06 मई 2025·8 मिनट
कैशिंग, सेशन और तेज़ लुकअप के लिए कुंजी-मूल्य स्टोर्स
जानें कि कैसे कुंजी-मूल्य स्टोर्स कैशिंग, उपयोगकर्ता सेशन्स और त्वरित लुकअप को सक्षम करते हैं—साथ ही TTL, एविक्शन, स्केलिंग विकल्प और व्यावहारिक ट्रेड-ऑफ जिन पर ध्यान देना चाहिए।
क्यों कुंजी-मूल्य स्टोर्स गति के लिए उपयोग किए जाते हैं
एक कुंजी-मूल्य स्टोर का मुख्य लक्ष्य सरल है: एंड-यूज़र पर लेटेंसी घटाना और आपके प्राथमिक डेटाबेस पर लोड कम करना। बार-बार वही महंगी क्वेरी चलाने या वही रिज़ल्ट फिर से कम्प्यूट करने के बजाय, आपकी ऐप पहले से कम्प्यूट किया हुआ मान एक ही, पूर्वानुमेय स्टेप में पढ़ सकती है।
तेज़ इसलिए कि एक्सेस पाथ सरल है
कुंजी-मूल्य स्टोर एक ऑपरेशन के इर्द-गिर्द ऑप्टिमाइज़ किए जाते हैं: “यह कुंजी दीजिए, मान लौटाइए।” यह संकुचित फोकस बहुत छोटा क्रिटिकल पाथ बनाता है।
कई सिस्टम में, एक लुकअप अक्सर निम्न चीज़ों से संभाला जा सकता है:
- एक इन-मेमोरी इंडेक्स (ताकि डिस्क सीक न हो)
- कुंजी → लोकेशन के लिए डायरेक्ट हैशिंग (ताकि खोज कम हो)
- सामान्य-उद्देश्य डेटाबेस क्वेरी इंजन की तुलना में कम CPU-भारी फीचर्स
परिणाम है कम और सुसंगत रिस्पॉन्स टाइम—जो कि कैशिंग, सेशन स्टोरेज और अन्य हाई-स्पीड लुकअप के लिए चाहिए।
तेज़ इसलिए कि यह अन्य जगहों पर काम बचाता है
भले ही आपका डेटाबेस अच्छी तरह ट्यून हो, उसे फिर भी क्वेरी पार्स करनी पड़ती है, प्लान बनाना पड़ता है, इंडेक्स पढ़ने पड़ते हैं और कन्करेंसी समन्वय करना पड़ता है। अगर हजारों रिक्वेस्ट एक ही “टॉप प्रोडक्ट्स” लिस्ट मांगती हैं, तो वह दोहरावदार काम बड़ा हो जाता है।
एक की-वैल्यू कैश वह दोहरावदार रीड ट्रैफ़िक डेटाबेस से हटाकर आपके डेटाबेस को उन रिक्वेस्ट्स पर अधिक समय बिताने देता है जिन्हें सचमुच उसकी ज़रूरत है: राइट्स, जटिल जॉइन, रिपोर्टिंग और कंसिस्टेंसी-क्रिटिकल रीड्स।
हर वर्कलोड फिट नहीं बैठता
गति मुफ़्त नहीं आती। की-वैल्यू स्टोर्स आमतौर पर समृद्ध क्वेरीइंग (फिल्टर्स, जॉइन्स) त्याग देते हैं और कॉन्फ़िगरेशन के आधार पर परसिस्टेंस और कंसिस्टेंसी के अलग गारंटीज़ दे सकते हैं।
ये तब चमकते हैं जब आप डेटा को स्पष्ट कुंजी से नाम दे सकते हैं (उदा. user:123, cart:abc) और तेज़ रिट्रीवल चाहते हैं। यदि आप अक्सर “X जहां सभी आइटम ढूंढो” जैसी क्वेरीज करते हैं, तो रिलेशनल या डॉक्युमेंट DB प्राथमिक स्टोर के रूप में बेहतर होगा।
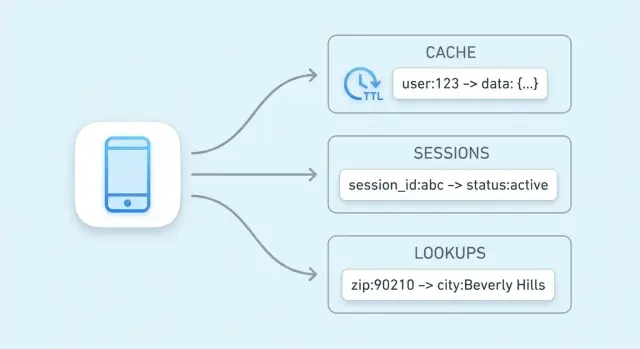
कुंजी-मूल्य के मूल तत्व: कुंजियाँ, मान और लुकअप
कुंजी-मूल्य स्टोर सबसे साधारण प्रकार का डेटाबेस है: आप एक मान (कुछ डेटा) को एक अद्वितीय कुंजी (लेबल) के तहत संग्रहित करते हैं, और बाद में कुंजी देकर मान वापस लेते हैं।
“कुंजी” और “मान” असल में क्या होते हैं
कुंजी को ऐसे सोचें जैसे आप उसे ठीक-ठीक दोहरा सकें, और मान वह चीज़ है जो आप वापस चाहते हैं।
- कोट-चेक: आपका टिकट नंबर कुंजी है; आपका कोट मान है।
- कॉन्टैक्ट्स ऐप: “Alice Chen” (या एक संपर्क ID) कुंजी है; फ़ोन नंबर और विवरण मान है।
- सेशन्स: एक रैंडम सेशन टोकन कुंजी है; यूज़र ID और लॉगिन स्थिति मान है।
कुंजियाँ आमतौर पर छोटी स्ट्रिंग्स होती हैं (जैसे user:1234 या session:9f2a...). मान छोटे (एक काउंटर) या बड़े (एक JSON ब्लॉब) हो सकते हैं।
कैसे कॉन्स्टेंट-टाइम लुकअप काम करते हैं (उच्च स्तर)
की-वैल्यू स्टोर्स “मुझे इस कुंजी के लिए मान दीजिए” क्वेरीज के लिए बनाए जाते हैं। आंतरिक रूप से, कई सिस्टम एक हैश टेबल जैसी संरचना उपयोग करते हैं: कुंजी को एक लोकेशन में ट्रांसफॉर्म किया जाता है जहाँ मान जल्दी मिल सके।
इसीलिए आप अक्सर सुनेंगे कॉन्स्टेंट-टाइम लुकअप (अक्सर O(1) लिखा जाता है): प्रदर्शन इस बात पर अधिक निर्भर करता है कि आप कितनी रिक्वेस्ट्स कर रहे हैं बनिस्बत कुल रिकॉर्ड्स की संख्या के। यह जादू नहीं है—कोलिज़न और मेमोरी सीमाएँ अभी भी matter करती हैं—पर सामान्य कैश/सेशन उपयोग के लिए यह बहुत तेज़ है।
सामान्य परिनियोजन: इन-मेमोरी, ऑन-डिस्क, या हाइब्रिड
- इन-मेमोरी: सबसे तेज़ रीड/राइट; रीस्टार्ट पर डेटा खो सकता है जब तक परसिस्ट न हो।
- ऑन-डिस्क: RAM से धीमा पर अधिक डेटा रखता है और रीस्टार्ट पर टिकता है।
- हाइब्रिड: हॉट डेटा को मेमोरी में रखता है और रिकवरी के लिए डिस्क पर लिखता है।
“हॉट डेटा” क्या है (और क्यों मायने रखता है)
हॉट डेटा वह छोटा हिस्सा है जो बार-बार पूछा जाता है (लोकप्रिय प्रोडक्ट पेज, सक्रिय सत्र, रेट-लिमिट काउंटर)। हॉट डेटा को की-वैल्यू स्टोर—खासकर मेमोरी में—रखने से धीमी DB क्वेरीज से बचा जा सकता है और लोड के दौरान रिस्पॉन्स टाइम पूर्वानुमेय रहते हैं।
कैशिंग 101: क्या और क्यों कैश करें
कैशिंग का मतलब है अक्सर ज़रूरी डेटा की एक कॉपी कहीं तेज़ स्थान पर रखना। की-वैल्यू स्टोर इसे करने के लिए सामान्य जगह है क्योंकि वह एक ही कुंजी-लुकअप में मान वापस कर सकता है, अक्सर कुछ मिलीसेकंड में।
कब कैशिंग सबसे मदद करती है
कैशिंग तब सबसे अच्छी होती है जब वही प्रश्न बार-बार पूछे जाते हैं: लोकप्रिय पेज, दोहराए गए सर्च, सामान्य API कॉल्स, या महंगी कैलकुलेशंस। यह उपयोगी है जब “असली” स्रोत धीमा या रेट-लिमिटेड हो—जैसे भारी लोड वाला प्राथमिक DB या प्रति-रिक्वेस्ट भुगतान करने वाला तीसरा-पक्ष API।
क्या कैश करें (व्यावहारिक उदाहरण)
अच्छे उम्मीदवार वे हैं जिन्हें बार-बार पढ़ा जाता है और जो बिल्कुल-तुरंत-अप-टू-डेट होने की आवश्यकता नहीं रखते:
- उपयोगकर्ता प्रोफ़ाइल सारांश (नाम, अवतार URL, प्राथमिकताएँ)
- उत्पाद सूचियाँ और कैटेगरी पेज
- कम्प्यूटेड परिणाम (सिफारिशें, टोटल्स, रिपोर्ट स्निपेट)
- हर रिक्वेस्ट पर पढ़ी जाने वाली कॉन्फ़िग और फीचर फ़्लैग्स
- बाहरी API प्रतिक्रियाएँ जिन्हें कुछ समय के लिए दोहराया जा सकता है
एक सरल नियम: ऐसे आउटपुट कैश करें जिन्हें आप जरूरत पड़ने पर पुनः जेनरेट कर सकते हैं। लगातार बदलने वाले या हर रीड पर कंसिस्टेंसी-क्रिटिकल डेटा (उदा. बैंक बैलेंस) को कैश करने से बचें।
कैशिंग कैसे डेटाबेस और APIs पर दबाव घटाती है
बिना कैशिंग के, हर पेज व्यू कई DB क्वेरीज या API कॉल्स ट्रिगर कर सकता है। कैश के साथ, एप्लिकेशन कई रिक्वेस्ट्स को की-वैल्यू स्टोर से सर्व कर सकती है और केवल कैश मिस पर प्राथमिक DB या API को फ़ॉलबैक करती है। इससे क्वेरी वॉल्यूम घटता है, कनेक्शन contention कम होती है, और ट्रैफ़िक स्पाइक्स के दौरान विश्वसनीयता बढ़ सकती है।
जोखिम: स्टेल डेटा और असंगत रीड्स
कैशिंग ताज़गी के बदले गति देती है। यदि कैश किए गए मान जल्दी अपडेट नहीं होते, तो यूज़र्स को स्टेल जानकारी दिख सकती है। वितरित सिस्टम्स में, दो रिक्वेस्ट्स अस्थायी रूप से एक ही डेटा के अलग-अलग वर्ज़न पढ़ सकते हैं।
आप इन जोखिमों को उपयुक्त TTL चुनकर, यह तय कर के कि कौन सा डेटा “थोड़ा पुराना” हो सकता है, और ऐप को डिज़ाइन करके ताकि कभी-कभी कैश मिस या रिफ्रेश डिले सहन कर सके, मैनेज करते हैं।
सामान्य कैश पैटर्न और कब किसे उपयोग करें
कैश “पैटर्न” एक रिपीटेबल वर्कफ़्लो है कि जब आपकी ऐप कैश शामिल करती है तो पढ़ना और लिखना कैसे होता है। सही पैटर्न चुनना टूल (Redis, Memcached आदि) से कम और इस बात पर अधिक निर्भर करता है कि मूल डेटा कितनी बार बदलता है और आप कितनी स्टेलनेस सहन कर सकते हैं।
Cache-aside (लेज़ी लोडिंग)
Cache-aside में आपकी ऐप कैश को स्पष्ट रूप से नियंत्रित करती है:
- कुंजी से कैश पढ़ें।
- यदि मिस है, तो DB/सोर्स ऑफ़ ट्रुथ से पढ़ें।
- परिणाम को TTL के साथ कैश में डालें।
- परिणाम लौटाएँ।
बेस्ट फिट: ऐसा डेटा जो अक्सर पढ़ा जाता है पर दुर्लभ रूप से बदलता है (उदा. प्रोडक्ट पेज, पब्लिक प्रोफाइल)। यह एक अच्छा डिफ़ॉल्ट है क्योंकि फेल्यर graceful हैं: अगर कैश खाली हो, तो आप अभी भी DB से पढ़ सकते हैं।
Read-through बनाम write-through
Read-through का मतलब है कि कैश लेयर मिस पर DB से लोड कर लेता है (आपकी ऐप “कैश से” पढ़ती है और कैश को लोडर इंटीग्रेशन चाहिए)। यह कोड को सरल बनाता है पर कैश-टियर में जटिलता जोड़ता है।
Write-through का मतलब है कि हर राइट सिंक्रोनसली कैश और डेटाबेस दोनों में जाता है। रीड्स तेज़ और ज़्यादातर कंसिस्टेंट होते हैं, पर राइट्स धीमे हैं क्योंकि दो ऑपरेशंस पूरी करनी पड़ती हैं।
बेस्ट फिट: जहां आप कम मिस और सरल रीड कंसिस्टेंसी चाहते हैं (उदा. उपयोगकर्ता सेटिंग्स, फीचर फ्लैग्स) और राइट लेटेसी स्वीकार्य हो।
Write-back / write-behind
Write-back में आपकी ऐप पहले कैश में लिखती है, और कैश बाद में (अक्सर बैच में) DB पर फ्लश करता है।
लाभ: बहुत तेज़ राइट्स और घटा हुआ DB लोड।
जोखिम: अगर कैश नोड फ्लॉप हो जाए और उसने फ्लश नहीं किया तो डेटा खो सकता है। इसे केवल तब उपयोग करें जब आप डेटा हानि सहन कर सकते हों या मजबूत ड्यूरेबिलिटी मैकेनिज़्म हों।
बदलाव की आवृत्ति के आधार पर कैसे चुनें
यदि डेटा दुर्लभ रूप से बदलता है, तो cache-aside और सेंसिबल TTL अक्सर पर्याप्त है। यदि डेटा अक्सर बदलता है और स्टेल रीड्स दर्दनाक हैं, तो write-through (या बहुत छोटे TTL + स्पष्ट इनवैलिडेशन) पर विचार करें। यदि राइट वॉल्यूम अत्यधिक है और कभी-कभार हानि स्वीकार्य है, तो write-behind लाभदायक हो सकता है।
ताज़गी नियंत्रण: TTL, एक्सपायर और इनवैलिडेशन
कैश किए गए डेटा को “काफ़ी ताज़ा” रखना ज़्यादातर प्रत्येक कुंजी के लिए उपयुक्त एक्सपायरी रणनीति चुनने के बारे में है। लक्ष्य परफेक्ट सटीकता नहीं है—बल्कि स्टेल परिणामों से आश्चर्य न हो और फिर भी कैशिंग के स्पीड लाभ मिलें।
TTL और एक्सपायर: क्या करते हैं और कैसे चुनें
TTL किसी कुंजी पर ऑटोमैटिक एक्सपायर सेट करता है। छोटे TTL स्टेलनेस घटाते हैं पर कैश मिस और बैकएंड लोड बढ़ते हैं। लंबे TTL हिट रेट बढ़ाते हैं पर पुराने मान परोसने का जोखिम बढ़ाते हैं।
एक व्यावहारिक तरीका:
- मूल डेटा परिवर्तन आवृत्ति के साथ मैच करें। कीमतें मिनटों में, यूज़र प्रोफ़ाइल घंटे में हो सकती है।
- बिजनेस प्रभाव पर विचार करें। “लाइक” काउंट पुराना होना आमतौर पर ठीक है; “खाता बैलेंस” नहीं।
- छोटी अनियमितता (jitter) जोड़ें। यदि कई कुंजियाँ एक ही TTL साझा करती हैं, तो वे एक साथ एक्सपायर होकर स्पाइक्स पैदा कर सकती हैं।
सक्रिय इनवैलिडेशन: जब डेटा बदला हो तो डिलीट या अपडेट करें
TTL पैसिव है। जब आप जानते हों कि डेटा बदल गया है, तो अक्सर सक्रिय रूप से इनवैलिडेट करना बेहतर होता है: पुरानी कुंजी डिलीट करें या नया मान तुरंत लिख दें।
उदा.: उपयोगकर्ता ने अपना ईमेल अपडेट कर दिया—user:123:profile डिलीट करें या कैश में तुरंत अपडेट करें। सक्रिय इनवैलिडेशन स्टेलनेस विंडो कम करता है, पर आपकी ऐप को भरोसेमंद तरीके से ये कैश अपडेट करना चाहिए।
वर्ज़न्ड कीज़: सरल, कम-जोखिम इनवैलिडेशन
पुरानी कुंजियों को हटाने के बजाय, कुंजी नाम में वर्ज़न शामिल करें, जैसे product:987:v42। जब प्रोडक्ट बदलता है, वर्ज़न बढ़ाकर v43 पढ़ना/लिखना शुरू करें। पुरानी वर्ज़न बाद में स्वाभाविक रूप से एक्सपायर हो जाएगी। यह उन रेस कंडीशन्स से बचने में मदद करता है जहाँ एक सर्वर कुंजी डिलीट कर रहा हो और दूसरा उसे लिख रहा हो।
कैश स्टैम्पीड से कैसे निपटें
स्टैम्पीड तब होता है जब लोकप्रिय कुंजी एक साथ एक्सपायर हो और कई रिक्वेस्ट एक ही समय पर उसे फिर से बनाना चाहें। सामान्य समाधान:
- रिक्वेस्ट कोएलेसिंग/लॉकिंग: एक ही रिक्वेस्ट रीबिल्ड करे।
- रीवैडेट करते हुए स्टेल सर्व करें: बैकग्राउंड में रीफ्रेश करते समय आखिरी मान थोड़ी देर दें।
- अर्ली रिफ्रेश: हॉट कीज़ के लिए TTL खत्म होने से पहले रीफ्रेश करें।
सेशन स्टोरेज एक की-वैल्यू स्टोर में
रोलबैक के साथ परिवर्तन टेस्ट करें
ज़रूरत पड़ने पर स्नैपशॉट्स और रोलबैक का उपयोग कर सुरक्षित रूप से कैश पैटर्न आज़माएं।
सेशन डेटा वह छोटा बंडल है जिसे आपकी ऐप को लौटते हुए ब्राउज़र/क्लाइंट को पहचानने के लिए चाहिए। न्यूनतम रूप में यह एक सेशन ID (या टोकन) है जो सर्वर-साइड स्टेट को मैप करता है। उत्पाद पर निर्भर करते हुए इसमें यूज़र स्टेट (लॉग-इन फ्लैग, रोल्स, CSRF नॉन्स), अस्थायी प्राथमिकताएँ और टाइम-सेंसिटिव डेटा जैसे कार्ट सामग्री शामिल हो सकते हैं।
सेशन्स के लिए की-वैल्यू स्टोर्स क्यों फिट बैठते हैं
की-वैल्यू स्टोर्स फिट बैठते हैं क्योंकि सेशन पढ़ना और लिखना सरल है: टोकन से लुकअप, मान फेच करना, अपडेट करना, और एक्सपायरी सेट करना। वे TTL लागू करना भी आसान बनाते हैं ताकि निष्क्रिय सेशन्स ऑटोमेटिकली गायब हो जाएँ, स्टोरेज साफ़ रहे और टोकन लीक होने पर जोखिम घटे।
सामान्य फ्लो:
- लॉगिन पर: नया रैंडम सेशन टोकन बनाएं और उस कुंजी के तहत सेशन डेटा स्टोर करें।
- हर रिक्वेस्ट पर: टोकन से पढ़ें, यदि स्लाइडिंग एक्सपायरी हो तो TTL रिफ्रेश करें।
- लॉगआउट/संदिग्ध गतिविधि पर: कुंजी तुरंत डिलीट करें।
सेशन कुंजी डिज़ाइन
स्पष्ट, स्कोप्ड कीज़ और छोटे मान रखें:
- नामकरण:
sess:<token>याsess:v2:<token>(वर्जनिंग भविष्य में मददगार)। - यूज़र स्कोपिंग: वैकल्पिक रूप से
user_sess:<userId> -> <token>रखें ताकि “प्रति-यूज़र एक सक्रिय सेशन” लागू किया जा सके या यूज़र द्वारा सेशन्स रिवोक कर सकें। - साइज़ लिमिट्स: पूरे प्रोफ़ाइल को सेशन में न भरें। केवल वही रखें जो जरूरी हो; बड़े डेटा को प्राथमिक DB में रखें और रेफर करें।
लॉगआउट और रोटेशन
लॉगआउट पर सेशन कुंजी और संबंधित इंडेक्स (जैसे user_sess:<userId>) डिलीट करें। रोटेशन (सिफारिश की जाती है) में नया टोकन बनाना, नया सेशन लिखना और फिर पुरानी कुंजी हटाना शामिल है। यह उस विंडो को संकुचित करता है जिसमें चोरी हुआ टोकन उपयोगी हो सकता है।
कैशिंग से आगे: हाई-स्पीड लुकअप्स
कैशिंग सबसे सामान्य उपयोग है, पर यह एकमात्र तरीका नहीं है जिससे की-वैल्यू स्टोर्स आपके सिस्टम को तेज़ करते हैं। कई ऐप्स छोटे, बार-बार संदर्भित स्टेट के लिए तेज़ रीड पर निर्भर हैं—ऐसी चीज़ें जो “सोर्स ऑफ़ ट्रुथ के पास” हैं और हर रिक्वेस्ट पर जल्दी चेक करनी होती हैं।
ऑथराइज़ेशन डेटा: परमिशन्स और एंटाइटलमेंट
ऑथ चेक अक्सर क्रिटिकल पाथ पर होते हैं: हर API कॉल को पूछना पड़ सकता है “क्या यह यूज़र यह कर सकता है?” रिलेशनल DB से हर रिक्वेस्ट पर परमिशन्स निकालना लेटेंसी और लोड बढ़ा सकता है।
एक की-वैल्यू स्टोर कॉम्पैक्ट ऑथ डेटा तेज़ लुकअप के लिए रख सकता है, जैसे:
perm:user:123→ परमिशन कोड्स की सूची/सेटentitlement:org:45→ एनेबल्ड प्लान फीचर्स
यह तब ख़ासकर उपयोगी है जब परमिशन्स पढ़ने-भारी हों और अपेक्षाकृत कम बदलें। जब परमिशन्स बदलें, आप छोटी कुंजी सेट को अपडेट/इनवैलिडेट करके नई एक्सेस नियमों को प्रभावी कर सकते हैं।
फीचर फ्लैग्स और कॉन्फ़िग रीड्स
फीचर फ्लैग्स छोटी, बार-बार पढ़ी जाने वाली वैल्यूज़ हैं जिन्हें तेजी से और सुसंगत रूप से उपलब्ध होना चाहिए। सामान्य पैटर्न:
flag:new-checkout→true/falseconfig:tax:region:EU→ JSON ब्लॉब या वर्ज़न्ड कॉन्फ़िग
की-वैल्यू स्टोर्स यहां अच्छा प्रदर्शन करते हैं क्योंकि रीड्स सरल, पूर्वानुमेय और तेज़ होते हैं। आप वैल्यूज़ को वर्ज़न भी कर सकते हैं (उदा. config:v27:...) ताकि रोलआउट सुरक्षित रहें और तेज़ रोलबैक संभव हो।
रेट लिमिटिंग और थ्रॉटलिंग काउंटर के साथ
रेट लिमिटिंग अक्सर प्रति-यूज़र, API की या IP के काउंटर पर समाहित होता है। की-वैल्यू स्टोर्स आमतौर पर एटॉमिक ऑपरेशंस सपोर्ट करते हैं, जो कई एक साथ आने वाली रिक्वेस्ट्स के दौरान सुरक्षित इंक्रीमेंट की अनुमति देते हैं।
उदाहरण:
rl:user:123:minute→ हर रिक्वेस्ट पर इंक्रीमेंट, 60 सेकंड पर एक्सपायरrl:ip:203.0.113.10:second→ शॉर्ट-विंडो बर्स्ट कंट्रोल
प्रत्येक काउंटर कुंजी पर TTL होने से सीमाएँ बिना बैकग्राउंड जॉब्स के ऑटोमेटिक रिसेट हो जाती हैं।
आइडेम्पोटेंसी कीज़ री-ट्राय-सेफ एंडपॉइंट्स के लिए
पेमेंट्स और अन्य “एक ही बार” ऑपरेशंस को रिट्राय से बचाने के लिए आइडेम्पोटेंसी कीज़ का रिकॉर्ड रखें:
idem:pay:order_789:clientKey_abc→ स्टोर किया गया परिणाम या स्थिति
पहली रिक्वेस्ट पर आप प्रोसेस करके परिणाम स्टोर करें और TTL दें। बाद के रिट्राइज़ पर आप स्टोर किया परिणाम लौटाएँ और ऑपरेशन फिर न चलाएँ। TTL अनबाउंड ग्रोथ को रोकता है जबकि वास्तविक रिट्राय विंडो को कवर करता है।
ये उपयोग “परम्परागत कैशिंग” नहीं हैं; ये लेटेंसी कम करने और तेज़ी व एटॉमिकिटी जैसी कोऑर्डिनेशन प्रिमिटिव्स के लिए हैं।
उपयोगी डेटा स्ट्रक्चर्स और एटॉमिक ऑपरेशंस
मोबाइल ऐप्स तक विस्तारित करें
वही कैश्ड APIs और session फ्लो दोबारा उपयोग करने वाला एक Flutter मोबाइल ऐप जोड़ें।
“की-वैल्यू स्टोर” हमेशा “स्ट्रिंग इन, स्ट्रिंग आउट” नहीं होता। कई सिस्टम समृद्ध डेटा स्ट्रक्चर्स देते हैं जो सामान्य ज़रूरतों को सीधे स्टोर के अंदर मॉडल करने देते हैं—अक्सर तेज़ और एप्लिकेशन कोड को कम जटिल बनाकर।
हैशेज/मैप्स: एक कुंजी के तहत कई फील्ड
हैश (या मैप) तब आदर्श हैं जब आपके पास एक चीज़ है जिसमें कई संबंधित एट्रिब्यूट हों। कई कुंजियाँ बनाने के बजाय जैसे user:123:name, user:123:plan, user:123:last_seen, आप सब कुछ user:123 के तहत फील्ड्स के रूप में रख सकते हैं।
यह की स्प्राल घटाता है और आपको केवल ज़रूरी फ़ील्ड फ़ेच या बदलने देता है—प्रोफाइल, फीचर फ्लैग्स या छोटे कॉन्फ़िग ब्लॉब्स के लिए उपयोगी।
सेट्स और सॉर्टेड सेट्स: सदस्यता और रैंकिंग
सेट्स “क्या X समूह में है?” जैसे प्रश्नों के लिए बहुत अच्छे हैं:
- क्या इस यूज़र ने पहले कूपन रिडीम किया?
- कौन से प्रोडक्ट IDs “summer-sale” कलेक्शन में हैं?
सॉर्टेड सेट्स में स्कोर के अनुसार ऑर्डर होता है, जो लीडरबोर्ड्स, “टॉप N” लिस्ट और समय/लोकप्रियता के अनुसार रैंकिंग के लिए उपयुक्त है।
एटॉमिक इंक्रीमेंट्स और कंडीशनल राइट्स
कॉनकरेंसी समस्याएँ छोटे फीचर्स में अक्सर दिखती हैं: काउंटर, कोटा, वन-टाइम एक्शन्स। यदि दो रिक्वेस्ट एक साथ आएँ और आपकी ऐप “रीड → +1 → राइट” करे तो अपडेट खो सकता है।
एटॉमिक ऑपरेशंस इसे एक ही, अविभाज्य स्टेप के रूप में करते हैं:
- एटॉमिक इंक्रीमेंट काउंटर के लिए (व्यूज़, रिट्राईज़, API कॉल्स)
- कंडीशनल राइट (केवल सेट अगर मिस, या केवल अपडेट अगर वर्ज़न मैच) डबल-प्रोसेसिंग रोकने के लिए
क्यों एटॉमिक ऑपरेशंस काउंटर और लिमिट्स को सरल बनाते हैं
एटॉमिक इंक्रीमेंट के साथ, आपको सर्वर-लेवल लॉक या अतिरिक्त समन्वय की ज़रूरत नहीं पड़ती। इसका मतलब है कम रेस कंडीशन्स, सरल कोड पाथ और लोड के दौरान अधिक पूर्वानुमेय व्यवहार—खासकर रेट-लिमिटिंग और उपयोग सीमा जहाँ “लगभग सही” ग्राहक-विरोधी मुद्दे पैदा कर सकता है।
ट्रैफ़िक के लिए स्केल करना: रेप्लिकेशन, शार्डिंग और उपलब्धता
जब की-वैल्यू स्टोर गंभीर ट्रैफ़िक संभालने लगे, “इसे तेज़ बनाना” अक्सर अर्थ रखता है “इसे चौड़ा बनाना": पढ़ने और लिखने को कई नोड्स पर फैलाना जबकि फेलियर के दौरान सिस्टम पूर्वानुमेय रहे।
पढ़ने और लिखने को स्केल करना: रेप्लिकेशन बनाम शार्डिंग
रेप्लिकेशन एक ही डेटा की कई प्रतियाँ रखता है。
- रीड-हेवी वर्कलोड के लिए (अकसर कैशिंग), रेप्लिकाज़ पढ़ने में मदद करते हैं।
- राइट्स आमतौर पर प्राइमरी/लीडर पर जाते हैं और फिर रेप्लिकाज़ में कॉपी होते हैं—जिससे रेप्लिकाज़ पर नवीनतम मान में थोड़ा लेग हो सकता है।
Shardिंग की-स्पेस को नोड्स में बाँट देती है।
- प्रत्येक नोड कुछ कुंजियों का मालिक होता है (उदा. कुंजी के हैश से निर्धारित)।
- शार्डिंग पढ़ने और लिखने दोनों थ्रूपुट बढ़ाती है क्योंकि काम विभाजित हो जाता है, पर ऑपरेशनल जटिलता बढ़ जाती है (रीबैलेंसिंग, हॉट कीज़, कौन नोड किसकीज़ का मालिक है ट्रैक करना)।
कई परिनियोजन इन दोनों को मिलाते हैं: थ्रूपुट के लिए शार्ड्स और उपलब्धता के लिए प्रति-शार्ड रेप्लिकाज़।
प्रैक्टिस में हाई अवेलेबिलिटी और फेलओवर
“हाई अवेलेबिलिटी” का मतलब आमतौर पर है कि कैश/सेशन लेयर अनुरोध परोसना जारी रखे भले ही कोई नोड फेल कर जाए।
- फेलओवर तब होता है जब प्राइमरी मर जाए तो एक रेप्लिका को नया प्राइमरी प्रमोट कर दिया जाए।
- व्यवहार में, आपकी ऐप को स्विचओवर के दौरान छोटे एरर्स या रिट्राईज़ सहन करने चाहिए, और स्वीकार करना चाहिए कि कुछ हालिया राइट्स बच नहीं सकते अगर वे सफलतापूर्वक रेप्लिकेट नहीं हुए थे।
क्लाइंट-साइड बनाम सर्वर-साइड राउटिंग
क्लाइंट-साइड राउटिंग में आपकी ऐप (या लाइब्रेरी) गणना करती है कि कौन सा नोड किस कुंजी का मालिक है (कंसिस्टेंट हैशिंग सामान्य)। यह तेज़ हो सकता है पर क्लाइंट को टोपोलोजी परिवर्तनों की जानकारी रखनी पड़ती है।
सर्वर-साइड राउटिंग में आप अनुरोध प्रॉक्सी या क्लस्टर एंडपॉइंट पर भेजते हैं जो सही नोड को फॉरवर्ड करता है। यह क्लाइंट को सरल बनाता है पर एक अतिरिक्त हॉप जोड़ता है।
क्षमता योजना: मेमोरी, हेडरूम और विकास
ऊपर से नीचे मेमोरी प्लान करें:
- वर्किंग-सेट का अनुमान लगाएँ (वह क्या आप वास्तव में “हॉट” रखने की अपेक्षा करते हैं), साथ में मेटाडेटा ओवरहेड।
- हेडरूम जोड़ें (अक्सर 20–50%) ट्रैफ़िक स्पाइक्स, रीबैलेंसिंग और uneven की वितरण के लिए।
- लोड के तहत एविक्शन-पॉलिसी व्यवहार को वैलिडेट करें ताकि सिस्टम थ्रैशिंग के बजाय graceful degrade करे।
भरोसेमंदी और समझने योग्य ट्रेड-ऑफ
की-वैल्यू स्टोर्स “इंस्टेंट” महसूस होते हैं क्योंकि वे हॉट डेटा को मेमोरी में रखते हैं और तेज़ रीड/राइट के लिए ऑप्टिमाइज़ करते हैं। इस गति की कीमत है: अक्सर आप प्रदर्शन, ड्यूरेबिलिटी और कंसिस्टेंसी के बीच चुनते हैं। पहले से ये ट्रेड-ऑफ समझना बाद में दर्दनाक आश्चर्य से बचाता है।
परसिस्टेंस: आप कितना डेटा खोने के लिए तैयार हैं?
कई की-वैल्यू स्टोर्स अलग-अलग परसिस्टेंस मोड्स में चल सकते हैं:
- कोई नहीं (पूरी तरह इन-मेमोरी): सबसे तेज़ और सरल—जब तक रीस्टार्ट पर सब हट न जाए। कैश के लिए अच्छा है जहां डेटा पुनः-जनरेट हो सके।
- स्नैपशॉट्स: समय-समय पर डिस्क पर सेव। नोड क्रैश होने पर आप आखिरी स्नैपशॉट के बाद का डेटा खो सकते हैं।
- एपेंड-ओनली लॉग्स: राइट्स सीक्वेंशियली रिकॉर्ड होते हैं। रिकवरी इन-मेमोरी से धीमी होती है पर आप स्नैपशॉट्स की तुलना में कम डेटा खोते हैं।
मोड चुनें जो डेटा के उद्देश्य से मेल खाता हो: कैशिंग डेटा हानि सहन कर सकती है; सेशन स्टोरेज को अधिक सावधानी चाहिए।
कंसिस्टेंसी अपेक्षाएँ: “क्या मेरी राइट सच्च में टिक गई?”
वितरित सेटअप्स में आप इवेंटुअल कंसिस्टेंसी देख सकते हैं—राइट के बाद कुछ समय तक पढ़ना पुराना मान वापस कर सकता है, खासकर फेलओवर या रेप्लिकेशन लेग के दौरान। मजबूत कंसिस्टेंसी (उदा. कई नोड्स से ACK चाहिए) अनॉमलीज़ को घटाता है पर लेटेसी बढ़ाता है और नेटवर्क इश्यूज़ पर उपलब्धता घटा सकता है।
जब मेमोरी भर जाए: एविक्शन और दबाव के तहत व्यवहार
कैश भर जाएगा। एक एविक्शन पॉलिसी तय करती है कि क्या हटेगा: least-recently-used, least-frequently-used, रैंडम, या “न-एविक्ट” (जो पूरा मेमोरी होने पर राइट फेल करवा दे सकता है)। तय करें कि आप प्रैसर में मिसेस को पसंद करेंगे या एरर्स।
स्टोर डाउन हो तो: डिग्रेडेड मोड की योजना
आउटेज़ मान कर चलें। सामान्य फ़ॉलबैक:
- कैश बायपास और प्राथमिक DB से पढ़ें (उपयुक्त रेट लिमिटिंग के साथ)।
- थोड़ी स्टेल डेटा परोसें जब सुरक्षित हो।
- संवेदनशील ऑपरेशन्स के लिए फेल क्लोज़ रखें, जबकि गैर-आवश्यक फीचर्स degrade कर दें।
इन बिहेवियर को जानबूझकर डिज़ाइन करना ही सिस्टम को यूज़र्स के लिए भरोसेमंद बनाता है।
सुरक्षा, मॉनिटरिंग और लागत के मूल बातें
कोड पर पूरा नियंत्रण रखें
जब आप इसे अपनी पाइपलाइन में चलाने के लिए तैयार हों तो सोर्स कोड एक्सपोर्ट करें।
की-वैल्यू स्टोर्स अक्सर आपकी ऐप के “हॉट पाथ” पर रहते हैं। इससे वे संवेदनशील भी होते हैं (वे सेशन टोकन या यूज़र आइडेंटिफ़ायर्स रख सकते हैं) और महंगे भी (आमतौर पर मेमोरी-सघन)। शुरुआती सही कदम बाद में बड़ी घटनाओं को रोकते हैं।
सुरक्षा: पहुँच कड़ी रखें
नेटवर्क सीमाएँ स्पष्ट रखें: स्टोर को प्राइवेट सबनेट/VPC में रखें और केवल उन्हीं एप्लिकेशन सेवाओं के लिए ट्रैफ़िक की अनुमति दें जिन्हें वास्तव में ज़रूरत है।
यदि उत्पादन प्रोडक्ट ऑथेंटिकेशन सपोर्ट करता है तो उसका उपयोग करें, और least privilege अपनाएँ: ऐप्स, एडमिन्स और ऑटोमेशन के लिए अलग क्रेडेंशियल्स; सीक्रेट्स रोटेट करें; साझा “root” टोकन से बचें।
ट्रैफ़िक ज़ोन/होस्ट पार कर रहा हो तो इन-ट्रांज़िट एन्क्रिप्शन (TLS) अनिवार्य करें। एट-रेस्ट एन्क्रिप्शन उत्पाद-और-परिनियोजन-निर्भर है; मैनेज्ड सर्विसेज़ में सक्षम करें और बैकअप एन्क्रिप्शन भी वेरिफाई करें।
मॉनिटरिंग: रोज़ किसपे नजर रखें
कुछ मुख्य मेट्रिक्स बताते हैं कि कैश मदद कर रहा है या नुकसान पहुँचा रहा है:
- हिट रेट: घटती हिट रेट खराब कुंजी, बहुत छोटे TTL या एविक्शन से हो सकती है।
- लेटेंसी (p95/p99): स्पाइक्स सैचुरेशन, नेटवर्क इश्यूज़, या बड़े वैल्यूज़ की निशानी हैं।
- मेमोरी उपयोग & एविक्शन्स: लगातार उच्च मेमोरी और एविक्शन्स मतलब आपका डेटा फिट नहीं हो रहा या पॉलिसी गलत है।
- एरर्स/टाइमआउट्स: छोटे आउटेज़ भी डेटाबेस और यूज़र-फेसिंग फेलियर में बदल सकते हैं।
अलर्ट्स अचानक बदलावों के लिए रखें, सिर्फ़ थ्रेशोल्ड्स के लिए नहीं, और की ऑपरेशंस को लॉग करते समय संवेदनशील मानों को ना लॉग करें।
लागत: बिल को क्या बढ़ाता है
सबसे बड़े ड्राइवर हैं:
- मेमोरी फुटप्रिंट: बड़े वैल्यूज़, बहुत सारी कुंजियाँ, या “अच्छा-है-रखने” वाला डेटा।
- ट्रैफ़िक: रीड/राइट वॉल्यूम और क्रॉज़-ज़ोन ट्रांसफर।
- रेप्लिकाज़ & हाई अवेलेबिलिटी: और नोड्स अधिक लागत जोड़ते हैं।
- रिटेंशन: लंबे TTL मेमोरी को फुल रखते हैं।
व्यावहारिक लागत लीवर: वैल्यू साइज घटाएँ और यथार्थवादी TTL सेट करें ताकि स्टोर सिर्फ़ वही रखे जो सक्रिय रूप से उपयोगी हो।
इम्प्लीमेंटेशन चेकलिस्ट और अगले कदम
प्रैक्टिकल रोलआउट चेकलिस्ट
सबसे पहले की नामकरण स्टैंडर्डाइज़ करें ताकि आपके कैश और सेशन कीज़ अनुमाननीय, सर्चेबल और बड़े ऑपरेशन्स में सुरक्षित हों। एक साधारण कॉन्वेंशन जैसे app:env:feature:id (उदा. shop:prod:cart:USER123) टकराव से बचाता और डिबगिंग तेज़ बनाता है।
एक TTL रणनीति पहले से तय करें। तय करें कौन सा डेटा जल्दी एक्सपायर हो सकता है (सेकंड/मिनट), क्या लंबी लाइफटाइम चाहिए (घंटे), और क्या बिल्कुल कैश न किया जाए। यदि आप DB पंक्तियों को कैश कर रहे हैं, तो TTLs को मूल डेटा की परिवर्तन दर के साथ संरेखित करें।
प्रत्येक कैश्ड आइटम टाइप के लिए एक इनवैलिडेशन प्लान लिखें:
- टाइम-आधारित एक्सपायर (TTL-only) उस freshness के लिए जो “पर्याप्त” है
- इवेंट-आधारित इनवैलिडेशन जब आप जानते हैं क्या बदला (उदा. प्रोडक्ट अपडेट)
- वर्ज़न्ड कीज़ (उदा.
product:v3:123) जब आप सरल “सभी इनवैलिडेट” व्यवहार चाहते हैं
सफलता कैसे मापें
शुरू से कुछ सफलता मीट्रिक्स चुनें और उन्हें ट्रैक करें:
- एंडपॉइंट के हिसाब से कैश हिट रेट टार्गेट्स (अधिकांश ऐप्स के लिए 70–95% उपयोगी रेंज होती है)
- डेटाबेस लोड में कमी (queries/sec, CPU, या read replica utilization)
- लेटेंसी पर p95/p99 में बदलाव (सिर्फ औसत नहीं)
साथ ही एविक्शन काउंट और मेमोरी उपयोग मॉनिटर करें ताकि कैश सही आकार में है यह कन्फर्म हो सके।
सामान्य पिटफॉल्ट्स से बचें
बड़े वैल्यूज़ नेटवर्क समय और मेमोरी दबाव बढ़ाते हैं—छोटे, प्रीकम्प्यूटेड फ्रैगमेंट्स पसंद करें। मिसिंग TTLs से स्टेल डेटा और मेमोरी लीक होते हैं; अनबाउंड की ग्रोथ से सावधान रहें (जैसे हर सर्च क्वेरी को हमेशा कैश करना)। साझा कुंजियों के तहत यूज़र-विशिष्ट डेटा कैश न करें।
अगले कदम
यदि आप विकल्पों का मूल्यांकन कर रहे हैं, तो लोकल इन-प्रोसेस कैश बनाम वितरित कैश की तुलना करें और तय करें कि कंसिस्टेंसी किस जगह ज़्यादा मायने रखती है। इम्प्लीमेंटेशन डिटेल्स और ऑपरेशनल गाइड के लिए /docs देखें। यदि आप क्षमता या प्राइसिंग अनुमान चाहते हैं, तो /pricing देखें।
यदि आप नया उत्पाद बना रहे हैं (या मौजूदा को मॉडर्नाइज़ कर रहे हैं), तो कैशिंग और सेशन स्टोरेज को शुरुआत से फर्स्ट-क्लास चिंता के रूप में डिज़ाइन करना मददगार होता है। On Koder.ai, टीमें अक्सर एक एंड-टू-एंड ऐप प्रोटोटाइप (React वेब, Go सर्विसेज़ के साथ PostgreSQL, और वैकल्पिक रूप से मोबाइल के लिए Flutter) बनाती हैं और फिर cache-aside, TTLs और रेट-लिमिट काउंटर जैसी पैटर्न के साथ प्रदर्शन पर इटेरेट करती हैं। प्लानिंग मोड, स्नैपशॉट्स और रोलबैक जैसी सुविधाएँ कैश कीज और इनवैलिडेशन रणनीतियों को सुरक्षित रूप से आज़माना आसान बनाती हैं, और जब आप तैयार हों तो स्रोत कोड एक्सपोर्ट कर सकते हैं।
अक्सर पूछे जाने वाले प्रश्न
परंपरागत डेटाबेस की तुलना में की-वैल्यू स्टोर्स इतने तेज़ क्यों होते हैं?
की-वैल्यू स्टोर्स एक ऑपरेशन के लिए ऑप्टिमाइज़ करते हैं: कुंजी दीजिए, मान लौटाइए। यह संकुचित फोकस इन-मेमोरी इंडेक्सिंग और हैशिंग जैसे तेज़ रास्तों को सक्षम करता है, और सामान्य-उद्देश्य डेटाबेस की तुलना में कम क्वेरी-योजना ओवरहेड होता है.
ये अप्रत्यक्ष रूप से भी आपके सिस्टम को तेज़ बनाते हैं क्योंकि वे बार-बार होने वाले रीड्स (लोकप्रिय पेज, सामान्य API प्रतिक्रियाएँ) को ऑफ़लोड कर देते हैं, ताकि प्राथमिक डेटाबेस राइट्स और जटिल क्वेरीज पर ध्यान दे सके।
कुंजी और मान असल में क्या होते हैं एक की-वैल्यू स्टोर में?
कुंजी एक अद्वितीय पहचानकर्ता है जिसे आप ठीक-ठीक दोहराकर दे सकते हैं (अक्सर स्ट्रिंग जैसे user:123 या sess:<token>). मान वह चीज़ है जिसे आप वापस पाना चाहते हैं—छोटा काउंटर से लेकर बड़ा JSON ब्लॉब तक कुछ भी हो सकता है।
अच्छी कुंजियाँ स्थिर, स्कोप्ड और अनुमाननीय होनी चाहिए—यह कैशिंग, सेशन और लुकअप को ऑपरेट और डिबग करने में आसान बनाता है।
मुझे की-वैल्यू स्टोर में क्या कैश करना चाहिए?
उन परिणामों को कैश करें जिन्हें बार-बार पढ़ा जाता है और जिन्हें खोने पर आप फिर से जेनरेट कर सकते हैं।
सामान्य उदाहरण:
- सार्वजनिक या अर्ध-स्थिर पेज फрагमेंट (श्रेणी पेज, “टॉप प्रोडक्ट्स”)
- कम्प्यूटेड आउटपुट (सिफारिशें, टोटल्स, रिपोर्ट स्निपेट)
- हर रिक्वेस्ट पर पढ़ी जाने वाली फीचर फ्लैग्स और कॉन्फ़िग्रेशन
- अल्पकालिक तीसरे-पक्ष API प्रतिक्रियाएँ
ऐसी चीज़ों को कैश करने से बचें जिन्हें बिल्कुल ताज़ा होना ज़रूरी है (उदा. बैंक बैलेंस) जब तक आपके पास भरोसेमंद इनवैलिडेशन रणनीति न हो।
cache-aside पैटर्न क्या है और यह कब अच्छा विकल्प है?
Cache-aside (लेज़ी लोडिंग) आमतौर पर डिफ़ॉल्ट पैटर्न है:
- कैश से कुंजी पढ़ें।
- मिस होने पर स्रोत (डेटाबेस) से पढ़ें।
- परिणाम को TTL के साथ कैश में रखें।
- परिणाम लौटाएँ।
यह gracefully degrade होता है: अगर कैश खाली या डाउन है तो आप अभी भी डेटाबेस से रीकवर कर सकते हैं (संतुलित सावधानियों के साथ)।
read-through और write-through कैशिंग में क्या फर्क है?
यदि आप चाहते हैं कि कैश लेयर मिस होने पर अपने आप लोड कर ले तो read-through उपयोग करें (ऐप को सरल बनाता है, पर कैश-टियर में लोडर इंटीग्रेशन चाहिए).
यदि आप चाहते हैं कि हर राइट सिंक्रोनसली कैश और डेटाबेस दोनों में जाए तो write-through उपयोग करें—रीड्स ज़्यादा कंसिस्टेंट रहते हैं पर राइट लेटेसी बढ़ती है।
चुनें जब आप ऑपरेशनल जटिलता (read-through) या बढ़ी हुई राइट टाइम (write-through) स्वीकार कर सकें।
कैश के लिए अच्छा TTL कैसे चुनें?
TTL (time to live) किसी कुंजी को स्वचालित रूप से समाप्त कर देता है। छोटे TTL से स्टेलनेस कम होता है पर कैश मिस और बैकएंड लोड बढ़ता है; लंबे TTL से हिट रेट बेहतर होता है पर पुराने मान परोसने का जोखिम बढ़ता है।
व्यवहारिक सुझाव:
- TTL को उस डेटा की परिवर्तन आवृत्ति के अनुरूप रखें।
- बहुत सारे एकसमान TTL वाले कीज़ के साथ समापन-लहर से बचने के लिए जिटर डालें।
- जब आप जानते हों कि डेटा बदल गया है तो एक्टिव इनवैलिडेशन (डिलीट/अपडेट) प्राथमिकता दें।
कैश स्टैम्पीड क्या है और मैं इसे कैसे रोक सकता/सकती हूँ?
जब लोकप्रिय कुंजी समाप्त हो जाती है और कई अनुरोध एक ही समय में उसे फिर से बनाने लगते हैं तो कैश स्टैम्पीड होता है।
सामान्य उपाय:
- रिक्वेस्ट कोएलेसिंग/लॉकिंग: केवल एक रिक्वेस्ट रीबिल्ड करे, बाकी इंतज़ार करें।
- रीवैलिडेट करते हुए स्टेल परोसा जाए: रीफ्रेश बैकग्राउंड में करते हुए पिछला मान थोड़ी देर के लिए दे दें।
- अर्ली रिफ्रेश: हॉट कीज़ के लिए TTL खत्म होने से पहले रीफ्रेश करें।
ये उपाय अचानक स्पाइक्स और बैकएंड ओवरलोड को कम करते हैं।
मुझे सेशन स्टोरेज के लिए की-वैल्यू स्टोर का उपयोग कैसे करना चाहिए?
सेशन ऐसे छोटे-सेट हैं जिन्हें आपकी ऐप वापसी करने वाले ब्राउज़र/क्लाइंट को पहचानने के लिए चाहिए—कम से कम सेशन ID/टोकन जो सर्वर-साइड स्टेट से मैप होता है।
सुनिश्चत करें:
- स्कोप्ड कीज़ का उपयोग करें जैसे
sess:<token>(वर्जनिंग जैसेsess:v2:<token>भविष्य की बदलावों में मदद करता है)। - सेशन वैल्यूज़ को छोटा रखें; पूरा प्रोफ़ाइल न भरें—बड़े डेटा को प्राइमरी DB में रखें और रेफर करें।
रेट लिमिटिंग में की-वैल्यू स्टोर्स कैसे मदद करते हैं?
कई की-वैल्यू स्टोर्स एटॉमिक इंक्रीमेंट जैसे ऑपरेशंस सपोर्ट करते हैं, इसलिए काउंटर कांकरेंसी में सुरक्षित रहते हैं।
सामान्य पैटर्न:
rl:user:123:minute→ हर रिक्वेस्ट पर इंक्रीमेंट करें- इस कुंजी पर 60 सेकंड का TTL सेट करें
यदि काउंटर थ्रेशोल्ड पार कर जाए तो थ्रॉटल या रिजेक्ट करें। TTL आधारित एक्सपायर स्वतः सीमाओं को रीसेट कर देता है बिना बैकग्राउंड जॉब्स के।
कुंजी-मूल्य स्टोर अपनाने से पहले मुझे कौन से रिलायबिलिटी ट्रेड-ऑफ समझने चाहिए?
मुख्य ट्रेड-ऑफ जिन्हें समझना ज़रूरी है:
- परसिस्टेंस: पूरी तरह इन-मेमोरी सबसे तेज़ है पर रीस्टार्ट पर डेटा चला जाता है; स्नैपशॉट्स/एपेंड-ओनली लॉग बेहतर परसिस्टेंस देते हैं पर ओवरहेड बढ़ाते हैं।
- कंसिस्टेंसी: रेप्लिकेशन में रेप्लिकेशन लेग से थोड़ी स्टेलनेस आ सकती है, विशेषकर फेलओवर के समय। मजबूत कंसिस्टेंसी लेटेसी बढ़ा सकती है और नेटवर्क इश्यूज़ पर उपलब्धता घटा सकती है।
- एविक्शन: मेमोरी भरने पर कौन सा नीति लागू होगी (LRU/LFU/random/no-evict) यह तय करें—क्या आप मिस पसंद करेंगे या एरर।
डिग्रेडेड मोड की योजना बनाएं: कैश बायपास करना, थोड़ी स्टेल डेटा परोसना या संवेदनशील ऑपरेशन्स के लिए फेल-कलोज़ रखना।