30 नव॰ 2025·8 मिनट
किस तरह एक वेब ऐप बनाएं जो क्लाउड लागत और उपयोग आवंटित करे
जानें कि कैसे एक वेब ऐप डिज़ाइन और बनाएं जो क्लाउड बिलिंग डेटा इनजेस्ट करे, उपयोग को टीमों को आवंटित करे, और डैशबोर्ड, बजट और actionable रिपोर्ट्स दे।
जानें कि कैसे एक वेब ऐप डिज़ाइन और बनाएं जो क्लाउड बिलिंग डेटा इनजेस्ट करे, उपयोग को टीमों को आवंटित करे, और डैशबोर्ड, बजट और actionable रिपोर्ट्स दे।
स्क्रीन या पाइपलाइन्स बनाना शुरू करने से पहले यह स्पष्ट करें कि आपकी ऐप किन सवालों का जवाब देगी। “क्लाउड लागत” का मतलब इनवॉइस टोटल, किसी टीम का मासिक खर्च, किसी सर्विस की यूनिट इकॉनॉमिक्स, या किसी ग्राहक-सामना करने वाली फीचर की लागत भी हो सकती है। अगर आप पहले से समस्या परिभाषित नहीं करते, तो आपके पास प्रभावशाली दिखने वाले डैशबोर्ड होंगे जो विवाद सुलझा नहीं पाएँगे।
एक सहायक फ्रेम: आपकी पहली डिलिवरेबल “एक डैशबोर्ड” नहीं है—यह एक साझा सत्य की परिभाषा है (नंबर क्या मतलब रखते हैं, उन्हें कैसे कंम्प्यूट किया जाता है, और कौन उन पर एक्शन लेने के लिए जिम्मेदार है)।
प्राथमिक उपयोगकर्ताओं को नाम देकर और उनके निर्णयों को लिखकर शुरू करें:
विभिन्न उपयोगकर्ता अलग स्तर की डिटेल चाहते हैं। Finance को स्थिर, ऑडिटेबल मासिक नंबर चाहिए; इंजीनियरों को दैनिक ग्रैन्युलैरिटी और ड्रिल-डाउन चाहिए।
स्पष्ट रूप से तय करें कि आप पहले कौन सा परिणाम दे रहे हैं:
स्कोप को तंग रखने का व्यावहारिक तरीका है एक “प्राथमिक परिणाम” चुनना और बाकी को फॉलो-ऑन मानना। अधिकांश टीमें showback और बुनियादी anomaly detection से शुरू करती हैं, फिर chargeback की तरफ जाती हैं।
दिन एक पर किन क्लाउड और बिलिंग एंटिटीज़ का समर्थन करना है उनकी सूची बनाएं: AWS payer accounts, Azure subscriptions और management groups, GCP billing accounts/projects, साथ में साझा सेवाएँ (logging, networking, security)। निर्णय लें कि क्या marketplace charges और थर्ड-पार्टी SaaS शामिल होंगे।
एक लक्षित अपडेट cadence चुनें: दैनिक वित्त और अधिकांश टीमों के लिए पर्याप्त है; near-real-time incident response और तेज़ संगठनों के लिए मददगार है पर जटिलता और लागत बढ़ाती है। साथ ही रिटेंशन सेट करें (उदा., 13–24 महीने) और क्या आपको ऑडिट के लिए immutable “month close” स्नैपशॉट चाहिए।
एक CSV इन्गेस्ट करने या बिलिंग API कॉल करने से पहले तय करें कि आपकी ऐप में “सत्य” कैसे दिखेगा। एक स्पष्ट मेजरमेंट मॉडल बाद में अनंत बहसों को रोकता है (“यह इनवॉइस से क्यों मेल नहीं खा रहा?”) और मल्टी-क्लाउड रिपोर्टिंग को प्रिडिक्टेबल बनाता है।
कम से कम हर बिलिंग लाइन को ऐसे रिकॉर्ड के रूप में मानें जिसमें लगातार माप हों:
एक व्यावहारिक नियम: अगर कोई वैल्यू फाइनेंस के भुगतान को या टीम के चार्ज को बदल सकती है, तो उसे अपना मेट्रिक बनाइए।
आयाम लागतों को एक्सप्लोर करने और आवंटित करने योग्य बनाते हैं। सामान्यतः:
आयामों को लचीला रखें: आप बाद में और जोड़ेंगे (उदा. “cluster”, “namespace”, “vendor”)।
आमतौर पर आपको कई समय अवधारणाएँ चाहिए:
एक सख्त परिभाषा लिखें:
यह परिभाषा आपके डैशबोर्ड, अलर्ट और नंबरों पर भरोसा बनाने को आकार देगी।
बिलिंग ingestion क्लाउड कॉस्ट मैनेजमेंट ऐप की नींव है: अगर कच्चे इनपुट्स अधूरे या पुनरुत्पादित करने में कठिन हैं तो हर डैशबोर्ड और आवंटन नियम विवाद का विषय बन जाएंगे।
हर क्लाउड के “नेेटिव सत्य” का समर्थन करके शुरू करें:
हर कनेक्टर को वही कोर आउटपुट देने के लिए डिज़ाइन करें: कच्ची फाइलों/पंक्तियों का सेट, साथ में एक ingestion log (क्या फेच किया, कब, कितनी रिकॉर्ड्स)।
आम तौर पर आप दो पैटर्न में से चुनेंगे:
कई टीमें हाइब्रिड चलाती हैं: freshness के लिए push और मिस हुई फाइलों के लिए रोज़ाना pull sweeper।
इंगेशन में मूल currency, time zone, और billing period semantics को संरक्षित करना चाहिए। अभी कुछ भी “ठीक” न करें—बस प्रदाता जो कहता है उसे capture करें और प्रदाता के period start/end को स्टोर करें ताकि लेट adjustments सही महीने में जाएँ।
कच्चे एक्सपोर्ट्स को एक immutable, versioned staging bucket/container/dataset में स्टोर करें। इससे ऑडिटयोग्यता बढ़ती है, parsing लॉजिक बदलने पर reprocessing संभव होता है, और विवाद सुलझाने में मदद मिलती है: आप बता सकेंगे कि किस सोर्स फाइल ने कोई संख्या जेनरेट की।
अगर आप AWS CUR, Azure Cost Management exports, और GCP Billing डेटा को जैसे हैं वैसे ही इनजेस्ट कर लेंगे तो ऐप incoherent लगेगा: वही चीज़ एक फाइल में “service” कही जाएगी, दूसरी में “meter” और कहीं “SKU”। नॉर्मलाइज़ेशन वह जगह है जहाँ आप प्रदाता-विशेष शब्दों को एक predictable स्कीमा में बदलते हैं ताकि हर चार्ट, फ़िल्टर और आवंटन नियम वही व्यवहार करें।
प्रदाता फील्ड्स को एक सामान्य सेट में मैप करके शुरू करें जिन पर आप हर जगह भरोसा कर सकें:
ट्रेसबिलिटी के लिए provider-native IDs भी रखें (जैसे AWS ProductCode या GCP SKU ID) ताकि विवाद होने पर मूल रिकॉर्ड तक पहुँच सकें।
नॉर्मलाइज़ेशन सिर्फ कॉलम्स का नाम बदलना नहीं है—यह डेटा हाइजीन है।
खाली या malformed टैग्स को “unknown” और “unallocated” अलग करके हैंडल करें ताकि समस्याएँ छिपें नहीं। retries से double-counting से बचने के लिए एक स्थिर key (source line item ID + date + cost) से deduplicate करें। Partial days पर ध्यान रखें (ख़ासकर “आज” के पास या export delays के दौरान) और उन्हें provisional मार्क करें ताकि डैशबोर्ड अचानक न झूलें।
हर normalized row में lineage metadata होना चाहिए: source file/export, import time, और transformation version (उदा., norm_v3)। जब mapping नियम बदलते हैं, आप फिर से प्रोसेस कर सकें और अंतर समझा सकें।
स्वचालित चेक बनाएं: दिन द्वारा टोटल्स, negative-cost नियम, currency consistency, और “cost by account/subscription/project”। फिर UI में एक import summary प्रकाशित करें: rows ingested, rows rejected, time coverage, और provider totals के मुकाबले डेल्टा। उपयोगकर्ता तब भरोसा करते हैं जब वे केवल अंतिम संख्या नहीं बल्कि यह देख सकें कि क्या हुआ।
लागत डेटा तभी उपयोगी है जब कोई लगातार जवाब दे सके “यह किसका है?” टैगिंग (AWS), labels (GCP), और resource tags (Azure) सबसे सरल तरीका हैं खर्च को टीमों, ऐप्स और पर्यावरणों से जोड़ने का—पर तब तक जब तक आप उन्हें उत्पाद डेटा की तरह ट्रीट करें, न कि बेहतर-कोशिश आदत की तरह।
एक छोटे सेट के आवश्यक keys प्रकाशित करके शुरू करें जिन पर आपका allocation इंजन और डैशबोर्ड निर्भर करेगा:
teamappcost-centerenv (prod/stage/dev)नियम स्पष्ट रखें: किन resources को टैग करना अनिवार्य है, टैग फॉर्मैट कौनसा स्वीकार्य है (उदा. lowercase kebab-case), और missing टैग पर क्या होता है (उदा. “Unassigned” बकेट + अलर्ट)। इस पॉलिसी को ऐप में दिखाते रहें और गहराई से मार्गदर्शन के लिए /blog/tagging-best-practices लिंक रखें।
नीतियों के बावजूद drift होगा: TeamA, team-a, team_a, या किसी टीम का नाम बदलना। एक lightweight “mapping” लेयर जोड़ें ताकि फाइनेंस और प्लेटफ़ॉर्म मालिक canonical values बिना हिस्ट्री rewrite किए normalize कर सकें:
TeamA, team-a → team-a)यह मैपिंग UI उन जगहों में enrichment करने की भी जगह है: अगर app=checkout है पर cost-center गायब है तो आप app registry से उसे infer कर सकते हैं।
कुछ खर्च आसानी से टैग नहीं होंगे:
इन्हें owned “shared services” के रूप में मॉडल करें जिनके लिए स्पष्ट allocation नियम हों (उदा., headcount के अनुसार split, उपयोग मेट्रिक्स के अनुसार, या सापेक्ष खर्च के अनुसार)। लक्ष्य परफेक्ट attribution नहीं है—लक्ष्य सुसंगत ownership है ताकि हर डॉलर का एक घर और एक व्यक्ति हो जो उसे समझा सके।
एक आवंटन इंजन normalized billing lines को "यह लागत किसकी है और क्यों" में बदलता है। लक्ष्य सिर्फ गणित नहीं है—यह ऐसे परिणाम देना है जिन्हें हितधारक समझ सकें, चुनौती दे सकें, और बेहतर बना सकें।
अधिकांश टीमों को मिश्रित तरीके चाहिए क्योंकि सभी लागतों में साफ ownership नहीं रहती:
आवंटन को ordered rules के रूप में मॉडल करें जिनमें priority और effective dates हों। इससे आप उत्तर दे सकेंगे: “10 मार्च को कौन सा नियम लागू हुआ था?” और इतिहास rewrite किए बिना नीति अपडेट कर सकेंगे।
एक व्यावहारिक rule schema में अक्सर शामिल होते हैं:
शेयरड कॉस्ट—Kubernetes clusters, networking, data platforms—अक्सर किसी एक टीम से सीधे मेल नहीं खाते। इन्हें पहले “pools” के रूप में मानें, फिर बांटें।
उदाहरण:
Before/after views दें: मूल vendor line items बनाम owner द्वारा आवंटित परिणाम। हर allocated row के लिए एक “explanation” स्टोर करें (rule ID, match fields, driver values, split percentages)। यह ऑडिट ट्रेल विवादों को घटाता है और खासकर chargeback/showback के दौरान भरोसा बनाता है।
क्लाउड बिलिंग एक्सपोर्ट्स जल्दी बड़ा हो जाते हैं: प्रति रिसोर्स, प्रति घंटे, कई अकाउंट्स और प्रदाताओं में लाइन आइटम्स। अगर आपकी ऐप धीमी लगेगी, उपयोगकर्ता भरोसा खो देंगे—इसलिए स्टोरेज डिज़ाइन ही प्रोडक्ट डिज़ाइन है।
एक सामान्य सेटअप सत्य के लिए रिलेशनल वेयरहाउस और analytics के लिए OLAP-शैली के व्यूज़/मैटेरियलाईजेशन है (छोटे deployments के लिए Postgres; जब वॉल्यूम बढ़े तो BigQuery या Snowflake)।
कच्चे बिलिंग लाइन आइटम्स को बिल्कुल वैसे ही स्टोर करें जैसे मिले (साथ में ingestion fields जैसे import time और source file)। फिर अपनी ऐप के लिए curated तालिकाएँ बनाएं। इससे "हमें क्या मिला" और "हम कैसे रिपोर्ट करते हैं" अलग रहते हैं, जो ऑडिट और reprocessing को सुरक्षित बनाता है।
अगर आप इसे scratch से बना रहे हैं तो पहले iteration को तेज़ करने के लिए किसी प्लेटफ़ॉर्म का उपयोग विचार करें। उदाहरण के लिए, Koder.ai (एक vibe-coding प्लेटफ़ॉर्म) चैट के जरिए एक काम करने वाला वेब ऐप जनरेट करने में मदद कर सकता है—आम तौर पर React frontend, Go backend, और PostgreSQL—ताकि आप डेटा मॉडल और आवंटन लॉजिक (भरोसा बनाने वाले हिस्से) पर अधिक समय खर्च कर सकें बजाय बॉयलरप्लेट को फिर से बनाने के।
ज़्यादातर क्वेरीज समय और बॉउंड्री (cloud account/subscription/project) से फ़िल्टर करती हैं। उसी के अनुसार partition और cluster/index करें:
इससे “Team A के पिछले 30 दिन” जैसे प्रश्न तेज़ रहेंगे भले ही इतिहास बहुत बड़ा हो।
डैशबोर्ड्स को कच्चे लाइन आइटम्स स्कैन नहीं करने चाहिए। उपयोगकर्ताओं के अन्वेषण के ग्रेनों पर aggregated तालिकाएँ बनाएं:
इन तालिकाओं को शेड्यूल पर (या क्रमिक रूप से) मैटेरियलाइज़ करें ताकि चार्ट सेकंड्स में लोड हों।
Allocation नियम, टैगिंग मैपिंग्स, और मालिकाना परिभाषाएँ बदलेंगी। हिस्ट्री recompute करने के लिए डिजाइन करें:
यह लचीलापन ही एक लागत डैशबोर्ड को भरोसेमंद सिस्टम बनाता है।
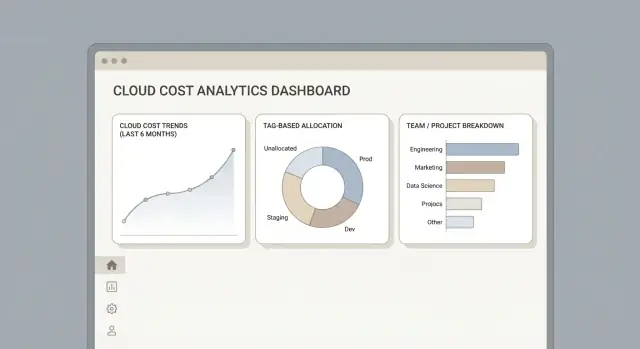
एक(cost allocation) ऐप तब सफल होता है जब लोग सामान्य सवालों के उत्तर सेकंड्स में पा सकें: “खर्च क्यों बढ़ा?”, “यह लागत किसकी है?”, और “हम इसके बारे में क्या कर सकते हैं?” आपका UI totals से details तक एक स्पष्ट कहानी बताना चाहिए, बिना उपयोगकर्ताओं को बिलिंग jargon समझने के लिए मजबूर किए।
एक छोटे, predictable view सेट के साथ शुरू करें:
हर जगह एक ही filter bar उपयोग करें: date range, cloud, team, project, और environment (prod/stage/dev)। फ़िल्टर व्यवहार को सुसंगत रखें (एक ही defaults, एक ही “applies to all charts”), और सक्रिय फ़िल्टर दिखाएँ ताकि स्क्रीनशॉट और साझा लिंक self-explanatory हों।
एक इरादतन पथ डिज़ाइन करें:
Invoice total → allocated total → service/category → account/project → SKU/line items.
हर चरण पर नंबर के पास “क्यों” दिखाएँ: लागू आवंटन नियम, उपयोग किए गए टैग्स, और किसी भी मान्यताओं को। जब उपयोगकर्ता एक लाइन आइटम पर आएँ, तो त्वरित क्रियाएँ दें जैसे “view owner mapping” (लिंक /settings/ownership) या “report missing tags” (लिंक /governance/tagging)।
हर तालिका से CSV exports जोड़ें, और साथ में shareable links जो फ़िल्टर को संरक्षित रखें। लिंक को रिपोर्ट की तरह ट्रीट करें: वे role-based access का पालन करें, एक audit trail शामिल करें, और वैकल्पिक रूप से expire हों। यह सहयोग आसान बनाता है जबकि संवेदनशील खर्च डेटा नियंत्रित रहता है।
डैशबोर्ड बताते हैं क्या हुआ। बजट और अलर्ट बताते हैं आगे क्या होगा।
अगर आपकी ऐप किसी टीम को नहीं बता सकती “आप अपना मासिक बजट पार करने वाले हैं” (और सही व्यक्ति को notify करे), तो यह केवल रिपोर्टिंग टूल ही रहेगी—न कि ऑपरेशनल टूल।
उसी स्तर पर बजट से शुरू करें जिस पर आप लागत आवंटित करते हैं: टीम, प्रोजेक्ट, environment, या product. हर बजट में होना चाहिए:
UI को सरल रखें: amount + scope + owner सेट करने के लिए एक स्क्रीन, और “परीक्षण” के लिए “इस स्कोप में पिछले महीने का खर्च” का प्रीव्यू।
बजट धीमे drift पकड़ते हैं, पर टीम्स को तुरंत संकेत भी चाहिए:
अलर्ट्स को actionable बनाएं: शीर्ष ड्राइवर (service, region, project), एक संक्षिप्त व्याख्या, और explorer view का लिंक (उदा., /costs?scope=team-a&window=7d)।
मशीन लर्निंग से पहले सहज और debug करने योग्य बेसलाइन तुलना लागू करें:
यह छोटे खर्च कैटेगरी पर शोर वाले अलर्ट्स से बचाता है।
हर अलर्ट इवेंट को स्टेटस के साथ स्टोर करें: acknowledged, muted, false positive, fixed, या expected। रिकॉर्ड करें किसने कार्रवाई की और कितना समय लगा।
समय के साथ इस इतिहास का उपयोग शोर घटाने के लिए करें: repeat alerts auto-suppress करें, स्कोप के अनुसार थ्रेशोल्ड्स सुधारें, और उन टीमों की पहचान करें जो हमेशा untagged रहती हैं—उनके लिए workflow सुधार ज़रूरी है न कि और नोटिफिकेशन।
लागत डेटा संवेदनशील होता है: यह विक्रेता की कीमतें, आंतरिक प्रोजेक्ट और ग्राहक प्रतिबद्धताएँ भी दिखा सकता है। अपने कॉस्ट ऐप को वित्तीय प्रणाली की तरह ट्रीट करें—क्योंकि कई टीमों के लिए यह वाकई में वैसा ही है।
एक छोटे सेट ऑफ रोल्स से शुरू करें और उन्हें समझने में आसान रखें:
इनको API स्तर पर लागू करें (सिर्फ UI पर नहीं), और resource-level scoping जोड़ें (उदा., एक टीम लीड दूसरी टीम के प्रोजेक्ट्स नहीं देख सके)।
क्लाउड बिलिंग एक्सपोर्ट्स और उपयोग APIs क्रिडेंशियल्स मांगते हैं। सीक्रेट्स को विशेष secret manager में रखें (या KMS से encrypted at rest), डेटाबेस फ़ील्ड्स में plain न रखें। सुरक्षित rotation सपोर्ट करने के लिए एकाधिक सक्रिय क्रेडेंशियल्स प्रति कनेक्टर की अनुमति दें जिनके साथ एक “effective date” हो, ताकि key swaps के दौरान ingestion न टूटे।
व्यावहारिक UI विवरण मदद करते हैं: last successful sync time दिखाएँ, permission scope warnings, और स्पष्ट “re-authenticate” फ्लो।
Append-only audit logs जोड़ेंสำหรับ:
लॉग्स searchable और exportable (CSV/JSON) हों और प्रत्येक लॉग एंट्री को प्रभावित ऑब्जेक्ट से लिंक करें।
UI में रिटेंशन और प्राइवेसी सेटिंग्स डॉक्यूमेंट करें: कच्ची बिलिंग फ़ाइलें कितनी देर तक रखी जाती हैं, कब aggregated tables कच्चे डेटा की जगह लेते हैं, और कौन डेटा हटा सकता है। एक सरल “Data Handling” पेज (उदा., /settings/data-handling) सपोर्ट टिकट कम करता है और फाइनेंस तथा सुरक्षा टीमों के साथ भरोसा बनाता है।
एक कॉस्ट आवंटन ऐप तभी व्यवहार बदलता है जब यह उन जगहों पर दिखाई दे जहां लोग पहले से काम करते हैं। इंटीग्रेशन रिपोर्टिंग ओवरहेड घटाते हैं और कॉस्ट डेटा को साझा, ऑपरेशनल संदर्भ में बदल देते हैं—फाइनेंस, इंजीनियरिंग, और नेतृत्व सभी एक ही नंबर देखते हैं।
नोटिफिकेशंस से शुरू करें क्योंकि वे तुरंत कार्रवाई प्रेरित करते हैं। संक्षिप्त संदेश भेजें जिनमें owner, service, delta, और ऐप के उसी दृश्य का लिंक हो (फिल्टर्ड टीम/प्रोजेक्ट और टाइम विंडो)।
आम अलर्ट्स:
अगर एक्सेस मुश्किल होगा तो लोग अपनाएंगे नहीं। SAML/OIDC SSO सपोर्ट करें और identity groups को cost “owners” (teams, cost centers) से मैप करें। यह offboarding आसान बनाता है और अनुमतियों को org परिवर्तनों के अनुरूप रखता है।
एक स्थिर API प्रदान करें ताकि आंतरिक सिस्टम "team/project द्वारा लागत" बिना स्क्रीन-स्क्रैपिंग के प्राप्त कर सकें।
एक व्यावहारिक आकार:
GET /api/v1/costs?team=payments\u0026start=2025-12-01\u0026end=2025-12-31\u0026granularity=dayrate limits, caching headers, और idempotent query semantics का डॉक्यूमेंटेशन दें ताकि उपभोक्ता भरोसेमंद पाइपलाइनों का निर्माण कर सकें।
Webhooks आपकी ऐप को प्रतिक्रियाशील बनाते हैं। ऐसे इवेंट्स फ़ायर करें: budget.exceeded, import.failed, anomaly.detected, और tags.missing ताकि अन्य सिस्टम वर्कफ़्लोज़ शुरू कर सकें।
सामान्य गंतव्य: Jira/ServiceNow टिकट निर्माण, incident tools, या कस्टम runbooks।
कई टीमें अपनी रिपोर्ट्स पर अड़े रहते हैं। एक गवर्न्ड एक्सपोर्ट (या एक read-only वेयरहाउस स्कीमा) ऑफ़र करें ताकि BI रिपोर्ट्स वही आवंटन लॉजिक उपयोग करें—Formulas को दोबारा implement करने के बजाय।
यदि आप इंटीग्रेशंस को add-ons के रूप में पैकेज करते हैं, तो उपयोगकर्ताओं को /pricing लिंक से प्लान विवरण दें।
एक कॉस्ट आवंटन ऐप तभी काम करता है जब लोग उस पर विश्वास करते हैं। वह भरोसा दोहराव योग्य टेस्टिंग, दिखाई देने वाले डेटा क्वालिटी चेक, और एक रोलआउट से आता है जो टीमों को आपके नंबरों की तुलना उनके पहले के स्रोतों से करने देता है।
प्रदाता एक्सपोर्ट्स और इनवॉइसेस का एक छोटा लाइब्रेरी बनाकर शुरू करें जो सामान्य edge cases दर्शाते हों: credits, refunds, taxes/VAT, reseller fees, free tiers, committed-use discounts, और support charges। इन सैंपलों के वर्ज़न रखें ताकि parser या allocation लॉजिक बदलने पर आप टेस्ट फिर से चला सकें।
पार्सिंग पर ही नहीं बल्कि आउटपुट पर फोकस करें:
स्वचालित चेक जोड़ें जो आपके गणितीय टोटल्स को प्रदाता-रिपोर्टेड टोटल्स के साथ सहिष्णुता के भीतर reconcile करें (उदा., rounding या timing differences के कारण)। इन चेक्स का ट्रैक रखें ताकि आप बता सकें, “यह drift कब शुरू हुआ?”
सहायक assertions:
इंगेशन फेल्योर, stalled pipelines, और “data not updated since” थ्रेशोल्ड्स के लिए अलर्ट सेट करें। धीमी क्वेरीज और डैशबोर्ड लोड समय मॉनिटर करें, और भारी स्कैन करने वाली रिपोर्ट्स को लॉग करें ताकि आप सही तालिकाओं को ऑप्टिमाइज़ कर सकें।
पहले कुछ टीमों के साथ पायलट चलाएँ। उन्हें उनके मौजूदा स्प्रेडशीट्स के खिलाफ तुलना view दें, परिभाषाओं पर सहमति बनाएं, फिर छोटे प्रशिक्षण और स्पष्ट फीडबैक चैनल के साथ व्यापक रोलआउट करें। एक चेंज लॉग प्रकाशित करें (भले ही सरल /blog/changelog) ताकि हितधारक देखें कि क्या बदला और क्यों।
अगर आप पायलट के दौरान प्रोडक्ट आवश्यकताओं पर तेजी से iterate कर रहे हैं, तो Koder.ai जैसे उपकरण UI flows (filters, drill-down paths, allocation rule editors) को प्रोटोटाइप करने में उपयोगी हो सकते हैं और परिभाषाएँ बदलने पर काम करने वाले वर्ज़न regenerate कर सकते हैं—जबकि आप अभी भी स्रोत कोड एक्सपोर्ट, डेप्लॉयमेंट, और रोलबैक पर नियंत्रण रखें।
पहले यह परिभाषित करें कि ऐप को किन निर्णयों का समर्थन करना है (वैरियंस की व्याख्या, वेस्ट घटाना, बजट की जवाबदेही, पूर्वानुमान)। फिर प्राथमिक उपयोगकर्ताओं पर सहमति बनाएँ (Finance/FinOps, Engineering, टीम लीड, एग्जीक्यूटिव) और सबसे पहले किन आउटपुट्स को देना है उसे तय करें: showback, chargeback, forecasting, या budget control.
डैशबोर्ड बनाने से पहले यह न लिखें कि “अच्छा” क्या है और आप प्रदाता के इनवॉइस से कैसे सामंजस्य करेंगे, तो बाद में समस्याएँ बढ़ेंगी।
Showback सिर्फ दृश्यता देता है (कौन कितना खर्च कर रहा है) बिना आंतरिक बिल जारी किए। Chargeback उन आवंटनों को आंतरिक बिलिंग में बदल देता है जो बजट पर प्रभाव डालते हैं और अक्सर अप्रूवल एवं ऑडिट ट्रेल की मांग करते हैं।
अगर आपको मजबूत जवाबदेही चाहिए तो शुरुआत में ही chargeback के लिए डिजाइन करें (immutable month-close स्नैपशॉट, explainable नियम, औपचारिक एक्सपोर्ट), भले ही लॉन्च showback UI के साथ हो।
हर प्रदाता की लाइन-आइटम को एक रिकॉर्ड की तरह मॉडल करें जिसमें ये मेट्रिक्स हों:
एक व्यावहारिक नियम: यदि कोई वैल्यू यह बदल सकती है कि फाइनेंस कितना भुगतान करता है या किसी टीम को कितना चार्ज होता है, तो उसे प्राथमिक मेट्रिक मानें।
उन आयामों के साथ शुरू करें जिन्हें उपयोगकर्ता अक्सर “group by” करते हैं:
आयामों को फ्लेक्सिबल रखें ताकि बाद में cluster/namespace/vendor जोड़ने पर रिपोर्ट टूटें नहीं।
विभिन्न वर्कफ़्लो अलग क्लॉक्स पर निर्भर करते हैं—इसलिए कई टाइम कीज़ कैप्चर करें:
साथ ही प्रदाता का मूल टाइमज़ोन और बिलिंग बॉउंड्रीज़ स्टोर करें ताकि लेट adjustments सही महीने में जाएँ।
Near-real-time इन्गेस्टशन incident response और तेज़ ऑर्ग्स के लिए मददगार है, पर यह जटिलता (deduplication, partial-day हैंडलिंग) और लागत बढ़ाता है.
डेली अपडेट्स ज्यादातर फाइनेंस और टीम्स के लिए काफी होते हैं। एक सामान्य हाइब्रिड पैटर्न है: freshness के लिए event-driven ingestion और मिस हुए फाइलों के लिए रोज़ाना एक sweeper job।
कच्चे प्रदाता एक्सपोर्ट्स को एक immutable, versioned staging area में रखें (S3/Blob/BigQuery आदि) और एक ingestion log स्टोर करें (क्या लिया गया, कब, रिकॉर्ड काउंट).
इससे parser बदलने पर reprocess करना, ऑडिट और विवाद सुलझाना आसान होता है—आप सटीक सोर्स फाइल दिखा सकते हैं जिसने संख्या जनरेट की थी।
प्रदाता-विशेष कॉन्सेप्ट्स को एक यूनिफाइड स्कीमा (जैसे: Service, SKU, Usage Type) में मानकीकृत करें, और ट्रेसबिलिटी के लिए provider-native IDs भी रखें.
फिर ये डेटा सफाई कदम अपनाएँ:
इससे multi-cloud चार्ट और allocation नियम प्रेडिक्टेबल बनते हैं।
एक छोटा सेट आवश्यक keys परिभाषित करें (उदा. team, app, cost-center, env) जिनपर आपका allocation इंजन और डैशबोर्ड भरोसा करेगा। टैग फॉर्मैट (उदा. lowercase kebab-case) और missing टैग्स का क्या नतीजा होगा (उदा. “Unassigned” बकेट + अलर्ट) स्पष्ट करें। नीति को ऐप में दिखाएँ और गाइडेंस के लिए /blog/tagging-best-practices लिंक दें।
इसके साथ ही एक mapping UI दें जो वास्तविक दुनिया की गड़बड़ी संभाले (उदा. , → canonical ), समय-सीमित मैपिंग सपोर्ट करें और audit notes रखें।
आवंटन को ordered rules की तरह मॉडल करें जिनमें priority और effective dates हों। आवश्यक तरीके:
Explainability के लिए हर allocated row में “why” स्टोर करें (rule ID, match fields, driver values, split %) और vendor line items बनाम allocated परिणामों के before/after views दें—यह विवाद घटाता है।
TeamAteam-ateam-a