ष्य नहीं बना रहे हों, लेकिन अच्छा ऑपरेशनल साक्ष्य भरोसा बनाता है।
रखें:
SLA रिपोर्टिंग वेब ऐप लॉन्च करना बड़े‑बैन रिलीज़ जैसा नहीं है—यह सटीकता सिद्ध करने और फिर दुहराने योग्य तरीके से स्केल करने के बारे में है। एक मजबूत लॉन्च प्लान विवादों को कम करता है क्योंकि परिणामों को सत्यापित और पुनरुत्पादन करना आसान होता है।
एक ऐसा क्लाइंट चुनें जिसके पास प्रबंधनीय सेवाएँ और डेटा स्रोत हों। अपने ऐप की SLA गणनाओं को उनकी मौजूदा स्प्रेडशीट्स, टिकट एक्सपोर्ट्स, या वेंडर पोर्टल रिपोर्ट्स के साथ समानांतर चलाएँ।
कॉमन mismatch क्षेत्रों पर ध्यान दें:
अंतर दस्तावेज़ करें और तय करें कि ऐप क्लाइंट के मौजूदा दृष्टिकोण का मिलान करे या इसे एक साफ़ मानक से प्रतिस्थापित करे।
हर नए क्लाइंट अनुभव को प्रत्याशित बनाने के लिए एक दोहराने योग्य ऑनबोर्डिंग चेकलिस्ट बनाएं:
यह चेकलिस्ट /pricing पर प्रयास और सपोर्ट चर्चाओं का अनुमान देने में भी मदद करती है।
SLA डैशबोर्ड तब ही भरोसेमंद होते हैं जब वे ताज़ा और पूर्ण हों। मॉनिटरिंग जोड़ें:
पहले आंतरिक अलर्ट भेजें; जब स्थिर हो जाए तो क्लाइंट‑विजिबल स्टेटस नोट्स पेश कर सकते हैं।
फीडबैक इकट्ठा करें कि कहाँ भ्रम होता है: परिभाषाएँ, विवाद (“यह क्यों ब्रीच है?”), और “पिछले महीने से क्या बदला।” छोटे UX सुधार प्राथमिकता दें जैसे टूलटिप्स, चेंज लॉग, और बहिष्करण पर स्पष्ट फुटनोट्स।
यदि आप एक इन‑हाउस MVP जल्दी शिप करना चाहते हैं (tenant मॉडल, इंटीग्रेशन्स, डैशबोर्ड्स, एक्सपोर्ट्स) बिना घंटों बॉइलरप्लेट पर खर्च किए, तो vibe‑coding दृष्टिकोण मदद कर सकता है। उदाहरण के लिए, Koder.ai टीमों को चैट के ज़रिये मल्टी‑टेनेन्ट वेब ऐप का ड्राफ्ट और इटरेट करने देता है—फिर सोर्स कोड एक्सपोर्ट और डिप्लॉय करने की सुविधा देता है। SLA रिपोर्टिंग उत्पादों के लिए यह व्यावहारिक है, जहाँ मुख्य जटिलता डोमेन नियम और डेटा सामान्यीकरण में है न कि UI स्कैफोल्डिंग में।
आप Koder.ai के planning mode का उपयोग करके एंटिटीज़ (tenants, services, SLA definitions, events, rollups) का आउटलाइन बना सकते हैं, फिर React UI और Go/PostgreSQL बैकएंड फ़ाउंडेशन जेनरेट कर सकते हैं जिसे आप अपनी इंटीग्रेशन्स और गणना लॉजिक से विस्तार कर सकें।
एक जीवित डॉक रखें जिसमें अगले कदम हों: नए इंटीग्रेशन्स, एक्सपोर्ट फ़ॉर्मैट्स, और ऑडिट ट्रेल्स। /blog पर संबंधित गाइडों के लिंक दें ताकि क्लाइंट्स और टीम स्वयं‑सेवा कर सकें।
केंद्रीकृत SLA रिपोर्टिंग का लक्ष्य एक ही सत्य का स्रोत बनाना है — अपटाइम, incidents, और टिकट टाइमलाइन को एक ही, ट्रेस करने योग्य व्यू में लाना।
व्यावहारिक रूप से, यह चाहिए कि:
शुरू में छोटे और सामान्यतः पहचानने योग्य सेट से शुरू करें, और तभी बढ़ाएँ जब आप उन्हें समझा और ऑडिट कर सकें।
सामान्य प्रारंभिक मैट्रिक्स:
हर मैट्रिक के लिए लिखें कि यह क्या मापता है, क्या बहिष्कृत है, और किस स्रोत की जरूरत है।
पहले नियम सामान्य भाषा में लिखें, फिर उन्हें लॉजिक में बदलें।
आम तौर पर आपको परिभाषित करना होगा:
अगर दो लोग वाक्यात्मक रूप से सहमत नहीं हैं, तो कोड संस्करण बाद में विवादित होगा।
सभी टाइमस्टैम्प UTC में स्टोर करें, और डिस्प्ले पर टेनेंट के रिपोर्टिंग टाइमज़ोन के अनुसार कन्वर्ट करें।
साथ ही पहले तय करें:
UI में स्पष्ट करें (उदा. “रिपोर्टिंग अवधि कटऑफ़ America/New_York में हैं”)।
ताज़गी बनाम पूर्णता के आधार पर इंटीग्रेशन विधियों का मिश्रण उपयोग करें:
व्यावहारिक नियम: जहाँ फ्रेशनस मायने रखता है वहाँ webhooks, जहाँ पूरी जानकारी चाहिए वहाँ API pulls।
एक छोटा canonical सेट परिभाषित करें ताकि अलग‑अलग टूल एक ही कांसेप्ट में मैप हो जाएँ।
उदाहरण:
incident_opened / incident_closedमल्टी‑टेनेन्ट सिस्टम में मॉडल चुनें और UI से परे अलगाव लागू करें।
मुख्य सुरक्षा उपाय:
tenant_id से स्कोप करेंएक्सपोर्ट्स और बैकग्राउंड जॉब्स की गलत कॉन्टेक्स वजह से डेटा लीक सबसे आसान स्थान होते हैं—इन्हें विशेष ध्यान दें।
तेज़ डैशबोर्ड और ऑडिटबिलिटी दोनों के लिए raw events और derived results दोनों स्टोर करें।
प्रैक्टिकल विभाजन:
जोड़ें ताकि नियम बदलने पर पुराने रिपोर्ट्स पुन:प्रोड्यूस किये जा सकें।
पाइपलाइन को staged और idempotent बनाएं:
विश्वसनीयता के लिए:
SLA रिपोर्टिंग के लिए तीन अलर्ट श्रेणियाँ शामिल करें ताकि सिस्टम केवल डैशबोर्ड न रह कर ऑपरेशनल बने:
शोर कम करने के लिए deduplication, quiet hours, और escalation लागू करें, और हर अलर्ट को acknowledgment और resolution notes के साथ actionable बनाएं।
downtime_starteddowntime_endedticket_created / first_response / resolvedसंगत फ़ील्ड शामिल करें: tenant_id, service_id, source_system, external_id, severity, और UTC timestamps।
calculation_version